1. Introduction
Randomness has proven to be a valuable resource for a multitude of tasks, be it computation or communication. In cryptography, access to reliable random bits is essential, since the security of various cryptographic primitives is known to be compromised if the incorporated randomness is of poor quality [
1,
2,
3]. In the study of random network modelling, being able to sample random graphs uniformly and (reliably) at random is crucial [
4]. And, for some problems, randomised algorithms are known to vastly outperform their deterministic counterparts [
5].
A distinction between two notions of randomness, those of
process and
product, is discussed in [
6] (chapter 8). Although both notions are tightly connected, randomness of a process refers to its unpredictability, while that of a product refers to a lack of pattern in it. An unpredictable process will, with high probability, produce a sequence (a string of bits, say) that is patternless; on the other hand, a seemingly irregular string of bits might not be unpredictable and instead be a probabilistic mixture of pre-recorded information. While product randomness suffices for tasks like Monte Carlo simulations, sampling and those involving randomised algorithms, cryptographic applications involving an adversary necessitate process randomness.
Process randomness, while being non-existent in the strictest interpretation of any classical theory, is permissible in quantum mechanics; an important example of this is quantum nonlocality as manifested in a Bell experiment. Quintessentially, the setup of a Bell experiment constitutes an entangled quantum system shared between two spatially separated stations and receiving inputs and , and recording outcomes and , respectively. If after n successive trials the observed correlations between the outcomes conditioned on the settings violate a Bell inequality then it can be ruled out that the outcomes were pre-assigned by some probabilistic mixture of deterministic processes. Also, the outcomes are (unpredictably) random, not only to the respective users of the devices at the two stations but also to an adversary, even to one having a complete understanding of the Bell experiment. This relationship between nonlocality in quantum mechanics and its random nature is at the foundation of various device-independent random number generation protocols.
Device independence is considered a gold standard in cryptographic tasks such as quantum random number generation and quantum key distribution, in which the respective users are not required to know or trust the inner machinery of their devices, thus treating them as mere black boxes to which they can provide inputs and record outcomes. The only assumption that the experimental setup must satisfy is that the measurement choices of the devices must be uncorrelated with their inner workings. This is the measurement independence assumption, which is ultimately untestable but is tacitly assumed, arguably, in almost all scientific experiments. The no-signalling condition that the outcome recorded at each station is not influenced by the choice of measurement at the other station holds throughout the experiment because of the space-like separation between the stations and the impossibility of superluminal signalling in accordance with the special theory of relativity. Furthermore, the adversary trying to simulate the observed statistics may be considered computationally unbounded, a standard that falls under the paradigm of information-theoretic security. Over the years, technological advancement has facilitated loophole-free Bell nonlocality experiments, which have not only provided experimental validation to rule out a classical description of nature [
7,
8,
9,
10], but have also found practical applications in device-independent quantum randomness generation and device-independent quantum key distribution [
11,
12,
13].
The probability estimation framework is a broadly applicable framework for performing device-independent quantum randomness generation (DIQRNG) upon a finite sequence of loophole-free Bell experiment data and involves direct estimation of the amount of certifiable randomness by obtaining high-confidence bounds on the conditional probability of the observed measurement outcomes conditioned on the measurement settings in the presence of classical side information [
14,
15,
16]. Advantageous primarily for its demonstrated applicability to Bell tests with small Bell violations and high efficiency for a finite number of trials, it can also accommodate changing experimental conditions and allows early stoppage upon meeting certain criteria. Also, it can be extended to randomness generation with quantum devices beyond the device-independent scenario.
The probability estimation framework for DIQRNG is provably secure against adversaries who do not possess entanglement with the sources. Security against more general adversaries, with quantum entanglement with the sources, is possible with the quantum estimation framework [
17], for which the constructions of the probability estimation framework can often be translated to the quantum estimation framework (as was carried out in [
18]), so that progress with the former framework can often be used for the more general latter framework.
The asymptotic optimality of the probability estimation framework was discussed in [
15]. The specific result of asymptotic optimality is as follows: given a sufficiently large number of trials sampling from a fixed behaviour (i.e., a set of quantum statistics), the amount of certified randomness per trial is arbitrarily close to a certain upper limit. Then [
15] argues, appealing to convex geometry and the asymptotic equipartition property (AEP), that an adversary can always implement a probabilistic mixture of conditional probability distributions, independent and identically distributed across successive experimental trials, that generates observed statistics consistent with the fixed behaviour while not needing to generate more than that same upper limit of randomness per trial that is certified by the probability estimation framework. This is important in the sense that the framework certifies all the randomness conceded by the adversary in that particular attack, while also showing that there is no advantage to be gained for the adversary by resorting to (more sophisticated) memory attacks.
In this paper, we provide a full derivation of the asymptotic optimality of the probability estimation framework, filling in some steps omitted by [
15], along the way obtaining a better characterisation of the adversary’s optimal probabilistic mixture for generating the observed statistics. Making precise the arguments from convex geometry, we explicitly describe the optimal attack that an adversary can employ with the minimum required number of different conditional distributions in convex mixture to simulate the observed statistics. Our improvement, with a more self-contained approach, upon the result in [
15] is to reduce by one the cardinality of the adversary’s (finite-cardinality) set from which the auxiliary random variable takes values. This random variable serves as her side-information and records which conditional distribution occurs in which trial. Specifically, we prove that the number of possible conditional distributions in her optimal probabilistic mixture attack
need not be more than one plus the dimension of the set of admissible distributions of a trial (Theorem 4). (We assume the set of admissible probability distributions of a given trial to be closed and convex, where we can take the convex closure when this assumption is not met; then the dimension
of a non-empty convex subset
C of
X is the dimension of the smallest affine subset containing
C.) An earlier result (Theorem 43 in [
15] under the same assumptions) proved only that the cardinality of the value space of the adversary’s side-information need not be more than two plus the dimension of the set of admissible distributions of a trial. Besides contributing to a methodological improvement, we have thus improved the result itself: a better understanding of the optimal attack in the asymptotic regime will establish a benchmark that will enable the implementer of the protocol to defend against these attack modes.
The central results on asymptotic optimality of the method of probability estimation comprise establishing an upper bound on the randomness per trial more than which the adversary need not concede (Theorems 3 and 4) and which is certified by the method of probability estimation (Theorems 5 and 6). Our derivation in Theorem 3 elucidates how only the classical form of the asymptotic equipartition property is needed for the probability estimation framework, allowing a simplified treatment. In addition to strengthening the result in Theorem 4, we have presented proofs for Theorems 5 and 6 (which have appeared previously in [
15]), including more details and specifications where we deemed fit. For instance, in the proof for Theorem 6, enlisting the extreme value theorem we avoid an explicit analytic construction as presented in [
15] (see Theorem 41 therein). We also consider the question of
robustness of the probability estimation framework, not considered in [
14,
15]; we derive a sufficient condition (Theorem 7) for a probability estimation factor (optimised at a particular distribution) to certify randomness at a positive rate at a
statistically different distribution.
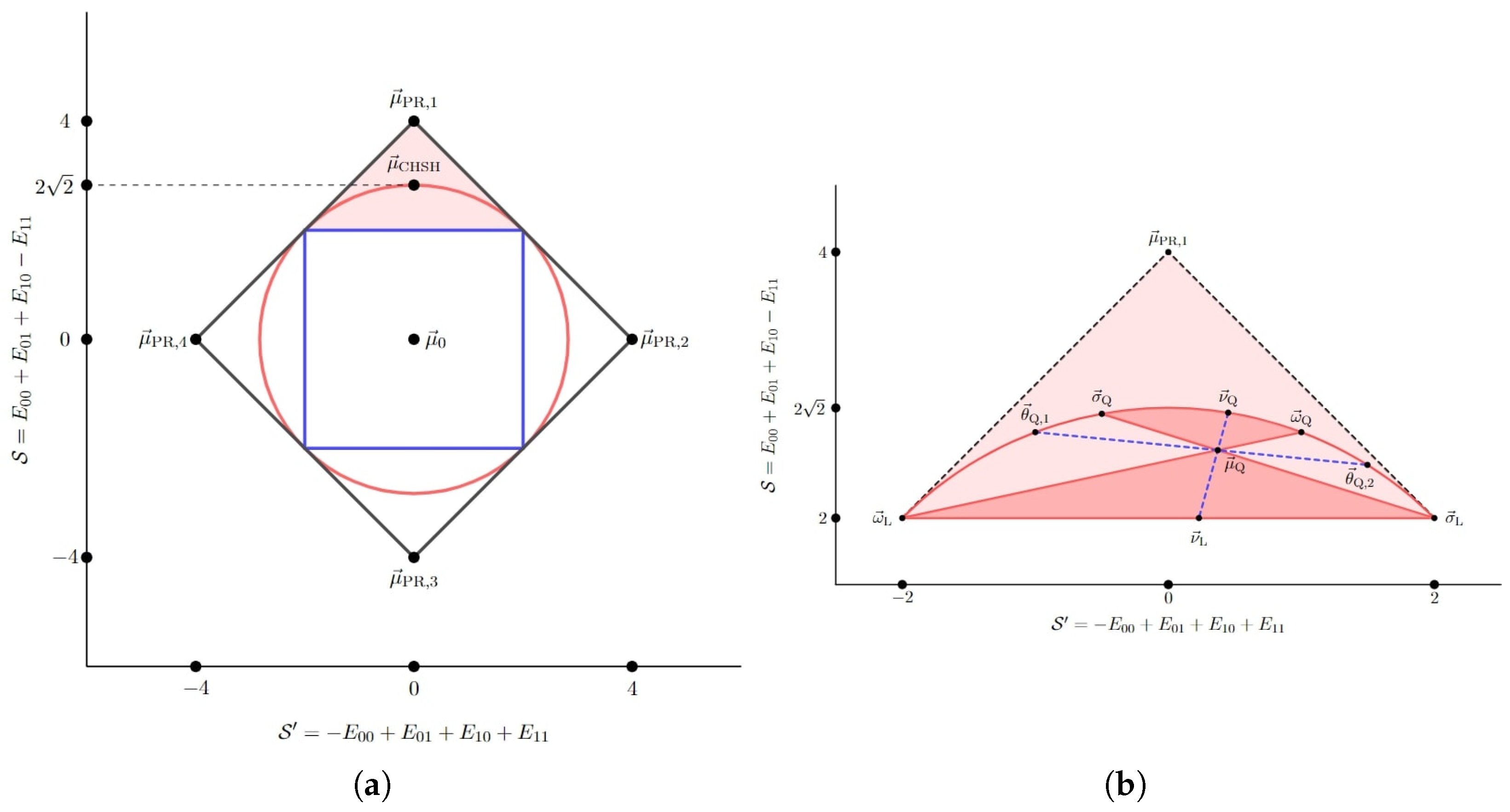
We apply our results to the (2,2,2) Bell scenario (the scenario of two parties, two measurement settings and two outcomes), obtaining an analytic characterisation of the optimal attack of an adversary (restricted only by the no-signalling condition) holding classical side information. We show that the optimal adversarial attack involves a decomposition of the observed statistics in terms of a single extremal no-signalling (super-quantum) correlation and eight local deterministic correlations. The proof of optimality relies upon the fact that equal mixtures of two extremal no-signalling nonlocal super-quantum correlations are expressible as an equal mixture of four local deterministic correlations. We show that this result does not generalise to higher scenarios such as the (3,2,2), (2,3,2) and (2,2,3) Bell scenarios, thereby indicating that the possibility of an optimal attack involving only a single extremal strategy is only ensured in the minimal (2,2,2) Bell scenario. Furthermore, we considered the possibility of an adversary holding classical side information (and, hence, restricted to probabilistic attack strategies) but trying to simulate the observed statistics using quantum-achievable probability distributions, while conceding as little randomness as possible. Assuming uniform settings distribution, numerical studies restricted to a two-dimensional slice of the set of quantum-achievable distributions provided some initial evidence that the optimal quantum-achievable attack strategy involves only one extremal quantum correlation, but we were not able to settle this and have phrased it as a conjecture.
The rest of the article is organised as follows: In
Section 2, we review the probability estimation framework where Theorem 1 formalises the central idea and Theorem 2 establishes a lower bound on the smooth conditional min-entropy of the sequence of outcomes conditioned on the settings and side-information. We also present a simplified proof of Lemma 1, an important result that allows the algorithm to execute the PEF method, compared to the proofs in [
14,
15]. In
Section 3, we present our complete proof of asymptotic optimality, study the implications for finding an optimal adversarial attack strategy and derive a robustness result. In
Section 4, we apply our results to the (2,2,2) Bell scenario obtaining an analytic characterisation of the optimal attack strategy for an adversary restricted only by the no-signalling condition. The optimal attack comprises a decomposition of the observed statistics in terms of a single Popescu–Rohrlich (PR) correlation and (up to) eight local deterministic correlations. We show that, for a higher number of parties, settings and/or outcomes, a crucial result from the (2,2,2) Bell scenario concerning equal mixtures of extremal nonlocal no-signalling correlations does not hold, and infer that the optimal attack may require more than one nonlocal distribution in general. Returning to the (2,2,2) scenario, we discuss a conjecture that the optimal strategy to mimic the observed statistics by means of a probabilistic mixture of quantum-achievable correlations constitutes only a single extremal quantum correlation and (up to) eight local deterministic correlations.
2. The Probability Estimation Framework
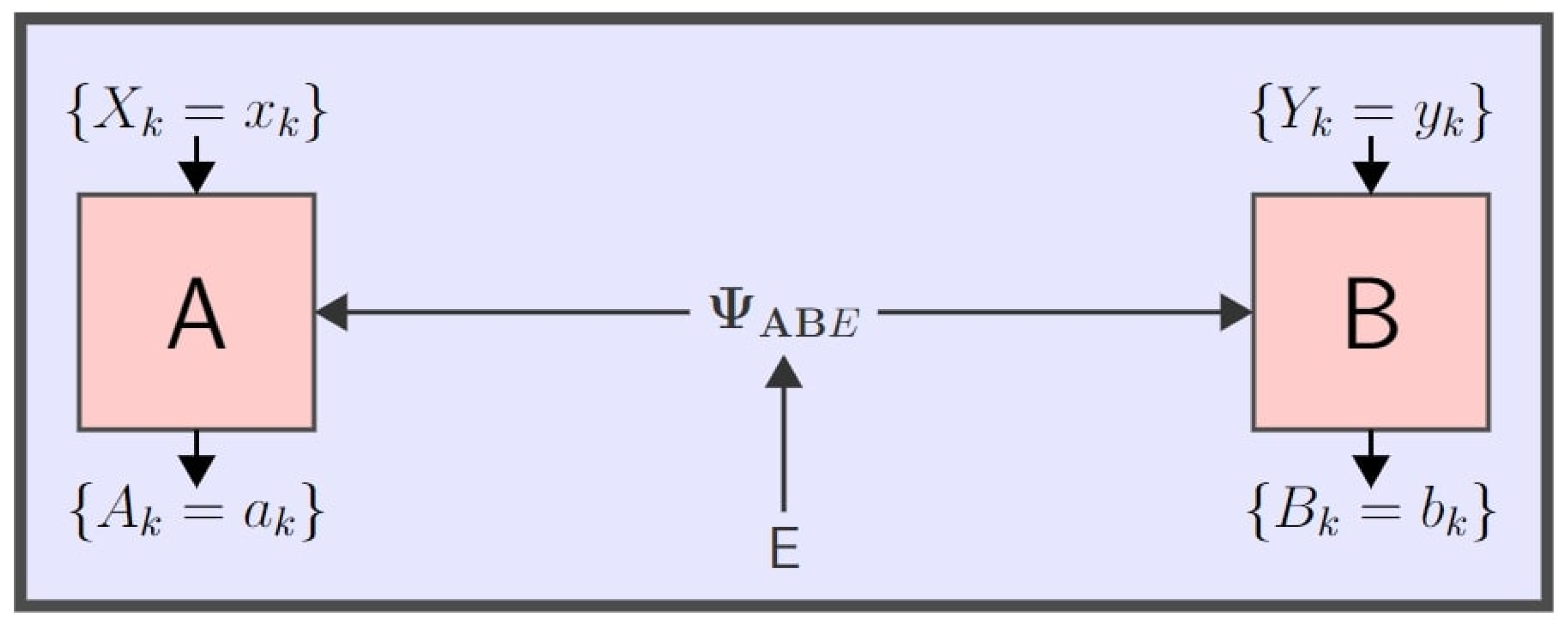
The probability estimation method relies on the probability estimation factor (PEF), which is a function that assigns a score to the results of a single trial of a quantum experiment, with higher scores corresponding to more randomness. The paradigmatic application is to a Bell nonlocality experiment comprising multiple spatially separated parties providing inputs (measurement settings) to measuring devices and recording outputs (observed outcomes); an experimental trial’s results then consist of both the choice of inputs and the recorded outputs for that trial.
Figure 1 below shows a schematic two-party representation of such an experimental setting. After many repeated trials the product of the PEFs from all the trials is used to estimate the probability of outcomes conditioned on the settings.
For the examples considered in
Section 4, we will consider the canonical scenario of two measuring parties Alice and Bob each selecting respective binary measurement settings
X and
Y and recording respective binary outcomes
A and
B, which we refer to as the (2,2,2) Bell scenario. For now, we treat things in a general manner as is carried out in [
14,
15], modelling the trial settings for all parties and outcomes for all parties with single random variables
Z and
C, respectively, taking values from respective finite-cardinality sets
and
. When applied to the (2,2,2) Bell scenario,
C comprises the ordered pair
and
Z comprises the ordered pair
.
The results of a sequence of n time-ordered trials are represented by the sequences ; and, so, realises values , where are the n-fold Cartesian products of . A PEF is then a real-valued function of C and Z satisfying certain conditions, while the product of PEFs from all trials will be a function of and . High values of the PEF product will correlate with low values of , the conditional probability of the outcomes given the settings.
To define PEFs, we introduce the notion of a
trial model: a set
encompassing all joint probability distributions of settings and outcomes which are compatible with basic assumptions about the experiment. One important trial model that we consider is
, consisting of joint distributions of
for which the conditional distribution of
C conditioned on
Z can be realised by a measurement on a quantum system. Here, we introduce the convention, used throughout, of using lower case Greek letters with random variables as arguments to denote distributions, i.e.,
and
denote the joint distribution of
and the conditional distribution of
C given
Z, respectively. Another important trial model is
(NS stands for “no-signalling"), consisting of distributions for which probabilities of measurement outcomes at one location are independent of measurement settings at the other distant locations. (This is more clearly understood in considering the Alice–Bob example, where one of the no-signalling conditions is that
for all
and
.) A third important trial model is the set
of distributions for which the conditional distribution of outcomes conditioned on settings are
local, which means they can be expressed as convex mixtures of local deterministic behaviours. In the bipartite setting, the conditional distribution
, also referred to as a behaviour, is local deterministic if
(where the notation
represents the function that evaluates to 1 if the condition within holds, 0 otherwise). In words, the outcomes are functions of the local settings and the local hidden variable
which can be understood to be a list of outcomes for all possible settings. A formal definition involving more parties and an arbitrary (albeit same) number of outcomes and settings for each party can be found in (
48). The sets
satisfy the following strict inclusions:
Certain distributions in
and
violate a Bell inequality and are known to contain randomness; they are contained in
and
, respectively. It is precisely the inability to decompose such distributions into deterministic ones, as in
, that implies the presence of randomness. The objective of the PEF approach is to quantify the randomness contained in such distributions. As trial models specify the joint distribution
, and for the above examples of trial models we gave only the conditional distributions
, one must also specify the marginal distribution of the settings
. For the discussions of
and
in subsequent sections, any fixed distribution satisfying
for all
is permitted. An example of a fixed settings distribution is the equiprobable distribution
defined as
for all
.
As a discrete probability distribution is effectively an ordered list of numbers in (the probabilities), trial models are always subsets of , where N is fixed by the cardinality of and . This enables us to use a geometric approach to study these sets, which prove to be invaluable for some arguments.
We can now define PEFs. We use the notation and to denote expectation and probability, respectively, with respect to a distribution ; and for the sake of notational concision we omit commas in distributions or functions of more than one random variable, for instance, and must be understood to mean and .
Definition 1 (Probability Estimation Factor)
. A probability estimation factor (PEF) with power for the model of distributions Π is a function of the random variables such that for all , holds.
In the expression above, denotes a random variable that is a function of the random variables C and Z: is the random variable that assumes the standard conditional probability (according to ) of C taking the value c conditioned on Z taking the value z; it is assigned the value zero if the probability is zero. The parameter can be any positive real value. We then note that the constant PEF for all is a valid PEF for any choice of . We will notice in the subsequent sections, however, that the parameter does have an effect on the method employed for choosing useful PEFs for the purpose of randomness certification; and in practice we choose the value of that corresponds to the maximum randomness certification.
Prior to defining a PEF we introduced the notion of a trial model. For the application of probability estimation to the outcomes of an experiment, which is a sequence of
n time-ordered trials, we introduce the notion of an
experiment model: it is a set
constraining the joint distribution of
,
and
E, constructed as a chain of individual trial models
; it consists of joint distributions
conditioned on the event
, where
E is the random variable denoting the adversary’s side information and realising values
e from the finite set
. It satisfies the following two assumptions:
In (
1),
denote the outcomes and measurement settings for the first
trials, where
, with
denoting their respective realisations. The random variables
are the outcomes and settings for the
’th trial. The first condition in (
1) formalises the assumption that the (joint) probability of the
’th outcome and setting, conditioned on the outcomes and settings for the first
i trials and each realised value
of the adversary’s side information, belongs to the
’th trial model, i.e., it is compatible with the conditions dictated by the trial model. The second condition states that for each
the setting for the
next trial is independent of the outcomes and settings of the
past and present trials. Our second condition is a stronger assumption than the corresponding assumption given in [
14], which is as follows: the joint distribution
of
is such that
is independent of
conditionally on both
and
E. It is a straightforward exercise to check that our stronger assumption implies the one stated in [
14]. While the weaker assumption is sufficient for the following result, we find the stronger assumption operationally clearer as an assumption that the future settings are independent of “everything in the past" for each realisation of
e.
For the rest of the paper we adopt the abbreviated notation of
for
. The following theorem, appearing as Theorem 9 in Appendix C in [
14], formalises the central idea behind the framework of probability estimation. We include a proof for this theorem in
Appendix A.1.1 for completeness.
Theorem 1. Suppose is a distribution of such that for each . Then, for fixed holds for each , where is the probability estimation factor for the i’th trial. The distinguishing feature of the framework of probability estimation is the direct estimation of
for each
by constructing PEFs
and accumulating them trial-wise in a multiplicative fashion. For a fixed error bound
and the power parameter
, the term
serves as an estimate for
. It is important to note that PEFs are functions of only the measurement outcomes and settings and not of the side information held by the adversary to which we do not have access. For a large value of
n—the number of trials—the trial-wise product
will be large if the experiment is well-calibrated and run properly. For the purpose of randomness generation the inequality (
2) in Theorem 1 can then be understood, intuitively, as follows: Since the trial-wise product
of the PEFs is large and so, for fixed
, the quantity
is small, for each
there is a very small probability (denoted by the outer probability
) that the conditional probability of the sequence of outcomes
conditioned on the sequence of settings
(denoted by
) is more than a small value. This translates to the measurement outcomes
being unpredictably random for a given
. Since this string of experimental outcomes is unpredictable even given the adversary’s side information, it can be used as a source of certifiable randomness. We stress that in the method of probability estimation the estimates on the conditional probability of measurement outcomes given the settings choices and side-information depend solely on the experimental data.
Conventional methods of randomness extraction, however, involve obtaining a lower bound on the smooth conditional min-entropy which quantifies the amount of raw randomness from a source. The lower bound then goes as one of the parameters in extractor functions to extract near-uniform random bits. It is therefore useful to translate the bound in (
2) into a statement about the smooth conditional min-entropy with respect to an adversary.
We motivate and introduce conditional min-entropy as follows. An adversary’s goal is to predict
C. Conditioned on a particular realisation of the settings sequence
and side information
, one can measure the “predictability” of the sequence of outcomes
with the following maximum probability:
It quantifies the best guess of the adversary. The
-conditional min-entropy of
, corresponding to that particular realisation
, is the following negative logarithm:
The subscript
in the notation
refers to the distribution
. The average
-conditional min-entropy is then defined as follows:
But, information-theoretic security of cryptographic protocols take into account a more realistic measure of average
-conditional min-entropy which involves a smoothing parameter
, a type of error bound, and is known as the
-smooth average
-conditional min-entropy. This quantity is useful for our scenario in which the probability distribution is not known exactly and its characteristics can only be inferred from observed data, which introduces the possibility of error. It is defined as follows.
Definition 2 (Smooth Average Conditional Min-Entropy)
. For a distribution of the set of distributions of is defined aswhere and is the total variation distance between σ and μ defined asThe ϵ-smooth average -conditional min-entropy is then defined as follows. The lower bound obtained on this quantity goes as one of the inputs to extractor functions in randomness extraction, whose purpose is to convert random functions with uneven distributions into shorter, close to uniformly distributed bit strings. We note that alternative definitions of
-smooth conditional min-entropy can be used, for instance, the
-smooth
worst-case conditional min-entropy of [
19]. A known result from the literature, proven in Proposition A1 in
Appendix E, justifies our usage of the
-smooth average conditional min-entropy without having to be concerned with the stricter
-smooth worst-case conditional min-entropy (defined in (A30)): specifically, the two quantities converge to one another in the asymptotic limit.
The result obtained from Theorem 1 can be translated into a result on smooth average conditional min-entropy formalised in Theorem 2 below. This theorem appears as Theorem 1 in [
14]. We include a proof for this theorem in
Appendix A.1.2 for completeness. In the notation of
-smooth average
-conditional min-entropy in (
7), the semicolon followed by
denotes that this information-quantity is assessed with respect to the distribution
after conditioning on the occurrence of the event
defined in the statement of Theorem 2. It pertains to an abort criterion. The protocol succeeds only if the product of the trial-wise PEFs exceeds some threshold value, otherwise it is aborted. So we want to establish the lower bound for smooth conditional min-entropy conditioned on the event that the protocol succeeds, because it is precisely this scenario in which we extract randomness. Since a completely predictable local distribution can always have a chance of passing the protocol, however minuscule (in the order of
, where the number of trials
n often goes up to millions)—and
will equal 1 in this case—it is necessary to assume a small but positive lower bound on the probability of not aborting to derive a useful min-entropy bound. This can be thought of as another type of error parameter. The assumed lower bound for the probability of success of the protocol is
.
Theorem 2. Let μ be a distribution of such that, for each , the following holds for every :where is a PEF with power β for the i’th trial. For a fixed choice of and , define the event . Then, if κ satisfies , the following holds: Under the same conditions of Theorem 2, the main result (
7) admits a minor reformulation as follows. This is the formulation that aligns with the statement of Theorem 1 in [
14].
Corollary 1. Let be a distribution of and F be a PEF with power β such that (6) holds for each . For a fixed choice of , and positive where , we have Proof. Use Theorem 2 with , and , noting that, since and hold, we have and as required for invoking the theorem. Then, notice the corresponding event aligns with the event . □
The above results hold when we consider distributions
of
, i.e., where the side information is structured as a sequence of random variables. The proof remains the same with the exception that we condition on an arbitrary sequence of realisation
of
. We consider this scenario in
Section 3 where we define an IID attack from the adversary.
Theorem 1 does not indicate how to find PEFs. One way to find useful PEFs is to first notice that the success criterion of the protocol is the event
that the inequality
holds, which can be equivalently expressed as
where
are pre-determined quantities to be chosen in advance of running the protocol. Then, considering an anticipated trial distribution
based on observed results and calibrations from previous trials, in the limit of sufficiently large
n the difference between the term on the left hand side of (
9) (which consists of the trial-wise sum of (base-2) logarithm of PEFs) and
will be either greater or less than zero with roughly equal probability. This follows from the Central Limit Theorem if the distribution remains roughly stable from trial to trial. Since it is desirable to have the largest value of
possible, one can then perform the following constrained maximisation using any convex programming software owing to the concavity of the objective function and the linearity of the constraints.
Since
are fixed, it is sufficient to maximise
subject to the same constraints. In practice, one can consider a range of values of
and perform the constrained maximisation with the objective
, then plug in the maximum value in the expression
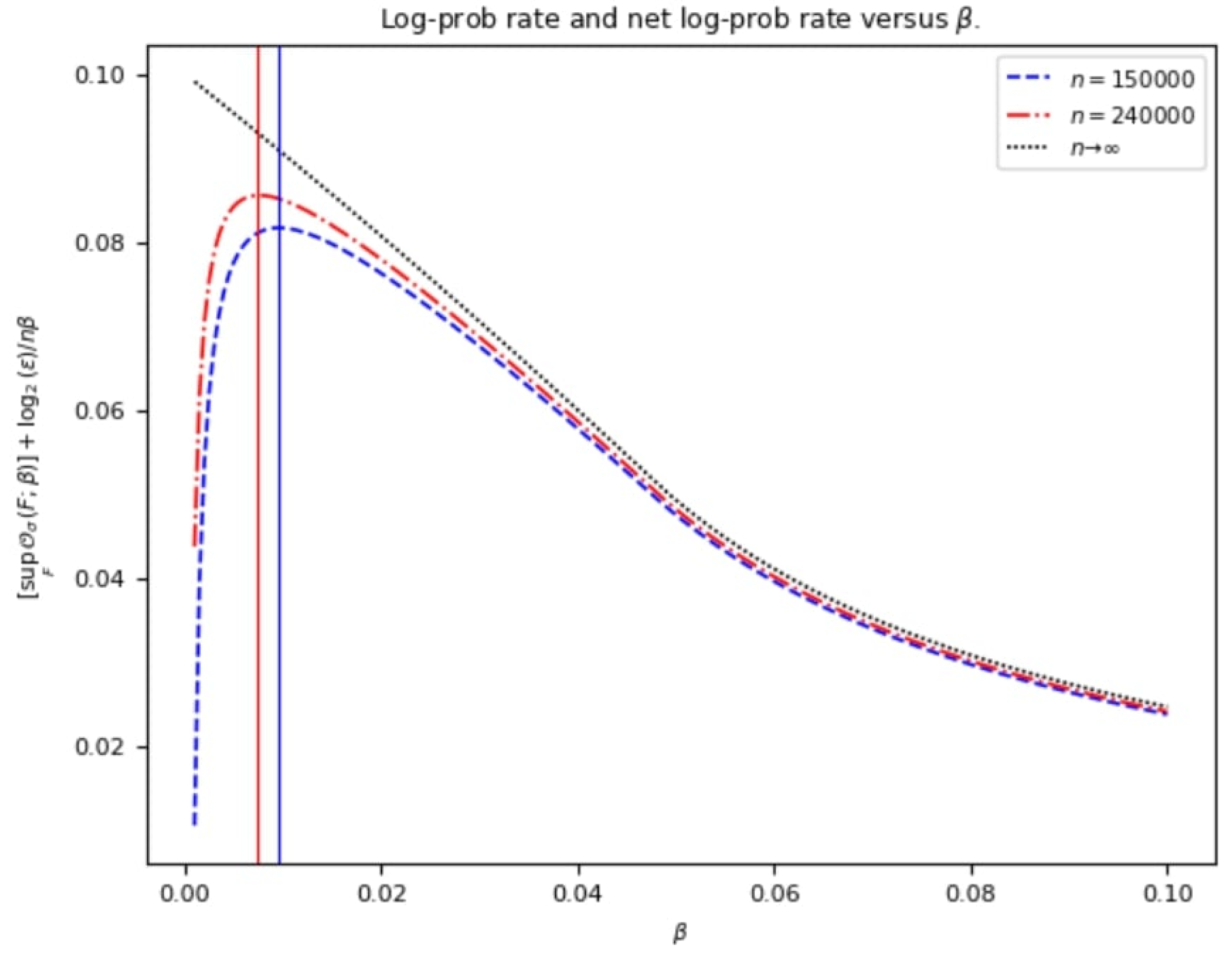
and obtain a plot with respect to the considered range of
values (see, for example,
Figure 2 in [
16]; a similar pattern is observed in
Figure 2 in
Section 2).
The following lemma (from [
14], see Lemma 15)—for which we provide a more direct proof—enables us to restrict the satisfiability constraints of the optimisation routine in (
10) to the extremal distributions of the model
under the condition that the model is convex and closed. So, the first line of constraints in (
10) can be replaced with
, where
is the set of extremal distributions of
. If the model
is not convex and closed, we take its convex closure. In words, the lemma states that, if
is a PEF with power
for the distributions
, then it is a PEF with the same power for all distributions that can be expressed as a convex combination of
and
.
Lemma 1. For distributions satisfying , for , if is expressible as for , then it satisfies .
Proof. For
z such that
, we have
as well and, from
, straightforward algebra shows that
for any
, where
. Since, for
,
is convex for
, we can write
Turning to cases where
and/or
may equal zero, we can also demonstrate (
11) under the convention of taking
to be zero when
. Then, the inequality holds as an equality when
(which implies
as well); for
one can verify (
11) after noting
and
, and the
case follows symmetrically. Now, multiplying both sides of (
11) by
and summing over
gives
□
We remark that the result of Lemma 1 can also be obtained through specialisation of known quantum results to classical distributions; however, this requires a more technical argument with additional machinery. To elaborate, the proof for Lemma 1 involves showing the joint convexity of
which can be seen as a special case of the joint convexity of sandwiched Rényi powers. To be more specific, it arises as a special case of the joint convexity of
for
when the distribution
is taken to be
. Notice that
is the (classical) Rényi divergence of order
of
with respect to
. The functional
can also be seen as a specialisation (to classical states) of the same functional, defined in terms of (quantum) density states
and
, whose joint convexity was proven in proposition 3 of [
20] with an extended technical argument.
3. Asymptotic Performance
The results of the previous section give us a method for certifying randomness. In this section, we assess the asymptotic performance of the method. Our figure of merit is the amount of randomness certified per trial, as measured by the average conditional min-entropy divided by the number of trials n. We will see in this section that the PEF method is asymptotically optimal, in the following sense: given a fixed observed distribution, the PEF method can asymptotically certify an amount of per-trial conditional min-entropy that is equal to the actual per-trial conditional min-entropy generated by an adversary replicating the observed distribution with as little randomness as possible.
To elaborate on this, consider that the adversary’s goal is to minimise the following quantity:
We assume that the adversary has complete knowledge of the distribution
, and can have access to not just the realised value of
E but also the realised value of
in guessing
. This access to
aligns with the paradigm, as discussed in [
11], of “using public (settings) randomness to generate private (outcome) randomness”. The adversary is constrained, however, in that the statistics when marginalised over
E must appear to be consistent with an expected observed trial distribution
for the protocol to not abort. Technically, all that is necessary for the protocol to pass is that the observed product of the PEFs must exceed some threshold value chosen by the experimenter—which could be possible with high probability with many different distributions
—but, as the experimenter’s threshold value will likely be chosen based on a full behaviour that they expect to observe, we study attacks that match the expected observed trial distribution exactly. We will find attacks meeting this criterion that are asymptotically optimal for minimising the conditional min-entropy.
Given an expected observed distribution, how can the adversary generate observed statistics consistent with it while yielding as little randomness as possible? She can employ a strategy of preparing multiple different states to be measured that will yield different distributions, each one consistent with the trial model , whose convex mixture is equal to the observed distribution. If she has an auxiliary random variable E realising values from the finite-cardinality set and recording which state was prepared on which trial, she can predict better the outcome conditioned on her side information , in conjunction with the settings Z. Indeed, some of her e-conditional distributions could be deterministic—specifically, the product of a fixed settings distribution and a deterministic behaviour (conditional distribution of the outcomes conditioned on settings), in which case she does not yield any randomness to Alice and Bob on a trial where E takes that value. But, if the overall observed statistics are nonlocal, then she is forced to prepare at least some states that contain randomness even conditioned on e; this, in essence, is because the information that she possesses with E is a local hidden variable.
3.1. I.I.D. Attacks
Given a convex decomposition of the observed distribution, the adversary’s simplest form of an attack is to select e from some finite-cardinality set in an i.i.d manner on each trial according to the distribution that recovers the observed distribution . A more general attack would allow her to use memory of earlier trials but we will see later that, asymptotically, this does not yield meaningful improvement.
Operationally, we do not like to think of the adversary accessing the devices in between trials to provide a choice of
for each trial. Instead, one can imagine her randomly sampling from the distribution of
for all trials, coming up with a choice
that encodes all the choices of
for each trial and then supplying this choice to the measured system, in advance, to determine its behaviour in each trial. She keeps a record of
to help her predict
C later. Through this sampling process there is a small chance that she will sample an atypical “bad”
that results in statistics deviating from the observed distribution but the probability that her
is typical is asymptotically high. Our figure of merit for the adversary now is:
which she wants to minimise with a distribution that, marginalised over
, is consistent with i.i.d sampling from an expected observed distribution
. We formally define the set
of distributions
of
mimicking
through such a convex decomposition as follows, where
e is shorthand for the event
:
Then, an IID attack can be defined as follows.
Definition 3 (IID Attack)
. Given a distribution , we define an IID attack (with ω) to be the distribution ϕ consisting of n independent and identical realisations of random variables distributed according to ω; i.e., the joint distribution of the sequence of random variables is such that .
As mentioned earlier, the adversary randomly samples from the distribution of
which represents their knowledge of all trials;
encodes the individual choices
for trial
. The IID attack satisfies the two assumptions of the experiment model discussed earlier (see (
1) and the short discussion that follows immediately). Namely, the (joint) probability of the
’th trial outcome and input setting, conditioned on each realisation of the outcomes and settings for the first
i trials and each realisation
of the side information, satisfies the conditions of the trial model; and, conditioned on each
, the settings for the
’th trial are (unconditionally) independent of the outcomes and settings of the past and present trials (i.e., the first
i trials). This is formally stated and proved in Lemma 2 below.
Lemma 2. The IID attack as defined in Definition 3 satisfies the following conditions. Proof. Consider the distribution
conditioned on a realisation
, where
. Notice that
. Marginalising over the random variables
we obtain:
Corresponding to a particular realisation
, we then have
; and, since
, we have
belongs to the set
for all values of
(by construction of the set
, see (
12)). Since (
16) is true for all realisations
we conclude (
13) holds. Next, marginalising (
15) over
we have:
In (
17),
can be observed by marginalising (
15) over the random variables
and
(from marginalising (
15) over
); (
17) is true for all
; hence, we conclude (14). □
Next, the adversary would like to implement an attack that “generates as little randomness as possible”. One measure of the randomness is the conditional Shannon entropy of the outcomes C conditioned on the inputs Z and the side information E.
Definition 4 (Conditional Shannon Entropy)
. For a distribution of the conditional Shannon entropy of the outcomes C conditioned on the settings Z and the side information E is defined as The Greek letter in the subscript of refers to the distribution with respect to which the conditional Shannon entropy is defined.
Theorem 3 below shows that
is an asymptotic upper bound on the per-trial conditional min-entropy that the adversary generates with an IID attack employing a trial distribution
that is consistent with the observed distribution
. This result was discussed but not demonstrated explicitly in [
15]. The proof of Theorem 3 involves one of the fundamental technical tools from information theory, the (classical) asymptotic equipartition property (AEP), or equivalently the notion of typical sequences which has the weak law of large numbers at its core.
Suppose
, the distribution of all trials, is obtained as
n i.i.d. copies of a single-trial distribution
. Then, for
,
there exists
such that
ensures
, where
and
is the conditional Shannon entropy. We refer to this as the AEP condition; it holds by a conditional form of the classical AEP (see, for instance, Section 14.6 in [
21]). The set
of distributions of
that are within a
distance of
from
and the sets
are as defined below:
where
is defined for any
for which
. Note that the case
reduces to a bound on the standard (non-smooth) average conditional min-entropy. We now state the result as follows.
Theorem 3. Let μ be an IID attack with ω. For , and , there exists such that for Proof. Throughout, we follow the convention that
for all
for any
with
. We begin with the inequality
that any
must satisfy and proceed as follows:
The inequality in (
22) follows as a result of the sum containing fewer terms; the inequality in (23) follows from the triangle inequality. Now from the AEP condition mentioned above we have the following:
For any
, we define
for any
as
. The average conditional maximum probability is then expressed as
. Because
, we have
for each
and we can write:
Using (
24) and (
25) we obtain
from which (
21) follows using the definition of smooth average conditional min-entropy. □
Having shown that the per-trial min-entropy generated by an IID attack is asymptotically bounded by the conditional Shannon entropy, we give the following definition of an optimal attack.
Definition 5 (Optimal IID Attack)
. The distribution of the sequence of random variables is an optimal IID attack if μ is obtained through an IID attack based on a single-trial distribution ω whose conditional Shannon entropy achieves the infimum defined below: Additional motivation for naming the attack of Definition 5 optimal is provided by later results in this section, which show that the adversary must generate at least of per-trial conditional min-entropy asymptotically with any attack that replicates the observed distribution .
In the theorem that follows, we formalise the claim that the infimum in (
26) is achieved. This theorem corresponds to Theorem 43 in [
15]; in comparison, the comprehensive proof provided here explicitly works out more of the steps. Crucially, this explicit approach also allowed us to provide an improvement upon the result of Theorem 43 in [
15], decreasing the required value of
by one, thereby better characterising the adversary’s optimal attack. Results in
Section 4.2 will illustrate that no further improvement, i.e., a decrease in
, is possible.
Theorem 4. Suppose Π is closed and equal to the convex hull of its extreme points. Then, there is a distribution with such that .
Theorem 4, in conjunction with the bound in Theorem 3, sets a benchmark for how well the adversary can perform with an IID attack that replicates the observed distribution . Specifically, the adversary’s goal is to minimise the amount of per trial conditional min-entropy and this shows there exists a strategy to replicate the observed statistics while conceding no more min-entropy per trial than , asymptotically.
3.2. Optimal PEFs
We now show that PEFs can asymptotically certify a min-entropy of per trial from an observed distribution . This is notable since it shows that an IID attack can be asymptotically optimal: since the PEF method certifies the presence of min-entropy per trial against any attack, this means no attack can generate observed statistics consistent with while conceding a smaller amount of randomness. This furthermore demonstrates that there is nothing to be gained (asymptotically) by the adversary employing a more sophisticated memory-based attack, since the PEF method allows for the possibility of memory attacks. Conversely, the below results show that the PEF method is asymptotically optimal: no (correct) method can certify more min-entropy per trial from than the amount that is present in an explicit attack.
To formalise and prove these claims, we use the following technical tool, called an “entropy estimator” as in [
15].
Definition 6 (Entropy Estimator)
. An entropy estimator of the model Π is a function of the random variables such that holds for all .
Given an entropy estimator , we say that its entropy estimate at a distribution is . We will see below that an entropy estimator can be used to construct PEFs certifying per-trial min-entropy arbitrarily close to its entropy estimate, underlying the significance of the following result:
Theorem 5. Suppose Π satisfies the conditions of Theorem 4 and ρ is in the interior of Π. Then, there exists an entropy estimator whose entropy estimate at ρ is equal to .
The assumption that
is in the interior of
will generally hold if
is estimated from real data, as the boundary of
is a measure zero set. If the assumption is removed, a weaker version of the theorem can still be obtained, which is discussed in the proof in
Appendix B.1.
The entropy estimator
whose existence is guaranteed by the above theorem can be used to show the existence of a family of PEFs that can become arbitrarily close to certifying
amount of per-trial min-entropy. However, for a precise formulation of this claim we need a way to measure the asymptotic rate of min-entropy using PEFs. Recall from (
8) that we can lower-bound the per-trial min-entropy certified by a PEF as:
As in [
15], we ignore the
term in the asymptotic regime, as the completeness parameter
can be thought of as a “reasonable” lower bound on the probability that the protocol does not abort, a type of error parameter that one might try to decrease somewhat for longer experiments but not at the exponential decay rate required to make this term asymptotically significant. Focusing then on the
term, recall that success of the protocol is determined by the occurrence of the event
, the inequality in which can be expressed equivalently as:
The expression on the left hand side of the above inequality is the negative base-2 logarithm of the upper bound on
for each
(refer to (
2) and the comments following Corollary 1) and so is a rough measure of the amount of randomness, up to an error probability of
, present in the outcome data. More concretely, since
p will be chosen to make
as large as reasonably possible to optimise min-entropy certified by (
27), the anticipated value of the left hand side quantity can be used as a measure of certifiable randomness. For a stable experiment (i.e., one with each trial having the same distribution
belonging to the same model
), the quantity
approaches
in the limit
, while the term
goes to zero for any fixed value of
and
. Hence, we introduce the following quantity as a measure of per-trial min-entropy certified by a PEF.
Definition 7 (Log-Prob Rate)
. The log-prob rate of a PEF with power β at a distribution is defined as .
We say that a PEF certifies randomness at a distribution if the quantity is positive. We note that this definition is consistent with our expectation that only nonlocal distributions allow the certification of randomness, as the log-prob rate for a local distribution is a non-positive number, i.e., : a local behaviour is a convex mixture of (finitely many) local deterministic behaviours . Hence, with a fixed settings distribution , the defining condition of a PEF for a distribution defined as , for all , is equivalently expressed as , since is either 0 or 1 for all . Due to the concavity of log function, we then have using Jensen’s inequality. Hence, no device-independent randomness can be certified at a local-realistic distribution.
Theorem 6. Given an entropy estimator and an observed distribution , for any there is a PEF whose log-prob rate at ρ is greater than .
Our proof follows the general approach of Theorem 41 in [
15], though we are able to shorten the argument.
Proof. Given an entropy estimator
and
from the statement of the theorem, for any
we can define a function
We will show that there exists a (small) positive value of
for which
is a PEF with power
; the asymptotic log-prob rate of this PEF at
will then be
as desired. So, our task is to find a value of
such that the following inequality holds for all
:
We study the left side of the above expression as a function of
; specifically, define a function
which is, for any fixed choice of
and
, a convex combination of positive constants raised to the power of
and so is infinitely differentiable at all
. (Note that we never encounter the problematic form
because the argument of
will always be strictly positive, as the sum defining
extends only over values of
for which
is positive, and hence
.) We can thus Taylor-expand
about
, obtaining via the Lagrange remainder theorem that, for any positive
, there exists a
making the following equality hold:
The first term in the expansion satisfies
. The coefficient of
in (
29) satisfies:
where the inequality follows from the condition
in the definition of an entropy estimator. Hence, (
29) yields
for some
. Now, it is given that a fixed
,
k may be different in (
30) for different choices of
; however, it must always lie in the interval
, so if we can show that there is a choice of
such that for
any the following inequality holds for all
then, for that value of
, we will know that
as defined in (
28) is a valid PEF satisfying the conditions of the theorem. To find the needed value of
making (
31) hold and complete the proof, we calculate
where
. We now assert that each quantity
is bounded above by a constant
for all
and
is independent of
. This follows because, for any fixed choice of
c and
z, this quantity is strictly smaller than the expression
for the choice of
(note that since
,
holds for any
). Then, two applications of l’Hôpital’s rule demonstrate that
exists and so
can be extended to a continuous function on
where it has a maximum by the extreme value theorem. Invocation of the extreme value theorem, rather than computing an explicit bound, is what primarily allows us to shorten the proof compared to the argument proving Theorem 41 in [
15]. Referring to this maximum as
and letting
, we obtain the desired bound as shown below.
This shows that, if
holds, then (
31) holds, from which it follows that a sufficiently small choice of
makes (
31) hold for all
. □
The combination of Theorem 5, which shows the existence of an entropy estimator with entropy estimate , and Theorem 6, which enables the construction of a family of PEFs with log-prob rate arbitrarily close to this entropy estimate, demonstrates the asymptotic optimality of the PEF method.
3.3. Robustness of PEFs
We want to consider a question not considered in the previous PEF papers: can a PEF optimised for certify randomness for a distribution different from , where the difference is measured in terms of the total variation distance between them; in other words, how robust is the PEF? We will see in the next section that, in the (2,2,2) Bell scenario, for any behaviour corresponding to violating the CHSH–Bell inequality, PEFs can be (up to any desired -tolerance) asymptotically optimal in terms of log-prob rate at while also generating randomness at a positive rate for any behaviour (corresponding to a distribution of outcomes and settings) that violates the CHSH–Bell inequality by a fixed positive amount, which can be chosen to be as small as desired.
The following theorem gives a useful sufficient condition for a distribution different from to have a positive log-prob rate and demonstrates that any nontrivial (i.e., non-constant) PEF will have at least some degree of robustness.
Theorem 7. Let be a non-constant positive PEF with power for Π. The log-prob rate at a distribution is related to the log-prob rate at and the total variation distance between ρ and σ aswhere and . Consequently, assuming that is positive, the following upper bound on the total variation distance between and is a sufficient condition for F to have a positive log-prob rate at Proof. Using the definition of log-prob rate at a given distribution we have
Hence, we have
Assuming that
is positive, a sufficient condition for
to be positive is
or, equivalently, the following bound on
:
□
We will see in
Section 4.2 that the bound (
33) can be saturated and so is tight.





{kind=link}
{kind=link}
{kind=link}
{kind=link}