

Genetic Algorithm for Feature Selection Applied to Financial Time Series Monotonicity Prediction: Experimental Cases in Cryptocurrencies and Brazilian Assets

 , , , , , and
, , , , , and 
Abstract
1. Introduction
- Proposal of two systems for predicting financial time series;
- Performance analysis focusing on feature selection methods;
- Performance analysis of the combination of other machine learning techniques in the systems.
2. Related Works
2.1. Feature Selection
2.2. GA for Feature Selection
2.3. Data Types and Preprocessing for Financial Time Series
2.4. Machine Learning in Financial Time Series Prediction
2.5. Final Considerations
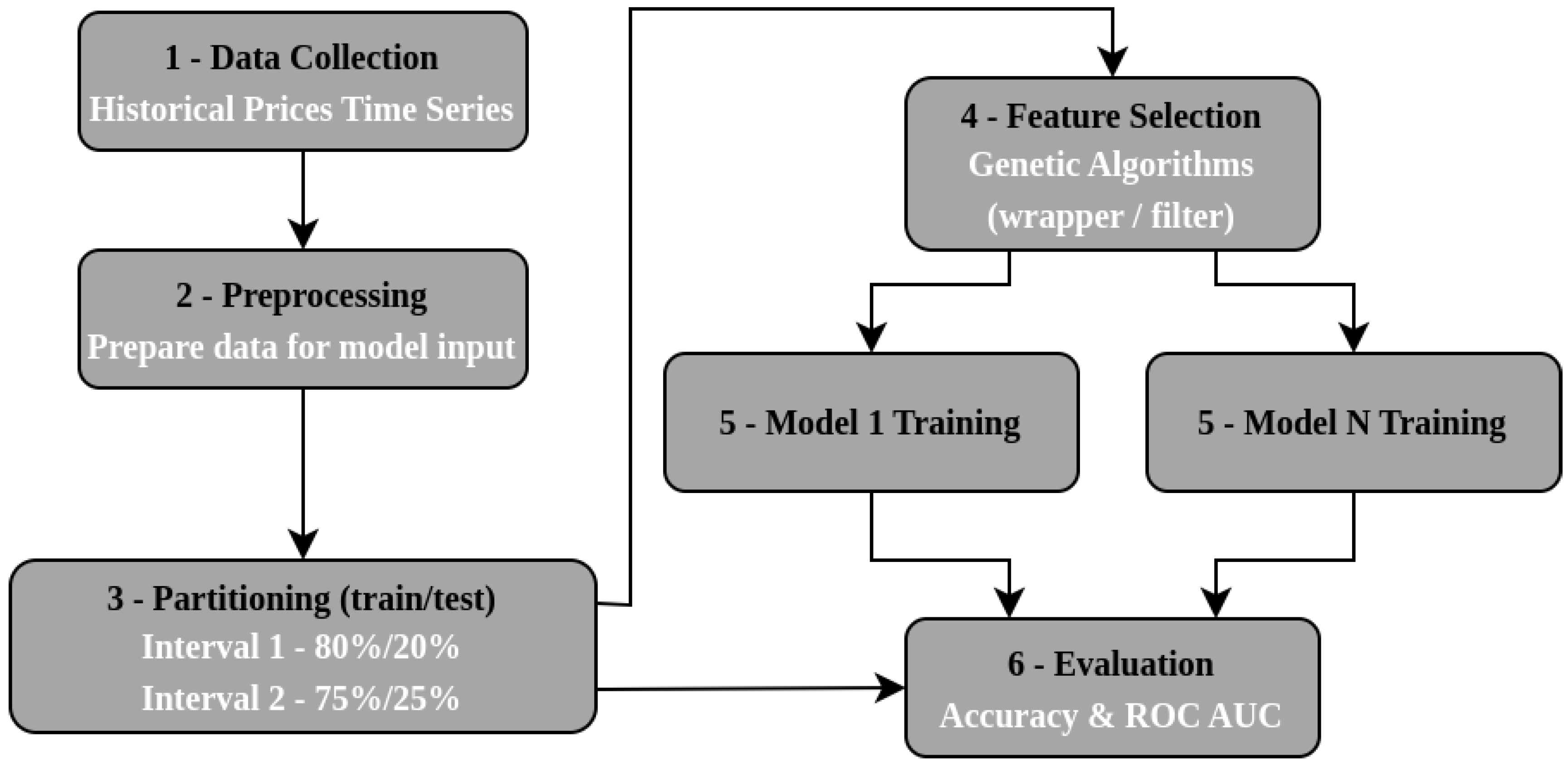
3. Materials and Methods
3.1. Data Collection
3.2. Data Preprocessing
3.3. Data Partitioning
3.4. Feature Selection
3.4.1. Solution Coding and Fitness
3.4.2. Operators and Parameters
3.5. Model Training
3.6. Model Evaluation
4. Results
4.1. Missing Data
- E1 (Bitcoin): KOSPI (19.10%), Platinum (18.17%), Palladium (18.17%), Coffee (18.17%), Copper (18.12%), Oat (18.12%), Silver (18.12%), Sugar (18.12%), NASDAQ (18.12%), Natural Gas (18.12%), Heating Oil (18.12%), Gold (18.12%), S&P500 (18.12%), Crude Oil (18.12%), Cocoa (18.12%), and DAX (18.06%);
- E2 (Ibovespa): Crude Oil (2.33%), E-Mini S&P 500 (2.33%), Gold (2.43%), Copper (2.43%), Wheat (2.33%), MSCI (2.53%), Natural Gas (2.33%), Nasdaq 100 (2.33%), Silver (2.43%), Corn (2.53%), Oat Futures, May-2023 (2.33%), Rough Rice Futures, May-2023 (3.54%), Soybean (2.33%), Cboe UK 100 (2.02%), Dow Jones (2.33%), FTSE 100 (2.23%), DAX (1.21%), S&P 500 (2.33%), NASDAQ (2.33%), NYSE (2.33%), Russell 2000 (2.33%), NYSE AMEX (2.33%), Euro (0.10%), and US Dollar (0.10%);
- E3 (Vale): Crude Oil (2.33%), E-Mini S&P 500 (2.33%) Gold (2.43%), Copper (2.43%), Wheat (2.33%), MSCI (2.53%), Natural Gas (2.33%), Nasdaq 100 (2.33%), Silver (2.43%), Corn (2.53%), Oat Futures, May-2023 (2.33%), Rough Rice Futures, May-2023 (3.54%), Soybean (2.33%), Cboe UK 100 (2.02%), Ibovespa (0.10%), Dow Jones (2.33%), FTSE 100 (2.22%), DAX (1.21%), S&P 500 (2.33%), NASDAQ (2.33%), NYSE (2.33%), Russell 2000 (2.33%), NYSE AMEX (2.33%), Euro (0.10%), and US Dollar (0.10%).
4.2. E1—Bitcoin
4.3. E2 and E3—Ibovespa and Vale
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
| Attribute | Description |
|---|---|
| Open | Opening price |
| High | Maximum price |
| Low | Minimum price |
| Close | Closing price |
| Volume | Volume of negotiations |
| AD | Chaikin A/D Line |
| ADOSC | Chaikin A/D Oscillator |
| ADX | Average Directional Movement Index |
| ADXR | Average Directional Movement Index Rating |
| AROON | Aroon |
| AROONOSC | Aroon Oscillator |
| ATR | Average True Range |
| AVGPRICE | Average Price |
| BBANDS | Bollinger Bands |
| BOP | Balance Of Power |
| CCI | Commodity Channel Index |
| CMO | Chande Momentum Oscillator |
| DEMA | Double Exponential Moving Average |
| DX | Directional Movement Index |
| EMA | Exponential Moving Average |
| HT_DCPERIOD | Hilbert Transform—Dominant Cycle Period |
| HT_DCPHASE | Hilbert Transform—Dominant Cycle Phase |
| HT_PHASOR | Hilbert Transform—Phasor Components |
| HT_SINE | Hilbert Transform—SineWave |
| HT_TRENDLINE | Hilbert Transform—Instantaneous Trendline |
| KAMA | Kaufman Adaptive Moving Average |
| MACD | Moving Average Convergence/Divergence |
| MACDEXT | MACD with controllable MA type |
| MACDFIX | Moving Average Convergence/Divergence Fix 12/26 |
| MAMA | MESA Adaptive Moving Average |
| MEDPRICE | Median Price |
| MFI | Money Flow Index |
| MIDPOINT | MidPoint over period |
| MIDPRICE | Midpoint Price over period |
| MINMAX | Lowest and highest values over a specified period |
| MINMAXINDEX | Indexes of lowest and highest values over a specified period |
| MINUS_DI | Minus Directional Indicator |
| MINUS_DM | Minus Directional Movement |
| MOM | Momentum |
| NATR | Normalized Average True Range |
| OBV | On Balance Volume |
| PLUS_DI | Plus Directional Indicator |
| PLUS_DM | Plus Directional Movement |
| PPO | Percentage Price Oscillator |
| ROC | Rate of change |
| ROCP | Rate of change Percentage |
| ROCR | Rate of change ratio |
| RSI | Relative Strength Index |
| SAR | Parabolic SAR |
| SMA | Simple Moving Average |
| STOCH | Stochastic |
| TEMA | Triple Exponential Moving Average |
| TRANGE | True Range |
| TYPPRICE | Typical Price |
| WCLPRICE | Weighted Close Price |
| WILLR | Williams %R |
| WMA | Weighted Moving Average |
References
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Picasso, A.; Merello, S.; Ma, Y.; Oneto, L.; Cambria, E. Technical analysis and sentiment embeddings for market trend prediction. Expert Syst. Appl. 2019, 135, 60–70. [Google Scholar] [CrossRef]
- Laboissiere, L.A.; Fernandes, R.A.; Lage, G.G. Maximum and minimum stock price forecasting of Brazilian power distribution companies based on artificial neural networks. Appl. Soft Comput. 2015, 35, 66–74. [Google Scholar] [CrossRef]
- Fang, F.; Ventre, C.; Basios, M.; Kanthan, L.; Martinez-Rego, D.; Wu, F.; Li, L. Cryptocurrency trading: A comprehensive survey. Financ. Innov. 2022, 8, 13. [Google Scholar] [CrossRef]
- Tredinnick, L. Cryptocurrencies and the blockchain. Bus. Inf. Rev. 2019, 36, 39–44. [Google Scholar] [CrossRef]
- Cocco, L.; Concas, G.; Marchesi, M. Using an artificial financial market for studying a cryptocurrency market. J. Econ. Interact. Coord. 2017, 12, 345–365. [Google Scholar] [CrossRef]
- Almeida, J.; Gonçalves, T.C. A systematic literature review of investor behavior in the cryptocurrency markets. J. Behav. Exp. Finance 2023, 37, 100785. [Google Scholar] [CrossRef]
- Jiang, W. Applications of deep learning in stock market prediction: Recent progress. Expert Syst. Appl. 2021, 184, 115537. [Google Scholar] [CrossRef]
- Cho, D.H.; Moon, S.H.; Kim, Y.H. Genetic Feature Selection Applied to KOSPI and Cryptocurrency Price Prediction. Mathematics 2021, 9, 2574. [Google Scholar] [CrossRef]
- Mallqui, D.C.; Fernandes, R.A. Predicting the direction, maximum, minimum and closing prices of daily Bitcoin exchange rate using machine learning techniques. Appl. Soft Comput. 2019, 75, 596–606. [Google Scholar] [CrossRef]
- Choudhry, R.; Garg, K. A hybrid machine learning system for stock market forecasting. Int. J. Comput. Inf. Eng. 2008, 2, 689–692. [Google Scholar]
- Ayala, J.; García-Torres, M.; Noguera, J.L.V.; Gómez-Vela, F.; Divina, F. Technical analysis strategy optimization using a machine learning approach in stock market indices. Knowl. Based Syst. 2021, 225, 107119. [Google Scholar] [CrossRef]
- Akita, R.; Yoshihara, A.; Matsubara, T.; Uehara, K. Deep learning for stock prediction using numerical and textual information. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Khan, W.; Malik, U.; Ghazanfar, M.A.; Azam, M.A.; Alyoubi, K.H.; Alfakeeh, A.S. Predicting stock market trends using machine learning algorithms via public sentiment and political situation analysis. Soft Comput. 2020, 24, 11019–11043. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; Volume 4. [Google Scholar]
- Charikar, M.; Guruswami, V.; Kumar, R.; Rajagopalan, S.; Sahai, A. Combinatorial feature selection problems. In Proceedings of the 41st Annual Symposium on Foundations of Computer Science, Redondo Beach, CA, USA, 12–14 November 2000; pp. 631–640. [Google Scholar] [CrossRef]
- Dokeroglu, T.; Deniz, A.; Kiziloz, H.E. A comprehensive survey on recent metaheuristics for feature selection. Neurocomputing 2022, 494, 269–296. [Google Scholar] [CrossRef]
- Tsai, C.F.; Hsiao, Y.C. Combining multiple feature selection methods for stock prediction: Union, intersection, and multi-intersection approaches. Decis. Support Syst. 2010, 50, 258–269. [Google Scholar] [CrossRef]
- Boussaïd, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Mohamed, A.W.; Hadi, A.A.; Mohamed, A.K. Gaining-sharing knowledge based algorithm for solving optimization problems: A novel nature-inspired algorithm. Int. J. Mach. Learn. Cybern.s 2020, 11, 1501–1529. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Kumbure, M.M.; Lohrmann, C.; Luukka, P.; Porras, J. Machine learning techniques and data for stock market forecasting: A literature review. Expert Syst. Appl. 2022, 197, 116659. [Google Scholar] [CrossRef]
- Chen, Y.; Hao, Y. A feature weighted support vector machine and K-nearest neighbor algorithm for stock market indices prediction. Expert Syst. Appl. 2017, 80, 340–355. [Google Scholar] [CrossRef]
- Ranjan, K.G.; Prusty, B.R.; Jena, D. Review of preprocessing methods for univariate volatile time-series in power system applications. Electr. Power Syst. Res. 2021, 191, 106885. [Google Scholar] [CrossRef]
- Yun, K.K.; Yoon, S.W.; Won, D. Prediction of stock price direction using a hybrid GA-XGBoost algorithm with a three-stage feature engineering process. Expert Syst. Appl. 2021, 186, 115716. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Deng, Z.; Xia, Y.; Fu, M. A new sampling method in particle filter based on Pearson correlation coefficient. Neurocomputing 2016, 216, 208–215. [Google Scholar] [CrossRef]
- Peng, G.; Nourani, M.; Harvey, J.; Dave, H. Feature selection using f-statistic values for EEG signal analysis. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: New York, NY, USA, 2020; pp. 5963–5966. [Google Scholar]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning: Methods, Systems, Challenges; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar] [CrossRef]
- Duarte, J.J.; Montenegro Gonzalez, S.; Cruz Jr, J.C. Predicting stock price falls using news data: Evidence from the Brazilian market. Comput. Econ. 2021, 57, 311–340. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Viana, M.S.; Contreras, R.C.; Morandin Junior, O. A New Frequency Analysis Operator for Population Improvement in Genetic Algorithms to Solve the Job Shop Scheduling Problem. Sensors 2022, 22, 4561. [Google Scholar] [CrossRef] [PubMed]
- Viana, M.S.; Morandin Jr, O.; Contreras, R.C. A new genetic improvement operator based on frequency analysis for Genetic Algorithms applied to Job Shop Scheduling Problem. In Proceedings of the Artificial Intelligence and Soft Computing (ICAISC 2021 Proceedings), Virtual, 21–23 June 2021; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 434–450. [Google Scholar]
- Viana, M.S.; Morandin Junior, O.; Contreras, R.C. A Modified Genetic Algorithm with Local Search Strategies and Multi-Crossover Operator for Job Shop Scheduling Problem. Sensors 2020, 20, 5440. [Google Scholar] [CrossRef] [PubMed]
- Viana, M.S.; Morandin Junior, O.; Contreras, R.C. An Improved Local Search Genetic Algorithm with a New Mapped Adaptive Operator Applied to Pseudo-Coloring Problem. Symmetry 2020, 12, 1684. [Google Scholar] [CrossRef]
- Viana, M.S.; Morandin Junior, O.; Contreras, R.C. An Improved Local Search Genetic Algorithm with Multi-Crossover for Job Shop Scheduling Problem. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 12–14 October 2020; Springer: Cham, Switzerland, 2020; pp. 464–479. [Google Scholar]
- Contreras, R.C.; Morandin Junior, O.; Viana, M.S. A New Local Search Adaptive Genetic Algorithm for the Pseudo-Coloring Problem. In Advances in Swarm Intelligence; Springer: Cham, Switzerland, 2020; pp. 349–361. [Google Scholar]
| Type | Time Series |
|---|---|
| Cryptocurrencies | Bitcoin |
| Commodities | Crude Oil, Gold, Silver, Coffee, Heating Oil, Natural Gas, Platinum, Palladium, Copper, Cocoa, Sugar, Oat |
| Stock Market Indexes | S&P 500, NASDAQ, DAX, KOSPI |
| Type | Time Series |
|---|---|
| Stocks | Vale, Petrobras, Usiminas, EcoRodovias, Raia Drogasil, Equatorial Energia, JBS, SABESP, BB Seguridade, EDP, Banco do Brasil, Itaúsa, Banco Bradesco, Multiplan, Itaú, Eletrobrás, B3, Ambev, Klabin |
| Commodities | Crude Oil, Gold, Rice, Soybean, Natural Gas, Silver, Corn, Wheat, Oat, Copper |
| Stock Market Indexes | Ibovespa, S&P 500, Dow Jones Industrial Average, NASDAQ, NYSE COMPOSITE, NYSE AMEX COMPOSITE INDEX, Cboe UK 100, Russell 2000 |
| Futures | Nasdaq 100, E-Mini S&P 500, MSCI World Index Futures |
| Currencies | US Dollar, Euro, British Pound |
| Day D | Lag (1 to 7) | WMA (30 days) |
|---|---|---|
| Open | Direction | Open |
| Open | High | |
| High | Low | |
| Low | Close | |
| Close | Volume | |
| Volume | Number of Transactions | |
| Number of Transactions | Transaction Fees | |
| Transaction Fees | Cost per Transaction | |
| Cost per Transaction | Average Hash Rate | |
| Average Hash Rate | ||
| Day D | Lag (1 to 7) | WMA (30 days) | WMA (30 days) |
|---|---|---|---|
| Open | Direction | Open | |
| Open | High | ||
| High | Low | ||
| Low | Close | ||
| Close | Volume | ||
| Volume | |||
| Experiment | Start Date | End Date | Training | Test |
|---|---|---|---|---|
| E1 - I1 | 08/19/2013 | 07/19/2016 | 08/19/2013–12/18/2015 (80%) | 12/19/2015–07/19/2016 (20%) |
| E1 - I2 | 04/01/2013 | 04/01/2017 | 04/01/2013–03/31/2016 (75%) | 04/01/2016–04/01/2017 (25%) |
| E2 - I1 | 01/01/2018 | 01/01/2021 | 01/01/2018–05/27/2020 (80%) | 05/28/2020–01/01/2021 (20%) |
| E2 - I2 | 01/01/2018 | 01/01/2022 | 01/01/2018–12/30/2020 (75%) | 12/31/2020–01/01/2022 (25%) |
| E3 - I1 | 01/01/2018 | 01/01/2021 | 01/01/2018–05/27/2020 (80%) | 05/28/2020–01/01/2021 (20%) |
| E3 - I2 | 01/01/2018 | 01/01/2022 | 01/01/2018–12/30/2020 (75%) | 12/31/2020–01/01/2022 (25%) |
| Operator/Parameter | Value |
|---|---|
| Population Size | 100 |
| Number of Generations | 10,000 (filter) | 1000 (wrapper) |
| Selection | Roulette Wheel |
| Crossover | two points |
| Mutation Probability | 0.001 |
| Replacement | elitism |
| Operator/Parameter | Value |
|---|---|
| Population Size | 100 |
| Number of Generations | 500 |
| Selection | rank |
| Crossover | two points |
| Mutation Probability | 0.01 |
| Replacement | elitism |
| Model | Tested Parameters |
|---|---|
| SVM | Regularization Parameter: 0.1; 0.5; 1; 3; 5; 7; 10 |
| Degree of the Polynomial Kernel: 1; 2;...; 9 | |
| Gamma Kernel Coefficient: ; | |
| RF | Max Depth: 1; 2;...; 29 |
| Number of Trees: 10; 20;...; 150 | |
| Number of Features to Consider for the Best Split: 1; 2;...; 9 | |
| MLP | Number of Hidden Layers: 2; 3 |
| Number of Neurons: 2; 4; 8; 16 | |
| Epochs 100; 200;...; 500 | |
| KNN | Number of Neighbors: 2; 3;...; 99 |
| Distance Metric: Manhattan; Euclidean | |
| LR | Regularization: 0.1; 0.5; 1; 3; 5; 7; 10 |
| Model | Tested Parameters |
|---|---|
| SVM | Regularization Parameter (C): 0.5; 1.0; 1.5; 10.0 |
| Kernel: Radial Basis, Polynomial | |
| Gamma Kernel Coefficient (): ; 0.1; 1.0; 10.0 | |
| Degree of the Polynomial Kernel (d): 1, 2, 3, 4 | |
| DT | Criterion: Gini, Entropy |
| Max Depth: 3, 4, 5, 6, 7 | |
| Minimum Number of Samples to Split: 3, 6, 9 | |
| Minimum Number of Samples to be at a Leaf Node: 1, 4, 7 | |
| KNN | Number of Neighbors (k): 1, 2,..., 30 |
| Weights: Uniform, Distance |
| Inteval | Model | Feature Selection | AUROC | Accuracy |
|---|---|---|---|---|
| 1 | ANN | wrapper | 0.5± 0.03 | 50.79%± 6.9% |
| ANN | none | 0.5 ± 0.02 | 50.78% ± 6.99% | |
| ANN | filter | 0.49 ± 0.02 | 52.5% ± 6.16% | |
| KNN | filter | 0.58 ± 0.0 | 59.35% ± 0.0% | |
| KNN | wrapper | 0.54 ± 0.0 | 52.8% ± 0.0% | |
| KNN | none | 0.53 ± 0.0 | 53.74% ± 0.0% | |
| LR | filter | 0.54 ± 0.0 | 58.41% ± 0.0% | |
| LR | none | 0.53 ± 0.0 | 57.94% ± 0.0% | |
| LR | wrapper | 0.51 ± 0.0 | 57.94% ± 0.0% | |
| RF | filter | 0.51 ± 0.02 | 52.95% ± 3.56% | |
| RF | wrapper | 0.5 ± 0.01 | 57.41% ± 0.89% | |
| RF | none | 0.5 ± 0.02 | 53.77% ± 3.47% | |
| SVM | filter | 0.6 ± 0.0 | 59.81% ± 0.0% | |
| SVM | wrapper | 0.6 ± 0.0 | 58.88% ± 0.0% | |
| SVM | none | 0.57 ± 0.0 | 60.75% ± 0.0% | |
| 2 | ANN | wrapper | 0.51 ± 0.02 | 57.52% ± 7.88% |
| ANN | filter | 0.51 ± 0.03 | 53.39% ± 9.72% | |
| ANN | none | 0.5 ± 0.02 | 56.85% ± 7.77% | |
| KNN | none | 0.61 ± 0.0 | 55.45% ± 0.0% | |
| KNN | filter | 0.6 ± 0.0 | 59.55% ± 0.0% | |
| KNN | wrapper | 0.56 ± 0.0 | 51.82% ± 0.0% | |
| LR | wrapper | 0.57 ± 0.0 | 56.82% ± 0.0% | |
| LR | filter | 0.53 ± 0.0 | 62.27% ± 0.0% | |
| LR | none | 0.5 ± 0.0 | 50.91% ± 0.0% | |
| RF | none | 0.51 ± 0.03 | 43.4% ± 5.1% | |
| RF | wrapper | 0.49 ± 0.03 | 46.81% ± 6.56% | |
| RF | filter | 0.49 ± 0.03 | 43.69% ± 5.53% | |
| SVM | none | 0.58 ± 0.0 | 65.91% ± 0.0% | |
| SVM | filter | 0.58 ± 0.0 | 58.64% ± 0.0% | |
| SVM | wrapper | 0.54 ± 0.0 | 58.64% ± 0.0% |
| Day D | Lag (n) | WMA 30 Days |
|---|---|---|
| Open | Cost per Transaction (2, 6) | Number of Transactions |
| Average Hash Rate (1, 6) | Volume | |
| Number of Transactions (1, 3) | ||
| Transaction Fees (4, 7) | Open | |
| Volume (1, 6, 7) | ||
| Direction (1, 5, 7) | ||
| High (1, 2) | ||
| Low (4, 5) |
| Interval 1 (I1) | Inteval 2 (I2) | ||||
|---|---|---|---|---|---|
| Model | ACC | AUROC | Model | ACC | AUROC |
| SVM: 1.5|p||3 (D1—filter) | 59.86% ± 0.0% | 0.62 ± 0.0 | SVM: 1.0|r||0 (D3—wrapper) | 56.36% ± 0.0% | 0.56 ± 0.0 |
| DT: g|5|4|3 (D2—wrapper) | 61.41% ± 1.69% | 0.60 ± 0.02 | DT: g|4|1|6 (D3—none) | 61.44% ± 0.0% | 0.61 ± 0.0 |
| KNN: 26|u (D4—none) | 55.63% ± 0.0% | 0.56 ± 0.0 | KNN: 26|d (D3—filter) | 55.51% ± 0.0% | 0.55 ± 0.0 |
| Inteval 1 (I1) | Interval 2 (I2) | ||||
|---|---|---|---|---|---|
| Model | ACC | AUROC | Model | ACC | AUROC |
| SVM: 1.5|p||3 (D3—wrapper) | 53.52% ± 0.0% | 0.52 ± 0.0 | SVM: 10.0|r||0 (D3—none) | 57.63% ± 0.0% | 0.57 ± 0.0 |
| DT: g|5|1|6 (D3—filter) | 55.63% ± 0.0% | 0.55 ± 0.0 | DT: g|3|1|3 (D2—none) | 57.41% ± 0.69% | 0.58 ± 0.01 |
| KNN: 5|u (D2—wrapper) | 56.34% ± 0.0% | 0.57 ± 0.0 | KNN: 24|u (D3—filter) | 53.81% ± 0.0% | 0.55 ± 0.0 |
| Experiment—Interval | D1 | D2 | D3 | D4 |
|---|---|---|---|---|
| E2—I1 | 0.62 | 0.60 | 0.56 | 0.58 |
| E2—I2 | 0.50 | 0.56 | 0.61 | 0.58 |
| E3—I1 | 0.51 | 0.57 | 0.55 | 0.53 |
| E3—I2 | 0.50 | 0.58 | 0.57 | 0.53 |
| Experiment—Interval | Filter | Wrapper | None |
|---|---|---|---|
| E2—I1 | 0.62 | 0.60 | 0.56 |
| E2—I2 | 0.58 | 0.56 | 0.61 |
| E3—I1 | 0.55 | 0.57 | 0.57 |
| E3—I2 | 0.55 | 0.57 | 0.58 |
| Experiment—Interval | KNN | DT | SVM |
|---|---|---|---|
| E2—I1 | 0.62 | 0.60 | 0.56 |
| E2—I2 | 0.56 | 0.61 | 0.55 |
| E3—I1 | 0.52 | 0.55 | 0.57 |
| E3—I2 | 0.57 | 0.58 | 0.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Contreras, R.C.; Xavier da Silva, V.T.; Xavier da Silva, I.T.; Viana, M.S.; Santos, F.L.d.; Zanin, R.B.; Martins, E.F.O.; Guido, R.C. Genetic Algorithm for Feature Selection Applied to Financial Time Series Monotonicity Prediction: Experimental Cases in Cryptocurrencies and Brazilian Assets. Entropy 2024, 26, 177. https://doi.org/10.3390/e26030177
Contreras RC, Xavier da Silva VT, Xavier da Silva IT, Viana MS, Santos FLd, Zanin RB, Martins EFO, Guido RC. Genetic Algorithm for Feature Selection Applied to Financial Time Series Monotonicity Prediction: Experimental Cases in Cryptocurrencies and Brazilian Assets. Entropy. 2024; 26(3):177. https://doi.org/10.3390/e26030177
Chicago/Turabian StyleContreras, Rodrigo Colnago, Vitor Trevelin Xavier da Silva, Igor Trevelin Xavier da Silva, Monique Simplicio Viana, Francisco Lledo dos Santos, Rodrigo Bruno Zanin, Erico Fernandes Oliveira Martins, and Rodrigo Capobianco Guido. 2024. "Genetic Algorithm for Feature Selection Applied to Financial Time Series Monotonicity Prediction: Experimental Cases in Cryptocurrencies and Brazilian Assets" Entropy 26, no. 3: 177. https://doi.org/10.3390/e26030177
APA StyleContreras, R. C., Xavier da Silva, V. T., Xavier da Silva, I. T., Viana, M. S., Santos, F. L. d., Zanin, R. B., Martins, E. F. O., & Guido, R. C. (2024). Genetic Algorithm for Feature Selection Applied to Financial Time Series Monotonicity Prediction: Experimental Cases in Cryptocurrencies and Brazilian Assets. Entropy, 26(3), 177. https://doi.org/10.3390/e26030177