
A Gibbs Posterior Framework for Fair Clustering

Abstract
1. Introduction
1.1. Generalized Bayesian Inference through Gibbs Posterior
1.2. Fairness in Clustering
2. Methodology
2.1. Preliminaries
2.2. Generalized Bayesian Fair Clustering
3. Posterior Analysis
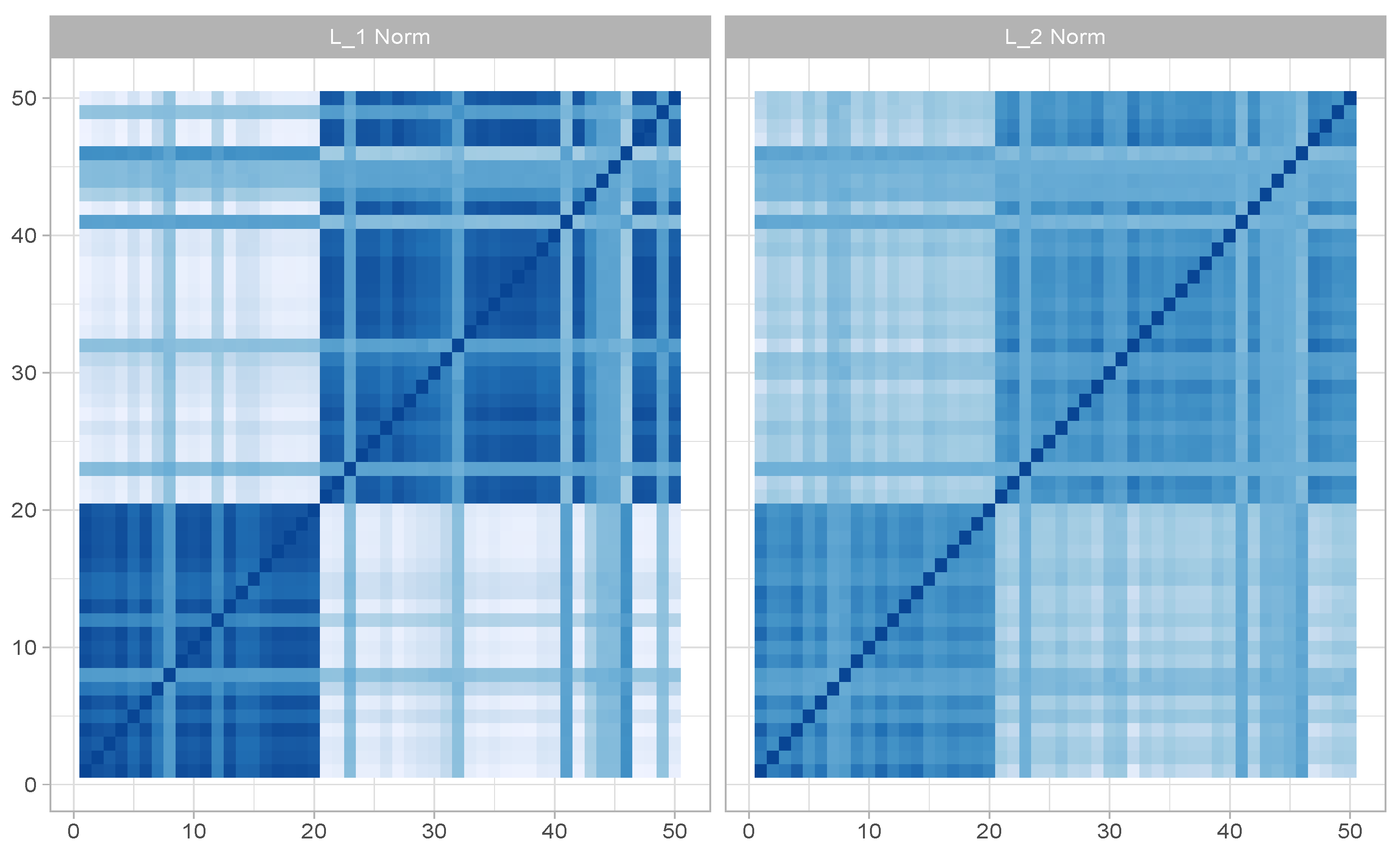
3.1. Sampling Scheme
| Algorithm 1: Weighted rectangular loop algorithm [15] |
 |
3.2. Posterior Summaries
3.3. Hyperparameter Tuning
4. Experiments
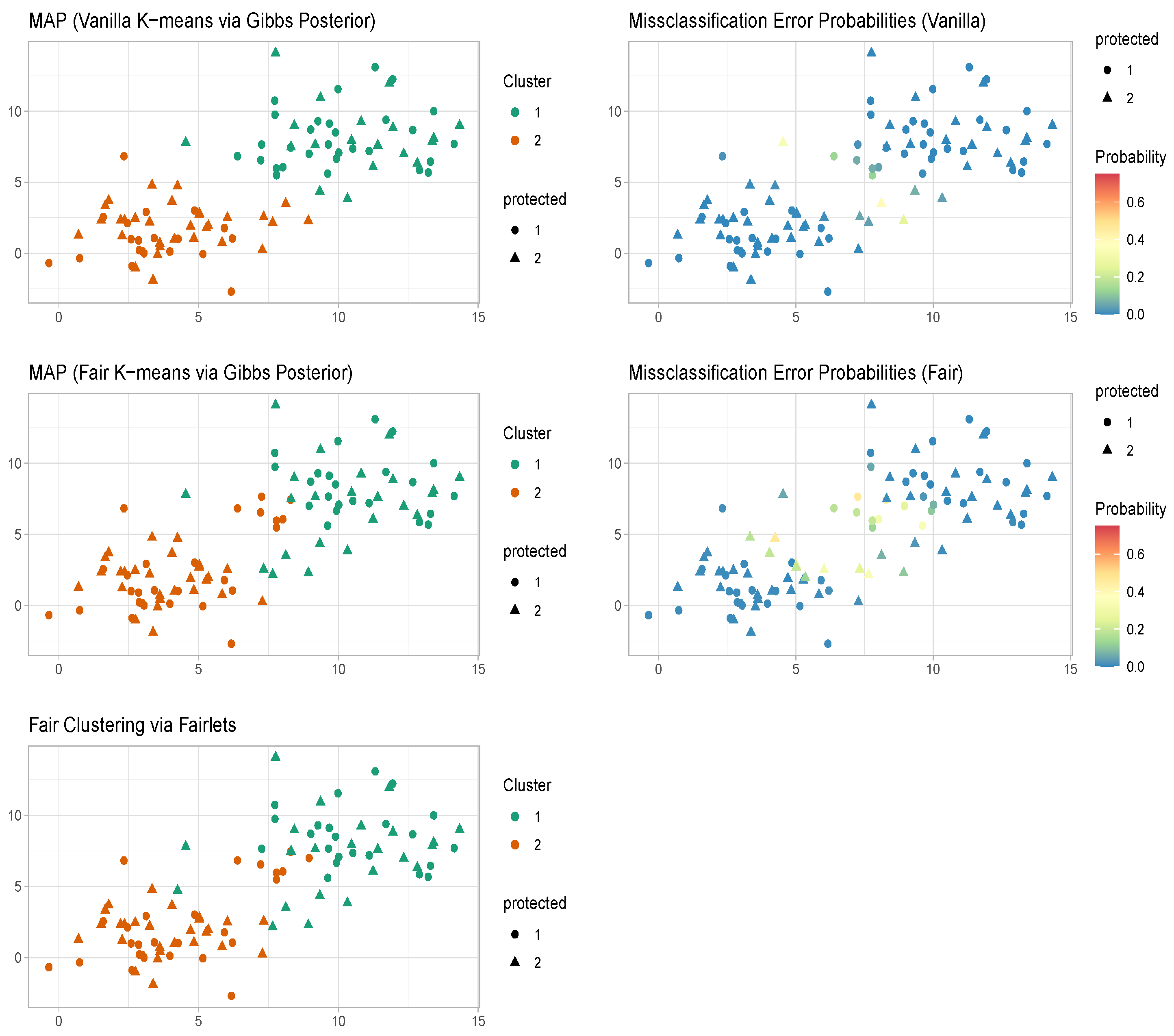
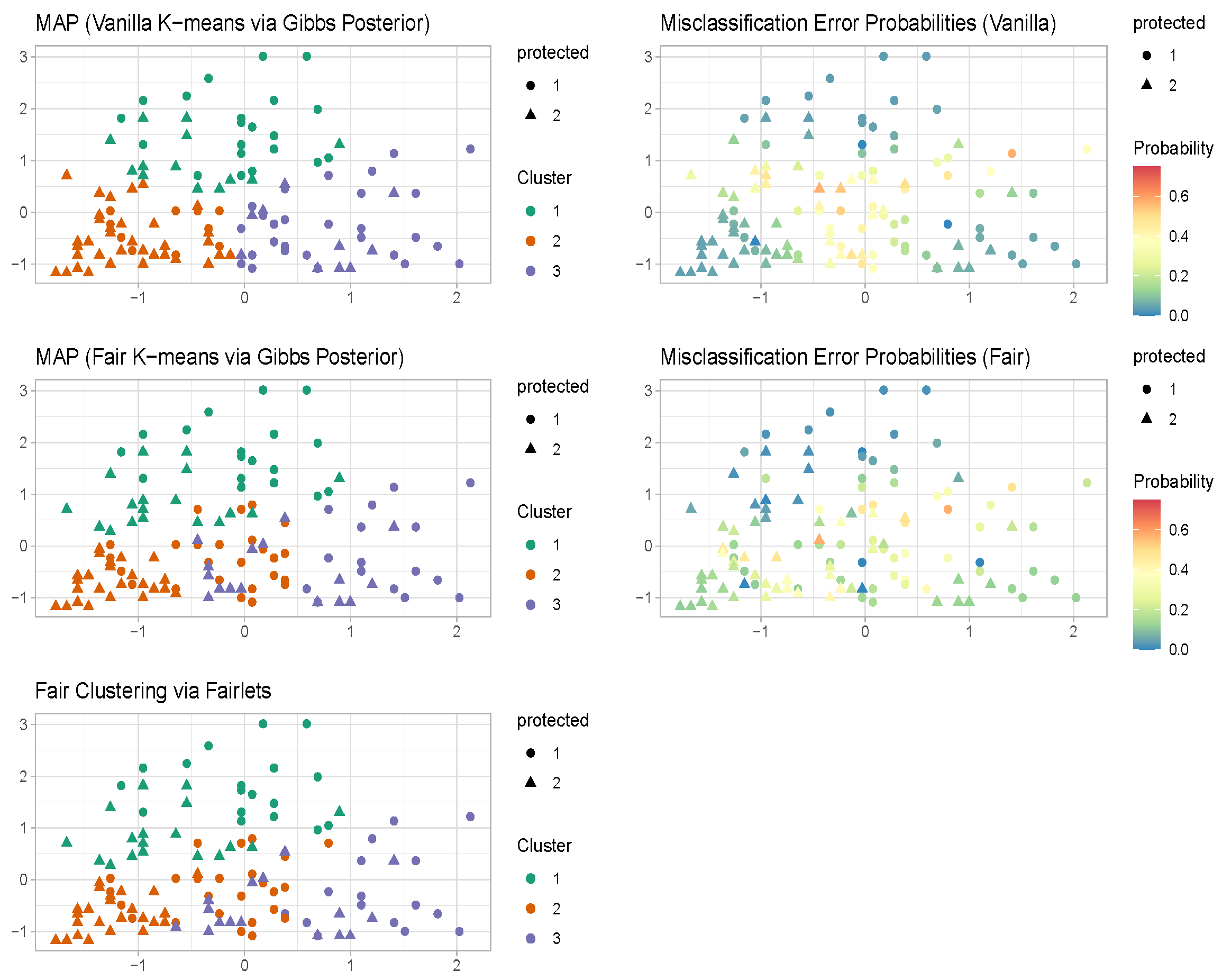
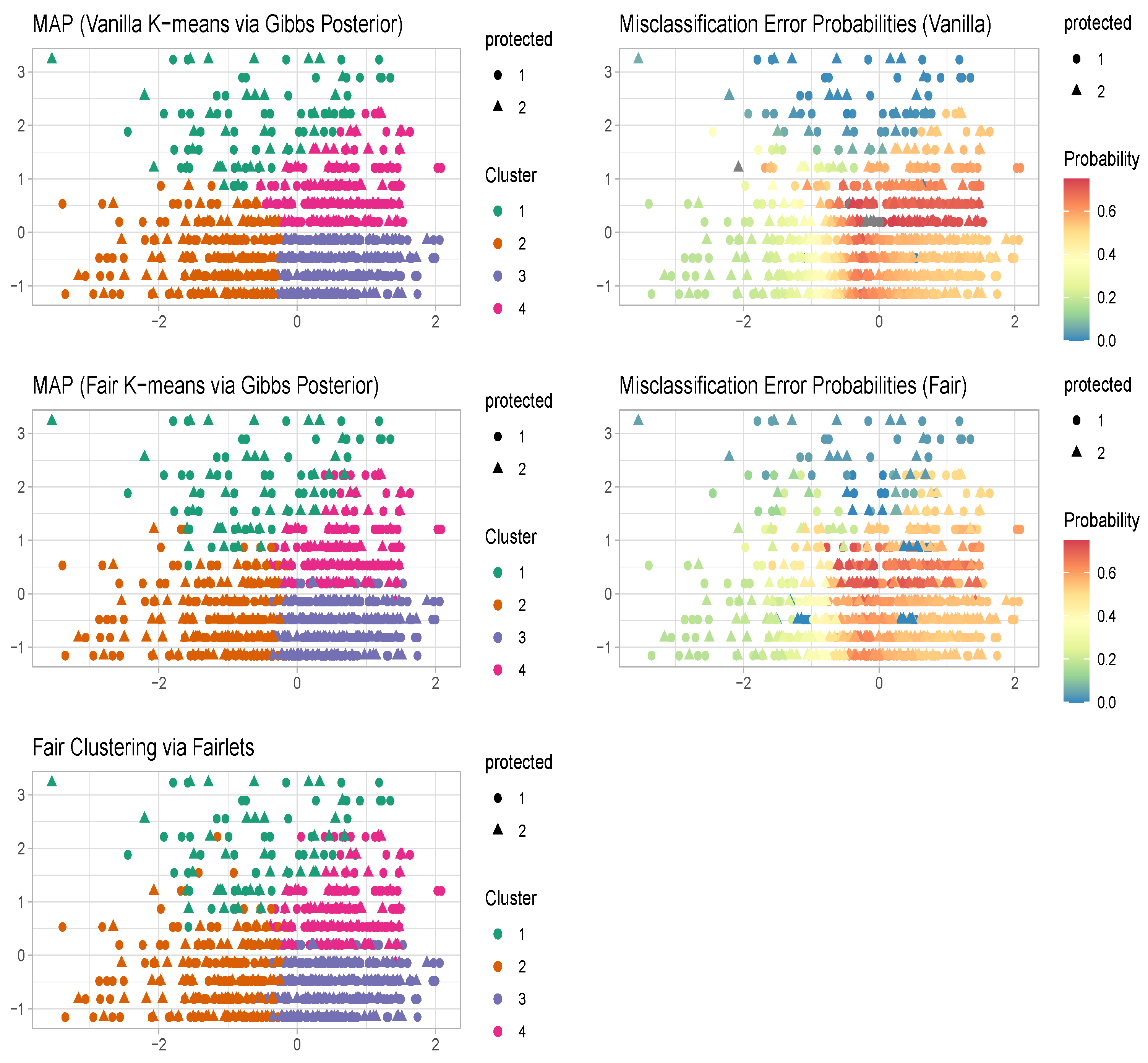
4.1. Well-Specified Case
4.2. Misspecified Case
5. Benchmark Data Sets
5.1. Credit Card Data
5.2. Diabetes Data
5.3. Portuguese Banking Data
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chierichetti, F.; Kumar, R.; Lattanzi, S.; Vassilvitskii, S. Fair Clustering Through Fairlets. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Böhm, M.; Fazzone, A.; Leonardi, S.; Schwiegelshohn, C. Fair Clustering with Multiple Colors. arXiv 2020, arXiv:2002.07892. [Google Scholar] [CrossRef]
- Esmaeili, S.; Brubach, B.; Tsepenekas, L.; Dickerson, J. Probabilistic Fair Clustering. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 12743–12755. [Google Scholar]
- Bera, S.; Chakrabarty, D.; Flores, N.; Negahbani, M. Fair Algorithms for Clustering. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Kleindessner, M.; Samadi, S.; Awasthi, P.; Morgenstern, J. Guarantees for Spectral Clustering with Fairness Constraints. arXiv 2019, arXiv:1901.08668. [Google Scholar] [CrossRef]
- Ahmadian, S.; Epasto, A.; Kumar, R.; Mahdian, M. Fair Correlation Clustering. arXiv 2020, arXiv:2002.02274. [Google Scholar]
- Ahmadian, S.; Epasto, A.; Knittel, M.; Kumar, R.; Mahdian, M.; Moseley, B.; Pham, P.; Vassilvitskii, S.; Wang, Y. Fair Hierarchical Clustering. arXiv 2020, arXiv:2006.10221. [Google Scholar]
- Kleindessner, M.; Awasthi, P.; Morgenstern, J. A Notion of Individual Fairness for Clustering. arXiv 2020, arXiv:2006.04960. [Google Scholar] [CrossRef]
- Mahabadi, S.; Vakilian, A. Individual Fairness for k-Clustering. arXiv 2020, arXiv:2002.06742. [Google Scholar] [CrossRef]
- Chakrabarty, D.; Negahbani, M. Better Algorithms for Individually Fair k-Clustering. arXiv 2021, arXiv:2106.12150. [Google Scholar]
- Chen, X.; Fain, B.; Lyu, C.; Munagala, K. Proportionally Fair Clustering. arXiv 2019, arXiv:1905.03674. [Google Scholar]
- Rösner, C.; Schmidt, M. Privacy preserving clustering with constraints. arXiv 2019, arXiv:1802.02497. [Google Scholar]
- Bandyapadhyay, S.; Inamdar, T.; Pai, S.; Varadarajan, K.R. A Constant Approximation for Colorful k-Center. arXiv 2019, arXiv:1907.08906. [Google Scholar]
- Kleindessner, M.; Awasthi, P.; Morgenstern, J. Fair k-Center Clustering for Data Summarization. arXiv 2019, arXiv:1901.08628. [Google Scholar] [CrossRef]
- Chakraborty, A.; Bhattacharya, A.; Pati, D. Fair Clustering via Hierarchical Fair-Dirichlet Process. arXiv 2023, arXiv:2305.17557. [Google Scholar]
- Jiang, W.; Tanner, M.A. Gibbs Posterior for Variable Selection in High-Dimensional Classification and Data Mining. Ann. Stat. 2008, 36, 2207–2231. [Google Scholar] [CrossRef]
- Martin, R.; Syring, N. Direct Gibbs Posterior Inference on Risk Minimizers: Construction, Concentration, and Calibration. arXiv 2023, arXiv:2203.09381. [Google Scholar]
- Berger, J.O. An Overview of Robust Bayesian Analysis. Test 1994, 3, 5–124. [Google Scholar] [CrossRef]
- Miller, J.W.; Dunson, D.B. Robust Bayesian Inference via Coarsening. J. Am. Stat. Assoc. 2019, 114, 1113–1125. [Google Scholar] [CrossRef]
- Chakraborty, A.; Bhattacharya, A.; Pati, D. Robust probabilistic inference via a constrained transport metric. arXiv 2023, arXiv:2303.10085. [Google Scholar]
- Robert, C.P.; Rousseau, J. Nonparametric Bayesian Clay for Robust Decision Bricks. Stat. Sci. 2016, 31, 506–510. [Google Scholar] [CrossRef]
- Ghosal, S.; van der Vaart, A. Fundamentals of Nonparametric Bayesian Inference; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2017; Volume 44. [Google Scholar]
- Chernozhukov, V.; Hong, H. An MCMC Approach to Classical Estimation. SSRN 2002. [Google Scholar] [CrossRef]
- Hong, L.; Martin, R. Model Misspecification, Bayesian versus Credibility Estimation, and Gibbs Posteriors. Scand. Actuar. J. 2020, 2020, 634–649. [Google Scholar] [CrossRef]
- Syring, N.; Martin, R. Robust and Rate-Optimal Gibbs Posterior Inference on the Boundary of a Noisy Image. Ann. Stat. 2020, 48, 1498–1513. [Google Scholar] [CrossRef]
- Wang, Z.; Martin, R. Gibbs posterior inference on a Levy density under discrete sampling. arXiv 2021, arXiv:2109.06567. [Google Scholar]
- Bhattacharya, I.; Martin, R. Gibbs posterior inference on multivariate quantiles. J. Stat. Plan. Inference 2022, 218, 106–121. [Google Scholar] [CrossRef]
- Syring, N.; Hong, L.; Martin, R. Gibbs Posterior Inference on Value-at-Risk. Scand. Actuar. J. 2019, 2019, 548–557. [Google Scholar] [CrossRef]
- Rigon, T.; Herring, A.H.; Dunson, D.B. A Generalized Bayes Framework for Probabilistic Clustering. Biometrika 2023, 110, 559–578. [Google Scholar] [CrossRef]
- Bissiri, P.G.; Holmes, C.C.; Walker, S.G. A general framework for updating belief distributions. J. R. Stat. Soc. Ser. B Methodol. 2016, 78, 1103–1130. [Google Scholar] [CrossRef] [PubMed]
- Syring, N.; Martin, R. Gibbs Posterior Concentration Rates under Sub-Exponential Type Losses. Bernoulli 2023, 29, 1080–1108. [Google Scholar] [CrossRef]
- Holmes, C.C.; Walker, S.G. Assigning a value to a power likelihood in a general Bayesian model. Biometrika 2017, 104, 497–503. [Google Scholar]
- Ahuja, R.K.; Magnanti, T.L.; Orlin, J.B. Network Flows: Theory, Algorithms, and Applications; Prentice Hall: Hoboken, NJ, USA, 1993. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Lloyd, S.P. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Richardson, S.; Green, P.J. On Bayesian analysis of mixtures with an unknown number of components. J. R. Stat. Soc. Ser. B Stat. Methodol. 1997, 59, 731–792. [Google Scholar] [CrossRef]
- Stephens, M. Dealing with label switching in mixture models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2000, 62, 795–809. [Google Scholar] [CrossRef]
- Celeux, G.; Govaert, G. A classification EM algorithm for clustering and two stochastic versions. Comput. Stat. Data Anal. 1992, 14, 315–332. [Google Scholar] [CrossRef]
- Banfield, J.D.; Raftery, A.E. Model-based Gaussian and non-Gaussian clustering. Biometrics 1993, 49, 803–821. [Google Scholar] [CrossRef]
- Ghahramani, Z.; Hinton, G.E. The EM Algorithm for Mixtures of Factor Analyzers; University of Toronto: Toronto, ON, Canada, 1996. [Google Scholar]
- Maugis, C. Model-based clustering of high-dimensional data: A review. Comput. Stat. Data Anal. 2014, 71, 52–78. [Google Scholar]
- Backurs, A.; Indyk, P.; Onak, K.; Schieber, B.; Vakilian, A.; Wagner, T. Scalable Fair Clustering. arXiv 2019, arXiv:1902.03519. [Google Scholar]
- Ziko, I.M.; Granger, E.; Yuan, J.; Ayed, I.B. Variational Fair Clustering. arXiv 2020, arXiv:1906.08207. [Google Scholar] [CrossRef]
- Robert, C.P.; Casella, G. Monte Carlo Statistical Methods; Springer Texts in Statistics; Springer: New York, NY, USA, 2004. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Rhodes, B.; Gutmann, M. Enhanced gradient-based MCMC in discrete spaces. arXiv 2022, arXiv:2208.00040. [Google Scholar]
- Zanella, G. Informed proposals for local MCMC in discrete spaces. arXiv 2017, arXiv:1711.07424. [Google Scholar] [CrossRef]
- Dahl, D. Model-Based Clustering for Expression Data via a Dirichlet Process Mixture Model, in Bayesian Inference for Gene Expression and Proteomics; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; UCI: Irvine, CA, USA, 2017. [Google Scholar]
- Chakraborty, A.; Chakraborty, A. Scalable Model-Based Gaussian Process Clustering. arXiv 2023, arXiv:2309.07882. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Fairness | Uncertainty Quantification |
|---|---|---|
| K-means | ✗ | ✗ |
| K-means via Gibbs posterior | ✗ | ✓ |
| Fair clustering via fairlets | ✓ | ✗ |
| Fair clustering via Gibbs posterior | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chakraborty, A.; Bhattacharya, A.; Pati, D. A Gibbs Posterior Framework for Fair Clustering. Entropy 2024, 26, 63. https://doi.org/10.3390/e26010063
Chakraborty A, Bhattacharya A, Pati D. A Gibbs Posterior Framework for Fair Clustering. Entropy. 2024; 26(1):63. https://doi.org/10.3390/e26010063
Chicago/Turabian StyleChakraborty, Abhisek, Anirban Bhattacharya, and Debdeep Pati. 2024. "A Gibbs Posterior Framework for Fair Clustering" Entropy 26, no. 1: 63. https://doi.org/10.3390/e26010063
APA StyleChakraborty, A., Bhattacharya, A., & Pati, D. (2024). A Gibbs Posterior Framework for Fair Clustering. Entropy, 26(1), 63. https://doi.org/10.3390/e26010063