
Improved CNN Prediction Based Reversible Data Hiding for Images

Abstract
1. Introduction
2. Proposed Improved Scheme
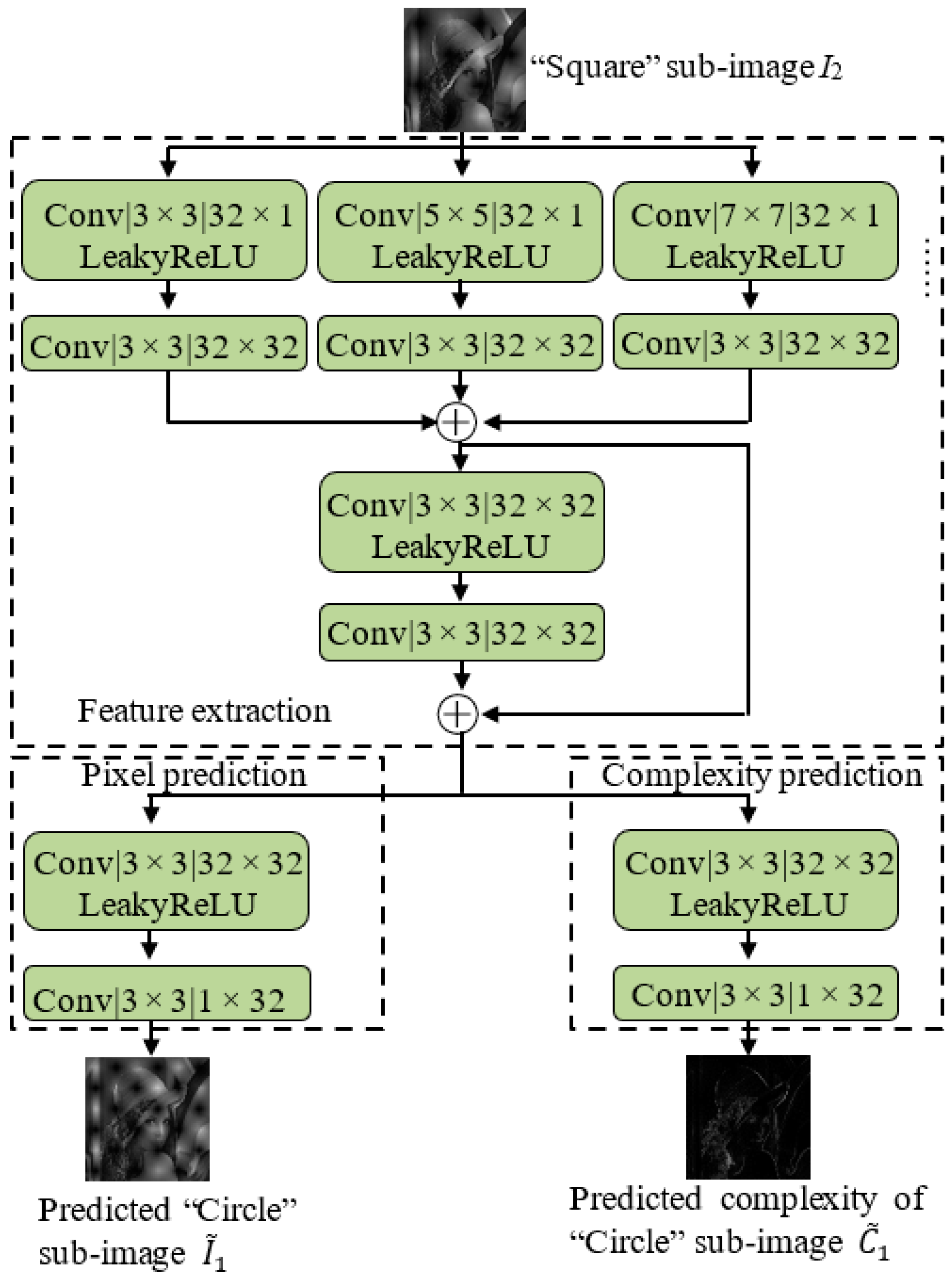
2.1. Network Architecture
2.2. Training
- (1)
- For “Square” pixels, is set to 0.
- (2)
- For “Circle” pixels, if , , , or , is set to 0; otherwise, is calculated aswhere
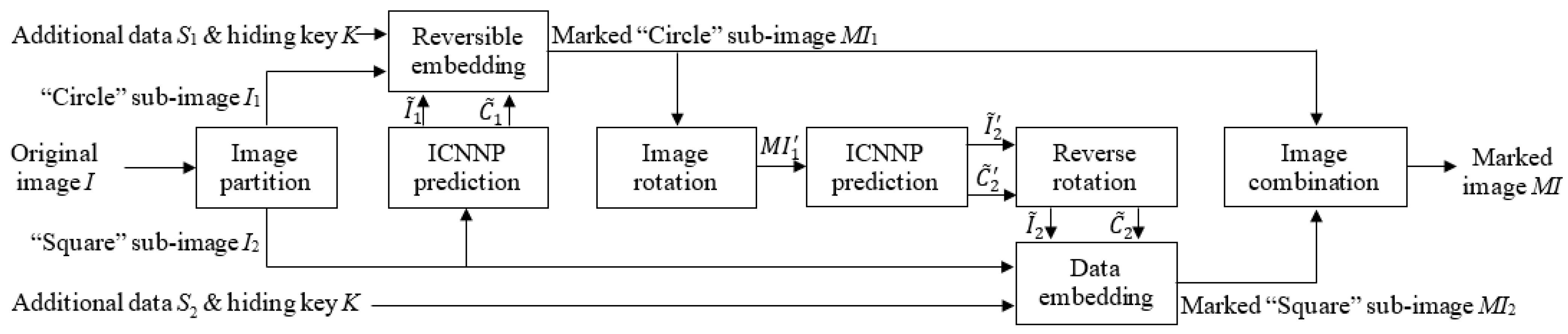
2.3. Data Embedding of ICNNP-Based RDH
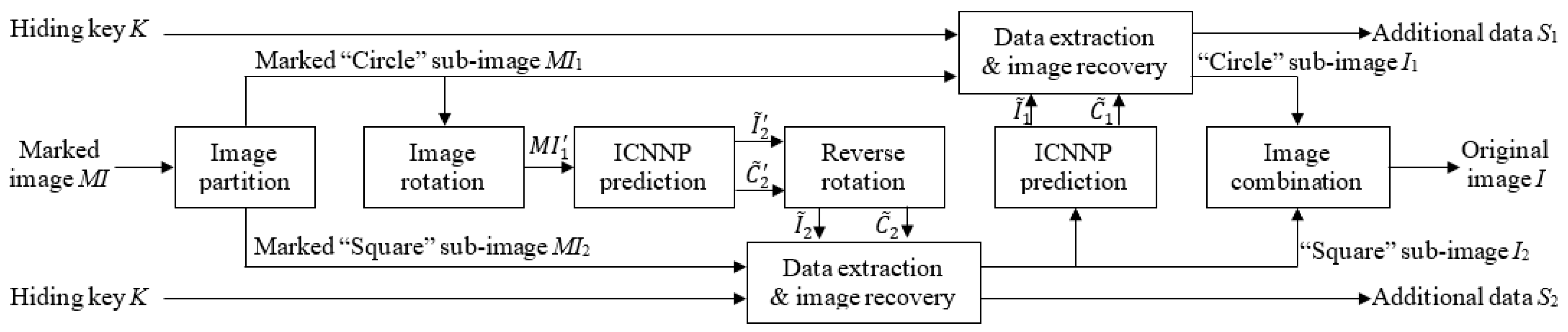
2.4. Extraction and Image Recovery of ICNNP-Based RDH
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shi, Y.-Q.; Li, X.; Zhang, X.; Wu, H.; Ma, B. Reversible data hiding: Advances in the past two decades. IEEE Access 2016, 4, 3210–3237. [Google Scholar] [CrossRef]
- Zhang, C.; Ou, B.; Peng, F.; Zhao, Y.; Li, K. A survey on reversible data hiding for uncompressed images. ACM Comput. Surv. 2024, 56, 1–33. [Google Scholar] [CrossRef]
- Celik, M.U.; Sharma, G.; Tekalp, A.M.; Saber, E. Lossless generalized-LSB data embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Hu, X.; Li, X.; Yu, N. Optimal transition probability of reversible data hiding for general distortion metrics and its applications. IEEE Trans. Image Process. 2015, 24, 294–304. [Google Scholar] [CrossRef]
- Hou, D.; Zhang, W.; Yang, Y.; Yu, N. Reversible data hiding under inconsistent distortion metrics. IEEE Trans. Image Process. 2018, 27, 5087–5099. [Google Scholar] [CrossRef]
- Tian, J. Reversible data embedding using a difference expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef]
- Thodi, D.M.; Rodriguez, J.J. Expansion embedding techniques for reversible watermarking. IEEE Trans. Image Process. 2007, 16, 721–730. [Google Scholar] [CrossRef]
- Luo, L.; Chen, Z.; Chen, M.; Zeng, X.; Xiong, Z. Reversible image watermarking using interpolation technique. IEEE Trans. Inf. Forensics Secur. 2010, 5, 187–193. [Google Scholar]
- Coltuc, D. Low distortion transform for reversible watermarking. IEEE Trans. Image Process. 2012, 21, 412–417. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Li, J.; Li, B.; Yang, B. High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion. Signal Process. 2013, 93, 198–205. [Google Scholar] [CrossRef]
- Dragoi, I.-C.; Coltuc, D. Local-prediction-based difference expansion reversible watermarking. IEEE Trans. Image Process. 2014, 23, 1779–1790. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Qian, Z.; Yu, L. Adaptive reversible data hiding by extending the generalized integer transformation. IEEE Signal Process. Lett. 2016, 23, 130–134. [Google Scholar]
- He, W.; Cai, Z. An insight into pixel value ordering prediction-based prediction-error expansion. IEEE Trans. Circuits Syst. Video Technol. 2020, 15, 3859–3871. [Google Scholar] [CrossRef]
- Luo, T.; Jiang, G.; Yu, M.; Zhong, C.; Xu, H.; Pan, Z. Convolutional neural networks-based stereo image reversible data hiding method. J. Vis. Commun. Image Represent. 2019, 61, 61–73. [Google Scholar] [CrossRef]
- Hu, R.; Xiang, S. CNN Prediction Based Reversible Data Hiding. IEEE Signal Process. Lett. 2021, 28, 464–468. [Google Scholar] [CrossRef]
- Hu, R.; Xiang, S. Reversible Data Hiding by Using CNN Prediction and Adaptive Embedding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 464–468. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Huang, F. New CNN-Based Predictor for Reversible Data Hiding. IEEE Signal Process. Lett. 2022, 29, 2627–2631. [Google Scholar] [CrossRef]
- Zhou, L.; Lu, Z.; You, W. Reversible data hiding using a transformer predictor and an adaptive embedding strategy. Front. Inf. Technol. Electron. Eng. 2023, 24, 1143. [Google Scholar] [CrossRef]
- Ni, Z.; Shi, Y.; Ansari, N.; Su, W. Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar]
- Sachnev, V.; Kim, H.J.; Nam, J.; Suresh, S.; Shi, Y.-Q. Reversible watermarking algorithm using sorting and prediction. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 989–999. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Gui, X.; Yang, B. Efficient reversible data hiding based on multiple histograms modification. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2016–2027. [Google Scholar]
- Qi, W.; Li, X.; Zhang, T.; Guo, Z. Optimal Reversible Data Hiding Scheme Based on Multiple Histograms Modification. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2300–2312. [Google Scholar] [CrossRef]
- Wang, J.; Chen, X.; Ni, J.; Mao, N.; Shi, Y. Multiple Histograms-Based Reversible Data Hiding: Framework and Realization. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2313–2328. [Google Scholar] [CrossRef]
- Ou, B.; Zhao, Y. High capacity reversible data hiding based on multiple histograms modification. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2329–2342. [Google Scholar] [CrossRef]
- Zhang, T.; Li, X.; Qi, W.; Guo, Z. Location-based pvo and adaptive pairwise modification for efficient reversible data hiding. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2306–2319. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Ma, B.; Li, Q.; Shi, Y.-Q. High Precision Error Prediction Algorithm Based on Ridge Regression Predictor for Reversible Data Hiding. IEEE Signal Process. Lett. 2021, 28, 1125–1129. [Google Scholar] [CrossRef]
- Weng, S.; Zhou, Y.; Zhang, T.; Xiao, M.; Zhao, Y. General Framework to Reversible Data Hiding for JPEG Images With Multiple Two-Dimensional Histograms. IEEE Trans. Multimed. 2023, 25, 5747–5762. [Google Scholar] [CrossRef]
- Mao, N.; He, H.; Chen, F.; Yuan, Y.; Qu, L. Reversible Data Hiding of JPEG Image Based on Adaptive Frequency Band Length. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7212–7223. [Google Scholar] [CrossRef]
- Zhou, X.; Hou, K.; Zhuang, Y.; Yin, Z.; Han, W. General Pairwise Modification Framework for Reversible Data Hiding in JPEG Images. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 153–167. [Google Scholar] [CrossRef]
- Li, F.; Qi, Z.; Zhang, X.; Qin, C. Progressive Histogram Modification for JPEG Reversible Data Hiding. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 1241–1254. [Google Scholar] [CrossRef]
- Qiu, Y.; Qian, Z.; He, H.; Tian, H.; Zhang, X. Optimized lossless data hiding in JPEG bitstream and relay transfer based extension. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1380–1394. [Google Scholar] [CrossRef]
- Du, Y.; Yin, Z.; Zhang, X. High capacity lossless data hiding in JPEG bitstream based on general VLC mapping. IEEE Trans. Depend. Secure Comput. 2022, 19, 1420–1433. [Google Scholar] [CrossRef]
- Maas, A.L.; Awni, Y.H.; Andrew, Y.N. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Bas, P.; Furon, T. Image Database of Bows-2. 2017. Available online: http://bows2.ec-lille.fr/ (accessed on 21 June 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Embedding Capacity (Bits) | Embedding Rate (bpp) | CNNP [15] | ICNNP |
|---|---|---|---|
| 10,000 | 0.038 | 61.31 | 62.37 |
| 20,000 | 0.076 | 58.01 | 58.82 |
| 30,000 | 0.114 | 55.98 | 56.58 |
| 40,000 | 0.153 | 54.43 | 54.98 |
| 50,000 | 0.191 | 53.10 | 53.66 |
| 60,000 | 0.229 | 51.94 | 52.49 |
| 70,000 | 0.267 | 50.86 | 51.40 |
| 80,000 | 0.305 | 49.85 | 50.38 |
| 90,000 | 0.343 | 48.88 | 49.39 |
| 100,000 | 0.381 | 47.91 | 48.38 |
| 110,000 | 0.420 | 46.95 | 47.36 |
| 120,000 | 0.458 | 46.03 | 46.40 |
| 130,000 | 0.496 | 45.13 | 45.46 |
| 140,000 | 0.534 | 44.29 | 44.55 |
| 150,000 | 0.572 | 43.47 | 43.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Y.; Peng, W.; Lin, X. Improved CNN Prediction Based Reversible Data Hiding for Images. Entropy 2025, 27, 159. https://doi.org/10.3390/e27020159
Qiu Y, Peng W, Lin X. Improved CNN Prediction Based Reversible Data Hiding for Images. Entropy. 2025; 27(2):159. https://doi.org/10.3390/e27020159
Chicago/Turabian StyleQiu, Yingqiang, Wanli Peng, and Xiaodan Lin. 2025. "Improved CNN Prediction Based Reversible Data Hiding for Images" Entropy 27, no. 2: 159. https://doi.org/10.3390/e27020159
APA StyleQiu, Y., Peng, W., & Lin, X. (2025). Improved CNN Prediction Based Reversible Data Hiding for Images. Entropy, 27(2), 159. https://doi.org/10.3390/e27020159