


The Epistemic Uncertainty Gradient in Spaces of Random Projections


Abstract
1. Introduction
2. Preliminaries
2.1. The Epistemic Uncertainty
2.2. The Mahalanobis Distance
3. Method
3.1. The Feature Space Transformation
3.2. The Epistemic Gradient
3.3. Geometric Interpretation
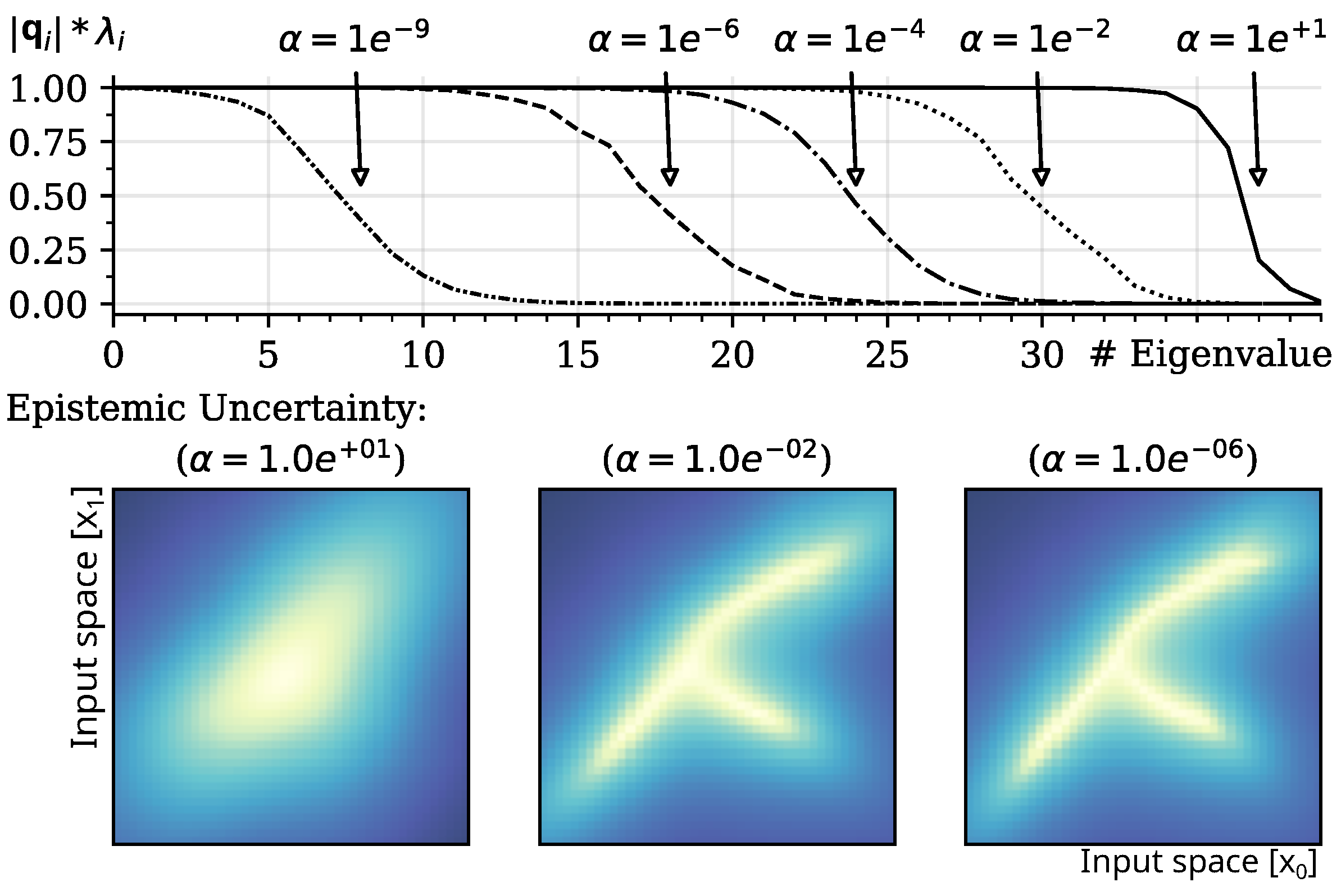
3.4. Parameterization of Prior
3.5. Method Application
3.5.1. The Auto-Associative Case
3.5.2. The Regression Case
3.6. Extended Method Applications
3.6.1. Local Gaussian Approximation
3.6.2. Unlearning
3.7. Summary of Method Application
4. Experiments and Evaluation
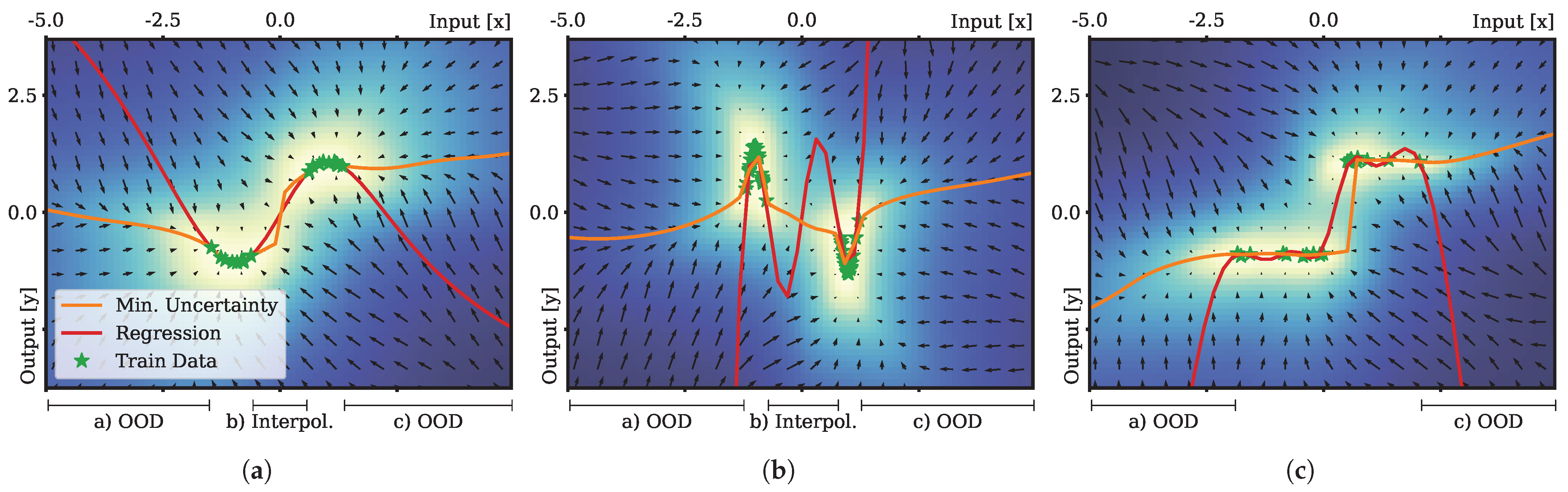
4.1. Regression
- Results:
4.2. Novelty and Outlier Detection
- Results:
4.3. Local Covariance Approximation
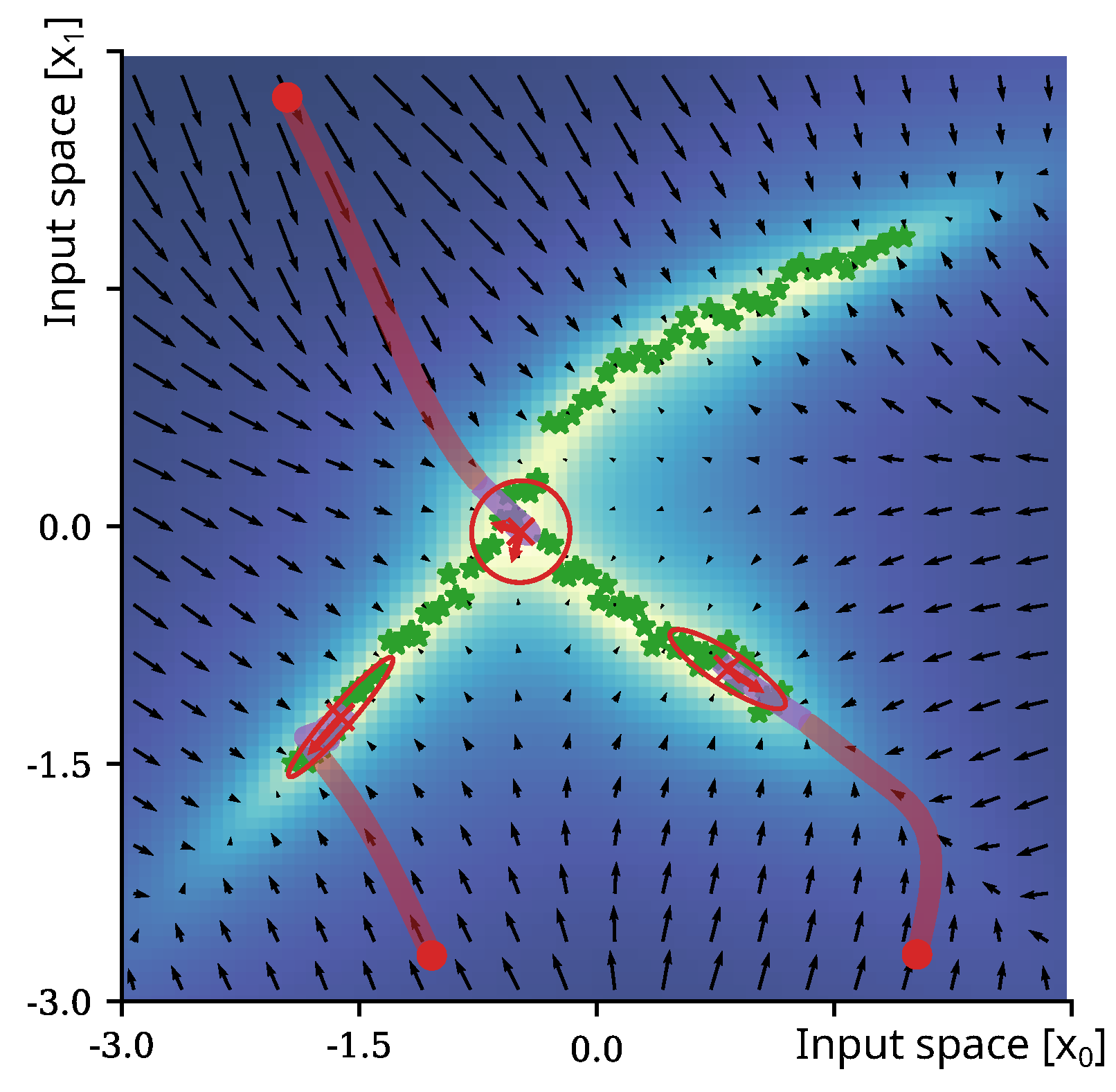
- Cluster Discovery:
- Probabilistic Trajectory Generation:
- Results:
4.4. Unlearning in Case of Noise
- Results:
5. Discussion and Conclusions
Outlook
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Implementation—Specific Details: Derivation of Epistemic Uncertainty
Appendix B. Implementation—Specific Details: The Hessian of the Epistemic Uncertainty
Appendix C. Implementation—Specific Details: Model Details
| Algorithm A1: Representation of training set , i.e., estimation of , given hyperparameter and . |
 |
| Algorithm A2: Query learned data distribution represented in on new data sample . Perform N minimization steps of the epistemic uncertainty before returning final estimate and the epistemic uncertainty . |
 |
Appendix D. Implementation—Specific Details: Iterative Approach to Unlearning
| Algorithm A3: Iterative unlearning procedure. |
 |
References
- Hüllermeier, E.; Waegeman, W. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Mach. Learn. 2021, 110, 457–506. [Google Scholar] [CrossRef]
- Hacking, I. Chap. 2. Duality. In The Emergence of Probability: A Philosophical Study of Early Ideas About Probability, Induction and Statistical Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2006; pp. 11–17. [Google Scholar] [CrossRef]
- Hora, S.C. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management. Reliab. Eng. Syst. Saf. 1996, 54, 217–223. [Google Scholar] [CrossRef]
- Kiureghian, A.D.; Ditlevsen, O. Aleatory or epistemic? Does it matter? Struct. Saf. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Senge, R.; Bösner, S.; Dembczyński, K.; Haasenritter, J.; Hirsch, O.; Donner-Banzhoff, N.; Hüllermeier, E. Reliable classification: Learning classifiers that distinguish aleatoric and epistemic uncertainty. Inf. Sci. 2014, 255, 16–29. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What uncertainties do we need in Bayesian deep learning for computer vision? In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; NIPS’17. pp. 5580–5590. [Google Scholar]
- Becker, A.; Liebig, T. Evaluating Machine Unlearning via Epistemic Uncertainty. arXiv 2022, arXiv:2208.10836. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Information science and statistics; Springer: Berlin/Heidelberg, Germany, 2006; Chapter Graphical; Volume 4, p. 738. [Google Scholar] [CrossRef]
- Pao, Y.H.; Takefuji, Y. Functional-link net computing: Theory, system architecture, and functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Valdenegro-Toro, M.; Mori, D.S. A Deeper Look into Aleatoric and Epistemic Uncertainty Disentanglement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Los Alamitos, CA, USA, 19–20 June 2022; pp. 1508–1516. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Learning Confidence for Out-of-Distribution Detection in Neural Networks. arXiv 2018, arXiv:1802.04865. [Google Scholar] [CrossRef]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2018; Volume 31. [Google Scholar]
- Malinin, A.; Gales, M. Predictive Uncertainty Estimation via Prior Networks. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2018; Volume 31. [Google Scholar]
- Sensoy, M.; Kaplan, L.; Kandemir, M. Evidential Deep Learning to Quantify Classification Uncertainty. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2018; Volume 31. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. (Methodol.) 1977, 39, 1–38. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Sato, A.; Yamada, K. Generalized Learning Vector Quantization. In Advances in Neural Information Processing Systems; Touretzky, D., Mozer, M., Hasselmo, M., Eds.; MIT Press: Cambridge, MA, USA, 1995; Volume 8. [Google Scholar]
- Williams, C.; Rasmussen, C. Gaussian Processes for Regression. In Advances in Neural Information Processing Systems; Touretzky, D., Mozer, M., Hasselmo, M., Eds.; MIT Press: Cambridge, MA, USA, 1995; Volume 8. [Google Scholar]
- Maass, W.; Natschläger, T.; Markram, H. Real-time computing without stable states: A new framework for neural computation based on perturbations. Neural Comput. 2002, 14, 2531–2560. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, H. Adaptive Nonlinear System Identification with Echo State Networks. In Advances in Neural Information Processing Systems; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2002; Volume 15. [Google Scholar]
- Steil, J.J. Backpropagation-decorrelation: Online recurrent learning with O (N) complexity. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 2, pp. 843–848. [Google Scholar]
- Steil, J.J. Online reservoir adaptation by intrinsic plasticity for backpropagation–decorrelation and echo state learning. Neural Netw. 2007, 20, 353–364. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, W.; Kraaijveld, M.; Duin, R. Feedforward neural networks with random weights. In Proceedings of the 11th IAPR International Conference on Pattern Recognition. Vol.II. Conference B: Pattern Recognition Methodology and Systems, The Hague, The Netherlands, 30 August–3 September 1992; pp. 1–4. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No.04CH37541), Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar] [CrossRef]
- Neumann, K.; Emmerich, C.; Steil, J.J. Regularization by intrinsic plasticity and its synergies with recurrence for random projection methods. J. Intell. Learn. Syst. Appl. 2012, 4, 230–246. [Google Scholar] [CrossRef]
- Amari, S.I. Learning Patterns and Pattern Sequences by Self-Organizing Nets of Threshold Elements. IEEE Trans. Comput. 1972, C-21, 1197–1206. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef]
- Ritter, H.; Schulten, K. Extending Kohonen’s self-organizing mapping algorithm to learn ballistic movements. In Neural Computers; Springer: Berlin/Heidelberg, Germany, 1987; pp. 393–406. [Google Scholar]
- Walter, J.; Ritter, H. Rapid learning with parametrized self-organizing maps. Neurocomputing 1996, 12, 131–153. [Google Scholar] [CrossRef]
- Barhen, J.; Gulati, S.; Zak, M. Neutral learning of constrained nonlinear transformations. Computer 1989, 22, 67–76. [Google Scholar] [CrossRef]
- Reinhart, R.F.; Steil, J.J. Efficient policy search in low-dimensional embedding spaces by generalizing motion primitives with a parameterized skill memory. Auton. Robot. 2015, 38, 331–348. [Google Scholar] [CrossRef]
- Yuen, K.V. Appendix A: Relationship between the Hessian and Covariance Matrix for Gaussian Random Variables. In Bayesian Methods for Structural Dynamics and Civil Engineering; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2010; pp. 257–262. [Google Scholar] [CrossRef]
- Efron, B.; Hinkley, D.V. Assessing the Accuracy of the Maximum Likelihood Estimator: Observed Versus Expected Fisher Information. Biometrika 1978, 65, 457–482. [Google Scholar] [CrossRef]
- Nguyen, Q.P.; Kian, B.; Low, H.; Jaillet, P. Variational Bayesian Unlearning. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 6–12 December 2020. NIPS’20. [Google Scholar]
- Rawat, A.; Requeima, J.; Bruinsma, W.P.; Turner, R.E. Challenges and Pitfalls of Bayesian Unlearning. arXiv 2022, arXiv:2207.03227. [Google Scholar] [CrossRef]
- Fletcher, R. Practical Methods of Optimization; Number v. 2 in a Wiley-Interscience Publication; Wiley: Hoboken, NJ, USA, 1987. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Hu, X.; Huang, H.; Jiang, M.; Zhao, Y. ADBench: Anomaly Detection Benchmark. In Proceedings of the Neural Information Processing Systems (NeurIPS), New Orleans, LO, USA, 28 November 2022. [Google Scholar]
- Reinhart, R.F.; Steil, J.J. Neural learning and dynamical selection of redundant solutions for inverse kinematic control. In Proceedings of the 2011 11th IEEE-RAS International Conference on Humanoid Robots, Bled, Slovenia, 26–28 October 2011; pp. 564–569. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: San Jose, CA, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Parameterization | |||
|---|---|---|---|
| Dims | |||
| Exp. 1 | 80 | ||
| Exp. 2 | 120 | ||
| Exp. 3 | 200 | ||
| IForest | KNN | PCA | KPCA | GMM | Ours | |
|---|---|---|---|---|---|---|
| Cardio | ||||||
| BreastW | ||||||
| Glass | ||||||
| Speech | ||||||
| Landsat | ||||||
| Hepatitis | ||||||
| Stamps | ||||||
| Thyroid | ||||||
| Vertebral | ||||||
| Yeast |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Queißer, J.F.; Tani, J.; Steil, J.J. The Epistemic Uncertainty Gradient in Spaces of Random Projections. Entropy 2025, 27, 144. https://doi.org/10.3390/e27020144
Queißer JF, Tani J, Steil JJ. The Epistemic Uncertainty Gradient in Spaces of Random Projections. Entropy. 2025; 27(2):144. https://doi.org/10.3390/e27020144
Chicago/Turabian StyleQueißer, Jeffrey F., Jun Tani, and Jochen J. Steil. 2025. "The Epistemic Uncertainty Gradient in Spaces of Random Projections" Entropy 27, no. 2: 144. https://doi.org/10.3390/e27020144
APA StyleQueißer, J. F., Tani, J., & Steil, J. J. (2025). The Epistemic Uncertainty Gradient in Spaces of Random Projections. Entropy, 27(2), 144. https://doi.org/10.3390/e27020144