1. Introduction
The intricate relationship between probability and entropy is a cornerstone in information theory and statistical thermodynamics, providing a robust framework for analyzing a multitude of phenomena ranging from data transmission processes to the behavior of many physical systems. Entropy, derived from the probability distribution of the states of a process or system, can be interpreted as a quantitative measure of randomness or disorder, offering deep insights into the underlying dynamics of several complex systems (see, for instance, Refs. [
1,
2,
3,
4,
5,
6]).
From a thermodynamic perspective, the entropy concept is intimately tied to the statistical mechanics of microstates. Entropy,
S, is defined by Boltzmann’s entropy equation,
, where
is the Boltzmann constant and
represents the number of microstates. This relationship can be interpreted as the degree of disorder or randomness in a system’s microscopic configurations, drawing a direct connection between the macroscopic observable properties and the statistical behavior of microstates. Complementarily, in the realm of information theory, entropy is fundamentally concerned with quantifying the expected level of “information”, “surprise”, or “uncertainty” in the potential outcomes of a system [
7]. This quantification is intricately linked to the probability distribution of these outcomes. It essentially measures the average unpredictability or the requisite amount of information needed to describe a random event, thereby providing a metric for the efficiency of data transmission and encoding strategies. Therefore, the duality of the entropy interpretation works as a bridge between the abstract realm of information and the tangible world of the statistics of physical systems. It encapsulates the essence of entropy as a fundamental measure, providing a unifying lens through which the behavior of complex systems, whether in the context of information processing or thermodynamics, can be coherently understood and analyzed. This interdisciplinary approach not only deepens our understanding of individual phenomenon but also reveals the underlying universality of the concepts of randomness and information across diverse scientific domains.
In the scenario described above, it is necessary to identify entropy measures that are effective in characterizing the spatiotemporal patterns of complex processes typically observed or simulated in
: following the notation of the amplitude equation theory, where
D corresponds to the spatial dimension in which the amplitude of a variable fluctuates over time. This need is justified by the great advances in the generation of big data in computational physics, with emphasis on the direct numerical simulation (DNS) of turbulence [
8,
9], ionized fluids [
10,
11,
12,
13,
14], and reactive–diffusive processes [
15] to highlight a few.
Our main objective in this work is to present and evaluate the performance of a set of information entropy measurements, conjugated two by two, in order to characterize different classes of 3D structural patterns arising from nonlinear spatiotemporal processes. To this end, the article is organized as follows: The analytical methodology is presented in
Section 2, and the data are presented in
Section 3. The results, in the context of a benchmark based on the generalization of the silhouette score, are presented and interpreted in
Section 4. Our concluding remarks, with emphasis on pointing out the usability of the method in the context of data-driven science, are presented in
Section 6.
2. Methods
Various entropy metrics have been proposed in the literature, including spectral entropy, permutation entropy, and statistical complexity.
The process of defining a new metric typically involves two fundamental steps: (i) establishing the probability definition and (ii) determining the entropic form. This framework allows for the generalization of any new metric by specifying these two steps (code publicly available at
https://github.com/rsautter/Eta (14 January 2024)).
In
Section 2.1 and
Section 2.2, we present, respectively, the key techniques for defining probabilities and entropic forms. Subsequently, in
Section 2.3, we introduce a methodology to assess these metrics using criteria that are commonly applied to clustering techniques.
2.1. Probabilities
Probability is a concept that quantifies the likelihood of an event occurring. It is expressed as a numerical value between 0 and 1. Here, 0 signifies the complete impossibility of an event, while 1 denotes absolute certainty. Mathematically, if we consider a process with a finite number of possible outcomes, the probability
of an event
E is defined by the following ratio:
This definition is useful for gaining insight of systems that produce discrete real-valued outcomes. In such a case, a histogram of proportions of observed events is the usual tool for estimating the underlying probability distribution of such outcomes.
Many systems produce continue-valued multidimensional outcomes, and the observer needs to define methods for estimating a useful probability that is able to characterize their behavior. Approaches such as permutation and spectral analysis incorporate spatial locality and scale considerations to elucidate the occurrence of specific patterns.
In the permutation approach, local spatial differences (increase, decrease, or constancy) represent the states. New states can be generated by permuting the array elements. Thus, the probabilities account for the occurrences of those states. To extend this definition to multiple dimensions, a given array is flattened. Further details of this technique have been explored by Pessa and Ribeiro [
16].
Another methodology involves spectral analysis, wherein the probability is computed as the power spectrum density (PSD) of the signal
, which is normalized accordingly. Since this approach considers the probability associated with a given frequency
, it explores the scaling relation of the signal. For instance, white noise, characterized by equal power across all frequencies, represents a type of signal exhibiting maximum entropy. In contrast, red noise presents a higher PSD for lower frequencies, leading to lower entropy values. This approach has been popularized in the literature to study time series [
2,
17]. The probabilities presented in this section describe the possible spatial states, while the subsequent subsection elaborates on the entropic characterization of this system.
2.2. Entropic Forms
Several entropy equations and generalizations have been proposed, such as Boltzmann–Gibbs entropy (also known as Shannon entropy), Tsallis entropy, and Rényi entropy. The most common form is Shannon entropy, which is expressed as follows:
Here,
is the probability of state
i, which can also comprise complex numbers [
18], and
W is the size of the set of possible events. The value of
depends on the distribution. Notably,
is at the maximum when all probabilities are equal, i.e., under the uniform distribution; in this case,
, and it is at the minimum when
is Dirac’s delta. To account for this maximum value, normalized Shannon entropy is given by the following:
Another significant entropic form is Tsallis entropy, proposed as a generalization of Boltzmann–Gibbs entropy [
19]:
where
is the entropic index or nonextensivity parameter, and it plays a crucial role in determining the degree of nonextensivity in Tsallis entropy.
It is important to explore a range of values for the parameter q to derive a metric distinct from Shannon entropy since . Therefore, we suggest exploring values for q in the range of and seek a relationship denoted by , where . This approach enables the examination of this generalization of .
A unique strategy for characterizing complex nonlinear systems is gradient pattern analysis (GPA). This technique involves computing a set of metrics derived from the gradient lattice representation and the gradient moments (see
Appendix A). Specifically, we highlight
, which is determined as the Shannon entropy from the complex representation of the gradient lattice:
In the lattice context, the gradient signifies the local variation of amplitudes, computed as the spatial derivative at every embedding dimension. From these spatial derivatives, the following complex representation is formed:
It comprises both the modulus (
) and phases (
). To obtain a probability, the complex notation is normalized by
. For an in-depth review of this metric, please refer to [
18,
20].
Table 1 provides a summary of all combinations of entropic forms with associated probabilities, along with the GPA metric, that were examined in this study.
To assess the efficacy of each metric and explore the impact of various combinations of probability definitions with entropic forms, we introduce a criterion outlined in the subsequent section. This criterion is formulated with a focus on clustering the entropy measures of the dataset.
2.3. Silhouette Score and Generalized Silhouette Score
Non-supervised algorithms face unique challenges, and a remarkable one is defining their efficiency. The silhouette score is a criterion for defining if a set has been well clusterized [
23]. Given an element
in a cluster
, this metric is computed as follows [
3,
24]:
where
is the average dissimilarity, which is the average distance of
to all other elements in the cluster
, and
is the average distance to the elements of other clusters. The greater the
value, the better performance of the clustering algorithm because it has produced groups with low dissimilarities and large distances between clusters. This technique can be extended to feature extractions if one considers the individual datasets as the clusters
. However, it is equally essential to account for the potential correlation between metrics, as metrics may inadvertently capture the same data aspects, which is undesirable. To mitigate this, we use the modulus of the Pearson correlation
to form the penalty term
as follows:
which we call the generalized silhouette score (GSS).
After defining a group of entropy measurements and the tool (GSS), which allows the determination of the best pair of measurements to compose a 2D parameter space, we selected the dataset to test and validate our methodological approach.
3. Data
Our main objective is to test the performance of a space composed of two entropy measures in which it is possible to distinguish different classes of complex spatiotemporal processes. For this first study, we chose turbulence-related processes and simulated dynamic colored noises.
We employ simulated data related to the following processes: (i) white noise; (ii) colored noise; (iii) weak turbulence; (iv) hydrodynamic turbulence; and (v) magnetohydrodynamic turbulence (MHD). The main reason for choosing these processes, except colored noise, is that they all present random-type patterns with underlying dynamic characteristics based on physical processes described by partial differential equations (diffusion, reaction, and advection). Each was obtained from simulations identified in
Table 2.
Based on the power-law-scaling algorithm technique [
25], we created our noise simulator [
26]. The data representing weak turbulence (also called chemical or reactive–diffusive turbulence) were obtained from the solution of the Ginzburg–Landau complex equation [
15,
27]. The hydrodynamic turbulence patterns were selected from the John Hopkins database (JHTDB) [
28], and the MHD turbulence was simulated using the PENCIL code [
12]. Details regarding the simulations are provided in the Supplementary Materials in the GitHub repository.
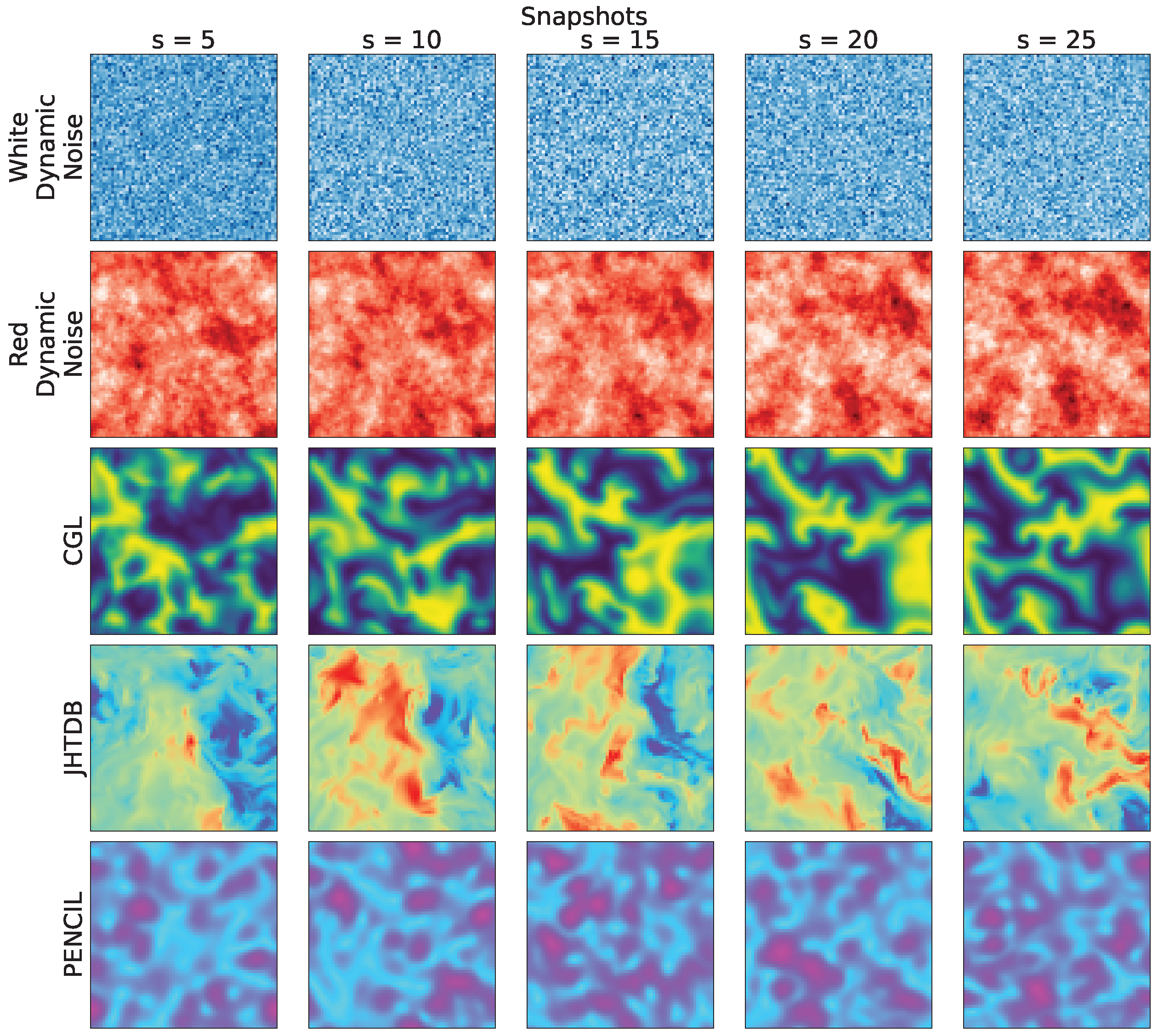
To test the approach based on entropy measurements, we selected a total of 25 snapshots representing the evolution of each chosen process. After selecting the middle slice of the hypercube, we uniformly resized all snapshots to byte-valued pixels using nearest neighbor interpolation; while this resizing expedites the analysis, it does entail a loss in resolution. The snapshots were extracted from 3D simulations, taking the analysis of the central slice of each hypercubeas a criterion as the measurement technique used to act on matrices within a two-dimensional approach.
Figure 1 shows representative snapshots of the respective spatiotemporal processes. These visualizations provide a compelling narrative of the dynamic behavior of each system, highlighting the wide variety of patterns that emerge through temporal dynamics in the phase space.
The numerical procedures and/or technical acquisition details related to the data shown in
Figure 1 are available in the Supplementary Materials in the repository (
https://github.com/rsautter/Eta/ (14 January 2024)) and in the section entitled “Data Simulations”.
4. Results and Interpretation
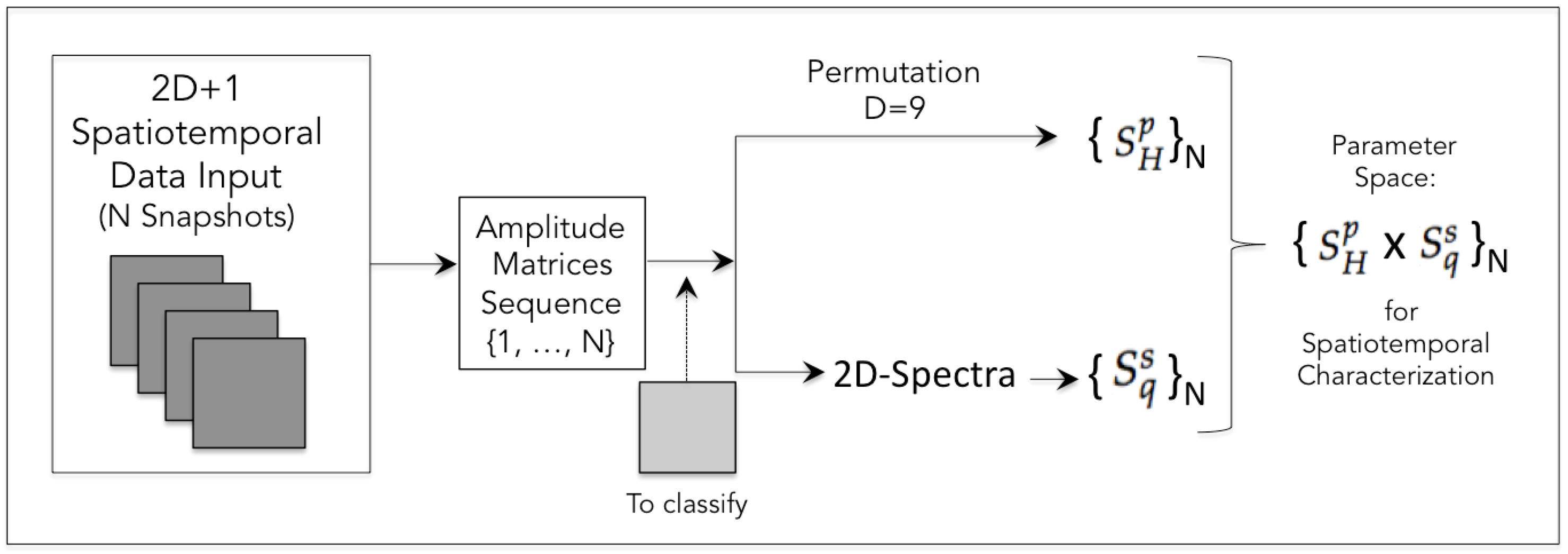
The analyses in this study were conducted within 2D metric spaces, encompassing all possible entropy measure combinations. Based on the minimum information principle, this configuration offers advantages in terms of interpretability, considering the minimum set of parameters that can be addressed as labels within a possible machine learning interpretation. Our approach to measuring entropies from the data follows the following steps:
Input of a snapshot;
Pre-processing for which its output is a matrix with amplitudes ranging from 0 to 255;
Generation of three matrix data outputs: 2D histogram, 2D permutation, and 2D FFT spectra;
For each of the three domains, the entropy measures are calculated.
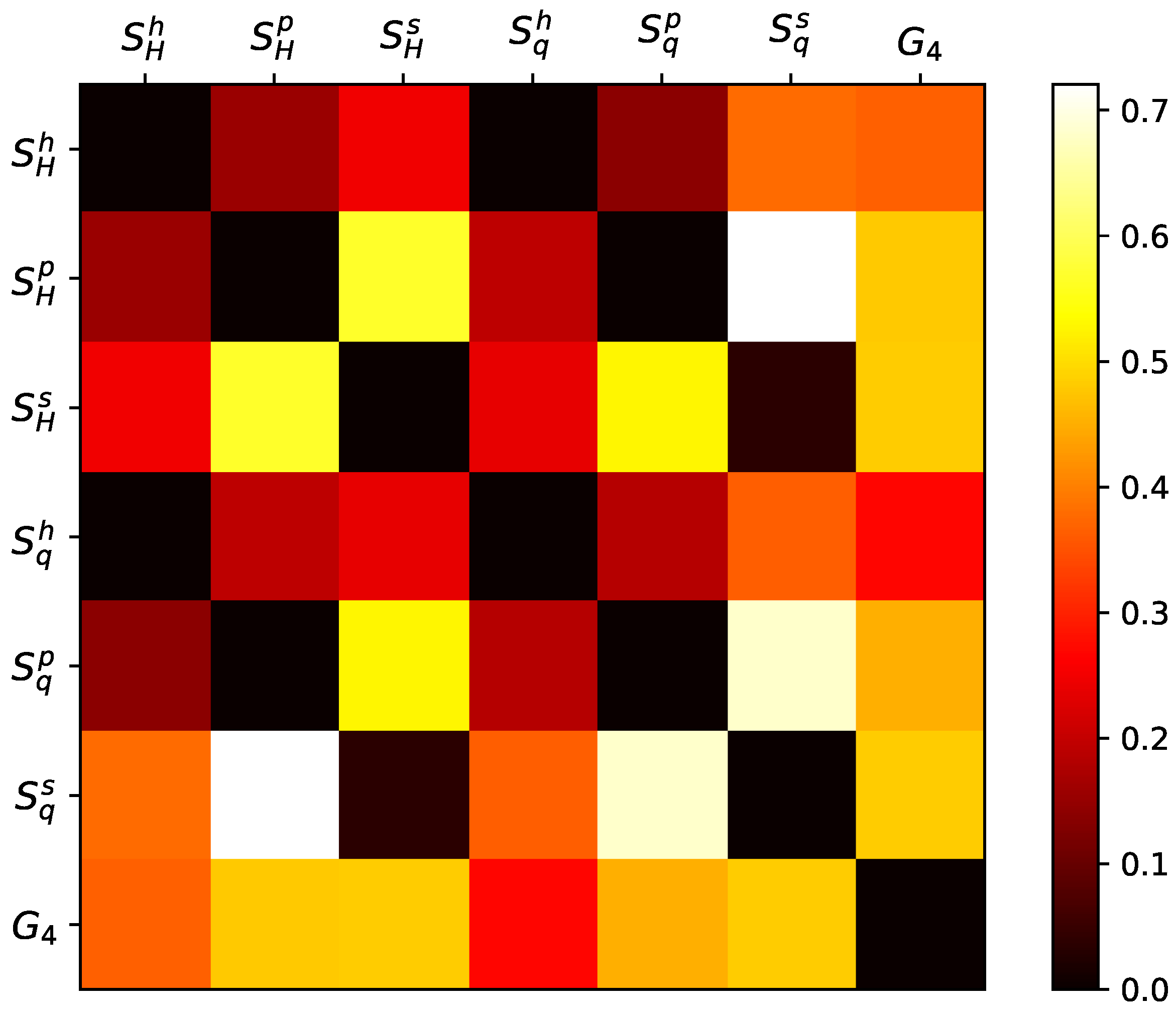
Given the definition of the three types of domains interpreted as probabilities (from histogram, permutation, and spectrum), we have six entropy variations, as detailed in
Section 2. To distinguish these metrics, we introduced superscripts denoted by
h for histogram probability,
p for permutation probability, and
s for spectral probability. The GPA analysis yields another metric, resulting in 21 scores, as illustrated in
Figure 2.
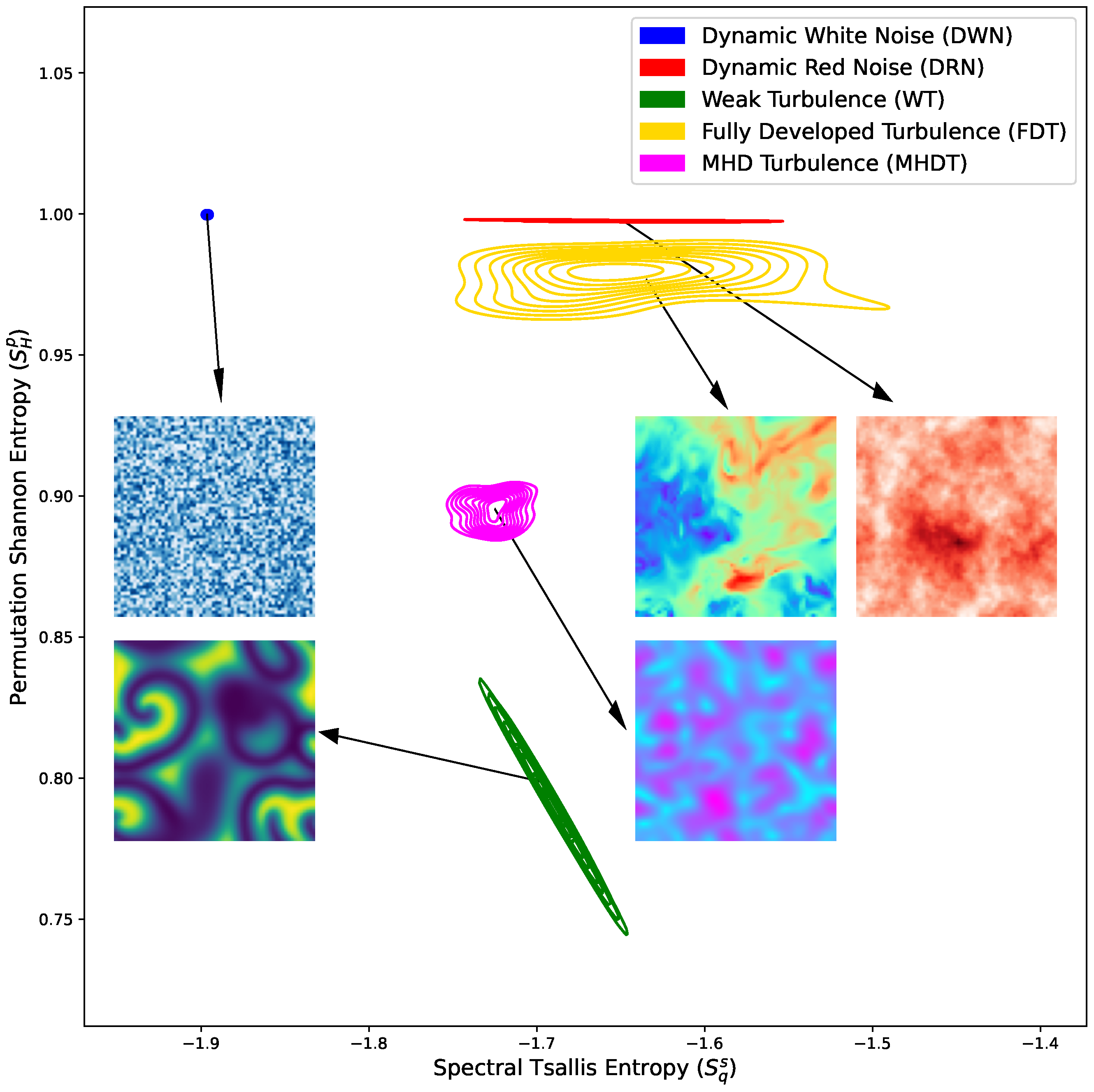
As a result, the most effective combination is the following pair: spectral Tsallis entropy (
) and Shannon permutation entropy (
). A visual representation of this space, accompanied by some snapshots, is presented in
Figure 3. In this space, the metrics reveal a constant Shannon permutation entropy dynamical noise system, which is solely distinguished by spectral Tsalllis entropy, indicating the differences in the scaling effects in pattern formation. Conversely, the distinct complex nonlinear characteristics and reaction terms observed in MHD simulations are more pronounced in Shannon permutation entropy, accentuating the diversity of localized patterns alongside the larger-scale ones.
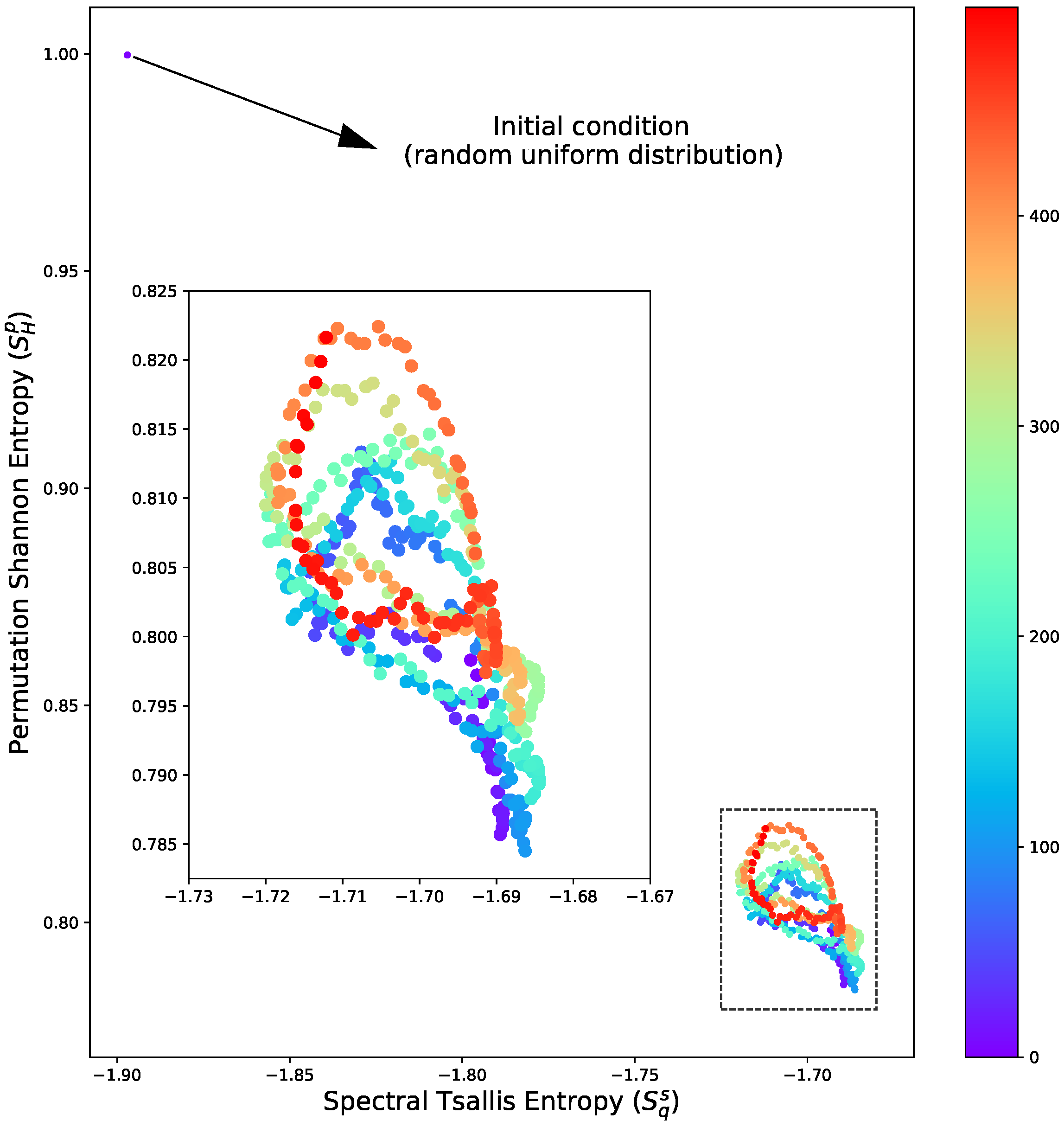
The analysis of entropy distribution is essential in a classification context, as it offers insights into the similarity between a new dataset and various models. However, carefully analysing the entropy metrics over time can highlight important aspects of the underlying physical processes. For instance, the transition from initial conditions to an oscillatory relaxation state is evident in
Figure 4. This outcome aligns with expectations in the context of the CGL system due to the periodic nature of the reaction term. However, it is essential to highlight that in this introductory study, we avoided simulations with more complex regimes (such as relaxations) as the primary purpose here is to present a new method, and the objective here is not to use it to deepen the physical interpretation of each process.
5. Outlook
Based on the study and approach presented here, we defined a methodological pipeline for the spatiotemporal characterization of simulated and/or observed complex processes (
Figure 5). The method can be applied to identify and segregate different classes of processes and to classify isolated patterns when necessary. In a context where measured and simulated data may exist, it also serves to validate models. Likewise, the pair of entropy measurements can also serve as a binomial label for training deep learning architectures for automatic classification.
6. Concluding Remarks
This work carried out a comprehensive analysis of entropy metrics and their application to complex extended nonlinear systems. The study explored new approaches, including different entropy measures and a new generalized silhouette score for measurement evaluation.
Through the meticulous consideration of canonical datasets, distinct patterns have been characterized in terms of entropy metrics. The pivotal finding was the identification of the optimal pair: spectral Tsallis entropy () and Shannon permutation entropy (), yielding superior outcomes in the generalized silhouette score. This combination showcased efficacy in distinguishing spatiotemporal dynamics coming from different classes of turbulent-like processes, including pure stochastic 2D (colored) noise.
The new method contributes valuable insights into applying entropy probabilistic measures, providing a foundation for future studies in terms of extended complex system pattern formation characterization.
Initial work considering entropy measurements for training machine learning models is underway. In this context, it also includes a study of the computational complexity of the method for a benchmark with other measures and approaches that may emerge. This strategy is fundamental when we think about the presented method being applied in a data science context.
Author Contributions
Conceptualization, R.R.R., L.O.B. and R.A.S.; methodology, R.R.R., L.O.B. and R.A.S.; software, L.O.B. and R.A.S.; validation, R.R.R., L.O.B., R.A.S., A.C.F. and E.L.R.; formal analysis, R.A.S. and L.O.B.; investigation, R.A.S. and L.O.B.; resources, R.R.R., L.O.B. and A.C.F.; data curation, E.L.R. and R.A.S.; writing—original draft preparation, R.R.R., L.O.B. and R.A.S.; writing—review and editing, R.R.R., L.O.B., R.A.S., A.C.F. and E.L.R.; visualization, L.O.B. and R.A.S.; supervision, R.R.R.; project administration, R.R.R.; funding acquisition, R.R.R., L.O.B., R.A.S. and A.C.F. All authors have read and agreed to the published version of the manuscript.
Funding
R.R.R. thanks FAPESP under Grant No. 2021/15114-8 for partial financial support. L.O. Barauna and R.A.S were supported by the Federal Brazilian Agency-CAPES. E.L.R. acknowledges financial support from CNPq (Brazil) under Grant No. 306920/2020-4. Te Herenga Waka–Victoria University of Wellington partially funded this publication through Read & Publish agreements negotiated by the Council of Australian University Librarians (CAUL) Consortium.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
All the mathematical content and data used in this work in a GitHub repository (
https://github.com/rsautter/Eta/ (14 January 2024)) to guarantee the reproducibility of this experiment.
Acknowledgments
The authors thank the Brazilian Space Agency (AEB) for the payment of APC (Article Processing Charge) costs.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Gradient Pattern Analysis
Gradient pattern analysis (GPA) represents a paradigm shift in data analysis, focusing on the spatiotemporal dynamics of information rather than static values. This innovative approach emphasizes the examination of gradients within datasets—dynamic vectors that encode the rate of change—thereby revealing patterns and structures that are often obscured by traditional analytical methods.
From a mathematical perspective, GPA utilizes a series of gradient moments to quantify the smoothness and alignment of these vectors within the data lattice:
and
where
and
are the connections in the Delaunay triangulation and the number of vertices;
is the number of asymmetrical vectors,
V is the total number of vectors in the lattice, and
is an asymmetrical vector;
and
, where
represents the modulus and
represents the phase and
These moments provide a distinctive signature that characterizes the inherent patterns in the data, and they are applicable across various domains. This versatility enables GPA’s application in diverse fields, ranging from time-series analysis in climatology to image recognition in computer vision.
One of the notable strengths of GPA is its capacity for efficient data compression. By discerning and eliminating redundant information while retaining the essential gradient characteristics, GPA achieves data compression without losing the dataset’s critical structural and dynamic properties. This aspect of GPA is particularly advantageous for storing, transmitting, and analysing large-scale datasets in numerous scientific and engineering disciplines. For a complete review, see Refs. [
18,
20].
Appendix B. Two-Dimensional Permutation Entropy
Based on the concept of permutation entropy [
29], two-dimensional multiscale sample entropy has been proposed as a new texture algorithm [
30,
31] and has therefore been used to evaluate the complexity of 2D patterns [
32]. In a simplified way, the technique is based on the following steps:
Step 1: Obtain the coarse-grained image as an matrix;
Step 2: Apply a window of size to it;
Step 3: Carry out reshape permutations to obtain the probabilities of each local pattern;
Step 4: Repeat the last procedure, scanning the entire matrix;
Step 5: Apply the probability values as input to the chosen entropy formula.
In our application, we use since it is the minimum kernel size encompassing a central pixel. This value corresponds to a kernel of .
References
- Tsallis, C. When may a system be referred to as complex? An entropic perspective. Front. Complex Syst. 2023, 1, 1284458. [Google Scholar] [CrossRef]
- Zhang, A.; Yang, B.; Huang, L. Feature Extraction of EEG Signals Using Power Spectral Entropy. In Proceedings of the International Conference on BioMedical Engineering and Informatics, Sanya, China, 27–30 May 2008. [Google Scholar]
- Raja Abdullah, R.S.A.; Saleh, N.L.; Syed Abdul Rahman, S.M.; Zamri, N.S.; Abdul Rashid, N.E. Texture classification using spectral entropy of acoustic signal generated by a human echolocator. Entropy 2019, 21, 963. [Google Scholar] [CrossRef]
- Mattedi, A.P.; Ramos, F.M.; Rosa, R.R.; Mantegna, R.N. Value-at-risk and Tsallis statistics: Risk analysis of the aerospace sector. Phys. A Stat. Mech. Its Appl. 2004, 344, 554–561. [Google Scholar] [CrossRef]
- Ramos, F.M.; Rosa, R.R.; Rodrigues Neto, C.; Bolzan, M.J.A.; Abren Sá, L.D. Nonextensive thermostatistics description of intermittency in turbulence and financial markets. Nonlinear Anal. Theory Methods Appl. 2001, 47, 3521–3530. [Google Scholar] [CrossRef]
- Ramos, F.M.; Bolzan, M.J.A.; Abreu Sá, L.D.; Rosa, R.R. Atmospheric turbulence within and above an Amazon forest. Phys. D Nonlinear Phenom. 2004, 193, 278–291. [Google Scholar] [CrossRef]
- Brissaud, J. The meanings of entropy. Entropy 2005, 7, 68–96. [Google Scholar] [CrossRef]
- Gotoh, T.; Kraichnan, R.H. Turbulence and Tsallis statistics. Physica D 2004, 193, 231–244. [Google Scholar] [CrossRef]
- Abdelsamie, A.; Janiga, G.; Thévenin, D. Spectral entropy as a flow state indicator. Int. J. Heat Fluid Flow 2017, 68, 102–113. [Google Scholar] [CrossRef]
- Mignone, A.; Bodo, G.; Massaglia, S.; Matsakos, T.; Tesileanu, O.; Zanni, C.; Ferrari, A. PLUTO: A numerical code for computational astrophysics. ApJS 2007, 170, 228–242. [Google Scholar] [CrossRef]
- Franci, L.; Hellinger, P.; Guarrasi, M.; Chen, C.H.K.; Papini, E.; Verdini, A.; Matteini, L.; Landi, S. Three-dimensional simulations of solar wind turbulence. J. Phys. Conf. Ser. 2018, 1031, 012002. [Google Scholar] [CrossRef]
- The Pencil Code Collaboration; Brandenburg, A.; Johansen, A.; Bourdin, P.A.; Dobler, W.; Lyra, W.; Rheinhardt, M.; Bingert, S.; Haugen, N.E.L.; Mee, A.; et al. The Pencil Code, a modular MPI code for partial differential equations and particles: Multipurpose and multiuser-maintained. J. Open Source Softw. 2021, 6, 2807. [Google Scholar]
- Veronese, T.B.; Rosa, R.R.; Bolzan, M.J.A.; Rocha Fernandes, F.C.; Sawant, H.S.; Karlicky, M. Fluctuation analysis of solar radio bursts associated with geoeffective X-class flares. J. Atmos. Sol.-Terr. Phys. 2011, 73, 1311–1316. [Google Scholar] [CrossRef]
- Bolzan, M.J.A.; Sahai, Y.; Fagundes, P.R.; Rosa, R.R.; Ramos, F.M.; Abalde, J.R. Intermittency analysis of geomagnetic storm time-series observed in Brazil. J. Atmos. Sol.-Terr. Phys. 2005, 67, 1365–1372. [Google Scholar] [CrossRef]
- Lu, H.; Lü, S.J.; Zhang, M.J. Fourier spectral approximations to the dynamics of 3D fractional complex Ginzburg-Landau equation. Discret. Contin. Dyn. Syst. 2017, 37, 2539–2564. [Google Scholar] [CrossRef]
- Pessa, A.A.B.; Ribeiro, H.V. ordpy: A Python package for data analysis with permutation entropy and ordinal network methods. Chaos Interdiscip. J. Nonlinear Sci. 2021, 31, 063110. [Google Scholar] [CrossRef]
- Xiong, P.Y.; Jahanshahi, H.; Alcarazc, R.; Chud, Y.M.; Gómez-Aguilar, J.F.; Alsaadi, F.E. Spectral Entropy Analysis and Synchronization of a Multi-Stable Fractional-Order Chaotic System using a Novel Neural Network-Based Chattering-Free Sliding Mode Technique. Chaos Solitons Fractals 2021, 144, 110576. [Google Scholar] [CrossRef]
- Ramos, F.M.; Rosa, R.R.; Rodrigues Neto, C.; Zanandrea, A. Generalized complex entropic form for gradient pattern analysis of spatio-temporal dynamics. Physica A 2000, 283, 171–174. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1998, 52, 479–487. [Google Scholar] [CrossRef]
- Rosa, R.R.; de Carvalho, R.R.; Sautter, R.A.; Barchi, P.H.; Stalder, D.H.; Moura, T.C.; Rembold, S.B.; Morell, D.R.F.; Ferreira, N.C. Gradient pattern analysis applied to galaxy morphology. Mon. Not. R. Astron. Soc. Lett. 2018, 477, L101–L105. [Google Scholar] [CrossRef]
- Lesne, A. Shannon entropy: A rigorous notion at the crossroads between probability, information theory, dynamical systems and statistical physics. Math. Struct. Comput. Sci. 2014, 24, e240311. [Google Scholar] [CrossRef]
- Li, C.; Shang, P. Multiscale Tsallis permutation entropy analysis for complex physiological time series. Physica A 2019, 523, 10–20. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P. Finding Groups in Data: An Introduction to Cluster Analysis; Wiley and Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Shutaywi, M.; Kachouie, N.N. Silhouette analysis for performance evaluation in machine learning with applications to clustering. Entropy 2021, 23, 759. [Google Scholar] [CrossRef] [PubMed]
- Timmer, J.; Koenig, M. On generating power law noise. Astron. Astrophys. 1995, 300, 707. [Google Scholar]
- Sautter, R.A. Gradient Pattern Analysis: Enhancements and Applications Including the Influence of Noise on Pattern Formation. Ph.D. Thesis, National Institute for Space Research, São José dos Campos, Brazil, 2023. [Google Scholar]
- Sautter, R.; Rosa, R.; Pontes, J. Incremental Gradient Pattern Analysis of Stochastic Complex Ginzburg-Landau Dynamics; ResearchGate: Berlin, Germany, 2023. [Google Scholar] [CrossRef]
- Li, Y.; Perlman, E.; Wan, M.; Yang, Y.; Meneveau, C.; Burns, R.; Chen, S.; Szalay, A.; Eyink, E. A public turbulence database cluster and applications to study Lagrangian evolution of velocity increments in turbulence. J. Turbul. 2008, 9, N31. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Silva, L.; Duque, J.; Felipe, J.; Murta, L.; Humeau-Heurtier, A. Two-dimensional multiscale entropy analysis: Applications to image texture evaluation. Signal Process. 2018, 147, 224–232. [Google Scholar] [CrossRef]
- Humeau-Heurtier, A.; Omoto, A.C.M.; Silva, L.E. Bi-dimensional multiscale entropy: Relation with discrete Fourier transform and biomedical application. Comput. Biol. Med. 2018, 100, 36–40. [Google Scholar] [CrossRef]
- Morel, C.; Humeau-Heurtier, A. Multiscale permutation entropy for two-dimensional patterns. Pattern Reg. Lett. 2021, 150, 139–146. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}