
Bitcoin Money Laundering Detection via Subgraph Contrastive Learning


Abstract
1. Introduction
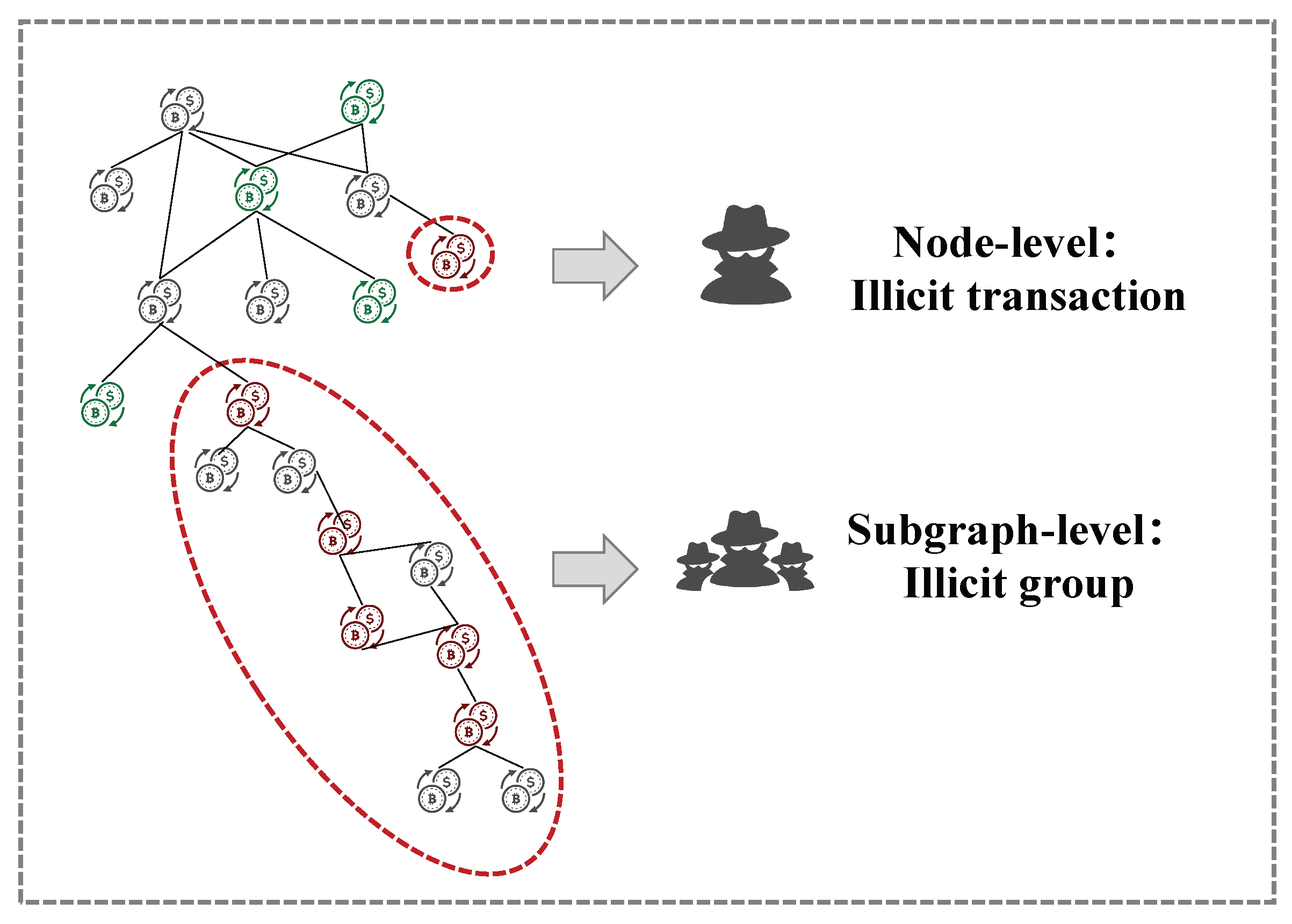
- Organized. Money laundering is usually an organized behavior while current algorithms in Bitcoin mainly focus on node-level detection. Therefore, it is a challenge to come up with an algorithm that detects money laundering groups directly. A large number of disclosed large-scale cryptocurrency money laundering cases (e.g., 1MDB [21] and Danske Bank scandal [22]) show that money laundering activities typically exhibit scale and organizational characteristics. As shown in Figure 1, node-level detection methods can identify individual nodes as potential illicit transactions. However, they ignore the relationships and interactions between nodes. In contrast, subgraph-level detection methods consider the topology between nodes and attempt to identify subgraphs with similar transaction patterns, such as frequent fund transfers and lengthy transaction chains.
- Heterogeneous. Although GNN-based illicit transaction detection techniques have achieved significant success, most of them are focused on homogeneous graphs, i.e., transaction record graph [20] or wallet address graph [23] in the upper-left corner of Figure 2. In reality, heterogeneity is an inherent characteristic of cryptocurrency transaction networks [24]. Specifically, the wallet address and transaction records together form the graph, as depicted in the top-left corner of Figure 2. Heterogeneity increases the complexity of data mining, leading to a more intricate risk identification process.
- Noisy. Despite the significant differences in behavioral patterns between licit and illicit transactions, real-world transactions often exhibit a notable amount of noise, including erroneous transactions and intentionally disruptive transactions initiated by money launderers to obfuscate their activities [25]. As a result, these noises can lead to an unclear distinction in the transaction topology.

- This work focuses on mining transaction patterns in subgraphs. We have discovered that the tree structure, as typical transaction patterns, can serve as a representative structure for distinguishing money laundering from non-money laundering activities.
- To the best of our knowledge, we are the first to propose a subgraph detection model based on graph contrastive learning methods in the field of cryptocurrency money laundering detection.
- Experimental results demonstrate the effectiveness of the Bit-CHetG models by integrating various money laundering detection models such as random forest [28], GCN [16], inspection-L [29], SubGNN [30], Tsgn [31], HAN [32], and MAGNN [33]. The comparison algorithms cover the latest graph-based money laundering detection algorithms in Bitcoin, subgraph classification algorithms, and heterogeneous graph classification algorithms. In particular, the Micro F1 Score of our proposed Bit_CHetG is improved by at least 5%.
2. Related Works
2.1. Money Laundering Detection in Cryptocurrency
2.2. Subgraph-Based Representation in Cryptocurrency
3. Problem
4. Proposed Method
4.1. Transaction Subgraph Embedding
4.1.1. Transaction Subgraph Sampling
- When generating the illicit subgraph, we start with an illicit transaction node and expand it by n hops. If all terminal nodes are licit, the process stops; otherwise, continue expanding by n hops.
- When generating a licit subgraph, we initiate the process from a licit transaction node and stop the extension after n hops. However, if the generated subgraph contains any illicit nodes, it is considered to be illicit. This condition ensures that the generated licit subgraph maintains its legality.
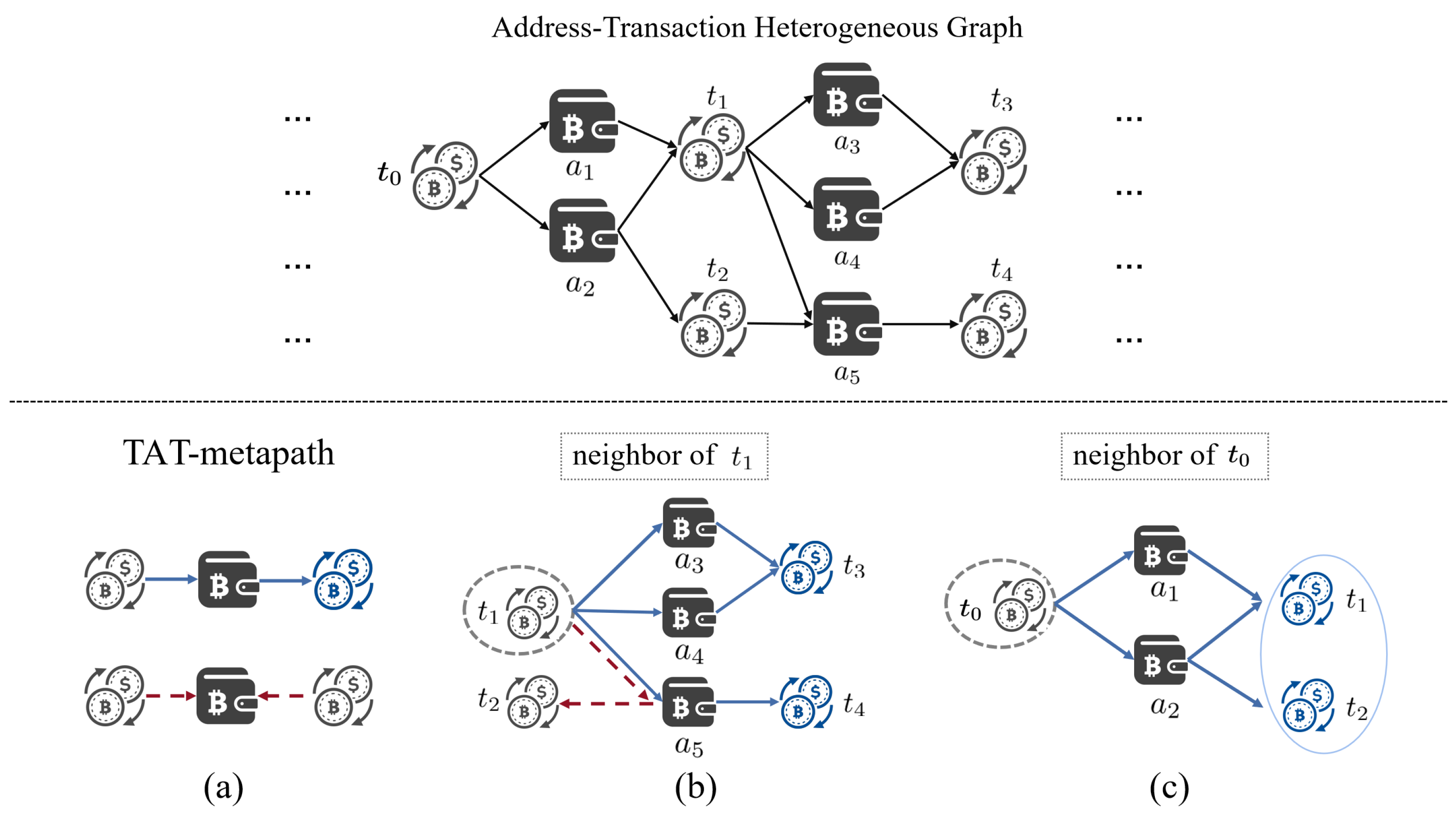
- Step 1: Given a target transaction node t as the parent node p, add the 1-hop neighborhood set of node t based on the TAT-metapath into the node set of the subgraph . The edges between node t and the nodes in the neighborhood set are added to the edge set of the subgraph. As shown by the subgraph sampling process framed by the dashed line in the bottom-left corner of Figure 4, the first generated subgraph contains the parent node framed in blue, as well as 1-hop neighbor nodes.
- Step 2: Randomly select a node from the 1-hop neighborhood set with a certain probability and extend the subgraph according to Step 1 with this node as the new parent node. This process generates the second subgraph and third subgraph shown in the subgraph sampling dashed line of Figure 4. If all the neighbor nodes have been traversed, continue to extend to the next level until the number of nodes in the node-set reaches a fixed number N.
4.1.2. Topology Feature Embedding
4.2. Address Feature Aggregation
- Step1: Identify the target node. Firstly, designate as the target transaction node for the AFA module, and add to the node set , highlighted by the red dashed box in Figure 4.
- Step2: Determine the edge set and node set. Traverse the node and edge sets in the address–transaction heterogeneous graph. Add all one-hop neighbor address nodes of the target node to the node set . These address nodes are connected through the ATA-metapath. The edge set consists of edges connecting the target node and the address nodes, without distinguishing the direction of edges.
4.3. Feature Fusion
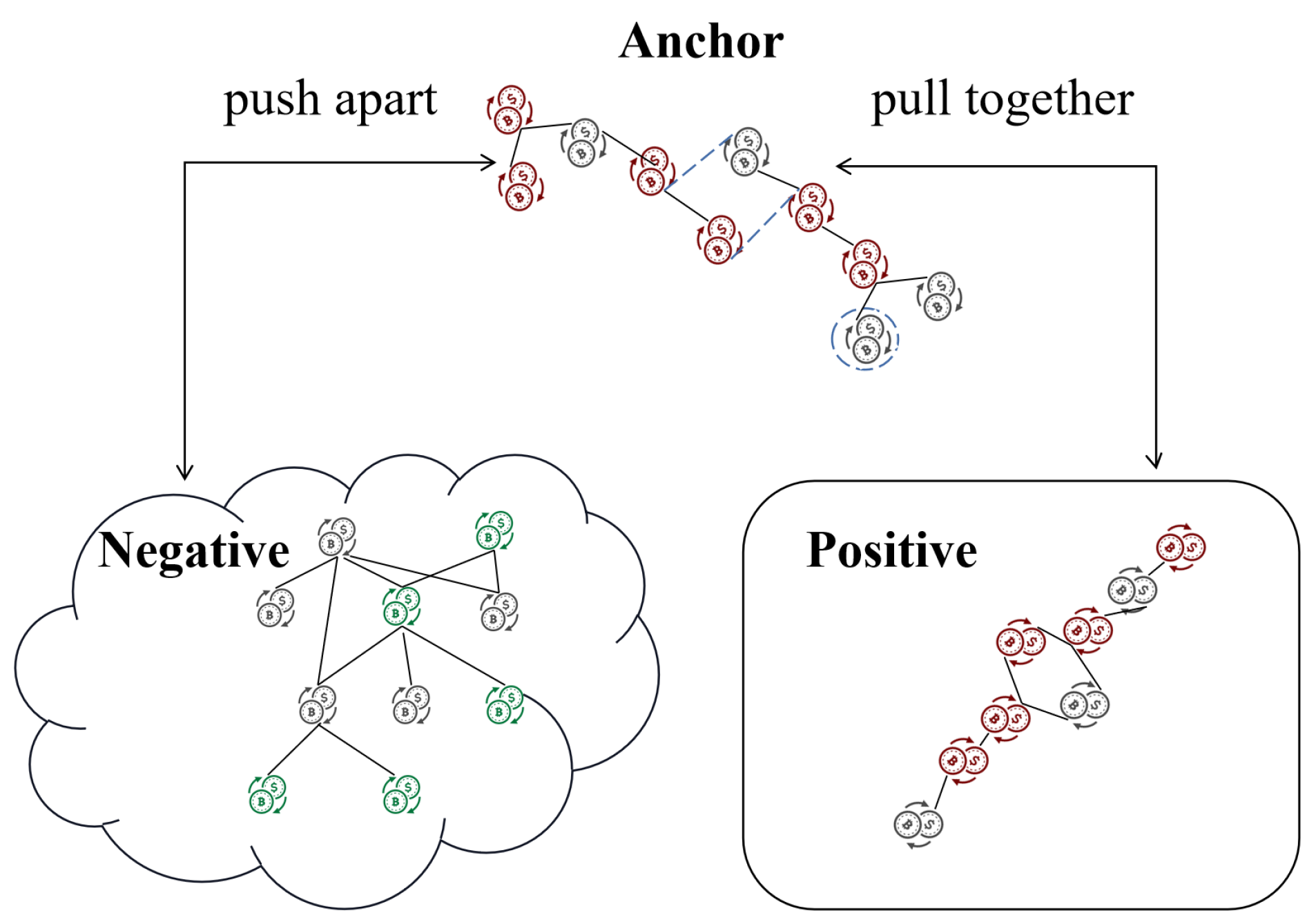
4.4. Contrastive Learning
5. Experiment
5.1. Experimental Setup
5.1.1. Datasets
5.1.2. Comparison Algorithms
5.2. Mining Tree-Structured Subgraphs
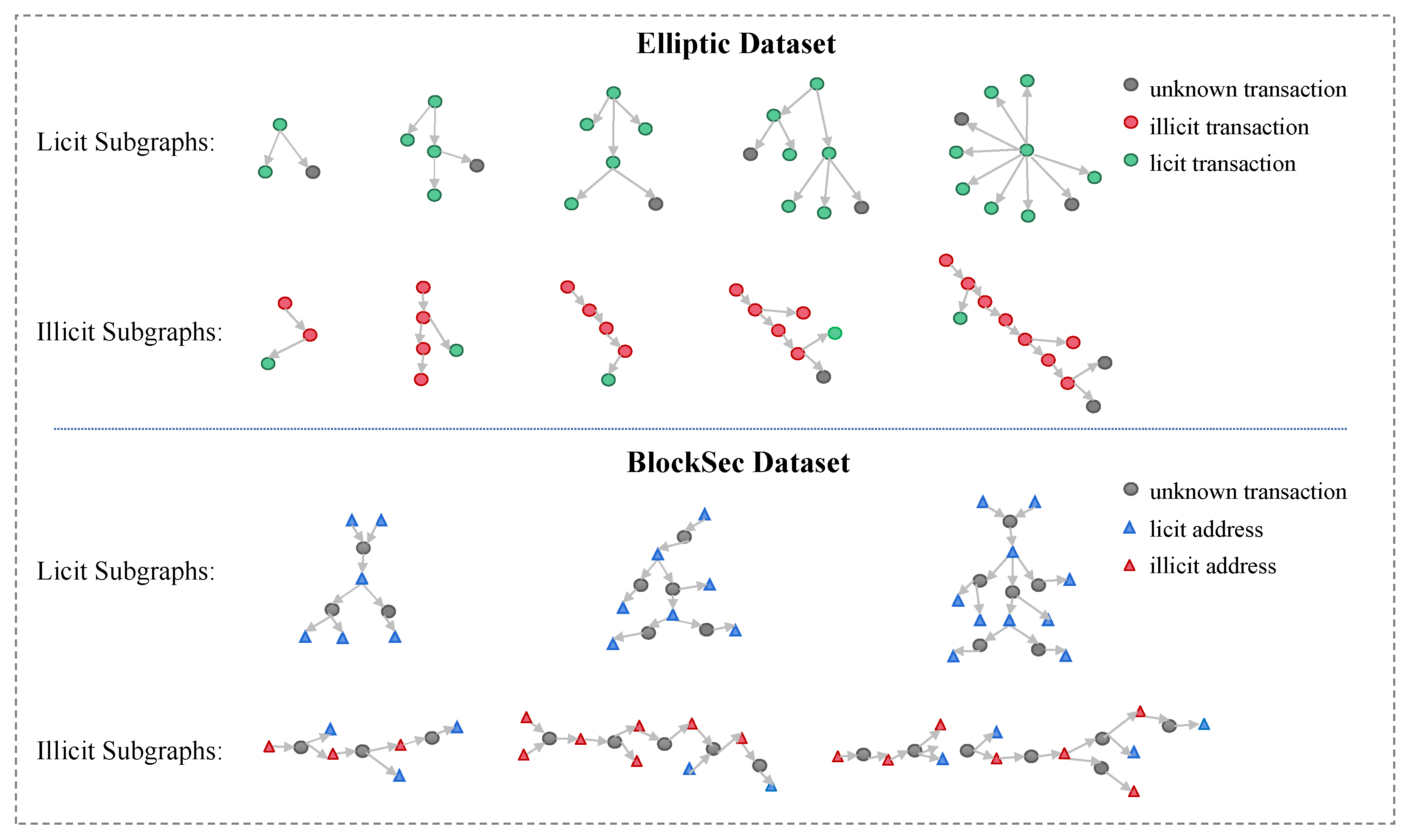
- There is a significant difference between the illicit and licit subgraphs. The distribution of licit transaction trees is more centralized, similar to a network-like structure, while the distribution of illicit transaction trees is more dispersed, similar to a chain-like structure. This suggests that illicit and licit transactions exhibit different topologies and that the tree-like subgraph generation method can effectively distinguish between money laundering and non-money laundering transaction patterns.
- In the set of illicit subgraphs, there are continuous money laundering chains in the transaction network. Therefore, identifying individual illicit nodes can be of great help in the subsequent tracking of illicit groups.
5.3. Experimental Results
- Bit-CHetG selects the appropriate subgraph sampling structure. As shown in Section 5.2, we have chosen the tree structure as the detection unit. The results of Bit-CHetG (polytree) in Table 3 and Table 4 show that the polytree structure as subgraph is inferior to the tree structure. This is because the polytree contains more interaction information which leads to interference in recognizing illicit and licit patterns.
- Bit-CHetG introduces a contrastive loss in addition to the original regression loss. As shown in the results of Bit-CHetG (Reg) as well as Bit-CHetG (Reg + Cl + Aug) in Table 3 and Table 4, contrastive learning and graph augmentation help the model better learn the commonalities between the same samples and the differences between different samples and thus generates high-quality feature representations.
- Bit-CHetG employs a flexible data augmentation strategy. By randomly adding or removing edges, we can simulate erroneous transactions or transactions deliberately interfered with by money launderers to conceal their activities. By simulating the noise during transactions through data augmentation, the results of Bit-CHetG (Reg + Cl + Aug) in Table 3 and Table 4 are more robust than those of Bit-CHetG (Reg + Cl).
- Bit-CHetG purposefully designed Metapaths. For UTXO, the smallest trading unit of Bitcoin, we design ATA-Metapath and TAT-Metapath to directly detect money laundering groups. Compared with the above comparison algorithms that acquire node characterization before applying it to downstream tasks, our approach significantly improves the effectiveness.
5.4. Ablation Study
- The introduction of contrastive learning in the Bit-CHetG model yields significant improvements over Bit-CHetG_NC. Specifically, Micro-Prec., Micro-Rec., and Micro-F1 increased by 5.8%, 2.5%, and 4.3%, respectively, highlighting the beneficial impact of contrastive learning.
- In comparison to Bit-CHetG, the Micro-Prec., Micro-Rec., and Micro-F1 of Bit-CHetG_NA decreased by 3.2%, 1.4%, and 2.3%, respectively. When contrastive learning is directly applied to the transaction graph without auxiliary account information, the model achieves only moderate predictive accuracy.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Micro-Prec. | Micro-Rec. | Micro-F1 |
|---|---|---|---|
| Bit-CHetG | 0.825 1 | 0.760 1 | 0.815 1 |
| Bit-CHetG_NC | 0.767 | 0.735 | 0.772 |
| Bit-CHetG_NA | 0.793 | 0.746 | 0.792 |
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Mukhopadhyay, U.; Skjellum, A.; Hambolu, O.; Oakley, J.; Yu, L.; Brooks, R. A brief survey of cryptocurrency systems. In Proceedings of the 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 745–752. [Google Scholar]
- Chainalysis. The Chainalysis 2023 Crypto Crime Report. 2023. Available online: https://go.chainalysis.com/rs/503-FAP-074/images/Crypto_Crime_Report_2023.pdf (accessed on 23 January 2024).
- Chen, Z.; Van Khoa, L.D.; Teoh, E.N.; Nazir, A.; Karuppiah, E.K.; Lam, K.S. Machine learning techniques for anti-money laundering (AML) solutions in suspicious transaction detection: A review. Knowl. Inf. Syst. 2018, 57, 245–285. [Google Scholar] [CrossRef]
- Financial Action Task Force. Updated Guidance for a Risk-Based Approach to Virtual Assets and Virtual Asset Service Providers. 2021. Available online: https://www.fatf-gafi.org/en/publications/Fatfrecommendations/Guidance-rba-virtual-assets-2021.html (accessed on 23 January 2024).
- Hallak, I. Markets in Crypto-Assets (MiCA); European Parliament Research Service: London, UK, 2022; Available online: https://www.europarl.europa.eu/RegData/etudes/ATAG/2023/745716/EPRS_ATA(2023)745716_EN.pdf (accessed on 23 January 2024).
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://www.ussc.gov/sites/default/files/pdf/training/annual-national-training-seminar/2018/Emerging_Tech_Bitcoin_Crypto.pdf (accessed on 23 January 2024).
- Tiwari, M.; Gepp, A.; Kumar, K. A review of money laundering literature: The state of research in key areas. Pac. Account. Rev. 2020, 32, 271–303. [Google Scholar] [CrossRef]
- Rajput, Q.; Khan, N.S.; Larik, A.; Haider, S. Ontology based expert-system for suspicious transactions detection. Comput. Inf. Sci. 2014, 7, 103. [Google Scholar] [CrossRef]
- Jourdan, M.; Blandin, S.; Wynter, L.; Deshpande, P. Characterizing entities in the bitcoin blockchain. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 55–62. [Google Scholar]
- Liang, J.; Li, L.; Chen, W.; Zeng, D. Targeted addresses identification for bitcoin with network representation learning. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI), Shenzhen, China, 1–3 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 158–160. [Google Scholar]
- Toyoda, K.; Mathiopoulos, P.T.; Ohtsuki, T. A novel methodology for hyip operators’ bitcoin addresses identification. IEEE Access 2019, 7, 74835–74848. [Google Scholar] [CrossRef]
- Ranshous, S.; Joslyn, C.A.; Kreyling, S.; Nowak, K.; Samatova, N.F.; West, C.L.; Winters, S. Exchange pattern mining in the bitcoin transaction directed hypergraph. In Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2017; pp. 248–263. [Google Scholar]
- Monamo, P.; Marivate, V.; Twala, B. Unsupervised learning for robust Bitcoin fraud detection. In Proceedings of the 2016 Information Security for South Africa (ISSA), Johannesburg, South Africa, 17–18 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 129–134. [Google Scholar]
- Nan, L.; Tao, D. Bitcoin mixing detection using deep autoencoder. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 280–287. [Google Scholar]
- Hu, Y.; Seneviratne, S.; Thilakarathna, K.; Fukuda, K.; Seneviratne, A. Characterizing and detecting money laundering activities on the bitcoin network. arXiv 2019, arXiv:1912.12060. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Alarab, I.; Prakoonwit, S.; Nacer, M.I. Competence of graph convolutional networks for anti-money laundering in bitcoin blockchain. In Proceedings of the 2020 5th International Conference on Machine Learning Technologies, Beijing, China, 19–21 June 2020; pp. 23–27. [Google Scholar]
- Han, H.; Wang, R.; Chen, Y.; Xie, K.; Zhang, K. Research on Abnormal Transaction Detection Method for Blockchain. In Proceedings of the International Conference on Blockchain and Trustworthy Systems, Chengdu, China, 4–5 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 223–236. [Google Scholar]
- Alarab, I.; Prakoonwit, S. Graph-based lstm for anti-money laundering: Experimenting temporal graph convolutional network with bitcoin data. Neural Process. Lett. 2023, 55, 689–707. [Google Scholar] [CrossRef]
- Weber, M.; Domeniconi, G.; Chen, J.; Weidele, D.K.I.; Bellei, C.; Robinson, T.; Leiserson, C. Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Jones, D.S. 1MDB corruption scandal in Malaysia: A study of failings in control and accountability. Public Adm. Policy 2020, 23, 59–72. [Google Scholar] [CrossRef]
- Bjerregaard, E.; Kirchmaier, T. The Danske Bank money laundering scandal: A case study. SSRN Electron. J. 2019. [Google Scholar] [CrossRef]
- Xiang, Y.; Li, T.; Li, Y. Leveraging Subgraph Structure for Exploration and Analysis of Bitcoin Address. In Proceedings of the 2022 IEEE International Conference on Big Data, Osaka, Japan, 17–20 December 2022; pp. 1957–1962. [Google Scholar]
- Wang, X.; Bo, D.; Shi, C.; Fan, S.; Ye, Y.; Philip, S.Y. A survey on heterogeneous graph embedding: Methods, techniques, applications and sources. IEEE Trans. Big Data 2022, 9, 415–436. [Google Scholar] [CrossRef]
- Tsang, K.P.; Yang, Z. The market for bitcoin transactions. J. Int. Financ. Mark. Inst. Money 2021, 71, 101282. [Google Scholar] [CrossRef]
- Lin, C.Y.; Liao, H.K.; Tsai, F.C. A systematic review of detecting illicit bitcoin transactions. Procedia Comput. Sci. 2022, 207, 3217–3225. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Rigatti, S.J. Random forest. J. Insur. Med. 2017, 47, 31–39. [Google Scholar] [CrossRef]
- Lo, W.W.; Kulatilleke, G.K.; Sarhan, M.; Layeghy, S.; Portmann, M. Inspection-L: Self-supervised GNN node embeddings for money laundering detection in bitcoin. Appl. Intell. 2023, 53, 19406–19417. [Google Scholar] [CrossRef]
- Alsentzer, E.; Finlayson, S.; Li, M.; Zitnik, M. Subgraph neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 8017–8029. [Google Scholar]
- Wang, J.; Chen, P.; Xu, X.; Wu, J.; Shen, M.; Xuan, Q.; Yang, X. Tsgn: Transaction subgraph networks assisting phishing detection in ethereum. arXiv 2022, arXiv:2208.12938. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar]
- Li, X.; Cao, X.; Qiu, X.; Zhao, J.; Zheng, J. Intelligent anti-money laundering solution based upon novel community detection in massive transaction networks on spark. In Proceedings of the 2017 Fifth International Conference on Advanced Cloud and Big Data (CBD), Shanghai, China, 13–16 August 2017; pp. 176–181. [Google Scholar]
- Heidarinia, N.; Harounabadi, A.; Sadeghzadeh, M. An intelligent anti-money laundering method for detecting risky users in the banking systems. Int. J. Comput. Appl. 2014, 97, 35–39. [Google Scholar] [CrossRef]
- Zhou, F.; Chen, Y.; Zhu, C.; Jiang, L.; Liao, X.; Zhong, Z.; Chen, X.; Chen, Y.; Zhao, Y. Visual analysis of money laundering in cryptocurrency exchange. IEEE Trans. Comput. Soc. Syst. 2023, 11, 731–745. [Google Scholar] [CrossRef]
- Camino, R.D.; State, R.; Montero, L.; Valtchev, P. Finding suspicious activities in financial transactions and distributed ledgers. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 787–796. [Google Scholar]
- Toyoda, K.; Ohtsuki, T.; Mathiopoulos, P.T. Time series analysis for bitcoin transactions: The case of pirate@ 40’s hyip scheme. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 151–155. [Google Scholar]
- Pham, T.; Lee, S. Anomaly detection in the bitcoin system-a network perspective. arXiv 2016, arXiv:1611.03942. [Google Scholar]
- Bielinskyi, A.O.; Serdyuk, O.A. Econophysics of cryptocurrency crashes: A systematic review. In Proceedings of the 9th International Conference on Monitoring, Modeling & Management of Emergent Economy (M3E2-MLPEED 2021), Odesa, Ukraine, 26–28 May 2021. [Google Scholar]
- Bein, B. Entropy. Best Pract. Res. Clin. Anaesthesiol. 2006, 20, 101–109. [Google Scholar] [CrossRef]
- Liu, F.; Fan, H.Y.; Qi, J.Y. Blockchain technology, cryptocurrency: Entropy-based perspective. Entropy 2022, 24, 557. [Google Scholar] [CrossRef] [PubMed]
- Hassan, M.U.; Rehmani, M.H.; Chen, J. Anomaly detection in blockchain networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2022, 25, 289–318. [Google Scholar] [CrossRef]
- Barbará, D.; Li, Y.; Couto, J. COOLCAT: An entropy-based algorithm for categorical clustering. In Proceedings of the Eleventh International Conference on Information and Knowledge Management, McLean, VI, USA, 4–9 November 2002; pp. 582–589. [Google Scholar]
- Lorenz, J.; Silva, M.I.; Aparício, D.; Ascensão, J.T.; Bizarro, P. Machine learning methods to detect money laundering in the bitcoin blockchain in the presence of label scarcity. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–8. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Elliptic. Available online: https://www.elliptic.co/ (accessed on 23 January 2024).
- Cai, L.; Chen, Z.; Luo, C.; Gui, J.; Ni, J.; Li, D.; Chen, H. Structural temporal graph neural networks for anomaly detection in dynamic graphs. In Proceedings of the 30th ACM international conference on Information & Knowledge Management, Virtual Event, 1–5 November 2021; pp. 3747–3756. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1725–1735. [Google Scholar]
- Dou, Y.; Liu, Z.; Sun, L.; Deng, Y.; Peng, H.; Yu, P.S. Enhancing graph neural network-based fraud detectors against camouflaged fraudsters. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 315–324. [Google Scholar]
- Farrugia, S.; Ellul, J.; Azzopardi, G. Detection of illicit accounts over the Ethereum blockchain. Expert Syst. Appl. 2020, 150, 113318. [Google Scholar] [CrossRef]
- Qi, Y.; Wu, J.; Xu, H.; Guizani, M. Blockchain Data Mining With Graph Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 729–748. [Google Scholar] [CrossRef] [PubMed]
- Di Francesco Maesa, D.; Marino, A.; Ricci, L. Data-driven analysis of bitcoin properties: Exploiting the users graph. Int. J. Data Sci. Anal. 2018, 6, 63–80. [Google Scholar] [CrossRef]
- Tao, B.; Dai, H.N.; Wu, J.; Ho, I.W.H.; Zheng, Z.; Cheang, C.F. Complex Network Analysis of the Bitcoin Transaction Network. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1009–1013. [Google Scholar] [CrossRef]
- Akcora, C.G.; Dey, A.K.; Gel, Y.R.; Kantarcioglu, M. Forecasting bitcoin price with graph chainlets. In Advances in Knowledge Discovery and Data Mining, Proceedings of the 22nd Pacific-Asia Conference, PAKDD 2018, Melbourne, VIC, Australia, 3–6 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 765–776. [Google Scholar]
- Moreno-Sanchez, P.; Modi, N.; Songhela, R.; Kate, A.; Fahmy, S. Mind your credit: Assessing the health of the ripple credit network. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 329–338. [Google Scholar]
- Wu, J.; Liu, J.; Chen, W.; Huang, H.; Zheng, Z.; Zhang, Y. Detecting mixing services via mining bitcoin transaction network with hybrid motifs. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 2237–2249. [Google Scholar] [CrossRef]
- Chiang, W.L.; Liu, X.; Si, S.; Li, Y.; Bengio, S.; Hsieh, C.J. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 257–266. [Google Scholar]
- Qiu, J.; Chen, Q.; Dong, Y.; Zhang, J.; Yang, H.; Ding, M.; Wang, K.; Tang, J. Gcc: Graph contrastive coding for graph neural network pre-training. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 1150–1160. [Google Scholar]
- Hassani, K.; Khasahmadi, A.H. Contrastive multi-view representation learning on graphs. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 4116–4126. [Google Scholar]
- BlockSec. Available online: https://blocksec.com/ (accessed on 23 January 2024).
- Navarin, N.; Van Tran, D.; Sperduti, A. Universal readout for graph convolutional neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, X.F.; Jiang, X.J.; Liu, S.H.; Tse, C.K. Knowledge discovery in cryptocurrency transactions: A survey. IEEE Access 2021, 9, 37229–37254. [Google Scholar] [CrossRef]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Available online: https://www.blockchain.com/ (accessed on 23 January 2024).



| Notation | Definition |
|---|---|
| Address–transaction heterogeneous graph | |
| Set of transaction subgraphs | |
| Set of associated address subgraphs | |
| Two types of metapaths: or | |
| One type of metapath: | |
| The embedding matrix of transaction subgraph under | |
| The topological embedding representation of transaction node t under | |
| The embedding matrix of associated address subgraph under | |
| The associated address representation of the central transaction node t under | |
| The node-level fusion feature vector for transaction node t | |
| The graph-level fusion feature vector for the m-th transaction subgraph |
| Dataset | Number of Transactions | Number of Addresses | Number of Subgraphs | Size of Transaction Subgraph |
|---|---|---|---|---|
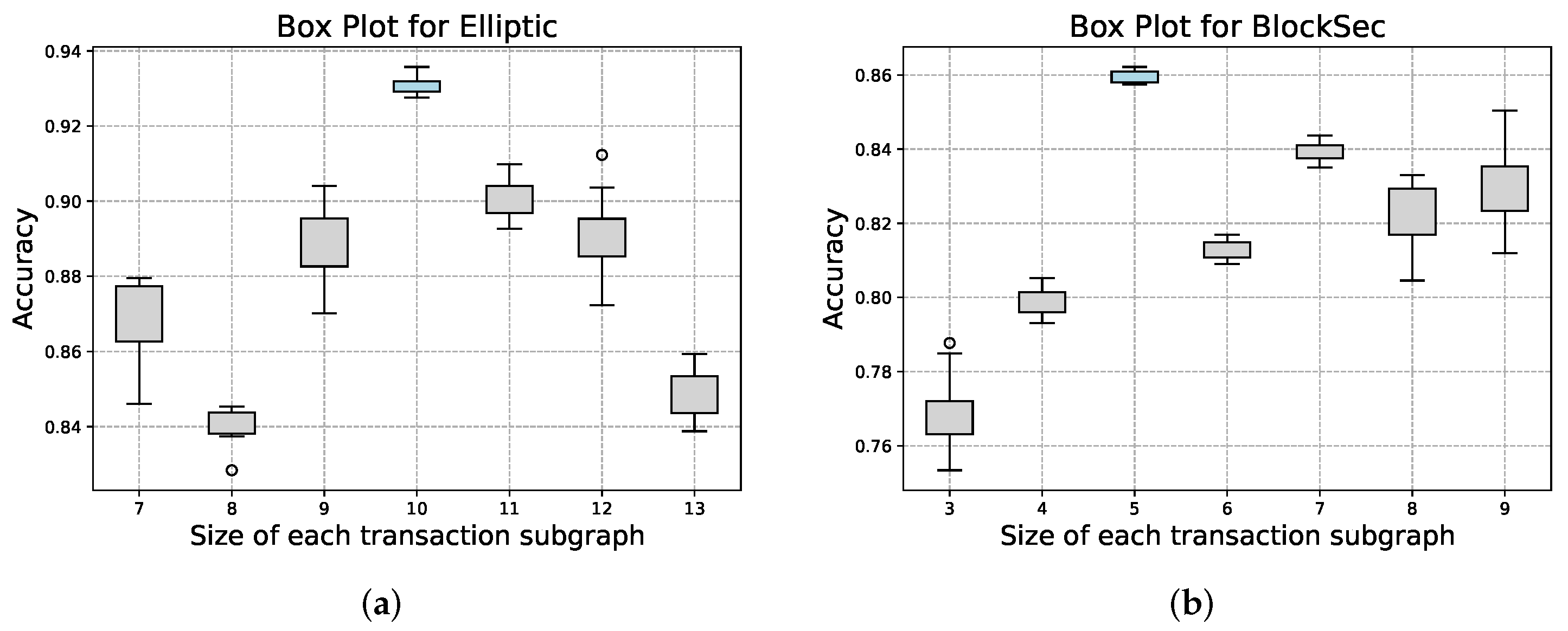
| Elliptic | 203,769 | None | 24,533 | 10 |
| BlockSec | 16,674,890 | 100,061 | 16,583 | 5 |
| Methods | Micro-Prec. | Micro-Rec. | Micro-F1 |
|---|---|---|---|
| Random forest | 0.803 | 0.711 | 0.694 |
| GCN | 0.812 | 0.801 | 0.799 |
| Inspection-L | 0.869 | 0.836 | 0.851 |
| SubGNN | 0.865 | 0.843 | 0.858 |
| Tsgn | 0.879 | 0.854 | 0.867 |
| Bit-CHetG (Reg + Cl + Aug) | 0.905 | 0.893 1 | 0.919 1 |
| Bit-CHetG (Reg + Cl) | 0.914 1 | 0.872 | 0.889 |
| Bit-CHetG (Reg) | 0.873 | 0.851 | 0.869 |
| Bit-CHetG (polytree) | 0.871 | 0.841 | 0.858 |
| Methods | Micro-Prec. | Micro-Rec. | Micro-F1 |
|---|---|---|---|
| GCN | 0.701 | 0.696 | 0.699 |
| SubGNN | 0.742 | 0.712 | 0.722 |
| Tsgn | 0.749 | 0.723 | 0.741 |
| HAN | 0.742 | 0.712 | 0.718 |
| MAGNN | 0.751 | 0.736 | 0.745 |
| Bit-CHetG (Reg + Cl + Aug) | 0.825 1 | 0.760 | 0.815 1 |
| Bit-CHetG (Reg + Cl) | 0.807 | 0.772 1 | 0.802 |
| Bit-CHetG (Reg) | 0.791 | 0.751 | 0.789 |
| Bit-CHetG (polytree) | 0.771 | 0.740 | 0.758 |
| k2 | 1 | 2 | 3 | |
| k1 | ||||
| 1 | 0.81 | 0.84 | 0.82 | |
| 2 | 0.82 | 0.86 1 | 0.84 | |
| 3 | 0.81 | 0.83 | 0.85 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, S.; Bai, Q.; Feng, H.; Hu, B. Bitcoin Money Laundering Detection via Subgraph Contrastive Learning. Entropy 2024, 26, 211. https://doi.org/10.3390/e26030211
Ouyang S, Bai Q, Feng H, Hu B. Bitcoin Money Laundering Detection via Subgraph Contrastive Learning. Entropy. 2024; 26(3):211. https://doi.org/10.3390/e26030211
Chicago/Turabian StyleOuyang, Shiyu, Qianlan Bai, Hui Feng, and Bo Hu. 2024. "Bitcoin Money Laundering Detection via Subgraph Contrastive Learning" Entropy 26, no. 3: 211. https://doi.org/10.3390/e26030211
APA StyleOuyang, S., Bai, Q., Feng, H., & Hu, B. (2024). Bitcoin Money Laundering Detection via Subgraph Contrastive Learning. Entropy, 26(3), 211. https://doi.org/10.3390/e26030211