
Information Complexity Ranking: A New Method of Ranking Images by Algorithmic Complexity



Abstract
1. Introduction
- We propose a new method for classifying images according to their complexity known as ICR.
- We define a protocol for generating synthetic images in order to evaluate the performance of the compression algorithms that can be used with our new method.
- We perform experiments on a dataset of 1400 diverse images to prove the robustness of our approach.
2. Materials and Methods
2.1. State-of-the-Art Algorithms
2.1.1. Statistical View of Complexity
2.1.2. Algorithmic View of Complexity
2.1.3. The Similarity between Two Objects
3. Information Complexity Ranking (ICR)
3.1. Proof
3.1.1. Reflexivity Property
3.1.2. Transitivity Property
3.1.3. Anti-Symmetry Property
4. Experiments
4.1. Synthetic Dataset
4.1.1. Purpose of the Experiment
4.1.2. Protocol
4.1.3. Results
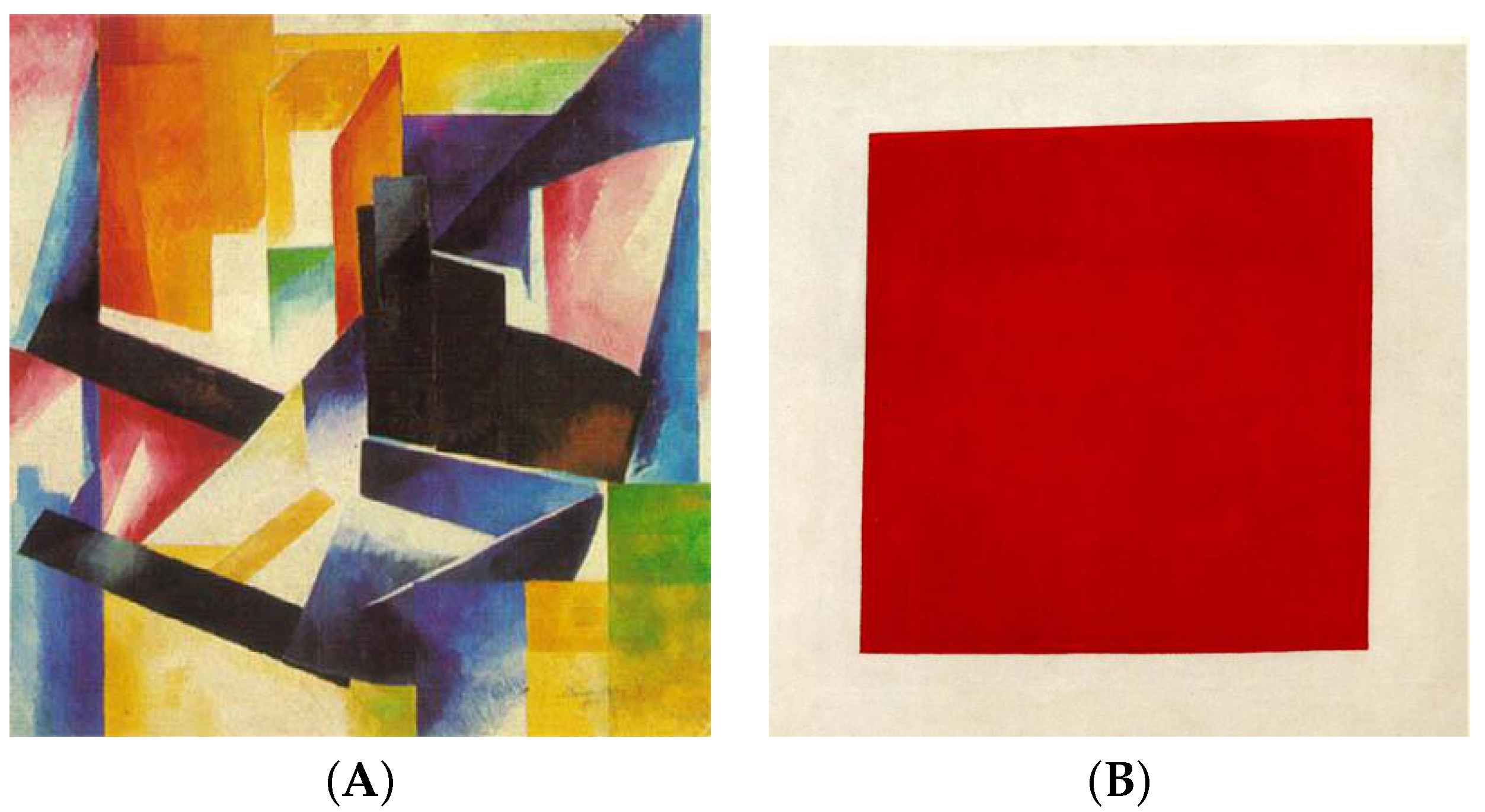
4.2. SAVOIAS Dataset
4.2.1. Dataset Description
4.2.2. Protocol
4.2.3. Results
5. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cilibrasi, R.; Vitányi, P.M. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef]
- Varré, J.S.; Delahaye, J.P.; Rivals, E. Transformation distances: A family of dissimilarity measures based on movements of segments. Bioinformatics 1999, 15, 194–202. Available online: http://xxx.lanl.gov/abs/https://academic.oup.com/bioinformatics/article-pdf/15/3/194/9732002/150194.pdf (accessed on 29 January 2023). [CrossRef]
- Brandouy, O.; Delahaye, J.P.; Ma, L. Estimating the algorithmic complexity of stock markets. Algorithmic Financ. 2015, 4, 159–178. [Google Scholar] [CrossRef]
- Zenil, H.; Delahaye, J.P.; Gaucherel, C. Image characterization and classification by physical complexity. Complexity 2012, 17, 26–42. [Google Scholar] [CrossRef]
- Deng, L.; Poole, M.S. Aesthetic design of e-commerce web pages—Webpage Complexity, Order and preference. Electron. Commer. Res. Appl. 2012, 11, 420–440. [Google Scholar] [CrossRef]
- Wang, Q.; Ma, D.; Chen, H.; Ye, X.; Xu, Q. Effects of background complexity on consumer visual processing: An eye-tracking study. J. Bus. Res. 2020, 111, 270–280. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Delahaye, J.P. Mesurer la Complexité des Objets Numériques. Bull. Soc. Inform. Fr. 2013, 1, 35–53. [Google Scholar]
- Chaitin, G.J. Algorithmic Information Theory. IBM J. Res. Dev. 1977, 21, 350–359. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three Approaches to Information. Probl. Peredachi Informatsii 1965, 1, 3–11. [Google Scholar]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications; Texts in Computer Science; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Ferbus-Zanda, M.; Grigorieff, S. Kolmogorov Complexity in perspective. Part I: Information Theory and Randomnes. arXiv 2010, arXiv:1010.3201. [Google Scholar]
- Turing, A.M. On Computable Numbers, with an Application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1937, s2-42, 230–265. [Google Scholar] [CrossRef]
- Solomonoff, R.J. A formal theory of inductive inference. Part I and Part II. Inf. Control 1964, 7, 1–22. [Google Scholar] [CrossRef]
- Grunwald, P.; Vitanyi, P. Shannon Information and Kolmogorov Complexity. arXiv 2004, arXiv:cs/0410002. [Google Scholar]
- Tsukiyama, T.; Kondo, Y.; Kakuse, K.; Saba, S.; Ozaki, S.; Itoh, K. Method and System for Data Compression and Restoration. U.S. Patent US4586027A, 29 April 1986. [Google Scholar]
- Li, M.; Chen, X.; Li, X.; Ma, B.; Vitányi, P.M. The similarity metric. IEEE Trans. Inf. Theory 2004, 50, 3250–3264. [Google Scholar] [CrossRef]
- Ferbus-Zanda, M. Kolmogorov Complexity in perspective. Part II: Classification, Information Processing and Duality. Synthese 43. [CrossRef]
- Bennett, C.; Gacs, P.; Li, M.; Vitanyi, P.; Zurek, W. Information distance. IEEE Trans. Inf. Theory 1998, 44, 1407–1423. [Google Scholar] [CrossRef]
- Grunert, K.G.; Bolton, L.E.; Raats, M.M. Processing and acting on nutrition labeling on food. In Transformative Consumer Research for Personal and Collective Well-Being; Routledge: New York, NY, USA, 2012; pp. 333–351. [Google Scholar]
- Saraee, E.; Jalal, M.; Betke, M. SAVOIAS: A Diverse, Multi-Category Visual Complexity Dataset. arXiv 2018, arXiv:cs.CV/1810.01771. [Google Scholar]
- Young, H.P. Condorcet’s Theory of Voting. Am. Political Sci. Rev. 1988, 82, 1231–1244. [Google Scholar] [CrossRef]
- Rosenholtz, R.; Li, Y.; Nakano, L. Measuring visual clutter. J. Vis. 2007, 7, 17. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Corchs, S.; Gasparini, F.; Schettini, R. No reference image quality classification for JPEG-distorted images. Digit. Signal Process. A Rev. J. 2014, 30, 86–100. [Google Scholar] [CrossRef]
- Deng, W.; Liu, Q.; Cheng, H.; Qin, Z. A malware detection framework based on kolmogorov complexity. J. Comput. Inf. Syst. 2011, 7, 2687–2694. [Google Scholar]
- Bennett, C.H. Logical Depth and Physical Complexity. In A Half-Century Survey on the Universal Turing Machine; Oxford University Press, Inc.: Oxford, MA, USA, 1988; pp. 227–257. [Google Scholar]
- Martin-Löf, P. The definition of random sequences. Inf. Control 1966, 9, 602–619. [Google Scholar] [CrossRef]
- Delahaye, J.P.; Vidal, C. Organized Complexity: Is Big History a Big Computation? Am. Philos. Assoc. Newsl. Philos. Comput. 2016, 17, 49–54. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | PNG | PPM | LZ77 | ALZ | LZP | LZW | AC | Huffman |
|---|---|---|---|---|---|---|---|---|
| Idempotency horizontal | 0.088 | 0.091 | 0.098 | 0.196 | 0.209 | 0.555 | 0.533 | 0.216 |
| Idempotency vertical | 0.043 | 0.047 | 0.058 | 0.130 | 0.133 | 0.631 | 0.591 | 0.237 |
| Symmetry horizontal | 0.004 | 0.014 | 0.004 | 0.007 | 0.007 | 0.004 | 0.001 | 0.000 |
| Symmetry vertical | 0.006 | 0.027 | 0.009 | 0.031 | 0.005 | 0.007 | 0.009 | 0.000 |
| Monotonicity horizontal | 0.318 | 0.202 | 0.285 | 0.197 | 0.334 | 0.323 | 0.731 | 1.423 |
| Monotonicity vertical | 0.344 | 0.204 | 0.298 | 0.199 | 0.329 | 0.343 | 0.909 | 1.588 |
| Distributivity horizontal | 0.313 | 0.197 | 0.273 | 0.203 | 0.327 | 0.314 | 0.736 | 1.414 |
| Distributivity vertical | 0.329 | 0.202 | 0.287 | 0.203 | 0.313 | 0.333 | 0.894 | 1.549 |
| Compression ratio | 3.174 | 3.676 | 3.509 | 3.745 | 3.300 | 3.875 | 2.028 | 0.760 |
| Category | Number of | Number of | Total Number of |
|---|---|---|---|
| Images | Comparisons | Processed Images | |
| Scenes | 200 | 80,000 | |
| Advertisement | 200 | 80,000 | |
| Visualization | 200 | 80,000 | |
| Objects | 200 | 80,000 | |
| Interior Design | 100 | 20,000 | |
| Art | 420 | 352,800 | |
| Suprematism | 100 | 20,000 |
| Category | NCD | ICR |
|---|---|---|
| Scenes | 0.23 | 0.40 |
| Advertisement | 0.16 | 0.58 |
| Visualizations | 0.13 | 0.31 |
| Objects | 0.05 | 0.16 |
| Interior Design | 0.52 | 0.67 |
| Art | 0.28 | 0.58 |
| Suprematism | 0.47 | 0.73 |
| Category | Edge Density | Number of Regions | Feature Congestion | Subband Entropy | Compression Ratio | ICR |
|---|---|---|---|---|---|---|
| Scenes | 0.16 | 0.57 | 0.42 | 0.16 | 0.30 | 0.40 |
| Advertisement | 0.54 | 0.41 | 0.56 | 0.54 | 0.56 | 0.58 |
| Visualizations | 0.57 | 0.38 | 0.52 | 0.61 | 0.55 | 0.31 |
| Objects | 0.28 | 0.29 | 0.30 | 0.10 | 0.16 | 0.16 |
| Interior Design | 0.61 | 0.67 | 0.58 | 0.31 | 0.68 | 0.67 |
| Art | 0.48 | 0.65 | 0.22 | 0.33 | 0.51 | 0.58 |
| Suprematism | 0.18 | 0.84 | 0.48 | 0.39 | 0.60 | 0.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chambon, T.; Guillaume, J.-L.; Lallement, J. Information Complexity Ranking: A New Method of Ranking Images by Algorithmic Complexity. Entropy 2023, 25, 439. https://doi.org/10.3390/e25030439
Chambon T, Guillaume J-L, Lallement J. Information Complexity Ranking: A New Method of Ranking Images by Algorithmic Complexity. Entropy. 2023; 25(3):439. https://doi.org/10.3390/e25030439
Chicago/Turabian StyleChambon, Thomas, Jean-Loup Guillaume, and Jeanne Lallement. 2023. "Information Complexity Ranking: A New Method of Ranking Images by Algorithmic Complexity" Entropy 25, no. 3: 439. https://doi.org/10.3390/e25030439
APA StyleChambon, T., Guillaume, J.-L., & Lallement, J. (2023). Information Complexity Ranking: A New Method of Ranking Images by Algorithmic Complexity. Entropy, 25(3), 439. https://doi.org/10.3390/e25030439