Abstract
A statistical manifold M can be defined as a Riemannian manifold each of whose points is a probability distribution on the same support. In fact, statistical manifolds possess a richer geometric structure beyond the Fisher information metric defined on the tangent bundle . Recognizing that points in M are distributions and not just generic points in a manifold, can be extended to a Hilbert bundle . This extension proves fundamental when we generalize the classical notion of a point estimate—a single point in M—to a function on M that characterizes the relationship between observed data and each distribution in M. The log likelihood and score functions are important examples of generalized estimators. In terms of a parameterization , is a distribution on while its generalization as an estimate is a function over that indicates inconsistency between the model and data. As an estimator, is a distribution of functions. Geometric properties of these functions describe statistical properties of . In particular, the expected slopes of are used to define , the -information of . The Fisher information I is an upper bound for the -information: for all g, . We demonstrate the utility of this geometric perspective using the two-sample problem.
1. Introduction
Statistical manifolds provide a geometric framework for understanding families of probability distributions. While traditionally defined as Riemannian manifolds equipped with the Fisher information metric, their structure extends beyond this basic framework. Lauritzen [1] identified an additional skewness tensor, and Amari [2] also noticed this additional structure which he used to define a family of connections including both the metric connection and a dual pair—the mixture and exponential connections. This duality, first observed by Efron [3], reveals geometric structure beyond the Riemannian setting, though this previous work remained confined to the tangent bundle.
Amari [4] introduced a Hilbert space extension of the tangent bundle which Amari and Kumon [5] applied to estimating functions. Kass and Vos (Section 10.3) [6] also describe statistical Hilbert bundles which Pistone [7] extends to other statistical bundles in the nonparametric setting where extra care is required when the sample space is not finite. Recent developments have expanded the geometric perspective on the role of the Hilbert bundle in parametric inference when the traditional approach to statistical inference is replaced with Fisher’s view of estimation.
Classical statistical inference separates estimation and hypothesis testing into distinct frameworks. Point estimators map from the sample space to the parameter space, with their local properties described through the tangent bundle. Test statistics similarly rely on tangent bundle geometry. The log likelihood and its derivative, the score function, bridge these approaches by providing both estimation methods (maximum likelihood) and testing procedures (likelihood ratio and score tests). Godambe [8] extended the score’s role in estimation through estimating equations, yet the fundamental separation between testing and estimation persisted.
Building on Fisher’s [9] conception of estimation as a continuum of hypothesis tests, Vos [10] unified these approaches by replacing point estimators with generalized estimators—functions on the parameter space that geometrically represent surfaces over the manifold. These generalized estimators shift the inferential focus from individual parameter values to entire functions, whose properties are naturally characterized within the Hilbert bundle framework.
This paper demonstrates the advantages of generalized estimators and the utility of the Hilbert bundle perspective specifically for the two-sample problem. We show how the orthogonalized score achieves information bounds as a consequence of its membership in the tangent bundle, while other generalized estimators, residing only in the larger Hilbert bundle, suffer information loss measured by their angular deviation from the tangent space.
2. Statistical Manifolds
Let be a family of probability measures with common support . While can be an abstract space, for most applications, . Each point in represents a candidate model for a population whose individuals take values in .
We consider inference based on a sample denoted by y, with corresponding sample space . The relationship between and depends on three factors: the sampling plan, any conditioning applied, and dimension reduction through sufficient statistics. In the simplest case—a simple random sample of size n without conditioning or dimension reduction—we have .
Let denote the family of probability measures on induced by through the sampling plan. For the simple random sampling case:
For any real-valued measurable function h, we define its expected value at as
The Hilbert space associated with M consists of all square-integrable functions:
This space carries a family of inner products indexed by points in M:
When , we say that h and are m-orthogonal and write .
We construct the Hilbert bundle over M by associating a copy of to each point:
The fiber at m, denoted or , inherits the inner product . For inference purposes, we decompose each fiber into the space of constant functions and its orthogonal complement:
Here, consists of centered functions, while contains the constants. Note that and is independent of m. As decomposition (1) holds fiberwise, we obtain a global decomposition:
The bundle extends the tangent bundle , which emerges naturally through parameterization. We assume that M admits a global parameterization—while not strictly necessary, this simplifies our exposition by avoiding coordinate charts. We require this parameterization to be a diffeomorphism.
Consider a parameterization with inverse . For a specific distribution , we write for its parameter value. When considering all distributions simultaneously, we write , where context distinguishes between as a point in (left side) and as a function (right side).
For notational convenience, we denote the distribution corresponding to parameter value as . This allows us to write the following:
where, again, context clarifies whether refers to the function or its value.
With this parameterization, the Hilbert bundle can be expressed as
allowing us to index fibers by parameter values: .
The log likelihood function plays a fundamental role in our geometric framework. On M, it is the function defined by . Through the parameterization, this induces given by . When the parameterization is clear from context, we simply write ℓ for .
The partial derivatives of ℓ with respect to the parameters,
evaluated at , form a basis for the tangent space . For all and all , , ensuring that . In fact, as vanishes on M.
3. Functions on
The log likelihood function ℓ and its derivatives are central to statistical inference. Traditionally, these serve as tools to find point estimates—particularly the maximum likelihood estimate (MLE)—and to characterize the estimator’s properties. We adopt a different perspective: we treat ℓ and its derivatives as primary inferential objects rather than mere computational tools. This approach aligns with Fisher’s conception of estimation as a continuum of tests.
As the log likelihood ratio for comparing models with parameters and is the difference and adding an arbitrary constant to each term does not affect this difference, we define the log likelihood so that for each fixed y. Thus we work with
As an inferential function, quantifies the dissonance between observation y and distribution . While the MLE set identifies parameters with minimal dissonance, our emphasis shifts to characterizing the full landscape of dissonance across the manifold. While “dissonance” lacks a precise mathematical definition, it can be thought of as the evidence in y against the model at —essentially, a test statistic evaluated at y for the null hypothesis specifying . We use the notation for the MLE when it is unique. When the MLE set is empty we say that the MLE does not exist. Note that ℓ is defined even when the MLE does not exist or is not unique; the only requirement is that .
The log likelihood exemplifies a broader class of generalized estimators: functions where, for almost every , the function measures dissonance between y and distributions across M. Like ℓ, we can normalize G so that .
Consider the geometric interpretation. For a function , let denote its graph. The graphs and form d-dimensional surfaces over . We compare these surfaces through their gradients:
where .
Viewing these as estimators requires replacing the fixed observation y with the random variable Y. Then and become random surfaces, while and become random gradient fields. The score components span the tangent space: . The key difference between generalized estimation described in this paper and the estimating equations of Godambe and Thompson [11] lies in their inferential approach: the former focuses on the distribution of graph slopes (gradients in a linear space), while the latter examines the distribution of where graphs intersect the horizontal axis (roots of g).
Under mild regularity conditions, the components of span a subspace of of dimension d although generally not . Strictly speaking, is isomorphic rather than equal to , as the former consists of vectors attached to the surface while the latter are attached to M (equivalently, to ). As shown in Vos and Wu [12], this precise relationship between the log likelihood surface and the manifold ensures that score-based estimators attain the information bound.
This perspective fundamentally shifts our focus. Rather than comparing point estimators through their variance or mean squared error on the parameter space , we compare the linear spaces spanned by the components of generalized estimators within the Hilbert bundle .
For point estimator , define its associated generalized estimator:
The estimator must have nonzero variance, for all , so that . Instead of traditional comparisons between (the MLE) and , we compare the spaces spanned by and through their -information—a generalization of Fisher information to arbitrary generalized estimators. Geometrically, the relationship between s and is characterized by angles between their component vectors. Statistically, this translates to correlations between the corresponding random variables. The -information is defined by the left-hand side of Equation (13) which also shows the role of the correlation.
Generalized estimators offer particular advantages when nuisance parameters are present. For point estimators, one seeks a parameterization where nuisance and interest parameters are orthogonal—a goal not always achievable. When working in rather than , orthogonalization remains important but becomes more flexible: the choice of nuisance parameterization becomes immaterial as orthogonalization occurs within itself.
The information bound for the interest parameter is attained by restricting generalized estimators to be orthogonal to the nuisance parameter’s score components. The general framework is developed in Vos and Wu [12]; we illustrate the approach through the special case for comparing two populations in the following section.
4. Comparing Two Populations
We now develop the general framework for comparing two distributions from the same parametric family. The next section applies this framework to the more specific case of contingency tables.
Let be a one-parameter family of distributions on , and let be the corresponding family of sampling distributions on . While we work primarily with sampling distributions in , we use superscripts to distinguish when necessary: denotes a sampling distribution obtained from population distribution .
For simple random sampling outside exponential families, . Within exponential families, represents the support of the sufficient statistic. For example, when consists of Bernoulli distributions with success probability , the family consists of binomial distributions for n trials with sample space .
Let parameterize . We define the population parameterization to ensure consistency: . Thus, each parameter value simultaneously labels both a population distribution in and its corresponding sampling distribution in . As our focus is on sampling distributions, we simplify notation by dropping the subscript .
The score function for parameter is
where we factor the score into its magnitude and its standardized version Z with and . Both and Z depend on and, thus, vary across .
Under reparameterization of , the standardized score Z remains invariant while the coefficient transforms as . The coefficient equals the square root of the total Fisher information: where is the Fisher information per observation. For the binomial family, .
Now consider independent samples of sizes and from two distributions in . The manifold of joint population distributions is
with corresponding manifold of joint sampling distributions:
The parameterization of induces natural parameterizations on and on . These share the same image where . Setting and , each point in labels both a joint sampling distribution and its generating population distribution.
The hypothesis that both samples arise from the same distribution corresponds to the diagonal submanifold:
with parameter space:
The joint parameter yields two score functions:
where and are orthonormal at each :
To compare the distributions, we reparameterize using the difference as our interest parameter and as the nuisance parameter. The inverse transformation gives and , yielding scores:
Let denote the unit vector in the direction of , satisfying , , and . As remains invariant under monotonic reparameterizations of , we use the subscript (for nuisance). In terms of the basis :
Let h be a point estimator or test statistic for . The function h is a generalized pre-estimator provided is a generalized estimator. For any pre-estimator h of , define its orthogonalized version:
where is the standardized direction and is the correlation with the nuisance direction.
To ensure that inference is independent of the nuisance parameter, we work with orthogonalized generalized estimators :
When h is the score for , the orthogonalized score becomes
where is the information after orthogonalization. The proportion of information loss due to the nuisance parameter is the square of the correlation between the interest and nuisance parameters
This loss cannot be recovered by reparameterization. Geometrically, , so the proportional information loss equals the squared cosine of the angle between the score and the tangent space of . The submanifold depends on the choice of interest parameter and is integral to the inference problem.
The orthogonalized Fisher information is additive on the reciprocal scale:
Equation (8) is established as follows. The orthogonalized score is a linear combination of the orthonormal basis vectors and ,
As and :
and taking the reciprocal of both sides of (10) gives (8). Substituting into (7) with shows
which means that the information loss due to the nuisance parameter is proportional to the squared difference in the Fisher information for the distributions being compared. Using Equation (9), the orthogonalized score in terms of the basis vectors and is
The basis is obtained from using the linear transformation
which is a rotation through an angle of . When is a location parameter, and are constant on M. With equal sample sizes (), the rotation angle is and .
While , for general estimators g we have but unless . This distinction explains why general estimators fail to achieve the information bound. The -information of g is , where is the correlation between and .
The null hypothesis deserves special attention. While generally depends on the parameterization choice, is parameterization-invariant as it is equivalent to . Under simple random sampling with , the standardized orthogonalized score on becomes
which is invariant across all parameterizations . This invariance does not hold for test statistics based on point estimators like , whose form depends on whether we parameterize using proportions, log-proportions, or log-odds.
5. Comparing Two Bernoulli Distributions
We now specialize the general framework to comparing two Bernoulli distributions, establishing the geometric structure that underlies inference for contingency tables.
For the Bernoulli sample space , the manifold of population distributions is
with natural parameterization . For a sample of size n, the sufficient statistic has support , yielding the manifold of binomial sampling distributions:
A natural bijection exists between and : each population distribution determines a unique sampling distribution. We define to make this bijection . Similarly, for any alternative parameterization (such as ), we define so that the bijection equals .
For independent samples of sizes and , the joint manifolds are
Using the proportion parameterization , the sampling distribution at p is
for , with corresponding population distribution:
for .
The Hilbert space for this manifold consists of all real-valued functions on the finite sample space:
As the support is finite, includes all finite-valued functions. The tangent space at m is the two-dimensional subspace:
where and .
Table 1 summarizes the Fisher information per observation for three common parameterizations of the Bernoulli distribution, each offering different advantages for inference.

Table 1.
Fisher information per observation, , for common parameterizations of the Bernoulli distribution expressed in the success parameter p.
We illustrate our geometric framework using data from Mendenhall et al. [13], who conducted a retrospective analysis of laryngeal carcinoma treatment. Disease was controlled in 18 of 23 patients treated with surgery alone and 11 of 19 patients treated with irradiation alone (, , , ). We use this data to compare the orthogonalized score with other generalized estimators when the interest parameter is the log odds ratio .
5.1. Orthogonalized Score
The score has two key properties: at each point in the sample space is a smooth function on the parameter space, and at each each point in the manifold is a distribution on the sample space. Formally, for y fixed and for fixed when there is no nuisance parameter. As is the interest parameter we use the notation s for the score . These properties persist after orthogonalization and standardization to obtain and .
Figure 1 illustrates these properties for using the cancer data. The black curve shows evaluated at the observed sample as a function of , with the nuisance parameter fixed at . Each of the 480 points in the sample space generates such a curve; two additional examples appear in gray. We distinguish the family of curves (uppercase) from the specific observed curve (lowercase).
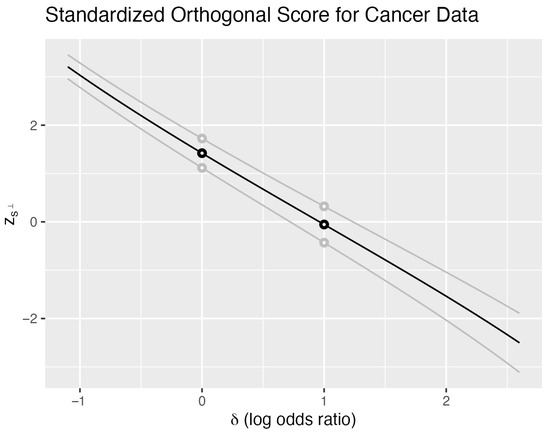
Figure 1.
Cancer data—orthogonalized score. Standardized orthogonal score as a function of the log odds difference . The observed data (18 of 23 surgery successes, 11 of 19 irradiation successes) yields the black curve. Two additional sample points shown in gray illustrate the family of 480 possible curves. The nuisance parameter is fixed at . Horizontal lines at intersect the observed curve to yield an approximate 95% confidence interval for .
For any fixed , the vertical line intersects all 480 curves, yielding a distribution of values. Together with the probability mass function , this defines the sampling distribution of when and . Crucially, every such vertical distribution has mean zero and variance one, reflecting the standardization of the score.
The intersection of horizontal lines with provides confidence intervals through inversion. The lines intersect the observed curve at points and , partitioning the parameter space into three regions:
- For : the observed exceeds 2 standard deviations above its expectation.
- For : the observed lies within 2 standard deviations.
- For : the observed falls below −2 standard deviations.
The interval forms an approximate 95% confidence interval for . The approximation quality depends on the normality of the vertical distributions, while the interval width depends on the slope of —steeper slopes yield narrower intervals.
These calculations are conditional on . Different nuisance parameter values yield different intervals, motivating our choice of the orthogonal parameterization where . With this choice, the one-dimensional submanifolds and intersect transversally, and their tangent spaces are orthogonal at the intersection point.
Varying the horizontal line height provides confidence intervals at different levels. For all , these lines intersect each of the 480 curves, ensuring that confidence intervals exist for every sample point. The intersection of all confidence levels can be interpreted as a point estimate for . For sample points other than and , this intersection equals the MLE—the point where crosses zero. At the boundary points and , the curves never cross zero, yielding an empty intersection that corresponds to the nonexistence of the MLE.
The 2-standard deviation confidence interval ( for the log odds ratio is (−0.35, 2.27). The exact 95% confidence interval is (−0.40, 2.40) for nuisance parameter equal to 29. This interval is a function of . To obtain an interval that is the same for all values of the nuisance parameter, we take the union of intervals as takes all values to obtain (−0.46, 2.42). The exact 95% confidence interval from Fisher’s exact test is (−0.57, 2.55).
5.2. Other Generalized Estimators
Point estimators naturally induce generalized estimators, though the relationship depends on the parameterization. For a parameterization and point estimator , if , then the generalized estimator is when no nuisance parameters exist, or with nuisance parameters present.
Consider the binomial family with proportion parameter p. The MLE yields , which is proportional to the score. However, for the log odds parameterization , the MLE satisfies and , so . No generalized estimator exists for the unmodified log odds MLE.
A standard remedy adds a small constant to each cell, yielding the modified MLE:
This modification ensures finite values throughout the sample space, enabling construction of the corresponding generalized estimator.
While the proportion MLE could similarly be modified, this is rarely performed despite the MLE’s failure at the boundaries. The MLE’s parameter invariance allows its definition without reference to any specific parameterization: for ,
This coordinate-free definition emphasizes the MLE’s geometric nature but obscures its boundary behavior.
For comparing two populations using log odds, the modified MLE yields the difference estimator , with orthogonalized generalized estimator:
Like the orthogonalized score, g exhibits smoothness in parameters and distributional properties in the sample space: for fixed y, and for fixed . Both are orthogonal to the nuisance space. The critical distinction lies in their geometric location: while , generally unless .
Figure 2 illustrates this distinction for the cancer data. The black curve shows for the observed sample with (adding 0.5 to each cell) and nuisance parameter . Each of the 480 sample points generates a smooth curve, with two shown in gray. Vertical lines at any intersect these curves to yield distributions with mean zero and unit variance.
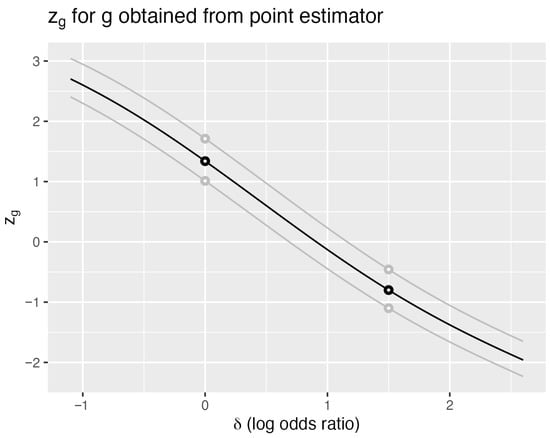
Figure 2.
Cancer data—modified MLE estimator. Standardized generalized estimator based on the modified log odds difference , where 0.5 is added to each cell count. The observed data (18 of 23 surgery successes, 11 of 19 irradiation successes) yields the black curve. Two additional sample points are shown in gray. The nuisance parameter is fixed at . Compare with Figure 1 to observe the flatter slope indicating lower -information.
As with , horizontal lines at determine confidence intervals through their intersections with . Steeper slopes produce narrower intervals, making the expected slope a natural efficiency measure. Differentiating the identity with respect to yields
Rearranging gives the fundamental inequality
where is the correlation between g and . Vos and Wu [12] define the left-hand side of (13) as the , -information in g for parameter . The bound is attained only when , establishing the optimality of the orthogonalized score:
The square of the correlation is the same for any reparameterization of , so we can define the -efficiency of g as
-efficiency is independent of the choice of interest or nuisance parameter. For example, -efficiency will be the same whether we use the odds ratio or the log odds ratio. -information, like Fisher information , is a tensor.
The geometric interpretation is revealing: measures the cosine of the angle between g and in . The information loss equals the squared sine of this angle times the total information. Estimators achieve full -efficiency only when perfectly aligned with the orthogonalized score.
A crucial distinction emerges when testing . Under this null hypothesis with simple random sampling, the standardized orthogonalized score becomes
which remains invariant across all parameterizations . This invariance reflects the geometric fact that is equivalent to regardless of the choice of .
In contrast, test statistics based on point estimators like depend critically on the parameterization. Tests based on proportions, log proportions, and log odds yield different statistics with different null distributions, even though they test the same hypothesis. The orthogonalized score provides a canonical, parameterization-invariant test that achieves maximum power against local alternatives.
The 2-standard deviation confidence interval ( for the log odds ratio is (−1.09, 2.95). The exact 95% confidence interval is (−0.43, 2.39) for nuisance parameter equal to 29. The union of intervals over values for is at least (−0.68, 2.47).
5.3. Discussion
Table 2 presents confidence intervals for the log odds difference computed using various methods. These intervals reveal substantial variation in both width and location, highlighting the importance of understanding the underlying geometric principles.
Table 2.
Confidence intervals for the log odds difference using cancer treatment data. Computed using R version 4.4.1 with package exact2x2 version 1.6.8 [14]. All methods except Fisher’s exact test are unconditional; Fisher’s conditions on the observed total of 29 successes.
The orthogonalized score interval, whether computed at or maximized over all nuisance parameter values, falls within both the modified MLE and Fisher’s exact test intervals for this particular dataset. However, this nesting relationship is sample-specific and should not guide method selection. The choice among methods should depend on their theoretical properties rather than their behavior for any particular observed data.
The orthogonalized score offers three key advantages:
- It attains the Fisher information bound, achieving maximum -efficiency.
- It requires no ad hoc modifications to handle boundary cases (unlike the MLE for log odds).
- It provides parameterization-invariant inference for , yielding identical test statistics whether we parameterize using proportions, log proportions, or log odds.
The R (version 4.4.1) package (version 4.4.1) exact2x2 (version 1.6.8) [14,15] implements several additional unconditional methods, each corresponding to different generalized estimators. While this diversity offers flexibility, it also highlights the need for principled comparison methods.
The geometric framework of generalized estimation provides this principled approach. By working in the Hilbert bundle, we obtain
- Unified treatment: Point estimators and test statistics become special cases of generalized estimators.
- Parameter invariance: Generalized estimators transform properly under reparameterization.
- Linear structure: The Hilbert bundle provides a natural vector space framework for combining and comparing estimators.
- Consistent comparison: -information offers a single efficiency measure, replacing the multiple criteria (bias, variance, MSE) used for point estimators.
This geometric perspective reveals why the orthogonalized score achieves optimality: it lies in the tangent bundle , while other generalized estimators reside only in the larger Hilbert bundle . The information loss of any estimator equals times the squared sine of its angle from the tangent space—a geometric characterization that unifies and clarifies classical efficiency results.
6. Conclusions
This paper has demonstrated how the Hilbert bundle structure of statistical manifolds provides a unified geometric framework for statistical inference. By recognizing that points in a statistical manifold are probability distributions rather than abstract points, we extend the traditional tangent bundle framework to encompass a richer geometric structure that naturally accommodates both estimation and hypothesis testing.
The central insight is that generalized estimators—functions on the parameter space—serve as the fundamental inferential objects. The -information of a generalized estimator g captures both its smooth structure across models in M and its distributional properties at each point. These dual aspects require different geometric descriptions: the smooth structure manifests through the graph of in the plane, while the distributional properties are naturally characterized within the Hilbert bundle .
The information bound emerges as a geometric principle: the mean slope of equals , and this slope is maximized precisely when g lies in the tangent bundle . Statistically, the bound is attained when , the orthogonalized score. For any other generalized estimator, the information loss equals , where measures the correlation between g and as elements of . This correlation has a direct geometric interpretation: it equals the cosine of the angle between these functions in the Hilbert space.
The presence of nuisance parameters introduces an additional layer of geometric structure. Information loss due to nuisance parameters equals , where is the correlation between the score s and the nuisance direction . Crucially, this correlation—and hence the information loss—remains invariant under reparameterization of either interest or nuisance parameters. This invariance reflects a fundamental geometric fact: specifying a value for the interest parameter defines a submanifold rather than a single point in M. The increased inferential difficulty is precisely quantified by , the squared correlation between the score and the tangent space of .
Our analysis of contingency tables illustrates these principles concretely. The orthogonalized score achieves three key advantages over traditional approaches: it attains the information bound, requires no ad hoc modifications for boundary cases, and provides parameterization-invariant inference. The geometric framework explains why different confidence interval methods yield different results—they correspond to different generalized estimators with varying degrees of alignment with the tangent bundle.
This geometric perspective resolves longstanding tensions between estimation and testing frameworks. Rather than treating these as separate endeavors united only by computational tools like the likelihood function, we see them as complementary aspects of a single geometric structure. Point estimators, test statistics, and estimating equations all become special cases of generalized estimators, whose efficiency is uniformly measured by their -information.
The Hilbert bundle framework thus provides both conceptual clarity and practical benefits. It reveals why certain statistical procedures are optimal, quantifies the cost of using suboptimal methods, and suggests principled ways to construct new inferential procedures. By shifting focus from points in parameter space to functions on the manifold, we gain a richer, more complete understanding of statistical evidence and its geometric foundations.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No data created.
Acknowledgments
The author thanks all reviewers for their valuable comments. Special acknowledgment goes to the reviewer who identified key references for the Hilbert bundle discussed in the introduction and emphasized the contribution of Godambe and Thompson [11] in Section 3, thereby strengthening the exposition of the distinction between generalized estimation and estimating equations. During the preparation of this manuscript, the author used Claude Opus 4.1 for the purposes of (1) clarifying and improving presentation of the penultimate draft, (2) summarizing the paper in the conclusion section with input from the author, and (3) writing the original R code (ggplot2) for the figures later modified by the author. The author has reviewed and edited the output and takes full responsibility for the content of this publication.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Lauritzen, S.L. Chapter 4: Statistical Manifolds. In Institute of Mathematical Statistics; Lecture Notes—MONOGRAPH series; Institute of Mathematical Statistics: Hayward, CA, USA, 1987; pp. 163–216. [Google Scholar]
- Amari, S.I. Differential-Geometrical Methods in Statistics. In Lecture Notes in Statistics; Springer: New York, NY, USA, 1990. [Google Scholar]
- Efron, B. The geometry of exponential families. Ann. Stat. 1978, 6, 362–376. [Google Scholar] [CrossRef]
- Amari, S.I. Dual connections on the Hilbert bundles of statistical models. Geom. Stat. Theory 1987, 6, 123–152. [Google Scholar]
- Amari, S.I.; Kumon, M. Estimation in the presence of infinitely many nuisance parameters–geometry of estimating functions. Ann. Stat. 1988, 16, 1044–1068. [Google Scholar] [CrossRef]
- Kass, R.E.; Vos, P.W. Geometrical Foundations of Asymptotic Inference; Wiley Series in Probability and Statistics; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Pistone, G. Affine statistical bundle modeled on a Gaussian Orlicz–Sobolev space. Inf. Geom. 2024, 7, 109–130. [Google Scholar] [CrossRef]
- Godambe, V.P. An Optimum Property of Regular Maximum Likelihood Estimation. Ann. Math. Stat. 1960, 31, 1208–1211. [Google Scholar] [CrossRef]
- Fisher, R. Statistical Methods and Scientific Induction. J. R. Stat. Soc. Ser. Methodol. 1955, 17, 69–78. [Google Scholar] [CrossRef]
- Vos, P. Generalized estimators, slope, efficiency, and fisher information bounds. Inf. Geom. 2022, 7, S151–S170. [Google Scholar] [CrossRef]
- Godambe, V.P.; Thompson, M.E. Some aspects of the theory of estimating equations. J. Stat. Plan. Inference 1978, 2, 95–104. [Google Scholar] [CrossRef]
- Vos, P.; Wu, Q. Generalized Estimation and Information. Inf. Geom. 2025, 8, 99–123. [Google Scholar] [CrossRef]
- Mendenhall, W.M.; Million, R.R.; Sharkey, D.E.; Cassisi, N.J. Stage T3 squamous cell carcinoma of the glottic larynx treated with surgery and/or radiation therapy. Int. J. Radiat. Oncol. Biol. Phys. 1984, 10, 357–363. [Google Scholar] [CrossRef] [PubMed]
- Michael, P. Fay Keith Lumbard. Confidence Intervals for Difference in Proportions for Matched Pairs Compatible with Exact McNemars or Sign Tests. Stat. Med. 2021, 40, 1147–1159. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2025. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).