

An Information-Theoretic Method for Identifying Effective Treatments and Policies at the Beginning of a Pandemic

Abstract
1. Introduction
2. Methods
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. The Information-Theoretic Inferential Model
Appendix A.1.1. Definitions and Problem Specification
Appendix A.1.2. The Model—A Summary
References
- Golan, A.; Mumladze, T.; Wilson, D.; Cohen, E.; McGuinness, T.; Mooney, W.; Moon, J. Effect of Universal TB Vaccination and Other Policy-Relevant Factors on the Probability of Patient Death from COVID-19. 2020. Available online: https://hceconomics.uchicago.edu/research/working-paper/effect-universal-tb-vaccination-and-other-policy-relevant-factors (accessed on 23 September 2024).
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Levine, R.D.; Tribus, M. The Maximum Entropy Formalism; MIT Press: Cambridge, MA, USA, 1979. [Google Scholar]
- Skilling, J. Data analysis: The maximum entropy method. Nature 1984, 309, 748–749. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Skilling, J. The Axioms of Maximum Entropy. In Maximum-Entropy and Bayesian Methods in Science and Engineering; Erickson, G.J., Smith, C.R., Eds.; Springer: Dutch, The Netherlands, 1988; pp. 173–187. [Google Scholar] [CrossRef]
- Shore, J.E.; Johnson, R.W. Axiomatic Derivation of the Principle of Maximum Entropy and the Principle of Minimum Cross-Entropy. IEEE Trans. Inf. Theory 1980, 26, 26–37. [Google Scholar] [CrossRef]
- Golan, A.; Harte, J. Information theory: A foundation for complexity science. Proc. Natl. Acad. Sci. USA 2022, 119, e2119089119. [Google Scholar] [CrossRef] [PubMed]
- Golan, A.; Judge, G.; Perloff, J.M. A Maximum Entropy Approach to Recovering Information from Multinomial Response Data. J. Am. Stat. Assoc. 1996, 91, 841–853. [Google Scholar] [CrossRef]
- Golan, A. Foundations of Info-Metrics: Modeling, Inference, and Imperfect Information; Oxford University Press: New York, NY, USA, 2018; ISBN 9780199349531. [Google Scholar]
- Karlberg, J. Do Men Have a Higher Case Fatality Rate of Severe Acute Respiratory Syndrome than Women Do? Am. J. Epidemiol. 2004, 159, 229–231. [Google Scholar] [CrossRef]
- Open COVID-19 Data Working Group. Detailed Epidemiological Data from the COVID-19 Outbreak. Available online: https://github.com/beoutbreakprepared/nCoV2019 (accessed on 24 April 2020).
- Rivas, M.N.; Ebinger, J.E.; Wu, M.; Sun, N.; Braun, J.; Sobhani, K.; Van Eyk, J.E.; Cheng, S.; Arditi, M. BCG vaccination history associates with decreased SARS-CoV-2 seroprevalence across a diverse cohort of health care workers. J. Clin. Investig. 2021, 131, 1. [Google Scholar] [CrossRef]
- Zwerling, A.; Behr, M.A.; Verma, A.; Brewer, T.F.; Menzies, D.; Pai, M. The of Global BCG Vaccination Policies and Practices. PLoS Med. 2011, 8, e1001012. [Google Scholar] [CrossRef]
- World Bank Open Data. Available online: https://data.worldbank.org (accessed on 19 May 2020).
- Riffe, T.; Acosta, E.; the COVerAGE-DB team. Data Resource Profile: COVerAGE-DB: A global demographic database of COVID-19 cases and deaths. Int. J. Epidemiol. 2021, 50, 390. [Google Scholar] [CrossRef]
- Yu, Z.; Bellander, T.; Bergström, A.; Dillner, J.; Eneroth, K.; Engardt, M.; Georgelis, A.; Kull, I.; Ljungman, P.; Pershagen, G.; et al. Association of Short-term Air Pollution Exposure with SARS-CoV-2 Infection Among Young Adults in Sweden. JAMA Netw. Open 2022, 5, e228109. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Nethery, R.C.; Sabath, M.B.; Braun, D.; Dominici, F. Air pollution and COVID-19 mortality in the United States: Strengths and limitations of an ecological regression analysis. Sci. Adv. 2020, 6, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Petrosillo, N.; Viceconte, G.; Ergonul, O.; Ippolito, G.; Petersen, E. COVID-19, SARS and MERS: Are they closely related? Clin. Microbiol. Infect. 2020, 26, 729–734. [Google Scholar] [CrossRef] [PubMed]
- Berg, M.K.; Yu, Q.; Salvador, C.E.; Melani, I.; Kitayama, S. Mandated Bacillus Calmette-Guérin (BCG) vaccination predicts flattened curves for the spread of COVID-19. Sci. Adv. 2020, 6, 1–7. [Google Scholar] [CrossRef]
- Faustman, D.L.; Lee, A.; Hostetter, E.R.; Aristarkhova, A.; Ng, N.C.; Shpilsky, G.F.; Tran, L.; Wolfe, G.; Takahashi, H.; Dias, H.F.; et al. Multiple BCG vaccinations for the prevention of COVID-19 and other infectious diseases in type 1 diabetes. Cell Rep. Med. 2022, 3, 1–12. [Google Scholar] [CrossRef]
- He, G.; Fan, M.; Zhou, M. The effect of air pollution on mortality in China: Evidence from the 2008 Beijing Olympic Games. J. Environ. Econ. Manag. 2016, 79, 18–39. [Google Scholar] [CrossRef]
- Singh, S.; Saavedra-Avila, N.A.; Tiwari, S.; Porcelli, S.A. A century of BCG vaccination: Immune mechanisms, animal models, non-traditional routes and implications for COVID-19. Front. Immunol. 2022, 13, 959656. [Google Scholar] [CrossRef]
- Parmar, K.; Siddiqui, A.; Nugent, K. Bacillus Calmette-Guerin Vaccine and Nonspecific Immunity. Am. J. Med. Sci. 2021, 361, 683–689. [Google Scholar] [CrossRef]
- Pittet, L.F.; Messina, N.L.; Orsini, F. Randomized Trial of BCG Vaccine to Protect against Covid-19 in Health Care Workers. NEJM 2023, 388, 1582–1596. [Google Scholar] [CrossRef]
- ten Doesschate, T.; van der Vaart., T.W.; Debisarun., P.A.; Taks, E.; Moorlag, S.J.C.F.M.; Paternotte, N.; Boersma, W.G.; Kuiper, V.P.; Roukens, A.H.E.; Rijnders, B.J.A.; et al. Bacillus Calmette-Guérin vaccine to reduce healthcare worker absenteeism in COVID-19 pandemic, a randomized controlled trial. CMI 2022, 28, 1278–1285. [Google Scholar] [CrossRef]
- Rabin, R/C. Why a Century-Old Vaccine Offers New Hope Against Pathogens. The New York Times. 2022. Available online: https://www.nytimes.com/2022/08/16/health/bcg-vaccine-diabetes-covid.html (accessed on 23 September 2024).
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
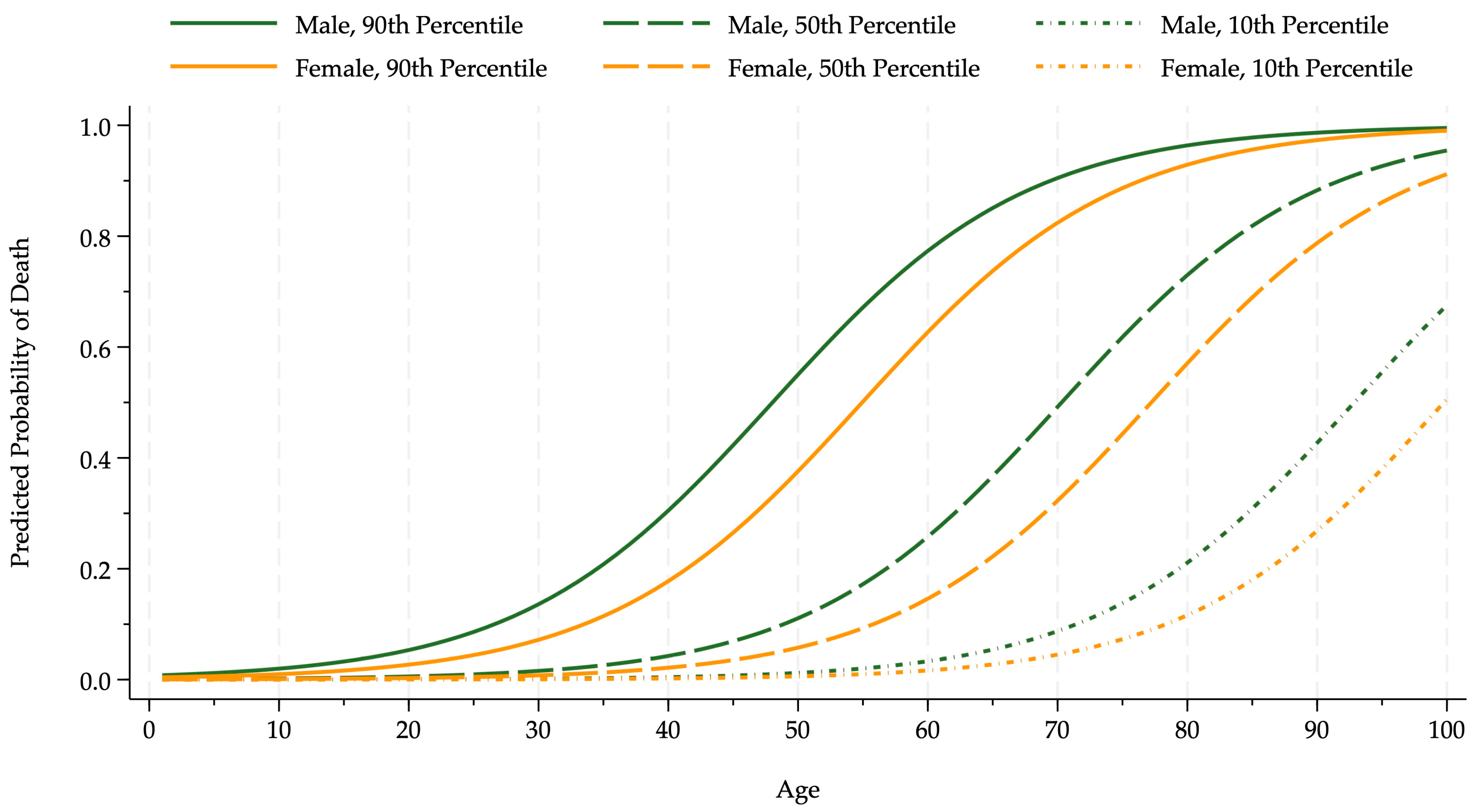
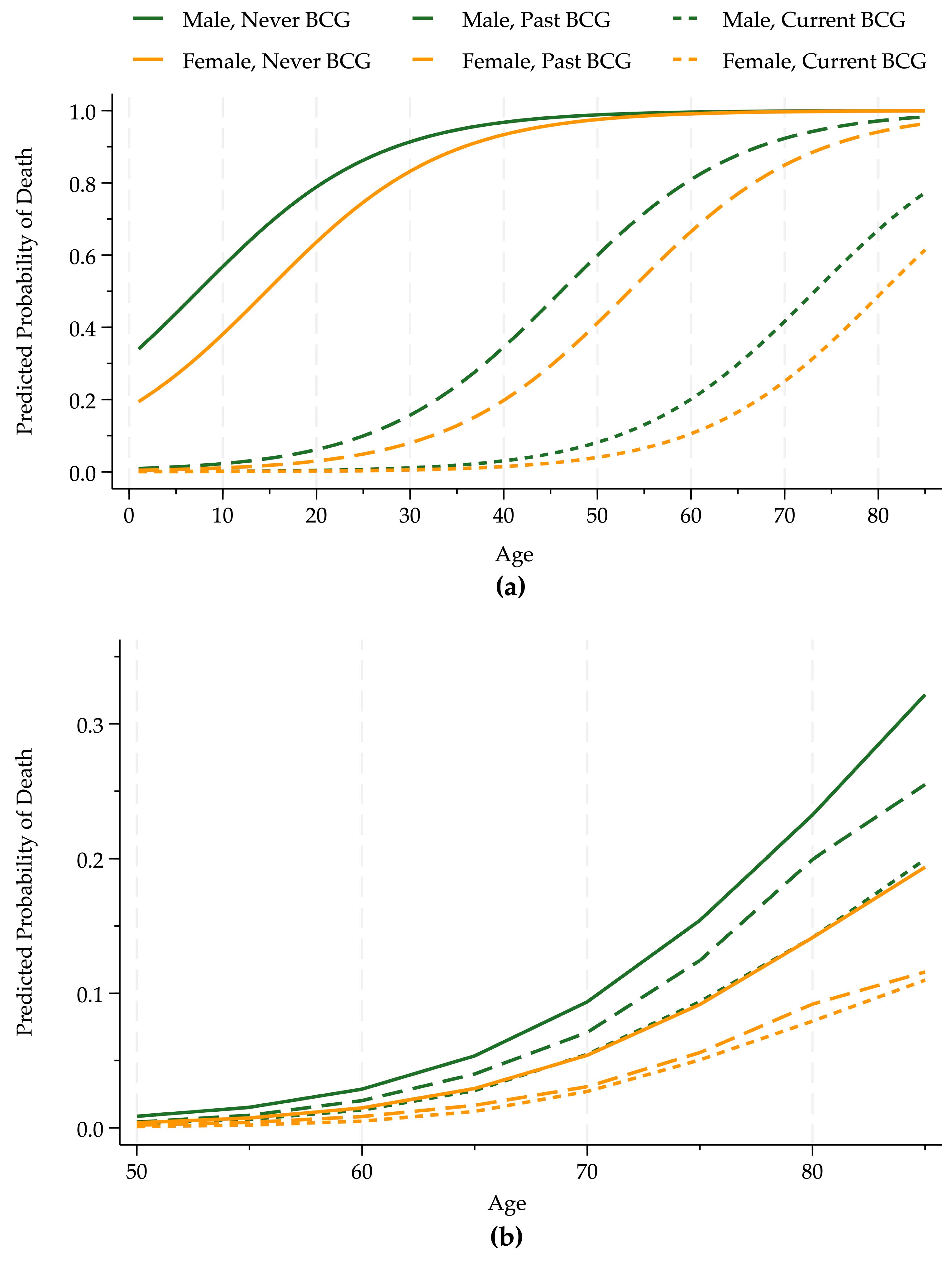

{kind=link}
{kind=link}
| Coefficients | Marginal Effects | |
|---|---|---|
| Female | −0.4545 | −0.0357 |
| (−1.163, 0.254) | (−0.091, 0.02) | |
| z = −1.26 | z = −1.26 | |
| Age | 0.0524 | 0.0048 |
| (0.029, 0.075) | (0.002, 0.008) | |
| z = 4.48 | z = 2.89 | |
| BCG never | 5.9907 | 0.4528 |
| (3.85, 8.131) | (0.360, 0.546) | |
| z = 5.49 | z = 9.58 | |
| BCG past | 2.6471 | 0.1721 |
| (0.557, 4.737) | (0.06, 0.284) | |
| z = 2.48 | z = 3.01 | |
| Health expenditure | −0.0019 | −0.0002 |
| (−0.003, −0.001) | (−0.0033, −0.0004) | |
| z = −2.60 | z = −1.89 | |
| Air pollution | 0.0287 | 0.0026 |
| (0.014, 0.043) | (0.001, 0.005) | |
| z = 3.86 | z = 2.69 | |
| Measles | −0.0925 | −0.0085 |
| (−0.189, 0.004) | (−0.019, 0.002) | |
| z = −1.88 | z = −1.57 | |
| Hepatitis B | 0.1666 | 0.0154 |
| (0.074, 0.259) | (0.003, 0.028) | |
| z = 3.53 | z = 2.37 | |
| Constant | −10.9248 | |
| (−16.761, −5.089) | ||
| z = −3.67 | ||
| Observations | 485 | |
| Degrees of freedom | 9 | |
| Pseudo R2 | 0.5417 | |
| Evaluation Score | With Informative Priors |
|---|---|
| Prediction Success | |
| Correct classification rate | 82.6% |
| Sensitivity (actual 1 s are correctly predicted) | 98.7% |
| Specificity (actual 0 s are correctly predicted) | 72.3% |
| Positive predictive value (predicted 1 s that were actual 1 s) | 69.3% |
| Negative predictive value (predicted 0 s that were actual 0 s) | 98.9% |
| Prediction Failure | |
| False positive rate for true survival (actual 0 s predicted as 1 s) | 27.7% |
| False negative rate for true death (actual 1 s predicted as 0) | 1.3% |
| False positive rate for classified death (predicted 1s that are actual 0 s) | 30.7% |
| False negative rate for classified survival (predicted 0 s that are actual 1s) | 1.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golan, A.; Mumladze, T.; Perloff, J.M.; Wilson, D. An Information-Theoretic Method for Identifying Effective Treatments and Policies at the Beginning of a Pandemic. Entropy 2024, 26, 1021. https://doi.org/10.3390/e26121021
Golan A, Mumladze T, Perloff JM, Wilson D. An Information-Theoretic Method for Identifying Effective Treatments and Policies at the Beginning of a Pandemic. Entropy. 2024; 26(12):1021. https://doi.org/10.3390/e26121021
Chicago/Turabian StyleGolan, Amos, Tinatin Mumladze, Jeffery M. Perloff, and Danielle Wilson. 2024. "An Information-Theoretic Method for Identifying Effective Treatments and Policies at the Beginning of a Pandemic" Entropy 26, no. 12: 1021. https://doi.org/10.3390/e26121021
APA StyleGolan, A., Mumladze, T., Perloff, J. M., & Wilson, D. (2024). An Information-Theoretic Method for Identifying Effective Treatments and Policies at the Beginning of a Pandemic. Entropy, 26(12), 1021. https://doi.org/10.3390/e26121021