1. Introduction
Oil-immersed power transformers are vital components in power systems, primarily utilized for voltage regulation and the transmission and distribution of electrical energy [
1]. These transformers utilize insulating oil for effective heat control. The design and operation of transformers directly impact the quality of the electrical energy and the reliability of the power system. Therefore, understanding the operational status of oil-immersed transformers and ensuring their safe and stable operation are crucial for the reliability of the power system [
2].
The fault diagnosis method for oil-immersed transformers based on dissolved gas analysis (DGA) in oil has gained widespread application in recent years [
3,
4]. By analyzing the gas content in the transformer oil, this method can effectively identify the types of electrical faults, discover potential issues, and provide crucial information for proactive maintenance of transformers. As a result, it has become increasingly prevalent in the field. Currently, the traditional diagnostic methods for dissolved gases in transformer oil include the three-ratio method [
5] and the Duval Triangle method [
6]. However, these approaches suffer from shortcomings such as insufficient coding and excessive absoluteness, leading to a higher rate of misjudgment. This phenomenon results in their inability to accurately diagnose certain faults. Therefore, there are now various intelligent diagnostic methods for oil-immersed transformer faults based on DGA. These methods mainly include Artificial Neural Networks (ANNs), Support Vector Machines (SVMs), Expert Systems (ESs), Extreme Learning Machines (ELMs), etc. ANNs offer advantages, such as distributed parallel processing, adaptability, self-learning, associative memory, and non-linear mapping. Zhou et al. [
7] proposed a probabilistic neural-network-based fault diagnosis model for power transformers, and the results show that it is applicable to the field of transformer fault diagnosis. However, ANNs suffer from slow convergence and susceptibility to local optima. In paper [
8], the multi-layer SVM technique is used to determine the classification of the transformer faults and the name of the dissolved gas. The results demonstrate that combination ratios and the graphical representation technique are more suitable as a gas signature and that an SVM with a Gaussian function outperforms the other kernel functions in its diagnosis accuracy. But SVMs have inherent binary attributes that limit their applications. Mani [
9] presented an intuitionistic fuzzy expert system to diagnose several faults in a transformer, and it was successfully used to identify the type of fault developing within a transformer, even if there was conflict in the results when AI techniques were applied to the DGA data. However, ESs rely on rich expert knowledge for diagnosis. Acquiring such knowledge is costly, potentially limiting the diagnostic accuracy. In paper [
10], a novel method for transformer fault diagnosis based on a parameter optimization kernel extreme learning machine was proposed. The results verified the effectiveness of the proposed method. ELM features few pre-set parameters, fast training speeds, and suitability for engineering applications. However, it has the drawback of relatively poor learning capabilities. A performance comparison of different diagnostic methods is shown in
Table 1.
Data-driven fault detection methods utilize machine learning and data analysis techniques to detect equipment faults [
11]. They analyze real-time sensor data or historical data, build models, and compare them with fault patterns. In recent years, these methods have been widely applied in various fields, such as industrial processes [
12], HVAC systems [
13], energy systems [
14], potential fault identification [
15], sensor analytics [
16], and medical device digital systems [
17]. Deep learning theory possesses robust feature learning and pattern recognition capabilities, extracting effective information from large-scale and complex data [
18]. In recent years, deep learning, particularly convolutional neural networks (CNNs), has found widespread application in fault diagnosis [
19]. CNNs, using convolutional and pooling layers, automatically learn the local and global features from the input data. It can provide effective representation of images, sequences, and so on [
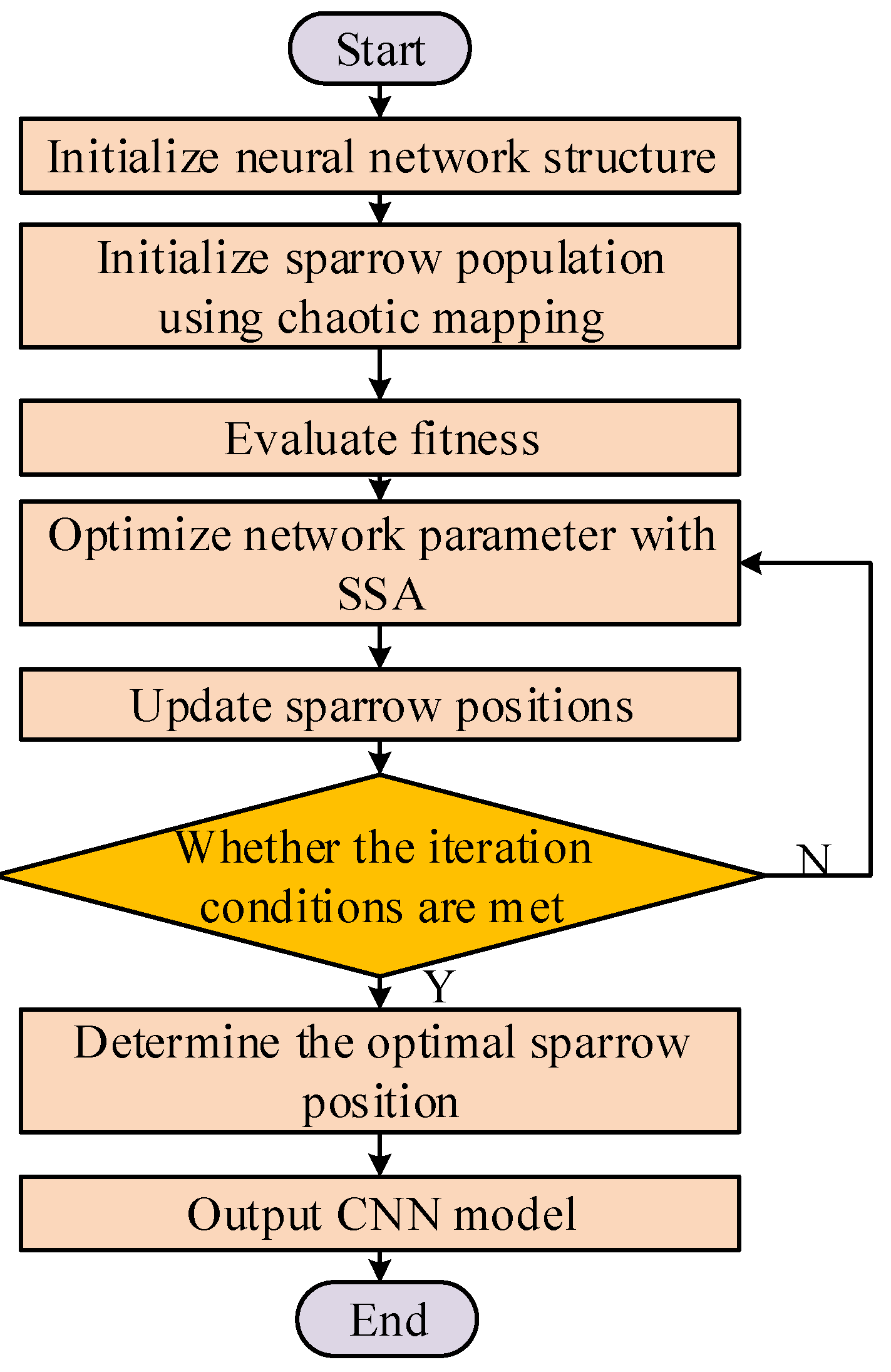
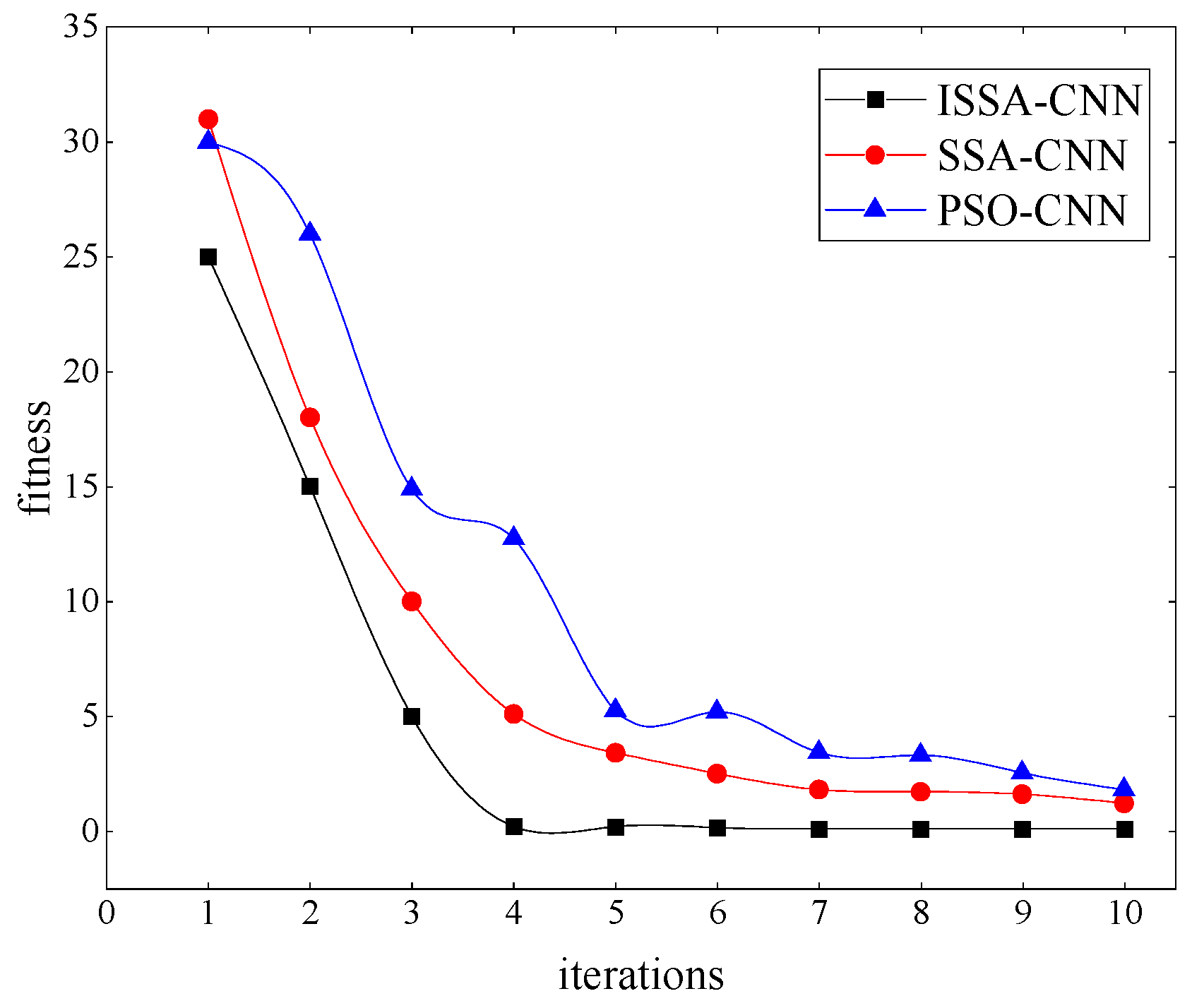
20]. The strength of CNNs lies in their efficient processing of complex data and feature learning capabilities. The proper hyperparameters, such as learning rate and filter size, are crucial to the model performance in CNNs. The sparrow search algorithm (SSA) was proposed in 2020 as a novel swarm intelligence optimization algorithm [
21]. It primarily achieves position optimization by emulating the foraging and anti-predatory behaviors of sparrows, aiming to locate the local optimum of a given problem [
22]. This study introduces an improved sparrow search algorithm (ISSA) for CNN parameter optimization. ISSA can dynamically adjust these parameters to enhance model generalization and robustness. The proposed approach will be applied to transformer fault diagnosis, showcasing the potential of CNNs optimized with ISSA.
The DGA method primarily utilizes the characteristic gas content for transformer fault diagnosis [
23]. However, the composition of dissolved gases in oil is highly complex and uncertain. Therefore, assessing the uncertainty solely based on the decomposed gas content is challenging. This study introduces information entropy [
24] as a feature indicator for transformer fault diagnosis. Information entropy, a concept from information theory, measures system uncertainty and information quantity. In transformer diagnosis, information entropy can be employed by analyzing the concentration distribution of dissolved gases, assessing system states. Higher entropy values indicate greater system complexity and uncertainty, potentially indicating underlying faults. Information entropy analysis enhances the understanding of system health, supporting early fault detection and prediction [
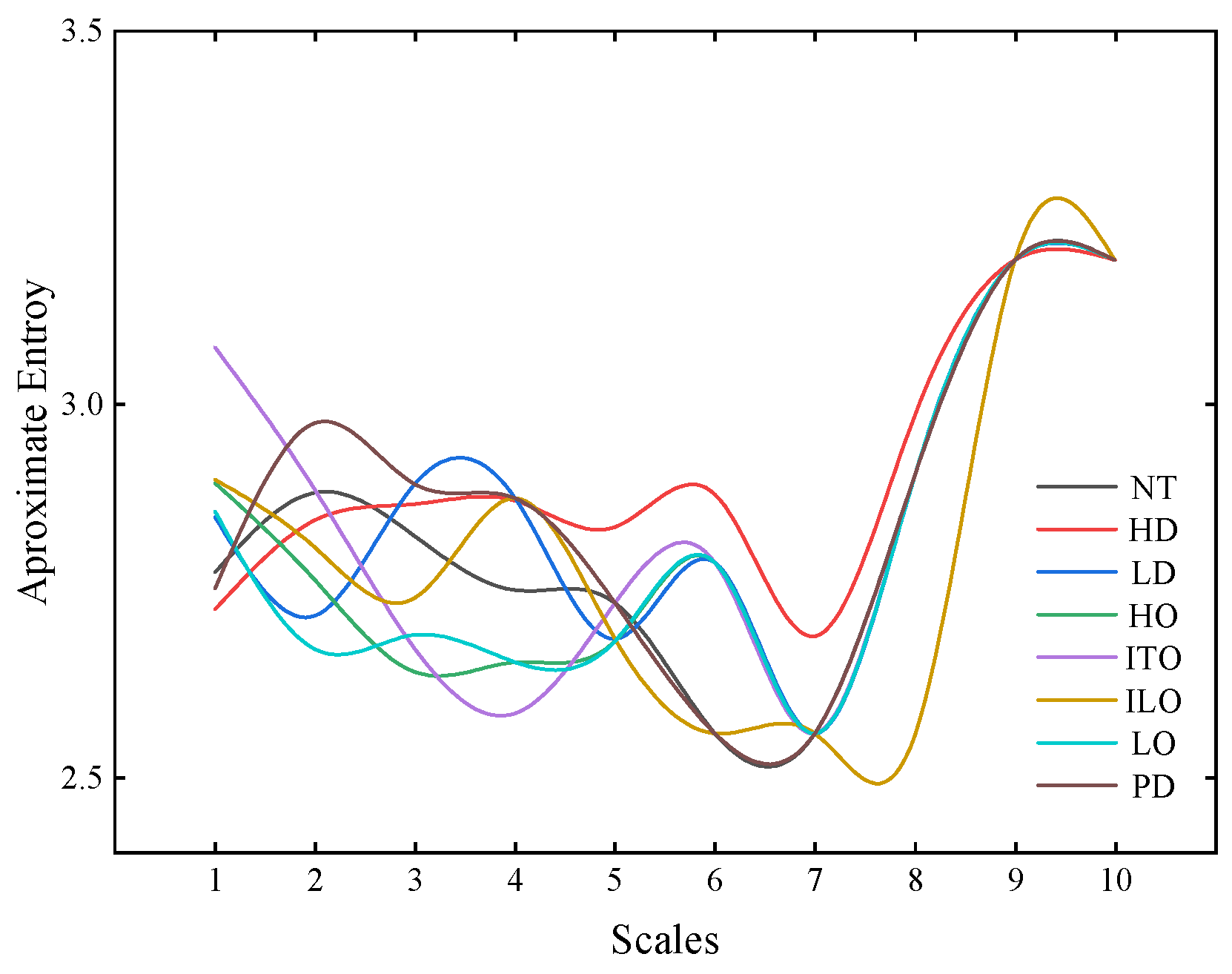
25]. Approximate entropy, a calculation method for information entropy, is commonly used for time-series data analysis [
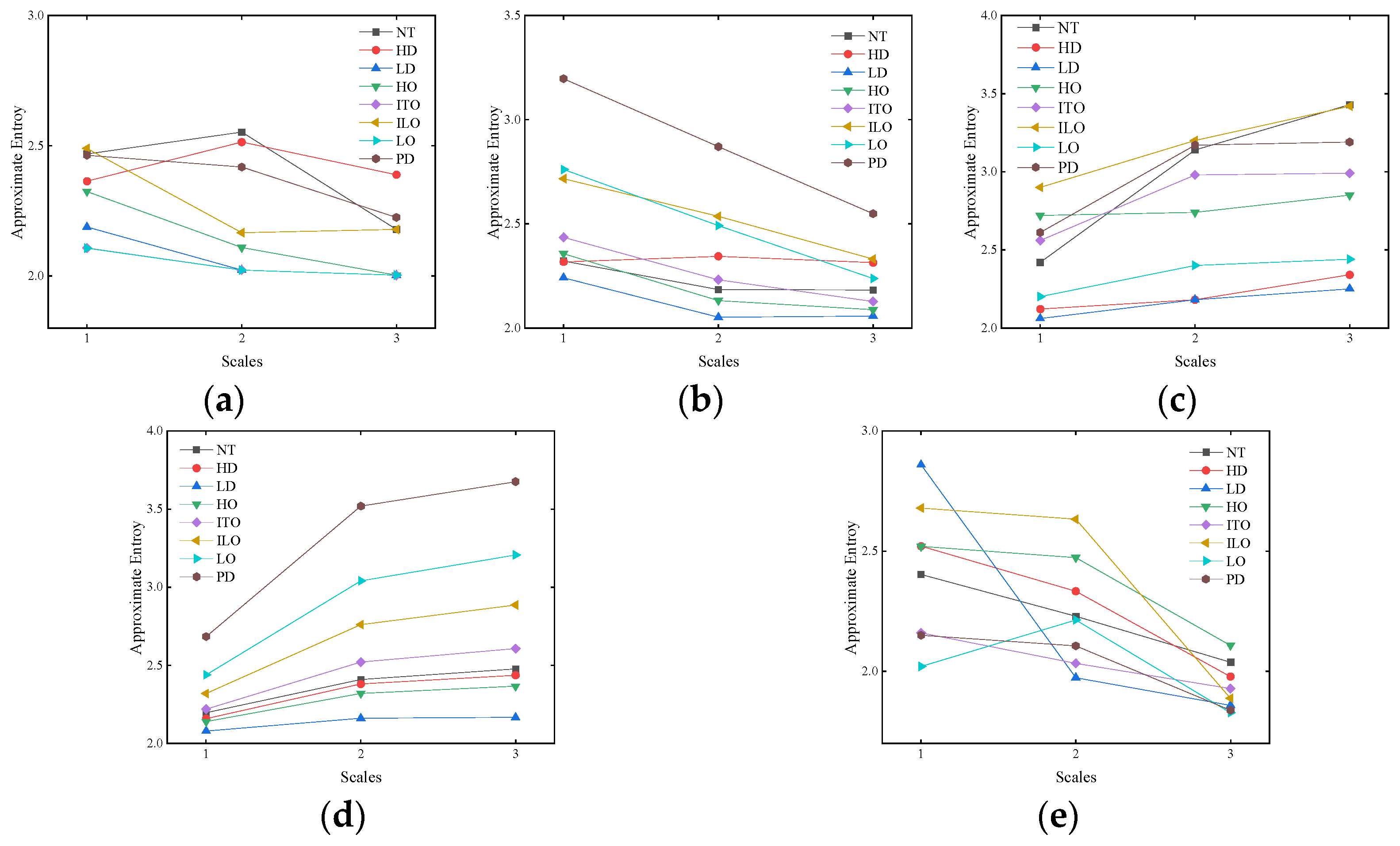
26]. It assesses system complexity and regularity, revealing patterns or trends in data. Multi-scale approximate entropy considers signal characteristics at different scales, observing how complexity evolves with scale changes [
27]. This method contributes to a comprehensive understanding of dynamic signal characteristics. It provides in-depth insights into system behavior across different time scales. Currently, approximate entropy has demonstrated effective applications in various fields, including biosignal analysis [
28], short-circuiting arc welding analysis [
29], mechanical vibration measurements [
30], and environmental monitoring [
31]. In transformer diagnosis, this paper attempts to enhance early fault prediction by calculating the multi-scale approximate entropy of dissolved gases in oil, offering a more comprehensive insight into system state changes.
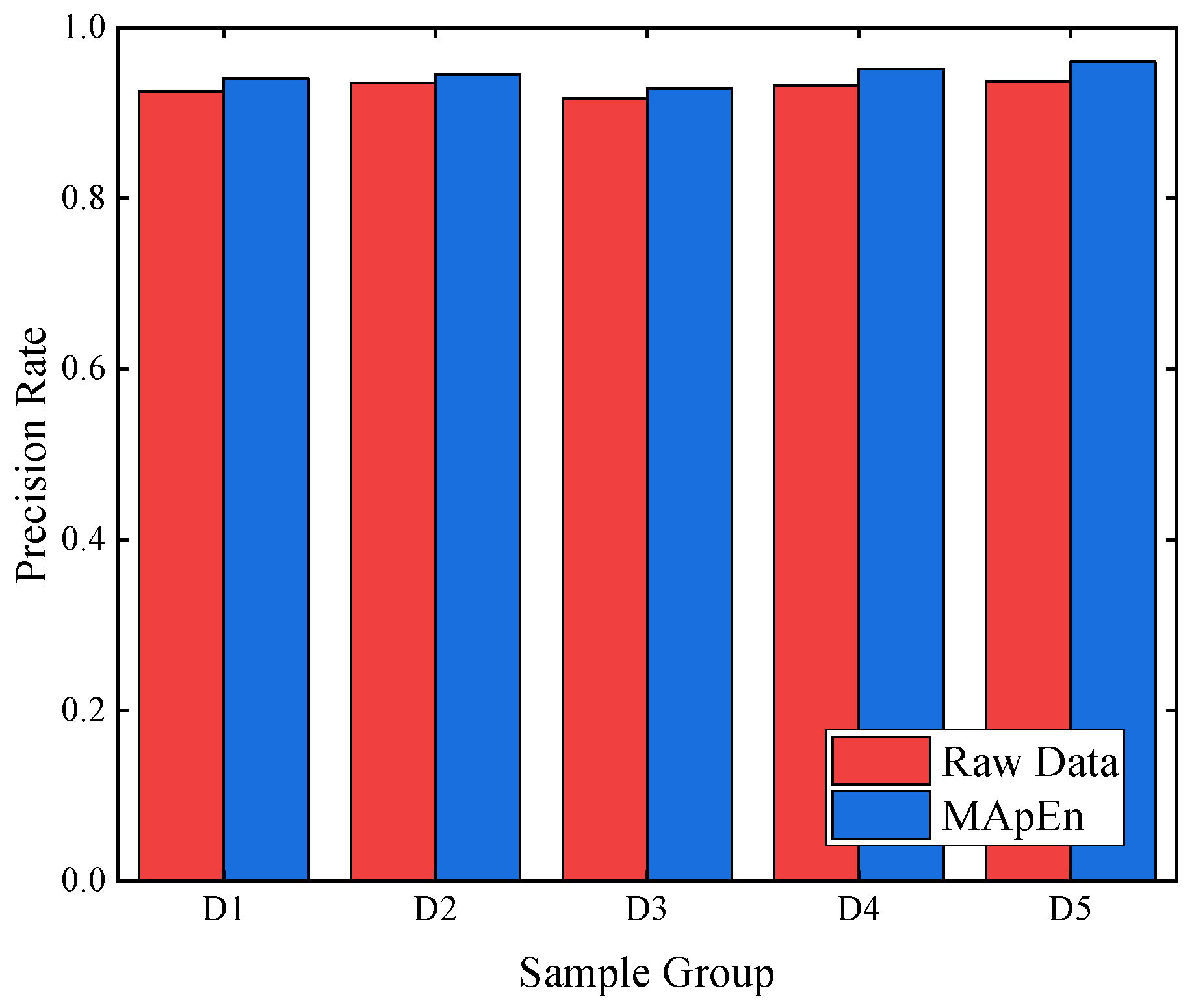
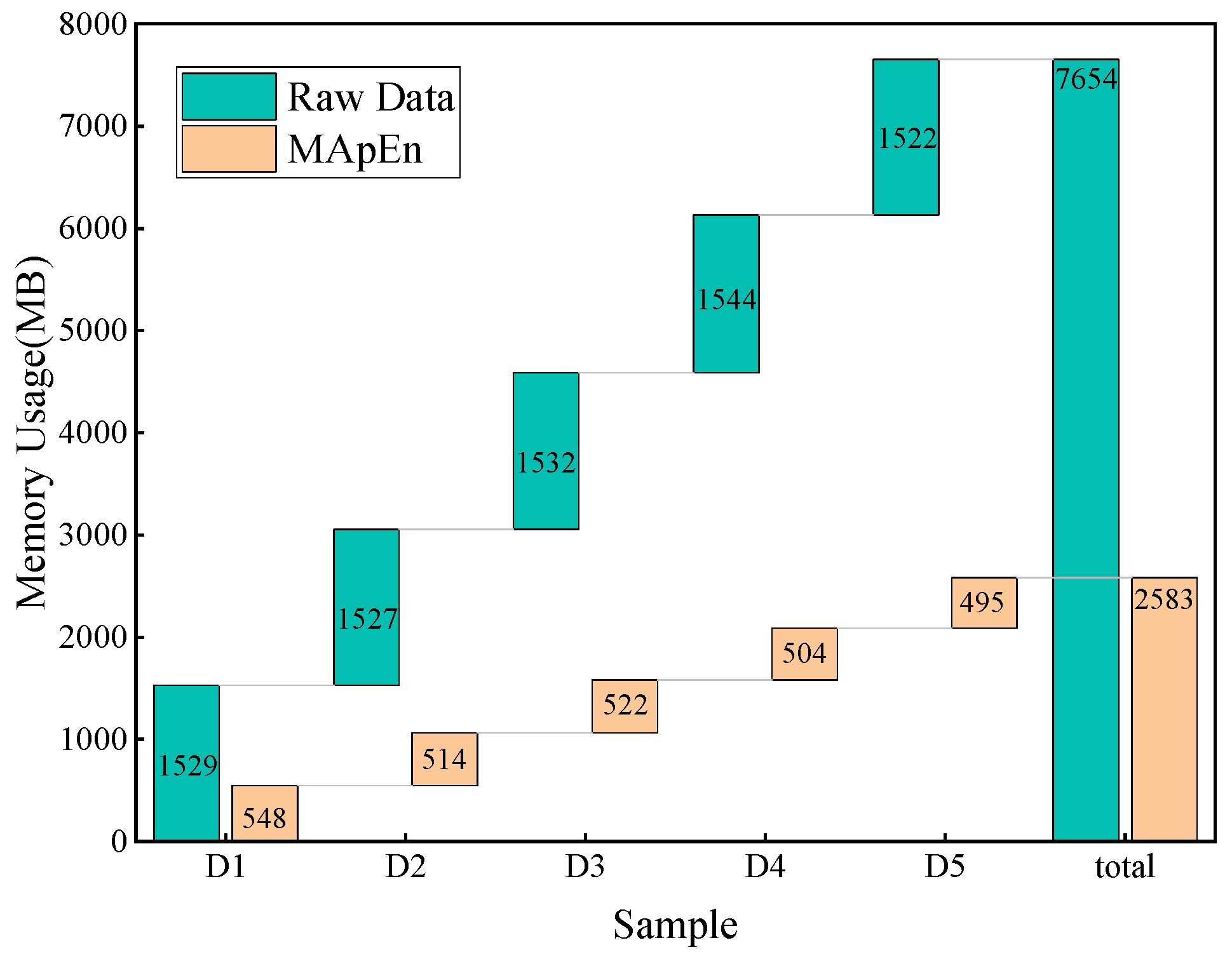
This study initially collects the characteristic gas content of oil-immersed transformers under various fault types, including H2, CH4, C2H6, C2H4, and C2H2. Subsequently, the content ratios of different gas types are obtained. The multi-scale approximate entropy values are then calculated through content ratios to assess the gas complexity. Finally, the multi-scale approximate entropy values serve as feature inputs for an optimized CNN-based classifier, deriving diagnostic results. Field data demonstrate the proposed method’s effectiveness and superiority in transformer fault diagnosis.
The structure of this paper is as follows. The principles of the relevant algorithms are detailed in
Section 2.
Section 3 presents an oil-immersed transformer fault diagnosis model based on multi-scale approximate entropy and optimized CNNs.
Section 4 shows the performance of the proposed diagnostic model.
Section 5 concludes the paper.





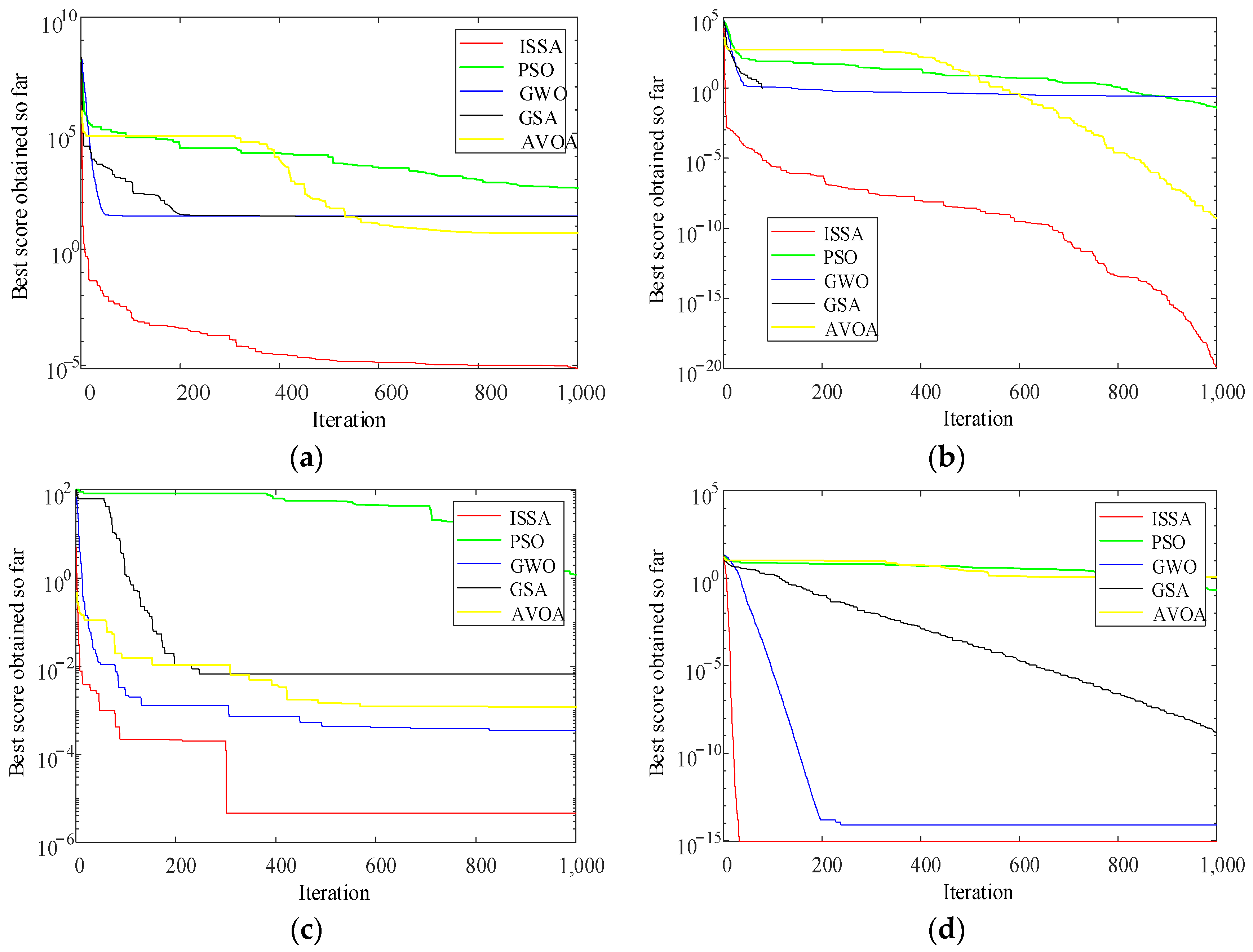

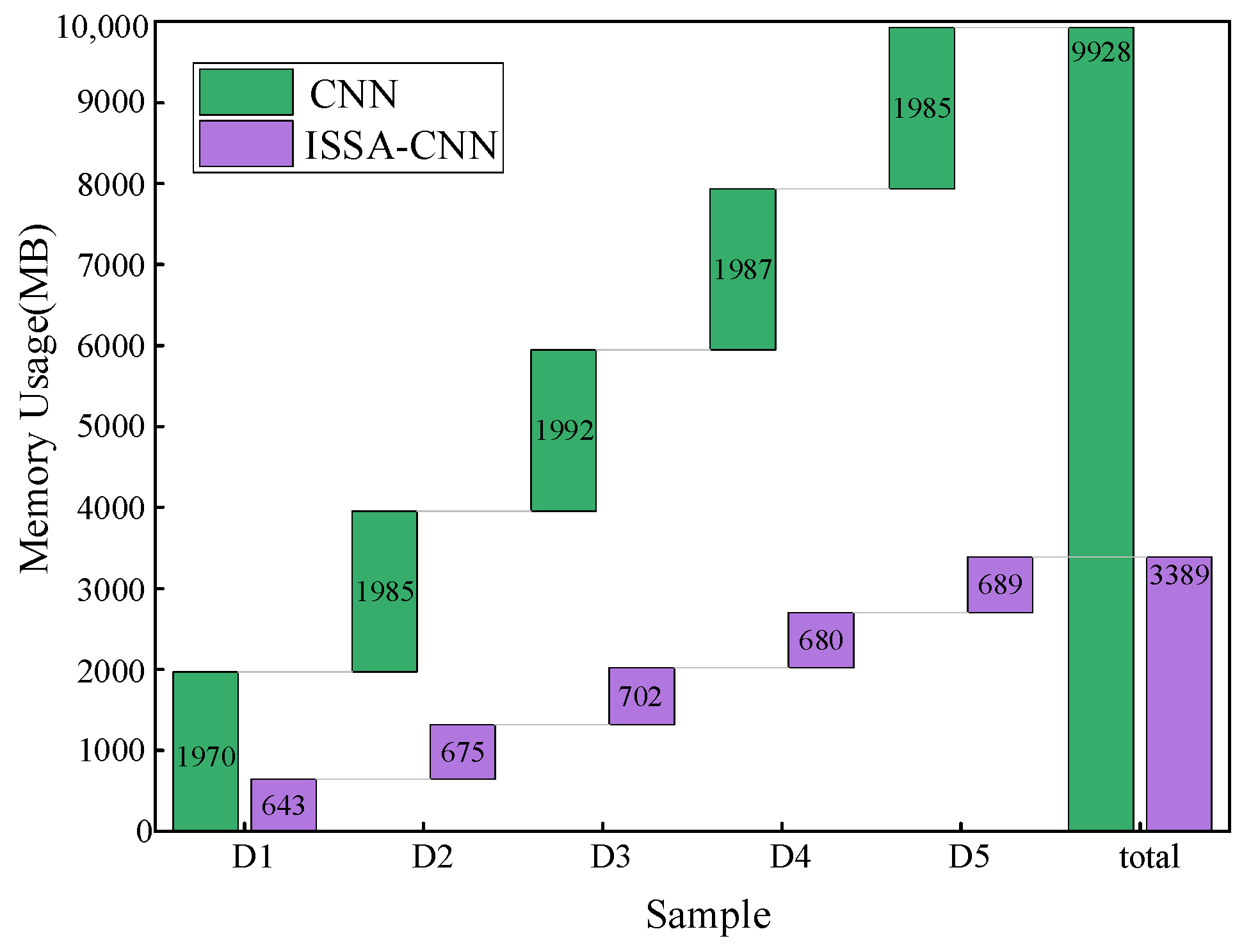
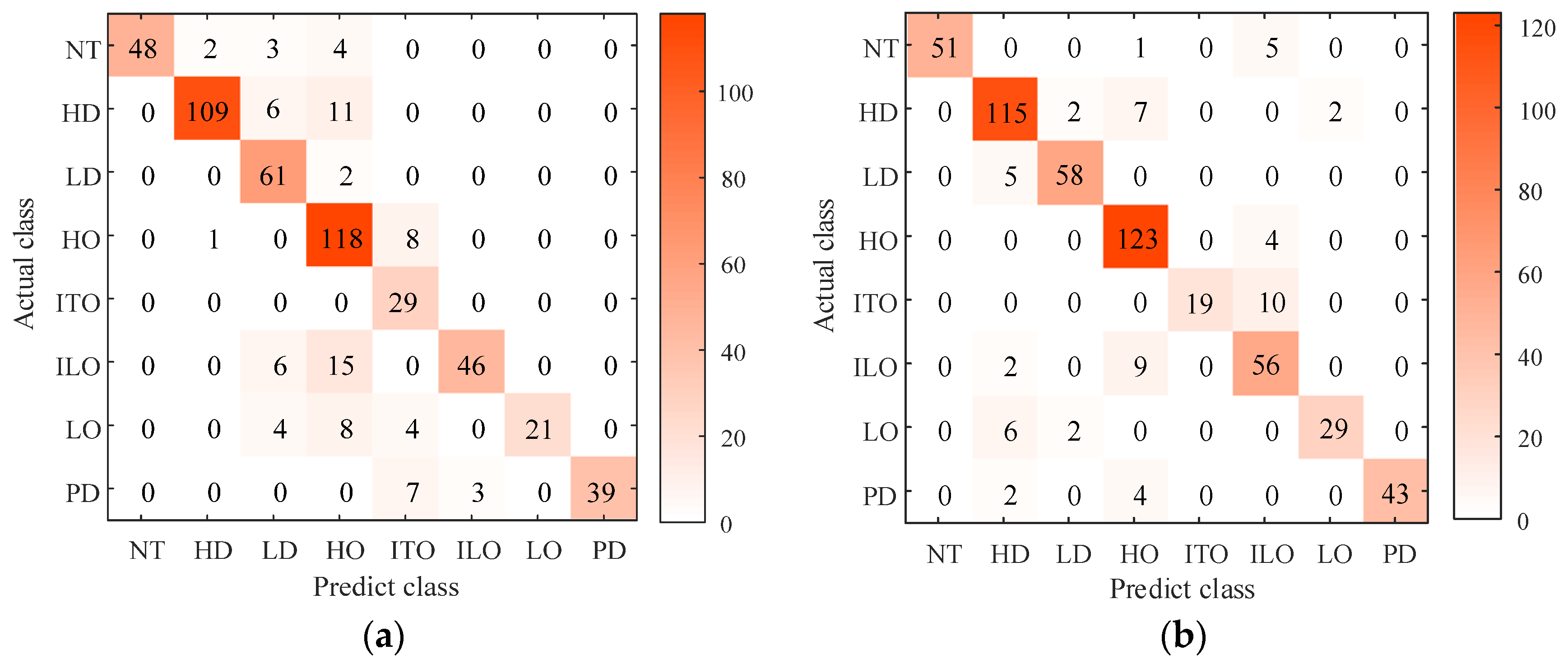
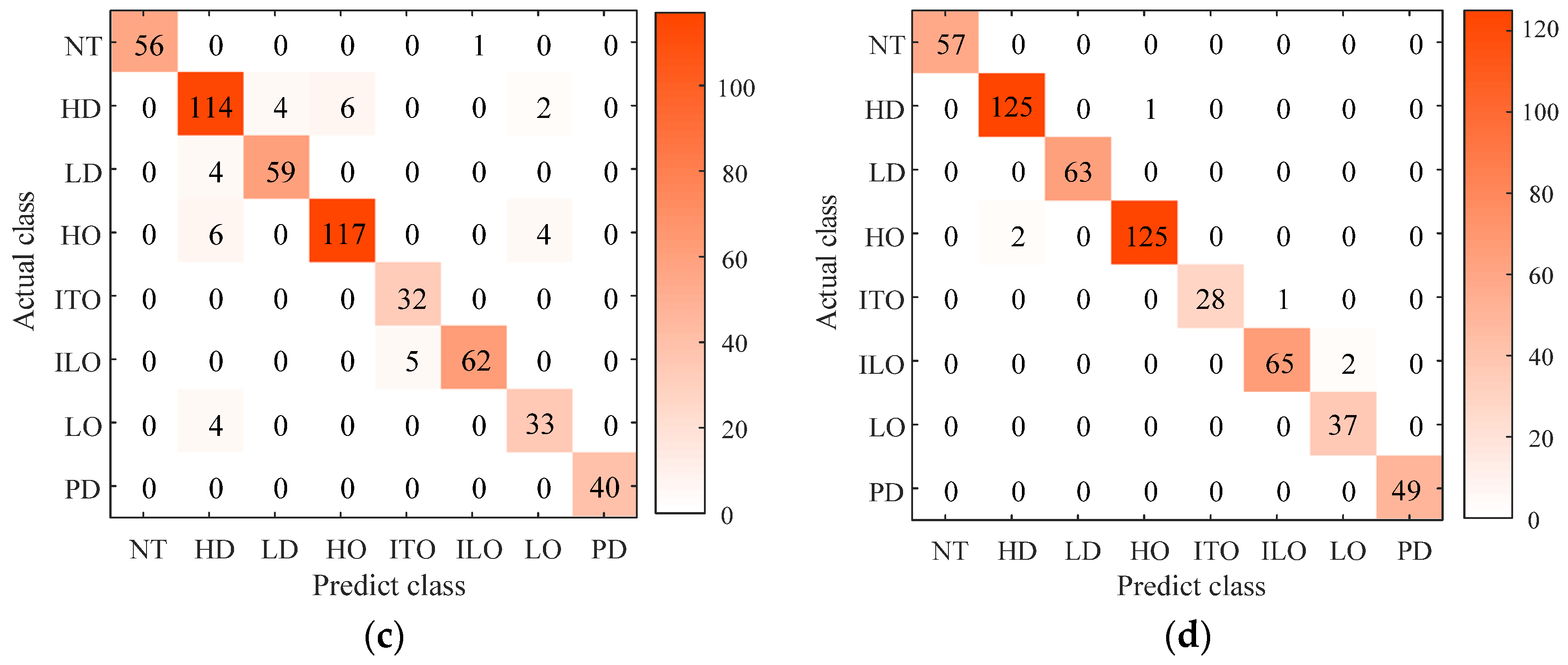


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}