
Enhancing Basketball Game Outcome Prediction through Fused Graph Convolutional Networks and Random Forest Algorithm



Abstract
1. Introduction
2. Related Work
2.1. Basketball Game Outcome Prediction
2.2. GNN Methodology and Sport Outcome Prediction
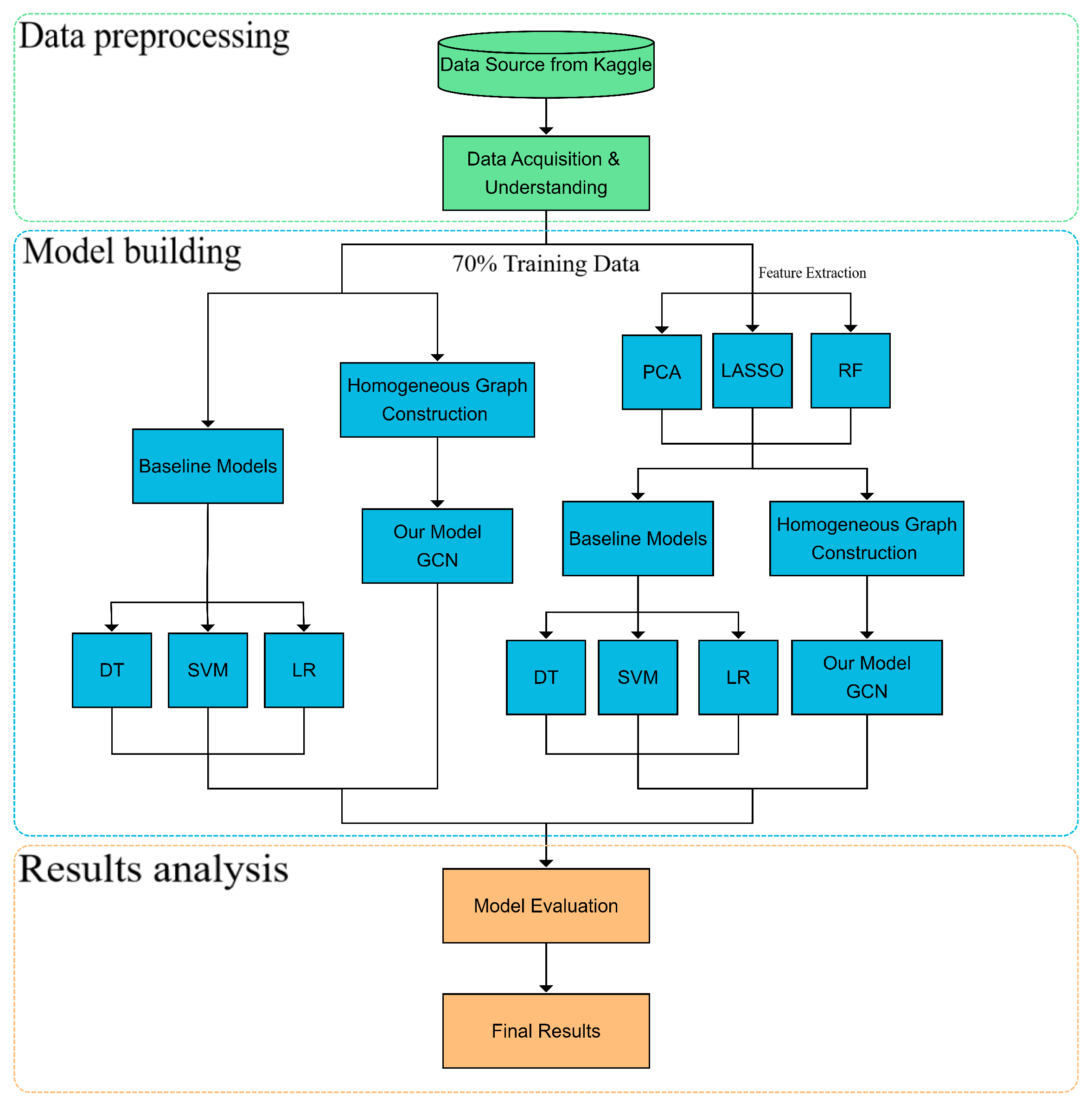
3. Methodology
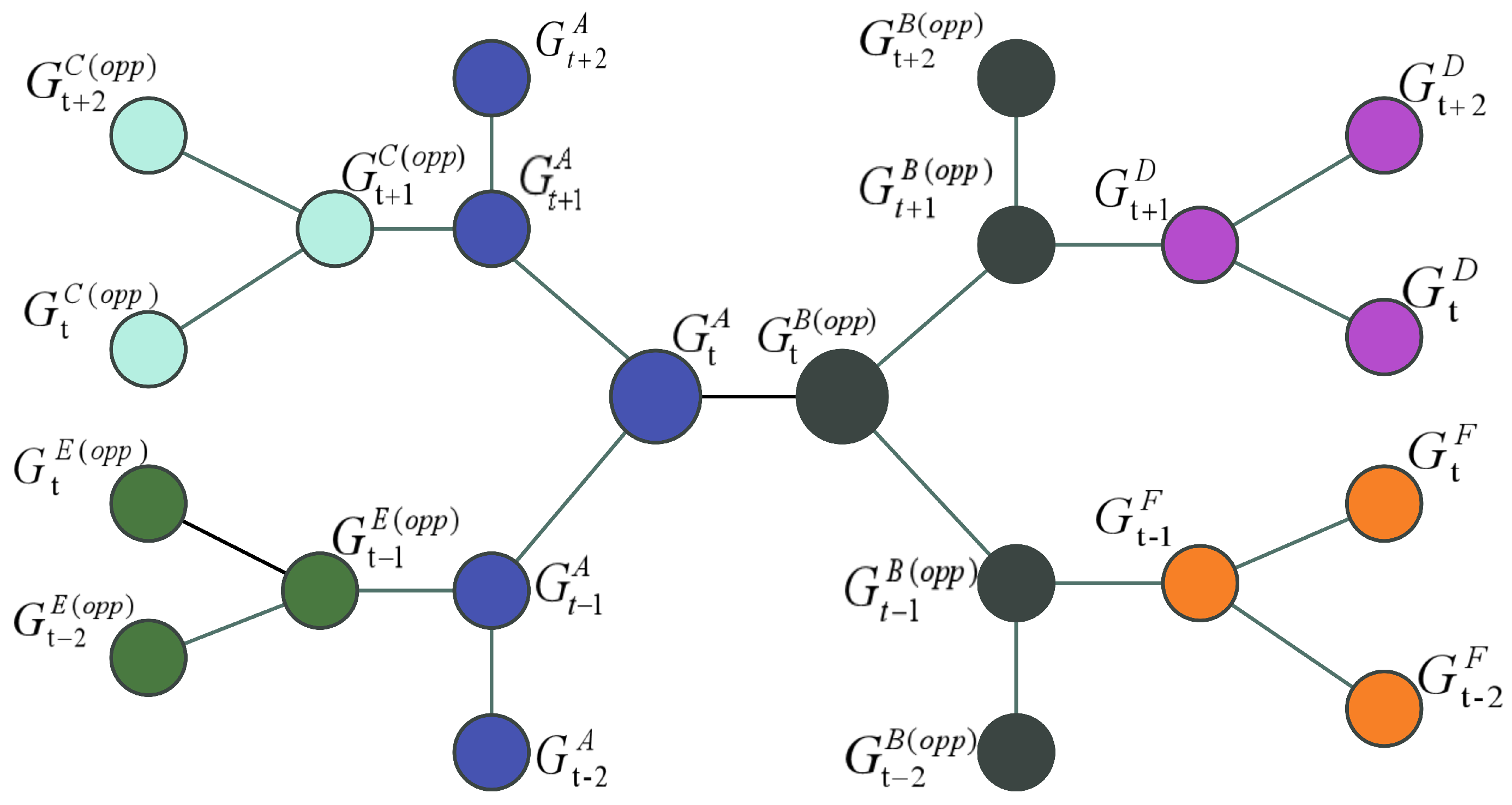
3.1. Graph Networks Construction
3.2. Principal Component Analysis
3.3. Feature Extraction Based on the LASSO Algorithm
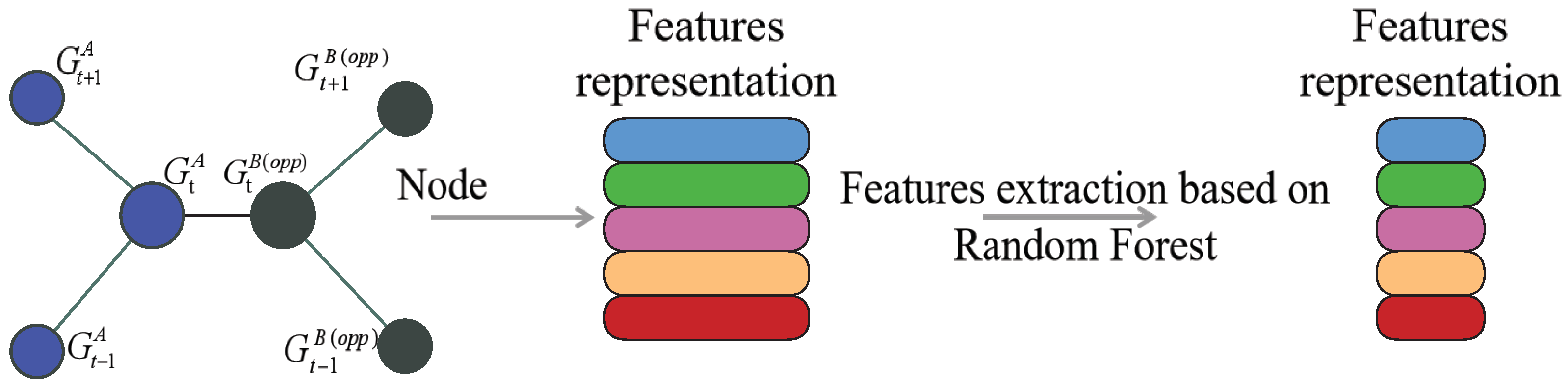
3.4. Feature Extraction Based on the Random Forest Algorithm
3.5. Graph Convolutional Network
4. Experiment and Results
4.1. Datasets
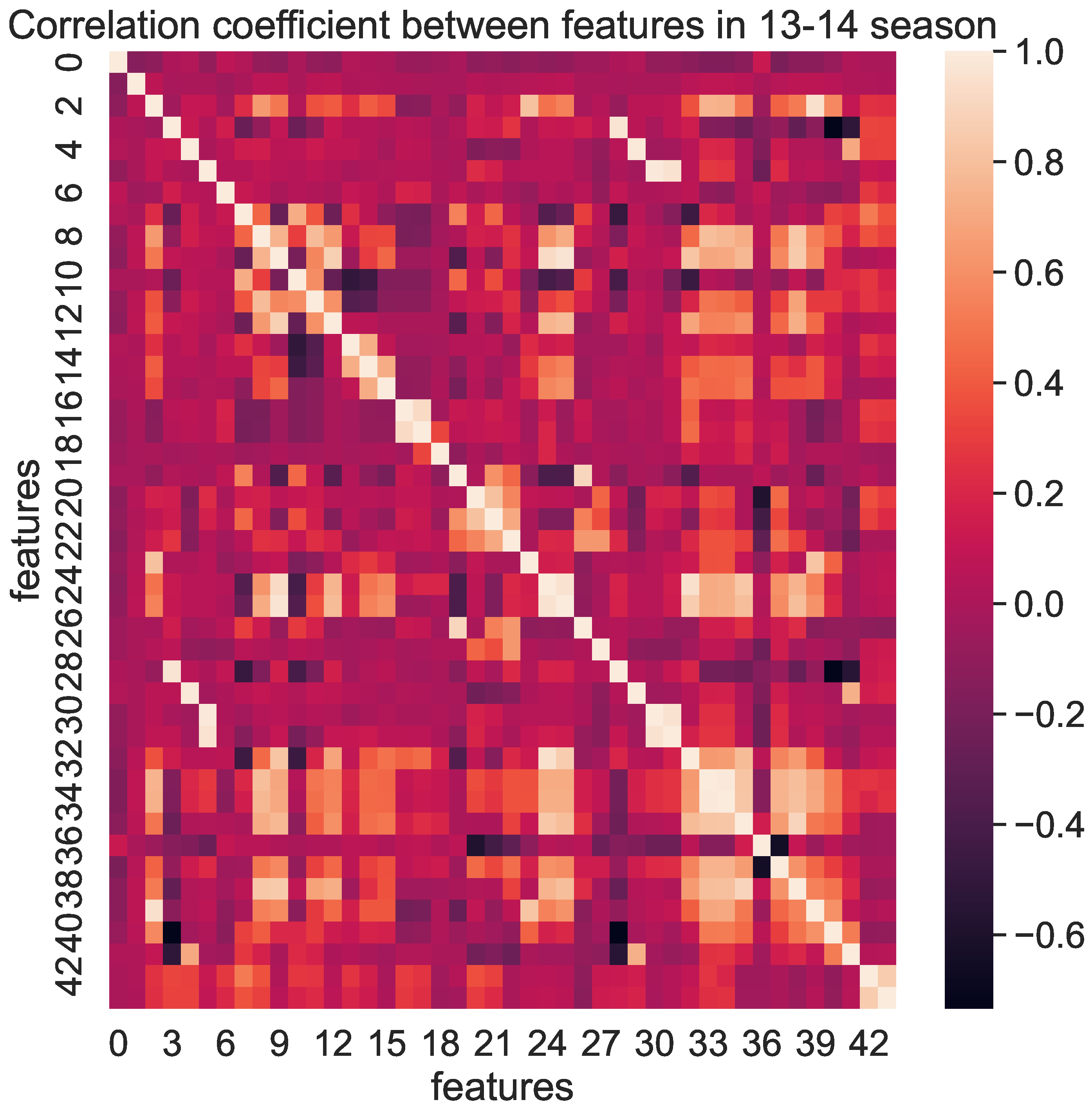
4.2. Feature Engineering
4.3. Experimental Results and Comparison
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| NBA | National Basketball Association |
| GNN | Graph Neural Networks |
| GCN | Graph Convolution Network |
| RF | Random Forest |
| FFNN | Feed-Forward Neural Network |
| SVM | Support Vector Machines |
| ANN | Artificial Neural Networks |
| DT | Decision Tree |
| LR | Linear Regression |
| PCA | Principal Component Analysis |
| LASSO | Least Absolute Shrinkage and Selection Operator |
References
- Yang, Z. Research on basketball players’ training strategy based on artificial intelligence technology. J. Phys. Conf. Ser. 2020, 1648, 042057. [Google Scholar] [CrossRef]
- Tian, C.; De Silva, V.; Caine, M.; Swanson, S. Use of machine learning to automate the identification of basketball strategies using whole team player tracking data. Appl. Sci. 2019, 10, 24. [Google Scholar] [CrossRef]
- Wu, W. Injury Analysis Based on Machine Learning in NBA Data. J. Data Anal. Inf. Process. 2020, 8, 295–308. [Google Scholar] [CrossRef]
- Li, B.; Xu, X. Application of artificial intelligence in basketball sport. J. Educ. Health Sport 2021, 11, 54–67. [Google Scholar] [CrossRef]
- Bunker, R.; Susnjak, T. The Application of Machine Learning Techniques for Predicting Match Results in Team Sport: A Review. J. Artif. Intell. Res. 2022, 73, 1285–1322. [Google Scholar] [CrossRef]
- Li, H. Analysis on the construction of sports match prediction model using neural network. Soft Comput. 2020, 24, 8343–8353. [Google Scholar] [CrossRef]
- Delen, D.; Cogdell, D.; Kasap, N. A comparative analysis of data mining methods in predicting NCAA bowl outcomes. Int. J. Forecast. 2012, 28, 543–552. [Google Scholar] [CrossRef]
- O’Donoghue, P.; Ball, D.; Eustace, J.; McFarlan, B.; Nisotaki, M. Predictive models of the 2015 Rugby World Cup: Accuracy and application. Int. J. Comput. Sci. Sport 2016, 15, 37–58. [Google Scholar] [CrossRef]
- Berrar, D.; Lopes, P.; Dubitzky, W. Incorporating domain knowledge in machine learning for soccer outcome prediction. Mach. Learn. 2019, 108, 97–126. [Google Scholar] [CrossRef]
- Gu, W.; Foster, K.; Shang, J.; Wei, L. A game-predicting expert system using big data and machine learning. Expert Syst. Appl. 2019, 130, 293–305. [Google Scholar] [CrossRef]
- Valero, C.S. Predicting Win-Loss outcomes in MLB regular season games–A comparative study using data mining methods. Int. J. Comput. Sci. Sport 2016, 15, 91–112. [Google Scholar] [CrossRef]
- Pathak, N.; Wadhwa, H. Applications of modern classification techniques to predict the outcome of ODI cricket. Procedia Comput. Sci. 2016, 87, 55–60. [Google Scholar] [CrossRef]
- Li, Y.; Wang, L.; Li, F. A data-driven prediction approach for sports team performance and its application to National Basketball Association. Omega 2021, 98, 102123. [Google Scholar] [CrossRef]
- Chen, W.J.; Jhou, M.J.; Lee, T.S.; Lu, C.J. Hybrid basketball game outcome prediction model by integrating data mining methods for the National Basketball Association. Entropy 2021, 23, 477. [Google Scholar] [CrossRef]
- Lu, C.J.; Lee, T.S.; Wang, C.C.; Chen, W.J. Improving Sports Outcome Prediction Process Using Integrating Adaptive Weighted Features and Machine Learning Techniques. Processes 2021, 9, 1563. [Google Scholar] [CrossRef]
- Lam, M.W. One-match-ahead forecasting in two-team sports with stacked Bayesian regressions. J. Artif. Intell. Soft Comput. Res. 2018, 8, 159–171. [Google Scholar] [CrossRef]
- Horvat, T.; Havaš, L.; Srpak, D. The impact of selecting a validation method in machine learning on predicting basketball game outcomes. Symmetry 2020, 12, 431. [Google Scholar] [CrossRef]
- Ozkan, I.A. A novel basketball result prediction model using a concurrent neuro-fuzzy system. Appl. Artif. Intell. 2020, 34, 1038–1054. [Google Scholar] [CrossRef]
- Song, K.; Zou, Q.; Shi, J. Modelling the scores and performance statistics of NBA basketball games. Commun. Stat.-Simul. Comput. 2020, 49, 2604–2616. [Google Scholar] [CrossRef]
- Zimmermann, A. Basketball predictions in the NCAAB and NBA: Similarities and differences. Stat. Anal. Data Min. ASA Data Sci. J. 2016, 9, 350–364. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Loeffelholz, B.; Bednar, E.; Bauer, K.W. Predicting NBA games using neural networks. J. Quant. Anal. Sport. 2009, 5, 1–17. [Google Scholar] [CrossRef]
- Zdravevski, E.; Kulakov, A. System for Prediction of the Winner in a Sports Game. In Proceedings of the International Conference on ICT Innovations, Ohrid Macedonia, North Macedonia, 28–30 September 2009; Springer: Berlin/Heidelberg, Germany, 2010; pp. 55–63. [Google Scholar]
- Miljković, D.; Gajić, L.; Kovačević, A.; Konjović, Z. The use of data mining for basketball matches outcomes prediction. In Proceedings of the IEEE 8th International Symposium on Intelligent Systems and Informatics, Subotica, Serbia, 10–11 September 2010; pp. 309–312. [Google Scholar]
- Cao, C. Sports Data Mining Technology Used in Basketball Outcome Prediction. Master’s Thesis, Technological University Dublin, Dublin, Ireland, 2012. [Google Scholar]
- Lin, J.; Short, L.; Sundaresan, V. Predicting National Basketball Association Winners. 2014. Available online: http://cs229.stanford.edu/proj2014/Jasper%20Lin,%20Logan%20Short,%20Vishnu%20Sundaresan,%20Predicting%20National%20Basketball%20Association%20Game%20Winners.pdf (accessed on 9 September 2022).
- Tran, T. Predicting NBA Games with Matrix Factorization. Bachelor’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2016. [Google Scholar]
- Li, S. Revisiting the Correlation of Basketball Stats and Match Outcome Prediction. In Proceedings of the 2020 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 63–67. [Google Scholar]
- Erhan, Ç.E.N.E. Makine öğrenmesi yöntemleriyle Euroleague basketbol maç sonuçlarının tahmin edilmesi ve maç sonuçları üzerinde en etkili değişkenlerin bulunması. Spor Ve Performans Araştırmaları Derg. 2022, 13, 31–54. [Google Scholar]
- Osken, C.; Onay, C. Predicting the winning team in basketball: A novel approach. Heliyon 2022, 8, e12189. [Google Scholar] [CrossRef]
- Aleksandra, P. Predicting Sports Matches with Neural Models. Master’s Thesis, Czech Technical University in Prague, Prague, Czech Republic, 2021. [Google Scholar]
- Xenopoulos, P.; Silva, C. Graph Neural Networks to Predict Sports Outcomes. In Proceedings of the 2021 IEEE International Conference on Big Data, Orlando, FL, USA, 15–18 December 2021; pp. 1757–1763. [Google Scholar]
- Mirzaei, A. Sports match outcome prediction with graph representation learning. Master’s Thesis, Simon Fraser University, Greater Vancouver, BC, Canada, 2022. [Google Scholar]
- Bisberg, A.J.; Ferrara, E. GCN-WP–Semi-Supervised Graph Convolutional Networks for Win Prediction in Esports. In Proceedings of the 2022 IEEE Conference on Games (CoG), Beijing, China, 21–24 August 2022; pp. 449–456. [Google Scholar]
- Chen, C.; Xu, Y.; Zhao, J.; Chen, L.; Xue, Y. Combining random forest and graph wavenet for spatial-temporal data prediction. Intell. Converg. Netw. 2022, 3, 364–377. [Google Scholar] [CrossRef]
- Hu, L.; Zhao, K.; Ling, B.W.K.; Lin, Y. Activity recognition via correlation coefficients based graph with nodes updated by multi-aggregator approach. Biomed. Signal Process. Control 2023, 79, 104255. [Google Scholar] [CrossRef]
- Rossottl, P. NBA Enhanced Box Score and Standings (2012–2018). Available online: https://www.kaggle.com/datasets/pablote/nba-enhanced-stats (accessed on 9 September 2022).
- Kipf, T. Graph Convolutional Networks. Available online: https://github.com/tkipf/gcn (accessed on 9 September 2022).
- Bisberg, A.; Kipf, T. Graph Convolutional Networks. Available online: https://github.com/ajbisberg/gcn (accessed on 9 September 2022).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Year | Amount of Data | Number of Features | Dataset | Model | Success Rate |
|---|---|---|---|---|---|---|
| Loeffelholz et al. [22] | 2009 | 620-Training, 30-Test | 11 | NBA 2007–2008 | FFNN | 74.33 |
| Zdravevski and Kulakov [23] | 2009 | 50%-Training, 50%-Test | 10 | NBA 2consecutive seasons | Logistic Regression | 72.78 |
| Miljkovic et al. [24] | 2010 | 778 games | 32 | NBA 2009–2010 | Naive Bayes | 67 |
| Cao [25] | 2012 | 80%-Training, 20%-Test | 46 | NBA 2005–2011 | Simple Logistic Regression | 69.67 |
| Lin, J. et al. [26] | 2014 | 85%-Training, 15%-Test | 17 | NBA 1991–1998 | Random Forests | 65 |
| Tran, T. [27] | 2016 | - | 15 | NBA 1985–2015 | Dependent Probabilistic Matrix Factorization | 72.1 |
| Li, Y. et al. [13] | 2019 | 80%-Training, 20%-Test | 10 | NBA 2011–2016 | DEA | 73.95 |
| Horvat, T. et al. [17] | 2020 | 11,578 games | 10 | NBA 2009–2018 | K-NN | 60 |
| Li [28] | 2020 | 7380 games | 14 | NBA 2012–2018 | Linear Regression | 67.24 |
| Ozkan I A. [18] | 2020 | 240 games | 9 | Turkish Basketball Super League 2015–2016 | CNFS | 79.2 |
| ÇENE E. [29] | 2022 | 70%-Training, 30%-Test | - | EuroLeague 2016–2017, 2020–2021 | Logistic Regression, SVM, ANN | 84 |
| Osken C and Onay C. [30] | 2022 | - | 49 | NBA 2012–2018 | ANN | 76 |
| Author(s) | Year | Amount of Data | Number of Features | Dataset | Model | Success Rate |
|---|---|---|---|---|---|---|
| Aleksandra P. [31] | 2021 | 216,743 games | No feature | 52 leagues (Soccer) | GNN | 49.62 (multiple leagues), 52.31 (single league) |
| Xenopoulos P. and Silva C. [32] | 2021 | 4038 games (NFL) | - | NFL 2017 season | GNN | - |
| Mirzaei A. [33] | 2022 | 21,374 games | Lineup | 11 countries and 11 leagues (soccer) | GNN | 50.36 |
| Bisberg A J and Ferrara E. [34] | 2022 | LPL-Training, LCK-Validation, LCS-Test | 5 | LPL, LCK and LCS | GCN | 61.9 |
| Features | Description | Features | Description |
|---|---|---|---|
| teamLoc | Identifies whether team is home or visitor | teamDayOff | Number of days since last game played by team |
| teamAST | Assists made by team | teamTO | Turnovers made by team |
| teamSTL | Steals made by team | teamBLK | Blocks made by team |
| teamPF | Personal fouls made by team | teamFGA | Field goal attempts made by team |
| teamFGM | Field goal shots made by team | teamFG% | Field goal percentage made by team |
| team2PA | Two-point attempts made by team | team2PM | Two-point shots made by team |
| team2P% | Two-point percentage made by team | team3PA | Three-point attempts made by team |
| team3PM | Three-point shots made by team | team3P% | Three-point percentage made by team |
| teamFTA | Free throw attempts made by team | teamFTM | Free throw shots made by team |
| teamFT% | Free throw percentage made by team | teamORB | Offensive rebounds made by team |
| teamDRB | Defensive rebounds made by team | teamTRB | Total rebounds made by team |
| teamTREB% | Total rebound percent by team | teamASST% | Assisted field goal percent by team |
| teamTS% | True shooting percentage by team | teamEFG% | Effective field goal percent by team |
| teamOREB% | Offensive rebound percent by team | teamDREB% | Defensive rebound percent by team |
| teamTO% | Turnover percentage by team | teamSTL% | Steal percentage by team |
| teamBLK% | Block percentage by team | teamBLKR | Block rate by team |
| teamPPS | Points per shot by team | teamFIC | Floor impact counter for team |
| teamFIC40 | Floor impact counter by team per 40 min | teamOrtg | Offensive rating for team |
| teamDrtg | Defensive rating for team | teamEDiff | Efficiency differential for team |
| teamPlay% | Play percentage for team | teamAR | Assist rate for team |
| teamAST/TO | Assist to turnover ratio for team | teamSTL/TO | Steal to turnover ratio for team |
| poss | Total team possessions | pace | Pace per game duration |
| Features | Score | Features | Score | Features | Score |
|---|---|---|---|---|---|
| teamEDiff | 0.361368 | teamDRB | 0.000000 | teamFIC40 | 0.000000 |
| teamFTA | 0.028293 | teamFGM | 0.000000 | teamTREB% | 0.000000 |
| teamPPS | 0.024126 | teamFGA | 0.000000 | teamBLKR | 0.000000 |
| teamBLK% | 0.006646 | teamBLK | 0.000000 | teamTO% | 0.000000 |
| team3P% | 0.004803 | teamSTL | 0.000000 | teamOREB% | 0.000000 |
| teamSTL/TO | 0.004417 | teamAST | 0.000000 | teamEFG% | 0.000000 |
| teamFIC | 0.004135 | teamDayOff | 0.000000 | teamTS% | 0.000000 |
| teamFT% | 0.000000 | teamORB | 0.000000 | teamASST% | 0.000000 |
| teamFTM | 0.000000 | teamTRB | 0.000000 | teamLoc | 0.000000 |
| team3PM | 0.000000 | poss | 0.000000 | teamTO | −0.002860 |
| team2P% | 0.000000 | teamSTL% | 0.000000 | teamDREB% | −0.004153 |
| team2PM | 0.000000 | teamAST/TO | 0.000000 | team3PA | −0.009556 |
| team2PA | 0.000000 | teamAR | 0.000000 | teamDrtg | −0.017633 |
| pace | 0.000000 | teamPlay% | 0.000000 | teamPF | −0.037388 |
| teamFG% | 0.000000 | teamOrtg | 0.000000 | - | - |
| Features | Score | Features | Score | Features | Score |
|---|---|---|---|---|---|
| teamEDiff | 0.3846 | teamFG% | 0.0097 | teamPF | 0.0038 |
| teamDrtg | 0.1163 | teamSTL% | 0.0092 | team2PA | 0.0037 |
| teamFIC | 0.1018 | team3PM | 0.0079 | poss | 0.0033 |
| teamPPS | 0.0602 | teamAST | 0.0069 | teamDREB% | 0.0033 |
| teamOrtg | 0.0438 | teamBLK% | 0.0057 | team2PM | 0.0032 |
| teamPlay% | 0.0331 | teamSTL/TO | 0.0057 | teamFGA | 0.0030 |
| teamEFG% | 0.0252 | teamFGM | 0.0054 | teamORB | 0.0027 |
| teamTREB% | 0.0187 | teamAST/TO | 0.0051 | teamBLK | 0.0021 |
| teamTRB | 0.0156 | teamBLKR | 0.0050 | teamFTA | 0.0018 |
| teamDRB | 0.0155 | teamFT% | 0.0044 | pace | 0.0017 |
| teamAR | 0.0154 | teamFTM | 0.0042 | teamTO | 0.0012 |
| team3P% | 0.0152 | teamTO% | 0.0042 | teamLoc | 0.0007 |
| teamTS% | 0.0145 | team3PA | 0.0040 | teamDayOff | 0.0007 |
| team2P% | 0.0132 | teamOREB% | 0.0038 | teamSTL | 0.0007 |
| teamFIC40 | 0.0101 | teamASST% | 0.0038 | - | - |
| Season | DT Classifier | SVM Classifier | LR | GCN |
|---|---|---|---|---|
| 2012–2013 | 0.6728 | 0.7114 | 0.7029 | 0.6850 |
| 2013–2014 | 0.6789 | 0.6965 | 0.6887 | 0.6790 |
| 2014–2015 | 0.6707 | 0.7439 | 0.7002 | 0.6900 |
| 2015–2016 | 0.6890 | 0.6748 | 0.6820 | 0.6080 |
| 2016–2017 | 0.6992 | 0.6585 | 0.7012 | 0.6690 |
| 2017–2018 | 0.6829 | 0.6707 | 0.6992 | 0.6830 |
| Average | 0.6823 | 0.6926 | 0.6957 | 0.6690 |
| Season | DT + PCA | SVM + PCA | LR + PCA | GCN + PCA |
|---|---|---|---|---|
| 2012–2013 | 0.6087 | 0.6343 | 0.6250 | 0.4960 |
| 2013–2014 | 0.6002 | 0.6239 | 0.6190 | 0.4970 |
| 2014–2015 | 0.5892 | 0.6022 | 0.6210 | 0.4960 |
| 2015–2016 | 0.6103 | 0.6105 | 0.6080 | 0.5107 |
| 2016–2017 | 0.6220 | 0.6221 | 0.6102 | 0.5200 |
| 2017–2018 | 0.6120 | 0.6342 | 0.6330 | 0.5240 |
| Average | 0.6071 | 0.6212 | 0.6194 | 0.5073 |
| Season | DT + LASSO | SVM + LASSO | LR + LASSO | GCN + LASSO |
|---|---|---|---|---|
| 2012–2013 | 0.6928 | 0.7322 | 0.7250 | 0.7295 |
| 2013–2014 | 0.7012 | 0.6820 | 0.7009 | 0.7024 |
| 2014–2015 | 0.7144 | 0.7023 | 0.7122 | 0.7285 |
| 2015–2016 | 0.6912 | 0.6988 | 0.6922 | 0.6829 |
| 2016–2017 | 0.7008 | 0.7102 | 0.6820 | 0.6932 |
| 2017–2018 | 0.7201 | 0.6979 | 0.7030 | 0.7053 |
| Average | 0.7034 | 0.7039 | 0.7026 | 0.7070 |
| Season | DT + RF | SVM + RF | LR + RF | Our Proposed Method (GCN + RF) |
|---|---|---|---|---|
| 2012–2013 | 0.7112 | 0.7152 | 0.7090 | 0.7215 |
| 2013–2014 | 0.7022 | 0.7220 | 0.7080 | 0.7154 |
| 2014–2015 | 0.7209 | 0.7090 | 0.7201 | 0.7378 |
| 2015–2016 | 0.7030 | 0.7113 | 0.7152 | 0.7073 |
| 2016–2017 | 0.7103 | 0.7098 | 0.7168 | 0.7154 |
| 2017–2018 | 0.7022 | 0.6889 | 0.7012 | 0.6951 |
| Average | 0.7083 | 0.7094 | 0.7117 | 0.7154 |
| Season | GCN + LASSO | Our Proposed Method (GCN + RF) |
|---|---|---|
| 2012–2013 | 0.7128 | 0.7295 |
| 2013–2014 | 0.6890 | 0.7105 |
| 2014–2015 | 0.6989 | 0.7285 |
| 2015–2016 | 0.7003 | 0.6829 |
| 2016–2017 | 0.7054 | 0.6879 |
| 2017–2018 | 0.6981 | 0.7106 |
| Average | 0.7008 | 0.7083 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, K.; Du, C.; Tan, G. Enhancing Basketball Game Outcome Prediction through Fused Graph Convolutional Networks and Random Forest Algorithm. Entropy 2023, 25, 765. https://doi.org/10.3390/e25050765
Zhao K, Du C, Tan G. Enhancing Basketball Game Outcome Prediction through Fused Graph Convolutional Networks and Random Forest Algorithm. Entropy. 2023; 25(5):765. https://doi.org/10.3390/e25050765
Chicago/Turabian StyleZhao, Kai, Chunjie Du, and Guangxin Tan. 2023. "Enhancing Basketball Game Outcome Prediction through Fused Graph Convolutional Networks and Random Forest Algorithm" Entropy 25, no. 5: 765. https://doi.org/10.3390/e25050765
APA StyleZhao, K., Du, C., & Tan, G. (2023). Enhancing Basketball Game Outcome Prediction through Fused Graph Convolutional Networks and Random Forest Algorithm. Entropy, 25(5), 765. https://doi.org/10.3390/e25050765