Comparing Statistical and Machine Learning Methods for Time Series Forecasting in Data-Driven Logistics—A Simulation Study


Abstract
1. Introduction
2. Methods
2.1. Time Series Methods
2.1.1. ARIMA
- AR (Autoregression): Represents the regression of the time series on its own past values, capturing dependencies through lagged observations. The number of lagged observations included in the models is given by p.
- I (Integrated): The differencing order (d) indicates the number of times the time series is differenced to achieve stationarity. This transformation involves subtracting the current observation from its d-th lag, which is crucial for stabilizing the mean and addressing trends.
- MA (Moving Average): Incorporates a moving average model to account for dependencies between observations and the residual errors of the lagged observations (q).
2.1.2. SARIMA
2.1.3. TBATS
- T (Trend): Captures the overall trend in the time series using an exponential smoothing mechanism.
- B (Box–Cox Transformation): Applies the Box–Cox transformation [50] to stabilize variance and ensure the homogeneity of variances.
- A (ARIMA Errors): Incorporates ARIMA errors to capture any remaining non-seasonal dependencies.
- S (Seasonal): Utilizes trigonometric functions to model multiple seasonal components, accommodating various seasonal patterns.
2.2. Machine Learning Methods
2.2.1. XGBoost
2.2.2. Random Forest
- B is the number of grown trees. Note that this parameter is usually not tuned since it is known that more trees are better.
- The cardinality of the sample of features at every node is .
- The minimum number of observations that each terminal node should contain (stopping criteria).
3. Simulation Set-Up
3.1. Data Generating Processes
3.2. Additional Complexities
3.3. Additional Queueing Models
3.4. Number of Different Settings
3.5. Data Preprocessing
3.6. Choice of Parameters
3.7. Evaluation Measure
4. Results
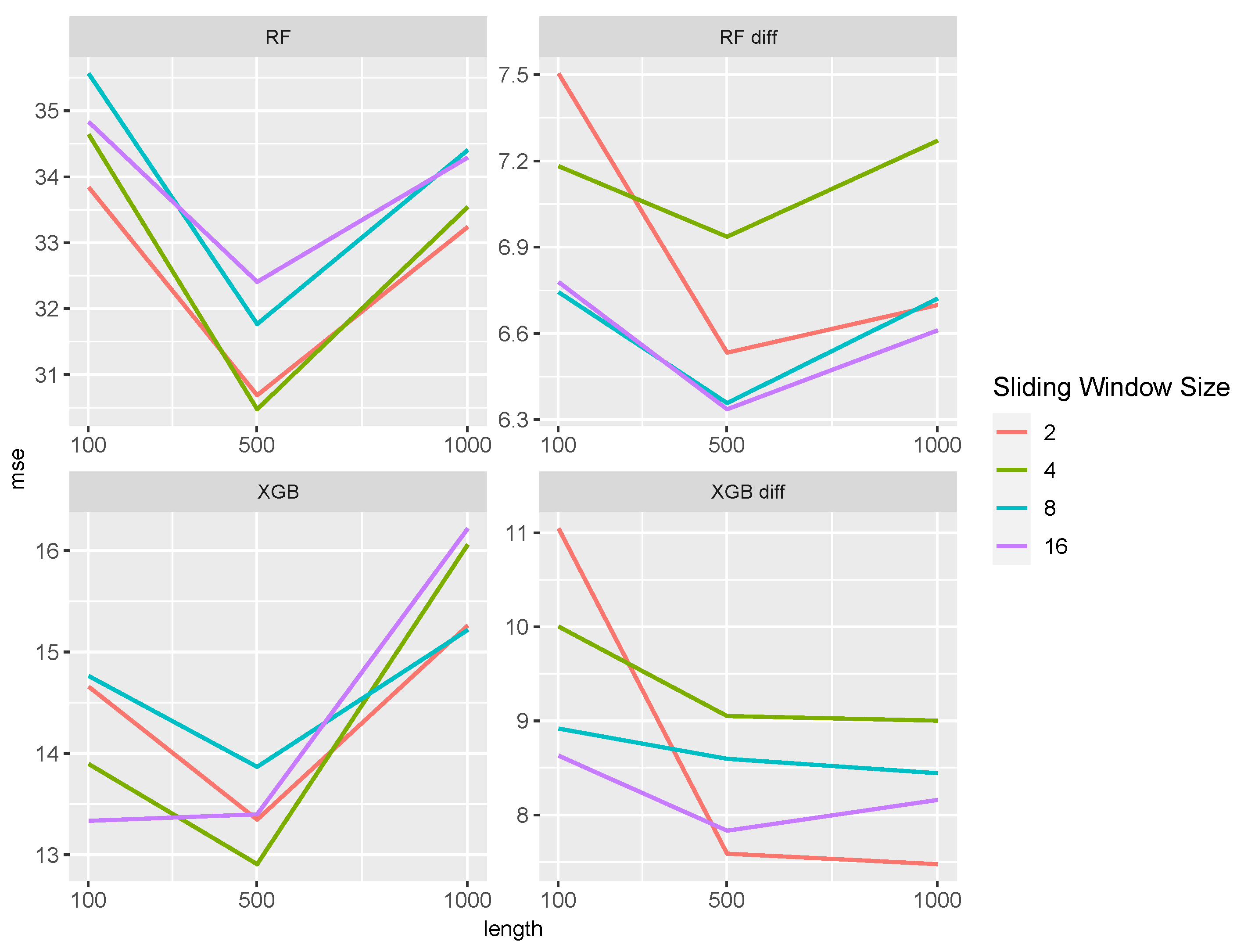
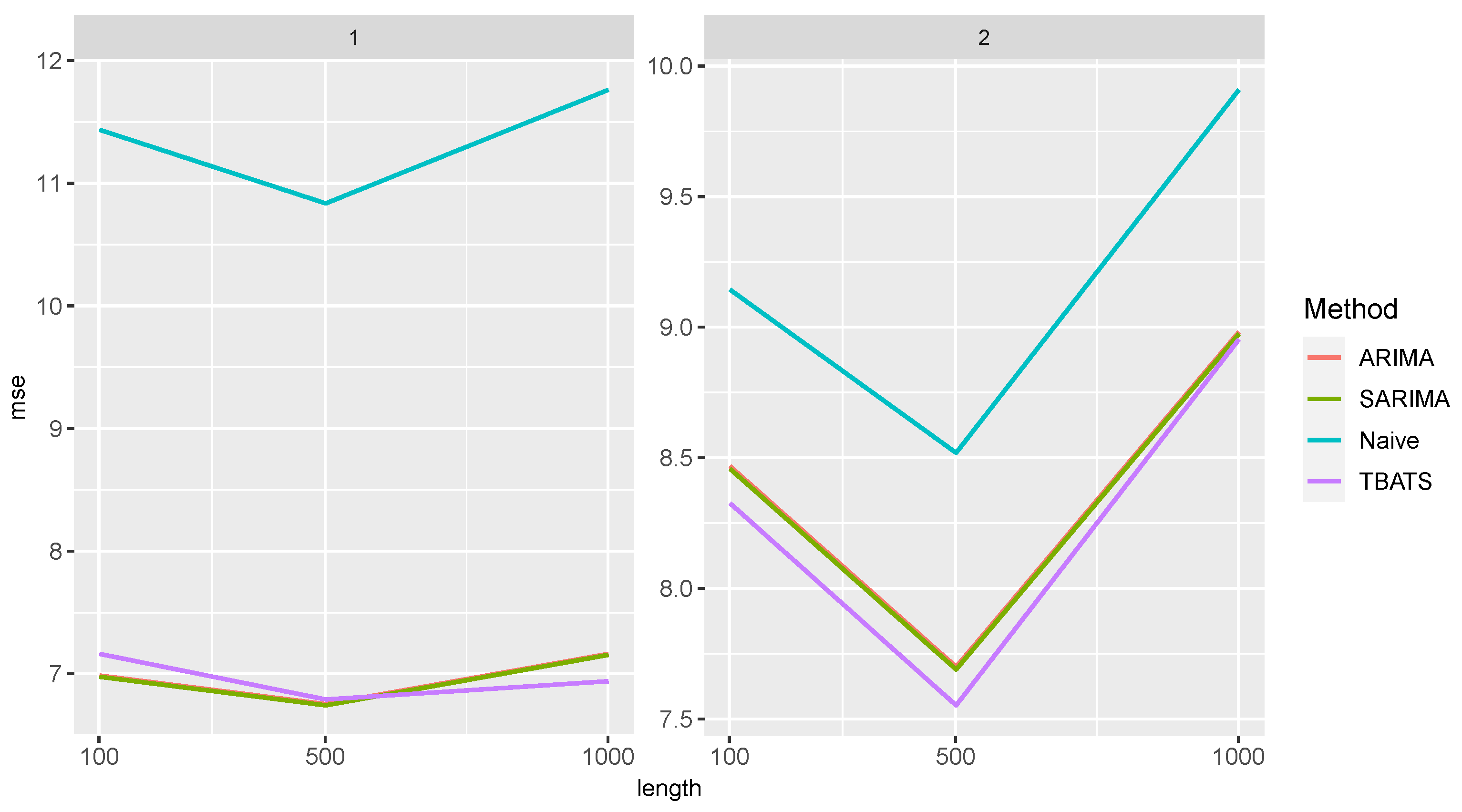
4.1. Predictive Power in Queueing Models
4.2. Predictive Power in the Different Time Series Settings
4.3. Influence of the Additional Complexities on the Predictive Power
4.4. Summarizing All Results
5. Real-World Data Example
6. Summary, Discussion, and Outlook
6.1. Summary with Highlights
- The out-of-the-box Random Forest emerged as the ML benchmark method.
- Training on differentiated time series can significantly improve the ML resilience.
- ML models are more robust with respect to additional (nonlinear) complexity, settings in which they outperformed statistical time series approaches.
- In all other settings, the time series approaches were at least competitive or even performed better.
6.2. Detailed Discussion and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
















References
- Huang, H.; Pouls, M.; Meyer, A.; Pauly, M. Travel time prediction using tree-based ensembles. In Proceedings of the Computational Logistics: 11th International Conference, ICCL 2020, Enschede, The Netherlands, 28–30 September 2020; Proceedings 11. Springer: Berlin/Heidelberg, Germany, 2020; pp. 412–427. [Google Scholar]
- Wu, C.H.; Ho, J.M.; Lee, D.T. Travel-time prediction with support vector regression. IEEE Trans. Intell. Transp. Syst. 2004, 5, 276–281. [Google Scholar] [CrossRef]
- Lin, H.E.; Zito, R.; Taylor, M. A review of travel-time prediction in transport and logistics. Proc. East. Asia Soc. Transp. Stud. 2005, 5, 1433–1448. [Google Scholar]
- Garrido, R.A.; Mahmassani, H.S. Forecasting freight transportation demand with the space–time multinomial probit model. Transp. Res. Part B Methodol. 2000, 34, 403–418. [Google Scholar] [CrossRef]
- Wu, H.; Levinson, D. The ensemble approach to forecasting: A review and synthesis. Transp. Res. Part C Emerg. Technol. 2021, 132, 103357. [Google Scholar] [CrossRef]
- Shi, Y.; Guo, X.; Yu, Y. Dynamic warehouse size planning with demand forecast and contract flexibility. Int. J. Prod. Res. 2018, 56, 1313–1325. [Google Scholar] [CrossRef]
- Ribeiro, A.M.N.; do Carmo, P.R.X.; Endo, P.T.; Rosati, P.; Lynn, T. Short-and very short-term firm-level load forecasting for warehouses: A comparison of machine learning and deep learning models. Energies 2022, 15, 750. [Google Scholar] [CrossRef]
- Feizabadi, J. Machine learning demand forecasting and supply chain performance. Int. J. Logist. Res. Appl. 2022, 25, 119–142. [Google Scholar] [CrossRef]
- Kuhlmann, L.; Pauly, M. A Dynamic Systems Model for an Economic Evaluation of Sales Forecasting Methods. Teh. Glas. 2023, 17, 397–404. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Babai, Z.; Boylan, J.E.; Kolassa, S.; Nikolopoulos, K. Supply chain forecasting: Theory, practice, their gap and the future. Eur. J. Oper. Res. 2016, 252, 1–26. [Google Scholar] [CrossRef]
- Ensafi, Y.; Amin, S.H.; Zhang, G.; Shah, B. Time-series forecasting of seasonal items sales using machine learning—A comparative analysis. Int. J. Inf. Manag. Data Insights 2022, 2, 100058. [Google Scholar] [CrossRef]
- Wu, Z.; Ramsundar, B.; Feinberg, E.N.; Gomes, J.; Geniesse, C.; Pappu, A.S.; Leswing, K.; Pande, V. MoleculeNet: A benchmark for molecular machine learning. Chem. Sci. 2018, 9, 513–530. [Google Scholar] [CrossRef]
- Weber, L.M.; Saelens, W.; Cannoodt, R.; Soneson, C.; Hapfelmeier, A.; Gardner, P.P.; Boulesteix, A.L.; Saeys, Y.; Robinson, M.D. Essential guidelines for computational method benchmarking. Genome Biol. 2019, 20, 125. [Google Scholar] [CrossRef] [PubMed]
- Niemann, F.; Reining, C.; Moya Rueda, F.; Nair, N.R.; Steffens, J.A.; Fink, G.A.; Ten Hompel, M. Lara: Creating a dataset for human activity recognition in logistics using semantic attributes. Sensors 2020, 20, 4083. [Google Scholar] [CrossRef]
- Arora, K.; Abbi, P.; Gupta, P.K. Analysis of Supply Chain Management Data Using Machine Learning Algorithms. In Innovative Supply Chain Management via Digitalization and Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2022; pp. 119–133. [Google Scholar]
- Reining, C.; Niemann, F.; Moya Rueda, F.; Fink, G.A.; ten Hompel, M. Human activity recognition for production and logistics—A systematic literature review. Information 2019, 10, 245. [Google Scholar] [CrossRef]
- Awasthi, S.; Fernandez-Cortizas, M.; Reining, C.; Arias-Perez, P.; Luna, M.A.; Perez-Saura, D.; Roidl, M.; Gramse, N.; Klokowski, P.; Campoy, P. Micro UAV Swarm for industrial applications in indoor environment—A Systematic Literature Review. Logist. Res. 2023, 16, 1–43. [Google Scholar]
- Friedrich, S.; Friede, T. On the role of benchmarking data sets and simulations in method comparison studies. Biom. J. 2023, 66, 2200212. [Google Scholar] [CrossRef] [PubMed]
- Shukla, M.; Jharkharia, S. ARIMA models to forecast demand in fresh supply chains. Int. J. Oper. Res. 2011, 11, 1–18. [Google Scholar] [CrossRef]
- Gilbert, K. An ARIMA Supply Chain Model. Manag. Sci. 2005, 51, 305–310. [Google Scholar] [CrossRef]
- Taylor, S.J.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Kumar Jha, B.; Pande, S. Time Series Forecasting Model for Supermarket Sales using FB-Prophet. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 547–554. [Google Scholar] [CrossRef]
- Hasmin, E.; Aini, N. Data Mining For Inventory Forecasting Using Double Exponential Smoothing Method. In Proceedings of the 2020 2nd International Conference on Cybernetics and Intelligent System (ICORIS), Manado, Indonesia, 27–28 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Carbonneau, R.; Laframboise, K.; Vahidov, R. Application of machine learning techniques for supply chain demand forecasting. Eur. J. Oper. Res. 2008, 184, 1140–1154. [Google Scholar] [CrossRef]
- Wenzel, H.; Smit, D.; Sardesai, S. A literature review on machine learning in supply chain management. In Artificial Intelligence and Digital Transformation in Supply Chain Management: Innovative Approaches for Supply Chains. Proceedings of the Hamburg International Conference of Logistics (HICL); epubli GmbH: Berlin, Germany, 2019; Volume 27, pp. 413–441. [Google Scholar]
- Sharma, R.; Kamble, S.S.; Gunasekaran, A.; Kumar, V.; Kumar, A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput. Oper. Res. 2020, 119, 104926. [Google Scholar] [CrossRef]
- Ni, D.; Xiao, Z.; Lim, M.K. A systematic review of the research trends of machine learning in supply chain management. Int. J. Mach. Learn. Cybern. 2020, 11, 1463–1482. [Google Scholar] [CrossRef]
- Baryannis, G.; Dani, S.; Antoniou, G. Predicting supply chain risks using machine learning: The trade-off between performance and interpretability. Future Gener. Comput. Syst. 2019, 101, 993–1004. [Google Scholar] [CrossRef]
- Kohzadi, N.; Boyd, M.S.; Kermanshahi, B.; Kaastra, I. A comparison of artificial neural network and time series models for forecasting commodity prices. Neurocomputing 1996, 10, 169–181. [Google Scholar] [CrossRef]
- Weng, Y.; Wang, X.; Hua, J.; Wang, H.; Kang, M.; Wang, F.Y. Forecasting horticultural products price using ARIMA model and neural network based on a large-scale data set collected by web crawler. IEEE Trans. Comput. Soc. Syst. 2019, 6, 547–553. [Google Scholar] [CrossRef]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparison of ARIMA and LSTM in forecasting time series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1394–1401. [Google Scholar]
- Palomares-Salas, J.; De La Rosa, J.; Ramiro, J.; Melgar, J.; Aguera, A.; Moreno, A. ARIMA vs. Neural networks for wind speed forecasting. In Proceedings of the 2009 IEEE International Conference on Computational Intelligence for Measurement Systems and Applications, Hong Kong, China, 11–13 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 129–133. [Google Scholar]
- Ampountolas, A. Modeling and forecasting daily hotel demand: A comparison based on sarimax, neural networks, and garch models. Forecasting 2021, 3, 580–595. [Google Scholar] [CrossRef]
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]
- Nyoni, T. Modeling and forecasting inflation in Kenya: Recent insights from ARIMA and GARCH analysis. Dimorian Rev. 2018, 5, 16–40. [Google Scholar]
- Benvenuto, D.; Giovanetti, M.; Vassallo, L.; Angeletti, S.; Ciccozzi, M. Application of the ARIMA model on the COVID-2019 epidemic dataset. Data Brief 2020, 29, 105340. [Google Scholar] [CrossRef] [PubMed]
- Tsay, R.S. Testing and modeling threshold autoregressive processes. J. Am. Stat. Assoc. 1989, 84, 231–240. [Google Scholar] [CrossRef]
- Francq, C.; Zakoian, J.M. GARCH Models: Structure, Statistical Inference and Financial Applications; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- De Gooijer, J.G.; Kumar, K. Some recent developments in non-linear time series modelling, testing, and forecasting. Int. J. Forecast. 1992, 8, 135–156. [Google Scholar] [CrossRef]
- Bontempi, G.; Ben Taieb, S.; Borgne, Y.A.L. Machine learning strategies for time series forecasting. In Proceedings of the European Business Intelligence Summer School, Brussels, Belgium, 15–21 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 62–77. [Google Scholar]
- Ahmed, N.K.; Atiya, A.F.; Gayar, N.E.; El-Shishiny, H. An empirical comparison of machine learning models for time series forecasting. Econom. Rev. 2010, 29, 594–621. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Al-Saba, T.; El-Amin, I. Artificial neural networks as applied to long-term demand forecasting. Artif. Intell. Eng. 1999, 13, 189–197. [Google Scholar] [CrossRef]
- Zhang, G.P.; Patuwo, B.E.; Hu, M.Y. A simulation study of artificial neural networks for nonlinear time-series forecasting. Comput. Oper. Res. 2001, 28, 381–396. [Google Scholar] [CrossRef]
- Hwarng, H.B. Insights into neural-network forecasting of time series corresponding to ARMA (p, q) structures. Omega 2001, 29, 273–289. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S.; Stoffer, D.S. Time Series Analysis and Its Applications; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- De Livera, A.M.; Hyndman, R.J.; Snyder, R.D. Forecasting time series with complex seasonal patterns using exponential smoothing. J. Am. Stat. Assoc. 2011, 106, 1513–1527. [Google Scholar] [CrossRef]
- Box, G.E.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. Ser. B (Methodol.) 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Ji, S.; Wang, X.; Zhao, W.; Guo, D. An application of a three-stage XGBoost-based model to sales forecasting of a cross-border e-commerce enterprise. Math. Probl. Eng. 2019, 2019, 8503252. [Google Scholar] [CrossRef]
- Islam, S.; Amin, S.H. Prediction of probable backorder scenarios in the supply chain using Distributed Random Forest and Gradient Boosting Machine learning techniques. J. Big Data 2020, 7, 65. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, Z.; Ihler, A.; Pan, B. Estimating warehouse rental price using machine learning techniques. Int. J. Comput. Commun. Control 2018, 13, 235–250. [Google Scholar] [CrossRef]
- Kuhlmann, L.; Wilmes, D.; Müller, E.; Pauly, M.; Horn, D. RODD: Robust Outlier Detection in Data Cubes. arXiv 2023, arXiv:2303.08193. [Google Scholar]
- Aguilar Madrid, E.; Antonio, N. Short-term electricity load forecasting with machine learning. Information 2021, 12, 50. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Therneau, T.M.; Atkinson, E.J. An Introduction to Recursive Partitioning Using the RPART Routines; Technical Report; Mayo Foundation: Rochester, MN, USA, 1997. [Google Scholar]
- Schapire, R.E.; Freund, Y. Boosting: Foundations and algorithms. Kybernetes 2013, 42, 164–166. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Mayr, A.; Binder, H.; Gefeller, O.; Schmid, M. The evolution of boosting algorithms. Methods Inf. Med. 2014, 53, 419–427. [Google Scholar]
- Morde, V. XGBoost Algorithm: Long May She Reign! Available online: https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d (accessed on 13 December 2023).
- Luo, J.; Zhang, Z.; Fu, Y.; Rao, F. Time series prediction of COVID-19 transmission in America using LSTM and XGBoost algorithms. Results Phys. 2021, 27, 104462. [Google Scholar] [CrossRef]
- Alim, M.; Ye, G.H.; Guan, P.; Huang, D.S.; Zhou, B.S.; Wu, W. Comparison of ARIMA model and XGBoost model for prediction of human brucellosis in mainland China: A time-series study. BMJ Open 2020, 10, e039676. [Google Scholar] [CrossRef]
- Zhang, L.; Bian, W.; Qu, W.; Tuo, L.; Wang, Y. Time series forecast of sales volume based on XGBoost. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1873, p. 012067. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: London, UK, 2017. [Google Scholar]
- Wright, M.N.; Ziegler, A. ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Goehry, B.; Yan, H.; Goude, Y.; Massart, P.; Poggi, J.M. Random Forests for Time Series. REVSTAT-Stat. J. 2023, 21, 283–302. [Google Scholar]
- Pórtoles, J.; González, C.; Moguerza, J.M. Electricity price forecasting with dynamic trees: A benchmark against the random forest approach. Energies 2018, 11, 1588. [Google Scholar] [CrossRef]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 15, 276. [Google Scholar] [CrossRef]
- Salari, N.; Liu, S.; Shen, Z.J.M. Real-time delivery time forecasting and promising in online retailing: When will your package arrive? Manuf. Serv. Oper. Manag. 2022, 24, 1421–1436. [Google Scholar] [CrossRef]
- Vairagade, N.; Logofatu, D.; Leon, F.; Muharemi, F. Demand forecasting using random forest and artificial neural network for supply chain management. In Proceedings of the Computational Collective Intelligence: 11th International Conference, ICCCI 2019, Hendaye, France, 4–6 September 2019; Proceedings, Part I 11. Springer: Berlin/Heidelberg, Germany, 2019; pp. 328–339. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. xgboost: Extreme Gradient Boosting; R Package Version 1.6.0.1. Available online: https://CRAN.R-project.org/package=xgboost (accessed on 10 July 2024).
- Luong, H.T. Measure of bullwhip effect in supply chains with autoregressive demand process. Eur. J. Oper. Res. 2007, 180, 1086–1097. [Google Scholar] [CrossRef]
- Ivanov, D.; Dolgui, A. Viability of intertwined supply networks: Extending the supply chain resilience angles towards survivability. A position paper motivated by COVID-19 outbreak. Int. J. Prod. Res. 2020, 58, 2904–2915. [Google Scholar] [CrossRef]
- Kingman, J.F.C. Poisson Processes; Clarendon Press: Oxford, UK, 1992; Volume 3. [Google Scholar]
- Sheffi, Y. The Resilient Enterprise: Overcoming Vulnerability for Competitive Advantage; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Chatfield, C.; Xing, H. The Analysis of Time Series: An Introduction with R; Chapman and hall/CRC: Boca Raton, FL, USA, 2019. [Google Scholar]
- Box, G. Signal-to-noise ratios, performance criteria, and transformations. Technometrics 1988, 30, 1–17. [Google Scholar] [CrossRef]
- Cooper, R.B. Queueing theory. In Proceedings of the ACM’81 Conference; Association for Computing Machinery: New York, NY, USA, 1981; pp. 119–122. [Google Scholar]
- Artalejo, J.R.; Lopez-Herrero, M. Analysis of the busy period for the M/M/c queue: An algorithmic approach. J. Appl. Probab. 2001, 38, 209–222. [Google Scholar] [CrossRef]
- Schwarz, M.; Sauer, C.; Daduna, H.; Kulik, R.; Szekli, R. M/M/1 queueing systems with inventory. Queueing Syst. 2006, 54, 55–78. [Google Scholar] [CrossRef]
- Kobayashi, H.; Konheim, A. Queueing models for computer communications system analysis. IEEE Trans. Commun. 1977, 25, 2–29. [Google Scholar] [CrossRef]
- Gautam, N. Analysis of Queues: Methods and Applications; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Brown, L.; Gans, N.; Mandelbaum, A.; Sakov, A.; Shen, H.; Zeltyn, S.; Zhao, L. Statistical analysis of a telephone call center: A queueing-science perspective. J. Am. Stat. Assoc. 2005, 100, 36–50. [Google Scholar] [CrossRef]
- Green, L. Queueing analysis in healthcare. In Patient Flow: Reducing Delay in Healthcare Delivery; Springer: Berlin/Heidelberg, Germany, 2006; pp. 281–307. [Google Scholar]
- Radmilovic, Z.; Colic, V.; Hrle, Z. Some aspects of storage and bulk queueing systems in transport operations. Transp. Plan. Technol. 1996, 20, 67–81. [Google Scholar] [CrossRef]
- Dietterich, T.G. Machine learning for sequential data: A review. In Proceedings of the Structural, Syntactic, and Statistical Pattern Recognition: Joint IAPR International Workshops SSPR 2002 and SPR 2002, Windsor, ON, Canada, 6–9 August 2002; Proceedings. Springer: Berlin/Heidelberg, Germany, 2002; pp. 15–30. [Google Scholar]
- Savva, A.D.; Kassinopoulos, M.; Smyrnis, N.; Matsopoulos, G.K.; Mitsis, G.D. Effects of motion related outliers in dynamic functional connectivity using the sliding window method. J. Neurosci. Methods 2020, 330, 108519. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, R.; Martiniano, A.; Ferreira, A.; Ferreira, A.; Sassi, R. Daily Demand Forecasting Orders. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/dataset/409/daily+demand+forecasting+orders (accessed on 10 June 2024).
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/datasets (accessed on 10 June 2024).
- Probst, P.; Boulesteix, A.L.; Bischl, B. Tunability: Importance of Hyperparameters of Machine Learning Algorithms. J. Mach. Learn. Res. 2019, 20, 1–32. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Venkatapathy, A.K.R.; Riesner, A.; Roidl, M.; Emmerich, J.; ten Hompel, M. PhyNode: An intelligent, cyber-physical system with energy neutral operation for PhyNetLab. In Proceedings of the Smart SysTech 2015; European Conference on Smart Objects, Systems and Technologies, VDE, Aachen, Germany, 16–17 July 2015; pp. 1–8. [Google Scholar]
- Gouda, A.; Heinrich, D.; Hünnefeld, M.; Priyanta, I.F.; Reining, C.; Roidl, M. A Grid-based Sensor Floor Platform for Robot Localization using Machine Learning. In Proceedings of the 2023 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Kuala Lumpur, Malaysia, 22–25 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Aladag, C.H.; Egrioglu, E.; Kadilar, C. Forecasting nonlinear time series with a hybrid methodology. Appl. Math. Lett. 2009, 22, 1467–1470. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Smyl, S. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 2020, 36, 75–85. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Variant(s) | Data Generating Process |
|---|---|---|
| Autoregressive | AR | |
| Bilinear | BL 1 | |
| BL2 | ||
| Nonlinear Autoregressive | NAR 1 | |
| NAR2 | ||
| Nonlinear Moving Average | NMA | |
| Sign Autoregressive | SAR 1 | , |
| SAR 2 | , | |
| Smooth Transition Autoregressive | STAR 1 | , |
| STAR 2 | , | |
| Threshold Autoregressive | TAR 1 | |
| TAR 2 |
| DGP | RF | RF Diff | XGBoost | XGBoost Diff | ARIMA | SARIMA | TBATS | Naive | |
|---|---|---|---|---|---|---|---|---|---|
| Queueing Models | 7 | 1 | 7 | 5 | 2.5 | 3.5 | 3 | 6 | |
| DGPS | no add. Compl. | 1 | 6 | 5 | 7 | 3 | 3 | 3 | 8 |
| from | Jumps | 7 | 1 | 7 | 5 | 3 | 3 | 3 | 6 |
| Table 1 | Random Walks | 5 | 1 | 7 | 6 | 3 | 3 | 3 | 8 |
| with | Both | 7 | 1 | 7 | 6 | 3 | 3 | 3 | 5 |
| MAPE | MSE | |||||
|---|---|---|---|---|---|---|
| Method | Prod. A | Prod. B | Prod. C | Prod. A | Prod. B | Prod. C |
| Random Forest | 24.30 | 35.05 | 30.79 | 22.39 | 262.41 | 695.70 |
| Random Forest Diff | 6.67 | 21.80 | 15.84 | 4.91 | 197.23 | 1.97 |
| XGBoost | 25.06 | 41.62 | 19.51 | 22.34 | 376.62 | 147.20 |
| XGBoost Diff | 10.70 | 37.98 | 27.15 | 13.10 | 841.56 | 41.00 |
| (S)ARIMA | 28.57 | 49.30 | 33.56 | 29.48 | 1142.14 | 655.88 |
| TBATS | 28.37 | 36.17 | 33.56 | 43.14 | 446.18 | 663.78 |
| Naive | 33.18 | 30.71 | 30.59 | 25.10 | 194.21 | 82.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schmid, L.; Roidl, M.; Kirchheim, A.; Pauly, M. Comparing Statistical and Machine Learning Methods for Time Series Forecasting in Data-Driven Logistics—A Simulation Study. Entropy 2025, 27, 25. https://doi.org/10.3390/e27010025
Schmid L, Roidl M, Kirchheim A, Pauly M. Comparing Statistical and Machine Learning Methods for Time Series Forecasting in Data-Driven Logistics—A Simulation Study. Entropy. 2025; 27(1):25. https://doi.org/10.3390/e27010025
Chicago/Turabian StyleSchmid, Lena, Moritz Roidl, Alice Kirchheim, and Markus Pauly. 2025. "Comparing Statistical and Machine Learning Methods for Time Series Forecasting in Data-Driven Logistics—A Simulation Study" Entropy 27, no. 1: 25. https://doi.org/10.3390/e27010025
APA StyleSchmid, L., Roidl, M., Kirchheim, A., & Pauly, M. (2025). Comparing Statistical and Machine Learning Methods for Time Series Forecasting in Data-Driven Logistics—A Simulation Study. Entropy, 27(1), 25. https://doi.org/10.3390/e27010025