
Mining Suicidal Ideation in Chinese Social Media: A Dual-Channel Deep Learning Model with Information Gain Optimization

 ,
,
Abstract
1. Introduction
- We introduce a novel Chinese dataset derived from Weibo, filling a significant gap in the research area of Chinese-centric data;
- Our proposed DSI-BTCNN model integrates the feature extraction capabilities of two distinct deep learning networks within a dual-channel framework, significantly improving the model’s accuracy in detecting suicidal ideation;
- The study emphasizes the benefits of a parallel multi-kernel architecture, deploying diverse kernel sizes to refine the model’s feature representation capabilities;
- We innovate by incorporating an information gain-based dynamic feature attention fusion network, dynamically modulating the fusion of diverse features. Our experiments demonstrate notable enhancements over baseline models.
2. Related Works
2.1. CNN-Based Detection of Suicidal Ideation
2.2. RNN-Based Detection of Suicidal Ideation
2.3. CNN-RNN Hybrid-Based Detection of Suicidal Ideation
3. Methodology
3.1. Model Detection Pprocedure
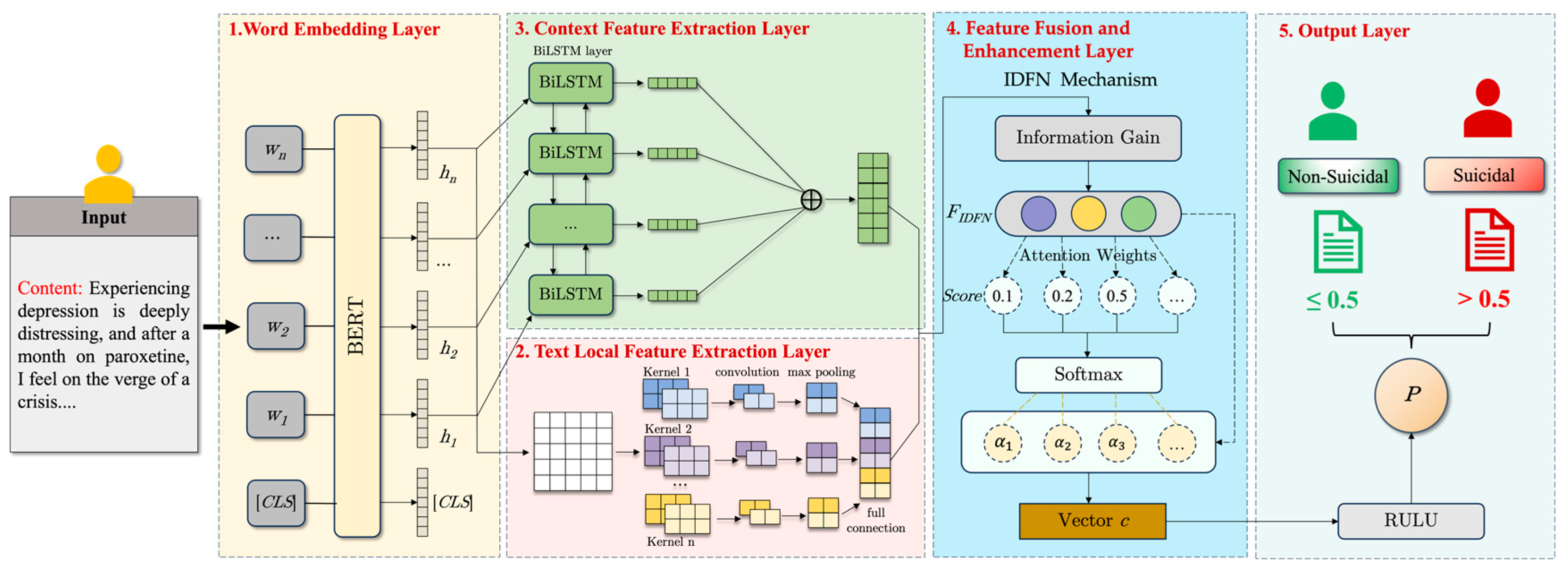
3.2. Model Architecture
- (1)
- Word Embedding Layer: utilizing a pre-trained BERT model, this layer distills contextual features from the microblog corpus, generating word embeddings that enrich the input for subsequent layers;
- (2)
- Text Local Feature Extraction Layer: multiple parallel convolutional kernels of varying sizes operate to extract multi-scale local features, which are concatenated to form a refined feature set;
- (3)
- Context Feature Extraction Layer: comprising two LSTM layers, this component processes sequences in both directions, swiftly grasping sequence dependencies to extract contextual features;
- (4)
- Feature Fusion and Enhancement Layer: This stratum amalgamates features extracted from the preceding layers, employing a bespoke information gain-driven dynamic fusion mechanism to augment the model’s acuity in identifying pivotal elements within microblog texts. Consequently, this refines the articulation of the model’s global feature representation;
- (5)
- Output Layer: Fully connected layers further refine the global features. A final layer with an activation function is employed to produce the model’s output, namely, the probability of suicidal ideation classification, which informs the classification decision.
3.2.1. Word Embedding Layer
3.2.2. Text Local Feature Extraction Layer
3.2.3. Context Feature Extraction Layer
3.2.4. Feature Fusion and Enhancement Layer
3.2.5. Output Layer
4. Datasets
4.1. Data Collection and Annotation
4.2. Data Pre-Processing
- Eliminating HTML tags, URLs, special characters, and emojis to mitigate noise;
- Trimming extraneous whitespace and punctuation and normalizing numerical data;
- Conducting word segmentation to transform text into discrete words or phrases for computational processing;
- Excising microblog-specific characters, such as “Super Topic Influencer”, which are nonsensical in sentiment analysis;
- Discarding microblog entries shorter than five characters, as they convey minimal emotional content post-processing;
- Stripping hashtags that denote microblog topics, e.g., #MyFavoriteHongKongTVSeriesinTVB#;
- Removing @user mentions, as they are irrelevant to the sentiment analysis, such as @Maston;
- Eradicating microblog behavior-related characters, like ‘[reposts]’, which appear in shared content.
5. Experiments
5.1. Experimental Setup
5.2. Baseline
5.2.1. Machine Learning Group
- Support Vector Machine (SVM): we utilize an SVM with an RBF kernel for microblog feature processing, setting parameter C to 0.1 and γ as the inverse of the feature space’s dimensionality;
- Naive Bayes (NB): a multinomial Naive Bayes classifier is utilized, calibrated with a smoothing parameter α of 0.001 to harmonize the smoothing effect with the data’s sparsity within the probabilistic framework;
- Random Forest (RF): constructed with an ensemble of 50 decision trees, and each tree is cultivated via bootstrap sampling.
5.2.2. Deep Learning Group
- (1)
- CNN Subgroup:
- CNN: utilizes varied convolution kernels and max-pooling, with a 100D input vector, ReLU, and Adam for efficient training;
- TextCNN: Capitalizing on the local feature extraction of CNNs, this model utilizes multiple kernel sizes to process text data. We have set 128 convolution kernels across three distinct window sizes, maintaining a 100-dimensional input vector;
- TextRCNN: a hybrid model that amalgamates the strengths of CNNs and RNNs, featuring a three-layer RNN structure with a 100-dimensional input vector.
- (2)
- RNN Subgroup:
- RNN: our RNN model is structured with three layers, each with 100-dimensional input vectors, and employs an SGD-optimized learning rate of 0.001;
- TextRNN: engineered to adeptly manage variable-length text sequences, this model mirrors the RNN structure, also with 100-dimensional input vectors;
- LSTM: equipped with 100-dimensional input vectors, this model allocates 128 LSTM units per layer to strike a balance between complexity and computational efficiency;
- BiLSTM: Enhancing the LSTM with a bidirectional propagation pathway, this model considers both antecedent and subsequent textual information. We configured 128 LSTM units for both the forward and backward components of the BiLSTM, with a 100-dimensional input vector.
5.3. Evaluation Metrics
6. Results
7. Discussion
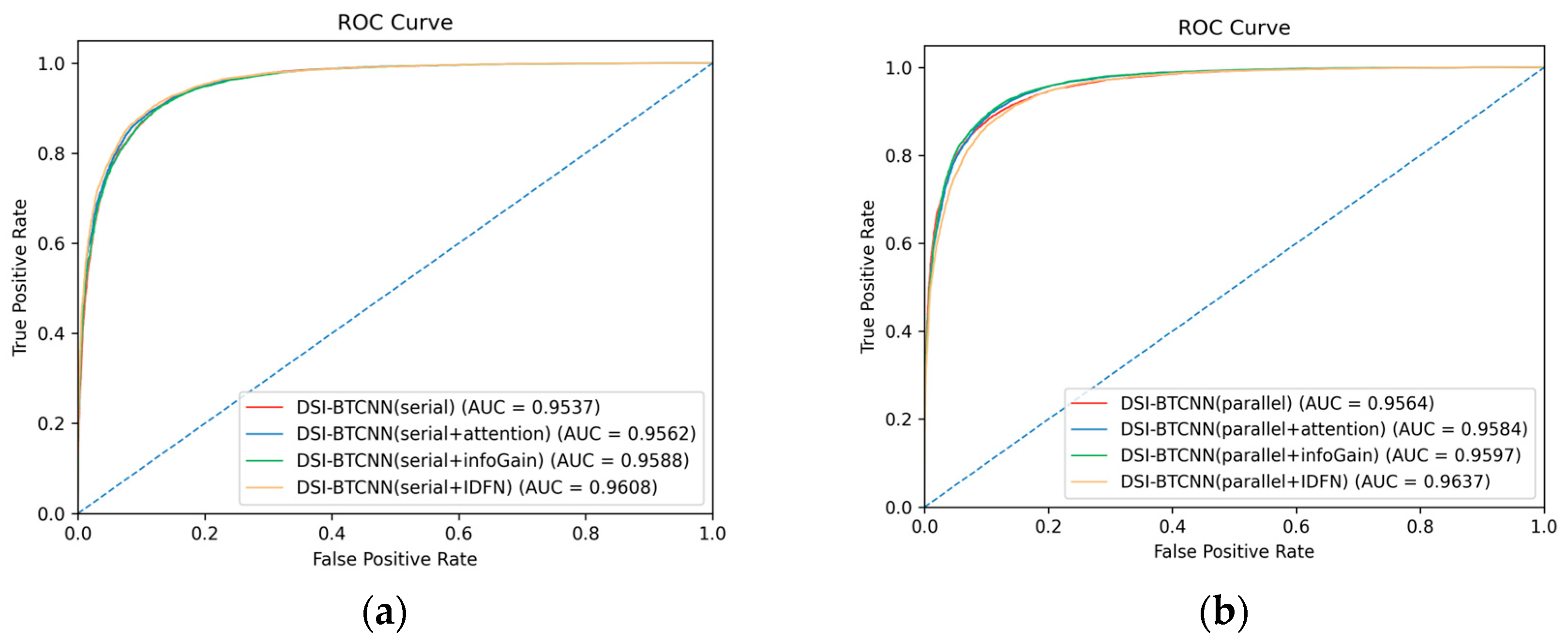
7.1. Effectiveness of the Dual-Channel Architecture
7.2. Advantages of the IDFN Fusion Mechanism
7.3. Efficacy of Parallel Multicore Architectures
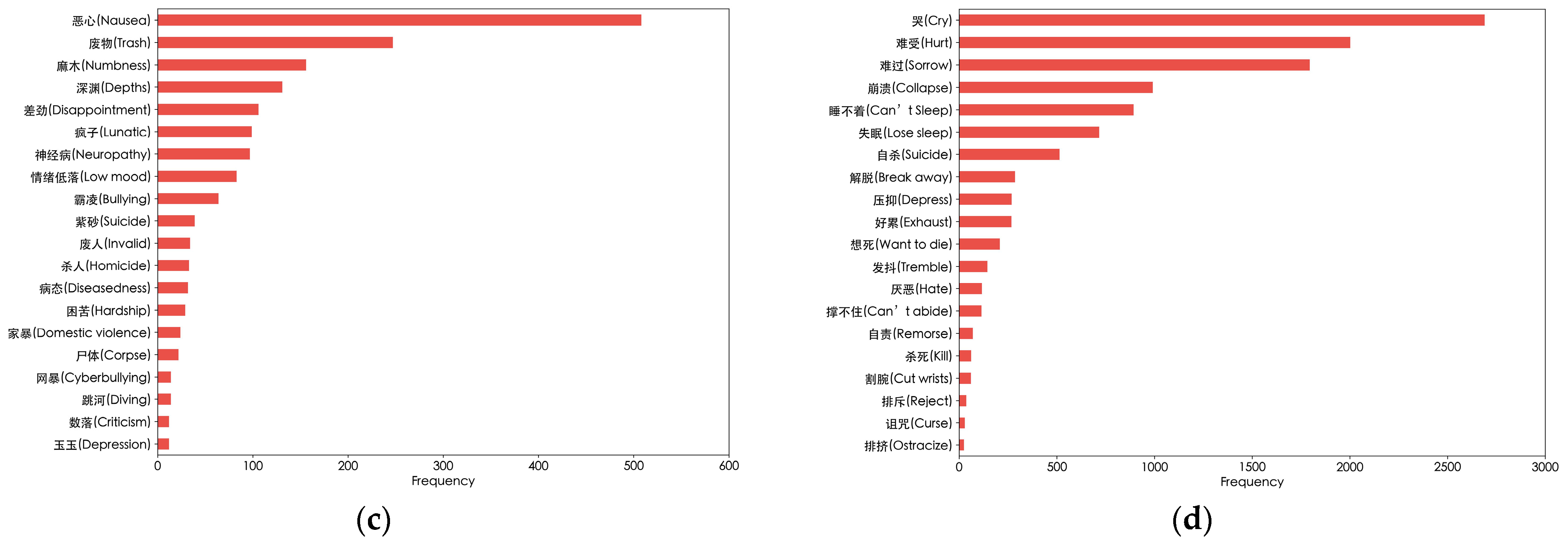
7.4. Word Frequency, Sentiment Analysis and Case Study
7.5. Theoretical Contributions
7.6. Practical Contributions
7.7. Limitations
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Figuerêdo, J.S.L.; Maia, A.L.L.; Calumby, R.T. Early depression detection in social media based on deep learning and underlying emotions. Online Soc. Netw. Media 2022, 31, 100225. [Google Scholar] [CrossRef]
- World Health Organization. World Health Statistics 2024: Monitoring Health for the SDGs, Sustainable Development Goals; World Health Organization: Geneva, Switzerland, 2024.
- World Health Organization. Suicide: Facts and Figures Globally; World Health Organization: Geneva, Switzerland, 2022.
- Wang, Z.; Jin, M.; Lu, Y. High-Precision Detection of Suicidal Ideation on Social Media Using Bi-LSTM and BERT Models. In Proceedings of the International Conference on Cognitive Computing, Shenzhen, China, 17–18 December 2023; pp. 3–18. [Google Scholar]
- Mbarek, A.; Jamoussi, S.; Hamadou, A.B. An across online social networks profile building approach: Application to suicidal ideation detection. Future Gener. Comput. Syst. 2022, 133, 171–183. [Google Scholar] [CrossRef]
- Li, T.M.; Chen, J.; Law, F.O.; Li, C.-T.; Chan, N.Y.; Chan, J.W.; Chau, S.W.; Liu, Y.; Li, S.X.; Zhang, J. Detection of suicidal ideation in clinical interviews for depression using natural language processing and machine learning: Cross-sectional study. JMIR Med. Inform. 2023, 11, e50221. [Google Scholar] [CrossRef]
- Chen, J.; Chan, N.Y.; Li, C.-T.; Chan, J.W.; Liu, Y.; Li, S.X.; Chau, S.W.; Leung, K.S.; Heng, P.-A.; Li, T.M. Multimodal digital assessment of depression with actigraphy and app in Hong Kong Chinese. Transl. Psychiatry 2024, 14, 150. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, J.; An, Z.; Cheng, W.; Hu, B. Deep hierarchical ensemble model for suicide detection on imbalanced social media data. Entropy 2022, 24, 442. [Google Scholar] [CrossRef] [PubMed]
- Sawhney, R.; Joshi, H.; Flek, L.; Shah, R. Phase: Learning emotional Phase-aware representations for suicide ideation detection on social media. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Bangkok, Thailand, 19–23 April 2021; pp. 2415–2428. [Google Scholar]
- Cao, L.; Zhang, H.; Feng, L.; Wei, Z.; Wang, X.; Li, N.; He, X. Latent suicide risk detection on microblog via suicide-oriented word embeddings and layered attention. arXiv 2019, arXiv:1910.12038. [Google Scholar]
- Cao, L.; Zhang, H.; Wang, X.; Feng, L. Learning users inner thoughts and emotion changes for social media based suicide risk detection. IEEE Trans. Affect. Comput. 2021, 14, 1280–1296. [Google Scholar] [CrossRef]
- Orabi, A.H.; Buddhitha, P.; Orabi, M.H.; Inkpen, D. Deep learning for depression detection of twitter users. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, New Orleans, LA, USA, 5 June 2018; pp. 88–97. [Google Scholar]
- Yao, H.; Rashidian, S.; Dong, X.; Duanmu, H.; Rosenthal, R.N.; Wang, F. Detection of suicidality among opioid users on reddit: Machine learning–based approach. J. Med. Internet Res. 2020, 22, e15293. [Google Scholar] [CrossRef]
- Kumar, A.; Trueman, T.E.; Abinesh, A.K. Suicidal risk identification in social media. Procedia Comput. Sci. 2021, 189, 368–373. [Google Scholar]
- Kour, H.; Gupta, M.K. An hybrid deep learning approach for depression prediction from user tweets using feature-rich CNN and bi-directional LSTM. Multimed. Tools Appl. 2022, 81, 23649–23685. [Google Scholar] [CrossRef] [PubMed]
- Allen, K.; Bagroy, S.; Davis, A.; Krishnamurti, T. ConvSent at CLPsych 2019 task A: Using post-level sentiment features for suicide risk prediction on reddit. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; pp. 182–187. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Li, Z.; Cheng, W.; Zhou, J.; An, Z.; Hu, B. Deep learning model with multi-feature fusion and label association for suicide detection. Multimed. Syst. 2023, 29, 2193–2203. [Google Scholar] [CrossRef]
- Alabdulkreem, E. Prediction of depressed Arab women using their tweets. J. Decis. Syst. 2021, 30, 102–117. [Google Scholar] [CrossRef]
- Matero, M.; Idnani, A.; Son, Y.; Giorgi, S.; Vu, H.; Zamani, M.; Limbachiya, P.; Guntuku, S.C.; Schwartz, H.A. Suicide risk assessment with multi-level dual-context language and BERT. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; pp. 39–44. [Google Scholar]
- Kancharapu, R.; SriNagesh, A.; BhanuSridhar, M. Prediction of human suicidal tendency based on social media using recurrent neural networks through lstm. In Proceedings of the 2022 International Conference on Computing, Communication and Power Technology (IC3P), Visakhapatnam, India, 7–8 January 2022; pp. 123–128. [Google Scholar]
- Deepa, J.; Shriraaman, S.; Shruti, V.; Vasanth, G. Detecting and Determining Degree of Suicidal Ideation on Tweets Using LSTM and Machine Learning Models. J. Surv. Fish. Sci. 2023, 10, 3217–3224. [Google Scholar]
- Almars, A.M. Attention-Based Bi-LSTM Model for Arabic Depression Classification. Comput. Mater. Contin. 2022, 71, 3091–3106. [Google Scholar] [CrossRef]
- Kancharapu, R.; A Ayyagari, S.N. A comparative study on word embedding techniques for suicide prediction on COVID-19 tweets using deep learning models. Int. J. Inf. Technol. 2023, 15, 3293–3306. [Google Scholar] [CrossRef]
- Sawhney, R.; Manchanda, P.; Mathur, P.; Shah, R.; Singh, R. Exploring and learning suicidal ideation connotations on social media with deep learning. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October 2018; pp. 167–175. [Google Scholar]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of suicide ideation in social media forums using deep learning. Algorithms 2019, 13, 7. [Google Scholar] [CrossRef]
- Priyamvada, B.; Singhal, S.; Nayyar, A.; Jain, R.; Goel, P.; Rani, M.; Srivastava, M. Stacked CNN-LSTM approach for prediction of suicidal ideation on social media. Multimed. Tools Appl. 2023, 82, 27883–27904. [Google Scholar] [CrossRef]
- Renjith, S.; Abraham, A.; Jyothi, S.B.; Chandran, L.; Thomson, J. An ensemble deep learning technique for detecting suicidal ideation from posts in social media platforms. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 9564–9575. [Google Scholar] [CrossRef]
- Chadha, A.; Kaushik, B. A hybrid deep learning model using grid search and cross-validation for effective classification and prediction of suicidal ideation from social network data. New Gener. Comput. 2022, 40, 889–914. [Google Scholar] [CrossRef]
- Zogan, H.; Razzak, I.; Wang, X.; Jameel, S.; Xu, G. Explainable depression detection with multi-aspect features using a hybrid deep learning model on social media. World Wide Web 2022, 25, 281–304. [Google Scholar] [CrossRef]
- Lv, M.; Li, A.; Liu, T.; Zhu, T. Creating a Chinese suicide dictionary for identifying suicide risk on social media. PeerJ 2015, 3, e1455. [Google Scholar] [CrossRef]
- Meng, X.; Wang, C.; Yang, J.; Li, M.; Zhang, Y.; Wang, L. Predicting Users’ Latent Suicidal Risk in Social Media: An Ensemble Model Based on Social Network Relationships. Comput. Mater. Contin. 2024, 79, 4259–4281. [Google Scholar] [CrossRef]
- Li, W.; Zhu, L.; Shi, Y.; Guo, K.; Cambria, E. User reviews: Sentiment analysis using lexicon integrated two-channel CNN–LSTM family models. Appl. Soft Comput. 2020, 94, 106435. [Google Scholar] [CrossRef]
- Kamyab, M.; Liu, G.; Rasool, A.; Adjeisah, M. ACR-SA: Attention-based deep model through two-channel CNN and Bi-RNN for sentiment analysis. PeerJ Comput. Sci. 2022, 8, e877. [Google Scholar] [CrossRef]
- Liang, S.; Zhu, B.; Zhang, Y.; Cheng, S.; Jin, J. A double channel CNN-LSTM model for text classification. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Cuvu, Fiji, 14–16 December 2020; pp. 1316–1321. [Google Scholar]
- Wang, Q.; Chen, D. Microblog sentiment analysis method using BTCBMA model in Spark big data environment. J. Intell. Syst. 2024, 33, 20230020. [Google Scholar] [CrossRef]
- Zou, S.; Zhang, M.; Zong, X.; Zhou, H. Text Sentiment Analysis Based on BERT-TextCNN-BILSTM. In Proceedings of the International Conference on Computer Engineering and Networks, Haikou, China, 4–7 November 2022; pp. 1293–1301. [Google Scholar]
- Liu, J.; Shi, M.; Jiang, H. Detecting suicidal ideation in social media: An ensemble method based on feature fusion. Int. J. Environ. Res. Public Health 2022, 19, 8197. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhao, B.; Sun, J.; Ge, Q.; Xiao, L.; Wei, F. Suicide Risk Identification Model Based on Microblog Text. Comput. Syst. Appl. 2020, 29, 121–127. [Google Scholar]
- Zhai, N.; Han, G. Research on emotion classification of epidemic public opinion based on BERT dual channel. J. Xiangtan Univ. (Nat. Sci. Ed.) 2022, 43, 173–177. [Google Scholar]
- Aldhyani, T.H.H.; Alsubari, S.N.; Alshebami, A.S.; Alkahtani, H.; Ahmed, Z.A. Detecting and analyzing suicidal ideation on social media using deep learning and machine learning models. Int. J. Environ. Res. Public Health 2022, 19, 12635. [Google Scholar] [CrossRef]
- Zhang, K.; Geng, Y.; Zhao, J.; Liu, J.; Li, W. Sentiment analysis of social media via multimodal feature fusion. Symmetry 2020, 12, 2010. [Google Scholar] [CrossRef]
- Huang, R.; Yi, S.; Chen, J.; Chan, K.Y.; Chan, J.W.Y.; Chan, N.Y.; Li, S.X.; Wing, Y.K.; Li, T.M.H. Exploring the role of first-person singular pronouns in detecting suicidal ideation: A machine learning analysis of clinical transcripts. Behav. Sci. 2024, 14, 225. [Google Scholar] [CrossRef]
- Lyu, S.; Ren, X.; Du, Y.; Zhao, N. Detecting depression of Chinese microblog users via text analysis: Combining Linguistic Inquiry Word Count (LIWC) with culture and suicide related lexicons. Front. Psychiatry 2023, 14, 1121583. [Google Scholar] [CrossRef] [PubMed]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of depression-related posts in reddit social media forum. IEEE Access 2019, 7, 44883–44893. [Google Scholar] [CrossRef]
- De Jesús Titla-Tlatelpa, J.; Ortega-Mendoza, R.M.; Montes-y-Gómez, M.; Villaseñor-Pineda, L. A profile-based sentiment-aware approach for depression detection in social media. EPJ Data Sci. 2021, 10, 54. [Google Scholar] [CrossRef]
- Alvarez-Mon, M.A.; Donat-Vargas, C.; Santoma-Vilaclara, J.; Anta, L.d.; Goena, J.; Sanchez-Bayona, R.; Mora, F.; Ortega, M.A.; Lahera, G.; Rodriguez-Jimenez, R. Assessment of antipsychotic medications on social media: Machine learning study. Front. Psychiatry 2021, 12, 737684. [Google Scholar] [CrossRef] [PubMed]
- Hickman, L.; Thapa, S.; Tay, L.; Cao, M.; Srinivasan, P. Text preprocessing for text mining in organizational research: Review and recommendations. Organ. Res. Methods 2022, 25, 114–146. [Google Scholar] [CrossRef]
- Galamiton, N.; Bacus, S.; Fuentes, N.; Ugang, J.; Villarosa, R.; Wenceslao, C.; Ocampo, L. Predictive Modelling for Sensitive Social Media Contents Using Entropy-FlowSort and Artificial Neural Networks Initialized by Large Language Models. Int. J. Comput. Intell. Syst. 2024, 17, 262. [Google Scholar] [CrossRef]
- Wang, F.; Li, Y. An Auto Question Answering System for Tree Hole Rescue. In Proceedings of the Health Information Science: 9th International Conference, HIS 2020, Amsterdam, The Netherlands, 20–23 October 2020; pp. 15–24. [Google Scholar]
- Silva, L. Suicide among children and adolescents: A warning to accomplish a global imperative. Acta Paul. Enferm. 2019, 32, III–IVI. [Google Scholar] [CrossRef]
- Gui, T.; Zhu, L.; Zhang, Q.; Peng, M.; Zhou, X.; Ding, K.; Chen, Z. Cooperative emultimodal approach to depression detection in twitter. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 110–117. [Google Scholar]
- Ramírez-Cifuentes, D.; Freire, A.; Baeza-Yates, R.; Puntí, J.; Medina-Bravo, P.; Velazquez, D.A.; Gonfaus, J.M.; Gonzàlez, J. Detection of suicidal ideation on social media: Multimodal, relational, and behavioral analysis. J. Med. Internet Res. 2020, 22, e17758. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Paper | Year | Method | Data Source | Language | Word Embedding Technique | Evaluation Metrics | Cons and Pros |
|---|---|---|---|---|---|---|---|---|
| CNN-based method | Orabi et al. [12] | 2018 | MultiChannel CNN | English | Word2Vec | Acc = 0.83 AUC = 0.92 F1 = 0.82 | The method excels in dataset generalization yet struggles with extracting features from extensive texts and subtle contexts. | |
| Allen et al. [16] | 2019 | CNN-LIWC | English | GloVe | Macro F1 = 0.500 | The model’s architecture is commendably efficient, significantly reducing the parameter count required, yet this optimization is effectively constrained to small-scale datasets. | ||
| Yao et al. [13] | 2020 | CNN | English | GloVe FastText | F1 = 0.966 | Leveraging Reddit’s metadata boosts the model’s performance via personalized analysis, but it may also heighten sensitivity to outlier instances. | ||
| Li et al. [18] | 2023 | TCNN-MF-LA | Chinese | Word2Vec | Acc = 0.888 P = 0.906 | A label association mechanism is proposed to integrate diverse features in the face of missing information, but the model’s training demands substantial investment. | ||
| RNN-based method | Alabdulkreem et al. [19] | 2021 | RNN | Arabic | Word2Vec GloVe | Acc = 0.72 | This approach is customized for the distinctive features of the Arabic language, providing powerful sequence processing. However, its regional focus restricts broader applicability. | |
| Matero et al. [20] | 2019 | Dual RNN | English | BERT | Acc = 0.59 F1 = 0.50 | The dual RNN structure is strong in dealing with context data but has the problem of vanishing gradients. | ||
| Kancharapu et al. [21] | 2022 | LSTM | English | N/A | Acc = 0.87 F1 = 0.83 | Leveraging LSTM capabilities, the sequence processing is enhanced, yet the training is time-consuming and not immune to data bias. | ||
| Deepa J et al. [22] | 2023 | LSTM | English | N/A | Acc = 0.908 | The model’s strong sequence processing capabilities help prevent the vanishing of gradients, but it still struggles to fully capture subsequent sentence information. | ||
| Almars [23] | 2022 | Bi-LSTM-Attention | Arabic | Word2Ve | F1 = 0.85 | Incorporating a Bi-LSTM structure, the framework boasts potent capabilities for bidirectional sequence data processing, but this comes with a high parameter count and complex tuning requirements. | ||
| Kancharapu et al. [24] | 2023 | Bi-LSTM-Ensemble | English | Word2Vec GloVe | Acc = 0.86 | The Bi-LSTM framework, in conjunction with sentiment analysis, effectively detects suicide-related tweets but is ill-suited for large datasets and prone to sensitivity to outliers. | ||
| CNN-RNN hybrid-based method | Sawhney et al. [25] | 2018 | C-LSTM | Reddit Tumblr | English | Word2Vec | Acc = 0.81 F1 = 0.83 | C-LSTM excels at capturing local and contextual features, but it faces challenges with text information loss. |
| Kour et al. [15] | 2022 | CNN-BiLSTM | English | Tailored Generative Word Embeddings | Acc = 0.94 AUC = 0.95 F1 = 0.95 | The model adeptly captures contextual and emotional semantics but is constrained by sentence length limitations. | ||
| Tadesse et al. [26] | 2019 | LSTM-CNN | English | Word2vec | Acc = 0.94 F1 = 0.93 | The integration of the two models’ strengths was intended to prevent overfitting, yet it is hampered by insufficient data and potential labeling bias. | ||
| Priyamvada et al. [27] | 2023 | Stacked CNN-2layers-LSTM | English | Word2Vec | Acc = 0.94 | The method broadens its feature extraction capabilities, but this expansion entails a large parameter set and demands substantial computing resources. | ||
| Renjith et al. [28] | 2022 | LSTM-Attention-CNN | English | Word2Vec | Acc = 0.90 F1 = 0.93 | This approach considers input value relationships and learns hidden text features yet overlooks class imbalance. | ||
| Chadha et al. [29] | 2022 | ACL | English | Word2vec GloVe | Acc = 0.88 F1 = 0.91 P = 0.87 | ACL zeroes in on the nuances and key terms of target data but neglects feature beyond social media text. | ||
| Zogan et al. [30] | 2022 | MDHAN | English | GloVe | Acc = 0.895 F1 = 0.89 | The multi-level attention network captures detailed user tweet encodings, disregarding topic and sentiment. |
| Type | Example | Likelihood Probability for Suicidal Ideation |
|---|---|---|
| Suicidal microblogs |
| 99.96% |
| 97.84% | |
| 99.99% | |
| 98.94% | |
| Non-Suicidal microblogs |
| 35.03% |
| 39.50% | |
| 43.07% | |
| 16.62% |
| Model | Word2Vec | Glove | BERT | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc% | P% | R% | F1% | AUC% | Acc% | P% | R% | F1% | AUC% | Acc% | P% | R% | F1% | AUC% | |
| SVM | 72.60 | 75.49 | 66.93 | 70.95 | 81.16 | 72.23 | 83.39 | 55.52 | 66.66 | 72.71 | 80.17 | 91.28 | 66.65 | 77.05 | 91.91 |
| NB | 70.45 | 73.26 | 64.39 | 68.54 | 78.56 | 70.02 | 79.81 | 53.46 | 64.03 | 82.26 | 77.49 | 90.21 | 61.60 | 73.21 | 87.77 |
| RF | 73.33 | 77.93 | 65.10 | 70.94 | 79.51 | 70.44 | 73.86 | 63.27 | 68.16 | 78.36 | 80.42 | 90.88 | 67.56 | 77.50 | 91.65 |
| CNN | 77.50 | 90.22 | 61.61 | 73.22 | 87.77 | 77.91 | 86.40 | 66.16 | 74.94 | 86.82 | 83.91 | 79.32 | 91.65 | 85.04 | 93.80 |
| TextCNN | 82.46 | 86.37 | 77.08 | 81.46 | 91.32 | 81.25 | 87.44 | 72.97 | 79.55 | 90.88 | 85.27 | 81.20 | 91.06 | 85.85 | 94.27 |
| TextRCNN | 80.49 | 86.48 | 72.27 | 78.74 | 90.05 | 78.56 | 86.20 | 67.99 | 76.02 | 88.55 | 83.51 | 91.98 | 73.36 | 81.62 | 93.52 |
| RNN | 76.22 | 84.72 | 63.98 | 72.90 | 84.26 | 76.81 | 89.06 | 61.13 | 72.50 | 86.81 | 83.90 | 78.77 | 92.86 | 85.24 | 93.12 |
| TextRNN | 78.64 | 88.38 | 65.94 | 75.53 | 90.22 | 77.96 | 87.11 | 65.56 | 74.81 | 89.34 | 84.25 | 79.33 | 92.74 | 85.51 | 93.49 |
| LSTM | 77.75 | 89.13 | 63.21 | 73.96 | 90.11 | 78.00 | 85.35 | 67.59 | 75.44 | 86.83 | 84.46 | 79.54 | 92.93 | 85.72 | 94.02 |
| BiLSTM | 80.58 | 87.87 | 70.94 | 78.50 | 90.78 | 80.74 | 86.46 | 72.90 | 79.10 | 90.04 | 84.68 | 78.78 | 95.81 | 86.46 | 95.41 |
| Model | Accuracy/% | Precision/% | Recall/% | F1-Score/% | AUC% |
|---|---|---|---|---|---|
| BERT-BiLSTM | 84.68 | 78.78 | 95.81 | 86.46 | 95.41 |
| BERT-TextCNN | 85.27 | 81.20 | 91.06 | 85.85 | 94.27 |
| BERT-BiLSTM-TextCNN | 85.76 | 80.83 | 94.25 | 87.03 | 95.28 |
| BERT-TextCNN-BiLSTM | 85.98 | 82.16 | 92.99 | 87.24 | 95.37 |
| DSI-BTCNN | 86.70 | 82.43 | 93.38 | 87.56 | 95.64 |
| Model | Accuracy/% | Precision/% | Recall/% | F1-Score/% | AUC/% | Entropy/% |
|---|---|---|---|---|---|---|
| DSI-BTCNN(1-kernel) | 88.78 | 93.01 | 85.13 | 89.07 | 96.37 | 80.73 |
| DSI-BTCNN(2-kernels) | 87.29 | 90.52 | 83.30 | 86.76 | 94.79 | 80.09 |
| DSI-BTCNN(3-kernels) | 89.64 | 92.84 | 85.90 | 89.24 | 96.50 | 81.75 |
| DSI-BTCNN(4-kernels) | 87.59 | 90.80 | 83.66 | 87.88 | 95.07 | 78.99 |
| DSI-BTCNN(5-kernels) | 86.67 | 93.93 | 78.42 | 85.48 | 95.92 | 75.46 |
| Case No. | Text | Probability for Suicidal Ideation in Our Model |
|---|---|---|
| 1 |
| 92.50% |
| 2 |
| 96.36% |
| 3 |
| 99.87% |
| 4 |
| 92.74% |
| 5 |
| 95.98% |
| 6 |
| 99.90% |
| 7 |
| 99.80% |
| 8 |
| 92.29% |
| 9 |
| 99.98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, X.; Cui, X.; Zhang, Y.; Wang, S.; Wang, C.; Li, M.; Yang, J. Mining Suicidal Ideation in Chinese Social Media: A Dual-Channel Deep Learning Model with Information Gain Optimization. Entropy 2025, 27, 116. https://doi.org/10.3390/e27020116
Meng X, Cui X, Zhang Y, Wang S, Wang C, Li M, Yang J. Mining Suicidal Ideation in Chinese Social Media: A Dual-Channel Deep Learning Model with Information Gain Optimization. Entropy. 2025; 27(2):116. https://doi.org/10.3390/e27020116
Chicago/Turabian StyleMeng, Xiuyang, Xiaohui Cui, Yue Zhang, Shiyi Wang, Chunling Wang, Mairui Li, and Jingran Yang. 2025. "Mining Suicidal Ideation in Chinese Social Media: A Dual-Channel Deep Learning Model with Information Gain Optimization" Entropy 27, no. 2: 116. https://doi.org/10.3390/e27020116
APA StyleMeng, X., Cui, X., Zhang, Y., Wang, S., Wang, C., Li, M., & Yang, J. (2025). Mining Suicidal Ideation in Chinese Social Media: A Dual-Channel Deep Learning Model with Information Gain Optimization. Entropy, 27(2), 116. https://doi.org/10.3390/e27020116