1. Introduction
Let be a measurable space with sample space and -algebra of events , and a positive measure. We consider a finite set of n probability distributions all dominated by and weighted by a vector w belonging to the open standard simplex . Let be the Radon–Nikodym densities of with respect to , i.e., .
The Kullback–Leibler divergence (KLD) between two densities
and
is defined by
. The KLD is asymmetric:
. We use the argument delimiter ‘:’ as a notation to indicate this asymmetry. The Jeffreys divergence [
1] symmetrizes the KLD as follows:
In general, the
D-barycenter
of
with respect to a statistical dissimilarity measure
yields a notion of centrality
defined by the following optimization problem:
Here, the upper case letter ‘R’ indicates that the optimization defining the
D-barycenter is carried on the right argument. When
is the uniform weight vector, the
D-barycenter is called the
D-centroid. We shall loosely call centroids barycenters in the remainder even when the weight vector is not uniform. Centroids with respect to information-theoretic measures have been studied in the literature.
Let us mention some examples of centroids: The entropic centroids [
2] (i.e., Bregman centroids and
f-divergences centroids), the Burbea–Rao and Bhattacharyya centroids [
3], the
-centroids with respect to
-divergences [
4], the Jensen–Shannon centroids [
5], etc.
The
-centroid is also called the symmetric Kullback–Leibler (SKL) divergence centroid [
6] in the literature. However, since there are many possible symmetrizations of the KLD [
7] like the Jensen–Shannon divergence [
8] or the resistor KLD [
9], we prefer to use the term Jeffreys centroid instead of SKL centroid to avoid any possible ambiguity on the underlying divergence. Notice that the square root of the Jensen–Shannon divergence is a metric distance [
10,
11] but all powers
of Jeffreys divergence
for
do not yield metric distances [
12].
This paper considers the Jeffreys centroids of a finite weighted set of densities
belonging to some prescribed exponential family [
13]
:
In particular, we are interested in computing the Jeffreys centroids for sets of categorical distributions or sets of multivariate normal distributions [
14].
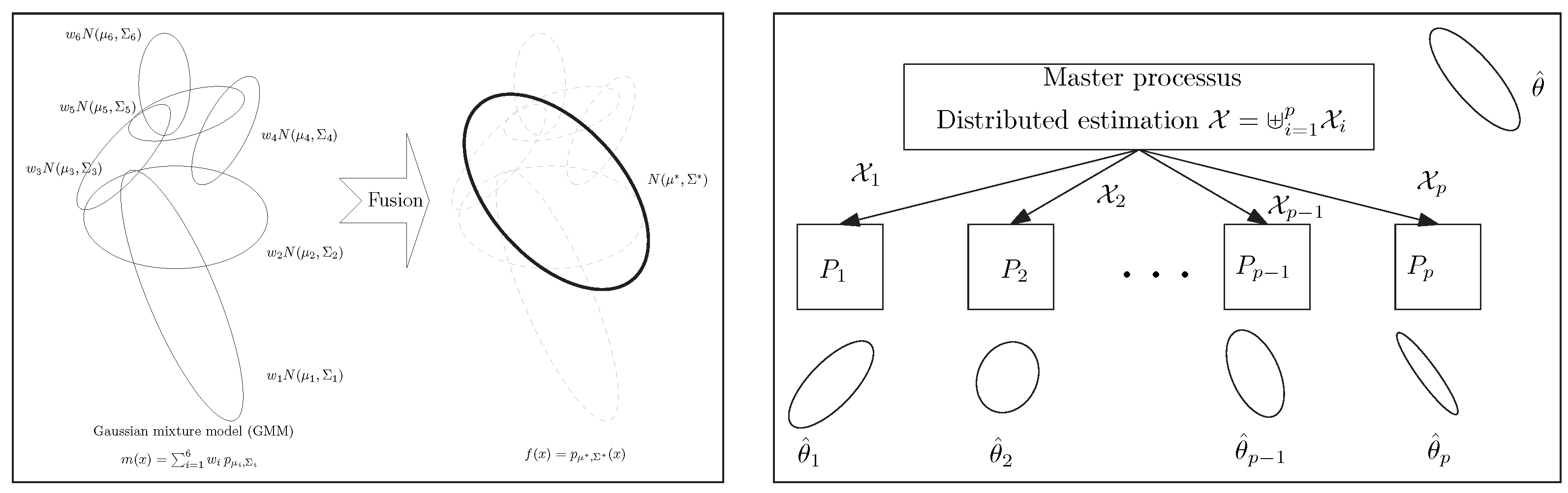
In general, centroids are used in
k means [
15,
16]-type clustering or hierarchical clustering (e.g., Ward criterion [
17]) and information fusion tasks [
18] (related to distributed model estimation [
19]) among others. See
Figure 1. The choice of the dissimilarity measure depends on the application at hand [
20]. Clustering with respect to Jeffreys divergence/-Jeffreys centroid has proven useful in many scenarios: for example, it was shown to perform experimentally better than Euclidean or square Euclidean distances for compressed histograms of gradient descriptors [
21] or in fuzzy clustering [
22]. Jeffreys divergence has also been used for image processing [
23], including image segmentation [
24], speech processing [
25], and computer vision [
26], just to name a few. In particular, finding weighted means of centered 3D normal distributions plays an important role in diffusion tensor imaging (DTI) for smoothing and filtering DT images [
27] which consist of sets of normal distributions centered at 3D grid locations.
In general, the Jeffreys centroid is not known in closed form for exponential families [
28] like the family of categorical distributions or the family of normal distributions often met in applications and thus needs to be numerically approximated in practice. The main contribution of this paper is to present and study two proxy centers as drop-in replacements of the Jeffreys centroids in applications and report the generic structural formula for generic exponential families with an explicit closed-form formula for the families of categorical and multivariate normal distributions. Namely, we define the Jeffreys–Fisher–Rao (JFR) center (Definition 2) and the Gauss–Bregman (GB) inductive center (Definition 3) in
Section 2.
This paper is organized as follows: By interpreting in two different ways the closed-form formula of the Jeffreys centroids for the particular case of sets of centered multivariate normal distributions [
29] (proof reported in
Appendix B), we define the Gauss–Bregman (GB) centers and the Jeffreys–Fisher–Rao (JFR) centers for sets of densities belonging to an exponential family in
Section 2. The Jeffreys centroid coincides with both the Gauss–Bregman inductive center and the Jeffreys–Fisher–Rao center for centered multivariate normal distributions but differ from each other in general. In
Section 2.4, we study the Gauss–Bregman inductive center [
30] induced by the cumulant function of an exponential family and prove the convergence under the separability condition of the generalized Gauss double sequences in the limit (Theorem 3). This Gauss–Bregman center can be easily approximated by limiting the number of iterations of a double sequence inducing it. In
Section 4, we report the generic formula for Jeffreys–Fisher–Rao centers for sets of uni-order exponential families [
13] and explicitly give the closed-form formula for the categorical family and the multivariate normal family. A comparison of those proxy centers with the numerical Jeffreys centroids is experimentally studied and visually illustrated with some examples. Thus, we propose to use in applications (e.g., clustering) either the fast Jeffreys–Fisher–Rao center when a closed-form formula is available for the family of distributions at hand or the Gauss–Bregman center approximation with a prescribed number of iterations as a drop-in replacement of the numerical Jeffreys centroids while keeping the Jeffreys divergence. Some experiments of the JFR and GB centers are reported for the Jeffreys centroid of categorical distributions in
Section 5. Finally, we conclude this paper in
Section 6 with a discussion and a generalization of our results to the more general setting of dually flat spaces of information geometry [
14].
The core of this paper is followed by an Appendix section as follows: In
Appendix A, we explicitly give the algorithm outlined in [
31] for numerically computing the Jeffreys centroid of sets of categorical distributions. In
Appendix B, we report a proof on the closed-form formula of the Jeffreys centroid for centered normal distributions [
29] that motivated this paper. In
Appendix C, we explain how to calculate in practice the elaborated closed-form formula for the Fisher–Rao geodesic midpoint between two multivariate normal distributions [
32].
2. Proxy Centers for Jeffreys Centroids
2.1. Background on Jeffreys Centroids
A density
belonging to an exponential family [
13]
can be expressed canonically as
, where
is a sufficient statistic vector,
is the log-normalizer, and
is the natural parameter belonging to the natural parameter space
. We consider minimal regular exponential families [
13] like the discrete family of categorical distributions (i.e.,
is the counting measure) or the continuous family of multivariate normal distributions (i.e.,
is the Lebesgue measure).
The Jeffreys centroid of categorical distributions was first studied by Veldhuis [
6], who designed a numerical two-nested loops Newton-like algorithm [
6]. A random variable
X following a categorical distribution
for a parameter
in sample space
is such that
. Categorical distributions are often used in image processing to statistically model normalized histograms with non-empty bins. The exact characterization of the Jeffreys centroid was given in [
31].
We summarize the results regarding the categorical Jeffreys centroid [
31] in the following theorem:
Theorem 1 (Categorical Jeffreys centroid [
31])
. The Jeffreys centroid of a set of n categorical distributions parameterized by arranged in a matrix and weighted by a vector is withwhere and are the j-th components of the weighted arithmetic and normalized geometric means, respectively; is the principal branch of the Lambert W function [33]; and is the unique real value such that . Furthermore, a simple bisection search is reported in [
31] §III.B that we convert into Algorithm A1 in
Appendix A, which allows one to numerically approximate the Jeffreys centroid to arbitrary fine precision.
2.2. Jeffreys Centroids on Exponential Family Densities: Symmetrized Bregman Centroids
The Jeffreys divergence between two densities of an exponential family
with cumulant function
amounts to a symmetrized Bregman divergence [
28] (SBD):
Using convex duality, we have
, where
and
is the Legendre–Fenchel convex conjugate. Thus, the Jeffreys barycenter of
amounts to either a symmetrized Bregman barycenter on the natural parameters
with respect to
or a symmetrized Bregman barycenter on the dual moment parameters
with respect to
.
It was shown in [
28] that the symmetrized Bregman barycenter
of
n weighted points amounts to the following minimization problem involving only the sided Bregman centroids:
where
(right Bregman centroid) and
(left Bregman centroid). Those
and
centers are centroids [
28] with respect to the Bregman divergence
and reverse Bregman divergence:
:
In general, when
is a strictly convex differentiable real-valued function of Legendre type [
34], the gradient
is globally invertible (in general, the implicit inverse function theorem only locally guarantees the inverse function) and we can define a quasi-arithmetic center of a point set
weighted by
w as follows:
Definition 1 (Quasi-arithmetic center)
. Let be the gradient of a strictly convex or concave differentiable real-valued function F of Legendre type. The quasi-arithmetic center is defined by This definition generalizes the scalar quasi-arithmetic means [
35] for univariate functions
h, which are continuous and strictly monotone. Quasi-arithmetic means (QAMs) are also called
f means or Kolmogorov–Nagumo means. Let
. Notice that
and
. That is, the arithmetic mean in a primal representation amounts to a QAM in the dual representation.
Thus, we can solve for
by setting the gradient of
to zero. In general, no closed-form formula is known for the symmetrized Bregman centroids, and a numerical approximation method was reported in [
28]. To circumvent the lack of a closed-form formula of symmetrized Bregman centroids for clustering, Nock et al. [
36] proposed a mixed Bregman clustering where each cluster has two representative dual Bregman centroids
(right Bregman centroid) and
(left Bregman centroid), and the dissimilarity measure is a mixed Bregman divergence defined by
Notice that minimizing Equation (3) amounts to minimizing the mixed Bregman divergence:
By using the dual parameterization
(with dual domain
) and the dual Bregman divergence
, we have
Since
and
, we obtain the dual equivalent optimization problem:
or
However, a remarkable special case is the family of multivariate normal distributions centered at the origin for which the Jeffreys centroid was reported in closed form in [
29]. Let
be the exponential family with sufficient statistics
, natural parameter
(the precision matrix) where the covariance matrix belongs to the cone
of symmetric positive-definite matrices, inner product
, and
. In that case, the Jeffreys divergence amounts to a symmetrized Bregman log-det (ld) divergence between the corresponding natural parameters:
Using the standard covariance matrix parameterization
, we can further express the Jeffreys divergence between two multivariate normal distributions
and
as
where
s are the eigenvalues of
. The symmetrized log-det divergence
is also called the symmetrized Stein loss [
37,
38]. When
, this divergence is the symmetrized Itakura–Saito divergence also called the COSH distance [
28]
. The Jeffreys centroid can be characterized using the Fisher–Rao geometry [
39] of
as the Fisher–Rao geodesic midpoint of the sided Kullback–Leibler centroids as follows:
Theorem 2 ([
29])
. The Jeffreys centroid C of a set of n centered multivariate normal distributions weighted with amounts to the symmetrized log-det Bregman centroid for the corresponding weighted set of positive-definite precision matrices . The symmetrized log-det Bregman barycenter C is the Riemannian geodesic midpoint of the arithmetic barycenter and harmonic barycenter where is the matrix geometric mean [40] : Since the proof of this result mentioned in [
29] was omitted in [
29], we report a proof involving matrix analysis in full detail in
Appendix B.
Next, we shall define two types of centers for sets of densities of a prescribed exponential family based on two different interpretations of Equation (5). We call them centers and not centroids because those points are defined by a generic structural formula instead of solutions of minimization problems of average divergences of Equation (1).
2.3. The Jeffreys–Fisher–Rao Center
Since an exponential family induces the Riemannian manifold with the Fisher metric g expressed in the -parameterization by the Fisher information matrix and Fisher–Rao geodesics defined with respect to the Levi-Civita connection (induced by g), we shall define the Jeffreys–Fisher–Rao center on using the Fisher–Rao geodesics as follows:
Definition 2 (Jeffreys–Fisher–Rao (JFR) center)
. The Jeffreys–Fisher–Rao center of a set of weighted densities by is defined as the Fisher–Rao midpoint of the sided Kullback–Leibler centroids and :where . Equation (6) is a generalization of Equation (5); therefore, the JFR center matches the Jeffreys centroid for same-mean multivariate normal distributions (Theorem 2).
Let and , where and . Denote by the JFR center of -coordinate . Then, = .
2.4. Gauss–Bregman Inductive Center
Another remarkable property of the Jeffreys centroid for a set
of same-mean multivariate normal distributions weighted by
with arithmetic and harmonic means
and
on the precision matrices
, respectively, is that we have the following invariance of the Jeffreys centroid (see Lemma 17.4.4 of [
29]):
Nakamura [
41] defined the following double sequence scheme converging to the matrix geometry mean
for any two symmetric positive-definite matrices
P and
Q:
initialized with
and
. We have
. Let
and
. That is, the geometric matrix mean can be obtained as the limits of a double sequence of means. We can thus approximate
by stopping the double sequence after
T iterations to obtain
Notice that we can recover those iterations from the invariance property of Equation (7): Indeed, we have
and
decreases [
41] as the number of iterations
t increases. Thus, by induction,
with
. Since
(means are reflexive), it follows that
. It is proved in [
41] that the convergence rate of the sequence of double iterations is quadratic. This type of mean has been called an inductive mean [
30,
42] (or compound mean [
43]) and originated from the Gauss arithmetic–geometric mean [
44].
Our second interpretation of the geometric matrix mean of Equation (5) is to consider it as an inductive mean [
30] and to generalize this double sequence process to pairs/sets of densities of an exponential family as follows:
Definition 3 (Gauss–Bregman
center)
. Let be a set of n distributions of an exponential family with the cumulant function weighted by a vector . Then, the Gauss–Bregman inductive center is defined as the limit of the double sequence:initialized with (right Bregman centroid) and (left Bregman centroid). That is, we have Let . Then, we have . The Gauss–Bregman center has -coordinates and -coordinates .
Algorithm 1 describes the approximation of the Gauss–Bregman inductive center by stopping the double sequence when the iterated centers are close enough to each other. We shall prove the matching convergence of those
and
sequences under separability conditions in
Section 2.4.
| Algorithm 1: Gauss–Bregman inductive center. |
![Entropy 26 01008 i001]() |
For example, the Gauss–Bregman center of two categorical distributions and on a sample space of d elements is obtained for the cumulant function with gradient where is the natural parameter. The reciprocal gradient is .
We may also compute the Gauss–Bregman center of two categorical distributions
and
using iterations of arithmetic means
and geometric normalized means
:
where the
s are unnormalized geometric means and the
represents normalized geometric means. We initialize the sequence with
and
, and the Gauss–Bregman center is obtained in the limit
. See Algorithm 2.
The Jeffreys centroid of a set of centered multivariate normal distributions is the Gauss–Bregman center obtained for the generator
, the cumulant function of the exponential family of centered normal distributions.
| Algorithm 2: Gauss–Bregman inductive center for sets of categorical distributions. |
![Entropy 26 01008 i002]() |
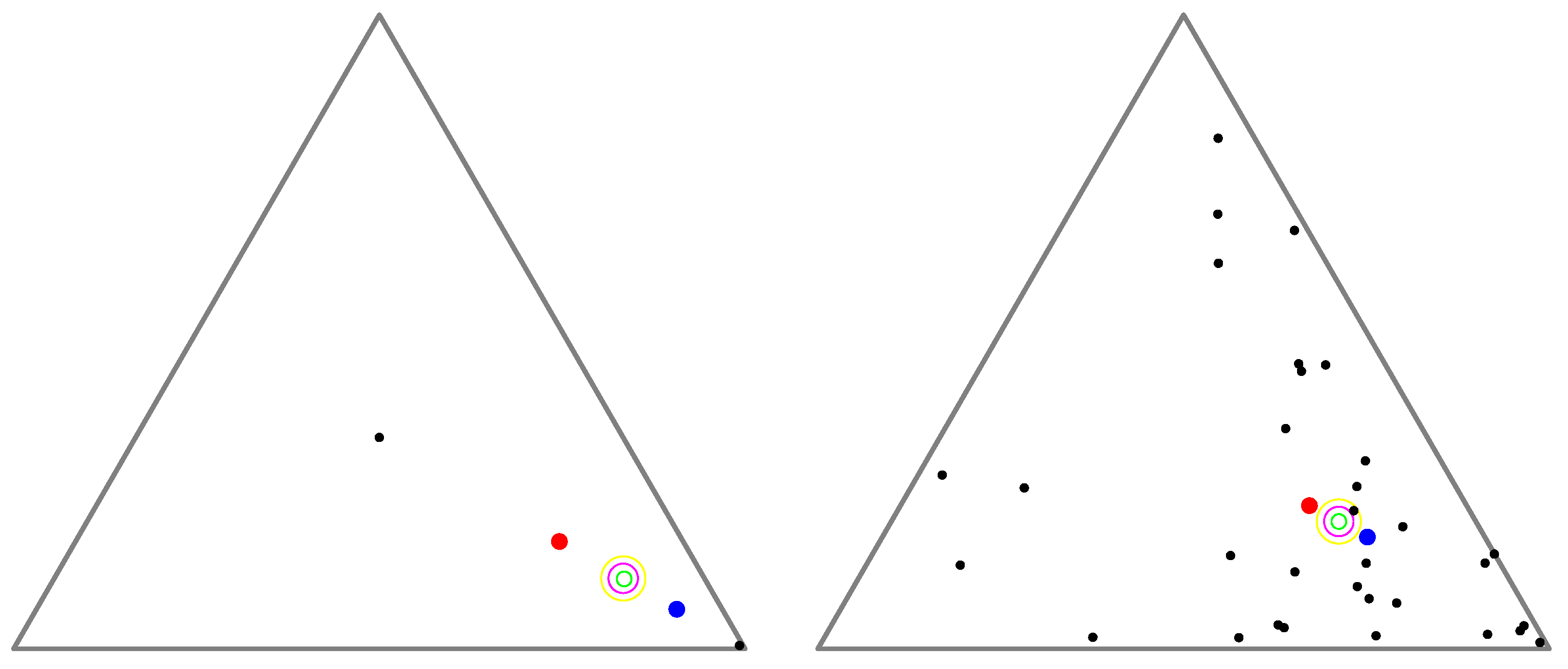
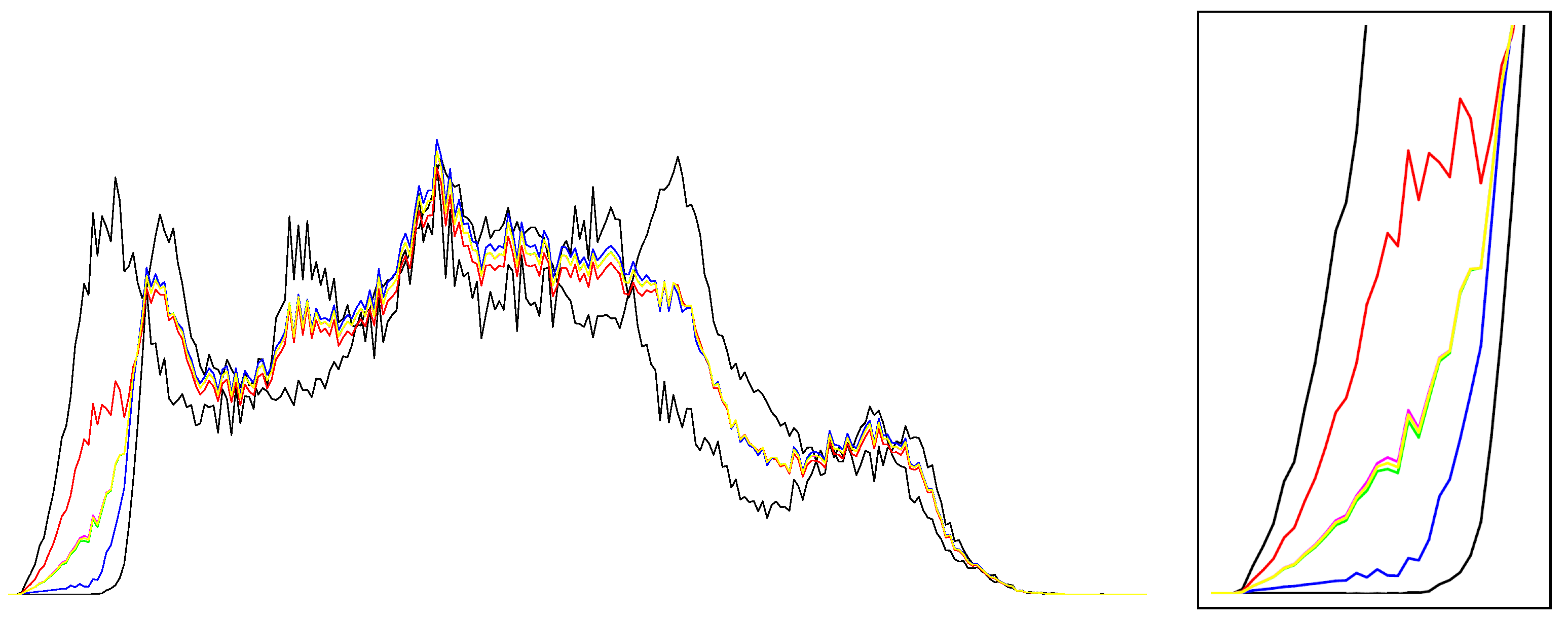
Figure 2 displays the arithmetic and normalized geometric and numerical Jeffreys, Jeffreys–Fisher–Rao, and Gauss–Bregman centroids/centers for a set of 32 trinomial distributions. We may consider normalized intensity histograms of images (modeled as multinomials with one trial) quantized with
bins; that is, a normalized histogram with
d bins is interpreted as a point in
and visualized as a polyline with
line segments.
Figure 3 (left) displays the various centroids and centers obtained for an input set consisting of two histograms (the commonly used
Barbara and
Lena images, which have been used in [
31]). Notice that the JFR center (purple) and GB center (yellow) are close to the numerical Jeffreys centroid (green). We also provide a close-up window in
Figure 3 (right).
Notice that we can experimentally check the quality of the approximation of the Gauss–Bregman center to the Jeffreys centroid by defining the symmetrized Bregman centroid energy:
and checking that
:
is close to zero, where
.
Next, we study these two new types of centers and how well they approximate the Jeffreys centroid.
3. Gauss–Bregman Inductive Centers: Convergence Analysis and Properties
Let
be a strictly convex and differentiable real-valued function of Legendre type [
45] defined on an open parameter space
. Then, the gradient map
is a bijection with the reciprocal inverse function
where
is the Legendre–Fenchel convex conjugate. For example, we may consider the cumulant functions of regular exponential families.
We define the Gauss–Bregman center
of a set
weighted by
as the limits of the sequences
and
defined by
initialized with
and
. That is, we have
Such a center has been called an inductive mean by Sturm [
30]. See [
42] for an overview of inductive means.
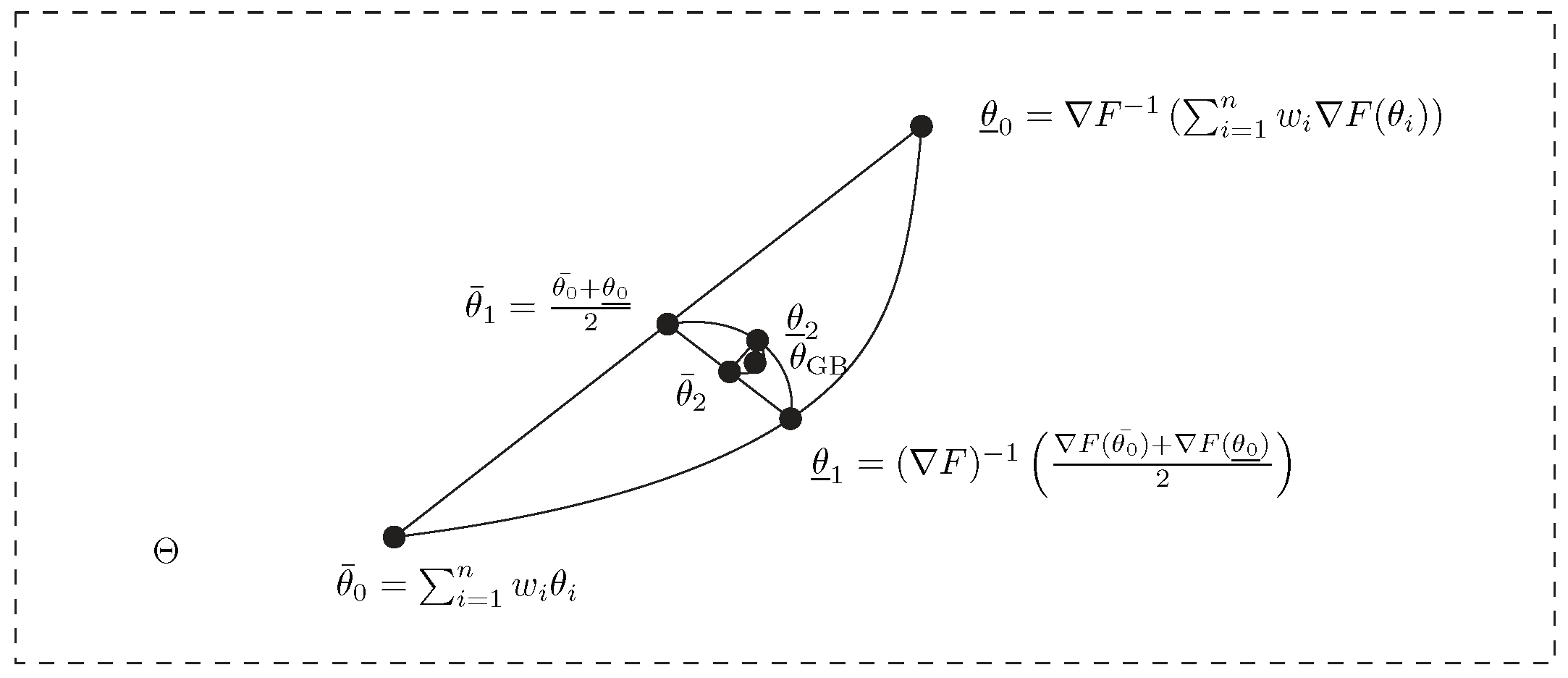
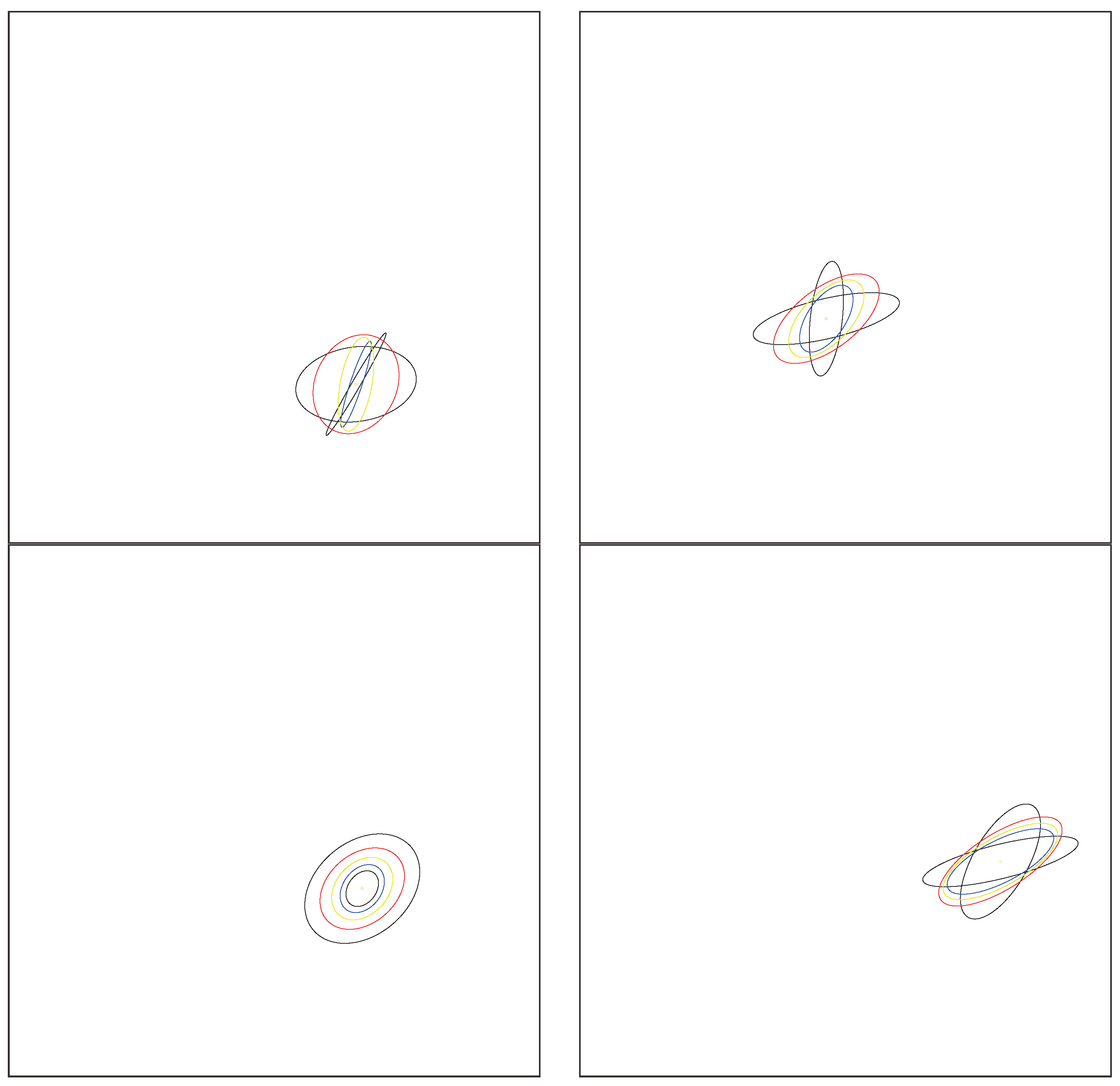
Figure 4 geometrically illustrates the double sequence iterations converging to the Gauss–Bregman mean.
Theorem 3. The Gauss–Bregman center with respect to a Legendre type function is well defined (i.e., the double sequence converges) for separable Bregman generators.
Proof. We need to prove the convergence of
and
to the same finite limit. When
is univariate, the convergence of the inductive centers was reported in [
43]. We need to prove that the double iterations of Equations (12) and (13) converge.
Let us consider the following cases:
When the dimension is one, the quasi-arithmetic mean
for
f, a strictly convex and differentiable function, lies between the minimal and maximal argument (i.e., this is the definition of a strict mean):
Thus, we have
and it follows that
. Thus, we have quadratic convergence of scalar
means. See
Figure 5.
When is multivariate and separable, i.e., where are the components of and the s are scalar strictly convex and differentiable functions, we can apply case 1 dimension-wise to obtain the quadratic convergence.
Otherwise, we consider the multivariate quasi-arithmetic center
with the uniform weight vector
. One problem we face is that the quasi-arithmetic center
for
may lie outside the open bounding box of
with diagonal corners
and
:
Indeed, in the 2D case, we may consider and . Clearly, the open bounding box is empty, and the midpoint lies outside this box. Yet, we are interested in the convergence rate when .
In general, we shall measure the difference between two iterations by the squared norm distance induced by the inner product:
□
Let denote the Gauss–Bregman center of and , the arithmetic mean, and the quasi-arithmetic center.
By construction, the Gauss–Bregman center enjoys the following invariance property generalizing Lemma 17.4.4 of [
29] in the case of the log det generator:
Property 1. We have .
Proof. Similar to the cascaded inequalities of Equation (8), we have
In the limit
, we have
Since
, we obtain the desired invariance property:
□
Note that when
is univariate, the Gauss–Bregman mean
converges at a quadratic rate [
43]. In particular, when
(Burg negentropy), we have
(
is the harmonic mean) and the Gauss–Bregman mean is the arithmetic–harmonic mean (AHM) which converges to the geometric mean, a simple closed-form formula. Notice that the geometric mean
of two scalars
and
can be expressed using the arithmetic mean
and the harmonic mean
:
. But when
(Shannon negentropy), the Gauss–Bregman mean
coincides with the Gauss arithmetic–geometric mean [
44] (AGM) since
and
, the geometric mean. Thus,
is related to the elliptic integral
K of the first type [
44]: there is no closed-form formula for the AGM in terms of elementary functions as this induced mean is related to the complete elliptic integral of the first kind
:
where
is the elliptic integral. Thus, it is difficult, in general, to report a closed-form formula for the inductive Gauss–Bregman means even for univariate generators
.
The Jeffreys centroid of
and
with respect to the scalar Jeffreys divergence
admits a closed-form solution [
31]:
where
and
and
is the principal branch of the Lambert
W function [
33]. This example shows that the Gauss–Bregman center does not coincide with the Jeffreys centroid in general (e.g., compare Equation (15) with Equation (16)).
5. Experiments
We run all experiments on a Dell Inspiron 5502 Core i7-116567@2.8 GHz using compiled Java programs. For each experiment, we consider a set of
uniformly randomized histograms with
d bins (i.e., points in
) and calculate the numerical Jeffreys centroid, which requires the time-consuming Lambert
W function, the GB center, and the JFR center. For each prescribed value of
d, we run 10,000 experiments to collect various statistics like the average and maximum approximations and running times. The approximations of the JFR and GB methods are calculated either as the approximation of the Jeffreys information (Equation (18)) or as the approximation of the centers with respect to the numerical Jeffreys centroids measured using the total variation distance.
Table 1 is a verbatim export of our experimental results when we range the dimension of histograms for
to
by doubling the dimension at each round. The inductive GB center is stopped when the total variation
.
We observe that the JFR center is faster to compute than the GB center but the GB center is of higher quality (i.e., a better approximation with a lower ) than the JFR center to approximate the numerical Jeffreys centroid.
Another test consists of choosing
and the following two 3D normalized histograms:
and
for
.
Table 2 reports the experiments. The objective is to find a setting where both the JFR and GB centers are distinguished from the Jeffreys centroid. We see that as we decrease
, the approximation factor
gets worse for both the JFR center and the GB center. The JFR center is often faster to compute than the GB inductive center, but the approximation of the GB center is better than the JFR approximation.
Finally, we implemented the Gauss–Bregman and Jeffreys–Fisher–Rao centers and Jeffreys centroid using multi-precision arithmetic. We report the following experiments using 200-digit precision arithmetic for the following input of two normalized histograms: and . We report the various first 17-digit mantissas obtained with the corresponding Jeffreys information:
Jeffreys center:
Jeffreys information: .
Gauss–Bregman center: (0.42490383904276856, 0.575096160957231439)
Jeffreys information: .
Jeffreys–Fisher–Rao center: (0.42490390202906282, 0.575096097970937175)
Jeffreys information: .
The total variation distance between the Jeffreys centroid and the Gauss–Bregman center is .
The total variation distance between the Jeffreys centroid and the Jeffreys–Fisher–Rao center is .
The total variation distance between the Gauss–Bregman center and the Jeffreys–Fisher–Rao center is .
Although all those points are close to each other, they are all distinct points (note that using the limited precision of the IEEE 754 floating point standard may yield a misleading interpretation of experiments).
6. Conclusions and Discussion
In this work, we considered the Jeffreys centroid of a finite weighted set of densities of a given exponential family
. This Jeffreys centroid amounts to a symmetrized Bregman centroid on the corresponding weighted set of natural parameters of the densities [
28]. In general, the Jeffreys centroids do not admit closed-form formulas [
28,
31] except for sets of same-mean normal distributions [
29] (see
Appendix B).
In this paper, we interpreted the closed-form formula for same-mean multivariate normal distributions in two different ways:
In general, the Jeffreys, JFR, and GB centers differ from each other (e.g., the case of categorical distributions). But for sets of same-mean normal distributions, they remarkably coincide altogether: namely, this was the point of departure of this research. We reported generic or closed-form formulas for the JFR centers of (a) uni-order parametric families in
Section 4.1 (Theorem 4), (b) categorical families in
Section 4.2 (Theorem 5), and (c) multivariate normal families in
Section 4.3 (Theorem 6).
Table 3 summarizes the new results obtained in this paper and states references of prior work. Notice that in practice, we approximate the Gauss–Bregman center by prescribing a number of iterations
for the Gauss–Bregman double sequence to obtain
. Prescribing the number of GB center iterations
T allows us to tune the time complexity of computing
while adjusting the quality of the approximation of the Jeffreys centroid.
In applications requiring the Jeffreys centroid, we thus propose to either use the fast Jeffreys–Fisher–Rao center when a closed-form formula is available for the family of distributions at hand or use the Gauss–Bregman center approximation with a prescribed number of iterations as a drop-in replacement of the numerical Jeffreys centroids while keeping the Jeffreys divergence (the centers we defined are not centroids as we do not exhibit distances from which they are population minimizers).
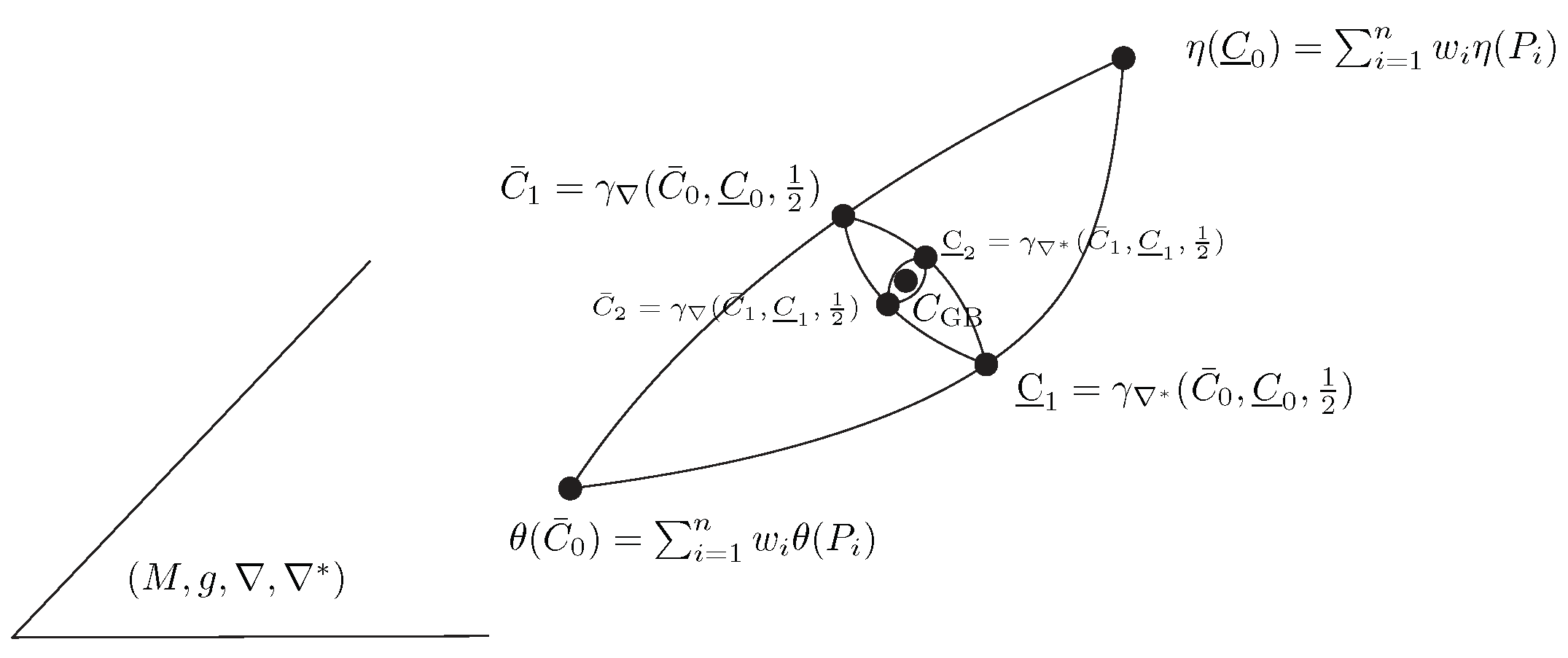
More generally, let us rephrase the results in a purely geometric setting using the framework of information geometry [
14]: let
be a set of
n points weighted by a vector
on an
m-dimensional dually flat space
with the ∇-affine coordinate system
and dual
-affine coordinate system
, where ∇ and
are two torsion-free dual affine connections. The Riemannian metric
g is a Hessian metric [
54], which may be expressed in the
-coordinate system as
or in the dual coordinate system as
, where
and
are dual convex potential functions related by the Legendre–Fenchel transform [
14,
54]. Let
and
be the coordinates of point
in the
- and
-coordinate systems, respectively. An arbitrary point
P can be either referenced in the
-coordinate system (
) or in the
-coordinate system (
). Then, the Jeffreys–Fisher–Rao center is defined as the midpoint with respect to the Levi-Civita connection
of
g:
The point
is the centroid with respect to the canonical flat divergence
, and the point
is the centroid with respect to the dual canonical flat divergence
. The canonical divergence is expressed using the mixed coordinates
/
but can also be expressed using the
-coordinates as an equivalent Bregman divergence
or as a reverse dual Bregman divergence
. This JFR center
approximates the symmetrized centroid with respect to the canonical symmetrized divergence
(i.e., Jeffreys divergence when written using the
-coordinate system). This symmetrized divergence
can be interpreted as the energy of the Riemannian length element
along the primal geodesic
and dual geodesic
(with
and
), see [
14]:
. The Riemannian distance
corresponds to the Riemannian length element along the Riemannian geodesic
induced by the Levi-Civita connection
:
.
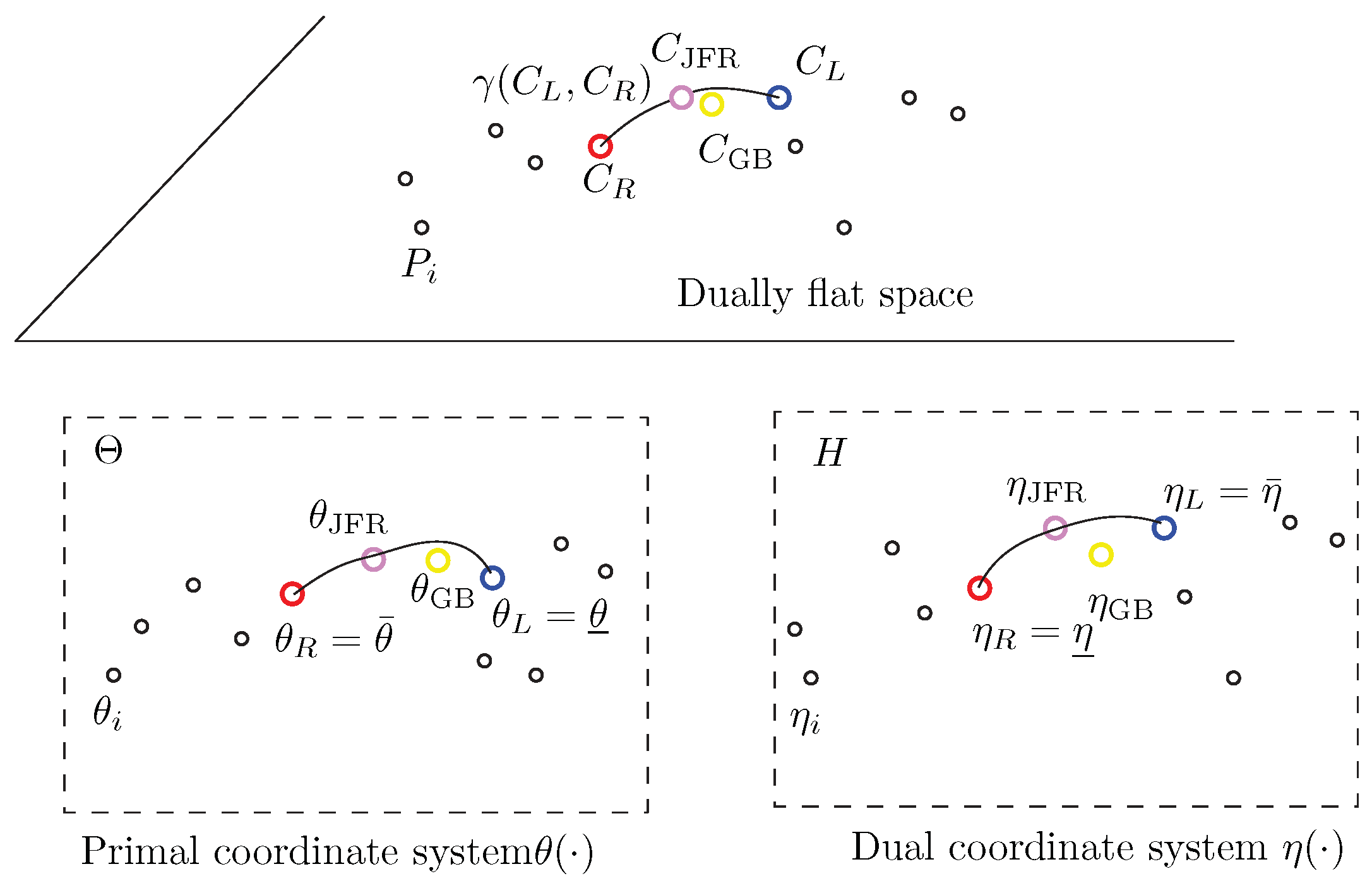
The inductive Gauss–Bregman center
is obtained as a limit sequence of taking iteratively the ∇ midpoints and
midpoints with respect to the ∇ and
connections. Those midpoints correspond to the right and left centroids
and
with respect to
:
initialized with
and
. We have
and
.
Figure 10 geometrically illustrates the double sequence of iteratively taking dual geodesic midpoints to converge toward the Gauss–Bregman center
. Thus, the GB double sequence can be interpreted as a geometric optimization technique.
Figure 11 illustrates the JFR and GB centers on a dually flat space. Notice that
has coordinates
in the
-chart and coordinates
in the
-chart. Similarly,
has coordinates
in the
-chart and coordinates
in the
-chart.
As a final remark, let us emphasize that choosing a proper mean or center depends on the application at hand [
55,
56]. For example, in Bayesian hypothesis testing, the Chernoff mean [
57] is used to upper bound Bayes’ error and has been widely used in information fusion [
18] for its empirical robustness [
58] in practice. Jeffreys centroid has been successfully used in information retrieval tasks [
6].









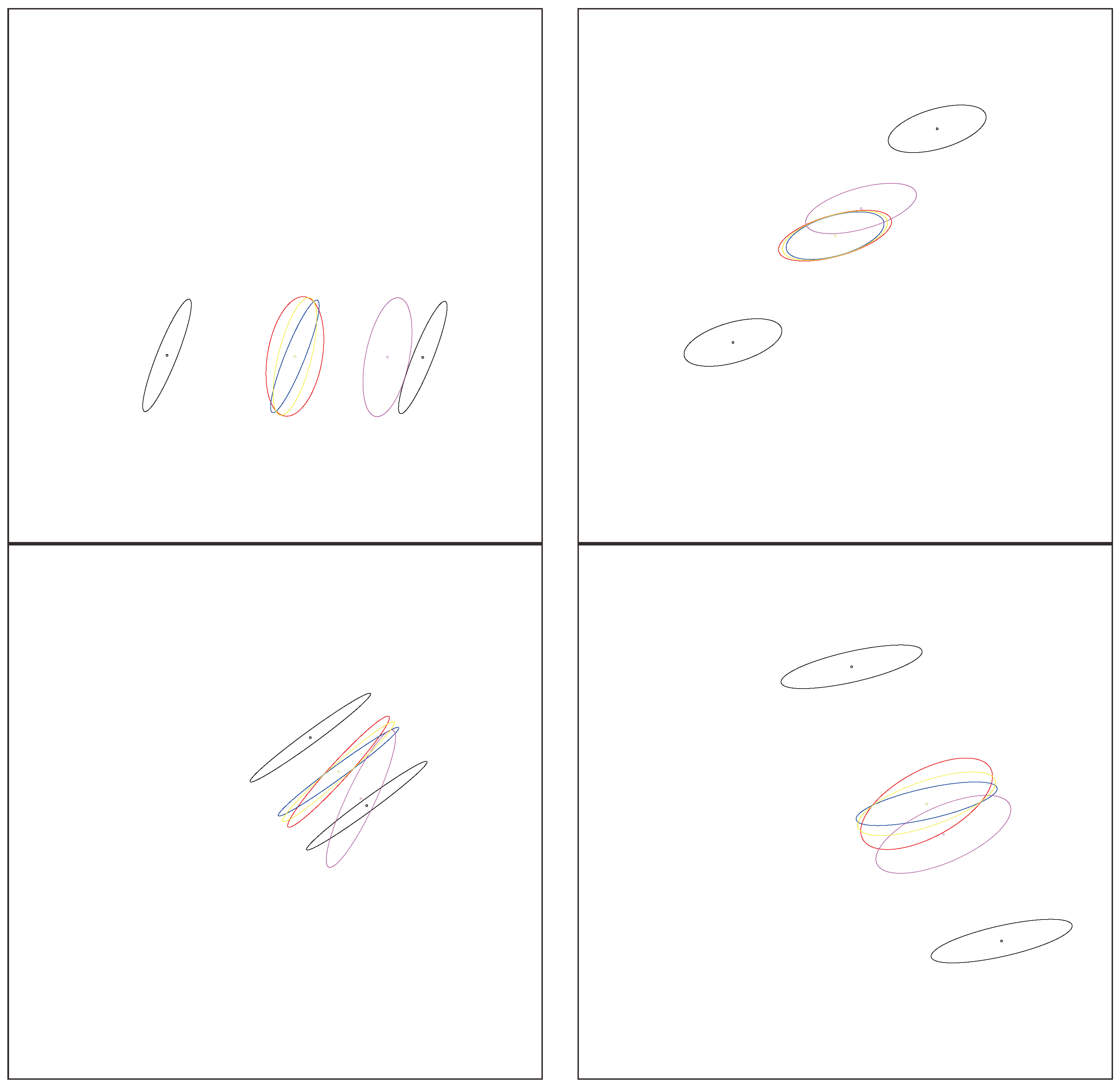

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}