
Enhanced Heterogeneous Graph Attention Network with a Novel Multilabel Focal Loss for Document-Level Relation Extraction


Abstract
1. Introduction
- We propose a two-stage mention-level framework for document-level relation extraction, which constructs a dependency-tree-based mention-aware heterogeneous graph and adopts different strategies for intra-sentential and inter-sentential relation prediction.
- For inter-sentential relation prediction and inference, we propose an enhanced heterogeneous graph attention network to better model long-distance semantic relationships and design an entity-coreference path-based inference strategy to conduct relation inference.
- We introduce a novel cross-entropy-based multilabel focal loss function to address the class imbalance problem and multilabel prediction simultaneously.
- Comprehensive experiments have been conducted to verify the effectiveness of our framework. Experimental results show that our approach significantly outperforms the existing methods.
2. Related Work
3. Methodology
3.1. Task Formulation
3.2. Model Architecture
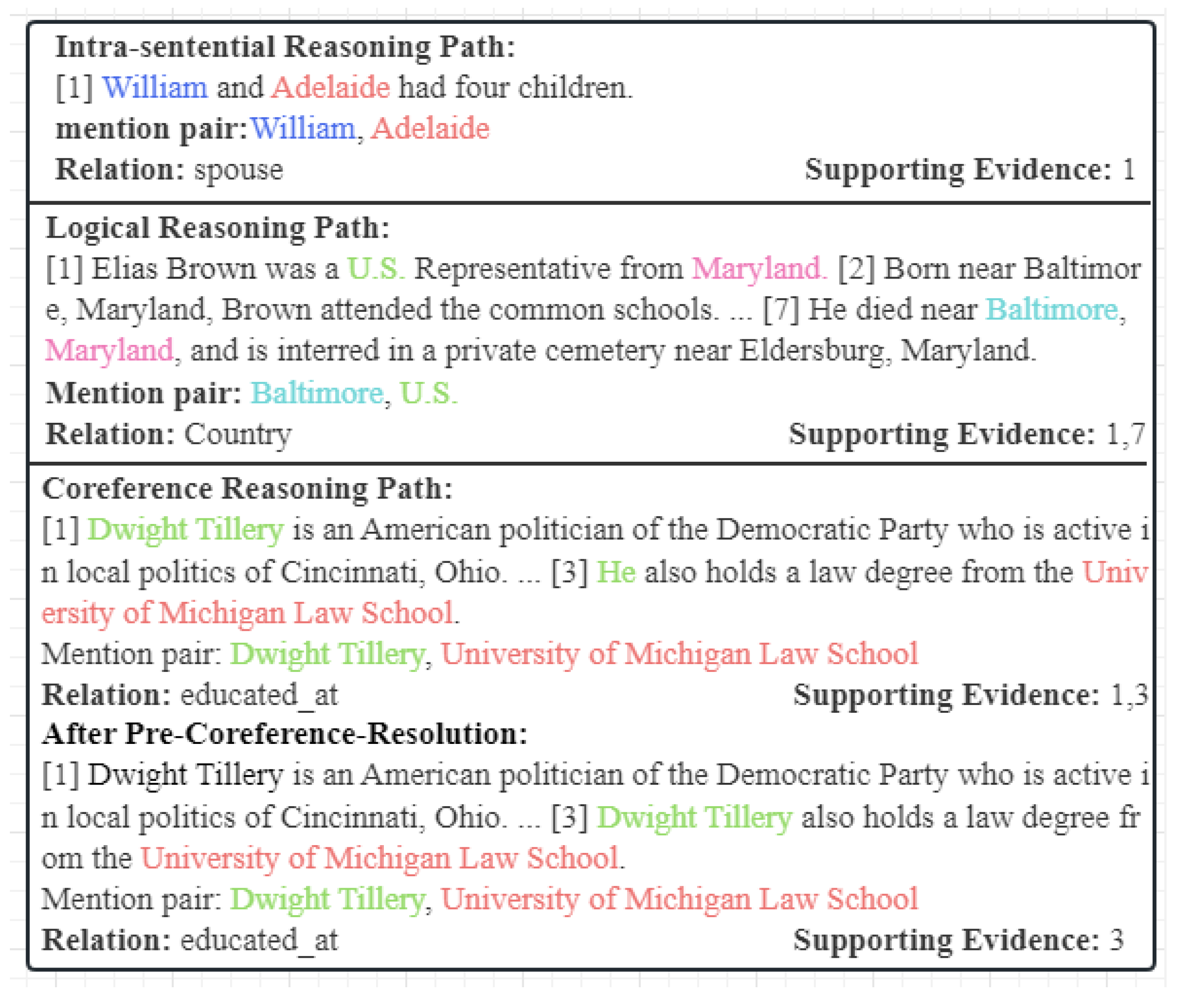
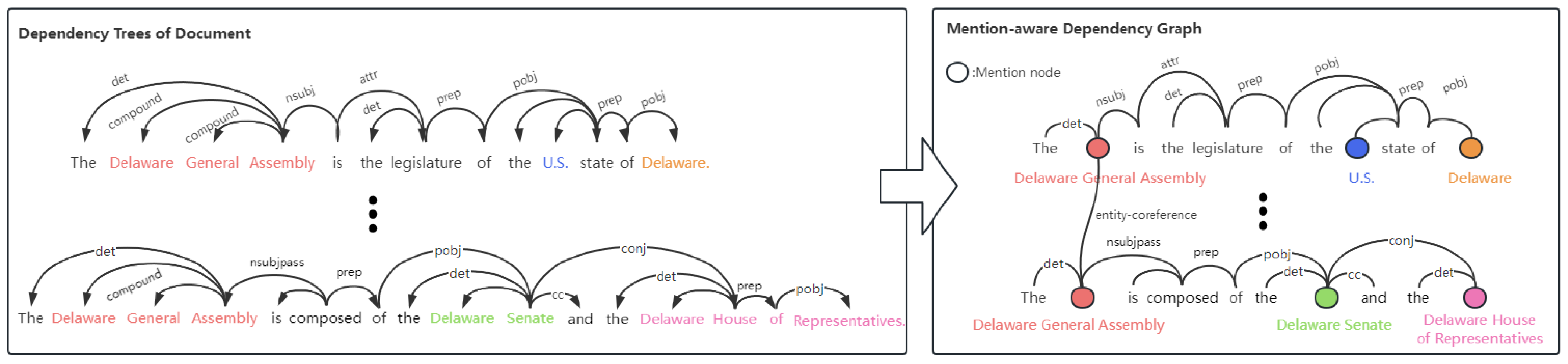
3.2.1. Pre-Coreference-Resolution
3.2.2. Mention-Aware Dependency Graph Construction
3.2.3. Context Encoder
3.2.4. Enhanced Heterogeneous Graph Attention Network
3.2.5. Relation Classification
3.2.6. Multilabel Focal Loss Function
4. Experiments
4.1. Dataset
4.2. Baseline Methods
4.3. Implementation Details
4.4. Experimental Result
5. Analysis
5.1. Ablation Study
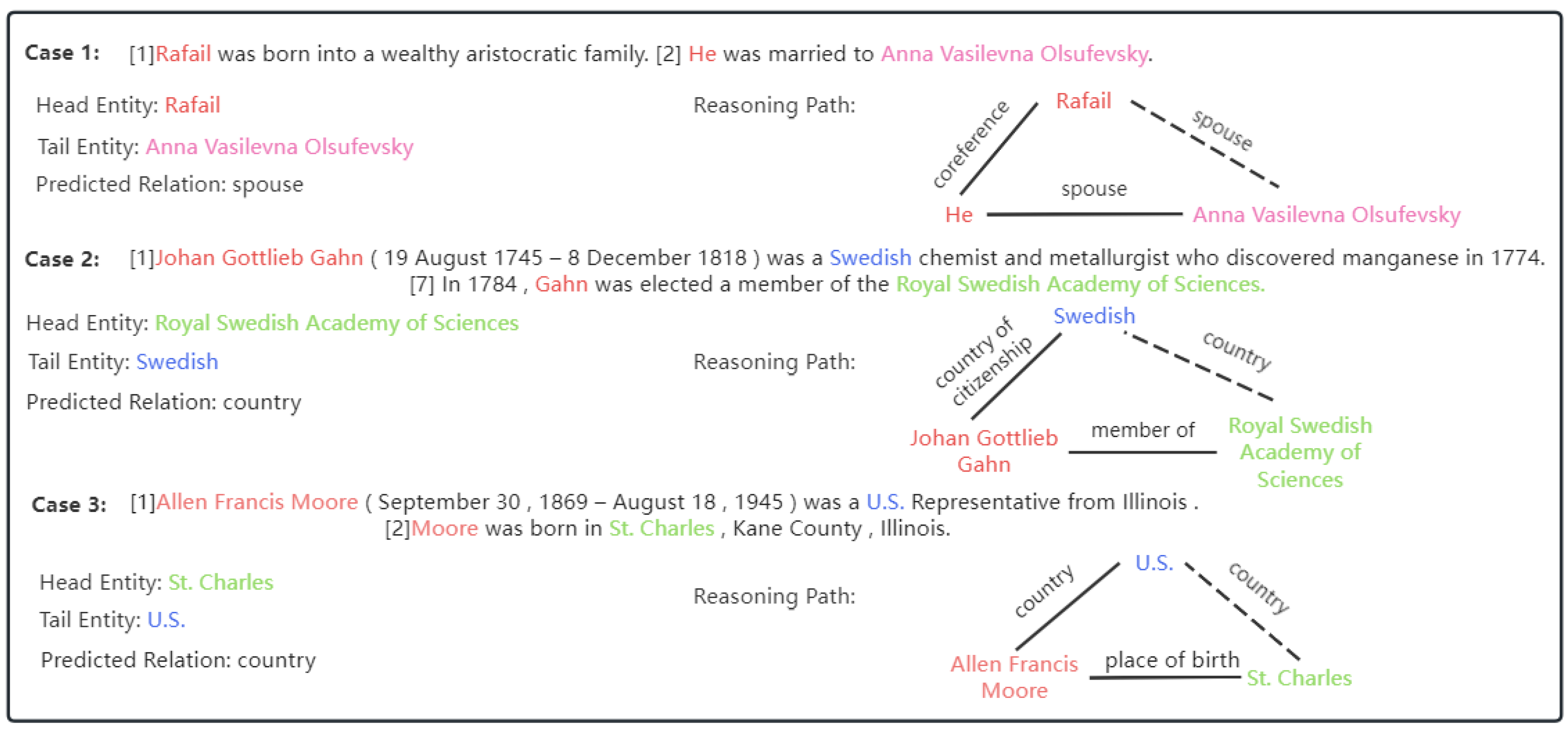
5.2. Case Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Song, Y.; Li, W.; Dai, G.; Shang, X. Advancements in Complex Knowledge Graph Question Answering: A Survey. Electronics 2023, 12, 4395. [Google Scholar] [CrossRef]
- Wei, S.; Liang, Y.; Li, X.; Weng, X.; Fu, J.; Han, X. Chinese Few-Shot Named Entity Recognition and Knowledge Graph Construction in Managed Pressure Drilling Domain. Entropy 2023, 25, 1097. [Google Scholar] [CrossRef] [PubMed]
- Tian, H.; Zhang, X.; Wang, Y.; Zeng, D. Multi-task learning and improved TextRank for knowledge graph completion. Entropy 2022, 24, 1495. [Google Scholar] [CrossRef]
- Xu, J.; Chen, Y.; Qin, Y.; Huang, R.; Zheng, Q. A feature combination-based graph convolutional neural network model for relation extraction. Symmetry 2021, 13, 1458. [Google Scholar] [CrossRef]
- Verga, P.; Strubell, E.; McCallum, A. Simultaneously self-attending to all mentions for full-abstract biological relation extraction. arXiv 2018, arXiv:1802.10569. [Google Scholar]
- Jia, R.; Wong, C.; Poon, H. Document-Level N-ary Relation Extraction with Multiscale Representation Learning. arXiv 2019, arXiv:1904.02347. [Google Scholar]
- Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; Sun, M. DocRED: A large-scale document-level relation extraction dataset. arXiv 2019, arXiv:1906.06127. [Google Scholar]
- Xu, W.; Chen, K.; Zhao, T. Discriminative reasoning for document-level relation extraction. arXiv 2021, arXiv:2106.01562. [Google Scholar]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6398–6407. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Jiang, X.; Wang, Q.; Li, P.; Wang, B. Relation extraction with multi-instance multi-label convolutional neural networks. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1471–1480. [Google Scholar]
- Huang, Y.Y.; Wang, W.Y. Deep residual learning for weakly-supervised relation extraction. arXiv 2017, arXiv:1707.08866. [Google Scholar]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]
- Peng, H.; Gao, T.; Han, X.; Lin, Y.; Li, P.; Liu, Z.; Sun, M.; Zhou, J. Learning from context or names? an empirical study on neural relation extraction. arXiv 2020, arXiv:2010.01923. [Google Scholar]
- Yin, H.; Liu, S.; Jian, Z. Distantly Supervised Relation Extraction via Contextual Information Interaction and Relation Embeddings. Symmetry 2023, 15, 1788. [Google Scholar] [CrossRef]
- Cheng, Q.; Liu, J.; Qu, X.; Zhao, J.; Liang, J.; Wang, Z.; Huai, B.; Yuan, N.J.; Xiao, Y. HacRED: A Large-Scale Relation Extraction Dataset Toward Hard Cases in Practical Applications. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; pp. 2819–2831. [Google Scholar]
- Sahu, S.K.; Christopoulou, F.; Miwa, M.; Ananiadou, S. Inter-sentence relation extraction with document-level graph convolutional neural network. arXiv 2019, arXiv:1906.04684. [Google Scholar]
- Christopoulou, F.; Miwa, M.; Ananiadou, S. Connecting the dots: Document-level neural relation extraction with edge-oriented graphs. arXiv 2019, arXiv:1909.00228. [Google Scholar]
- Wang, D.; Hu, W.; Cao, E.; Sun, W. Global-to-local neural networks for document-level relation extraction. arXiv 2020, arXiv:2009.10359. [Google Scholar]
- Zeng, S.; Xu, R.; Chang, B.; Li, L. Double graph based reasoning for document-level relation extraction. arXiv 2020, arXiv:2009.13752. [Google Scholar]
- Wang, H.; Qin, K.; Lu, G.; Yin, J.; Zakari, R.Y.; Owusu, J.W. Document-level relation extraction using evidence reasoning on RST-GRAPH. Knowl. Based Syst. 2021, 228, 107274. [Google Scholar] [CrossRef]
- Zeng, S.; Wu, Y.; Chang, B. Sire: Separate intra-and inter-sentential reasoning for document-level relation extraction. arXiv 2021, arXiv:2106.01709. [Google Scholar]
- Tan, Q.; He, R.; Bing, L.; Ng, H.T. Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1672–1681. [Google Scholar]
- Honnibal, M.; Montani, I. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. To Appear 2017, 7, 411–420. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Proceedings 15. Springer: Cham, Switzerland, 2018; pp. 593–607. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Li, G.; Xiong, C.; Thabet, A.; Ghanem, B. Deepergcn: All you need to train deeper gcns. arXiv 2020, arXiv:2006.07739. [Google Scholar]
- He, R.; Ravula, A.; Kanagal, B.; Ainslie, J. Realformer: Transformer likes residual attention. arXiv 2020, arXiv:2012.11747. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Ye, D.; Lin, Y.; Du, J.; Liu, Z.; Li, P.; Sun, M.; Liu, Z. Coreferential reasoning learning for language representation. arXiv 2020, arXiv:2004.06870. [Google Scholar]
- Xu, B.; Wang, Q.; Lyu, Y.; Zhu, Y.; Mao, Z. Entity structure within and throughout: Modeling mention dependencies for document-level relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 14149–14157. [Google Scholar]
- Zhou, W.; Huang, K.; Ma, T.; Huang, J. Document-level relation extraction with adaptive thresholding and localized context pooling. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 14612–14620. [Google Scholar]
- Zhang, N.; Chen, X.; Xie, X.; Deng, S.; Tan, C.; Chen, M.; Huang, F.; Si, L.; Chen, H. Document-level relation extraction as semantic segmentation. arXiv 2021, arXiv:2106.03618. [Google Scholar]
- Xie, Y.; Shen, J.; Li, S.; Mao, Y.; Han, J. Eider: Empowering Document-level Relation Extraction with Efficient Evidence Extraction and Inference-stage Fusion. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 257–268. [Google Scholar]
- Xiao, Y.; Zhang, Z.; Mao, Y.; Yang, C.; Han, J. SAIS: Supervising and augmenting intermediate steps for document-level relation extraction. arXiv 2021, arXiv:2109.12093. [Google Scholar]
- Li, R.; Zhong, J.; Xue, Z.; Dai, Q.; Li, X. Heterogenous affinity graph inference network for document-level relation extraction. Knowl. Based Syst. 2022, 250, 109146. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | DocRED |
|---|---|
| # Train docs. | 3053 |
| # Dev docs. | 1000 |
| # Test docs. | 1000 |
| # Distant docs. | 101,873 |
| # Relations | 97 |
| Avg. # entities per doc. | 19.5 |
| Avg. # mentions per entity | 1.4 |
| Avg. # relations per doc. | 12.5 |
| Model | Evidence Information | Syntactic Structure | Dev | Test | ||
|---|---|---|---|---|---|---|
| Ign_F1 | F1 | Ign_F1 | F1 | |||
| Coref [30] | ✗ | ✗ | 57.35 | 59.43 | 57.9 | 60.25 |
| SSAN [31] | ✔ | ✗ | 59.40 | 61.42 | 60.25 | 62.08 |
| GAIN [20] | ✗ | ✗ | 60.87 | 63.09 | 60.31 | 62.76 |
| HAG [36] | ✗ | ✗ | 60.85 | 63.06 | 60.78 | 60.82 |
| ATLOP [32] | ✗ | ✗ | 61.32 | 63.18 | 61.39 | 63.40 |
| DocuNet [33] | ✗ | ✗ | 62.23 | 64.12 | 62.39 | 64.55 |
| EIDER [34] | ✔ | ✗ | 62.34 | 64.27 | 62.85 | 64.79 |
| SAIS [35] | ✗ | ✗ | 62.23 | 65.17 | 63.44 | 65.11 |
| AFLKD [23] | ✗ | ✗ | 65.27 | 67.12 | 65.24 | 67.28 |
| TSFGAT(ours) | ✔ | ✔ | 67.57 | 69.87 | 68.14 | 69.93 |
| Model | Ign_F1 | F1 |
|---|---|---|
| Full model | 68.14 | 69.93 |
| w/o two-stage strategy | 65.32 | 66.80 |
| w/o pre-coreference-resolution | 41.68 | 43.65 |
| w/o enhanced heterogeneous graph attention network | 66.29 | 67.72 |
| w/o attention with edge-type information | 67.62 | 69.01 |
| w/o residual attention | 67.13 | 68.76 |
| w/o multilabel focal loss | 64.37 | 65.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Shi, B. Enhanced Heterogeneous Graph Attention Network with a Novel Multilabel Focal Loss for Document-Level Relation Extraction. Entropy 2024, 26, 210. https://doi.org/10.3390/e26030210
Chen Y, Shi B. Enhanced Heterogeneous Graph Attention Network with a Novel Multilabel Focal Loss for Document-Level Relation Extraction. Entropy. 2024; 26(3):210. https://doi.org/10.3390/e26030210
Chicago/Turabian StyleChen, Yang, and Bowen Shi. 2024. "Enhanced Heterogeneous Graph Attention Network with a Novel Multilabel Focal Loss for Document-Level Relation Extraction" Entropy 26, no. 3: 210. https://doi.org/10.3390/e26030210
APA StyleChen, Y., & Shi, B. (2024). Enhanced Heterogeneous Graph Attention Network with a Novel Multilabel Focal Loss for Document-Level Relation Extraction. Entropy, 26(3), 210. https://doi.org/10.3390/e26030210