
A Simple Approximation Method for the Fisher–Rao Distance between Multivariate Normal Distributions


Abstract

1. Introduction
1.1. The Fisher–Rao Normal Manifold
1.2. Fisher–Rao Distance between Normal Distributions: Some Subfamilies with Closed-Form Formula
- to know explicitly the expression of the Riemannian Fisher–Rao geodesic and
- to integrate, in closed form, the length element along this Riemannian geodesic.
- when the normal distributions are univariate (),
- when we consider the set of normal distributions sharing the same mean (with the embedded submanifold ), and
- when we consider the set of normal distributions sharing the same covariance matrix (with the corresponding embedded submanifold ).
- In the univariate case , the Fisher–Rao distance between and can be derived from the hyperbolic distance [44] expressed in the Poincaré upper space since we havewhere and . It follows thatThus, we have the following expression for the Fisher–Rao distance between univariate normal distributions:withIn particular, we have
- –
- when (same mean),
- –
- when (same variance),
- –
- when and (standard normal).
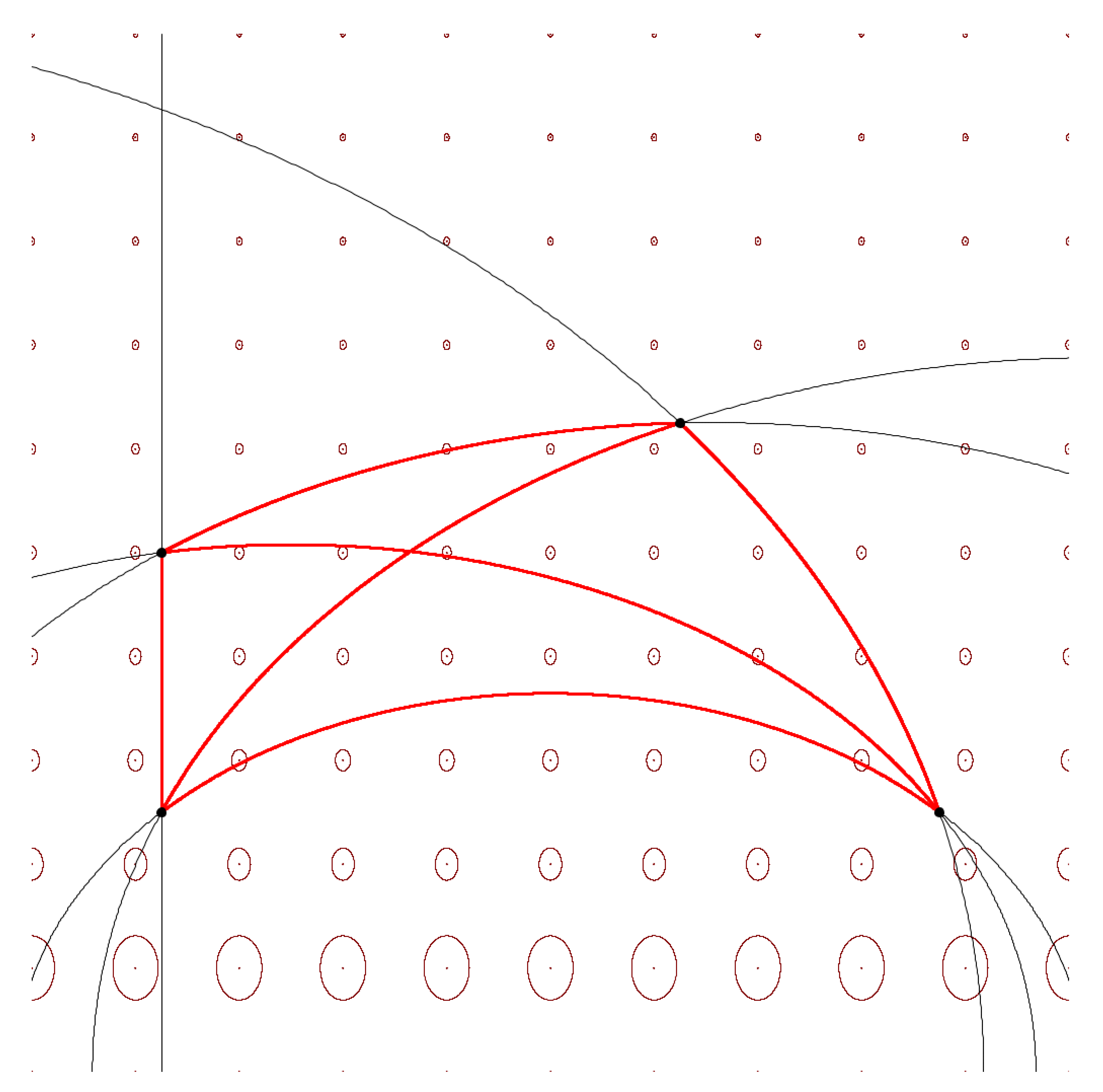
In 1D, the affine-invariance property (Property 1) extends to function as follows:Using one of the many identities between inverse hyperbolic functions (e.g., arctanh, arccosh, arcsinh), we can obtain an equivalent formula for Equation (7). For example, since for , we have equivalently:The Fisher–Rao geodesics are semi-ellipses with centers located on the x-axis. See Appendix A.1 for the parametric equations of Fisher–Rao geodesics between univariate normal distributions. Figure 1 displays four univariate normal distributions with their pairwise geodesics and Fisher–Rao distances.Using the identity with , we also haveSince the inverse hyperbolic cosecant (CSC) function is defined by , we further obtainWe can also writeThus, using the many-conversions formula between inverse hyperbolic functions, we obtain many equivalent different formulas of the Fisher–Rao distance, which are used in the literature. - In the second case, the Fisher–Rao distance between and has been reported in [6,7,45,46,47]:where denotes the i-th generalized largest eigenvalue of matrix M, where the generalized eigenvalues are solutions of the equation . Let us notice that since and . Matrix may not be SPD and thus the ’s are generalized eigenvalues. We may consider instead the SPD matrix which is SPD and such that . The Fisher–Rao distance of Equation (11) can be equivalently written [48] aswhere is the matrix logarithm (unique when M is SPD) and is the matrix Fröbenius norm. This metric distance between SPD matrices although first studied by Siegel [45] in 1964 was rediscovered and analyzed recently in [49] (2003). Let so that .The Riemannian SPD distance enjoys the following well-known invariance properties:
- –
- Invariance by congruence transformation:
- –
- Invariance by inversion:Let be the Cholesky decomposition (unique when ). Then apply the congruence invariance for :We can also consider the factorization where is the unique symmetric square root matrix [50]. Then we have
- The Fisher–Rao distance between and has been reported in closed form [42] (Proposition 3). The method is described with full details in Appendix B. We present a simpler scheme based on the inverse of the symmetric square root factorization [50] of (ith ). Let us use the affine-invariance property of the Fisher–Rao distance under the affine transformation and then apply affine invariance under translation as follows:The right-hand side Fisher–Rao distance is computed from Equation (7) and justified by the method [42] (Proposition 3) described in Appendix B using a rotation matrix R with so thatThen we apply the formula of Equation (23) of [42]. Section 1.5 shall report a simpler closed-form formula by proving that the Fisher–Rao distance between and is a scalar function of their Mahalanobis distance [51] using the algebraic method of maximal invariants [52].
1.3. Fisher–Rao Distance: Totally versus Non-Totally Geodesic Submanifolds
- we do not know the Fisher–Rao geodesics with boundary value conditions (BVP) in closed form but the geodesics with initial value conditions [48] (IVP) are known explicitly using the natural parameters of MVNs,
- we must integrate the line element along the geodesic.
1.4. Contributions and Paper Outline
1.5. A Closed-Form Formula for the Fisher–Rao Distance between Normal Distributions Sharing the Same Covariance Matrix
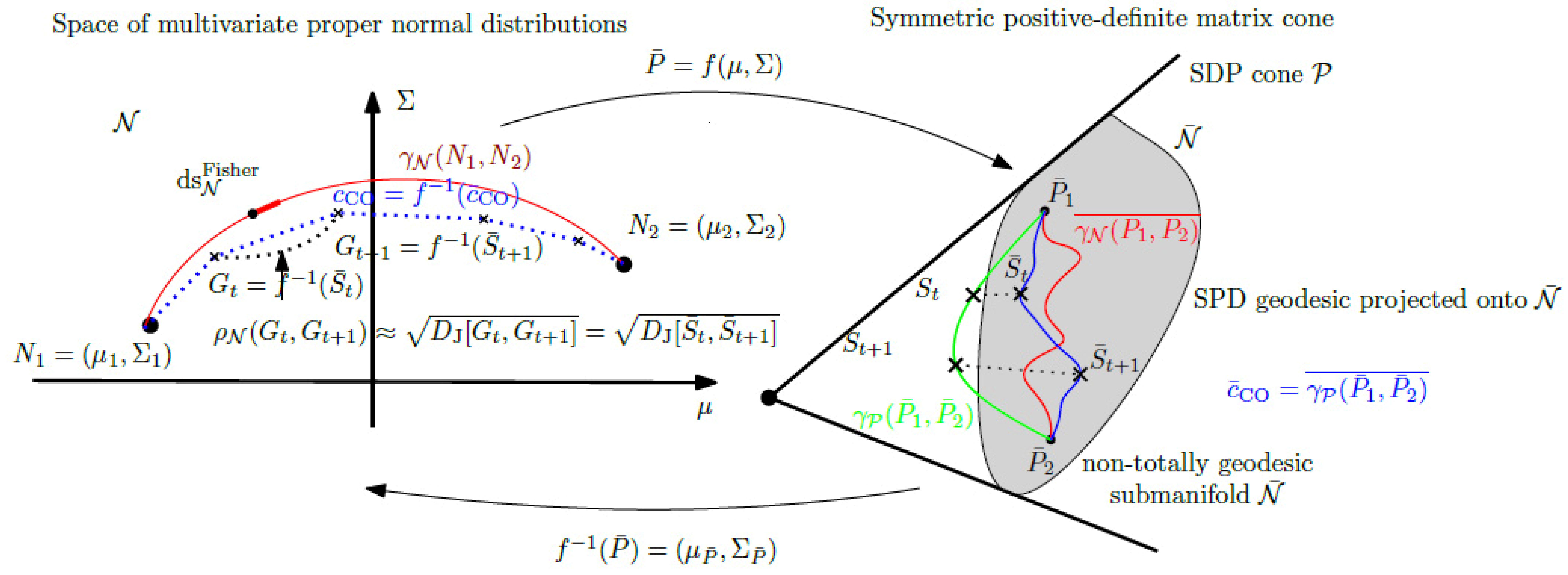
2. Calvo and Oller’s Family of Diffeomorphic Embeddings
3. Approximating the Fisher–Rao Distance
3.1. Approximating Length of Curves
3.2. A Curve Derived from Calvo and Oller’s Embedding
3.3. Some Experiments
- We use the following example of Han and Park [39] (Equation (26)):Their geodesic shooting algorithm [39] evaluates the Fisher–Rao distance to (precision ).We obtain:In that setting, the upper bound is better than the upper bound of Equation (35), and the projected Calvo and Oller geodesic yields the best approximation of the Fisher–Rao distance (Figure 15) with an absolute error of (about relative error). When , we have , when , we obtain , and when we obtain (which is better than the approximation obtained for ). Figure 16 shows the fluctuations of the approximation of the Fisher–Rao distance by the projected C&O curve when T ranges from 3 to 100.
- Bivariate normal and bivariate normal with and . We obtain
- –
- Calvo and Oller lower bound:
- –
- Upper bound of Equation (35):
- –
- upper bound:
- –
- :
- –
- :
- –
- :
- –
- :
- –
- :
- Bivariate normal and bivariate normal with and . We get:
- –
- Calvo and Oller lower bound:
- –
- Upper bound of Equation (35):
- –
- upper bound:
- –
- :
- –
- :
- –
- :
- –
- :
- –
- :
4. Approximating the Smallest Enclosing Fisher–Rao Ball of MVNs
- First, we convert MVN set into the equivalent set of -dimensional SPD matrices using the C&O embedding. We relax the problem of approximating the circumcenter of the smallest enclosing Fisher–Rao ball by
- Second, we approximate the center of the smallest enclosing Riemannian ball of using the iterative smallest enclosing Riemannian ball algorithm in [66] with say iterations. Let denote this approximation center: .
- Finally, we project back onto : . We return as the approximation of .
- Let
- For to T
- –
- Compute the index of the SPD matrix which is farthest from the current circumcenter :
- –
- Update the circumcenter by walking along the geodesic linking to :
- Return
5. Some Information–Geometric Properties of the C&O Embedding
- is an exponential family ⇔ is -autoparallel in (exercise 13.8),
- is a mixture family ⇔ is -autoparallel in (exercise 13.9).
6. Conclusions and Discussion
Supplementary Materials
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Entities | |
| d-variate normal distribution (mean , covariance matrix ) | |
| Probability density function of | |
| Probability density function of | |
| Positive–definite matrix with matrix entries | |
| Mappings | |
| Calvo and Oller mapping [19] (1990) | |
| Calvo and Oller mapping [32] (2002) or [82] | |
| Groups | |
| Group of linear transformations (invertible matrices) | |
| Special linear group ( matrices with unit determinant) | |
| Affine group of dimension d | |
| Sets | |
| Set of multivariate normal distributions (MVNs) | |
| Set of symmetric real matrices | |
| Symmetric positive–definite matrix cone (SPD matrix cone) | |
| Set of SPD matrices with fixed determinant c () | |
| SSPD, | Set of SPD matrices with unit determinant |
| Parameter space of : | |
| , | Set of zero-centered normal distributions |
| Set of normal distributions with fixed | |
| Set of normal distributions with fixed | |
| Set of SPD matrices | |
| Riemannian length elements | |
| MVN Fisher | |
| 0-MVN Fisher | |
| SPD trace | (when , ) |
| SPD Calvo and Oller metric | |
| (with ) | |
| when , in | |
| SPD symmetric space | |
| Siegel upper space | () |
| Manifolds and submanifolds | |
| () | Manifold of multivariate normal distributions |
| Tangent space at | |
| Submanifold of MVNs with prescribed | |
| Submanifold of MVNs with prescribed | |
| manifold of (non-embedded in ) | |
| manifold of (non-embedded in ) | |
| Submanifold of MVN set | |
| where v is an eigenvector of | |
| manifold of symmetric positive–definite matrices | |
| Distances | |
| Fisher–Rao distance between normal distributions and | |
| Riemannian SPD distance between and | |
| Calvo and Oller distance from embedding N to | |
| Symmetric space distance from embedding N to | |
| Hilbert distance | |
| Kullback–Leibler divergence between MVNs and | |
| Jeffreys divergence between MVNs and | |
| Calvo and Oller dissimilarity measure of Equation (26) | |
| Geodesics and curves | |
| Fisher–Rao geodesic between MVNs and | |
| Fisher–Rao geodesic between SPD and | |
| exponential geodesic between MVNs and | |
| mixture geodesic between MVNs and | |
| projection curve (not geodesic) of onto | |
| Metrics and connections | |
| Fisher information metric of MVNs | |
| trace metric | |
| Fisher information metric of centered MVNs | |
| Killing metric studied in [82] | |
| Levi–Civita metric connection | |
| exponential connection | |
| mixture connection |
Appendix A. Geodesics on the Fisher–Rao Normal Manifold
Appendix A.1. Parametric Equations of the Fisher–Rao Geodesics between Univariate Normal Distributions

Appendix A.2. Geodesics with Initial Values on the Multivariate Fisher–Rao Normal Manifold
Appendix B. Fisher–Rao Distance between Normal Distributions Sharing the Same Covariance Matrix
Appendix C. Embedding the Set of Multivariate Normal Distributions in a Riemannian Symmetric Space
Appendix D. Embedding the Set of Multivariate Normal Distributions in the Siegel Upper Space

Appendix E. The Symmetrized Bregman Divergence Expressed as Integral Energies on Dual Geodesics
References
- Amari, S.I. Information Geometry and Its Applications; Applied Mathematical Sciences; Springer: Tokyo, Japan, 2016. [Google Scholar]
- Calin, O.; Udrişte, C. Geometric Modeling in Probability and Statistics; Springer: Berlin/Heidelberg, Germany, 2014; Volume 121. [Google Scholar]
- Lin, Z. Riemannian geometry of symmetric positive definite matrices via Cholesky decomposition. SIAM J. Matrix Anal. Appl. 2019, 40, 1353–1370. [Google Scholar] [CrossRef]
- Soen, A.; Sun, K. On the variance of the Fisher information for deep learning. Adv. Neural Inf. Process. Syst. 2021, 34, 5708–5719. [Google Scholar]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Classification of covariance matrices using a Riemannian-based kernel for BCI applications. Neurocomputing 2013, 112, 172–178. [Google Scholar] [CrossRef]
- Skovgaard, L.T. A Riemannian Geometry of the Multivariate Normal Model; Technical Report 81/3; Statistical Research Unit, Danish Medical Research Council, Danish Social Science Research Council: Copenhagen, Denmark, 1981. [Google Scholar]
- Skovgaard, L.T. A Riemannian geometry of the multivariate normal model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Malagò, L.; Pistone, G. Information geometry of the Gaussian distribution in view of stochastic optimization. In Proceedings of the ACM Conference on Foundations of Genetic Algorithms XIII, Aberystwyth, UK, 17–22 January 2015; pp. 150–162. [Google Scholar]
- Herntier, T.; Peter, A.M. Transversality Conditions for Geodesics on the Statistical Manifold of Multivariate Gaussian Distributions. Entropy 2022, 24, 1698. [Google Scholar] [CrossRef] [PubMed]
- Atkinson, C.; Mitchell, A.F. Rao’s distance measure. SankhyĀ Indian J. Stat. Ser. 1981, 43, 345–365. [Google Scholar]
- Radhakrishna Rao, C. Information and accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81–91. [Google Scholar]
- Chen, X.; Zhou, J.; Hu, S. Upper bounds for Rao distance on the manifold of multivariate elliptical distributions. Automatica 2021, 129, 109604. [Google Scholar] [CrossRef]
- Hotelling, H. Spaces of statistical parameters. Bull. Am. Math. Soc. 1930, 36, 191. [Google Scholar]
- Cencov, N.N. Statistical Decision Rules and Optimal Inference; American Mathematical Soc.: Providence, RI, USA, 2000; Volume 53. [Google Scholar]
- Bauer, M.; Bruveris, M.; Michor, P.W. Uniqueness of the Fisher–Rao metric on the space of smooth densities. Bull. Lond. Math. Soc. 2016, 48, 499–506. [Google Scholar] [CrossRef]
- Fujiwara, A. Hommage to Chentsov’s theorem. Inf. Geom. 2022, 1–20. [Google Scholar] [CrossRef]
- Bruveris, M.; Michor, P.W. Geometry of the Fisher–Rao metric on the space of smooth densities on a compact manifold. Math. Nachrichten 2019, 292, 511–523. [Google Scholar] [CrossRef]
- Burbea, J.; Oller i Sala, J.M. On Rao Distance Asymptotic Distribution; Technical Report Mathematics Preprint Series No. 67; Universitat de Barcelona: Barcelona, Spain, 1989. [Google Scholar]
- Calvo, M.; Oller, J.M. A distance between multivariate normal distributions based in an embedding into the Siegel group. J. Multivar. Anal. 1990, 35, 223–242. [Google Scholar] [CrossRef]
- Rios, M.; Villarroya, A.; Oller, J.M. Rao distance between multivariate linear normal models and their application to the classification of response curves. Comput. Stat. Data Anal. 1992, 13, 431–445. [Google Scholar] [CrossRef]
- Park, P.S.; Kshirsagar, A.M. Distances between normal populations when covariance matrices are unequal. Commun. Stat. Theory Methods 1994, 23, 3549–3556. [Google Scholar] [CrossRef]
- Gruber, M.H. Some applications of the Rao distance to shrinkage estimators. Commun. Stat. Methods 2008, 37, 180–193. [Google Scholar] [CrossRef]
- Strapasson, J.E.; Pinele, J.; Costa, S.I. Clustering using the Fisher-Rao distance. In Proceedings of the 2016 IEEE Sensor Array and Multichannel Signal Processing Workshop (SAM), Rio de Janeiro, Brazil, 10–13 July 2016; pp. 1–5. [Google Scholar]
- Le Brigant, A.; Puechmorel, S. Quantization and clustering on Riemannian manifolds with an application to air traffic analysis. J. Multivar. Anal. 2019, 173, 685–703. [Google Scholar] [CrossRef]
- Said, S.; Bombrun, L.; Berthoumieu, Y. Texture classification using Rao’s distance on the space of covariance matrices. In Proceedings of the Geometric Science of Information: Second International Conference, GSI 2015, Proceedings 2, Palaiseau, France, 28–30 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 371–378. [Google Scholar]
- Legrand, L.; Grivel, E. Evaluating dissimilarities between two moving-average models: A comparative study between Jeffrey’s divergence and Rao distance. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 8 August–2 September 2016; pp. 205–209. [Google Scholar]
- Halder, A.; Georgiou, T.T. Gradient flows in filtering and Fisher-Rao geometry. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 4281–4286. [Google Scholar]
- Collas, A.; Breloy, A.; Ren, C.; Ginolhac, G.; Ovarlez, J.P. Riemannian optimization for non-centered mixture of scaled Gaussian distributions. arXiv 2022, arXiv:2209.03315. [Google Scholar]
- Liang, T.; Poggio, T.; Rakhlin, A.; Stokes, J. Fisher-Rao metric, geometry, and complexity of neural networks. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, PMLR, Naha, Japan, 16–18 April 2019; pp. 888–896. [Google Scholar]
- Yoshizawa, S.; Tanabe, K. Dual differential geometry associated with the Kullback-Leibler information on the Gaussian distributions and its 2-parameter deformations. SUT J. Math. 1999, 35, 113–137. [Google Scholar] [CrossRef]
- Shima, H. The Geometry of Hessian Structures; World Scientific: Singapore, 2007. [Google Scholar]
- Calvo, M.; Oller, J.M. A distance between elliptical distributions based in an embedding into the Siegel group. J. Comput. Appl. Math. 2002, 145, 319–334. [Google Scholar] [CrossRef]
- Burbea, J. Informative Geometry of Probability Spaces; Technical Report; Pittsburgh Univ. PA Center for Multivariate Analysis: Pittsburgh, PA, USA, 1984. [Google Scholar]
- Eriksen, P.S. Geodesics Connected with the Fischer Metric on the Multivariate Normal Manifold; Institute of Electronic Systems, Aalborg University Centre: Aalborg, Denmark, 1986. [Google Scholar]
- Berkane, M.; Oden, K.; Bentler, P.M. Geodesic estimation in elliptical distributions. J. Multivar. Anal. 1997, 63, 35–46. [Google Scholar] [CrossRef]
- Imai, T.; Takaesu, A.; Wakayama, M. Remarks on Geodesics for Multivariate Normal Models; Technical Report; Faculty of Mathematics, Kyushu University: Fukuoka, Japan, 2011. [Google Scholar]
- Inoue, H. Group theoretical study on geodesics for the elliptical models. In Proceedings of the Geometric Science of Information: Second International Conference, GSI 2015, Proceedings 2, Palaiseau, France, 28–30 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 605–614. [Google Scholar]
- Strapasson, J.E.; Porto, J.P.; Costa, S.I. On bounds for the Fisher-Rao distance between multivariate normal distributions. AIP Conf. Proc. 2015, 1641, 313–320. [Google Scholar]
- Han, M.; Park, F.C. DTI segmentation and fiber tracking using metrics on multivariate normal distributions. J. Math. Imaging Vis. 2014, 49, 317–334. [Google Scholar] [CrossRef]
- Pilté, M.; Barbaresco, F. Tracking quality monitoring based on information geometry and geodesic shooting. In Proceedings of the 2016 17th International Radar Symposium (IRS), Krakow, Poland, 10–12 May 2016; pp. 1–6. [Google Scholar]
- Barbaresco, F. Souriau exponential map algorithm for machine learning on matrix Lie groups. In Proceedings of the Geometric Science of Information: 4th International Conference, GSI 2019, Proceedings 4, Toulouse, France, 27–29 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 85–95. [Google Scholar]
- Pinele, J.; Strapasson, J.E.; Costa, S.I. The Fisher–Rao distance between multivariate normal distributions: Special cases, bounds and applications. Entropy 2020, 22, 404. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connexion with graphs. In Edsger Wybe Dijkstra: His Life, Work, and Legacy; Association for Computing Machinery: New York, NY, USA, 2022; pp. 287–290. [Google Scholar]
- Anderson, J.W. Hyperbolic Geometry; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Siegel, C.L. Symplectic Geometry; First Printed in 1964; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- James, A.T. The variance information manifold and the functions on it. In Multivariate Analysis–III; Elsevier: Amsterdam, The Netherlands, 1973; pp. 157–169. [Google Scholar]
- Wells, J.; Cook, M.; Pine, K.; Robinson, B.D. Fisher-Rao distance on the covariance cone. arXiv 2020, arXiv:2010.15861. [Google Scholar]
- Calvo, M.; Oller, J.M. An explicit solution of information geodesic equations for the multivariate normal model. Stat. Risk Model. 1991, 9, 119–138. [Google Scholar] [CrossRef]
- Förstner, W.; Moonen, B. A metric for covariance matrices. In Geodesy-the Challenge of the 3rd Millennium; Springer: Berlin/Heidelberg, Germany, 2003; pp. 299–309. [Google Scholar]
- Dolcetti, A.; Pertici, D. Real square roots of matrices: Differential properties in semi-simple, symmetric and orthogonal cases. arXiv 2020, arXiv:2010.15609. [Google Scholar]
- Mahalanobis, P.C. On the generalised distance in statistics. In Proceedings of the National Institute of Science of India; Springer: New Delhi, India, 1936; Volume 12, pp. 49–55. [Google Scholar]
- Eaton, M.L. Group Invariance Applications in Statistics; Institute of Mathematical Statistics: Beachwood, OH, USA, 1989. [Google Scholar]
- Godinho, L.; Natário, J. An introduction to Riemannian geometry: With Applications to Mechanics and Relativity. In Universitext; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Strapasson, J.E.; Pinele, J.; Costa, S.I. A totally geodesic submanifold of the multivariate normal distributions and bounds for the Fisher-Rao distance. In Proceedings of the IEEE Information Theory Workshop (ITW), Cambridge, UK, 1–11 September 2016; pp. 61–65. [Google Scholar]
- Chen, X.; Zhou, J. Multisensor Estimation Fusion on Statistical Manifold. Entropy 2022, 24, 1802. [Google Scholar] [CrossRef]
- Cherian, A.; Sra, S. Riemannian dictionary learning and sparse coding for positive definite matrices. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2859–2871. [Google Scholar] [CrossRef]
- Nguyen, X.S. Geomnet: A neural network based on Riemannian geometries of SPD matrix space and Cholesky space for 3d skeleton-based interaction recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13379–13389. [Google Scholar]
- Dolcetti, A.; Pertici, D. Differential properties of spaces of symmetric real matrices. arXiv 2018, arXiv:1807.01113. [Google Scholar]
- Verdoolaege, G.; Scheunders, P. On the geometry of multivariate generalized Gaussian models. J. Math. Imaging Vis. 2012, 43, 180–193. [Google Scholar] [CrossRef]
- Ali, S.M.; Silvey, S.D. A general class of coefficients of divergence of one distribution from another. J. R. Stat. Soc. Ser. B 1966, 28, 131–142. [Google Scholar] [CrossRef]
- Csiszár, I. Information-type measures of difference of probability distributions and indirect observation. Stud. Sci. Math. Hung. 1967, 2, 229–318. [Google Scholar]
- Nielsen, F.; Okamura, K. A note on the f-divergences between multivariate location-scale families with either prescribed scale matrices or location parameters. arXiv 2022, arXiv:2204.10952. [Google Scholar]
- Moakher, M.; Zéraï, M. The Riemannian geometry of the space of positive-definite matrices and its application to the regularization of positive-definite matrix-valued data. J. Math. Imaging Vis. 2011, 40, 171–187. [Google Scholar] [CrossRef]
- Dolcetti, A.; Pertici, D. Elliptic isometries of the manifold of positive definite real matrices with the trace metric. Rend. Circ. Mat. Palermo Ser. 2 2021, 70, 575–592. [Google Scholar] [CrossRef]
- Nielsen, F. The Siegel–Klein Disk: Hilbert Geometry of the Siegel Disk Domain. Entropy 2020, 22, 1019. [Google Scholar] [CrossRef]
- Arnaudon, M.; Nielsen, F. On approximating the Riemannian 1-center. Comput. Geom. 2013, 46, 93–104. [Google Scholar] [CrossRef]
- Ceolin, S.R.; Hancock, E.R. Computing gender difference using Fisher-Rao metric from facial surface normals. In Proceedings of the 25th SIBGRAPI Conference on Graphics, Patterns and Images, Ouro Preto, Brazil, 22–25 August 2012; pp. 336–343. [Google Scholar]
- Wang, Q.; Li, P.; Zhang, L. G2DeNet: Global Gaussian distribution embedding network and its application to visual recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2730–2739. [Google Scholar]
- Miyamoto, H.K.; Meneghetti, F.C.; Costa, S.I. The Fisher–Rao loss for learning under label noise. Inf. Geom. 2022, 1–20. [Google Scholar] [CrossRef]
- Kurtek, S.; Bharath, K. Bayesian sensitivity analysis with the Fisher–Rao metric. Biometrika 2015, 102, 601–616. [Google Scholar] [CrossRef]
- Marti, G.; Andler, S.; Nielsen, F.; Donnat, P. Optimal transport vs. Fisher-Rao distance between copulas for clustering multivariate time series. In Proceedings of the 2016 IEEE Statistical Signal Processing Workshop (SSP), Palma de Mallorca, Spain, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Tang, M.; Rong, Y.; Zhou, J.; Li, X.R. Information geometric approach to multisensor estimation fusion. IEEE Trans. Signal Process. 2018, 67, 279–292. [Google Scholar] [CrossRef]
- Wang, W.; Wang, R.; Huang, Z.; Shan, S.; Chen, X. Discriminant analysis on Riemannian manifold of Gaussian distributions for face recognition with image sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2048–2057. [Google Scholar]
- Li, P.; Wang, Q.; Zeng, H.; Zhang, L. Local log-Euclidean multivariate Gaussian descriptor and its application to image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 803–817. [Google Scholar] [CrossRef]
- Picot, M.; Messina, F.; Boudiaf, M.; Labeau, F.; Ayed, I.B.; Piantanida, P. Adversarial robustness via Fisher-Rao regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2698–2710. [Google Scholar] [CrossRef] [PubMed]
- Collas, A.; Bouchard, F.; Ginolhac, G.; Breloy, A.; Ren, C.; Ovarlez, J.P. On the Use of Geodesic Triangles between Gaussian Distributions for Classification Problems. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 5697–5701. [Google Scholar]
- Murena, P.A.; Cornuéjols, A.; Dessalles, J.L. Opening the parallelogram: Considerations on non-Euclidean analogies. In Proceedings of the Case-Based Reasoning Research and Development: 26th International Conference, ICCBR 2018, Proceedings 26, Stockholm, Sweden, 9–12 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 597–611. [Google Scholar]
- Popović, B.; Janev, M.; Krstanović, L.; Simić, N.; Delić, V. Measure of Similarity between GMMs Based on Geometry-Aware Dimensionality Reduction. Mathematics 2022, 11, 175. [Google Scholar] [CrossRef]
- Micchelli, C.A.; Noakes, L. Rao distances. J. Multivar. Anal. 2005, 92, 97–115. [Google Scholar] [CrossRef]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef]
- Davis, J.; Dhillon, I. Differential entropic clustering of multivariate Gaussians. Adv. Neural Inf. Process. Syst. 2006, 19, 337–344. [Google Scholar]
- Lovrić, M.; Min-Oo, M.; Ruh, E.A. Multivariate normal distributions parametrized as a Riemannian symmetric space. J. Multivar. Anal. 2000, 74, 36–48. [Google Scholar] [CrossRef]
- Welzl, E. Smallest enclosing disks (balls and ellipsoids). In Proceedings of the New Results and New Trends in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 359–370. [Google Scholar]
- Gonzalez, T.F. Clustering to minimize the maximum intercluster distance. Theor. Comput. Sci. 1985, 38, 293–306. [Google Scholar] [CrossRef]
- Acharyya, S.; Banerjee, A.; Boley, D. Bregman divergences and triangle inequality. In Proceedings of the 2013 SIAM International Conference on Data Mining, SIAM, Austin, TX, USA, 2–4 May 2013; pp. 476–484. [Google Scholar]
- Ohara, A.; Suda, N.; Amari, S.i. Dualistic differential geometry of positive definite matrices and its applications to related problems. Linear Algebra Appl. 1996, 247, 31–53. [Google Scholar] [CrossRef]
- Nock, R.; Nielsen, F. Fitting the smallest enclosing Bregman ball. In Proceedings of the Machine Learning: ECML 2005: 16th European Conference on Machine Learning, Proceedings 16, Porto, Portugal, 3–7 October 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 649–656. [Google Scholar]
- Ohara, A. Doubly autoparallel structure on positive definite matrices and its applications. In Proceedings of the International Conference on Geometric Science of Information, Toulouse, France, 27–29 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 251–260. [Google Scholar]
- Globke, W.; Quiroga-Barranco, R. Information geometry and asymptotic geodesics on the space of normal distributions. Inf. Geom. 2021, 4, 131–153. [Google Scholar] [CrossRef]
- Nielsen, F.; Sun, K. Clustering in Hilbert’s projective geometry: The case studies of the probability simplex and the elliptope of correlation matrices. In Geometric Structures of Information; Springer: Berlin/Heidelberg, Germany, 2019; pp. 297–331. [Google Scholar]
- Journée, M.; Nesterov, Y.; Richtárik, P.; Sepulchre, R. Generalized power method for sparse principal component analysis. J. Mach. Learn. Res. 2010, 11, 517–553. [Google Scholar]
- Verdoolaege, G. A new robust regression method based on minimization of geodesic distances on a probabilistic manifold: Application to power laws. Entropy 2015, 17, 4602–4626. [Google Scholar] [CrossRef]
- Chandrupatla, T.R.; Osler, T.J. The perimeter of an ellipse. Math. Sci. 2010, 35. [Google Scholar]
- Householder, A.S. Unitary triangularization of a nonsymmetric matrix. J. ACM 1958, 5, 339–342. [Google Scholar] [CrossRef]
- Fernandes, M.A.; San Martin, L.A. Fisher information and α-connections for a class of transformational models. Differ. Geom. Appl. 2000, 12, 165–184. [Google Scholar] [CrossRef]
- Fernandes, M.A.; San Martin, L.A. Geometric proprieties of invariant connections on SL(n,R)/SO(n). J. Geom. Phys. 2003, 47, 369–377. [Google Scholar] [CrossRef]
- Bridson, M.R.; Haefliger, A. Metric Spaces of Non-Positive Curvature; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 319. [Google Scholar]
- Frauendiener, J.; Jaber, C.; Klein, C. Efficient computation of multidimensional theta functions. J. Geom. Phys. 2019, 141, 147–158. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
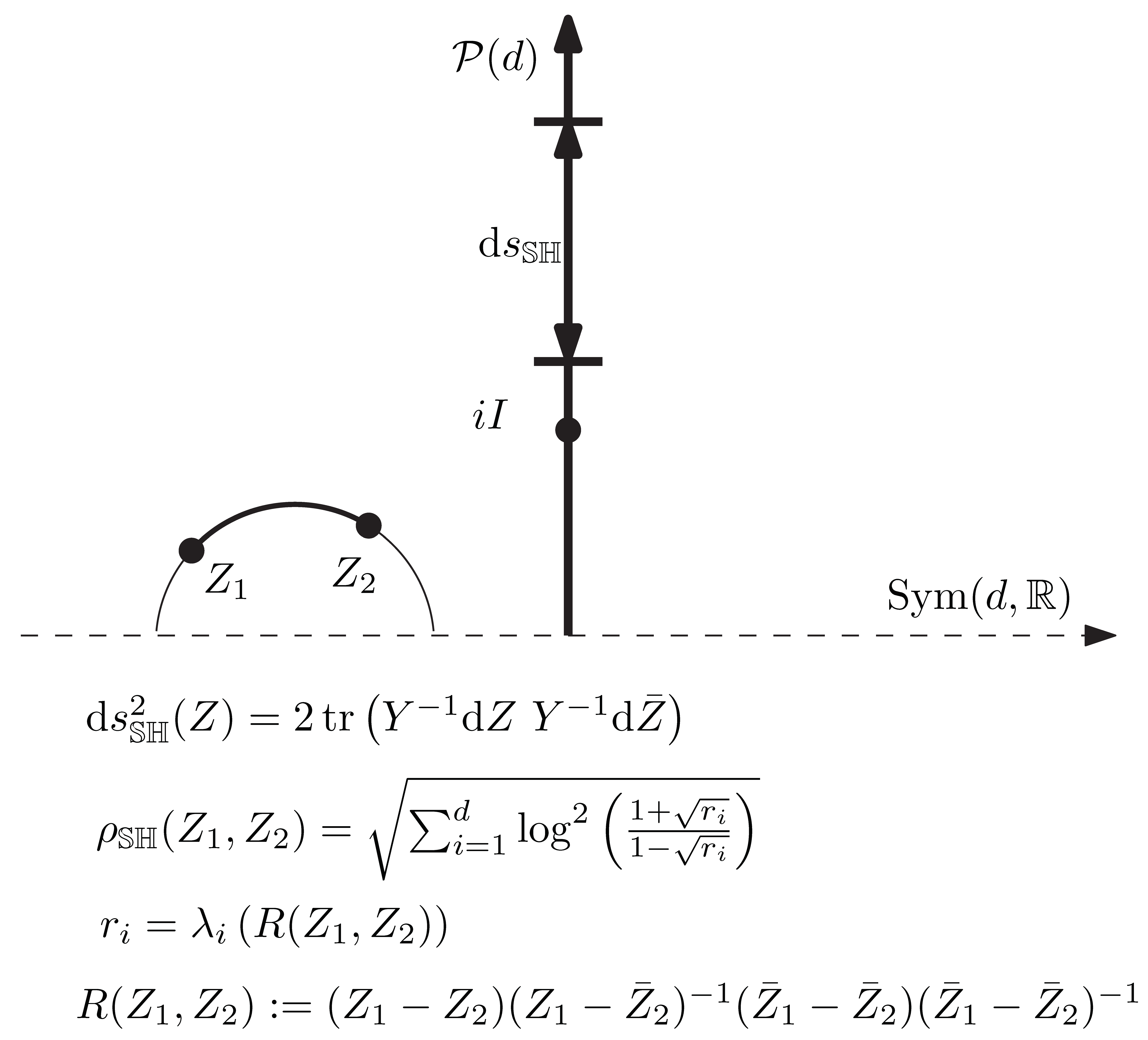{kind=link}
| d | |||||
|---|---|---|---|---|---|
| 1 | 1.0025 | 1.0414 | 1.1521 | 1.0236 | 1.0154 |
| 2 | 1.0167 | 1.0841 | 1.1923 | 1.0631 | 1.0416 |
| 3 | 1.0182 | 1.8997 | 2.6072 | 1.9965 | 1.07988 |
| 4 | 1.0207 | 2.0793 | 1.8080 | 2.1687 | 1.1873 |
| 5 | 1.0324 | 4.1207 | 12.3804 | 5.6170 | 4.2349 |
| d | |||
|---|---|---|---|
| 1 | 1.7563 | 1.8020 | 3.1654 |
| 2 | 3.2213 | 3.3194 | 6.012 |
| 3 | 4.6022 | 4.7642 | 8.7204 |
| 4 | 5.9517 | 6.1927 | 11.3990 |
| 5 | 7.156 | 7.3866 | 13.8774 |
| d | ||||
|---|---|---|---|---|
| 1 | 1.0569 | 1.1405 | 1.139 | 1.0734 |
| 5 | 1.1599 | 1.4696 | 1.5201 | 1.1819 |
| 10 | 1.2180 | 1.6963 | 1.7887 | 1.2184 |
| 11 | 1.2260 | 1.7333 | 1.8285 | 1.2235 |
| 12 | 1.2301 | 1.7568 | 1.8539 | 1.2282 |
| 15 | 1.2484 | 1.8403 | 1.9557 | 1.2367 |
| 20 | 1.2707 | 1.9519 | 2.0851 | 1.2466 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nielsen, F. A Simple Approximation Method for the Fisher–Rao Distance between Multivariate Normal Distributions. Entropy 2023, 25, 654. https://doi.org/10.3390/e25040654
Nielsen F. A Simple Approximation Method for the Fisher–Rao Distance between Multivariate Normal Distributions. Entropy. 2023; 25(4):654. https://doi.org/10.3390/e25040654
Chicago/Turabian StyleNielsen, Frank. 2023. "A Simple Approximation Method for the Fisher–Rao Distance between Multivariate Normal Distributions" Entropy 25, no. 4: 654. https://doi.org/10.3390/e25040654
APA StyleNielsen, F. (2023). A Simple Approximation Method for the Fisher–Rao Distance between Multivariate Normal Distributions. Entropy, 25(4), 654. https://doi.org/10.3390/e25040654