1. Introduction
Example-based image color style transfer methods have emerged as powerful tools in computer graphics and image processing. Their significance lies in their ability to transfer the color characteristics from the example image to the source image. This allows for various key applications, such as artistic effects transformation [
1], photorealistic image stylization [
2], image illuminance adjustment [
3,
4], and underwater image enhancement [
5,
6].
Pioneering work in example-based image color style transfer was presented in [
7]. The authors achieved the decorrelation of color channels by transforming RGB images into the Lab color space, leveraging simple statistics, such as mean and standard deviation, to linearly map the color characteristics from one image to another. Building on this foundation, the method introduced in [
8] retained operations within the RGB space and utilized mean and covariance to account for the inherent correlations between the three color channels. Furthermore, the method detailed in [
9] accomplished one-to-one color mapping by transferring the color palette of the example image to the source image through an iterative algorithm that transforms one probability density function into another. In [
10], a linear color transformation derived from the Monge–Kantorovich theory was proposed. Following this, Ref. [
11] introduced a regularized discrete optimal transport formulation for color transformation, effectively addressing challenges such as mass conservation relaxation and regularization. The method in [
12] employed illuminant matching and optimal color palette mapping to achieve color transfer. Moreover, Ref. [
13] tackled the limitations of relaxed optimal transport in color transfer by implementing a non-convex regularized optimal transportation method that enforced one-to-one feature matching while minimizing transport dispersion. The authors of [
14] introduced a transformation between Multivariate Generalized Gaussian Distributions (MGGDs), consisting of optimal transportation of the second-order statistics and a stochastic-based shape parameter transformation.
While optimal transportation algorithms offer advantages in computational efficiency and ease of use, they have limitations. Notably, the application of a uniform processing method across all pixels hinders the ability to ensure the reasonableness of transformation results in all image regions. This may lead to artifacts, unnatural colorization, irrational luminosity relationships, biased color positioning, and color vignetting in the output image.
To overcome this limitation, an Expectation-Maximization (EM)-based segmentation method for regional color transfer was introduced in [
15]. In [
16], a soft color segmentation method was presented for color transfer, using a Gaussian Mixture Model (GMM) to capture broad color patterns with soft labels. The method proposed in [
17] utilized an improved EM algorithm and a GMM for the automatic selection of appropriate reference colors within target regions. Focusing on local style variations, the method introduced in [
18] leveraged Gaussian clustering to capture fine-grained light and color details within images. This method employed novel source-example cluster mapping policies and achieved style transfer through a combination of parametric color transfer and local chromatic adaptation, allowing for seamless image synthesis while preserving spatial and color coherence. A content-based color transfer method introduced in [
19] performed high-level scene analysis for semantic region correspondence and utilized a novel optimization framework to achieve color transfer while preserving spatial layout and visual coherence. For applications in cartoon and fabric color transfer, the method presented in [
20] improved color transfer vividness and enhanced detail preservation through image segmentation and the incorporation of a total generalized variation regularizer. A representative superpixel-based method for color transfer was presented in [
21], utilizing a fast method that employed approximate nearest neighbor matching with enforced diversity and a fusion framework. Lastly, an L2 divergence-based method for color transfer was described in [
22], offering flexibility by accommodating color correspondences and ensuring performance despite potential outlier pairs.
Building upon differential geometry concepts, Ref. [
23] introduced a method for per-frame color transform interpolation that minimized curvature. In contrast, the method presented in [
24] employed iterative probabilistic color mapping with self-learning filtering and multiscale detail manipulation, minimizing the Kullback–Leibler divergence to enhance color fidelity and detail preservation. To improve robustness, the method in [
25] leveraged scattered point interpolation with moving least squares and probabilistic modeling in 3D RGB space, enabling robust color transfer across varying conditions. For more compelling results, the method in [
26] considered scene illumination and target gamut constraints, utilizing white balancing, illuminant-aware tone mapping, and gamut-based color mapping techniques. Based on the color homography theorem, the method in [
27] decomposed color transfer into chromaticity shift and shading adjustment, represented by a global shading curve. Additionally, a 3D color homography model was introduced in [
28], approximating the transformation as a combination of a 3D perspective transform and mean intensity mapping. Addressing color transfer in a two-stage process, the method in [
29] first prioritized similarities between source image pixel colors and dominant colors during color mapping, followed by an L0 gradient-preserving detail preservation step to refine large gradients at color region boundaries while maintaining small gradients within regions. The method in [
30] tackled color transfer estimation with pixel-to-pixel correspondences using a robust feature-based method. This method utilized an optimal inlier maximization algorithm for outlier handling, combined with a novel structure tensor-based feature detector and descriptor, ensuring reliable color distribution matching across images.
Convolutional Neural Networks (CNNs) have proven remarkably adept at capturing the underlying features of images. This proficiency makes them particularly well suited for image style transfer tasks. Their advantage stems from their ability to learn complex image representations, often referred to as deep features. The most common method leverages these deep features to establish correspondences between the source and example images, subsequently implementing the style transfer [
31,
32,
33,
34,
35,
36].
Under this framework, a method for visual attribute transfer between images with different appearances was introduced in [
37], focusing on images with similar semantic structures. This method leveraged deep image analogy and extended PatchMatch to guide semantically meaningful transfers. Similarly, the method proposed in [
38] was designed for accurate and coherent color transfer in images with similar semantic structures, employing dense correspondences and local linear models. A local colorization method that allowed for customizable results by incorporating different example images was presented in [
39]. Beyond CNN-based methods, a self-supervised Generative Adversarial Network (GAN) for High Dynamic Range (HDR) image color transfer was introduced in [
40]. A style representation learning method for arbitrary image style transfer using contrastive learning was proposed in [
41]. Meanwhile, a multichannel correlation network (MCCNet) for arbitrary video and image style transfer, which ensures temporal consistency and addresses flickering effects, was proposed in [
42]. Detailed reviews of different color transfer techniques can be found in [
43,
44].
While deep learning methods generally achieve superior performance, they have certain limitations. Extensive training datasets and substantial computational resources are required to train these models. Additionally, their performance is hindered when the source image type is not present in the training data. Once trained, these networks may struggle to adapt to different source image sizes.
Existing methods for color transfer each have their own advantages. However, it is difficult to achieve good performance in all aspects, such as texture preservation, color brightness, and time efficiency. To overcome these challenges, this paper makes the following contributions:
- 1.
This paper proposes a method that balances holistic and local costs, named BHL. The BHL method captures the color information of example images more comprehensively at a holistic level while better preserving the texture details of the source images.
- 2.
A customized optimization method is introduced, based on the Riemannian information gradient and called the uRIG method, to address the high computational time associated with parameter estimation for the MGGD and GMM probability models. By leveraging the second-order acceleration effect of the Riemannian information metric (matrix), the uRIG method significantly enhances the time efficiency of the BHL algorithm.
- 3.
In the preprocessing stage, SLIC (Simple Linear Iterative Clustering) is used to sample mini-batches for subsequent iterations. This ensures that the colors of the image will not be too monotonous when refining local areas.
- 4.
Extensive numerical experiments demonstrate that the BHL method achieves a significant advantage in time complexity over existing color transfer techniques while matching or even surpassing the visual quality of existing methods.
3. Optimization Algorithm
3.1. Main Algorithm
To minimize the cost function in Equations (12) and (
14), a two-stage optimization process is introduced.
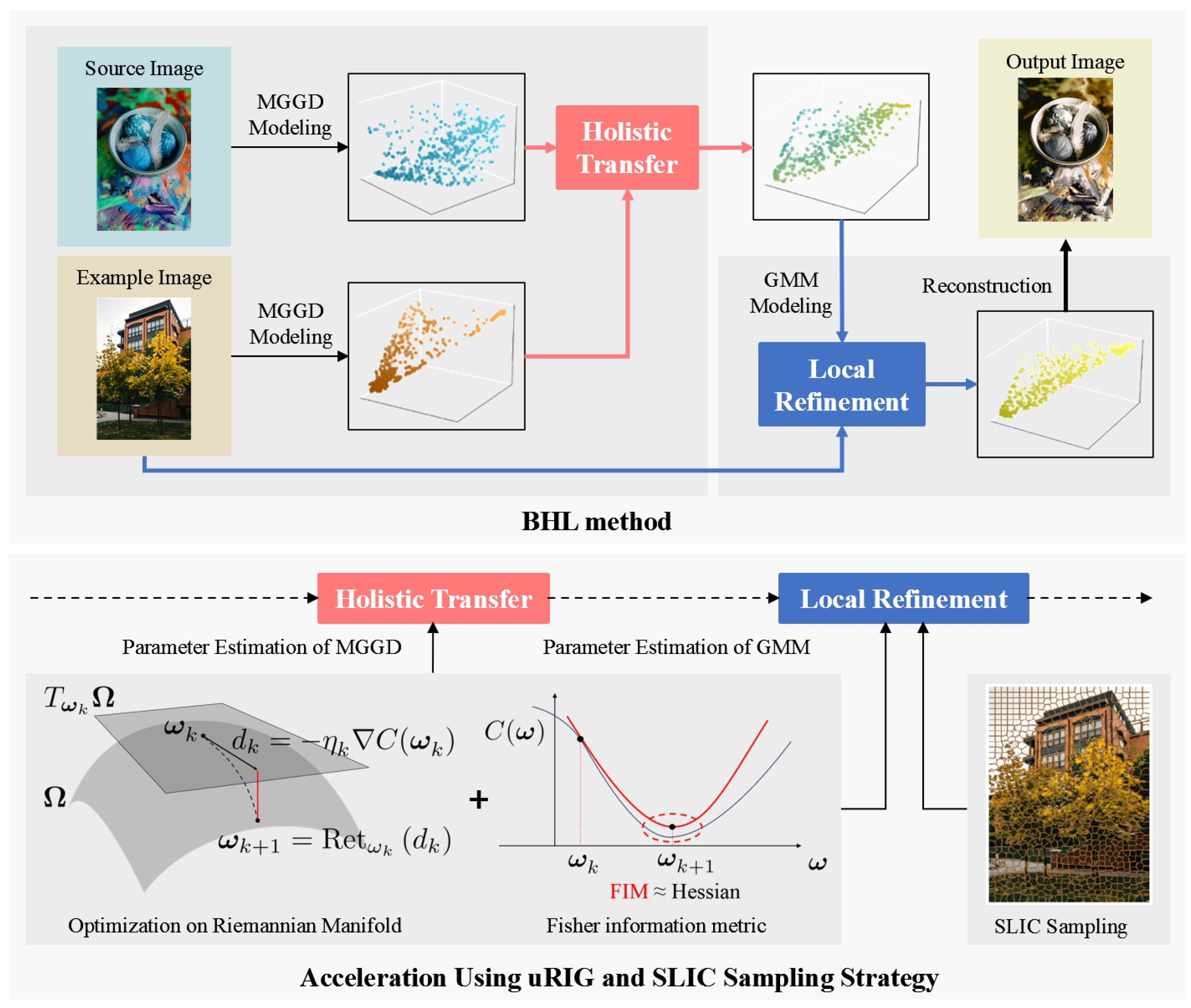
Figure 1 illustrates the overall workflow.
During the first stage, we employ Multivariate Generalized Gaussian Distributions (MGGDs) to independently model the source image and the example image . We then estimate the parameters for these respective models. Utilizing these estimated parameters, we construct the holistic transformation equation and subsequently apply it to achieve holistic color transfer.
The output of the first stage, denoted as
, serves as the input for the second stage. Here, a GMM with means denoted by
is leveraged. We posit that the example image
constitutes a sample set for this GMM. Through an iterative maximum likelihood estimation process initialized with
, the estimated
represents the refined result, which is also the final transformed image. The BHL method is summarized in the Algorithm 1 as below.
| Algorithm 1 The BHL method |
- Require:
Source image , example image ; - 1:
← MGGDESTIMATION(); - 2:
← MGGDESTIMATION(); - 3:
← TRANSMGGD(, , ); - 4:
← GMMESTIMATION(, ); - Ensure:
Edited image ; - 5:
procedure TransMGGD(, , ) - 6:
Holistic transformation via ( 11); - 7:
return ; - 8:
end procedure
|
This color transfer method necessitates solving three optimization problems: (
12a), (
12b), and (
14) (refer to Steps 1 and 2 in Algorithm 1). Traditionally, these problems are addressed using the fixed-point iteration method for (
12a) and (
12b), and the Expectation-Maximization (EM) algorithm for (
14). However, these methods become computationally expensive, particularly for high-resolution images, due to increased time and memory demands. To overcome this computational bottleneck, the unit-wise Riemannian information gradient (uRIG) method is introduced. The core idea of uRIG leverages two key mathematical concepts: the Riemannian manifold and the Fisher information metric [
47,
48]. Updates on the Riemannian manifold effectively bypass numerical instabilities often encountered with nonlinear constraints, such as positive definite matrices, leading to a more robust algorithm. Additionally, the use of the Fisher information metric (matrix) as a replacement for the Hessian matrix eliminates the need for computationally expensive numerical approximations, thereby accelerating the convergence of the estimation process [
49].
3.2. Minimization of the Holistic Cost
While the shape parameter of an MGGD is known, such as in the Gaussian (
) and Laplace (
) distributions, its closed-form Fisher information metric exists, as detailed in [
50,
51]. However, when the shape parameter is unknown, its FIM requires solving a system of partial differential equations, which currently lacks a closed-form solution [
52]. Inspired by [
53], this paper proposes utilizing a unit-wise Riemannian information metric to address both Problem (12) and the subsequent Problem (
14). In Problem (12), the MGGD parameters reside in a product space encompassing
for the location parameter
, the set
of
-dimensional symmetric positive definite (SPD) matrices for scatter matrix
, and
for the shape parameter
. The spaces
and
are special Riemannian manifolds with zero curvature. The space
is a matrix (Riemannian) manifold with negative curvature. The product of these three spaces is then a Riemannian manifold [
47]. We call a subspace in the product space
a unit since it has a closed-form FIM.
Definition 1. For the MGGD model, the following spaces are defined: (i) The space for the location parameter is called a unit; (ii) The space for the scatter matrix Σ is called a unit; (iii) The space for the shape parameter β is called a unit.
While the interesting manifold (parameter space) is well defined, the proposition below gives the unit-wise FIM.
Proposition 1. Denote as the parameter space of an MGGD and as the tangent space of . The unit-wise FIM of this MGGD iswithwhere is the matrix trace. The vectors and are elements in . To simplify the notations, we use the symbols , , , and to represent the coefficients in the three inner products above. The following remark gives the values of the three information coefficients.
Remark: The three inner products involved in Proposition 1 all have closed-form expressions for the constant coefficients, which can be directly used without any numerical approximation. The information constant with respect to
is
where
d is the dimension of the image color vector and
is the Gamma function. The information constants with respect to
are
The information constant with respect to
is
where
and
are the digamma and trigamma functions. The proof of Proposition 1 and its remark can be found in
Appendix A. After defining the uFIM on the parameter space
, we are able to derive the associated Riemannian gradient based on this metric, i.e., the unit-wise Riemannian information gradient.
Proposition 2. The uRIG of the holistic cost in Equation (12) is under the following form:where the components of the three parameters are as follows: The values of the coefficients
,
, and
are presented in (19). We recall that the symbol
denotes the Mahalanobis distance, defined as
. The symbol
denotes the digamma function. The proof of Proposition 2 can be found in
Appendix B.
Having established the relevant metric and gradient on the manifold, we now turn to the retraction map, which plays an important role in optimization algorithms. The retraction map serves as a bridge between the tangent space and the manifold itself, enabling us to efficiently perform gradient descent.
In Euclidean space, no special treatment is usually required for gradient descent. However, on a manifold, after moving in the direction of descent (i.e., typically the gradient) in the tangent space, a ‘retraction’ operation is needed to ensure that the parameters always remain within the constrained space. Therefore, the ideal retraction map is the geodesic map that performs the ‘retraction’ operation along geodesics. In particular, the geodesic map for Euclidean space is simply vector addition. Then, for the geodesic map on
, we employ the form introduced in [
54] in this work. Since each of the three units possesses its own intrinsic geodesic map, the most natural retraction map on
is the product of the three geodesic maps.
Proposition 3. The following map is a retraction on :where is the tangent space at the point , and the vector is an element of . In Proposition 3, exp denotes the natural exponential function on the real number field, while
refers to the matrix exponential map. The proof of Proposition 3 is presented in
Appendix C.
With the foundation of necessary components in place, we now turn our attention to the specific iterative method employed for the estimation of the MGGD.
In the Algorithm 2,
is given in (
22). Indeed, in practical applications, in pursuit of time efficiency, the iteration is carried out in the form of mini-batch stochastic gradient descent, i.e., the constant
L in (21) is the mini-batch size. Its convergence analysis and the selection of the coefficient
a are discussed in
Section 3.4, along with the optimization of
.
| Algorithm 2 MGGD estimation using the uRIG method |
- Require:
Dataset ; - Ensure:
estimate ; - 1:
for
do - 2:
- 3:
Define learning rate - 4:
Update - 5:
end for
|
3.3. Minimization of the Local Cost
We assumed in
Section 2.2 that all the component weights of the GMM are equal to 1/M, where M is the number of components. So, the EM algorithm is no longer the most suitable choice when the component weights are pre-set.
Instead, we adopt the uRIG method in the stochastic gradient descent framework. Specifically, for any component, the GMM, is a Gaussian distribution, which is a special case of the MGGD with the shape parameter . Therefore, we can directly apply the uRIG of the MGGD to the estimation of the GMM.
Due to the complex parameters of the GMM, we declare the following symbols for the sake of convenience in expression and understanding:
Parameter: , with ;
Parameter space: , with ;
Tangent space at point : , with .
Similar to the case of the MGGD, we start with the definition of a unit.
Definition 2. For any component of the GMM defined in Equation (13), we define the following spaces: In fact, each unit of the GMM parameter space is simply a Euclidean space; therefore, its uFIM is easier to derive. The uFIM is able to be obtained in the following form by taking the second differential of the log-likelihood with respect to each unit.
Proposition 4. The unit-wise Fisher information metric of the GMM isThe vectors and are elements in , and and are elements in . The proof can be found in
Appendix A. Then, the unit-wise information gradient can be easily derived based on the inner product in Equation (
23).
Proposition 5. The unit-wise information gradient of the GMM iswherewhere represents the posterior probabilities The proof of Proposition 5 is presented in
Appendix B. For the means
, the retraction map is vector addition in the Euclidean space
. For the coefficient
of the covariance, we follow the same treatment as for the shape parameter
in (
22). Using their product, the retraction shown below can be obtained.
Proposition 6. The following map is a retraction on the parameter space of the GMM: The Algorithm 3 below gives the update rule for parameter estimation of the GMM.
| Algorithm 3 GMM estimation using the uRIG method |
- Require:
Dataset ; - Ensure:
estimate ; - 1:
for
do - 2:
- 3:
Define learning rate - 4:
Update - 5:
end for
|
In the above algorithm,
and
are given in (
24) and (
26), respectively. For the GMM, the uRIG method also performs under the form of mini-batch stochastic gradient descent. The convergence analysis and selection of the coefficient
a of Algorithms 2 and 3 are discussed in the following subsection.
3.4. Convergence Analysis
To simplify the presentation and enhance the clarity of the convergence analysis of Algorithms 2 and 3, we unify the notations in this subsection. In the following part of this subsection, we use to represent the parameters and to denote the parameter space (regardless of whether it is MGGD or GMM). Consider a statistical model with M units, and let N be the number of observed samples.
Since the conditions (1–3) shown below hold, the high time efficiency and robustness of Algorithm 1 can be established, as shown in Proposition 7.
The conditions are as follows:
The cost has an isolated stationary point at , where is the true parameter;
There exists a compact and convex neighborhood of such that the sequence generated by Algorithm 1 remains within .
The learning rate
,
, verifies the usual condition for stochastic approximation:
Proposition 7. With these three conditions, we have The proof of Proposition 7 is shown in
Appendix D.
4. Experiment
In this section, the BHL method is evaluated from two perspectives: visual assessment and objective quantitative analysis. The BHL method is benchmarked against five state-of-the-art methods known for their high performance. In terms of holistic transformation methods, we chose the representative MGGD transformation method in [
14]. In the domain of local transformation methods, we chose two top-performing methods: the GMM-based transformation technique [
46] and the method derived from L2 divergence [
22]. Two state-of-the-art deep neural network-based methods, specifically the CAST method [
41] and MCCNet [
42], were also included in the comparative experiments for evaluation.
We randomly selected five groups of images for experimental comparison, i.e., 10 different images, with 5 as the source images and 5 as the example images. All experiments were conducted on a regular laptop with an AMD Ryzen 7 6800H processor and a main frequency of 3.2 GHz.
4.1. Parameter Setting
For the uRIG algorithm, the initialization
of Algorithm 2 was determined using the method of moments [
55], while the initialization of Algorithm 3 was obtained from the output of holistic transformation
, i.e.,
. The coefficient
a of the learning rate was estimated according to Proposition 2 in [
56].
To facilitate gradient descent, a preprocessing step was introduced in [
46] to select the mini-batch. Prior to commencing the iterations, for each pixel in
,
b nearest neighbors are chosen from
. Notably,
b corresponds to the size of the mini-batch, and these selected
b pixels from
then comprise the mini-batch employed for gradient descent. While this method effectively captures color information, it results in a significant computational burden in the preprocessing stage due to the need to sort
pixels.
To address this limitation, we proposed a distinct mini-batch sampling strategy that leverages the Simple Linear Iterative Clustering (SLIC) algorithm. Initially, we applied the SLIC algorithm for superpixel segmentation on the example image , partitioning it into 1000 superpixels. For each pixel in , we computed the distance to the mean of each superpixel in . Based on these distances, the nearest superpixels were selected to replace the first b pixels during the iteration (typically, ). This method offers two main advantages. First, it significantly reduces the sorting time, particularly for high-resolution images. Second, by utilizing all pixels within the superpixels, the hyperparameter becomes less sensitive to the final output. Specifically, extreme values of mainly affect the algorithm’s runtime rather than the color richness of the output. Therefore, it is possible to choose a relatively smaller to reduce time costs. In the experiments, we set and .
This method substantially reduced the preprocessing time complexity, as detailed in
Section 4.4. In addition, to incorporate spatial information, the Laplacian regularization term introduced in [
46,
57] was also applied to Equation (
14).
4.2. Quantitative Comparison
In existing research [
12,
18,
25,
46,
58], the Structural Similarity Index Measure (SSIM) and Peak Signal-to-Noise Ratio (PSNR) are commonly employed to assess the textural similarity between the output image
and the source image
. Specifically, the SSIM quantifies the level of artifacts introduced by the color transfer method, while the PSNR measures the mean squared error between the two images. The color style similarity between the output image and the example image is typically evaluated using the Frechet Inception Distance (FID) and Perceptual Hash Value (PHV) [
59,
60].
The five methods involved in the comparative experiment have their own advantages due to their different processing techniques and optimization goals. However, no method performed well across all four quantitative evaluation criteria at the same time. For example, MCCNet achieved superior structural fidelity visually because it enhanced the edges of objects in the image (such as the edges of petals). However, excessive enhancement led to large artifacts. The L2 method provided bright-colored visual results, but because it requires local matching of the color palette, its output sometimes contained local color deviations. The results of the MGGD method and the BHL method show that their PSNR values were not relatively high. This is because the processing of these two methods requires a resampling operation combined with the parameters of the example image. Noise that differs from the source image will result in a low PSNR value [
58].
To evaluate the performance of these methods, we introduced a comprehensive evaluation technique: the Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) [
61]. TOPSIS is a multi-criteria decision analysis technique that assesses the performance of candidate methods by calculating their distances to the ideal and negative-ideal solutions, thereby providing a comprehensive assessment.
Quantitative comparisons between the BHL method and five other methods are presented in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5. When calculating the TOPSIS score, we performed the necessary order adjustments and normalization steps. The final TOPSIS scores range from 0 to 1, with higher values indicating better overall performance. As shown in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5, the BHL method, which balances holistic and local information, achieved the highest TOPSIS scores. Due to its modeling and optimization techniques, the GMM algorithm achieved the best results in terms of the SSIM and PSNR. However, the performance of this algorithm varied with different hyperparameter settings, resulting in differing color effects. Consequently, the GMM method did not perform very well in the FID and PHV criteria. In contrast, the two deep learning methods, CAST and MCCNet, benefited from the robust color feature-capture capabilities of deep neural networks, achieving higher FID and PHV scores. However, these methods fell short in obtaining high textural similarity scores. The L2 divergence-based method showed severe distortions and artifacts in some images, leading to a low PHV score and, consequently, a lower comprehensive evaluation score. The MGGD method, which is based on optimal transport, performed well across all criteria. However, its lack of attention to detail resulted in numerous local artifacts, adversely affecting its evaluation score. Detailed visual comparisons are provided in the next subsection.
4.3. Visual Comparison
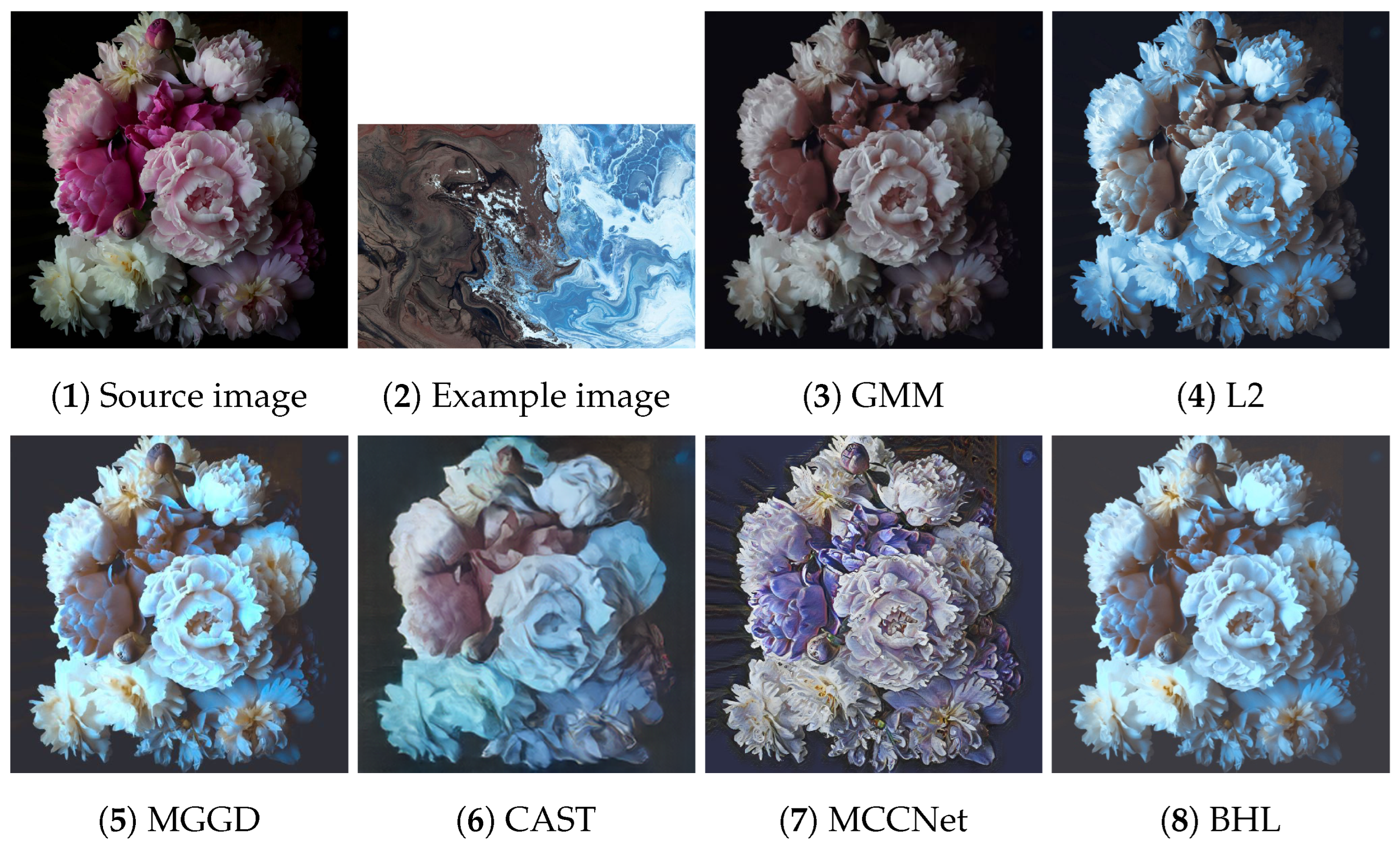
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 present the visual results of the five experiments. Due to its modeling approach, the GMM method excelled at preserving the texture of the source images. This advantage was also reflected in the quantitative evaluation. However, its output was highly sensitive to hyperparameter selection, such as the number of iterations (set to 50 for all five experiments, consistent with [
46]). As shown in
Figure 4(3) and
Figure 6(3), the colors of the example images were not accurately transferred, and the results retained the color style of the source images. Furthermore, in
Figure 5(3) and
Figure 7(2), significant white artifacts can be observed in the GMM results.
Compared to other methods, the L2 method produced a brighter color style in its results. For example, in
Figure 3(4), the L2 result has a significantly brighter color style, but it also deviates from the color style of the example image. This is because the L2 method relies on local matching of the color palettes, and the accuracy of color transfer depends on the precision of this local matching. In
Figure 7(3), green shadows are visible on the yellow petals in the L2 result. A similar issue occurs in
Figure 7(10), where the petals exhibit a cyan tint.
The MGGD method shares some visual similarities with the BHL method, which also employs a similar modeling technique in its first stage. The key distinction between the MGGD and BHL methods lies in the local refinement in the subsequent steps of the BHL method. Specifically, as shown in
Figure 7(4), the MGGD method produces unnatural purple hues on the water droplets, and the black area to the right of the droplets appears opaque and blurry due to the lack of local color adjustments.
Leveraging the powerful ability of convolutional neural networks to extract structural features from images, CAST and MCCNet demonstrated excellent structural fidelity. However, due to the inherent limitations of deep neural networks, such as rigidity in input and output sizes and challenges with generalization, some flaws were present in their results. For instance, in
Figure 3(6,7), sharp black blocks appear in the background, which should have been blurred. Similarly, in
Figure 7(5,6), the edges of the water droplets in the results of both methods appear as rigid straight lines rather than as curves.
The BHL method achieves a good balance between holistic color style and local structural details. By utilizing a more efficient training method (uRIG) and an innovative sampling strategy, it delivers a more robust color transfer effect. The advantages in terms of time efficiency are demonstrated in the subsequent section.
4.4. Time Efficiency
We also assessed the runtime efficiency of the six methods, with the results presented in
Table 6. For deep learning methods, the runtime is generally divided into two phases: training and inference. In contrast, probabilistic methods estimate parameters dynamically for each individual dataset or image rather than relying on a pre-trained model. Consequently, their runtime cannot be compared to that of deep learning methods in the same manner, and the results are, therefore, presented differently.
For the four probabilistic methods, the first two rows of
Table 6 display the average runtimes across five experiments. This analysis accounts for all processing steps involved in the four comparative methods, including data preprocessing, parameter estimation, and color transformation. The total number of pixels across the five image sets (i.e., the sample size for a single experiment) ranged from
to
. The results indicate that due to the BHL method’s use of the uRIG method and a novel sampling strategy based on SLIC, its average runtime across the five experiments was only 4.874 s, demonstrating a significant advantage over the other three probabilistic methods.
In contrast, for the two deep learning methods, CAST and MCCNet, the training times were 18 h and 59 h, respectively, with inference times of 0.011 s and 0.013 s. Compared to the probabilistic methods, CAST and MCCNet exhibited a substantial advantage in inference speed. However, the extended training times and the limited scope of the training datasets clearly constrained their ability to address all scenarios. For instance, in
Figure 3(6), large black smudges obscure the petal contours, and in
Figure 7(5,6), the water droplet contours are transformed into rigid lines. These issues did not arise with any of the four probabilistic methods.
To further validate the time efficiency benefits of the uRIG method, we conducted a simulation comparison experiment with other commonly used stochastic gradient-based optimization methods. The comparison included classic Stochastic Gradient Descent (SGD), Adam [
62], and Affine-Invariant Gradient Descent (AIG) [
63], which is equivalent to the classic Riemannian gradient descent method. The simulation involved 150 Monte Carlo simulations. Each experiment’s data followed a randomly generated MGGD, with the initial values provided by the method of moments. The averaged results are presented in
Figure 8. The horizontal axis represents the number of iterations, while the vertical axis depicts the error calculated using the empirical Kullback–Leibler divergence.
As evident from
Figure 8, the uRIG method demonstrates a clear advantage for the parameter estimation task in statistical models. This advantage becomes increasingly pronounced as the number of iterations grows, highlighting the accelerating effect of the Fisher information metric.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}