
Quantum State Assignment Flows

 , ,
, ,
Abstract
:1. Introduction
1.1. Overview and Motivation
1.2. Contribution and Organization
1.3. Basic Notation
| Canonical basis vectors of | |
| Euclidean inner vector product | |
| Euclidean norm | |
| Unit matrix of | |
| Component-wise vector multiplication | |
| Component-wise division | |
| Space of Hermitian matrices (cf. (22)) | |
| Trace of matrix A | |
| Matrix inner product , | |
| Commutator | |
| The diagonal matrix with vector v as entries | |
| The vector of the diagonal entries of a square matrix V | |
| The matrix exponential | |
| The matrix logarithm | |
| The set of discrete probability vectors of dimension c (cf. (6)) | |
| The relative interior of , i.e., the set of strictly positive probability | |
| vectors (cf. ) | |
| The product manifold (cf. ) | |
| The set of symmetric positive definite matrices (cf. (17)) | |
| The subset of matrices in whose trace is equal to 1 (cf. (18)) | |
| The product manifold (cf. (96)) | |
| Barycenter of the manifold | |
| Barycenter of the manifold | |
| Matrix | |
| The Riemannian metrics on (cf. (8), (54), (25)) | |
| The tangent spaces to (cf. (10), (54), (21)) | |
| Orthogonal projections onto (cf. (11), (24)) | |
| Replicator operators associated with the assignment flows | |
| on (cf. (12), (58), (64), (105)) | |
| ∂ | Euclidean gradient operator: |
| grad | Riemannian gradient operator with respect to the Fisher–Rao metric |
| , etc. | Square brackets indicate a linear operator that acts in a non-standard |
| way, e.g., row-wise to a matrix argument. |
2. Information Geometry
- The relative interior of probability simplices, each of which represents the categorical (discrete) distributions of the corresponding dimension; and
- The set of positive definite symmetric matrices with trace one.
2.1. Categorical Distributions
2.2. Density Matrices
2.3. Alternative Metrics and Geometries
2.3.1. Affine-Invariant Metrics
2.3.2. Log-Euclidean Metric
2.3.3. Comparison to Bogoliubov-Kubo-Mori Metric
3. Assignment Flows
3.1. Single-Vertex Assignment Flow
3.2. Assignment Flows
3.3. Reparameterized Assignment Flows
4. Quantum State Assignment Flows
- Determination of the form of the Riemannian gradient of functions with respect to the BKM metric (25), the corresponding replicator operator and exponential mappings Exp and exp, together with their differentials (Section 4.1);
- Definition of the single-vertex quantum state assignment flow (Section 4.2);
- Determination of the general quantum state assignment flow equation for an arbitrary graph (Section 4.3) and its alternative parameterization (Section 4.4), which generalizes Formulation (62) of the assignment flow accordingly.
4.1. Riemannian Gradient, Replicator Operator and Further Mappings
4.2. Single-Vertex Density Matrix Assignment Flow
4.3. Quantum State Assignment Flow
4.4. Reparameterization and Riemannian Gradient Flow
4.5. Recovering the Assignment Flow for Categorical Distributions
- (a)
- The submanifold with the induced BKM metric is isometric to ;
- (b)
- If , then the tangent subspace is contained in the subspace defined by (32);
- (c)
- Let denote an orthonormal basis of such that for every , there are that form a basis of . Then, there is an inclusion of commutative subsets that corresponds to an inclusion .
- (i)
- If , then .
- (ii)
5. Experiments and Discussion
- Structure-preserving feature patch smoothing without accessing data at individual pixels (Section 5.3);
5.1. Geometric Integration
| Algorithm 1:Geometric Integration Scheme |
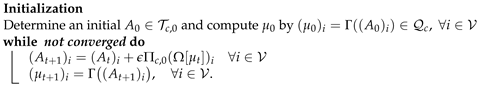 |
- A reasonable convergence criterion that measures how close the states are to a rank-one matrix is ;
- A reasonable range for the step size parameter is ;
- In order to remove spurious non-Hermitian numerical rounding errors, we replace each matrix with ;
- The constraint of (18) can be replaced by with any constant . This ensures that for larger matrix dimensions c, the entries of vary in a reasonable numerical range and that the stability of the iterative updates.
5.2. Labeling 3D Data on Bloch Spheres
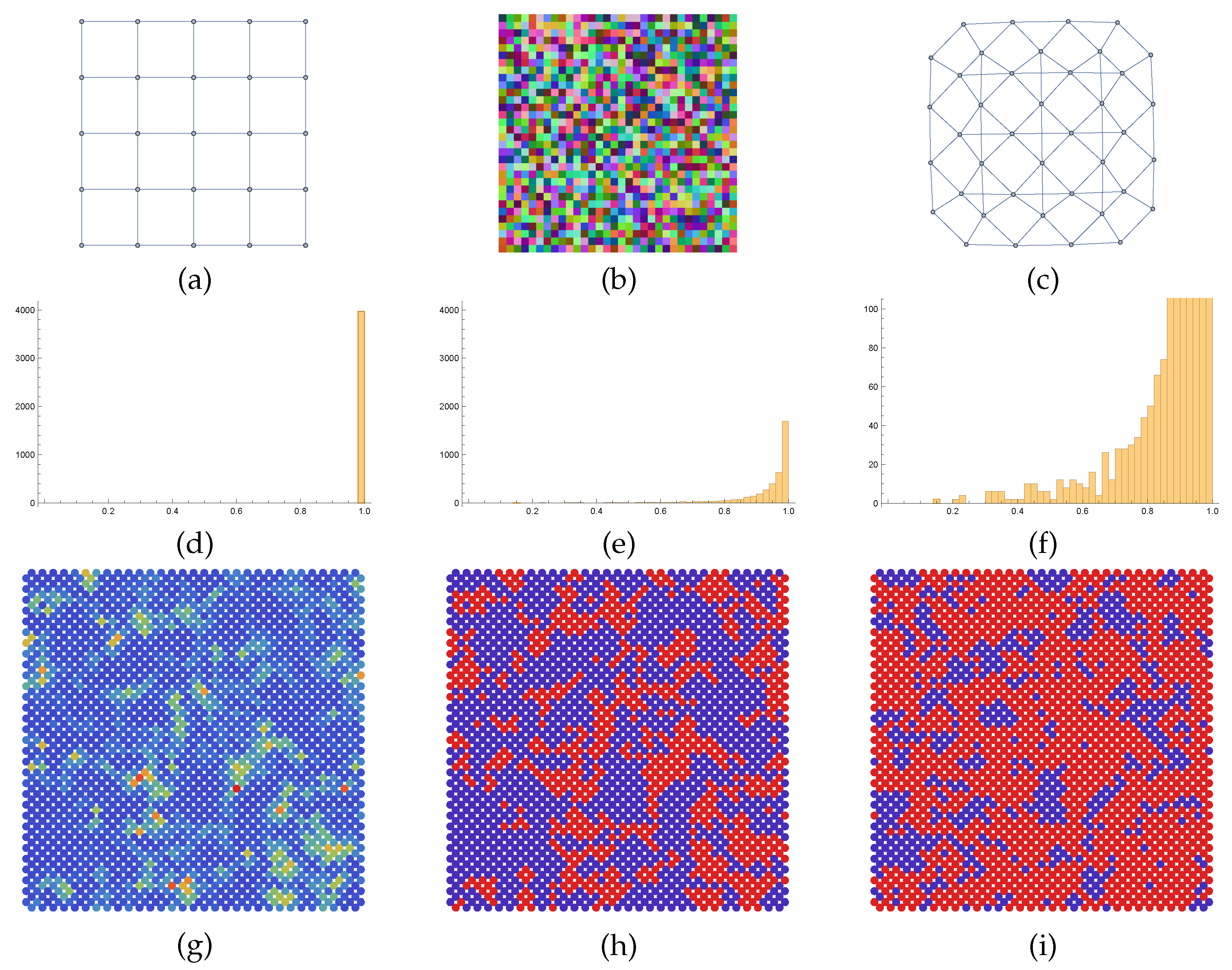
5.3. Basic Image Patch Smoothing
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proofs
Appendix A.1. Proofs of Section 2
Appendix A.2. Proofs of Section 3
Appendix A.3. Proofs of Section 4
- (b)
- Let and . Suppose that vector X is represented by a curve such that and . In view of the definition (123) of , we haveConsequently, if is a basis of that diagonalizes , then the tangent vector X is also diagonal in this basis , and X commutes with , i.e., and . This proves (b).
- (a)
- The bijection is explicitly given byThis is bijective according to the definition of . It remains to be shown that it is an isometry. Consider another tangent vector . We know that can all be diagonalized in a common eigenbasis. This basis is denoted again by . Then, we can writeand computeNote that the vector comes from . Therefore, the value must occur times in for every . This observation also holds for the vectors and . Thus, the sum above can be reduced towhere , and . Taking into account that and are the images of under the differential , we concludeThis proves part (a).
- (c)
- Part (c) is about the commutativity of the diagram.The horizontal arrows can be described as follows. Recall that . represents the dimensions of the images of the projectors . For a fixed , setThen, is given byDiagram (A128) commutes according to the definition of the maps.
- (i)
- Due to the commutativity of the components of , we can simplify the expression for the vector field of the QSAF as follows.Define such that all the components can be written asThen, we can further simplifyand, consequently,whereThus,This has to be compared with the general form of a tangent vector( given by (A120). The only condition the vector in (A120) has to satisfy is that its components sum to 0. This also holds for . We conclude that lies in for all or, equivalently, .
- (ii)
- We write for all with and express in terms of as
References
- Bakır, G.; Hofmann, T.; Schölkopf, B.; Smolar, A.J.; Taskar, B.; Vishwanathan, S.V.N. (Eds.) Predicting Structured Data; MIT Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Åström, F.; Petra, S.; Schmitzer, B.; Schnörr, C. Image Labeling by Assignment. J. Math. Imaging Vis. 2017, 58, 211–238. [Google Scholar] [CrossRef]
- Schnörr, C. Assignment Flows. In Variational Methods for Nonlinear Geometric Data and Applications; Grohs, P., Holler, M., Weinmann, A., Eds.; Springer: Berlin, Germany, 2020; pp. 235–260. [Google Scholar]
- Zern, A.; Zeilmann, A.; Schnörr, C. Assignment Flows for Data Labeling on Graphs: Convergence and Stability. Inf. Geom. 2022, 5, 355–404. [Google Scholar] [CrossRef]
- Hühnerbein, R.; Savarino, F.; Petra, S.; Schnörr, C. Learning Adaptive Regularization for Image Labeling Using Geometric Assignment. J. Math. Imaging Vis. 2021, 63, 186–215. [Google Scholar] [CrossRef]
- Sitenko, D.; Boll, B.; Schnörr, C. Assignment Flow For Order-Constrained OCT Segmentation. Int. J. Comput. Vis. 2021, 129, 3088–3118. [Google Scholar] [CrossRef]
- Hofbauer, J.; Siegmund, K. Evolutionary Game Dynamics. Bull. Am. Math. Soc. 2003, 40, 479–519. [Google Scholar] [CrossRef]
- Sandholm, W.H. Population Games and Evolutionary Dynamics; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Amari, S.-I.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RI, USA; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Zeilmann, A.; Savarino, F.; Petra, S.; Schnörr, C. Geometric Numerical Integration of the Assignment Flow. Inverse Probl. 2020, 36, 034004. [Google Scholar] [CrossRef]
- Sitenko, D.; Boll, B.; Schnörr, C. A Nonlocal Graph-PDE and Higher-Order Geometric Integration for Image Labeling. SIAM J. Imaging Sci. 2023, 16, 501–567. [Google Scholar] [CrossRef]
- Zern, A.; Zisler, M.; Petra, S.; Schnörr, C. Unsupervised Assignment Flow: Label Learning on Feature Manifolds by Spatially Regularized Geometric Assignment. J. Math. Imaging Vis. 2020, 62, 982–1006. [Google Scholar] [CrossRef]
- Zisler, M.; Zern, A.; Petra, S.; Schnörr, C. Self-Assignment Flows for Unsupervised Data Labeling on Graphs. SIAM J. Imaging Sci. 2020, 13, 113–1156. [Google Scholar] [CrossRef]
- Bengtsson, I.; Zyczkowski, K. Geometry of Quantum States: An Introduction to Quantum Entanglement, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Petz, D. Quantum Information Theory and Quantum Statistics; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Schwarz, J.; Boll, B.; Sitenko, D.; Gonzalez-Alvarado, D.; Gärttner, M.; Albers, P.; Schnörr, C. Quantum State Assignment Flows. In Scale Space and Variational Methods in Computer Vision; Calatroni, L., Donatelli, M., Morigi, S., Prato, M., Santacesaria, M., Eds.; Springer: Berlin, Germany; pp. 743–756.
- Amari, S.-I. Differential-Geometrical Methods in Statistics, 1990 ed.; Lecture Notes in Statistics; Springer: Berlin/Heidelberg, Germany, 1985; Volume 28. [Google Scholar]
- Lauritzen, S.L. Chapter 4: Statistical Manifolds. In Differential Geometry in Statistical Inference; Gupta, S.S., Amari, S.I., Barndorff-Nielsen, O.E., Kass, R.E., Lauritzen, S.L., Rao, C.R., Eds.; Institute of Mathematical Statistics: Hayward, CA, USA, 1987; pp. 163–216. [Google Scholar]
- Brown, L.D. Fundamentals of Statistical Exponential Families; Institute of Mathematical Statistics: Hayward, CA, USA, 1986. [Google Scholar]
- Čencov, N.N. Statistical Decision Rules and Optimal Inference; American Mathematical Society: Providence, RI, USA, 1981. [Google Scholar]
- Brazitikos, S.; Giannopoulos, A.; Valettas, P.; Vritsiou, B.-H. Geometry of Isotropic Convex Bodies; American Mathematical Society: Providence, RI, USA, 2014. [Google Scholar]
- Ay, N.; Jost, J.; Lê, H.V.; Schwachhöfer, L. Information Geometry; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Calin, O.; Udriste, C. Geometric Modeling in Probability and Statistics; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Petz, D. Geometry of Canonical Correlation on the State Space of a Quantum System. J. Math. Phys. 1994, 35, 780–795. [Google Scholar] [CrossRef]
- Bodmann, B.G.; Haas, J.I. A Short History of Frames and Quantum Designs. In Topological Phases of Matter and Quantum Computation; Contemporary Mathematics; American Mathematical Society: Providence, RI, USA, 2020; Volume 747, pp. 215–226. [Google Scholar]
- Petz, D.; Toth, G. The Bogoliubov Inner Product in Quantum Statistics. Lett. Math. Phys. 1993, 27, 205–216. [Google Scholar] [CrossRef]
- Grasselli, M.R.; Streater, R.F. On the Uniqueness of the Chentsov Metric in Quantum Information Geometry. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 2001, 4, 173–182. [Google Scholar] [CrossRef]
- Thanwerdas, Y.; Pennec, X. O(n)-invariant Riemannian Metrics on SPD Matrices. Linear Algebra Appl. 2023, 61, 163–201. [Google Scholar] [CrossRef]
- Bhatia, R. Positive Definite Matrices; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Skovgaard, L.T. A Riemannian Geometry of the Multivariate Normal Model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Bridson, M.R.; Häflinger, A. Metric Spaces of Non-Positive Curvature; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Jost, J. Riemannian Geometry and Geometric Analysis, 7th ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Geometric Means in a Novel Vector Space Structure on Symmetric Positive-Definite Matrices. SIAM J. Matrix Anal. Appl. 2007, 29, 328–347. [Google Scholar] [CrossRef]
- Michor, P.W.; Petz, D.; Andai, A. The Curvature of the Bogoliubov-Kubo-Mori Scalar Product on Matrices. Infin. Dimens. Anal. Quantum Probab. Relat. Top. 2000, 3, 1–14. [Google Scholar]
- Rockafellar, R. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 1970. [Google Scholar]
- Savarino, F.; Schnörr, C. Continuous-Domain Assignment Flows. Eur. J. Appl. Math. 2021, 32, 570–597. [Google Scholar] [CrossRef]
- Absil, P.A.; Mahony, R.; Sepulchre, R. Optimization Algorithms on Matrix Manifolds; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Higham, N.J. Functions of Matrices: Theory and Computation; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 2008. [Google Scholar]
- Savarino, F.; Albers, P.; Schnörr, C. On the Geometric Mechanics of Assignment Flows for Metric Data Labeling. arXiv (to appear in: Information Geometry). 2021, arXiv:2111.02543. [Google Scholar]
- Levine, Y.; Yakira, D.; Cohen, N.; Shashua, A. Deep Learning and Quantum Entanglement: Fundamental Connections with Implications to Network Design. In Proceedings of the Sixth International Conference on Learning Representations ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, R.T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D. Neural Ordinary Differential Equations. In Advances in Neural Information Processing Systems 31, Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis, 2nd ed.; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Kobayashi, S.; Nomizu, K. Foundations of Differential Geometry; Inderscience Publishers: New York, NY, USA; John Wiley & Sons: Hoboken, NJ, USA, 1969; Volume II. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Assignment Flow (AF) | Quantum State AF (QSAF) |
|---|---|
| Single-vertex AF (Section 3.1) | Single-vertex QSAF (Section 4.2) |
| AF approach (Section 3.2) | QSAF approach (Section 4.3) |
| Riemannian gradient AF (Section 3.3) | Riemannian gradient QSAF (Section 4.4) |
| Recovery of the AF from the QSAF by restriction (Section 4.5) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schwarz, J.; Cassel, J.; Boll, B.; Gärttner, M.; Albers, P.; Schnörr, C. Quantum State Assignment Flows. Entropy 2023, 25, 1253. https://doi.org/10.3390/e25091253
Schwarz J, Cassel J, Boll B, Gärttner M, Albers P, Schnörr C. Quantum State Assignment Flows. Entropy. 2023; 25(9):1253. https://doi.org/10.3390/e25091253
Chicago/Turabian StyleSchwarz, Jonathan, Jonas Cassel, Bastian Boll, Martin Gärttner, Peter Albers, and Christoph Schnörr. 2023. "Quantum State Assignment Flows" Entropy 25, no. 9: 1253. https://doi.org/10.3390/e25091253
APA StyleSchwarz, J., Cassel, J., Boll, B., Gärttner, M., Albers, P., & Schnörr, C. (2023). Quantum State Assignment Flows. Entropy, 25(9), 1253. https://doi.org/10.3390/e25091253