

On the Applicability of Quantum Machine Learning


Abstract
1. Introduction
- How do QKE and VQC algorithms compare to classical machine learning methods such as XGBoost, Ridge, Lasso, LightGBM, CatBoost, and MLP regarding accuracy and efficiency on simulated quantum circuits?
- To what extent can a randomized search to find a suitable set of hyperparameters make the performance of quantum machine learning algorithms comparable to classical approaches?
- What are the limitations and challenges associated with the current state of quantum machine learning, and how can future research address these challenges to unlock the full potential of quantum computing in machine learning applications?
- Do quantum machine learning algorithms outperform regular machine learning algorithms on datasets constrained by the rules of quantum mechanics? Thus, do they provide a quantum advantage for datasets that exhibit strong symmetry properties in terms of adhering to Lie algebras?
2. Related Work
3. Methodology
3.1. Supervised Machine Learning
3.2. Classical Supervised Machine Learning Techniques
- Lasso and Ridge Regression/Classification: Lasso (least absolute shrinkage and selection operator) and Ridge Regression are linear regression techniques that incorporate regularization to prevent overfitting and improve model generalization [11,12]. Lasso uses L1 regularization, which tends to produce sparse solutions, while Ridge Regression uses L2 regularization, which prevents coefficients from becoming too large.Both of these regression algorithms can also be used for classification tasks.
- Multilayer Perceptron: MLP is a type of feedforward artificial neural network with multiple layers of neurons, including input, hidden, and output layers [15]. MLPs are capable of modeling complex non-linear relationships and can be trained using backpropagation.
- Support Vector Machines (SVM): SVMs are supervised learning models used for classification and regression tasks [29]. They work by finding the optimal hyperplane that separates the data into different classes, maximizing the margin between the classes.
- Gradient Boosting Machines: Gradient boosting machines are an ensemble learning method that builds a series of weak learners, typically decision trees, to form a strong learner [30]. The weak learners are combined by iteratively adding them to the model while minimizing a loss function. Notable gradient boosting machines for classification tasks include XGBoost [10], CatBoost [14], and LightGBM [13]. These three algorithms have introduced various improvements and optimizations to the original gradient boosting framework, such as efficient tree learning algorithms, handling categorical features, and reducing memory usage.
3.3. Quantum Machine Learning
3.3.1. Variational Quantum Circuit (VQC)
- Preprocessing: The data are prepared and preprocessed before being encoded onto qubits.
- Feature map encoding (yellow in the figure): The preprocessed data are encoded onto qubits using a feature map.
- Variational quantum circuit (Ansatz) (steel-blue in the figure): The encoded data undergo processing through the variational quantum circuit, also known as the Ansatz, which consists of a series of quantum gates and operations.
- Measurement (orange in the figure): The final state of the qubits is measured, providing probabilities for the different quantum states.
- Parameter optimization (Optimizer): The variational quantum circuit is optimized by adjusting the parameters , such as the rotations of specific quantum gates, to improve the outcome/classification.
3.3.2. Quantum Kernel Estimator
- Data preprocessing: The input data are preprocessed, which may include tasks such as data cleaning, feature scaling, or feature extraction. This step ensures that the data are in an appropriate format for the following quantum feature maps.
- Feature map encoding (yellow in the figure): The preprocessed data are encoded onto qubits using a feature map.
- Kernel computation (steel-blue in the figure): Instead of directly computing the kernel matrix from the original data, a kernel function is precomputed using the quantum computing capabilities, meaning that the inner product of two quantum states is estimated on a quantum simulator/circuit. This kernel function captures the similarity between pairs of data points in a high-dimensional feature space.
- SVM training: The precomputed kernel function is then used as input to the SVM algorithm for model training. The SVM aims to find an optimal hyperplane that separates the data points into different classes with the maximum margin.

3.3.3. Qiskit Machine Learning
3.4. Accuracy Score for Classification
3.5. Datasets
- Iris Dataset: A widely known dataset consisting of 150 samples of iris flowers, each with four features (sepal length, sepal width, petal length, and petal width) and one of three species labels (Iris Setosa, Iris Versicolor, or Iris Virginica). This dataset is included in the Scikit-learn library [16].
- Wine Dataset: A popular dataset for wine classification, which consists of 178 samples of wine, each with 13 features (such as alcohol content, color intensity, and hue) and one of three class labels (class 1, class 2, or class 3). This dataset is also available in the Scikit-learn library [16].
- Indian Liver Patient Dataset (LPD): This dataset contains 583 records, with 416 liver patient records and 167 non-liver patient records [32]. The dataset includes ten variables: age, gender, total bilirubin, direct bilirubin, total proteins, albumin, A/G ratio, SGPT, SGOT, and Alkphos. The primary task is to classify patients into liver or non-liver patient groups.
- Breast Cancer Coimbra Dataset: This dataset consists of 10 quantitative predictors and a binary dependent variable, indicating the presence or absence of breast cancer [33,34]. The predictors are anthropometric data and parameters obtainable from routine blood analysis. Accurate prediction models based on these predictors can potentially serve as a biomarker for breast cancer.
- Teaching Assistant Evaluation Dataset: This dataset includes 151 instances of teaching-assistant (TA) assignments from the Statistics Department at the University of Wisconsin-Madison, with evaluations of their teaching performance over three regular semesters and two summer semesters [35,36]. The class variable is divided into three roughly equal-sized categories (“low”, “medium”, and “high”). There are six attributes, including whether the TA is a native English speaker, the course instructor, the course, the semester type (summer or regular), and the class size.
- Impedance Spectrum of Breast Tissue Dataset: This dataset contains impedance measurements of freshly excised breast tissue at the following frequencies: 15.625, 31.25, 62.5, 125, 250, 500, and 1000 KHz [37,38]. The primary task is to predict the classification of either the original six classes or four classes by merging the fibro-adenoma, mastopathy, and glandular classes whose discrimination is not crucial.
3.5.1. Data Obtained from Lie-Algebras
- The multiplication map defined by is smooth.
- The inversion map defined by is smooth.
4. Experimental Design
4.1. Artificially Generated Scikit Datasets
4.2. Artificially Generated SU(2) Datasets
4.3. Benchmark Datasets and Hyperparameter Optimization
5. Results
- numpy version: 1.18.5
- sklearn version: 0.23.1
- catboost version: 0.26.1
- xgboost version: 1.2.1
- lightgbm version: 3.2.1
- qiskit version: {‘qiskit-terra’: ‘0.19.2’, ‘qiskit-aer’: ‘0.10.3’, ‘qiskit-ignis’: ‘0.7.0’, ‘qiskit-ibmq-provider’: ‘0.18.3’, ‘qiskit-aqua’: None, ‘qiskit’: ‘0.34.2’, ‘qiskit-nature’: ‘0.3.1’, ‘qiskit-finance’: None, ‘qiskit-optimization’: None, ‘qiskit-machine-learning’: ‘0.3.1’}
- qiskit_machine_learning version: 0.3.1
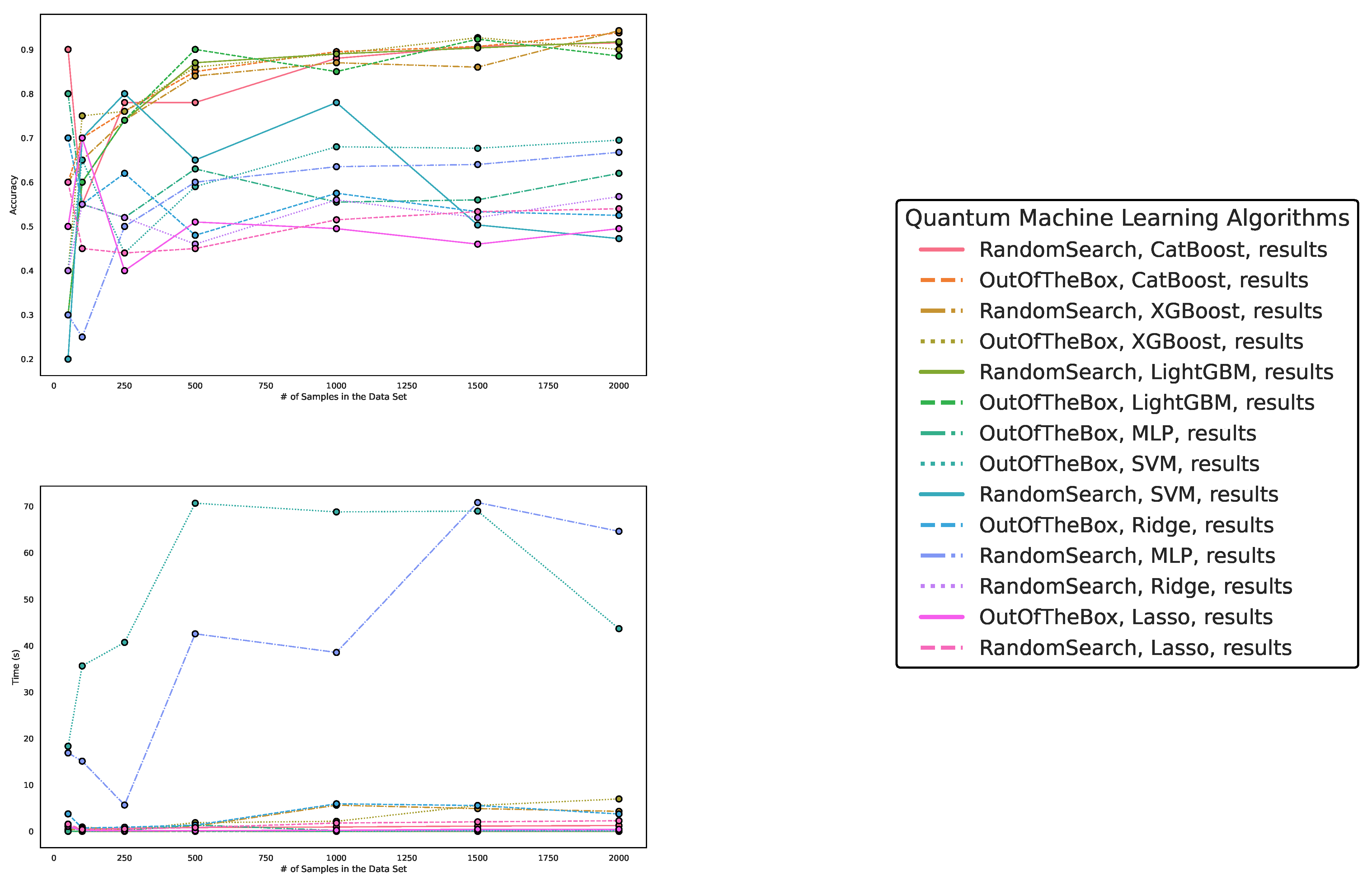
5.1. Performance on Artificially Generated Scikit Datasets
5.2. Performance on Artificially Generated SU2 Datasets
5.3. Results on Benchmark Datasets
5.4. Comparison and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Parametrization
Appendix A.1. Ridge
Appendix A.2. Lasso
Appendix A.3. SVM
Appendix A.4. MLP
Appendix A.5. XGBoost
Appendix A.6. LightGBM
Appendix A.7. CatBoost
Appendix A.8. QKE
Appendix A.9. VQC
References
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information: 10th Anniversary Edition, 10th ed.; Cambridge University Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. An introduction to quantum machine learning. Contemp. Phys. 2015, 56, 172–185. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef] [PubMed]
- Cerezo, M.; Arrasmith, A.; Babbush, R.; Benjamin, S.C.; Endo, S.; Fujii, K.; McClean, J.R.; Mitarai, K.; Yuan, X.; Cincio, L.; et al. Variational quantum algorithms. Nat. Rev. Phys. 2021, 3, 625–644. [Google Scholar] [CrossRef]
- Griol-Barres, I.; Milla, S.; Cebrián, A.; Mansoori, Y.; Millet, J. Variational Quantum Circuits for Machine Learning. An Application for the Detection of Weak Signals. Appl. Sci. 2021, 11, 6427. [Google Scholar] [CrossRef]
- Kuppusamy, P.; Yaswanth Kumar, N.; Dontireddy, J.; Iwendi, C. Quantum Computing and Quantum Machine Learning Classification—A Survey. In Proceedings of the 2022 IEEE 4th International Conference on Cybernetics, Cognition and Machine Learning Applications (ICCCMLA), Goa, India, 8–9 October 2022; pp. 200–204. [Google Scholar] [CrossRef]
- Blance, A.; Spannowsky, M. Quantum machine learning for particle physics using a variational quantum classifier. J. High Energy Phys. 2021, 2021, 212. [Google Scholar] [CrossRef]
- Abohashima, Z.; Elhoseny, M.; Houssein, E.H.; Mohamed, W.M. Classification with Quantum Machine Learning: A Survey. arXiv 2020, arXiv:2006.12270. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, Montréal, ON, Canada, 2–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 6639–6649. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical report; California Univ San Diego La Jolla Inst for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 282–290. [Google Scholar]
- Raubitzek, S. Quantum_Machine_Learning. Preprints 2023, 2023050833. [Google Scholar] [CrossRef]
- Zeguendry, A.; Jarir, Z.; Quafafou, M. Quantum Machine Learning: A Review and Case Studies. Entropy 2023, 25, 287. [Google Scholar] [CrossRef]
- Mitarai, K.; Negoro, M.; Kitagawa, M.; Fujii, K. Quantum circuit learning. Phys. Rev. A 2018, 98, 032309. [Google Scholar] [CrossRef]
- Farhi, E.; Neven, H. Classification with quantum neural networks on near term processors. arXiv 2018, arXiv:1802.06002. [Google Scholar]
- Rebentrost, P.; Mohseni, M.; Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 2014, 113, 130503. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Rebentrost, P. Quantum machine learning for quantum anomaly detection. Phys. Rev. A 2019, 100, 042328. [Google Scholar] [CrossRef]
- Broughton, M.; Verdon, G.; McCourt, T.; Martinez, A.J.; Yoo, J.H.; Isakov, S.V.; King, A.D.; Smelyanskiy, V.N.; Neven, H. TensorFlow Quantum: A Software Framework for Quantum Machine Learning. arXiv 2020, arXiv:2003.02989. [Google Scholar]
- Qiskit Contributors. Qiskit: An Open-source Framework for Quantum Computing. Zenodo 2023. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. In Proceedings of the 2007 Conference on Emerging Artificial Intelligence Applications in Computer Engineering: Real Word AI Systems with Applications in EHealth, HCI, Information Retrieval and Pervasive Technologies; IOS Press: Amsterdam, The Netherlands, 2007; pp. 3–24. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., ÖZSU, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Schuld, M.; Killoran, N. Quantum Machine Learning in Feature Hilbert Spaces. Phys. Rev. Lett. 2019, 122, 040504. [Google Scholar] [CrossRef]
- Ramana, B.V.; Babu, M.S.P.; Venkateswarlu, N.B. LPD (Indian Liver Patient Dataset) Data Set. 2012. Available online: https://archive.ics.uci.edu/ml/datasets/ILPD+(Indian+Liver+Patient+Dataset) (accessed on 25 June 2023).
- Patrício, M.; Pereira, J.; Crisóstomo, J.; Matafome, P.; Gomes, M.; Seiça, R.; Caramelo, F. Using Resistin, glucose, age and BMI to predict the presence of breast cancer. BMC Cancer 2018, 18, 29. [Google Scholar] [CrossRef] [PubMed]
- Crisóstomo, J.; Matafome, P.; Santos-Silva, D.; Gomes, A.L.; Gomes, M.; Patrício, M.; Letra, L.; Sarmento-Ribeiro, A.B.; Santos, L.; Seiça, R. Hyperresistinemia and metabolic dysregulation: A risky crosstalk in obese breast cancer. Endocrine 2016, 53, 433–442. [Google Scholar] [CrossRef] [PubMed]
- Loh, W.Y.; Shih, Y.S. Split selection methods for classification trees. Stat. Sin. 1997, 7, 815–840. [Google Scholar]
- Lim, T.S.; Loh, W.Y.; Shih, Y.S. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Mach. Learn. 2000, 40, 203–228. [Google Scholar] [CrossRef]
- Marques de Sá, J.; Jossinet, J. Breast Tissue Impedance Data Set. 2002. Available online: https://archive.ics.uci.edu/ml/datasets/Breast+Tissue (accessed on 25 June 2023).
- Estrela da Silva, J.; Marques de Sá, J.P.; Jossinet, J. Classification of breast tissue by electrical impedance spectroscopy. Med. Biol. Eng. Comput. 2000, 38, 26–30. [Google Scholar] [CrossRef] [PubMed]
- Georgi, H. Lie Algebras in Particle Physics: From Isospin to Unified Theories; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar] [CrossRef]
- Schuld, M.; Petruccione, F. Quantum ensembles of quantum classifiers. Sci. Rep. 2018, 8, 2772. [Google Scholar] [CrossRef]
- Moiseyev, N. Non-Hermitian Quantum Mechanics; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm/Parametrization | Size 50 | Size 100 | Size 250 | Size 500 | Size 1000 | Size 1500 | Size 2000 | Average |
|---|---|---|---|---|---|---|---|---|
| OutOfTheBox, CatBoost, results | 1.0 | 1.0 | 0.98 | 0.97 | 0.925 | 0.93 | 0.9425 | 0.963929 |
| RandomSearch, CatBoost, results | 1.0 | 1.0 | 0.96 | 0.96 | 0.935 | 0.936667 | 0.9425 | 0.962024 |
| RandomSearch, SVM, results | 1.0 | 1.0 | 0.94 | 0.96 | 0.945 | 0.93 | 0.9375 | 0.958929 |
| RandomSearch, XGBoost, results | 1.0 | 0.95 | 0.98 | 0.96 | 0.93 | 0.933333 | 0.9425 | 0.956548 |
| QKE, PauliFeatureMap, statevector-simulator, 1000.0 | 1.0 | 1.0 | 0.96 | 0.93 | 0.93 | 0.93 | 0.925 | 0.953571 |
| OutOfTheBox, XGBoost, results | 1.0 | 0.95 | 0.94 | 0.96 | 0.91 | 0.936667 | 0.95 | 0.949524 |
| OutOfTheBox, SVM, results | 1.0 | 1.0 | 0.92 | 0.92 | 0.94 | 0.933333 | 0.93 | 0.949048 |
| QKE, ZZFeatureMap, statevector-simulator, 177.82794100389228 | 1.0 | 1.0 | 0.94 | 0.93 | 0.915 | 0.926667 | 0.9225 | 0.947738 |
| QKE, ZFeatureMap, statevector-simulator, 5.623413251903491 | 1.0 | 1.0 | 0.92 | 0.91 | 0.925 | 0.93 | 0.9375 | 0.946071 |
| RandomSearch, MLP, results | 1.0 | 1.0 | 0.94 | 0.88 | 0.905 | 0.933333 | 0.94 | 0.942619 |
| OutOfTheBox, MLP, results | 1.0 | 1.0 | 0.94 | 0.89 | 0.905 | 0.916667 | 0.9275 | 0.939881 |
| OutOfTheBox, Ridge, results | 1.0 | 1.0 | 0.94 | 0.88 | 0.9 | 0.896667 | 0.9025 | 0.93131 |
| QKE, ZFeatureMap, qasm-simulator, 5.623413251903491 | 1.0 | 1.0 | 0.94 | 0.82 | 0.91 | 0.92 | 0.9025 | 0.9275 |
| QKE, ZZFeatureMap, statevector-simulator, 31.622776601683793 | 1.0 | 0.95 | 0.92 | 0.88 | 0.88 | 0.926667 | 0.9175 | 0.924881 |
| QKE, PauliFeatureMap, statevector-simulator, 5.623413251903491 | 1.0 | 0.95 | 0.92 | 0.85 | 0.895 | 0.93 | 0.92 | 0.923571 |
| QKE, ZFeatureMap, statevector-simulator, 0.1778279410038923 | 1.0 | 0.95 | 0.9 | 0.88 | 0.9 | 0.92 | 0.9125 | 0.923214 |
| QKE, ZFeatureMap, aer-simulator, 0.1778279410038923 | 1.0 | 0.95 | 0.9 | 0.87 | 0.905 | 0.92 | 0.9125 | 0.9225 |
| RandomSearch, Ridge, results | 1.0 | 1.0 | 0.9 | 0.88 | 0.88 | 0.893333 | 0.9025 | 0.922262 |
| QKE, ZZFeatureMap, qasm-simulator, 5.623413251903491 | 1.0 | 0.95 | 0.92 | 0.86 | 0.89 | 0.91 | 0.9175 | 0.921071 |
| QKE, PauliFeatureMap, qasm-simulator, 5.623413251903491 | 1.0 | 0.95 | 0.92 | 0.86 | 0.89 | 0.91 | 0.9175 | 0.921071 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, statevector-simulator | 1.0 | 0.95 | 0.9 | 0.9 | 0.92 | 0.893333 | 0.88 | 0.920476 |
| RandomSearch, Lasso, results | 1.0 | 1.0 | 0.94 | 0.82 | 0.895 | 0.893333 | 0.89 | 0.919762 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, qasm-simulator | 1.0 | 0.95 | 0.9 | 0.88 | 0.92 | 0.91 | 0.845 | 0.915 |
| QKE, PauliFeatureMap, aer-simulator, 1.0 | 0.9 | 0.95 | 0.92 | 0.89 | 0.89 | 0.93 | 0.91 | 0.912857 |
| VQC, ZFeatureMap, EfficientSU2, SPSA, qasm-simulator | 1.0 | 0.95 | 0.9 | 0.86 | 0.925 | 0.91 | 0.845 | 0.912857 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, aer-simulator | 1.0 | 0.95 | 0.92 | 0.88 | 0.9 | 0.906667 | 0.8275 | 0.912024 |
| VQC, ZFeatureMap, EfficientSU2, SPSA, statevector-simulator | 1.0 | 0.95 | 0.92 | 0.87 | 0.89 | 0.89 | 0.835 | 0.907857 |
| VQC, ZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 1.0 | 0.95 | 0.9 | 0.86 | 0.905 | 0.85 | 0.865 | 0.904286 |
| RandomSearch, LightGBM, results | 0.4 | 1.0 | 0.98 | 0.95 | 0.93 | 0.933333 | 0.9475 | 0.877262 |
| OutOfTheBox, LightGBM, results | 0.4 | 1.0 | 0.96 | 0.94 | 0.925 | 0.936667 | 0.9375 | 0.87131 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, qasm-simulator | 0.9 | 0.75 | 0.9 | 0.84 | 0.89 | 0.86 | 0.8675 | 0.858214 |
| VQC, ZFeatureMap, EfficientSU2, NFT, statevector-simulator | 1.0 | 0.95 | 0.86 | 0.72 | 0.9 | 0.776667 | 0.77 | 0.85381 |
| QKE, PauliFeatureMap, aer-simulator, 31.622776601683793 | 1.0 | 0.85 | 0.96 | 0.7 | 0.875 | 0.826667 | 0.735 | 0.849524 |
| QKE, ZFeatureMap, aer-simulator, 31.622776601683793 | 1.0 | 1.0 | 0.88 | 0.62 | 0.835 | 0.736667 | 0.7475 | 0.83131 |
| QKE, PauliFeatureMap, aer-simulator, 1000.0 | 1.0 | 0.85 | 0.96 | 0.58 | 0.87 | 0.826667 | 0.665 | 0.821667 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, aer-simulator | 0.8 | 0.75 | 0.9 | 0.73 | 0.845 | 0.86 | 0.8525 | 0.819643 |
| VQC, PauliFeatureMap, EfficientSU2, NFT, statevector-simulator | 0.8 | 0.65 | 0.9 | 0.8 | 0.84 | 0.783333 | 0.8475 | 0.802976 |
| QKE, ZFeatureMap, qasm-simulator, 177.82794100389228 | 0.9 | 1.0 | 0.88 | 0.57 | 0.875 | 0.73 | 0.6375 | 0.798929 |
| VQC, ZZFeatureMap, EfficientSU2, COBYLA, aer-simulator | 0.7 | 0.7 | 0.9 | 0.71 | 0.82 | 0.826667 | 0.835 | 0.784524 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, qasm-simulator | 0.8 | 0.7 | 0.9 | 0.62 | 0.775 | 0.816667 | 0.785 | 0.770952 |
| VQC, ZZFeatureMap, RealAmplitudes, NFT, qasm-simulator | 0.7 | 0.7 | 0.9 | 0.86 | 0.775 | 0.786667 | 0.535 | 0.750952 |
| VQC, PauliFeatureMap, RealAmplitudes, NFT, qasm-simulator | 0.6 | 0.7 | 0.9 | 0.49 | 0.8 | 0.763333 | 0.78 | 0.719048 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 0.5 | 0.65 | 0.84 | 0.73 | 0.83 | 0.83 | 0.575 | 0.707857 |
| QKE, PauliFeatureMap, aer-simulator, 0.03162277660168379 | 0.4 | 0.35 | 0.9 | 0.65 | 0.86 | 0.923333 | 0.8275 | 0.701548 |
| QKE, PauliFeatureMap, aer-simulator, 0.005623413251903491 | 0.4 | 0.35 | 0.9 | 0.49 | 0.75 | 0.766667 | 0.8275 | 0.640595 |
| QKE, PauliFeatureMap, qasm-simulator, 0.005623413251903491 | 0.4 | 0.35 | 0.9 | 0.49 | 0.75 | 0.766667 | 0.8275 | 0.640595 |
| QKE, ZFeatureMap, statevector-simulator, 0.005623413251903491 | 0.4 | 0.35 | 0.84 | 0.49 | 0.63 | 0.85 | 0.83 | 0.627143 |
| VQC, ZFeatureMap, TwoLocal, SPSA, statevector-simulator | 0.7 | 0.65 | 0.52 | 0.51 | 0.52 | 0.493333 | 0.58 | 0.567619 |
| QKE, PauliFeatureMap, qasm-simulator, 0.001 | 0.4 | 0.35 | 0.9 | 0.49 | 0.48 | 0.753333 | 0.4975 | 0.552976 |
| OutOfTheBox, Lasso, results | 0.4 | 0.35 | 0.5 | 0.49 | 0.48 | 0.506667 | 0.4975 | 0.460595 |
| VQC, ZZFeatureMap, TwoLocal, COBYLA, qasm-simulator | 0.2 | 0.35 | 0.28 | 0.35 | 0.225 | 0.216667 | 0.3975 | 0.288452 |
| VQC, PauliFeatureMap, TwoLocal, SPSA, qasm-simulator | 0.2 | 0.35 | 0.26 | 0.38 | 0.185 | 0.223333 | 0.4 | 0.285476 |
| VQC, PauliFeatureMap, TwoLocal, COBYLA, statevector-simulator | 0.2 | 0.35 | 0.28 | 0.36 | 0.19 | 0.223333 | 0.39 | 0.284762 |
| VQC, PauliFeatureMap, TwoLocal, SPSA, statevector-simulator | 0.2 | 0.35 | 0.28 | 0.36 | 0.19 | 0.223333 | 0.39 | 0.284762 |
| Algorithm/Parametrization | Size 50 | Size 100 | Size 250 | Size 500 | Size 1000 | Size 1500 | Size 2000 | Average |
|---|---|---|---|---|---|---|---|---|
| OutOfTheBox, Lasso, results | 0.001473 | 0.001162 | 0.001158 | 0.001123 | 0.001141 | 0.001153 | 0.001159 | 0.001196 |
| OutOfTheBox, Ridge, results | 0.002933 | 0.001553 | 0.001433 | 0.001894 | 0.002628 | 0.002575 | 0.002436 | 0.002207 |
| OutOfTheBox, SVM, results | 0.001021 | 0.000648 | 0.001039 | 0.002457 | 0.005501 | 0.017243 | 0.0295 | 0.008201 |
| OutOfTheBox, XGBoost, results | 0.016881 | 0.017187 | 0.022922 | 0.038751 | 0.05111 | 0.151807 | 0.120973 | 0.059947 |
| OutOfTheBox, LightGBM, results | 0.009655 | 0.024887 | 0.104107 | 0.124862 | 0.1898 | 0.489043 | 0.218343 | 0.165814 |
| RandomSearch, Lasso, results | 1.045328 | 0.113413 | 0.102258 | 0.105736 | 0.104031 | 0.120507 | 0.116006 | 0.243897 |
| RandomSearch, Ridge, results | 1.120708 | 0.122188 | 0.114706 | 0.175996 | 0.226949 | 0.255845 | 0.25067 | 0.323866 |
| RandomSearch, SVM, results | 1.06376 | 0.135593 | 0.163875 | 0.159699 | 0.203163 | 0.354172 | 0.442741 | 0.360429 |
| OutOfTheBox, MLP, results | 0.082953 | 0.091169 | 0.121317 | 0.232771 | 0.451674 | 0.947373 | 1.376965 | 0.472032 |
| OutOfTheBox, CatBoost, results | 0.389826 | 0.411965 | 0.654325 | 0.783825 | 0.867595 | 1.085298 | 1.1931 | 0.769419 |
| RandomSearch, LightGBM, results | 1.711872 | 0.376494 | 0.58387 | 0.704715 | 0.728305 | 0.897428 | 1.000039 | 0.857532 |
| RandomSearch, XGBoost, results | 1.572541 | 0.399174 | 0.441059 | 0.577969 | 0.99776 | 1.467667 | 1.352474 | 0.972663 |
| VQC, ZFeatureMap, TwoLocal, SPSA, statevector-simulator | 0.502447 | 0.82391 | 1.319602 | 2.9078 | 6.75953 | 11.81601 | 18.064725 | 6.027718 |
| VQC, PauliFeatureMap, TwoLocal, COBYLA, statevector-simulator | 0.536454 | 0.886945 | 1.757877 | 3.486975 | 8.137821 | 14.688881 | 22.79476 | 7.469959 |
| VQC, PauliFeatureMap, TwoLocal, SPSA, statevector-simulator | 1.981785 | 0.715829 | 1.621059 | 3.488372 | 8.517624 | 15.170185 | 22.300972 | 7.685118 |
| VQC, PauliFeatureMap, TwoLocal, SPSA, qasm-simulator | 0.750719 | 1.154406 | 2.53449 | 5.000262 | 11.265137 | 19.493945 | 29.031463 | 9.89006 |
| VQC, ZZFeatureMap, TwoLocal, COBYLA, qasm-simulator | 0.734865 | 1.097202 | 2.514703 | 4.990832 | 11.895971 | 19.283406 | 29.318269 | 9.976464 |
| RandomSearch, MLP, results | 3.899634 | 3.298337 | 5.003618 | 9.651274 | 14.729924 | 20.652249 | 31.202069 | 12.633872 |
| QKE, ZFeatureMap, statevector-simulator, 0.1778279410038923 | 1.343983 | 0.802286 | 2.170829 | 5.965899 | 18.504546 | 36.659922 | 59.889941 | 17.905344 |
| QKE, ZFeatureMap, statevector-simulator, 0.005623413251903491 | 0.411296 | 0.697461 | 2.154164 | 6.122564 | 19.670819 | 37.297334 | 62.1901 | 18.363391 |
| QKE, PauliFeatureMap, statevector-simulator, 1000.0 | 0.470933 | 0.956269 | 2.721257 | 7.2817 | 21.356298 | 40.130716 | 67.422908 | 20.048583 |
| QKE, PauliFeatureMap, statevector-simulator, 5.623413251903491 | 0.501446 | 0.922237 | 2.775664 | 7.454642 | 21.780637 | 40.426036 | 66.758927 | 20.088513 |
| QKE, ZFeatureMap, statevector-simulator, 5.623413251903491 | 0.378018 | 0.757363 | 2.141677 | 4.962464 | 19.901565 | 41.913003 | 71.453831 | 20.215417 |
| QKE, ZZFeatureMap, statevector-simulator, 31.622776601683793 | 0.214386 | 0.567282 | 1.650304 | 5.302437 | 20.77629 | 42.614517 | 72.871078 | 20.570899 |
| QKE, ZZFeatureMap, statevector-simulator, 177.82794100389228 | 0.461093 | 0.943574 | 2.780804 | 7.580857 | 22.906811 | 41.955521 | 68.045553 | 20.667745 |
| RandomSearch, CatBoost, results | 8.627878 | 10.873142 | 26.728395 | 35.20857 | 36.902272 | 56.253265 | 37.994929 | 30.369779 |
| VQC, ZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 47.438183 | 63.446748 | 192.148143 | 404.233954 | 1060.291657 | 1619.397205 | 2290.222381 | 811.025467 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, qasm-simulator | 43.113636 | 83.175558 | 166.040938 | 421.278374 | 1064.238564 | 1702.893006 | 2719.340939 | 885.725859 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 45.909504 | 83.201411 | 152.20265 | 509.1956 | 1158.902532 | 1654.065907 | 2603.942577 | 886.774312 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, statevector-simulator | 48.546243 | 81.030425 | 190.958188 | 402.121722 | 1044.855825 | 1807.676357 | 2751.241623 | 903.775769 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, aer-simulator | 57.728111 | 100.590997 | 240.174666 | 507.58709 | 1253.080578 | 2139.855218 | 3196.07247 | 1070.727019 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, qasm-simulator | 59.058898 | 100.862056 | 242.285405 | 507.171731 | 1262.650143 | 2151.503499 | 3191.745568 | 1073.611043 |
| VQC, ZZFeatureMap, EfficientSU2, COBYLA, aer-simulator | 59.651649 | 105.629842 | 254.918442 | 601.245125 | 1335.017904 | 2260.354294 | 3366.65501 | 1140.496038 |
| QKE, ZFeatureMap, qasm-simulator, 177.82794100389228 | 4.589478 | 13.184805 | 82.633779 | 332.71327 | 1337.102907 | 3020.689579 | 5368.201509 | 1451.30219 |
| QKE, ZZFeatureMap, qasm-simulator, 5.623413251903491 | 4.352785 | 15.921249 | 97.165028 | 390.472092 | 1573.103197 | 3549.629798 | 6282.670251 | 1701.902057 |
| QKE, PauliFeatureMap, aer-simulator, 0.03162277660168379 | 3.549125 | 15.094144 | 98.970568 | 393.496921 | 1581.662241 | 3554.962927 | 6317.355669 | 1709.298799 |
| QKE, PauliFeatureMap, aer-simulator, 0.005623413251903491 | 3.373257 | 15.311538 | 99.2351 | 390.52131 | 1574.108371 | 3555.3048 | 6339.026443 | 1710.982974 |
| QKE, PauliFeatureMap, qasm-simulator, 0.005623413251903491 | 3.812115 | 19.479307 | 101.289711 | 404.432384 | 1636.24686 | 3642.937393 | 6307.605039 | 1730.828973 |
| QKE, PauliFeatureMap, aer-simulator, 31.622776601683793 | 3.848578 | 17.062982 | 101.387533 | 408.69903 | 1635.863136 | 3674.976257 | 6555.811507 | 1771.092718 |
| VQC, ZFeatureMap, EfficientSU2, NFT, statevector-simulator | 98.831974 | 167.48274 | 394.378037 | 836.913451 | 2197.652135 | 3719.047116 | 5621.134708 | 1862.205737 |
| VQC, PauliFeatureMap, EfficientSU2, NFT, statevector-simulator | 103.914165 | 177.047181 | 423.423603 | 1014.963511 | 2338.078356 | 3953.861723 | 5905.433094 | 1988.10309 |
| VQC, ZZFeatureMap, RealAmplitudes, NFT, qasm-simulator | 105.987181 | 183.918751 | 427.016702 | 1036.605473 | 2366.463152 | 4052.521035 | 6042.538015 | 2030.721473 |
| VQC, PauliFeatureMap, RealAmplitudes, NFT, qasm-simulator | 103.625823 | 180.306618 | 425.488049 | 1041.160999 | 2371.366715 | 4044.856475 | 6048.573929 | 2030.768373 |
| VQC, ZFeatureMap, EfficientSU2, SPSA, statevector-simulator | 119.513477 | 200.101417 | 474.113288 | 1008.932874 | 2601.731917 | 4505.306268 | 6781.089745 | 2241.541284 |
| VQC, ZFeatureMap, EfficientSU2, SPSA, qasm-simulator | 145.295744 | 256.711762 | 609.791229 | 1272.675059 | 3150.527537 | 5366.116602 | 8009.649075 | 2687.25243 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, aer-simulator | 144.280811 | 259.102175 | 625.193096 | 1502.476923 | 3356.340799 | 5689.827615 | 8454.144295 | 2861.623673 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, qasm-simulator | 152.666649 | 269.680847 | 642.400747 | 1505.762521 | 3388.662998 | 5709.505826 | 8438.957709 | 2872.519614 |
| QKE, ZFeatureMap, aer-simulator, 31.622776601683793 | 5.993241 | 25.852654 | 166.703792 | 669.201309 | 2934.169598 | 6729.31411 | 12,037.430687 | 3224.095056 |
| QKE, PauliFeatureMap, qasm-simulator, 5.623413251903491 | 8.384715 | 32.795287 | 206.595473 | 890.414904 | 3753.488868 | 8537.768589 | 15,232.745542 | 4094.599054 |
| QKE, PauliFeatureMap, qasm-simulator, 0.001 | 7.792093 | 32.566225 | 207.832614 | 896.042249 | 3778.324351 | 8610.335147 | 15,348.810142 | 4125.957546 |
| QKE, ZFeatureMap, aer-simulator, 0.1778279410038923 | 10.511296 | 43.335078 | 276.810734 | 1111.545614 | 4799.032996 | 10,979.135601 | 19,768.073574 | 5284.063556 |
| QKE, ZFeatureMap, qasm-simulator, 5.623413251903491 | 11.573929 | 43.186982 | 277.291314 | 1113.664313 | 4842.587094 | 10,978.908476 | 19,798.821156 | 5295.147609 |
| QKE, PauliFeatureMap, aer-simulator, 1000.0 | 12.596938 | 51.788837 | 332.281104 | 1434.208601 | 5986.631006 | 13,592.866065 | 24,280.544075 | 6527.273804 |
| QKE, PauliFeatureMap, aer-simulator, 1.0 | 12.261604 | 51.508959 | 332.561822 | 1423.111135 | 5984.902587 | 13,603.956887 | 24,362.83202 | 6538.733573 |
| Algorithm/Parametrization | Size 50 | Size 100 | Size 250 | Size 500 | Size 1000 | Size 1500 | Size 2000 | Average |
|---|---|---|---|---|---|---|---|---|
| RandomSearch, CatBoost, results | 0.9 | 0.55 | 0.78 | 0.78 | 0.88 | 0.906667 | 0.915 | 0.815952 |
| OutOfTheBox, CatBoost, results | 0.6 | 0.7 | 0.76 | 0.85 | 0.895 | 0.906667 | 0.9375 | 0.807024 |
| RandomSearch, XGBoost, results | 0.6 | 0.65 | 0.74 | 0.84 | 0.87 | 0.86 | 0.9425 | 0.786071 |
| OutOfTheBox, XGBoost, results | 0.4 | 0.75 | 0.76 | 0.86 | 0.89 | 0.926667 | 0.9 | 0.78381 |
| QKE, ZFeatureMap, statevector-simulator, 1000.0 | 0.7 | 0.8 | 0.74 | 0.79 | 0.8 | 0.806667 | 0.8475 | 0.783452 |
| RandomSearch, LightGBM, results | 0.3 | 0.6 | 0.74 | 0.87 | 0.89 | 0.903333 | 0.9175 | 0.745833 |
| OutOfTheBox, LightGBM, results | 0.3 | 0.6 | 0.74 | 0.9 | 0.85 | 0.923333 | 0.885 | 0.742619 |
| QKE, ZZFeatureMap, statevector-simulator, 177.82794100389228 | 0.8 | 0.55 | 0.54 | 0.71 | 0.795 | 0.826667 | 0.85 | 0.724524 |
| QKE, PauliFeatureMap, aer-simulator, 5.623413251903491 | 0.7 | 0.65 | 0.44 | 0.73 | 0.725 | 0.683333 | 0.72 | 0.664048 |
| QKE, ZZFeatureMap, qasm-simulator, 31.622776601683793 | 0.7 | 0.7 | 0.7 | 0.59 | 0.615 | 0.62 | 0.665 | 0.655714 |
| QKE, ZZFeatureMap, statevector-simulator, 0.1778279410038923 | 0.8 | 0.5 | 0.62 | 0.55 | 0.645 | 0.693333 | 0.7375 | 0.649405 |
| QKE, ZZFeatureMap, aer-simulator, 0.1778279410038923 | 0.4 | 0.6 | 0.7 | 0.67 | 0.625 | 0.713333 | 0.7075 | 0.630833 |
| QKE, PauliFeatureMap, aer-simulator, 0.1778279410038923 | 0.5 | 0.65 | 0.64 | 0.63 | 0.615 | 0.68 | 0.7 | 0.630714 |
| QKE, PauliFeatureMap, statevector-simulator, 0.1778279410038923 | 0.4 | 0.65 | 0.6 | 0.55 | 0.75 | 0.666667 | 0.73 | 0.620952 |
| OutOfTheBox, MLP, results | 0.8 | 0.55 | 0.52 | 0.63 | 0.555 | 0.56 | 0.62 | 0.605 |
| VQC, ZZFeatureMap, EfficientSU2, SPSA, aer-simulator | 0.7 | 0.5 | 0.6 | 0.6 | 0.605 | 0.576667 | 0.645 | 0.60381 |
| VQC, ZZFeatureMap, EfficientSU2, COBYLA, qasm-simulator | 0.6 | 0.6 | 0.62 | 0.54 | 0.6 | 0.606667 | 0.66 | 0.60381 |
| OutOfTheBox, SVM, results | 0.4 | 0.65 | 0.44 | 0.59 | 0.68 | 0.676667 | 0.695 | 0.590238 |
| RandomSearch, SVM, results | 0.2 | 0.7 | 0.8 | 0.65 | 0.78 | 0.503333 | 0.4725 | 0.586548 |
| VQC, ZZFeatureMap, EfficientSU2, NFT, statevector-simulator | 0.5 | 0.6 | 0.54 | 0.56 | 0.7 | 0.58 | 0.61 | 0.584286 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, statevector-simulator | 0.6 | 0.65 | 0.6 | 0.53 | 0.575 | 0.543333 | 0.5775 | 0.582262 |
| VQC, PauliFeatureMap, EfficientSU2, COBYLA, aer-simulator | 0.4 | 0.75 | 0.52 | 0.55 | 0.56 | 0.606667 | 0.6225 | 0.572738 |
| VQC, PauliFeatureMap, RealAmplitudes, NFT, statevector-simulator | 0.3 | 0.65 | 0.52 | 0.69 | 0.63 | 0.586667 | 0.62 | 0.570952 |
| OutOfTheBox, Ridge, results | 0.7 | 0.55 | 0.62 | 0.48 | 0.575 | 0.533333 | 0.525 | 0.569048 |
| VQC, ZFeatureMap, RealAmplitudes, COBYLA, qasm-simulator | 0.7 | 0.5 | 0.52 | 0.57 | 0.59 | 0.573333 | 0.5275 | 0.56869 |
| VQC, ZZFeatureMap, EfficientSU2, NFT, aer-simulator | 0.4 | 0.7 | 0.56 | 0.58 | 0.575 | 0.543333 | 0.6175 | 0.567976 |
| QKE, ZZFeatureMap, aer-simulator, 31.622776601683793 | 0.4 | 0.55 | 0.6 | 0.62 | 0.625 | 0.596667 | 0.555 | 0.56381 |
| QKE, PauliFeatureMap, aer-simulator, 31.622776601683793 | 0.6 | 0.45 | 0.6 | 0.56 | 0.57 | 0.62 | 0.5425 | 0.563214 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 0.6 | 0.65 | 0.48 | 0.55 | 0.535 | 0.573333 | 0.545 | 0.561905 |
| QKE, ZFeatureMap, qasm-simulator, 177.82794100389228 | 0.6 | 0.7 | 0.5 | 0.52 | 0.5 | 0.556667 | 0.53 | 0.558095 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, aer-simulator | 0.7 | 0.6 | 0.5 | 0.48 | 0.525 | 0.48 | 0.615 | 0.557143 |
| VQC, ZZFeatureMap, RealAmplitudes, NFT, qasm-simulator | 0.6 | 0.4 | 0.58 | 0.47 | 0.66 | 0.573333 | 0.61 | 0.55619 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, qasm-simulator | 0.7 | 0.5 | 0.56 | 0.55 | 0.51 | 0.566667 | 0.505 | 0.555952 |
| QKE, PauliFeatureMap, qasm-simulator, 0.1778279410038923 | 0.5 | 0.35 | 0.36 | 0.63 | 0.655 | 0.693333 | 0.7025 | 0.555833 |
| QKE, ZZFeatureMap, qasm-simulator, 0.001 | 0.7 | 0.45 | 0.66 | 0.57 | 0.54 | 0.466667 | 0.4725 | 0.55131 |
| VQC, ZFeatureMap, RealAmplitudes, SPSA, aer-simulator | 0.7 | 0.5 | 0.5 | 0.59 | 0.495 | 0.516667 | 0.555 | 0.550952 |
| VQC, ZFeatureMap, EfficientSU2, SPSA, statevector-simulator | 0.3 | 0.8 | 0.44 | 0.59 | 0.55 | 0.563333 | 0.595 | 0.548333 |
| VQC, PauliFeatureMap, RealAmplitudes, NFT, qasm-simulator | 0.4 | 0.55 | 0.6 | 0.54 | 0.59 | 0.553333 | 0.58 | 0.544762 |
| VQC, ZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 0.8 | 0.45 | 0.48 | 0.48 | 0.52 | 0.513333 | 0.545 | 0.54119 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, statevector-simulator | 0.5 | 0.55 | 0.56 | 0.56 | 0.54 | 0.516667 | 0.56 | 0.540952 |
| QKE, ZFeatureMap, aer-simulator, 1000.0 | 0.6 | 0.55 | 0.6 | 0.52 | 0.505 | 0.486667 | 0.52 | 0.540238 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, qasm-simulator | 0.4 | 0.45 | 0.56 | 0.64 | 0.575 | 0.533333 | 0.6075 | 0.537976 |
| VQC, ZFeatureMap, RealAmplitudes, NFT, aer-simulator | 0.5 | 0.4 | 0.62 | 0.52 | 0.58 | 0.533333 | 0.5875 | 0.534405 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, aer-simulator | 0.4 | 0.45 | 0.54 | 0.54 | 0.64 | 0.56 | 0.6 | 0.532857 |
| QKE, ZFeatureMap, statevector-simulator, 0.1778279410038923 | 0.5 | 0.45 | 0.54 | 0.54 | 0.585 | 0.556667 | 0.555 | 0.532381 |
| QKE, ZFeatureMap, aer-simulator, 1.0 | 0.4 | 0.5 | 0.4 | 0.63 | 0.56 | 0.603333 | 0.575 | 0.524048 |
| QKE, ZFeatureMap, qasm-simulator, 1000.0 | 0.6 | 0.5 | 0.44 | 0.59 | 0.525 | 0.443333 | 0.5 | 0.514048 |
| QKE, PauliFeatureMap, statevector-simulator, 0.03162277660168379 | 0.5 | 0.45 | 0.58 | 0.56 | 0.46 | 0.476667 | 0.5675 | 0.513452 |
| RandomSearch, MLP, results | 0.3 | 0.25 | 0.5 | 0.6 | 0.635 | 0.64 | 0.6675 | 0.513214 |
| QKE, ZFeatureMap, aer-simulator, 177.82794100389228 | 0.4 | 0.65 | 0.54 | 0.46 | 0.495 | 0.48 | 0.565 | 0.512857 |
| QKE, ZFeatureMap, qasm-simulator, 0.005623413251903491 | 0.5 | 0.65 | 0.48 | 0.47 | 0.515 | 0.48 | 0.485 | 0.511429 |
| RandomSearch, Ridge, results | 0.4 | 0.55 | 0.52 | 0.46 | 0.56 | 0.52 | 0.5675 | 0.511071 |
| OutOfTheBox, Lasso, results | 0.5 | 0.7 | 0.4 | 0.51 | 0.495 | 0.46 | 0.495 | 0.508571 |
| RandomSearch, Lasso, results | 0.6 | 0.45 | 0.44 | 0.45 | 0.515 | 0.533333 | 0.54 | 0.504048 |
| Algorithm/Parametrization | Size 50 | Size 100 | Size 250 | Size 500 | Size 1000 | Size 1500 | Size 2000 | Average |
|---|---|---|---|---|---|---|---|---|
| OutOfTheBox, Lasso, results | 0.004103 | 0.000646 | 0.000661 | 0.001249 | 0.000804 | 0.000694 | 0.000691 | 0.001264 |
| OutOfTheBox, Ridge, results | 0.003733 | 0.002898 | 0.002786 | 0.029688 | 0.001899 | 0.001929 | 0.00178 | 0.006388 |
| OutOfTheBox, SVM, results | 0.00111 | 0.000919 | 0.002298 | 0.006078 | 0.012139 | 0.025935 | 0.04667 | 0.013593 |
| RandomSearch, Lasso, results | 1.055654 | 0.123047 | 0.103457 | 0.104252 | 0.117591 | 0.124301 | 0.115839 | 0.249163 |
| RandomSearch, Ridge, results | 1.084348 | 0.122741 | 0.138248 | 0.145562 | 0.156783 | 0.129915 | 0.14262 | 0.274317 |
| OutOfTheBox, XGBoost, results | 0.026616 | 0.040969 | 0.207265 | 1.348421 | 0.190274 | 0.123878 | 0.205496 | 0.306131 |
| RandomSearch, SVM, results | 1.133957 | 0.167929 | 0.131167 | 0.147877 | 0.233314 | 0.444834 | 0.438209 | 0.385327 |
| OutOfTheBox, CatBoost, results | 1.072432 | 0.439886 | 0.68483 | 0.813699 | 0.936663 | 1.13145 | 1.252242 | 0.904457 |
| RandomSearch, XGBoost, results | 1.555324 | 0.398761 | 0.517864 | 0.817118 | 1.79372 | 2.056436 | 2.289563 | 1.346969 |
| OutOfTheBox, LightGBM, results | 0.134499 | 0.935128 | 0.319397 | 1.125076 | 5.646488 | 4.908206 | 4.312101 | 2.482985 |
| OutOfTheBox, MLP, results | 0.447343 | 0.385258 | 0.303056 | 1.874662 | 2.165486 | 5.582801 | 6.986128 | 2.534962 |
| RandomSearch, LightGBM, results | 3.76752 | 0.726469 | 0.892496 | 1.349411 | 5.942432 | 5.569574 | 3.741842 | 3.141392 |
| QKE, ZFeatureMap, statevector-simulator, 1000.0 | 0.588803 | 1.105112 | 3.115228 | 9.692818 | 24.488245 | 46.863381 | 75.605305 | 23.065556 |
| QKE, ZZFeatureMap, statevector-simulator, 177.82794100389228 | 1.023377 | 2.014738 | 6.133744 | 14.08855 | 36.209869 | 63.510698 | 97.575217 | 31.508028 |
| QKE, PauliFeatureMap, statevector-simulator, 0.1778279410038923 | 1.110054 | 2.154783 | 6.591036 | 14.487802 | 36.089562 | 62.912848 | 97.64273 | 31.569831 |
| RandomSearch, MLP, results | 16.90452 | 15.129156 | 5.671446 | 42.576796 | 38.564641 | 70.807035 | 64.602048 | 36.322235 |
| QKE, ZFeatureMap, statevector-simulator, 0.1778279410038923 | 1.235019 | 1.984607 | 5.547594 | 15.333808 | 41.977686 | 79.052726 | 127.710628 | 38.977438 |
| QKE, PauliFeatureMap, statevector-simulator, 0.03162277660168379 | 1.453579 | 2.804056 | 9.085313 | 19.440721 | 47.633347 | 81.740004 | 128.186636 | 41.477665 |
| QKE, ZZFeatureMap, statevector-simulator, 0.1778279410038923 | 2.194236 | 4.856549 | 10.043207 | 20.391739 | 57.658834 | 97.515617 | 151.070676 | 49.104408 |
| RandomSearch, CatBoost, results | 18.350174 | 35.654742 | 40.725868 | 70.65956 | 68.788446 | 68.958949 | 43.685619 | 49.546194 |
| VQC, ZFeatureMap, RealAmplitudes, COBYLA, qasm-simulator | 55.500573 | 100.423827 | 241.59017 | 577.400258 | 1286.962867 | 2164.282246 | 3315.185871 | 1105.906545 |
| VQC, ZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 61.174412 | 116.296597 | 274.944359 | 672.215972 | 1509.987298 | 2624.710516 | 4058.819283 | 1331.164062 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, statevector-simulator | 68.600875 | 123.207802 | 380.446356 | 770.716185 | 1635.89919 | 2621.242822 | 3805.021206 | 1343.590634 |
| VQC, PauliFeatureMap, EfficientSU2, COBYLA, aer-simulator | 89.832315 | 163.70887 | 480.279572 | 975.291255 | 2084.174564 | 3407.844934 | 5050.433405 | 1750.223559 |
| VQC, ZZFeatureMap, EfficientSU2, COBYLA, qasm-simulator | 88.21128 | 163.988243 | 480.35886 | 973.614566 | 2068.950356 | 3425.564759 | 5057.849761 | 1751.219689 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, qasm-simulator | 85.847133 | 156.496491 | 381.392026 | 888.461174 | 2300.527629 | 3878.06995 | 6136.175247 | 1975.281379 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, statevector-simulator | 103.51928 | 191.066923 | 456.017277 | 1079.39181 | 2305.444005 | 3940.212229 | 5958.277453 | 2004.846997 |
| VQC, ZFeatureMap, RealAmplitudes, NFT, aer-simulator | 111.03018 | 203.235006 | 491.978903 | 1181.668828 | 2620.544781 | 4428.84701 | 6770.538213 | 2258.263274 |
| VQC, ZFeatureMap, EfficientSU2, COBYLA, aer-simulator | 113.765615 | 205.589837 | 516.289881 | 1202.288662 | 2663.121947 | 4533.378097 | 6730.84663 | 2280.754381 |
| VQC, ZZFeatureMap, RealAmplitudes, COBYLA, aer-simulator | 111.686165 | 209.034186 | 638.294179 | 1296.48554 | 2869.708946 | 4781.981067 | 7074.925479 | 2426.016509 |
| VQC, PauliFeatureMap, RealAmplitudes, NFT, qasm-simulator | 163.24924 | 303.991817 | 936.898012 | 1915.698994 | 4145.466983 | 6900.43208 | 10,273.374065 | 3519.873027 |
| VQC, ZFeatureMap, EfficientSU2, SPSA, statevector-simulator | 190.048137 | 341.454534 | 823.875859 | 1930.637818 | 4188.237967 | 6999.258807 | 10,586.6448 | 3580.02256 |
| VQC, PauliFeatureMap, RealAmplitudes, NFT, statevector-simulator | 190.485358 | 349.906865 | 1108.180672 | 2248.345232 | 4814.143806 | 7883.610885 | 11,821.059517 | 4059.390334 |
| VQC, ZFeatureMap, RealAmplitudes, SPSA, aer-simulator | 195.45132 | 357.101921 | 856.679886 | 2110.857992 | 4766.449826 | 8178.593323 | 12,549.799371 | 4144.99052 |
| VQC, ZZFeatureMap, RealAmplitudes, NFT, qasm-simulator | 224.602174 | 405.497928 | 1270.741552 | 2674.141109 | 5725.217252 | 9676.191547 | 14,306.04881 | 4897.491482 |
| VQC, ZZFeatureMap, EfficientSU2, NFT, statevector-simulator | 243.54281 | 457.172266 | 1372.528644 | 2784.422174 | 5896.297166 | 9666.126191 | 14,179.331314 | 4942.774366 |
| QKE, ZFeatureMap, aer-simulator, 1.0 | 9.847104 | 40.399745 | 258.379268 | 1171.612393 | 4847.638381 | 10,994.736629 | 19,569.132042 | 5270.249366 |
| VQC, ZZFeatureMap, EfficientSU2, NFT, aer-simulator | 259.240503 | 473.126474 | 1408.601057 | 2903.563737 | 6301.786963 | 10,332.959201 | 15,345.314436 | 5289.227482 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, aer-simulator | 316.140029 | 574.301472 | 1727.700192 | 3530.722918 | 6706.076042 | 9861.491595 | 14,726.388476 | 5348.974389 |
| QKE, ZFeatureMap, aer-simulator, 1000.0 | 10.898171 | 46.773357 | 297.390107 | 1339.784466 | 5587.107904 | 11,607.623344 | 19,440.97092 | 5475.79261 |
| VQC, ZZFeatureMap, EfficientSU2, SPSA, aer-simulator | 243.897139 | 463.586231 | 1368.88324 | 2789.133991 | 6570.676821 | 11,456.705765 | 17,726.796588 | 5802.811396 |
| VQC, PauliFeatureMap, EfficientSU2, SPSA, qasm-simulator | 348.216144 | 639.131772 | 1898.469802 | 3945.807249 | 8437.848893 | 13,815.446673 | 20,511.034176 | 7085.136387 |
| QKE, ZFeatureMap, qasm-simulator, 1000.0 | 11.579451 | 47.675482 | 344.543775 | 1568.903939 | 6191.830912 | 14,908.467701 | 27,002.766078 | 7153.681048 |
| QKE, ZFeatureMap, aer-simulator, 177.82794100389228 | 14.163619 | 56.856619 | 359.793343 | 1620.482626 | 6647.990849 | 15,084.137764 | 26,961.326713 | 7249.250219 |
| QKE, ZFeatureMap, qasm-simulator, 177.82794100389228 | 16.35717 | 77.129608 | 482.478877 | 2237.68152 | 9219.954344 | 18,899.046552 | 26,623.312487 | 8222.28008 |
| QKE, ZFeatureMap, qasm-simulator, 0.005623413251903491 | 16.184459 | 68.030962 | 439.889123 | 2003.14586 | 8339.157072 | 18,939.866418 | 33,875.189822 | 9097.351959 |
| QKE, PauliFeatureMap, aer-simulator, 31.622776601683793 | 16.822446 | 70.391611 | 549.285996 | 2267.794391 | 9148.306499 | 20,490.131389 | 36,687.638808 | 9890.05302 |
| QKE, ZZFeatureMap, aer-simulator, 31.622776601683793 | 17.382234 | 70.921393 | 552.720236 | 2290.305118 | 9223.01824 | 20,681.450668 | 36,991.554065 | 9975.335993 |
| QKE, ZZFeatureMap, aer-simulator, 0.1778279410038923 | 19.618006 | 80.653612 | 632.012298 | 2628.407038 | 9714.431489 | 20,666.725844 | 36,766.378776 | 10,072.603866 |
| QKE, PauliFeatureMap, aer-simulator, 5.623413251903491 | 20.03461 | 81.805468 | 657.437384 | 2646.600018 | 10,751.043722 | 24,303.410594 | 42,050.186601 | 11,501.502628 |
| QKE, ZZFeatureMap, qasm-simulator, 0.001 | 22.474871 | 94.5939 | 748.53639 | 3061.492908 | 11,095.037557 | 24,179.108494 | 42,833.544061 | 11,719.255454 |
| QKE, PauliFeatureMap, aer-simulator, 0.1778279410038923 | 15.70449 | 64.293166 | 539.372432 | 2052.767245 | 10,360.381735 | 28,219.134103 | 53,610.138579 | 13,551.684536 |
| QKE, PauliFeatureMap, qasm-simulator, 0.1778279410038923 | 28.777769 | 121.675706 | 961.248534 | 3951.052992 | 16,159.343561 | 35,692.431334 | 48,691.262451 | 15,086.541764 |
| QKE, ZZFeatureMap, qasm-simulator, 31.622776601683793 | 28.201021 | 110.795119 | 877.141222 | 3647.413017 | 16,257.207805 | 38,819.796065 | 69,300.661749 | 18,434.459428 |
| Classifier\Dataset | Iris | Wine | ILPD | BC-Coimbra | TAE | Breast-Tissue |
|---|---|---|---|---|---|---|
| VQC | 0.817 | 0.817 | 0.706 | 0.599 | 0.417 | 0.339 |
| QKE | 0.908 | 0.853 | 0.706 | 0.620 | 0.483 | 0.382 |
| Ridge | 0.914 | 0.875 | 0.080 | 0.053 | 0.053 | <0.001 |
| Lasso | 0.914 | 0.870 | 0.085 | 0.004 | 0.004 | <0.001 |
| MLP | 0.975 | 0.937 | 0.712 | 0.687 | 0.425 | 0.406 |
| SVM | 0.958 | 0.759 | 0.706 | 0.630 | 0.450 | 0.382 |
| XGBoost | 0.958 | 0.986 | 0.695 | 0.656 | 0.533 | 0.441 |
| LightGBM | 0.967 | 0.986 | 0.699 | 0.666 | 0.475 | 0.393 |
| CatBoost | 0.950 | 0.979 | 0.702 | 0.688 | 0.525 | 0.440 |
| Classifier\Dataset | Iris | Wine | ILPD | BC-Coimbra | TAE | Breast-Tissue |
| VQC | 0.767 | 0.639 | 0.744 | 0.541 | 0.388 | 0.334 |
| QKE | 1.0 | 0.833 | 0.744 | 0.792 | 0.613 | 0.409 |
| Ridge | 0.947 | 0.878 | 0.115 | 0.234 | <0.001 | <0.001 |
| Lasso | 0.945 | 0.882 | 0.115 | 0.296 | <0.001 | <0.001 |
| MLP | 1.0 | 1.0 | 0.769 | 0.875 | 0.387 | 0.455 |
| SVM | 1.0 | 0.972 | 0.743 | 0.875 | 0.355 | 0.455 |
| XGBoost | 1.0 | 1.0 | 0.735 | 0.917 | 0.533 | 0.441 |
| LightGBM | 1.0 | 1.0 | 0.752 | 0.917 | 0.419 | 0.455 |
| CatBoost | 1.0 | 1.0 | 0.744 | 0.917 | 0.645 | 0.545 |
| Classifier\ Dataset | Iris | Wine | ILPD | BC-Coimbra | TAE | Breast-Tissue |
|---|---|---|---|---|---|---|
| VQC | 3:32:16.547605 | 1 day, 13:56:59.455185 | 2 days, 23:03:26.398856 | 9:55:17.907443 | 2:46:25.921553 | 9:01:58.623806 |
| QKE | 2:03:57.921154 | 21:41:38.738255 | 7 days, 6:30:41.179676 | 5:02:26.430001 | 1:28:54.069725 | 3:37:05.655104 |
| Ridge | 0:00:00.175009 | 0:00:00.496771 | 0:00:00.399229 | 0:00:00.240857 | 0:00:00.209600 | 0:00:00.296966 |
| Lasso | 0:00:00.173051 | 0:00:00.181444 | 0:00:00.237455 | 0:00:00.192257 | 0:00:00.229508 | 0:00:00.225531 |
| MLP | 0:00:16.876288 | 0:00:10.477420 | 0:00:26.748907 | 0:00:10.951229 | 0:00:08.475263 | 0:00:13.729790 |
| SVM | 0:00:00.143353 | 0:00:00.165431 | 0:00:00.484485 | 0:00:00.180694 | 0:00:00.228508 | 0:00:00.226784 |
| XGBoost | 0:00:03.809085 | 0:00:04.030425 | 0:00:04.752627 | 0:00:02.744122 | 0:00:05.820371 | 0:00:06.864497 |
| LightGBM | 0:00:02.971164 | 0:00:03.180770 | 0:00:03.062553 | 0:00:01.462174 | 0:00:03.056615 | 0:00:04.540870 |
| CatBoost | 0:00:06.465975 | 0:00:18.511612 | 0:00:11.352944 | 0:00:07.460460 | 0:00:06.964821 | 0:00:26.639070 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raubitzek, S.; Mallinger, K. On the Applicability of Quantum Machine Learning. Entropy 2023, 25, 992. https://doi.org/10.3390/e25070992
Raubitzek S, Mallinger K. On the Applicability of Quantum Machine Learning. Entropy. 2023; 25(7):992. https://doi.org/10.3390/e25070992
Chicago/Turabian StyleRaubitzek, Sebastian, and Kevin Mallinger. 2023. "On the Applicability of Quantum Machine Learning" Entropy 25, no. 7: 992. https://doi.org/10.3390/e25070992
APA StyleRaubitzek, S., & Mallinger, K. (2023). On the Applicability of Quantum Machine Learning. Entropy, 25(7), 992. https://doi.org/10.3390/e25070992