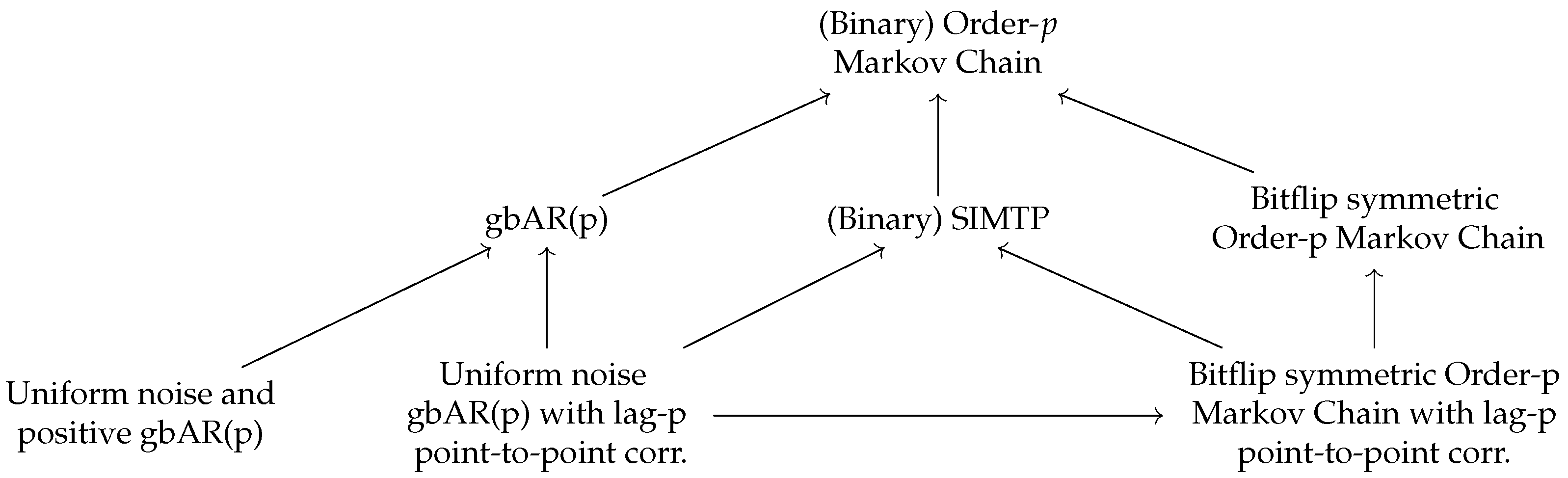
1. Introduction
The security of cryptographic systems often relies on the generation of random values. Although there is a broad spectrum of algorithms and devices used to generate these random values, they are all generically denoted by random number generators (RNGs). Given the important role that RNGs play in the context of cybersecurity, it becomes evident that rigorous criteria are necessary to evaluate the reliability and performance of an RNG.
Multiple approaches are commonly employed to assess the quality of the output of an RNG (cf. [
1,
2,
3,
4,
5,
6], etc.). In this paper, the emphasis will be put on the following:
Entropy tests, as those found in NIST Special Publication 800-90B [
7], which estimate the entropy of a noise source based on appropriate samples (cf. [
8,
9,
10], etc.).
Machine Learning models trained with the output of an RNG aiming to guess the bit or set of bits that follow a given sequence, which can give an insight into how predictable the output of the RNG is (cf. [
11,
12,
13,
14,
15,
16], etc.).
The relationship between entropy measures and the predictability of sequences is a key concept in information theory. Nevertheless, the link between these two concepts is far from being completely understood, especially if one takes into account the heterogeneity of entropy definitions that can be found in the literature and how much the predictability of the output of an entropy source relies on the predictor being considered. Based on the evidence provided by [
17] that the entropy estimators considered by NIST Special Publication 800-90B [
7] tend to underestimate min-entropy, in this paper, an attempt is made to reinforce the argument [
18] that predictors are better suited to estimate average min-entropy [
19] than min-entropy. In the first stage, the theoretical framework required to support our thesis is developed. In the second stage, experimental validation of the theoretical analysis is conducted.
Whereas [
17] concentrates on ensemble, categorical data, and numerical predictors, the focus of this paper will be on machine learning predictors. In particular, a hybrid model that integrates convolutional and recurrent long short-term memory (LSTM) layers, and the transformer-based GPT-2 model will be considered. As in [
18], we generate sets of data for which a theoretical entropy can be calculated so that the machine learning entropy estimation can be compared to the theoretical value. Nevertheless, while the data generated in [
18] come from an oscillator-based model and Markov processes of order at most 2, our data come from generalized binary autoregressive models [
20], a subclass of Markov chains that allows us to easily parameterize correlations and anticorrelations at the bit level and compute min-entropies.
Our research also investigates the influence of the number of target bits on the estimation of min-entropy. We demonstrate that the relationship between average min-entropy and min-entropy is significantly affected by the number of target bits predicted. This finding highlights the importance of considering the target bit count when assessing the min-entropy of RNGs using machine learning predictors.
The remainder of this paper is structured as follows.
Section 2 presents a literature review, discussing the current state-of-the-art in the application of predictors for min-entropy estimation. In
Section 3, we establish the theoretical framework, where we study the concept of average min-entropy and its relationship with min-entropy, deriving a series of results for order-p Markov chains and gbAR(p).
Section 4 outlines our experimental methodology that aims to validate the theoretical findings.
Section 5 presents the results of our experiments, followed by
Section 6, which offers a discussion of these results and their implications. Finally,
Section 7 concludes the paper with a summary of our findings and suggestions for future research.
Notation and Conventions
The following notation and conventions will be considered throughout this paper:
Random variables: Uppercase letters represent random variables, while their corresponding realizations are represented by lowercase letters , and by abusing the notation, will be denoted by . Furthermore, by , we mean that X is a random variable that follows a binomial distribution with number of trials n and a success probability p, and by , we mean that is a multivariate random variable that follows a multinomial distribution with number of trials n and probability vector .
Expected values: The notation
is used to indicate expected values. Given discrete random variables
where
, and
are nonnegative, we will be particularly interested in the following type of expression:
Logarithms: All logarithmic functions are considered to be base 2 and are denoted by log.
4. Experimental Methodology
In this section, we outline the experimental methodology that has been carried out, which is primarily based on code implementations. Our main goal is to validate our theoretical findings, for which we generate correlated data using gbAR(p) models (see Definition 7).
Building upon Kelsey’s predictor concept [
17], we use machine learning as a tool for the estimation of the min-entropy. Our methodology adopts the traditional machine learning approach, marked by separate training and evaluation phases. This strategy deviates from Kelsey’s model of continuous updates, which we consider a non-essential aspect of predictor concepts for min-entropy evaluation. Thus, our methodology, termed machine learning predictors, streamlines the process by clearly separating these stages, focusing on essential predictive capabilities without the need for constant updates.
Contrasting with the approach in [
11], which examines processes failing randomness due to large periods, we focus on processes with shorter range, bit-level correlations since such correlations could be more similar to the realistic failure modes of physical and hardware-based RNGs, in line with the use of order-
k or order-2 Markov chains in [
17] and [
18], respectively. Physical implementations inherently exhibit such behavior: sampling and holding operations introduce memory effects through exponentially decaying autocorrelation functions [
40], while detector characteristics like dead time and afterpulsing create similar temporal correlations between successive bits [
41]. Given this requirement for modeling realistic RNG failures with shorter-range dependencies, gbAR(p) models provide a parsimonious parameterization that allows us to control correlations and anti-correlations, making them a suitable choice for our analysis.
These data serve as the training set for two different types of neural networks, which are tasked with predicting the next
target_bits bits. As highlighted in the theory section (Remark 3 and
Figure 2), order-1 Markov chains may present trivial cases where min-entropy and average min-entropy match. Therefore, it is important to analyze the behavior of our predictors in scenarios where this equivalence does not hold, which is the basis of our experimental approach.
All experiments were performed on an AMD EPYC 9354P 32-Core Processor (Advanced Micro Devices Inc., Santa Clara, CA, USA) (3.24 GHz) running under KVM virtualization on Debian GNU/Linux 11 (bullseye) with Linux kernel 5.10.0-32-amd64. The system includes an NVIDIA GeForce RTX 3090 GPU (NVIDIA Corporation, Santa Clara, CA, USA) with 24.576 GiB of memory running CUDA version 12.3.
The experimental framework can be structured around four primary components: the data generation process using the gbAR(p) model, the Monte Carlo simulation for the evaluation of minimum entropies, the implementation of machine learning model training and evaluation, specifically GPT-2 and a variation of RCNN (a model taken from [
11]), and the integration of all data processing steps. This pipeline encompasses the generation of gbAR(p) data, its evaluation using the NIST SP 800-90B test suite, the execution of machine learning predictions and the compilation of relevant results.
For detailed documentation on code usage, parameter explanations, and additional technical details, refer to
README.md file in the associated code repository [
42].
4.1. Data Generation
Data generation is an implementation of the gbAR(p) model (Definition 6) in the gbAR() function. The call to this function is wrapped in the function generate_gbAR_random_bytes(), which leverages different autocorrelation functions, namely, point-to-point, uniform (all the components being equal), exponential, and Gaussian, to define the autocorrelation pattern through the parameter (as defined in Definition 6).
It computes binary sequences by considering the autocorrelation defined by
and the (here always uniform) random noise term (weighted by
), sourced from OpenSSL’s
RAND_bytes() function, which generates bytes using a cryptographically secure pseudo random generator (CSPRNG). Running on Linux, this CSPRNG draws its entropy from the kernel’s entropy pool (/dev/urandom) [
43]. The same CSPRNG is employed in the
ossl_rand_mn_rvs() function to generate samples from a multinomial distribution as required by the gbAR(p) model. These samples are then used to construct the final binary sequence according to the autocorrelation characteristics defined by the model parameters.
The gbAR() function includes a mechanism that discards an initial segment (here with size bytes) of the generated binary sequence. The rationale behind this is to allow the sequence to reach a state of statistical stationarity, thereby minimizing the initial transient effects introduced in the generation.
4.2. Min-Entropy Calculation
In our approach to numerically evaluate the average min-entropy and min-entropy of the gbAR(p) processes, we employ a Monte Carlo simulation. This involves creating a program that generates 100 samples, each comprising bytes. These samples are used to empirically estimate the joint frequencies. The computed frequencies form the basis for calculating both the min-entropy and the average min-entropy (using the known transition probabilities specific to the gbAR(p) processes).
4.3. Machine Learning Predictors
In this work, we use two distinct machine learning models to tackle the task of predicting binary sequences. The first model is an adaptation of the RCNN, while the second model is based on the GPT-2 architecture.
The selection of the RCNN and GPT-2 architectures is driven by our goal to explore prediction capabilities on binary sequences generated from autoregressive models with short-range correlations. The RCNN, as used by Truong et al., has proven effective in detecting correlations in quantum random number generators under deterministic classical noise influence. Its convolutional and recurrent layers are well suited to capture local patterns and short-term dependencies. In contrast, the transformer-based GPT-2 model, with its self-attention mechanism, offers a different approach. Although originally designed for natural language processing, we adapt it to our binary sequence prediction task to examine how it captures order-p Markov chain characteristics. Using these two models enables us to validate the theoretical finding that machine learning predictors tend to estimate average min-entropy independently of architecture, provided they can learn from the data’s correlations.
4.3.1. Target Space Representation and Inference Strategies
As discussed in
Section 2.2, there are various approaches for multi-token prediction in language models. Although recent work such as Gloeckle et al. [
34], Stern et al. [
35], and Cai et al. [
36] has shown promising results in natural language processing tasks, our research focuses on a different domain. We aim to explore the relationship between model predictions and the min-entropy of the data, specifically for data with different correlations, rather than natural language.
To address the limitations of autoregressive inference strategies that rely on local decisions at each step, we propose directly predicting the entire sequence of n bits simultaneously. This approach allows us to obtain the global maximum probability for the complete sequence from the model, rather than relying on step-by-step decisions. By doing so, we aim to capture long-range dependencies and avoid the potential pitfalls of greedy, beam search, or other methods in finding globally optimal sequences.
Our method involves using different tokenization strategies for input and target spaces:
Input space: We use binary tokenization where each token represents a single bit (0 or 1).
Output space: We employ a tokenization where each token represents n bits, resulting in unique classes.
This tokenization approach allows the model to predict groups of bits as single tokens, considering the joint probability of the entire sequence. We believe that this method will lead to more accurate and globally optimal predictions, as it forces the model to consider the interdependencies between bits in the sequence.
4.3.2. Model Training and Evaluation Methodology
Our training dataset consists of sequences generated from the gbAR(p) model. From these sequences, we extract subsequences of length bits. Both models are adapted to classify over classes, corresponding to all possible sequences of n bits. In this context, each possible combination of is treated as a distinct class in the classification task.
We evaluate the model prediction accuracy
as
Here,
represents the number of correct predictions made by the model and
denotes the total number of evaluations conducted. This measure of accuracy serves as a key indicator of the model’s performance and its ability to accurately predict future bits based on the training received. The estimated min-entropy will be
We obtain a basic approximation of the error using the Wald approximation for the binomial proportion confidence interval, as outlined in [
44]. The propagation of this error yields
where
is the number of evaluation sequences and
z is the
quantile of a standard normal distribution (1.96 for 95% confidence level).
In addition to accuracy, to assess the performance of the training procedure during the development phase, we have included the evaluation of the binary entropy of the predictions, , the proportion of zeros in the prediction, , and the loss.
4.3.3. RCNN Model
We use a model based on the RCNN model from the framework presented in [
11]. The original implementation combines convolutional and LSTM layers followed by fully connected layers. Initially, input integers are converted into one-hot vectors. These vectors are then processed through convolutional layers with max-pooling to extract features, which are subsequently handled by the LSTM layer to capture temporal dependencies.
Our adaptation transitions from byte-based input processing to bit sequence handling, accommodating classification over a fixed number of classes, where n is the number of target_bits. This aligns with the original design intended for classification over fixed classes. The architecture employs an output layer with neurons and softmax activation, allowing multiclass classification. The categorical cross-entropy loss function is used for training. We use the RMSprop optimizer with a learning rate of 0.005.
Regarding the model architecture, we have slightly modified Truong’s model to increase its size, including
Convolution1D layers with 32, 64, and 128 filters and kernel sizes of 12, 6, and 3 respectively, all using ‘relu’ activation and ‘same’ padding.
LSTM layers with 256 and 128 units, featuring return sequences and dropout layers with a rate of 0.2 for regularization.
A final dense layer with an output size equal to target_bits, using sigmoid activation.
This model architecture results in approximately trainable parameters.
4.3.4. GPT-2 Model
The GPT-2 model, referenced in [
23], is adapted from its typical use in natural language processing, as provided by the hugging face transformers library [
45]. This adaptation restructures the traditional classification model over the possible
classes for the next
n target_bits.
For processing binary sequences, we implement a custom BinaryDataset class. Each data entry in this dataset consists of a binary bit sequence with a length defined by the seqlen parameter. This setup facilitates the mapping of each bit in the input sequence to the next target_bits, aligning with the classification framework.
In terms of the model architecture for the adapted GPT-2, the vocabulary size is set to , aligned with the number of classes in our classification framework. The specific configuration of the model includes parameters such as n_positions=512, n_ctx=512, n_embd=768, n_layer=3, and n_head=3. This configuration leads to the GPT-2 model having trainable parameters.
For the training phase, we use the RMSprop optimizer with a learning rate of 0.0005. The CrossEntropyLoss loss function is chosen as the loss function.
We incorporate gradient scaling and accumulation in our training approach to enhance memory optimization and computational efficiency, especially important under constrained GPU availability.
4.4. Pipeline
We encapsulate in a pipeline the entire data processing for this work, from generating random numbers to saving results.
For each selection of input parameters, the method generates random bytes using the previously described gbAR(p) model. These bytes are saved to a file that is later used in the data generators within the models to train and evaluate the models. We generate new gbAR(p) sequences for each run to ensure data variability and robustness.
The pipeline runs the NIST SP 800-90B entropy assessment for non-i.i.d. data in parallel with the model execution over a sample of the generated data (here bytes). We use the -a flag to analyze the complete dataset.
After the analysis, we meticulously compile various results, including entropy assessments, model parameters, values, execution time, and more, into a CSV file.
5. Results
Our primary objective is to investigate the relationship between the estimated min-entropy and the number of
target_bits. To facilitate this analysis, we focus on low-entropy data for several reasons. Firstly, it ensures that models can effectively learn and capture the underlying patterns. Secondly, it improves the distinction between model predictions and inherent noise, allowing for more robust statistical analysis. In high entropy scenarios (characterized by small
values), the entropy per bit approaches 1, resembling uniform noise (see
Figure 2). This proximity to maximum entropy poses challenges in assessing model performance due to overlapping confidence intervals. These intervals often encompass both the maximum entropy value of 1 and the expected theoretical value, which is also close to 1. Consequently, a large number of evaluations would be required to reduce measurement uncertainty and achieve statistical distinguishability. To address these challenges, we employ a generalized binary autoregressive model of order
with a uniform
vector and a uniform noise term
. This configuration provides a balance between learnable patterns and stochastic noise, enabling effective extraction of the
target_bits dependence while maintaining statistical significance in our results.
The training data for both the GPT-2 and RCNN models varied based on the number of target bits to be predicted. For tasks involving 1 to 12 target bits, 20 million bytes of raw data were used, equivalent to 125,000 128 bit training sequences each. This increased to 30 million bytes (187,499 sequences) for 13 to 15 target bits, and further to 42 million bytes (262,499 sequences) for 16 target bits. In each case, 80% of the available data was allocated for training, with the remaining 20% reserved for evaluation.
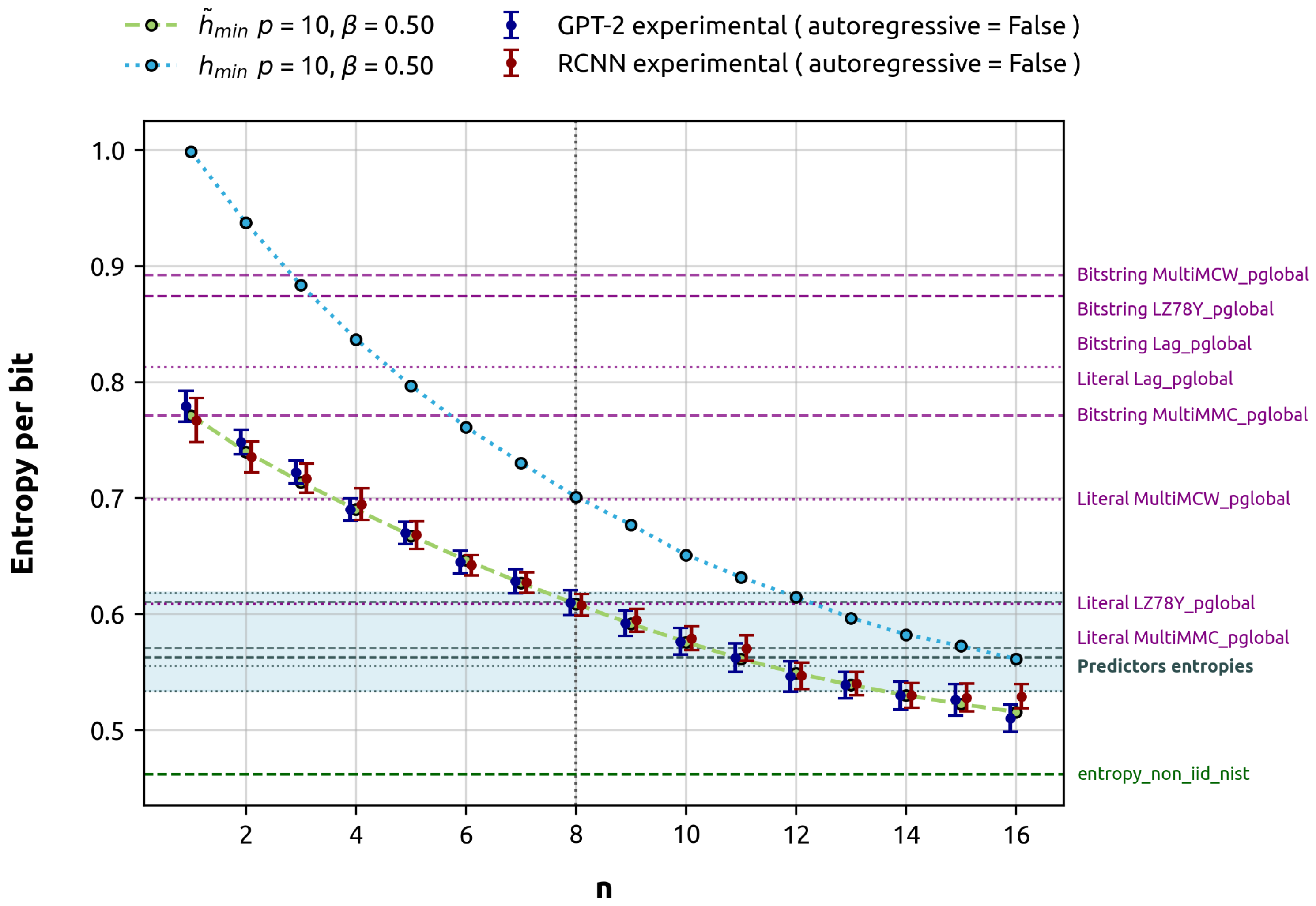
Our primary objective is to compare the min-entropy estimated by these models against the theoretical calculations and the estimations provided by the NIST SP 800-90B predictors and its overall entropy assessment. The results of these experiments are presented in
Figure 4.
Finally, for illustration purposes, we demonstrate how greedy decoding fails to accurately estimate the min-entropy in data with certain types of correlations. This experiment used 20 million bytes of data, equivalent to 125,000 sequences of 128 bits each. Following our standard protocol, 80% (100,000 sequences) were used for training, and 20% (25,000 sequences) for evaluation. In this case, we focus on predicting 1 to 8 target bits. For comparison, we used two gbAR(2) models with alpha vectors
and
. In the case with alternating correlation signs, the global maximum probability cannot be split as the product of the local maximums, so greedy decoding leads to suboptimal predictions compared to inference over
classes. In the first case (
), the global maximum can be reached as the product of local maximums at each bit (see Remark A2), so both approaches match. This comparison illustrates how the greedy approach may lead to suboptimal predictions, as it does not consider the joint probability of the complete sequence in all cases. The results of this analysis are illustrated in
Figure 5, highlighting how the greedy decoding strategy can fall short in accurately estimating min-entropy under certain correlation conditions, while performing adequately in others.
6. Discussion
Our work builds on Kelsey’s definition of predictors [
17], showing that these predictors effectively estimate the average min-entropy as long as they can harness correlations and effectively model conditional probabilities, rather than joint. This distinction becomes significant when dealing with stochastic processes with complex correlation structures.
While our theoretical framework was developed for order-p Markov and gbAR(p) models, the ability of machine learning predictors to estimate average min-entropy is more general. This is because these models inherently approximate conditional probabilities and, when we evaluate prediction accuracy by selecting the most likely output, we are taking the maximum of these approximated conditional probabilities. When this is carried out over several evaluation runs on random samples, their prediction accuracy naturally computes an average of these maximum conditional probabilities—exactly the quantity appearing in the average min-entropy definition. Therefore, while NIST predictors are designed for broad coverage of potential randomness deviations, our machine learning approach can effectively capture any type of correlation structure that manifests itself in predictable patterns, not just those arising from Markov processes.
We show that while min-entropy varies with the number of bits considered, defining min-entropy per bit for the entire process is still possible. Lemma 1 establishes that the average min-entropy per bit is always lower than or equal to the min-entropy for order-p Markov chains. Although generally distinct, in specific cases (Theorem 2), both joint min-entropy and average min-entropy converge towards a process-wide min-entropy per bit. Interestingly, different states may exhibit varied decay laws despite this common limit (
Figure 3), which is operationally significant when attackers have access to correlated data.
Figure 2 illustrates the interplay between correlation ‘width’ and ‘length’ in how average min-entropy approaches the min-entropy limit. This aligns with Remark 3, where average min-entropy per bit equals the min-entropy of uniform noise gbAR(p) models with point-to-point lag-
p correlations, regardless of
target_bits,
p, and
values.
As we approach high-entropy limits, all entropy forms converge to the process limit, consistent across various alpha levels for the considered gbAR(p) models. This reaffirms that min-entropy consistently exceeds average min-entropy, as per Lemma 1.
Figure 4 shows that our min-entropy estimations from both models align with the average min-entropy and stay within the error interval. Interestingly, the NIST Bitstring global predictors, designed to estimate the entropy of 1 target bit, generally overestimate the average min-entropy for 1 target bit, with the notable exception of the MultiMMC predictor. For 8
target_bits, the NIST global predictors, specifically MultiMCW and Lag, tend to overestimate the average min-entropy. However, LZ78Y and MultiMMC show results that are close to the theoretical calculation. It is important to note that NIST predictors are not designed to estimate entropy in the large
n limit. In the particular case studied, where the min-entropy continues to decay beyond
, it is not surprising that the GPT-2 predictor provides a lower estimate in the
run. This estimate is compatible with the theoretically expected value and, moreover, does not overlap with the gray area representing the minimum between the local and global estimates. Consequently, the GPT-2 predictor’s estimate is closer to the min-entropy of the stochastic process, making it a better and more conservative estimation.
Local predictions consistently dominate the min-entropy estimate across all cases. As a result, the overall outcome of the predictor is determined by the local estimate, since the final entropy estimate is the lesser of the local and global predictions. Local predictions fall within the theoretical min-entropy for the 9–14 target_bits range and are significantly higher than the min-entropy limit of the process. The overall result of the NIST’s entropy non-IID test, which is the minimum of all tests in the suite, including both predictors and non-predictors, is closer to the min-entropy limit. In this specific scenario, predictors do not significantly contribute to the overall test.
Our analysis of greedy decoding versus direct prediction (
Figure 5) reveals limitations in autoregressive inference approaches. For certain correlation structures (e.g., gbAR(2) with
), greedy decoding fails to capture global maximum probability. This underscores the importance of multi-token prediction for accurately estimating min-entropy in complex correlation structures. Single-token or greedy approaches may lead to suboptimal predictions and min-entropy overestimation, emphasizing the need for methods capturing joint probabilities over multiple tokens.
In conclusion, our machine learning predictors demonstrate more consistent performance compared to NIST SP 800-90B in estimating the average min-entropy for both 1 and 8 target_bits in low entropy scenarios, while also providing robust estimates for larger values of n. This superior performance can be attributed, in part, to the nonparametric nature of ML min-entropy estimation. Unlike traditional methods that often assume specific underlying distributions, ML approaches allow for flexible modeling, making them particularly powerful in capturing complex, nonlinear dependencies in the data. This flexibility is especially valuable when dealing with stochastic processes exhibiting intricate correlation structures, as it enables the model to adapt to the data’s inherent patterns without being constrained by predetermined statistical assumptions.
High-entropy scenarios present additional challenges, which could require larger training runs and models. Augmenting target bits offers improved capture of long-range correlations but at a significant computational cost. As Equation (
33) indicates, maintaining constant error rates with increasing target bits requires exponential growth in the evaluations, such as
in high entropy limits. This accuracy–computation trade-off necessitates careful balancing of long-range correlation capture and practical computational requirements. Future research should focus on developing efficient algorithms or approximation methods to handle larger target bits without prohibitive computational costs, addressing the challenges of multi-token prediction, autoregressive inference limitations, and target bit scaling in entropy estimation.
7. Conclusions
Our research has revealed several key insights into the estimation of the min-entropy. We have shown that machine learning predictors are good at estimating average min-entropy, as long as they effectively harness correlations by estimating conditional probabilities. This becomes particularly significant in stochastic processes with complex correlation structures, where the difference between average min-entropy and min-entropy is relevant.
Our results show that both entropies depend on the number of target_bits considered. Given this important role of target_bits, especially in scenarios with complex correlation structures, it may be operationally significant to include assessments of both average min-entropy and min-entropy for specific target_bits values relevant to cryptographic (or other) scenarios. Importantly, in the examples studied, we observed that as average min-entropy decays with increasing target_bits, targeting only a few bits could lead to an overestimate of the min-entropy. This finding underscores the potential risks of relying on limited-scope entropy estimates in cryptographic applications. While defining min-entropy per bit for the entire process is feasible, and the entropies studied here converge towards this limit (suggesting a lower bound or worst-case scenario), this bound has not been explicitly demonstrated in this work. Therefore, the development of effective methods to estimate this limit remains essential.
We have also found that machine learning predictors can beat NIST SP 800-90B’s predictors estimates in some cases, making them suitable tools to be included in entropy assessment suites.
Our research leaves several avenues open for exploration that may be of particular interest in further studies:
Development of computationally efficient methods for estimating min-entropy in large target_bits and high-entropy scenarios where the number of evaluations required to maintain statistical significance grows exponentially with the number of target_bits.
Validation on diverse real-world RNG data sources, with particular emphasis on high-entropy scenarios that present both computational and measurement challenges.
Exploration of the relationship between the min-entropy of the training data, the size of the model, and the size of the training data necessary for accurate estimation of the min-entropy. This investigation goes beyond aligning the prediction accuracy of the model with the theoretical curves; it aims to provide a deeper understanding of the model learning capacity at various entropy levels. This knowledge could inform the appropriate scaling of computational resources and potentially offer improved estimates by considering theoretical bounds on min-entropy estimation.
In conclusion, while our work has advanced the understanding of min-entropy estimation through machine learning, it also highlights the practical complexity of this method and the need for more research to address its challenges.


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}