

Community-Based Matrix Factorization (CBMF) Approach for Enhancing Quality of Recommendations

Abstract
:1. Introduction
1.1. Applications
- 1.
- Natural Language Processing (NLP): Within the field of NLP, techniques for matrix factorization have been used in a variety of tasks in topic modeling, text classification, etc. [13,14]. Through the decomposition of the document matrix, MF algorithms can reveal latent representations that effectively capture the underlying semantic structure of the textual data.
- 2.
- Social Network Analysis: MF techniques have been utilized in social network analysis to unveil communities of individuals sharing common interests or behaviors [15,16]. SVD++ facilitates the identification of friends, influencers, or interest-based communities by enhancing user experience and engagement on social media platforms. FANMF is used to uncover community structures and identify influential nodes within the network. FANMF can effectively detect the group of nodes by exposing hidden relationships and structures by factorizing them into nonnegative adjacency matrices.
- 3.
- E-commerce: In the realm of e-commerce platforms, SVD++ is extensively utilized to deliver personalized product recommendations to users [17,18]. By including implicit feedback, supplementary data, and user-item ratings, SVD++ can adeptly capture user preferences and item characteristics for accurate product recommendations [19].
- 4.
- Streaming Services: Streaming platforms, including music or video services or SVD++, provide personalized content recommendations to the users. SVD++ significantly enhances the discovery and recommendation of relevant and captivating content. It ensures that the users are presented with content aligned with their individual tastes and preferences [20].
- 5.
- Image Processing: FANMF finds application in image processing tasks, where the image data are factored into nonnegative matrices. By extraction, it improves image quality and facilitates the analysis of visual data. By decomposition, matrix factorization algorithms are capable of distinguishing noise from the underlying structure. It also completes missing parts and extracts significant features for analysis and representation [21].
- 6.
- Nutritional Recommendation: In the realm of nutritional recommendations, matrix factorization entails structuring dietary information into a user-item matrix. This matrix uncovers hidden factors linked to individual tastes and nutritional traits, facilitating the delivery of personalized dietary advice. By accounting for variables such as taste preferences, dietary constraints, and health objectives, this approach aids individuals in devising well-balanced diets, promoting healthier and custom-tailored eating habits [22].
1.2. Problem Statement
2. Literature Review
3. Methodology
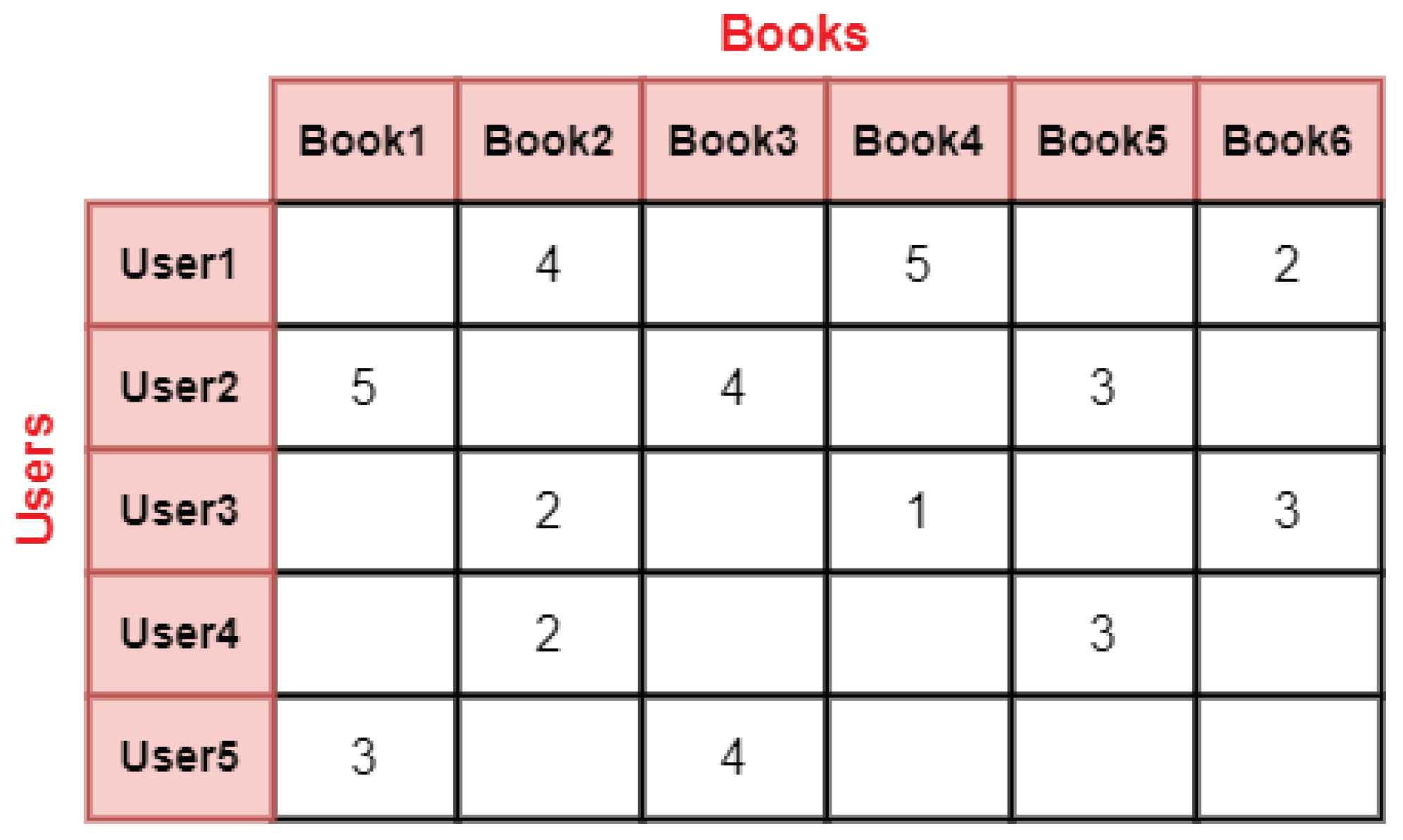
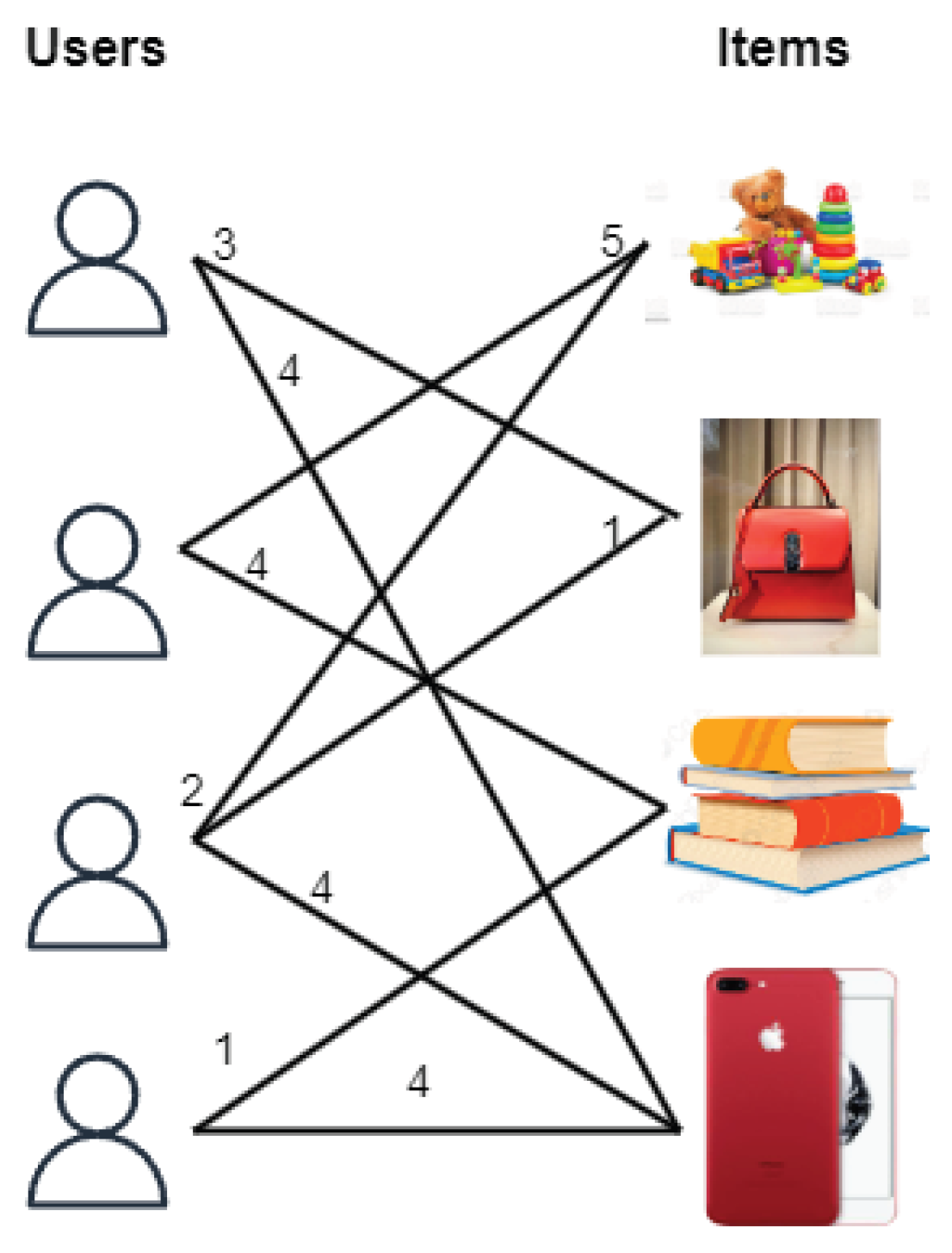
3.1. Matrix Factorization
3.1.1. Basic Matrix Factorization
- Step 1: Initialize the entries of user latent feature matrix M and item latent feature matrix N of sizes and , respectively, with random values. k is the number of latent features, tuned experimentally with different values of k.
- Step 2: Multiply the matrices M and N to obtain the predicted rating matrix with non-empty cells having some predicted ratings, as shown below in Equation (1).
- Step 3: Compute the deviation between actual and predicted ratings as shown in Equation (3), where is of order and is of order .
- Step 4: Minimize the error in the prediction. It is common to use Equation (4) to compute the squared error.In order to avoid overfitting the squared error, the regularization term is added as shown in Equation (5).The impact of the regularization is controlled by a constant . is the frobenius norm. The approximation of this value is calculated using stochastic gradient descent or alternating least squares. For each rating in the training data, the prediction error is calculated using the stochastic gradient descent method as displayed in Equation (6).
- Step 5: The following update rules shown in Equation (7) are used to update the matrices M and N to minimize squared error.The representation of a matrix for the above Equation (7) are as follows:For the equationthe matrix representation isFor the equationthe matrix representation is
- The steps 3, 4, and 5 are repeated until either the number of iterations is fixed or the error reaches 0.
3.1.2. SVD++
3.1.3. Factorized Asymmetric nonnegative Matrix Factorization (FANMF)
3.2. Community Detection
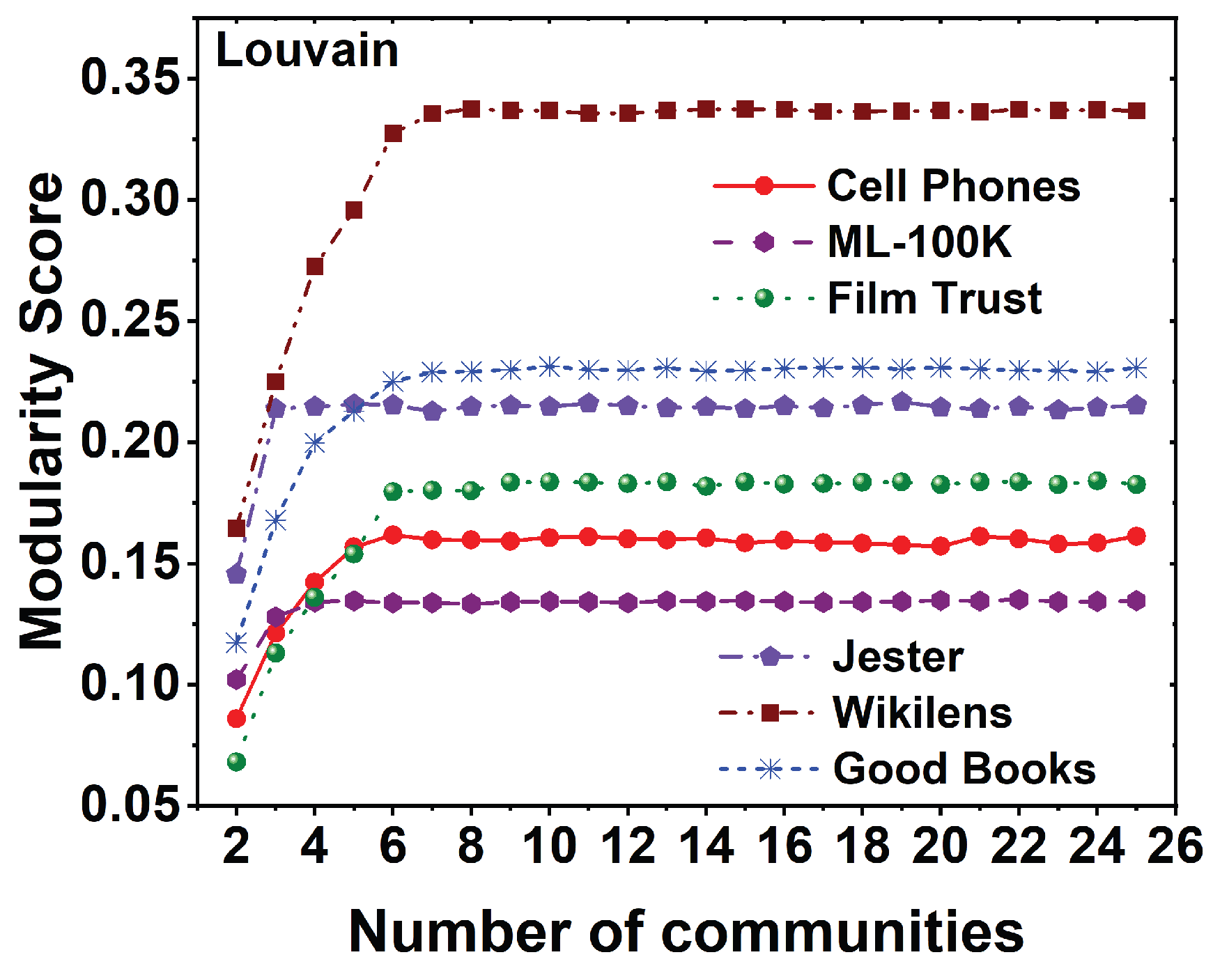
Louvain Algorithm
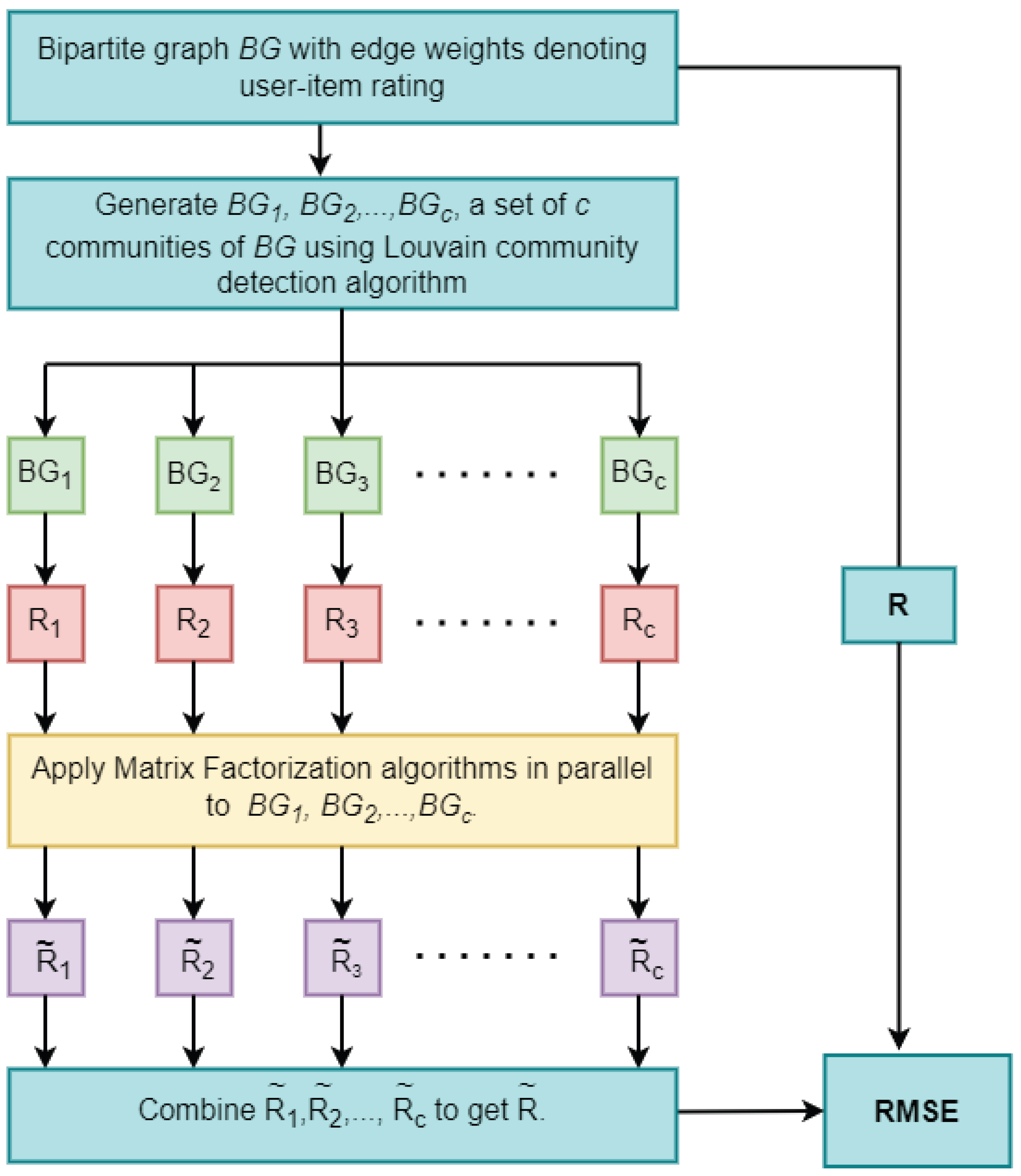
4. Proposed Method
4.1. Motivation
4.2. Community-Based Matrix Factorization (CBMF) Approach
| Algorithm 1: Community-Based Matrix Factorization (CBMF) |
 |
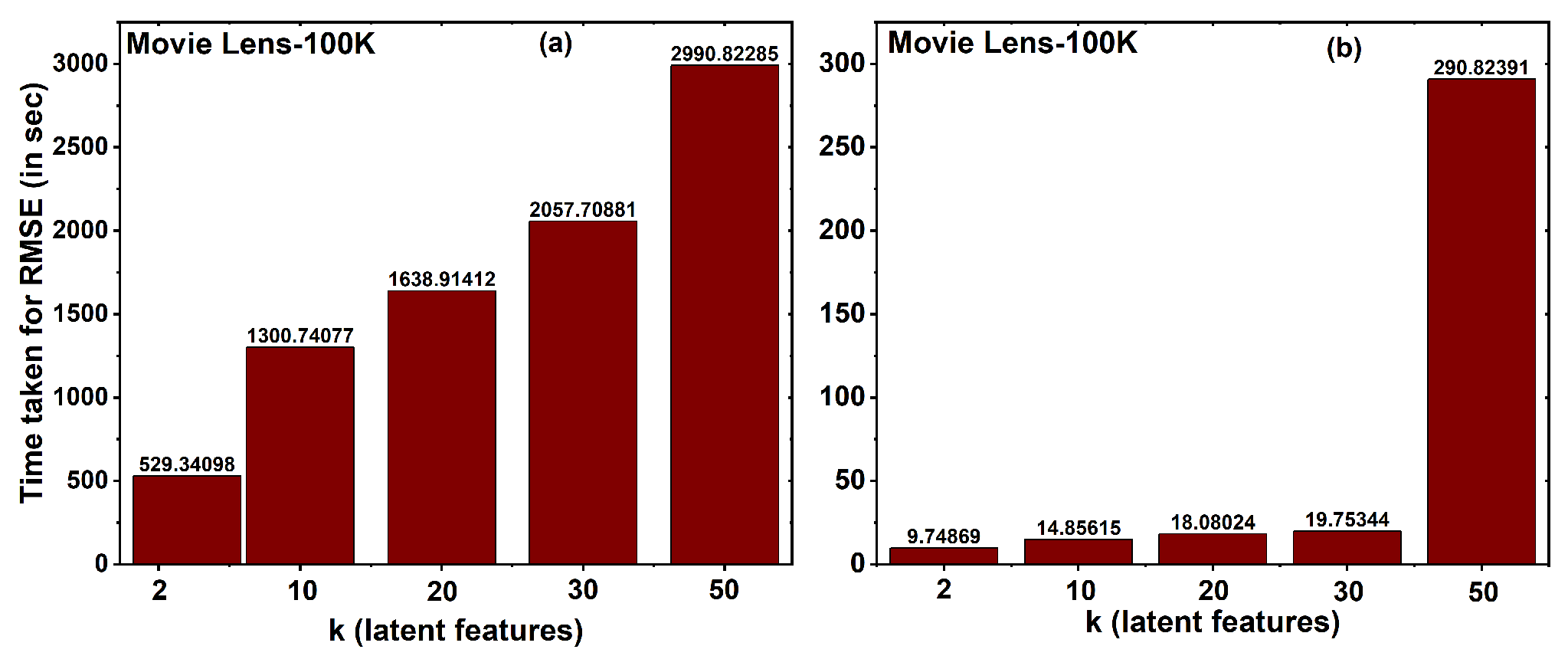
4.3. Time Complexity
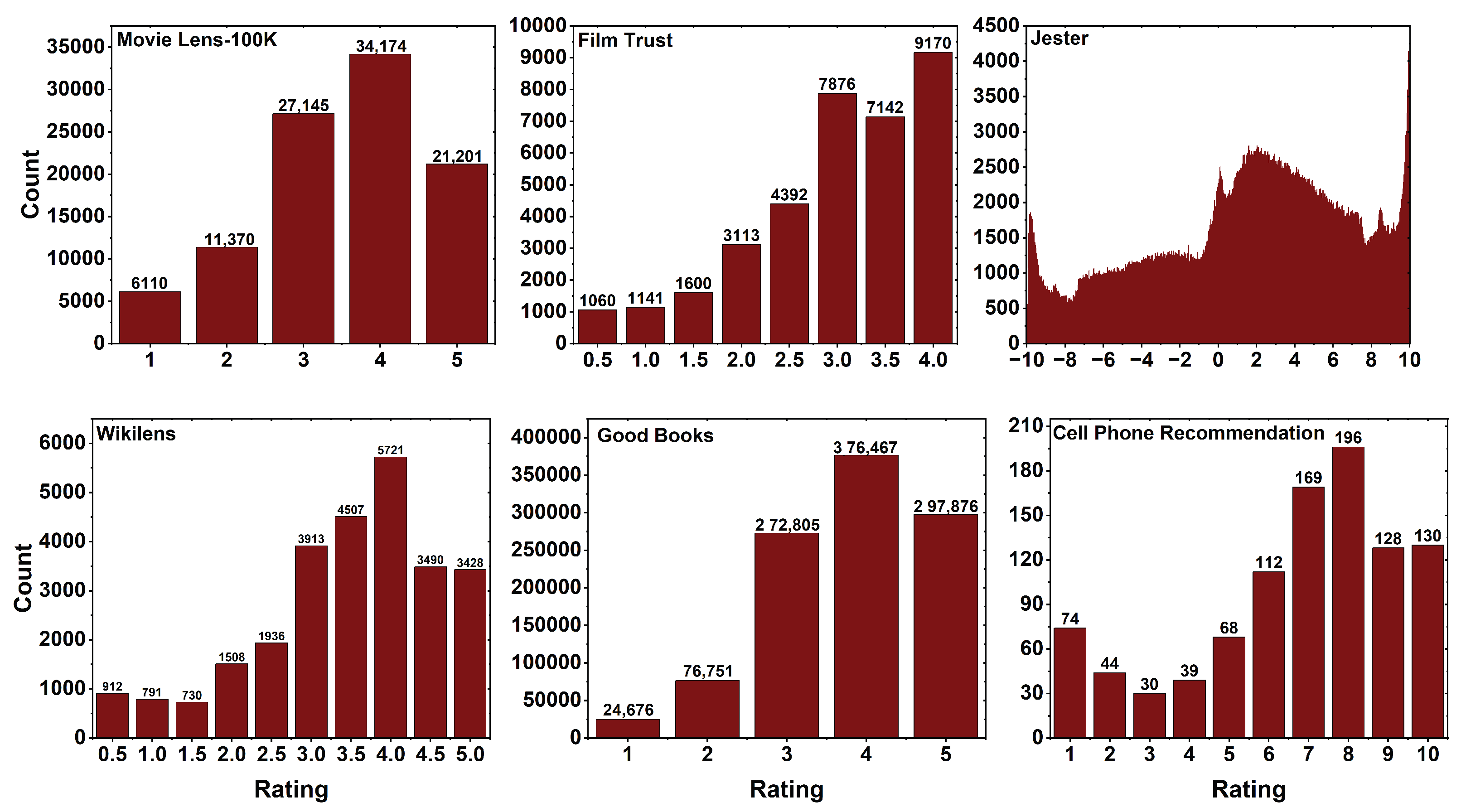
5. Dataset Statistics
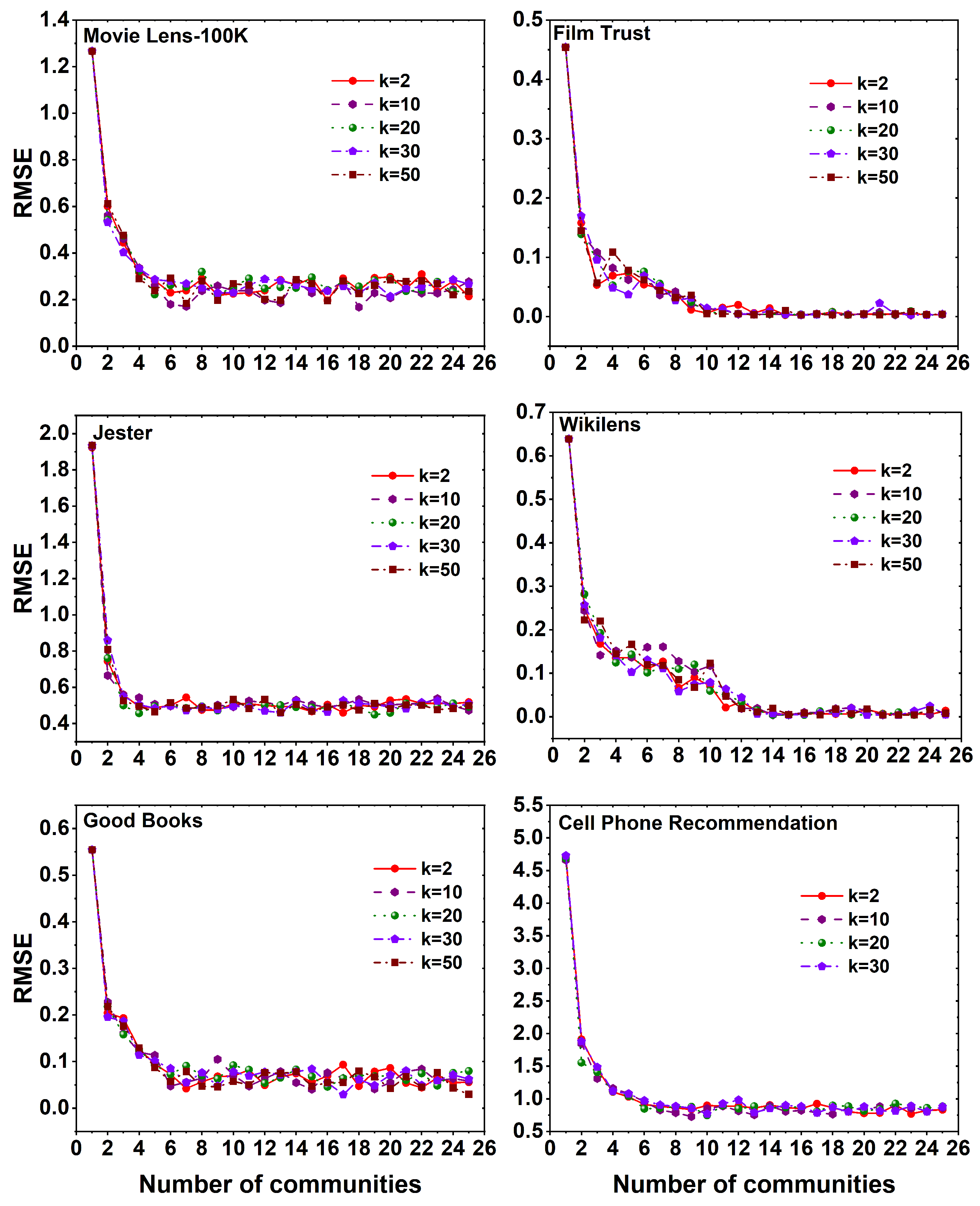
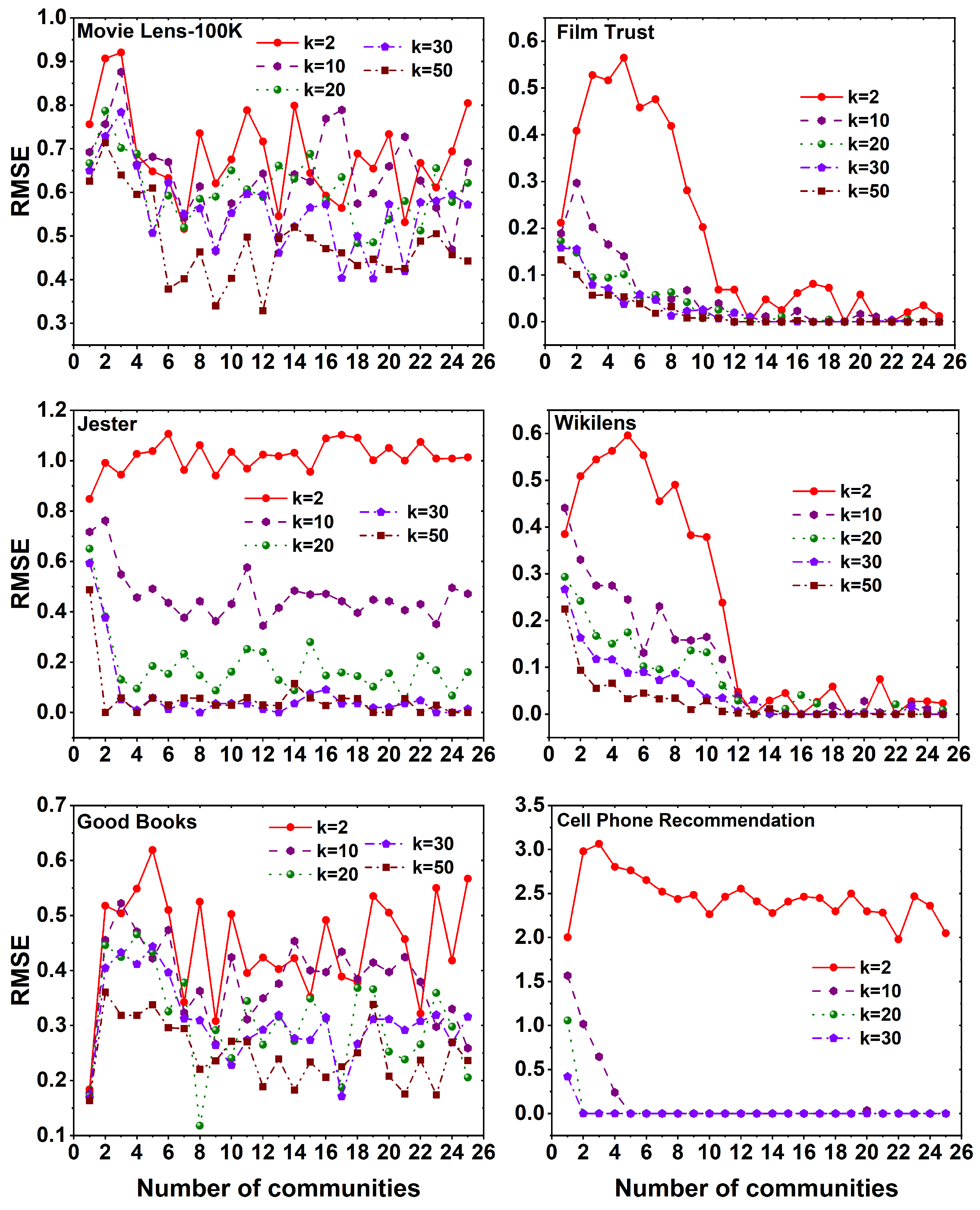
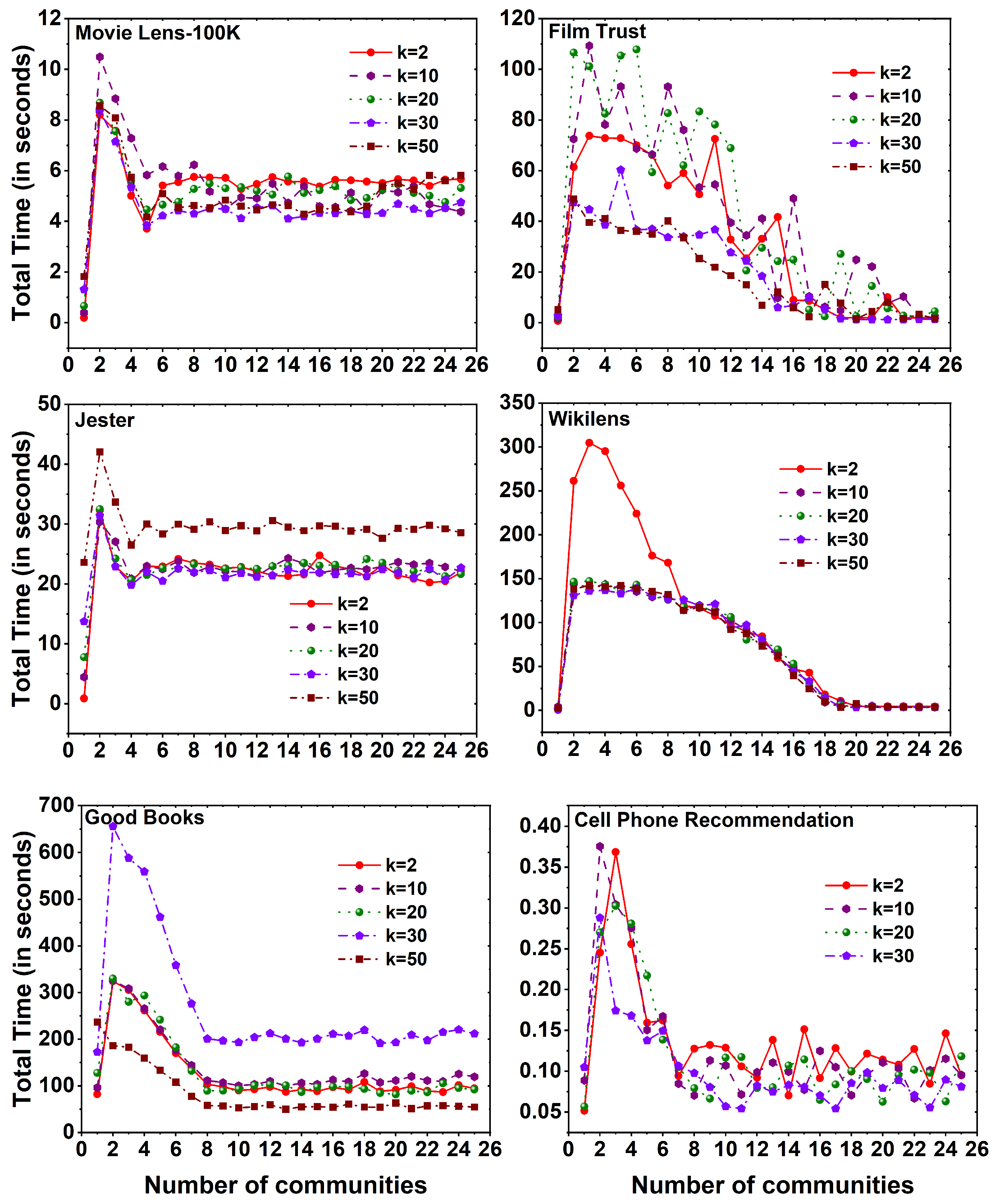
6. Result Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BG | Bipartite Graph |
| DMF | Deep Matrix Factorization |
| FANMF | Factorized Asymmetric Nonnegative Matrix Factorization |
| MF | Matrix Factorization |
| NLP | Natural Language Processing |
| NMF | nonnegative Matrix Factorization |
| PCSNMF | Pairwisely Constrained Nonnegative Symmetric Matrix Factorization |
| RMSE | Root Mean Square Error |
| SVD++ | Advanced Singular Value Decomposition |
References
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Felfernig, A.; Jeran, M.; Ninaus, G.; Reinfrank, F.; Reiterer, S.; Stettinger, M. Basic approaches in recommendation systems. In Recommendation Systems in Software Engineering; Springer: Berlin/Heidelberg, Germany, 2014; pp. 15–37. [Google Scholar]
- Hintz, J. Matrix Factorization for Collaborative Filtering Recommender Systems. 2015. Available online: https://www.cs.utexas.edu/~ans/pubs/hintz_f15.pdf (accessed on 31 July 2023).
- Kumar Bokde, D.; Girase, S.; Mukhopadhyay, D. Role of matrix factorization model in collaborative filtering algorithm: A survey. arXiv 2015, arXiv:1503.07475. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Mehta, R.; Rana, K. A review on matrix factorization techniques in recommender systems. In Proceedings of the 2017 2nd International Conference on Communication Systems, Computing and IT Applications (CSCITA), Mumbai, India, 7–8 April 2017; pp. 269–274. [Google Scholar]
- Abdrabbah, S.B.; Ayachi, R.; Amor, N.B. Collaborative filtering based on dynamic community detection. In Proceedings of the 2nd Workshop on Dynamic Networks and Knowledge Discovery, Nancy, France, 15 September 2014. [Google Scholar]
- Kumar, P.; Chawla, P.; Rana, A. A review on community detection algorithms in social networks. In Proceedings of the 2018 4th International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Mangalore, India, 6–8 September 2018; pp. 304–309. [Google Scholar]
- Bedi, P.; Sharma, C. Community detection in social networks. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2016, 6, 115–135. [Google Scholar] [CrossRef]
- Du, N.; Wu, B.; Pei, X.; Wang, B.; Xu, L. Community detection in large-scale social networks. In Proceedings of the 9th WebKDD and 1st SNA-KDD 2007 Workshop on Web Mining and Social Network Analysis, San Jose, CA, USA, 12 August 2007; pp. 16–25. [Google Scholar]
- Karataş, A.; Şahin, S. Application areas of community detection: A review. In Proceedings of the 2018 International Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT), Ankara, Turkiye, 3–4 December 2018; pp. 65–70. [Google Scholar]
- Lalwani, D.; Somayajulu, D.V.; Krishna, P.R. A community driven social recommendation system. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 821–826. [Google Scholar]
- Guo, W.; Gao, H.; Shi, J.; Long, B.; Zhang, L.; Chen, B.C.; Agarwal, D. Deep natural language processing for search and recommender systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 3199–3200. [Google Scholar]
- Musto, C.; De Gemmis, M.; Lops, P.; Semeraro, G. Generating post hoc review-based natural language justifications for recommender systems. User Model. -User-Adapt. Interact. 2021, 31, 629–673. [Google Scholar] [CrossRef]
- Chen, S.; Owusu, S.; Zhou, L. Social network based recommendation systems: A short survey. In Proceedings of the 2013 International Conference on Social Computing, Alexandria, VA, USA, 8–14 September 2013; pp. 882–885. [Google Scholar]
- Sun, Z.; Han, L.; Huang, W.; Wang, X.; Zeng, X.; Wang, M.; Yan, H. Recommender systems based on social networks. J. Syst. Softw. 2015, 99, 109–119. [Google Scholar] [CrossRef]
- Kim, J.K.; Cho, Y.H.; Kim, W.J.; Kim, J.R.; Suh, J.H. A personalized recommendation procedure for Internet shopping support. Electron. Commer. Res. Appl. 2002, 1, 301–313. [Google Scholar] [CrossRef]
- Wei, K.; Huang, J.; Fu, S. A survey of e-commerce recommender systems. In Proceedings of the 2007 International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007; pp. 1–5. [Google Scholar]
- Kim, K.j.; Ahn, H. A recommender system using GA K-means clustering in an online shopping market. Expert Syst. Appl. 2008, 34, 1200–1209. [Google Scholar] [CrossRef]
- Hasan, M.R.; Jha, A.K.; Liu, Y. Excessive use of online video streaming services: Impact of recommender system use, psychological factors, and motives. Comput. Hum. Behav. 2018, 80, 220–228. [Google Scholar] [CrossRef]
- Park, D.H.; Kim, H.K.; Choi, I.Y.; Kim, J.K. A literature review and classification of recommender systems research. Expert Syst. Appl. 2012, 39, 10059–10072. [Google Scholar] [CrossRef]
- Fewtrell, M.; Bronsky, J.; Campoy, C.; Domellöf, M.; Embleton, N.; Mis, N.F.; Hojsak, I.; Hulst, J.M.; Indrio, F.; Lapillonne, A.; et al. Complementary feeding: A position paper by the European Society for Paediatric Gastroenterology, Hepatology, and Nutrition (ESPGHAN) Committee on Nutrition. J. Pediatr. Gastroenterol. Nutr. 2017, 64, 119–132. [Google Scholar] [CrossRef] [PubMed]
- Isinkaye, F.O. Matrix factorization in recommender systems: Algorithms, applications, and peculiar challenges. IETE J. Res. 2021, 1–14. [Google Scholar] [CrossRef]
- Schafer, J.B.; Konstan, J.A.; Riedl, J. E-commerce recommendation applications. Data Min. Knowl. Discov. 2001, 5, 115–153. [Google Scholar] [CrossRef]
- Hallinan, B.; Striphas, T. Recommended for you: The Netflix Prize and the production of algorithmic culture. New Media Soc. 2016, 18, 117–137. [Google Scholar] [CrossRef]
- Paatero, P.; Tapper, U. Positive matrix factorization: A nonnegative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. Advances in Neural Information Processing Systems. 2007, Volume 20. Available online: https://proceedings.neurips.cc/paper_files/paper/2007/file/d7322ed717dedf1eb4e6e52a37ea7bcd-Paper.pdf (accessed on 31 July 2023).
- Mastorakis, N.E. The singular value decomposition (svd) in tensors (multidimensional arrays) as an optimization problem. solution via genetic algorithms and method of nelder-mead. WSEAS Trans. Syst. 2007, 6, 17–23. [Google Scholar]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Shi, X.; Lu, H.; He, Y.; He, S. Community detection in social network with pairwisely constrained symmetric nonnegative matrix factorization. In Proceedings of the Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015, Paris, France, 25–28 August 2015; pp. 541–546. [Google Scholar]
- Xue, H.J.; Dai, X.; Zhang, J.; Huang, S.; Chen, J. Deep matrix factorization models for recommender systems. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3203–3209. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Proceedings 15. Springer: Cham, Switzerland, 2018; pp. 593–607. [Google Scholar]
- Tosyali, A.; Kim, J.; Choi, J.; Jeong, M.K. Regularized asymmetric nonnegative matrix factorization for clustering in directed networks. Pattern Recognit. Lett. 2019, 125, 750–757. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Pons, P.; Latapy, M. Post-processing hierarchical community structures: Quality improvements and multi-scale view. Theor. Comput. Sci. 2011, 412, 892–900. [Google Scholar] [CrossRef]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Verma, B.; Rastogi, S.S. Social popularity based SVD++ recommender system. Int. J. Comput. Appl. 2014, 87. [Google Scholar] [CrossRef]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Hosseinzadeh Aghdam, M.; Daryaie Zanjani, M. A novel regularized asymmetric nonnegative matrix factorization for text clustering. Inf. Process. Manag. 2021, 58, 102694. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Alzahrani, T.; Horadam, K.J. Community detection in bipartite networks: Algorithms and case studies. In Complex Systems and Networks: Dynamics, Controls and Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 25–50. [Google Scholar]
- Gupta, S.; Singh, D.P. Recent trends on community detection algorithms: A survey. Mod. Phys. Lett. B 2020, 34, 2050408. [Google Scholar] [CrossRef]
- He, X.; Zhang, H.; Kan, M.Y.; Chua, T.S. Fast matrix factorization for online recommendation with implicit feedback. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 549–558. [Google Scholar]
- Seifikar, M.; Farzi, S.; Barati, M. C-blondel: An efficient Louvain-based dynamic community detection algorithm. IEEE Trans. Comput. Soc. Syst. 2020, 7, 308–318. [Google Scholar] [CrossRef]
- Kaggle. Available online: https://www.kaggle.com/datasets/prajitdatta/movielens-100k-dataset (accessed on 31 July 2023).
- Konect. Available online: https://www.kaggle.com/datasets/tranhungnghiep/goodbooks6m (accessed on 31 July 2023).
- Konect. Available online: https://www.kaggle.com/datasets/meirnizri/cellphones-recommendations (accessed on 31 July 2023).
- Konect. Available online: http://konect.cc/networks/librec-filmtrust-ratings/ (accessed on 31 July 2023).
- Konect. Available online: http://konect.cc/networks/Jester2/ (accessed on 31 July 2023).
- Konect. Available online: http://konect.cc/networks/Wikilens-ratings/ (accessed on 31 July 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Users | Number of Items | Number of Ratings | Rating Scale | Average Rating | Sparsity |
|---|---|---|---|---|---|---|
| MovieLens 100K | 943 | 1682 | 100,000 | 1–5 | 3.529 | 0.937 |
| Film Trust | 1508 | 2071 | 35,494 | 0.5–4 | 3.002 | 0.988 |
| Jester | 31,958 | 140 | 1,048,575 | −10–+10 | 0.955 | 0.839 |
| Wikilens | 326 | 5111 | 26936 | 0.5–5 | 3.468 | 0.983 |
| Good Books | 13,123 | 7774 | 1,048,575 | 1–5 | 3.806 | 0.989 |
| Cell Phone Recommendation | 99 | 33 | 990 | 1–10 | 6.689 | 0.708 |
| Dataset | Time (s) |
|---|---|
| MovieLens 100K | 1473.21 |
| Film Trust | 936.00 |
| Jester | 11,714.99 |
| Wikilens | 1068.41 |
| Good Books | 43,125.11 |
| Cell Phone Recommendation | 15.58 |
| MF method (→)/ Dataset (↓) | Basic MF | SVD++ | FANMF | |||
|---|---|---|---|---|---|---|
| Non-CBMF | CBMF | Non-CBMF | CBMF | Non-CBMF | CBMF | |
| MovieLens 100K | 3.8 | 0.37 | 1.26 | 0.21 | 0.75 | 0.2 |
| Film Trust | 7.69 | 0.002 | 0.4 | 0.003 | 0.2 | 0.0001 |
| Jester | 3.1 | 0.55 | 1.9 | 0.47 | 0.84 | 0.005 |
| Wikilens | 5.11 | 0.004 | 0.63 | 0.005 | 0.44 | 0.002 |
| Good Books | 3.9 | 0.11 | 0.55 | 0.02 | 0.18 | 0.009 |
| Cell Phone Recommendation | 5.8 | 0.42 | 4.7 | 0.7 | 2.9 | 0.003 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tokala, S.; Enduri, M.K.; Lakshmi, T.J.; Sharma, H. Community-Based Matrix Factorization (CBMF) Approach for Enhancing Quality of Recommendations. Entropy 2023, 25, 1360. https://doi.org/10.3390/e25091360
Tokala S, Enduri MK, Lakshmi TJ, Sharma H. Community-Based Matrix Factorization (CBMF) Approach for Enhancing Quality of Recommendations. Entropy. 2023; 25(9):1360. https://doi.org/10.3390/e25091360
Chicago/Turabian StyleTokala, Srilatha, Murali Krishna Enduri, T. Jaya Lakshmi, and Hemlata Sharma. 2023. "Community-Based Matrix Factorization (CBMF) Approach for Enhancing Quality of Recommendations" Entropy 25, no. 9: 1360. https://doi.org/10.3390/e25091360
APA StyleTokala, S., Enduri, M. K., Lakshmi, T. J., & Sharma, H. (2023). Community-Based Matrix Factorization (CBMF) Approach for Enhancing Quality of Recommendations. Entropy, 25(9), 1360. https://doi.org/10.3390/e25091360