
Posterior Averaging Information Criterion


Division of Biostatistics and Bioinformatics, Department of Public Health Sciences, Pennsylvania State University, Hershey, PA 17033, USA
Entropy 2023, 25(3), 468; https://doi.org/10.3390/e25030468
Submission received: 15 November 2022
/
Revised: 22 February 2023
/
Accepted: 27 February 2023
/
Published: 7 March 2023
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:We propose a new model selection method, named the posterior averaging information criterion, for Bayesian model assessment to minimize the risk of predicting independent future observations. The theoretical foundation is built on the Kullback–Leibler divergence to quantify the similarity between the proposed candidate model and the underlying true model. From a Bayesian perspective, our method evaluates the candidate models over the entire posterior distribution in terms of predicting a future independent observation. Without assuming that the true distribution is contained in the candidate models, the new criterion is developed by correcting the asymptotic bias of the posterior mean of the in-sample log-likelihood against out-of-sample log-likelihood, and can be generally applied even for Bayesian models with degenerate non-informative priors. Simulations in both normal and binomial settings demonstrate superior small sample performance.
1. Introduction
Model selection plays a key role in statistical modeling and machine learning. Information theoretic criteria, such as Akaike information criterion (AIC) [1] minimum description length [2] and Schwarz information criterion [3], have been frequently and widely exploited with profound impact on many research fields.
Among these popular methods, a substantial group of model selection criteria was proposed based on the Kullback–Leibler (K-L) information divergence [4]. In the context of model selection, it provides an objective measure to quantify the overall closeness of a probability distribution (the candidate model) and the underlying true model. On both theoretical and applied fronts, K-L based information criteria have drawn a huge amount of attention, and a rich body of literature now exists for both frequentist and Bayesian modeling.
Here we will focus on predictive model selection. To choose a proper criterion for a statistical data analysis project, it is essential to distinguish the ultimate goal of modeling. Geisser & Eddy [5] challenged researchers with two fundamental questions that should be asked in advance of any procedure conducted for model selection:
- Which of the models best explains a given set of data?
- Which of the models yields the best predictions for future observations from the same process that generated the given set of data?
The first question, which concerns the accuracy of the model in describing the current data, has been an empirical problem for many years. It represents the explanatory perspective. The second question, which represents the predictive perspective, concerns the accuracy of the model in predicting future data, having drawn substantial attention in recent decades. If an infinitely large quantity of data is available, the predictive perspective and the explanatory perspective may converge. However, with a limited number of observations we encounter in practice, predictive model selection methods should achieve an optimal balance between goodness of fit and parsimony, for example, as we have seen in AIC.
Compared with frequentist methods, Bayesian approaches to statistical inference have unique concerns regarding the interpretation of parameters and models. However, many earlier Bayesian K-L information criteria, such as Deviance Information Criterion (DIC) [6], follow essentially the frequentist philosophy insofar as they select a model using plug-in estimators of the parameters. Subsequently, the parameter uncertainty is largely ignored. Such a paradigm has changed since the Bayesian predictive information criterion (BPIC) [7], as model selection criteria were developed over the entire posterior distribution. Nevertheless, BPIC has its own limitations, particularly with asymmetric posterior distributions. More importantly, BPIC is undefined under improper prior distributions, which limits its use in practice. More details can be found in Section 3 with a review of alternative methods.
The rest of this article is organized as follows. To explain the motivation of the proposed Bayesian criterion, in Section 2 we review the K-L divergence, its application and development in frequentist statistics, and the adaption to Bayesian modeling based on plug-in parameter estimation. In Section 3, major attention is given to the K-L based predictive criterion for models evaluated by averaging over the posterior distributions of parameters. To select models with better predictive performance, a generally applicable method, named the posterior averaging information criterion (PAIC), is proposed for comparing different Bayesian statistical models under mild regularity conditions. The new criterion is developed by correcting the asymptotic bias of using the posterior mean of the log-likelihood as an estimator of its expected log-likelihood, and we prove that the asymptotic property holds even though the candidate models are misspecified. In Section 4, we present some numerical studies in both normal and binomial cases to investigate its performance with small sample sizes. We also provide a real data variable selection example in Section 5 to exhibit possible differences between the explanatory and predictive approaches. We conclude with a few summary remarks and discussions in Section 6.
2. Kullback–Leibler Divergence and Model Selection
Kullback & Leibler [4] derived an information measure to assess the dissimilarity between any two models. If we assume that and , respectively, represent the probability density distributions of the ‘true model’ and the ‘approximate model’ on the same measurable space, the K-L divergence is defined by
which is always non-negative, reaching the minimum value of 0 when f is the same as g almost surely. It is interpreted as the ‘information’ loss when g is used to approximate f. Namely, the smaller the value of , the closer we consider the model g to be to the true distribution.
Only the second term of in (1) is relevant in practice to compare different possible models g without full knowledge of the true distribution. This is because the first term, , is a constant that depends on only the unknown true distribution f, and can be neglected in model comparison for given data.
Let be n independent observations of the data following probability density function . is a future independent observation following the same density function , representing an unknown but potentially observable quantity [8]. Without exactly knowing , we denote a model m with density among a list of potential operating models . For notational purposes, we ignore the model index m when there is no ambiguity. The true model f is referred to as the unknown data generating mechanism, not necessarily to be encompassed in any approximate model family of .
As the sample size , the average of the log-likelihood
tends to by the law of large numbers, which suggests how we can estimate the second term of .
The model selection based on the K-L divergence is straightforward when all the operating models are fixed probability distributions, i.e., . The model with the largest empirical log-likelihood is favored, when the observed data are used as the test sample. However, when the distribution family contains some unknown parameters , the direct comparison becomes no longer feasible. A typical strategy is to conduct the model fitting first, and then compare the operating models specified at the fitted parameters. In this case, the same data are indeed used twice—in both model fitting (as the training sample) and evaluation (as the test sample). Therefore, the in-sample log-likelihood is not optimal for the predictive modeling. For a desirable out-of-sample predictive performance, a common idea is to identify a bias correction term to rectify the over-estimation bias of the in-sample estimator, which is also the focus of this work.
In the frequentist setting, the general model selection procedure chooses candidate models specified by some point estimate based on a certain statistical principle such as maximum likelihood. A considerable amount of theoretical research has addressed this problem by correcting for the bias of in estimation of [1,9,10,11]. A nice review can be found in Burnham Anderson [12].
Since the introduction of the AIC [1], researchers have commonly applied frequentist model selection methods into Bayesian modeling. However, the differences in the underlying philosophies between Bayesian and frequentist statistical inference caution against such direct applications. There also have been a few attempts to specialize the K-L divergence for Bayesian model selection (see, for example, [5,13,14]) in the last century. These methods are limited either in the scope of methodology or computational feasibility, especially when the parameters of the Bayesian models are in high-dimensional hierarchical structures.
The seminal work of Spiegelhalter et al. [6,15] proposed DIC,
as a Bayesian adaption of AIC and implemented it using Gibbs sampling (BUGS) [16], where is the deviance function, is the posterior mean and is the effective number of parameters. Although its establishment lacks a theoretical foundation [17,18], , as a model selection measure, heuristically estimates , the expected out-of-sample log-likelihood specified at the posterior mean, after assuming that the proposed model encompasses the true model. Alternative methods can be found either using a similar approach for mixed-effects models [19,20,21] or using numerical approximation [22] to estimate cross-validative predictive loss [23].
3. Posterior Averaging Information Criterion
The preceding methods in general can be viewed as Bayesian adaptation of the information criteria originally designed for frequentist statistics, when each model is assessed in terms of the similarity between the true distribution f and the model density function specified by the plug-in parameters. This may not be ideal since, in contrast to frequentist modeling, “Bayesian inference is the process of fitting a probability model to a set of data and summarizing the result by a probability distribution on the parameters of the model and on unobserved quantities such as predictions for new observations” [8]. Rather than considering a model specified by a point estimate, it is more reasonable to assess the goodness of a Bayesian model in terms of the posterior distribution.
3.1. Rationale and the Proposed Method
Ando [7] proposed an estimator for the posterior averaged discrepancy function,
Under certain regularity conditions, it was shown that an asymptotic unbiased estimator of is
Here, is the prior distribution, is the posterior mode, K is the cardinality of , and matrices and are some empirical estimators for the Bayesian asymptotic Hessian matrix,
and Bayesian asymptotic Fisher information matrix,
where .
The Bayesian predictive information criterion (BPIC) was introduced as . It is applicable when the true model f is not necessarily in the specified family of probability distributions. In model comparison, the candidate model with a minimum BPIC value is favored. However, it has the following limitations in practice.
- 1.
which shows that it was actually the plug-in estimator , rather than natural estimator , was used in estimation of for bias correction. Compared with the natural estimator, the estimation efficiency of using plug-in estimator is suboptimal when the posterior distribution is asymmetric.
- 2.
- The BPIC cannot be calculated when the prior distribution is degenerate, a common situation in Bayesian analysis when an objective non-informative prior is selected. For example, if we use non-informative prior for the mean parameter of the normal distribution in the following Section 4.1, the values of and in Equation (3) are undefined.
In order to avoid those drawbacks, we propose a new model selection criterion in terms of the posterior mean of the empirical log-likelihood , a natural estimator of estimand . Without losing any of the attractive properties of BPIC, the new criterion expands the model scope to all regular Bayesian models. As we will show in the simulation study, empirically it also improves the unbiased property for small samples, and enhances the robustness of the estimation.
Because all the data are used for both model fitting and model selection, always overestimates . To correct the estimation bias from the overuse of the data, we have the following theorem.
Theorem 1.
Let be n independent observations drawn from the probability cumulative distribution with density function . Consider as a family of candidate statistical models that do not necessarily contain the true distribution f, where is the p-dimensional vector of unknown parameters, with prior distribution . Under the following three regularity conditions:
- C1:
- Both the log density function and the log unnormalized posterior density are twice continuously differentiable in the compact parameter space Θ;
- C2:
- The expected posterior mode is unique in Θ;
- C3:
- The Hessian matrix of is non-singular at ,
the bias of for η can be approximated asymptotically without bias by
where is the posterior mode that maximizes the posterior distribution and
Proof.
Recall that the quantity of interest is . To estimate it, we first check
and expand it about ,
The first term can be linked to the empirical log likelihood function as follows:
where the last equation holds due to Lemma A5 (together with other Lemmas, provided in the Appendix A).
The second term vanishes since
as is the expected posterior mode.
Using Lemma A4, the third term can be rewritten as
By substituting each term in Equation (5) and neglecting the residual term, we obtain
Recall that we have defined , so that asymptotically we have
Therefore, can be estimated by
Replacing by , by and by , we obtain as an asymptotically unbiased estimate for . □
With the above result, we propose a new predictive criterion for Bayesian modeling, named the Posterior Averaging Information Criterion (PAIC),
The candidate models with small criterion values (6) are preferred for the purpose of model selection.
Remark 1.
PAIC selects the candidate models with optimal performance to predict a future outcome.
The optimality is defined in a sense to maximize the out-of-sample log density , which is equivalent to minimize the posterior predictive K-L divergence.
Remark 2.
PAIC is derived without assuming that the approximating distributions contain the truth.
In another word, PAIC is generally applicable even if all candidate models are misspecified. In such settings, rather than select the true model, the goal is to identify the best candidate model(s) with small PAICs among all models under consideration. Similar to other K-L based information criteria, we consider a model is better if its PAIC is smaller with a difference larger than 2.
Remark 3.
The averaging over the posterior distribution in empirical likelihood helps differentiate the candidate models.
The posterior distribution function, rather than a point estimator, represents the current best knowledge from a Bayesian perspective. In some cases, two candidate models may have identical posterior mean but different posterior distributions. (A simple example could be in the setting of Section 4.1, when model A has and model B has in the prior distribution.) Apparently, Bayesian model assessment with respect to the posterior distribution is more effective in model selection. When the posterior distribution of the parameters is asymmetric, the estimation of information criterion averaged over the posterior is also more robust than plugging in a point estimator.
Remark 4.
PAIC can be applied to Bayesian models with flexible prior structures.
For example, in cases when the prior distributions are consistent and sample size dependent [24,25], the information in the prior distribution does not degenerate asymptotically, but is accommodated spontaneously in empirical log-likelihood and bias-correction for predictive assessment. Unlike the BPIC, PAIC relaxes the restriction in common prior distribution specification. It is well-defined and can cope with degenerate non-informative prior distributions for parameters. The bias correction term is closely related to the concept of measuring a Bayesian model’s complexity [26]. Particularly, when the candidate model is true and has no hierarchical structures, and the prior distribution is non-informative with a dimension of p, we have exactly , which is similar to the bias correction in AIC [1].
3.2. Relevant Methods for the Posterior Averaged K-L Discrepancy
Rather than deriving the bias correction analytically, resampling approaches, such as cross-validation and bootstrap, can also be used to measure the posterior averaged K-L discrepancy. Plummer [22] introduced the expected deviance penalized loss with ‘expected deviance’ defined as
which is a special case of the predictive discrepancy measure [27]. The standard cross-validation method can also be applied in this circumstance to estimate , simply by considering the K-L discrepancy as the utility function of [28] and further investigated by [29]. The estimation of the bootstrap error correction with bootstrap analogues
and
for was discussed by Ando [7] as a Bayesian adaptation of frequentist model selection [10]. Although numeric algorithms such as importance sampling can be used for intensive computation, one caveat is that it may cause inaccurate estimation in practice if some observation was influential [28]. To address that problem, Vehtari [30] proposed Pareto smoothed importance sampling, a new algorithm for regularizing importance weights, and developed a numerical tool [31] to facilitate computation. Watanabe [32] established a singular learning theory and proposed a new criterion named Watanabe–Akaike [29], or widely applicable information criterion (WAIC) [33,34], while WAIC was proposed for the plug-in discrepancy and WAIC for the posterior averaged discrepancy. However, compared with BPIC and PAIC, we found that WAIC tends to have a larger bias and variation for regular Bayesian models, as shown in simulation studies in the next section.
4. Simulation Study
In this section, we present some numerical results to illustrate the performance of the proposed method under small sample sizes. Assuming K-L divergence is a good measure for model selection, our goal is simply to assess how it can be estimated with the smallest bias. In the simulation experiments, we estimate the true expected bias either analytically in a Gaussian setting (Section 4.1) or numerically by averaging over a large number of extra independent draws of when there is asymmetric posterior distribution and no closed form for the integration (Section 4.2). To have BPIC well-defined for comparison, only the proper prior distributions are considered.
4.1. A Case with Closed-Form Expression for Bias Estimators
Suppose observations are a vector of iid samples generated from , with unknown true mean and variance . Assume the data are analyzed by the approximating model with prior , where is fixed, but not necessarily equal to the true variance . When , the model is misspecified.
The posterior distribution of is normally distributed with mean and variance , where
Therefore, the K-L discrepancy function and its estimator are
We assess the bias estimator defined in Theorem 1, and four other bias estimators: [7], [33], [22], and [35].
We compare them with the true bias
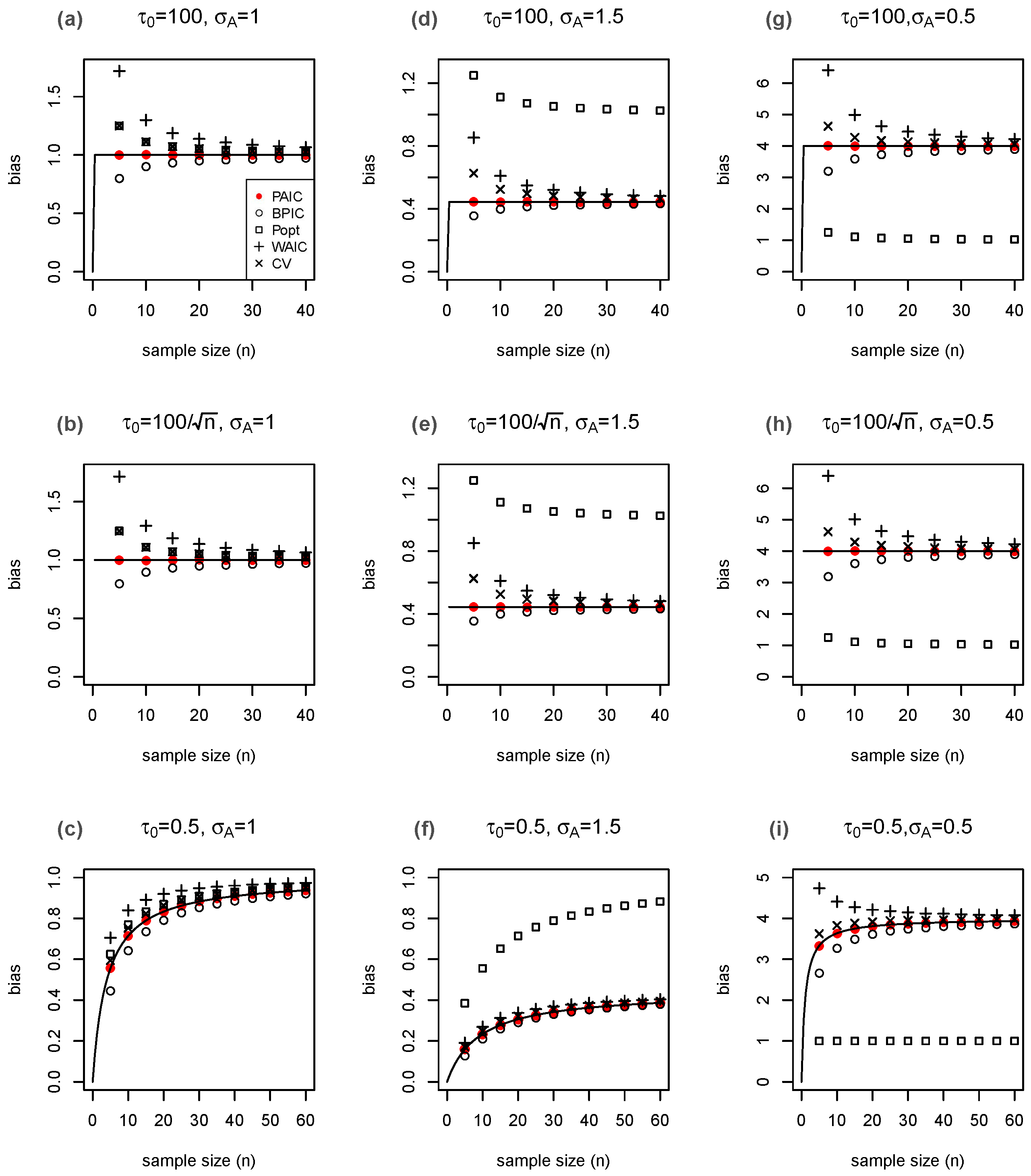
The results are in accordance with the theory (Figure 1). All of the estimates are close to the true bias-correction values when the model is well-specified with , especially when the sample size becomes moderately large (Figure 1, panels (a), (b), and (c)). The estimated values based on the PAIC are consistently closer to the true values than either those based on Ando’s method, which underestimates the bias, or the WAIC, cross-validation or expected deviance penalized loss, which overestimate the bias, especially when the sample size is small. When the models are misspecified, it is not surprising that in all of the plots given in panels (d)–(i) of Figure 1, only the expected deviance penalized loss misses the target even asymptotically since its assumption is violated, whereas all the other approaches converge to . In summary, PAIC achieves the best overall performance.
4.2. Bayesian Logistic Regression
Consider frequencies , which are independent observations from binomial distributions with respective true probabilities , and sample sizes, . To draw the inference of the ’s, we assume that the logits
are random effects that follow the normal distribution The weakly-informative joint prior distribution - is proposed on the hyper-parameter so that the BPIC is properly defined and computable. The posterior distribution is asymmetric due to the logistic transformation.
We compare the performance of four asymptotically unbiased bias estimators in this hierarchical, asymmetric setting. The true bias does not have an analytical form. We estimate it through numerical computation using independent simulation from the same data generating process, assuming the underlying true values of and . The simulation scheme is as follows:
- 1.
- Draw , , from the true distribution.
- 2.
- Simulate the posterior draws of .
- 3.
- Estimate , , , and .
- 4.
- Draw , , for approximation of true .
- 5.
- Compare each with true bias .
- 6.
- Repeat steps 1–5.
Table 1 summarizes the bias and standard deviation of the estimation error when we choose and , and the ’s are independently simulated from the standard normal distribution assuming the true hyper-parameter mean and variance . The simulation is repeated for 1000 scenarios, each with 20,000 for out-of-sample estimation. PAIC and BPIC were calculated based on definition; leave-one-out cross-validation and WAIC were estimated using R package loo v2.5.1 [31]. The actual error, mean absolute error, and mean square error were considered to assess the estimation error using the bias correction estimates. With respect to all three different metrics, the bias estimation of PAIC is consistently superior to other methods. Compared to BPIC, the second best performed model selection criterion, the bias, and the mean squared error of PAIC are reduced by about , while the absolute bias is reduced by about one quarter, which matches our expectation that the natural estimate will estimate the posterior averaged K-L discrepancy more precisely than plug-in estimate when the posterior distribution is asymmetric and correlated. Compared to WAIC, the bias, absolute error, and mean square error of PAIC are dramatically reduced by at least . In practice, we expect the improvement is even larger when proposed models have more complicated hierarchical structures.
As suggested by reviewers, we also assessed PAIC in bias estimation with different priors, including the commonly used -[36]. Although these priors may produce different posterior distributions, we found almost identical results in terms of bias estimation error to Table 1, suggesting the robustness of the proposed method. Furthermore, we examined the BPIC and PAIC for uncorrelated posterior distributions of s, by fixing the hyperparameters either at its true value or at the posterior mode. In the simulation replications containing extreme observations (i.e., ∃, such that either or ), we observed a large deviation of the plug-in estimate to , which cannot be properly recovered by BPIC’s bias correction term in Equation (3) and yields significant estimation error; meanwhile, the plug-in estimand was also much more vulnerable to the observed data than given the extreme value, suggesting that the latter (the posterior averaged discrepancy) could be a better choice for model assessment.
5. Application
This is a variable selection example that uses real data to illustrate the practical difference between criteria proposed in either the explanatory or predictive perspective. We explore the problem of finding the best model to predict the selling of new accounts in branches of a large bank. The data were introduced in example 5.3 of George & McCulloch [37], analyzed with their method, the stochastic search variable selection (SSVS) technique to select the promising subsets of predictors. Their report on the 10 most frequently selected models after 10,000 iterations of Gibbs sampling for potential subsets, is listed in the first column of Table 2.
The original data consist of the numbers of new accounts sold in some time period as the outcome , together with 15 predictor variables X in each of 233 branches. Multiple linear regressions are employed to fit the data in the form of
with prior and , when m indicates the specific model with a subset of predictor .
Several model selection estimators for , including the leave-one-out cross-validated estimator (LOO-CV), K-fold cross-validated estimator (KCV), the expected deviance penalized loss with , BPIC, and PAIC, are calculated based on a large number of MCMC draws of the posterior distribution for model selection inference. In KCV, the original data are randomly partitioned for the K-fold cross-validation with a common choice of . All the posterior samples are simulated from three parallel chains based on MCMC techniques for model selection inference. To generate 15,000 effective draws of the posterior distribution, only one out of five iterations after convergence are kept to reduce the serial correlation.
The results are presented in Table 2, in which the models that have the smallest estimation value by each criterion are highlighted. The first 10 models with SSVS frequencies were originally picked by SSVS as shown in George & McCulloch [37]. An interesting finding is that the favored models selected by the K-L based criteria and SSVS are quite different. All of the K-L based criteria are developed in a predictive perspective, whereas SSVS is a variable selection method to pursue the model that best describes the given set of data. This illustrates that with different modeling purposes, either explanatory or predictive, the ‘best’ models found may not coincide. The estimated , BPIC, and PAIC values for every candidate model are quite close to each other; whereas the cross-validation estimators are noisy due to the simulation error and tendency to overestimate the value. It is worth mentioning that the estimators of LOO-CV, K-fold-CV, and are relatively unstable, even with 15,000 posterior draws. Those methods have been much more computationally intensive than BPIC and PAIC.
6. Discussion
A clearly defined model selection criterion or score usually lies at the heart of any statistical selection and decision procedure. It facilitates the comparison of competing models through the assignment of some sort of preference or ranking to the alternatives. One of the typical scores is the K-L divergence, a non-symmetric measure of the difference between two probability distributions. By further acknowledging uncertainty in parameters and randomness in data, frequentist statistics theoretically employing K-L divergence into parametric model selection emerged during the 1970s. Since then, the development of related theories and applications has rapidly accelerated.
A good assessment measure helps establish attractive properties. To guide the Bayesian method development, two important questions should be first investigated.
- 1.
- What is a good estimand, based on K-L discrepancy, to evaluate Bayesian models?
- 2.
- What is a good estimator to estimate the estimand for K-L based Bayesian model selection?
The prevailing plug-in parameter methods, such as DIC, presume the candidate models are correct, and assess the goodness of each candidate model with a density function specified by the plug-in parameters. However, from a Bayesian perspective, it is inherent to examine the performance of a Bayesian model over the entire posterior distribution, as stated by (Celeux et al. [18], p. 703): “...we concede that using a plug-in estimate disqualifies the technique from being properly Bayesian.” Accordingly, statistical approaches to estimate the K-L discrepancy as evaluated by averaging over the posterior distribution are of great interest.
We have proposed PAIC, a versatile model selection technique for Bayesian models under regularity assumptions, to address this problem. From a predictive perspective, we consider the asymptotic unbiased estimation of a K-L discrepancy, which averages the conditional density of the observable data against the posterior knowledge about the unobservable data. Empirically, the proposed PAIC measures the similarity of the fitted model and the underlying true distribution, regardless of whether or not the approximating distribution family contains the true model. The range of applications of the proposed criterion can be quite broad.
PAIC and BPIC are similar in many aspects. In addition to all the asymptotic properties and similar computational costs both methods share, PAIC has some unique features, mainly because it employs the natural posterior-averaged estimator. For example, PAIC can be well applied even if the prior distribution of the parameters degenerates, in which case BPIC becomes uninterpretable. In the illustrative experiments, we focused on the comparison of estimation accuracy between the proposed criterion and other Bayesian model selection criteria including BPIC and WAIC. PAIC showed the least bias and variance to estimate the posterior averaged discrepancy.
Because the regularity condition assumes twice continuously differentiability and non-singularity, it could be problematic if the posterior mode is on the boundary of the parameter space . For example, as pointed out by one reviewer, in the famous eight-school example [8]. This is a common concern for K-L based model selection since the method derivation relies on the Taylor series expansion. However, in practice, a reparameterization may help. In the eight-school example, we can introduce the uniform prior to pair with the weakly informative prior , which yields a posterior mode for .
There are some future directions for the current work. In the current simulation setting, we made a default assumption that the estimand, i.e., the posterior-averaged out-of-sample log-likelihood, can be distinguished between candidate models. A more comprehensive comparison of Bayesian predictive methods for empirical model selection can be investigated by taking into account the likely over-fitting in the selection phase, similar to [38]. Because the users of PAIC and BPIC have to specify the first and second derivatives of the posterior distribution in their modeling, development of advanced computational tools for simultaneous calculations will be helpful. In singular learning machines, the regularity conditions can be relaxed to singular in a sense that the mapping from parameters to probability distributions is not necessarily one-to-one. Although here we focused on only the regular models, it is also possible to generalize PAIC to singular settings with a modified bias correction term, after an algebraic geometrical transformation of the singular parameter space to a real d-dimensional manifold. Finally, other metrics for comparing the distance or dissimilarity between two distributions, such as Hellinger distance [39] or Jensen–Shannon divergence [40], may be explored further and employed as alternative metrics in Bayesian model assessment.
Funding
This research was funded part by Columbia University GSAS Faculty Fellowship and NIH/NCI Grant CA100632.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The author would like to acknowledge Ciprian Giurcaneanu, four anonymous referees, one associate editor and editor for careful reviews and constructive comments that substantially improved the article. The author is also grateful to David Madigan and Andrew Gelman for helpful discussions, and to Lee Ann Chastain for editorial assistance.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AIC | Akaike information criterion |
| BPIC | Bayesian predictive information criterion |
| DIC | Deviance information criterion |
| K-L | Kullback–Leibler |
| PAIC | Posterior averaging information criterion |
| WAIC | Watanabe–Akaike information criterion |
Appendix A. Supplementary Materials for Proof of Theorem 1
Appendix A.1. Some Important Notations
By the law of large numbers we have as n tends to infinity. Denote , the expected and empirical posterior mode of the log unnormalized posterior density , ,
and let and denote the Bayesian Hessian matrix and Bayesian Fisher information matrix
and
Appendix A.2. Proof of Lemmas
We start with a few lemmas to support the proofs of Theorem 1.
Lemma A1.
Under the same regularity conditions of Theorem 1, is asymptotically distributed as .
Proof.
Consider the Taylor expansion of at ,
Note that is the mode of and satisfies . Plug it into the above equation, we have
From the central limit theorem, the right-hand-side (RHS) of Equation (A1) is approximately distributed as when . Therefore,
□
Lemma A2.
Under the same regularity conditions of Theorem 1, .
Proof.
Taylor-expand the logarithm of around the posterior mode
where .
Consider the RHS of Equation (A2) as a function of : the first term is a constant, whereas the second term is proportional to the logarithm of a normal density. It yields the approximation of the posterior distribution for :
which completes the proof.
Alternatively, though less intuitive, this lemma can also be proved by applying the Berstein–Von Mises theorem. □
Lemma A3.
Under the same regularity conditions of Theorem 1, .
Proof.
First we have
Since is the mode of , it satisfies . Therefore, . Note that
Because of assumption (C1), the equation holds when we change the order of the integral and derivative. Therefore,
Together with derived from Lemma A1, we complete the proof. □
Lemma A4.
Under the same regularity conditions of Theorem 1,
Proof.
can be rewritten as . Applying Lemmas A1–A3, we complete the proof. □
Lemma A5.
Under the same regularity conditions of Theorem 1,
Proof.
The posterior mean of the log joint density distribution of can be Taylor-expanded around as
Expand around to the first order, we obtain
Because the posterior mode is the solution of , Equation (A4) can be re-written as
Substituting it into the second term of (A3), the expansion of becomes:
where in the last line we replace with the result of Lemma A4. in the second term of the expansion can be rewritten as , where the former term is asymptotically equal to by Lemma A1, and the latter is negligible with higher order , as shown in Lemma A3. Therefore, the expansion can be finally simplified as
□
Appendix B. Supplementary Materials for Derivation of Equation (3)
References
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Selected Papers of Hirotugu Akaike; Parzen, E., Tanabe, K., Kitagawa, G., Eds.; Springer Series in Statistics; Springer: New York, NY, USA, 1998; pp. 267–281. [Google Scholar]
- Rissanen, J. Modeling by shortest data description. Automatica 1978, 14, 465–471. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar]
- Geisser, S.; Eddy, W.F. A predictive approach to model selection. J. Am. Stat. Assoc. 1979, 74, 153–160. [Google Scholar]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; Van der Linde, A. Bayesian measures of model complexity and fit (with discussion). J. R. Stat. Soc. B 2002, 64, 583–639. [Google Scholar]
- Ando, T. Bayesian predictive information criterion for the evaluation of hierarchical Bayesian and empirical Bayes models. Biometrika 2007, 94, 443–458. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 2nd ed.; CRC Press: London, UK, 2003. [Google Scholar]
- Hurvich, C.; Tsai, C. Regression and time series model selection in small samples. Biometrika 1989, 76, 297–307. [Google Scholar]
- Konishi, S.; Kitagawa, G. Generalised information criteria in model selection. Biometrika 1996, 83, 875–890. [Google Scholar]
- Takeuchi, K. Distributions of information statistics and criteria for adequacy of models. Math. Sci. 1976, 153, 15–18. (In Japanese) [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Laud, P.W.; Ibrahim, J.G. Predictive model selection. J. R. Stat. Soc. B 1995, 57, 247–262. [Google Scholar]
- San Martini, A.; Spezzaferri, F. A predictive model selection criterion. J. R. Stat. Soc. B 1984, 46, 296–303. [Google Scholar]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; Van der Linde, A. The deviance information criterion: 12 years on. J. R. Stat. Soc. B 2002, 76, 485–493. [Google Scholar]
- Spiegelhalter, D.J.; Thomas, A.; Best, N.G. WinBUGS Version 1.2 User Manual; MRC Biostatistics Unit: Cambridge, UK, 1999. [Google Scholar]
- Meng, X.L.; Vaida, F. Comments on ‘Deviance Information Criteria for Missing Data Models’. Bayesian Anal. 2006, 70, 687–698. [Google Scholar]
- Celeux, G.; Forbes, F.; Robert, C.P.; Titterington, D.M. Deviance information criteria for missing data models. Bayesian Anal. 2006, 70, 651–676. [Google Scholar]
- Liang, H.; Wu, H.; Zou, G. A note on conditional AIC for linear mixed-effects models. Biometrika 2009, 95, 773–778. [Google Scholar]
- Vaida, F.; Blanchard, S. Conditional Akaike information for mixed effects models. Biometrika 2005, 92, 351–370. [Google Scholar]
- Donohue, M.C.; Overholser, R.; Xu, R.; Vaida, F. Conditional Akaike information under generalized linear and proportional hazards mixed models. Biometrika 2011, 98, 685–700. [Google Scholar]
- Plummer, M. Penalized loss functions for Bayesian model comparison. Biostatistics 2008, 9, 523–539. [Google Scholar]
- Efron, B. Estimating the Error Rate of a Prediction Rule: Improvement on Cross-Validation. J. Am. Stat. Assoc. 1983, 78, 316–331. [Google Scholar]
- Lenk, P.J. The logistic normal distribution for Bayesian non parametric predictive densities. J. Am. Stat. Assoc. 1988, 83, 509–516. [Google Scholar]
- Walker, S.; Hjort, N.L. On bayesian consistency. J. R. Stat. Soc. B 2001, 63, 811–821. [Google Scholar]
- Hodges, J.S.; Sargent, D.J. Counting degrees of freedom in hierarchical and other richly-parameterised models. Biometrika 2001, 88, 367–379. [Google Scholar]
- Gelfand, A.E.; Ghosh, S.K. Model Choice: A Minimum Posterior Predictive Loss Approach. Biometrika 1998, 85, 1–11. [Google Scholar]
- Vehtari, A.; Lampinen, J. Bayesian model assessment and comparison using cross-validation predictive densities. Neural Comput. 2002, 14, 1339–2468. [Google Scholar]
- Gelman, A.; Hwang, J.; Vehtari, A. Understanding predictive information criteria for Bayesian models. Stat. Comput. 2014, 24, 997–1016. [Google Scholar]
- Vehtari, A.; Gelman, A.; Gabry, J. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 2017, 27, 1413–1432. [Google Scholar]
- Vehtari, A.; Gabry, J.; Yao, Y.; Gelman, A. loo: Efficient Leave-One-Out Cross-Validation and WAIC for Bayesian Models. R Package Version 2.5.1. 2018. Available online: https://CRAN.R-project.org/package=loo (accessed on 28 August 2022).
- Watanabe, S. Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J. Mach. Learn. Res. 2010, 11, 3571–3594. [Google Scholar]
- Watanabe, S. Algebraic Geometry and Statistical Learning Theory; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Watanabe, S. A formula of equations of states in singular learning machines. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 2098–2105. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions (with discussion). J. R. Stat. Soc. B 1974, 36, 111–147. [Google Scholar]
- Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 2006, 1, 515–534. [Google Scholar]
- George, E.I.; McCulloch, R. Variable selection via Gibbs sampling. J. Am. Stat. Assoc. 1993, 88, 881–889. [Google Scholar]
- Piironen, J.; Vehtari, A. Comparison of Bayesian predictive methods for model selection. Stat. Comput. 2017, 27, 711–735. [Google Scholar]
- Beran, R. Minimum Hellinger distance estimates for parametric models. Ann. Stat. 1977, 5, 445–463. [Google Scholar]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar]
Figure 1.
Performance of the bias estimators for . The top panels are under a relatively non-informative prior with ; the middle panels are under the case that the prior distribution grows with sample size with ; the bottom panels are under an informative prior with . The left panels (a–c) are under the scenario of , i.e., the true distribution is contained in the candidate models. The middle panels (d–f) are under the scenario of and right panels (g–i) are under the scenario of when the proposed model is misspecified from . The true bias is curved by (—) as a function of sample size n. The averages of the different bias estimators are marked by (•) for PAIC; (∘) for BPIC; (□) for ; (+) for WAIC; and (×) for cross-validation. Each mark represents the mean of the estimated bias of 100,000 replications of .
Figure 1.
Performance of the bias estimators for . The top panels are under a relatively non-informative prior with ; the middle panels are under the case that the prior distribution grows with sample size with ; the bottom panels are under an informative prior with . The left panels (a–c) are under the scenario of , i.e., the true distribution is contained in the candidate models. The middle panels (d–f) are under the scenario of and right panels (g–i) are under the scenario of when the proposed model is misspecified from . The true bias is curved by (—) as a function of sample size n. The averages of the different bias estimators are marked by (•) for PAIC; (∘) for BPIC; (□) for ; (+) for WAIC; and (×) for cross-validation. Each mark represents the mean of the estimated bias of 100,000 replications of .

{kind=link}
Table 1.
The estimation error of bias correction: the mean and standard deviation (in parentheses) from 1000 replications.
Table 1.
The estimation error of bias correction: the mean and standard deviation (in parentheses) from 1000 replications.
| Criterion | Actual Error | Mean Absolute Error | Mean Square Error |
|---|---|---|---|
| 0.160 (0.238) | 0.206 (0.199) | 0.082 (0.207) | |
| 0.259 (0.244) | 0.272 (0.229) | 0.127 (0.267) | |
| 0.840 (0.285) | 0.840 (0.285) | 0.786 (0.633) | |
| 0.511 (0.248) | 0.511 (0.248) | 0.323 (0.389) |
Table 2.
Comparison of model performance using K-L based model selection criteria for SSVS example. The first row indicates the independent variables (x) to be excluded in each model. The mid rule separates the models most frequently appeared using SSVS method (above) vs. the models with lower PAIC (below).
Table 2.
Comparison of model performance using K-L based model selection criteria for SSVS example. The first row indicates the independent variables (x) to be excluded in each model. The mid rule separates the models most frequently appeared using SSVS method (above) vs. the models with lower PAIC (below).
| SSVS | LOO-CV | KCV | BPIC | PAIC | ||
|---|---|---|---|---|---|---|
| 4, 5 | 827 | 2603.85 | 2580.74 | 2527.32 | 2528.89 | 2529.60 |
| 2, 4, 5 | 627 | 2572.98 | 2564.92 | 2544.77 | 2533.90 | 2534.44 |
| 3, 4, 5, 11 | 595 | 2583.63 | 2572.59 | 2545.23 | 2539.79 | 2540.20 |
| 3, 4, 5 | 486 | 2593.10 | 2579.97 | 2567.85 | 2541.75 | 2542.32 |
| 3, 4 | 456 | 2590.36 | 2571.76 | 2538.80 | 2533.37 | 2533.97 |
| 4, 5, 11 | 390 | 2589.76 | 2573.04 | 2526.77 | 2527.94 | 2528.58 |
| 2, 3, 4, 5 | 315 | 2576.66 | 2577.17 | 2561.57 | 2553.29 | 2553.77 |
| 3, 4, 11 | 245 | 2579.53 | 2566.28 | 2565.22 | 2532.87 | 2533.42 |
| 2, 4, 5, 11 | 209 | 2564.67 | 2559.36 | 2540.41 | 2533.60 | 2534.03 |
| 2, 4 | 209 | 2741.46 | 2741.17 | 2737.46 | 2740.42 | 2740.51 |
| 5, 10, 12 | n/a | 2602.23 | 2572.86 | 2519.41 | 2525.07 | 2525.61 |
| 4, 12 | n/a | 2596.51 | 2570.94 | 2520.52 | 2524.31 | 2524.94 |
| 5, 12 | n/a | 2595.86 | 2570.32 | 2520.51 | 2524.19 | 2524.90 |
| 4, 5, 12 | n/a | 2596.67 | 2574.73 | 2525.65 | 2526.19 | 2526.86 |
| 4, 10, 12 | n/a | 2603.05 | 2573.80 | 2520.62 | 2525.17 | 2525.70 |
| 4, 5, 10, 12 | n/a | 2603.51 | 2577.86 | 2526.53 | 2527.06 | 2527.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhou, S. Posterior Averaging Information Criterion. Entropy 2023, 25, 468. https://doi.org/10.3390/e25030468
AMA Style
Zhou S. Posterior Averaging Information Criterion. Entropy. 2023; 25(3):468. https://doi.org/10.3390/e25030468
Chicago/Turabian StyleZhou, Shouhao. 2023. "Posterior Averaging Information Criterion" Entropy 25, no. 3: 468. https://doi.org/10.3390/e25030468
APA StyleZhou, S. (2023). Posterior Averaging Information Criterion. Entropy, 25(3), 468. https://doi.org/10.3390/e25030468
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.