1. Introduction
Millions of digital texts have been created since word processors appeared on the market, and handling these documents became one of the most popular digital production-activity. However, Johnson [
1] called attention to his findings as early as late the 90s that:
“…it is believed that a very little knowledge, a skimpy overview, is sufficient. The value of limited study of word processing applications is rather doubtful. In fact, a little bit of knowledge about word processing may be almost useless—and a quick overview is certainly not sufficient to realize most of the overwhelming benefits of using computers for writing.”
He went even further, claiming that:
“In order to take advantage of the powers of word processing requires considerable skill in its use. Those who understand only a little about word processors will probably employ them in a linear fashion like an expensive typewriter and compose in exactly the same way they would on a typewriter because they simply do not know how to use the sophisticated editing features of a word processor.”
What surprising is that the quality of digital texts has not improved considerably during the past years, and the mentioned misconceptions regenerate and intensify the problems. Johnson [
1] only mentions the complexity of word processors and users’ lack of knowledge; however, we also must pay attention to the content and the structure of the texts, which is more complex and demanding than the technical details of using word processors. It is said that building football stadiums does not make football, having a telescope does not make astronomy. In a similar way, owning hardware and software does not make informatics, or computer sciences, which is clearly expressed both in science [
2] and industry [
3,
4].
“When major new machinery comes along—as computers have—it’s rather disorientating.”
“Relying on technical innovation alone often provides only temporary competitive advantage.”
“Society has reached the point where one can push a button and be immediately deluged with technical and managerial information. This all very convenient, of course, but in one is not careful there is a danger of losing the ability to think. We must remember that in the end it’s the individual human being who must solve the problems.”
Consequently, the quality of word-processed documents is questionable due to the circulating misconceptions and the ill-use of these rather complex applications [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20], which can be proven by thorough analyses of the available documents and rather inefficient modification processes. More and more word-processed documents are publicly available on the internet and circulate in closed networks. On one hand, the erroneous documents encourage untrained end-users to copy and follow these examples, and they use them as references. On the other hand, it allows researchers to build their corpora for various error detection studies on the subject. Considering the available word processors and their popularity at the time of writing the present paper, we selected the most widely used program and its documents for further analysis, which was Microsoft Word and documents with DOC and DOCX extensions [
21]. One further reason for choosing Microsoft Word was that it allows users to seamlessly present non-printing characters on the interface which—despite its credible popularity—is crucial in the editing process of digital texts [
22,
23,
24,
25].
The question is whether self-taught [
26], overconfident [
27,
28,
29], tool-centered end-users (non-professional authors and/or editors of documents) [
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43], or those who raise doubts about the quality of word-processed texts have merit [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19]. To find proof, instead of relying on legends and folktales [
44,
45], we must find facts by using the results of educational research connected to the subject [
44,
45,
46,
47,
48,
49,
50,
51,
52,
53]. Being aware of the low efficiency of word processing activities, we launched a research project to find an objective measuring system and define the entropy of erroneous and correct digital texts, what we call text-entropy.
Our previous research in the field of didactics of informatics has already revealed that in general, education performs a crucial role in developing students’ computational thinking skills [
54], especially in handling digital texts [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19]. It is also found that the cognitive load of handling digital text-based documents in a “user-friendly” GUI is so high [
55] that novel methods and approaches are required to be able to cope with this complex problem.
Considering the role of education, the complexity of digital texts, the algorithm-driven, deceptive “user-friendly” word processing programs, and the millions of erroneous documents circulating either in closed communities (corporate, school, training group, etc.) or on the internet available for everyone, it is found that we are in great need of approaches and methods that can handle errors. Surprisingly, educational research has paid little attention to learning from errors [
56], with a few exceptions [
57,
58,
59]. Primarily sports, where ignoring errors would lead to serious injuries and underperformance in competitions [
60,
61,
62,
63,
64]. Not less surprising is that the profit-oriented “real-world” and their production systems also pay minimal attention to errors. However, the Toyota Production System claims that they must bring problems to the surface, make them visible, and go to work immediately on countermeasures [
4]. One of the principles of the Toyota Way is that:
“We view errors as opportunities for learning. Rather than blaming individuals, the organization takes corrective actions and distributes knowledge about each experience broadly. Learning is a continuous company-wide process as superiors motivate and train subordinates; as predecessors do the same for successors; and as team members at all levels share knowledge with one another.”
However, most of these principles, and educational and/or training research consider students’, employees’, athletes’, etc., errors committed by themselves which must be corrected as soon as possible to avoid further damages.
Based on this concept, but using already existing erroneous documents and teaching-learning materials as examples, the Error Recognition Model (ERM) was introduced [
7,
11,
12]. We use the very same model to define the entropy of digital texts (text entropy) and decide whether a text is correct or not.
1.1. Error Recognition Model
The Error Recognition Model (ERM) [
7,
11,
12] would be a solution for increasing the effectiveness of digital text management, since it has been proven more efficient and effective than the widely accepted tool-centered approaches, and the circulating misconceptions. Both are primarily rooted in the published teaching-learning materials, or rather tutorials, the disadvantages of tool-centered computer courses [
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43], and the believes of overconfident but ignorant end-users [
27,
28,
29].
“… the significant advantages of word processing are available exclusively to those who are proficient in the use of the hardware and software; they will be inaccessible to those who have only a little understanding of word processing. A stand-alone computer skills course (taught by a school or by a computer dealer) may not be the best means to teach substantial knowledge of word processing; examples and practice will inevitably be simulated and artificial, and there will be little motivation to fully understand the applications.”
It is proven that applying ERM [
12] in the teaching-learning process has advantages which the widely accepted tool-centered, low-mathability approaches miss [
2,
65,
66,
67,
68,
69,
70]. These advantages are due to “real-world” texts used as examples and the consideration of cognitive load at each step of method. The erroneous “real-world” texts perform a crucial role in motivation, where students claim proudly that they can do better. By keeping the cognitive load at bay [
44,
71,
72,
73,
74], we can make countermeasures immediately and develop students’ computational thinking skills step-by-step. Consequently, we can avoid unrepairable damage when students and end-users create, edit, and modify their own or somebody else’s documents.
1.1.1. Properly Formatted Text
The ERM accepts the definition of the properly formatted text [
7,
11], and, based on it, builds up a teaching-learning approach that focuses on the text, instead of the word processing tools and interfaces.
The definition of the properly formatted text has two constrains which are the following:
The text fulfils the requirements of printed documents (quantitative requirements, and errors detailed in
Section 1.1.2).
The content is indifferent to modification (qualitative requirements, and errors detailed in
Section 1.1.2)—the document is editable, but applied changes must be limited to the correct form of those actions that the user originally intended.
1.1.2. Error Categories
The focuses of ERM are the recognition of errors in digital texts (e.g., finding, being aware of, avoiding, and correcting them), learning how to avoid them, and transferring this knowledge and skills to other types of digital texts (e.g., from word processors to presentations and web pages, and the other way around). ERM teaches that we must be aware of errors, we must learn how to handle and avoid them to improve the quality of our works [
3,
4,
56,
57,
58,
59]. One of the primary principles of ERM is that errors are user-friendly tools in handling digital contents, as they are in the real world [
3,
4,
56,
57,
58,
59].
In accordance with the definition of the properly formatted text and due to the extremely high number of errors in digital texts, they must be categorized. Considering the terminology of both natural and artificial languages in connection with computers, errors are listed in two hypernym, then three and three hyponym categories [
11].
Quantitative error categories (recognizable in any printed or electronically displayed form, can be seen by the reader or viewer of the document):
- a.
syntactic (the grammar of the text);
- b.
semantic (the content of the text);
- c.
typographic (the appearance of the text) [
75,
76,
77,
78].
Qualitative error categories (recognizable in editable digital form only; therefore, invisible to the target audience, and seen exclusively by the author(s) and other participants handling the original or the modified file):
- a.
layout (the arrangement of characters and objects of the text);
- b.
formatting (applying formatting commands);
- c.
style (handling—applying, defining, reformatting—styles).
It is not rare that one error category triggers another or a third. In these cases, primary and secondary categories are applied to the errors, depending on which triggers the other. For example, in
Figure 1 Line 19 has a manual hyphenation which is a layout error. However, the manual hyphenation (with the Enter and Space characters in the middle of the word ‘parental’) creates syntactical and/or semantical errors (with the separate words ‘pa’ and ‘rental’).
1.1.3. The Application of ERM
The application of ERM in an educational environment consists of three major steps depending on the tools used by students/teachers can be unplugged (UP), semi-unplugged (SUP), and digital (D) [
12].
The first step is error recognition in two clearly distinguishable phases:
- a.
The marking, explaining (writing), and later categorizing the quantitative errors of the text in its printed form (paper, picture, or PDF). In this phase, the only source is the printed text (UP). This is the form of the document which readers and viewers see.
- b.
The marking, explaining (writing), and later categorizing the qualitative errors of the text in its editable (digital) form. In this phase, the primary source is the editable, opened document (if available with the turned-on
Show/Hide button to clearly present the non-printing characters [
22,
23,
24,
25]). The secondary source is the printed document where notetaking takes place. To distinguish the two types of error hypernyms, different colors are used to mark the errors. The coloring system would also serve students in practicing, rehearsing, and catching up (SUP).
The second step is correcting the errors of the document. In this phase, a correction algorithm is set up whose primary concept is to start with the errors of the widest range (domain), and finish with the least significant. The algorithm also considers correction with the Replace… command or with macros when repeated errors must be corrected (e.g., multiple empty paragraph marks, tabulator and/or space characters, repeated formatting) (D).
The third phase is the formatting of the text which, similar to correction, is based on an algorithm. The steps of the algorithm are primarily decided focusing on the range of the planned formatting commands, starting from those of the widest range to the least significant (D).
We must note at this point that there are cases where some steps of the third phase (formatting) must be conducted in the second phase (e.g., modifying page setup, setting Normal style).
The steps of ERM reveal that the focus is on the text [
12]. On one hand, the model supports the readers by making the text as legible and understandable as possible. On the other hand, it helps in avoiding and correcting qualitative errors, and making the text ready for effective modification and formatting restricted only to the intention of the author/editor. In this scenario, the text-editing application, the use of the GUI performs only a secondary role, meanwhile building proficiency in the ERM text-handling process.
Unlike traditional course books, teaching-learning materials, and tutorials [
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
42,
43], this concept does not start teaching text management through:
operating system instructions (this knowledge should have been brought in through knowledge-transfer, and if not, then it should be introduced and practiced somewhere else) [
30,
32];
toying with font-face appearances [
33,
34,
35,
36];
new features of the application [
30];
the introduction of the GUI objects [
30];
typing text.
Instead of these, in ERM real world texts with real contents are provided during the teaching-learning process, which idea is in complete accordance with the main concept of:
Informatics Reference Framework [
79,
80];
TPCK (Technological Pedagogical Content Knowledge) [
81,
82,
83];
Polya’s concept-based problem solving approach [
65];
Kahneman’s thinking fast and slow theory [
71] along with the cognitive load theory [
72];
Hattie’s results on teaching effectively [
73];
Chen’s Meaning System Model [
66].
Considering the combination of these theories, the teaching-learning materials can be adjusted to the students’ (in general, and end-users) age, background knowledge, interests, school subjects, work requirements, etc.
1.2. Detecting End-User Activities—ANLITA
To record what actions end-users perform in digital texts, our research group developed a dedicated logging application, named ANLITA (Atomic Natural Language Input Tracking Application). In the present research, ANLITA is primarily used to log all the keyboard actions and to screen-record the complete editing process conducted in Word documents. The program outputs two files:
a text file containing all the keyboard events;
a video file, in which the entire text handling process was recorded.
Using these two files, the complete text handling process can be retraced, the techniques and algorithms (if there was any) applied to the text can be revealed. Based on this data, an objective measurement system can be set up which might help us to provide information on the quality of the text, more precisely how efficiently the message of the natural language digital text is communicated.
2. Sample
For the present study, three documents of different content and length were selected, each carrying both quantitative and qualitative errors:
A single page proposition of a Grade 7 student voicing requests of their class for better conditions in the school (for short:
medicine) (
Figure 1). This document includes text-content only. (Line numbering shown in
Figure 1 was added for referencing purposes in the present paper.)
A teacher’s three-page long test paper (
Figure 2). This document includes a combination of text-content, pictures, other graphical objects, and two table-imitations (for short:
frenchfood).
An equation cut from a longer document created by a senior pre-service teacher of mathematics and library information (for short:
equation) (
Figure 3).
These documents are from our private collection, gathered from students and colleagues rendered unidentifiable.
In general, our study checked for the flexibility of these documents, e.g., how efficiently the intended modifications can be applied to them. Consequently, our primarily concerns were the qualitative errors [
7,
11]. To identify those, the visibility of non-printing characters perform a crucial role in the analysis, so all recordings and figures were created with the
Show/Hide button turned-on [
22,
23,
24,
25] and some with the text boundaries of the document sections made visible.
2.1. Document: medicine
The medicine document contains several layout errors in the form of multiple Space and Enter characters and Enter characters at the end of the lines (Lines 4, 5, 6, 12, 18, and 19). In general, these characters were meant to create left indentation and vertical spacing between paragraphs, and right alignment in Line 30. We could not explain the multiple Space characters in Line 34. There is a formatting and style error in Line 12 which is unreasonable (style Heading 1 with the Keep with next paragraph formatting, reformatted to match the appearance of the main body of the text). Line numbers were not part of the original document, we turned those on to enable us referring to the location of the errors in a more convenient and reliable way.
2.2. Document: frenchfood
The original
frenchfood document is a three-page long text created by a teacher with testing purposes. The length of the document depends on the settings of the
Normal style, but it was meant to be three pages long. The first page (
Section 1) has
Portrait, while the second and third pages
Landscape orientation (
Section 2) set up.
The document is burdened:
with layout errors in the form of multiple Tabulator, Space, and Enter characters,
a mixture of layout and formatting errors on the graphical objects (lines and textboxes both in the body and the fake headers),
style and formatting errors on fonts and paragraphs.
2.3. Document: equation
The content of the
equation document is a portion of a senior pre-service teacher’s lesson plan.
Figure 3 clearly presents the document creator’s attempted manipulation of the text (Ben-Ari [
5] calls this bricolage). Instead of inserting proper math formulae into the document using the readily available built-in equation editor, the author fabricated various text-positioning tricks to construct these formula-lookalikes. The errors in this piece of text are the following.
The first formula starts with a manual numbering. (Later in the analysis, the manual numbering was ignored since it does not perform any role in the editing of the equations.)
Numerators and denominators are typed in separate paragraphs.
Vincula are imitated by applying underline character formatting on the numerators.
Minus signs are substituted with underscore characters.
Plus signs and whole number are received a subscript character formatting.
Equal signs are imitated by blanks (Space characters) with double-underline formatting applied.
Space characters are used to horizontally position numerators and denominators.
This document has one further characteristic we must mention; the overconfident author blamed MS Word not allowing equation sign at end the of the lines (marked by a footnote in Formula 1, and by the imitation of footnotes in Formulas 2 and 3) (
Figure 3) [
27,
28,
29].
3. Methods
On the selected documents, a rigorous analysis was conducted to reveal their structures and to detect their errors. This is primarily an unplugged and/or semi-unplugged process according to ERM [
12].
Following the steps of ERM, in the second phase, the errors of the original documents were corrected, then the proper formatting took place. Finally, both to the original and the corrected-formatted documents, modifications were applied to measure and compare the entropy of the documents.
We must note that all these steps can be repeated by anyone interested. However, the steps detailed in the present paper were conducted by two of the authors. They both are professionals in text management, which helped them to set up a normalized algorithm to each text and to minimize the time assigned to the algorithm steps. Consequently, less experienced end-users repeating all these steps might provide different time and probability. However, these differences not necessarily deteriorate the entropy as the limit to how effectively one can handle a digital text, to how effectively one can communicate the outcome of a text handling process (
Section 6).
3.1. Correction of the Documents
Considering the content, each piece of text is unique. However, the analyses revealed that the primary concern our analysis is the improper use of non-printing characters. Since we were not present at the creation of the documents, we do not know whether the authors had these turned on or off [
22,
23,
24,
25]. Regardless of the authors’ awareness of the non-printing characters and our lack of this information, all the processes applied to the texts during the study are conducted and recorded with the turned-on
Show/Hide button. We can use this method to disambiguate whether characters or formatting are used to set up an appearance, which perform crucial role both in the analyses and the documentation of the analyses, and later in the dissemination of the findings.
A correction-algorithm was set up for to the medicine and frenchfood documents, along which their correction was executed. Beyond correcting the errors of a document, the algorithm serves our research to set up a lower bound on the average size (number of instructions and time) of each modification that end-users can apply to a text. With this method, we can define correction-entropy and the number of bits a text requires to be corrected.
These steps of the algorithms are presented in in
Section 5, along with the time spent on each step.
3.2. Formatting of the Documents
Following the correction of the documents, all the three texts were properly formatted which includes the modification of the Normal style. Furthermore, where it was necessary, minor adjustments were applied. This happened in the case of the frenchfood document where some of the pictures on the second page must be resized to fit the content of the three rows on one page.
In a similar way to correction, a lower bound on the average size of each formatting is set up. The steps of the algorithms are presented in in
Section 5, along with the time spent on each step.
The aims of the correction and formatting processes were to set up the entropy of the documents and find an objective measuring system which can distinguish erroneous texts from their properly formatted counterpart.
3.3. Correction, Formatting, and Statistics
In the following, the methods of the correction and formatting of the medicine and the frenchfood documents are detailed. Beyond the algorithms of these processes, the statistics and other graphical tools provided by the software (GUI) are added for giving more explanatory details.
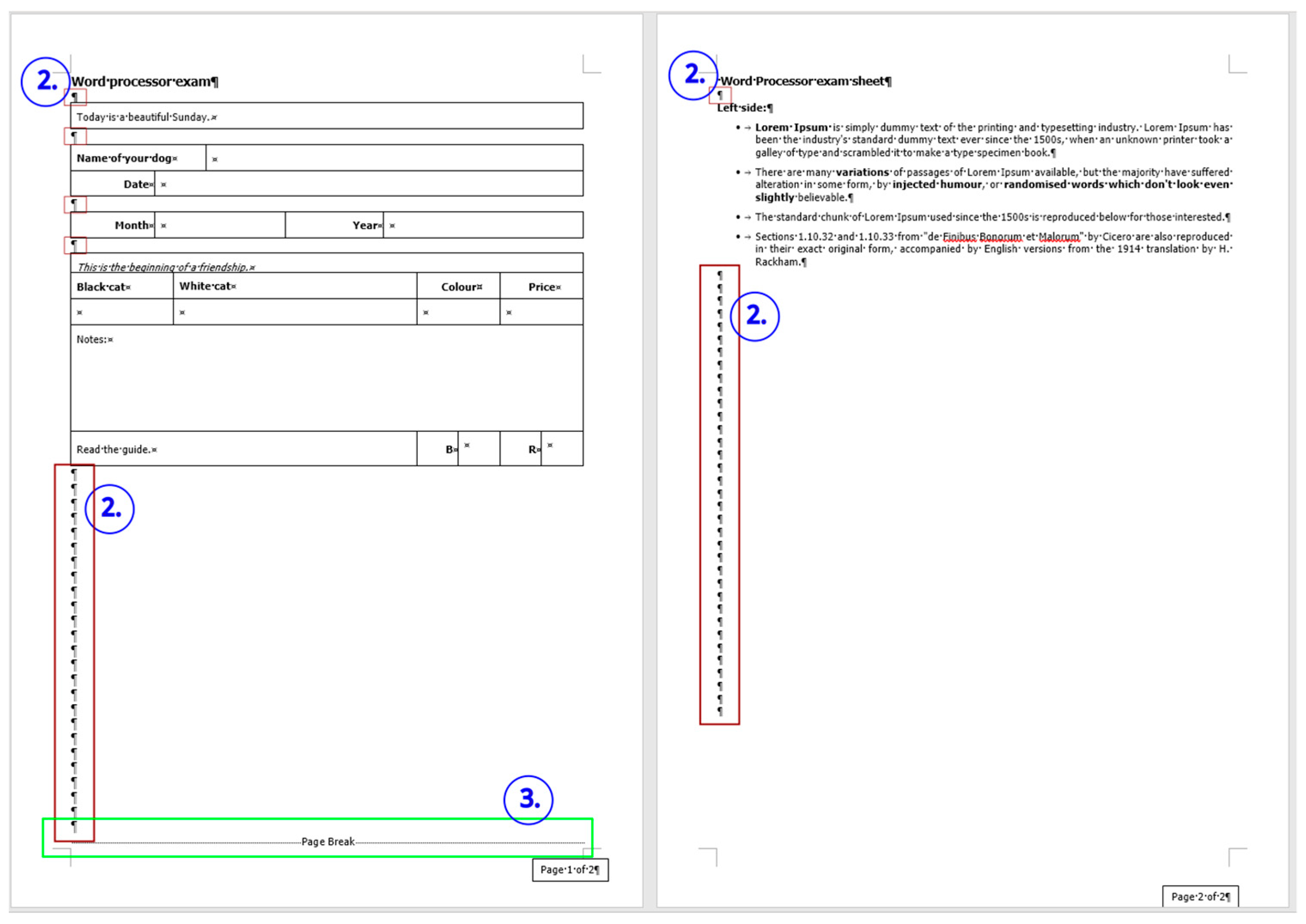
3.3.1. Document: medicine
The corrected
medicine document consists of 8 paragraphs (
Figure 4, right) compared to the 34 paragraphs in the original (
Figure 4, left).
The text boundaries (
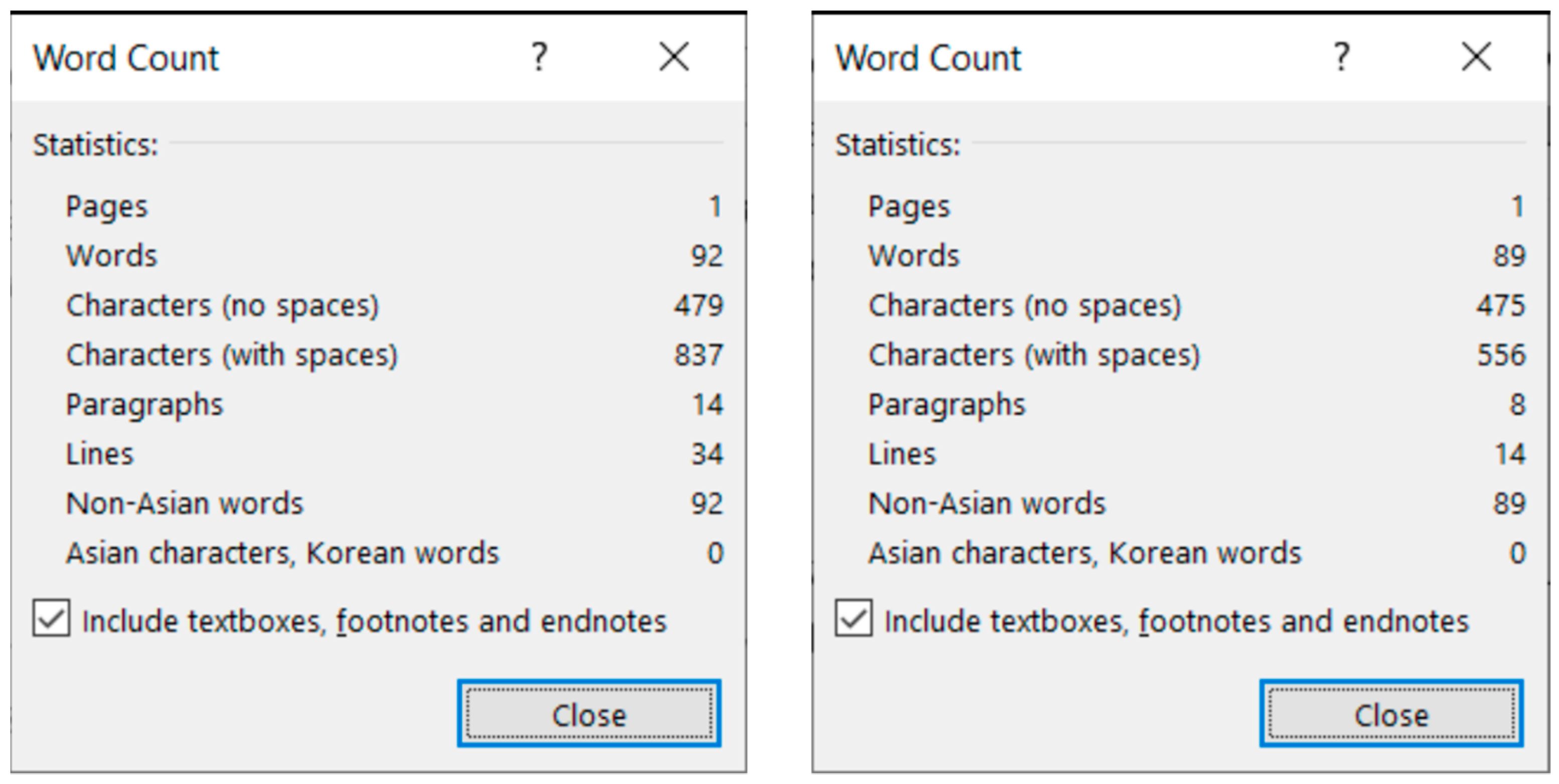
Figure 4) reveal that MS Word is able to recognize each individual paragraph of the document, including the empty ones. However, the document statistics calculated and shown by the application are manipulated (
Figure 5) by leaving out the empty paragraphs, despite that they perform a crucial role in the text-handling processes. According to the statistics (
Figure 5), the original medicine document has 14 paragraphs, because MS Word counts those paragraphs only where at least one alphabetical/numerical/special printable character content is present.
In the case of the medicine document, the aim of the correction was to clear all the unnecessary and incorrect characters and formats of the document. While in the formatting phase, we wanted to apply proper formatting steps to set up a correct document as similar in appearance to the original one as possible.
3.3.2. Document: frenchfood
The comparison of the boundaries of the erroneous (
Figure 6) and the corrected document (
Figure 7), and the statistics of the original and the correct
frenchfood documents (
Figure 8) reveals that the empty paragraphs are not counted in the statistics. Furthermore, it can be concluded that only those paragraphs are counted which have printable characters, and, in that respect, neither figures nor drawn shapes count as paragraph-content.
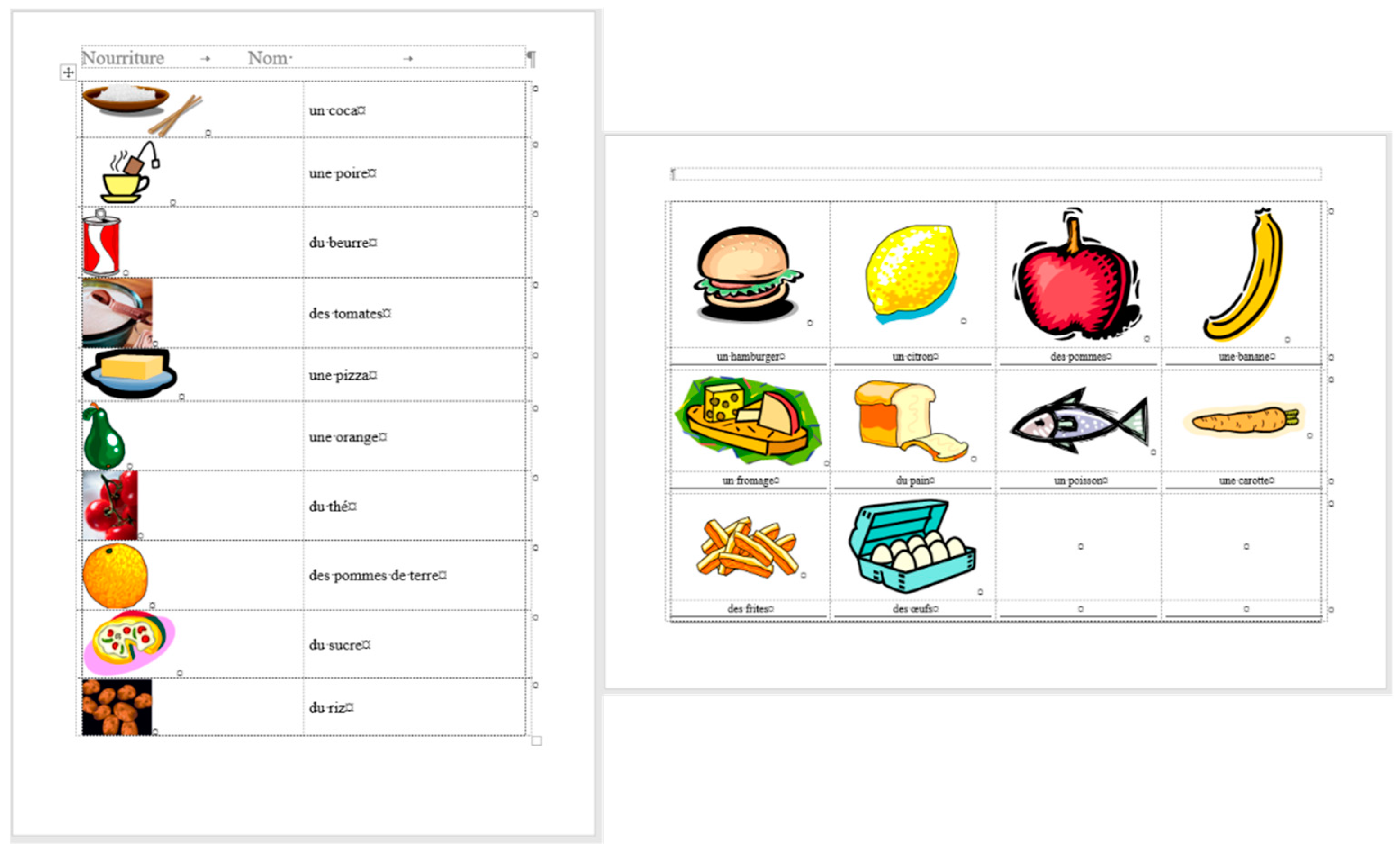
According to the MS Word statistics (
Figure 8), in the original document there are 15 paragraphs: 10 + 1 on Page 1 (P1), and 3 + 1 on Page 2 (P2). On P1, the paragraph of the orange does not count (there is no printable character in this paragraph), while both of the text boxes do (one on P1 and the other on P2). In the corrected document, there are 10 paragraphs on P1 and 3 on P2. However, the text boundaries reveal that the original
frenchfood document is loaded with uncounted empty paragraphs, and there are two unnecessary text boxes.
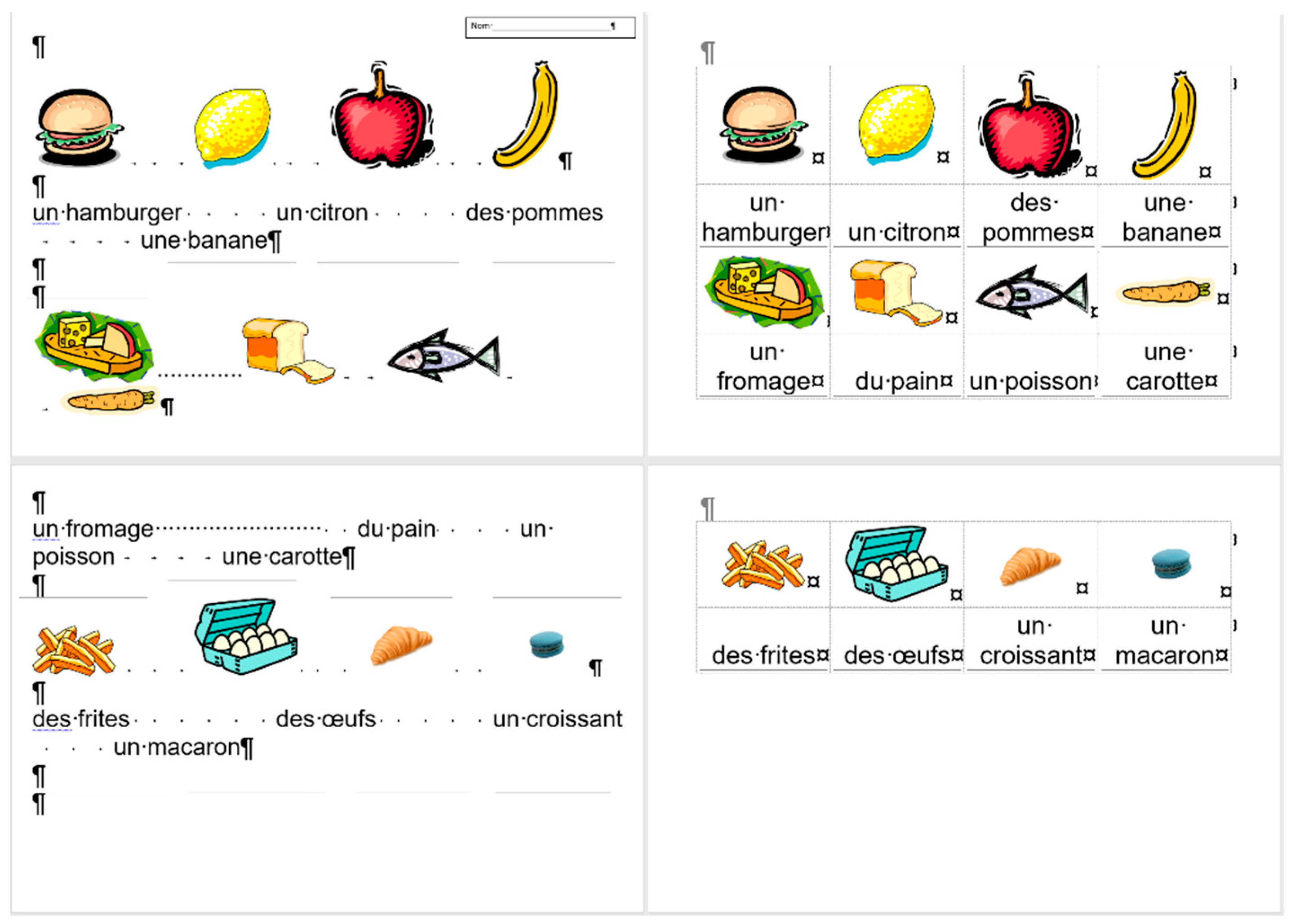
Figure 9 presents the corrected and formatted
frenchfood document. In this document, the first paragraph of P1 is moved to the header, a table was created on each page, and the pictures and food names were put side by side on P1, and names were arranged below the pictures on P2. Furthermore, on P2 a line (bottom border with paragraph domain) was added to each food name to mimic the appearance seen on the original document.
In the correction phase of the analysis, the aim was to create two tables holding all the pictures and food names. On P1, we kept the original order of the pictures and names, while on P2, the pictures and names got rearranged into matching pairs.
3.4. Modification of the Documents
Beyond calculating correction- and formatting-entropy of the documents, we also wanted to calculate the modification-entropy. In this context, modification means that either content is added to the document, or a formatting is performed.
The modification of the documents was planned and executed in accordance with the content and the characteristics of the texts. Considering these criteria, the following modifications were applied to both the original and the corrected documents (
Table 1).
3.4.1. Document: medicine
In the
medicine documents two modifications were applied (both to the original and the corrected). In the first analysis, two words were added to the second paragraph (as counted in the correct document) (
Figure 10), while in the second analysis, the font size of the paragraph was changed (
Figure 11).
3.4.2. Document: frenchfood
In the original
frenchfood document on P2, ten figures were arranged into three rows. The first two rows consist of four and four pictures, while the third row contained only two pictures. To fill in this gap, two pictures and two food names were added to the content of P2 (
Figure 12).
The second modification to the
frenchfood document was the changing of the font size.
Figure 13 presents the results of this modification both in the original (left) and in the corrected (right) documents. While in the original document further amendments were required to match the pictures and the food names, in the corrected document no additional steps were required.
3.4.3. Document: equation
Introducing the equation editor in word processors is considered difficult, thus it is seldom taught in schools and trainings. In general, only advanced or special classes deal with the subject. However, to measure the difficulty and the complexity of creating equations, we launched several subjective and an objective test. In the subjective tests, the equation editor was introduced in a Grade 7 math class. In the subjective tests, the equation editor was introduced in a Grade 7 math class. Before we introduced the equation editor, these students had already used touch screen displays and their fingers to enter equations. During the testing period where the equation editor was introduced and used, both the activities and the results of the students, along with the time spent on the computer were observed. Furthermore, the eligibility of the formulae were considered.
To find objective measures, we first applied our planned modifications to the formula-lookalikes in the erroneous document following the jiggery-pokery method of the original author, then to the properly constructed equations. (
Figure 3).
The modifications performed in this objective measuring process were:
calculating the common denominator of the fractions (
Figure 14),
adding a new fraction to the equation (
Figure 15),
solving the substitution problem by simplifying the equation (
Figure 16).
The final step of the test was to measure the entropy of both solutions, to see how much data is required to put on the communication channel to handle equations (formulas).
5. Results
To calculate the entropy of a document we decided to take into consideration:
first level modifications, which are fundamental actions (typing, changing font size, and inserting pictures),
the correction of the document to avoid carrying the inefficient modification processes,
the formatting of a document.
If the document is properly edited and formatted, the correction and the formatting of the document is left out from both the text-management process and the analysis. Furthermore, if the original document carries errors, modifications were applied in both the original and the corrected documents to be able to compare the messages which the two forms of the document carry.
One further technique in the process of measuring the entropy of digital texts is the grouping of repeating steps. With this method, for example handling multiple Space, Tab, and Enter characters are not logged character by character. This method allows space for various solutions handling these repetitions (e.g., deleting with replacement, selecting by blocks or double clicks, etc.), reduces the steps of the algorithm to a reasonable size, and the time assigned to these steps can be measured in seconds. The results of the analyses are shown in the following tables (Tables in
Section 5) where the steps are presented as modification events (Column
Algorithm), to which the duration, the information content and the entropy values are assigned(
Time (tk),
Ik, and
Ek, respectively).
Considering the formatting of the documents, in the testing process these steps were performed only in the correct version of the documents to avoid the multiplication of errors.
Following these concerns, the next sections provide the results of how the algorithms were set up and the entropy assigned to these algorithms.
5.1. Document: medicine–Correction
The algorithm of the correction of the
medicine document is presented in
Table 2. In general, it is found that two bits of data (
Eb) are required to put on the communication channel to correct this document. The crucial steps of the algorithm are the following:
the recognition of the extra Space and Enter characters,
how to delete these characters,
how to remove all the font and paragraph formats to clear the typographic and formatting errors,
recognizing and correcting syntax errors.
Clearing all the errors of the medicine document took around 230 seconds. To remove multiple Space and Enter characters two methods were recorded:
selecting blocks and deleting them,
using replacement (Replace… command), where two Space or Enter characters were substituted by one and handling the line opening and closing Space characters.
In this document, there was no significant difference between the times spent on the two methods.
After correcting the
medicine document, it has eight paragraphs, and there is no unnecessary character left (
Figure 4 right, and
Figure 5 right). In the next step, the formatting of the corrected document took place.
5.2. Document: medicine–Formatting
The algorithm of the formatting, along with the time spent on the atomic steps (events) and the information content of the steps of the
medicine document is presented in
Table 3. To format this document three bits of data (
Eb) must be put on the channel.
At first sight (and originally meant to be by the author), this document is an easy to handle little thing. However, the power of this document is underestimated. The entropy of the formatting reveals that the knowledge pieces required by this document are extremely demanding. The three bits of data needed to format this document indicate that firm background knowledge is necessary to complete the task. Calculating the entropy of this “easy” task explains the errors of the original document. Furthermore, it proves that minimal guidance [
74] is not enough to teach fundamental word processing. A lot more data must be put on the channel than course books and other teaching-learning materials suggest [
33,
34,
35,
36,
37,
38,
39,
40].
5.3. Document: medicine–Modification
The modification of the medicine document has four stages:
increasing the font size of one paragraph in the original (
Table 6) and the corrected (
Table 7) documents (
Figure 11).
In the erroneous text, typing two words into a paragraph requires additional steps to restore the appearance similar to the original, imitating the left indent. These additional steps are typing and deleting Space and Enter characters. With this method, three bits of data must be put on the channel to reach the expected arrangement (
Table 4). However, we must mention a further side effect of this solution: whenever the content of the text is changed, adjusting the text to the fake ident must be repeated, which is an extremely time- and resource-consuming process.
Completing the “insert two words” task in the corrected document requires only one bit of data. In this case, purely the intention of the end-user (the typing) needs to be completed, no collateral activities are imposed.
The comparison of the entropy of the two corrections reveals that handling an erroneous document is much more demanding than a correct one. In this case, typing two words required almost three times more time, and around three times more data put on the channel in the erroneous document.
Further typing and content modification would have the same requirements with a linear increase in time. However, we calculated the time and the entropy of formatting of the
medicine document (
Table 3) and found that these tasks required three bits of data. The comparison of the entropy of typing in the erroneous document is around as much as the entropy of the formatting. We can conclude that if end-users want to work effectively in a digital text, the content first need to be correctly edited and formatted. In any other cases, the word processing activities are disadvantageous, we lose time, money, and resources.
Increasing the font size of a paragraph in the original (erroneous) document requires four bits of data (Eb). This can be explained by the collateral actions imposed on the user to realign the fabricated left indent. These actions are beyond the modification intention of the end-user (which was simply to just change the font size) and based on the entropy this is quite demanding.
In the corrected document, changing the font size of the selected paragraph took less than 5 s, and one bit of data must be put on the channel.
5.4. Document: frenchfood–Correction
The
frenchfood document is supposed to have two tables, one on Page 1 (P1) and the other on Page 2 (P2). Instead of using two actual tables, the original document is loaded with fiddly attempts to imitate them. Due to the high number of layout errors of the
frenchfood document, the correction took more than 380 s, and four bits of data (
Eb) were needed (
Table 8). This shows that recognizing the errors of a document is quite demanding and should be handled more consciously during the teaching-learning process; primarily, to avoid these errors, secondarily to be able to correct them before any modification is applied to the document.
The steps of the correction algorithm reveal that after deleting the multiple Space, Tab, and Enter characters, the most important knowledge pieces are the inserting and formatting tables.
5.5. Document: frenchfood–Formatting
The formatting of the corrected document took around 100 s, and three bits of data must be put on the channel (
Table 9). End-users intended to modify this document must apply fundamental font and paragraph formatting in tables, handle borders in table with paragraph domain, format header with positioned tabulators, and set up the location of the header.
5.6. Document: frenchfood—Modification: Inserting Picture and Text
In the modification phase of the research, two pictures of food and their names were inserted into the empty cells of T2 on P2 (
Figure 12). The modification was conducted both in the original (erroneous) and the corrected and formatted documents. The steps of these processes are presented in
Table 10 and
Table 11.
It is found that the modification of the original document is more demanding than that of the correct one. It required more than twice as much time and knowledge pieces in the erroneous document than in the corrected one. In both cases, the pictures needed to be inserted and the words needed to be typed, which took around the same amount of time. Adjusting the size of the pictures was conducted in both documents without any serious alteration in time. However, in the original document additional steps were required to adjust the pictures and the words (one below the other and horizontally centered). These steps took up time.
5.7. Document: frenchfood–Modification: Changing Font Size
Changing the
Normal style with the font (Arial) and font size (32 pt) of the original and the corrected documents show remarkable differences. While in the original document it took around 300 s (
Table 12), in the corrected document, only around 20 s were needed (
Table 13). Furthermore, it is also remarkable that changing the font size and then adjusting the pictures and text require four bits of data (
Table 12), while in the corrected document one bit is needed (
Table 13). In general, we can conclude that handling erroneous documents is more difficult, complicated, and demanding than handling correct ones.
5.8. Document: equation–Modification
The
equation document is different both from
medicine and
frenchfood in the sense that it cannot be corrected. The formulae of the
equation document are so poorly designed that our research group gave up on its correction but created the correct formulae using the built-in equation editor of the word processor.
Figure 17 presents the paragraphs of the erroneous and corrected
equation documents, with the text boundaries made visible.
In this phase of our research, the original equation document was modified by adding new fractions to the original formula in accordance with the following concept:
Calculating the common denominator of the fractions (
Figure 14) requires five bits of data in the erroneous (
Table 14), and four in the correct (
Table 15) document. Furthermore, the time spent on the actions is almost four times more in the erroneous document than in the correct one (
Table 14 and
Table 15). In the correct document, creating the common denominator requires nothing else but positioning the cursor, deleting the old value and typing the new. In the case of the erroneous formulae, additional time is required to adjust the position of denominators and numerators with Space characters, and formatting the equal sign and the vincula with further adjustments.
The following step of the analysis was to imitate the solving of the presented problem in the original lesson plan (
Figure 16 and
Figure 17). In this phase, several atomic actions were performed, for example inserting new fractions, typing numerators and denominators, simplifications, and calculations. Similar to calculating the common denominator, beyond the required elements in the formulae, collateral adjustments and formatting were imposed. Considering the number of knowledge pieces required to complete this task, in both cases five bits of data must be put on the channel (
Table 16 and
Table 17). However, the time spent on the task is 2.6 times more in the erroneous document (
Table 16 and
Table 17).
In the third test of the
equation documents, a new fraction was added to the existing one (
Figure 15). In this case, the number of bits which must be put on the channel in the erroneous (
Table 18) and the correct (
Table 19) documents was 3 and 2, respectively. The time spent on this modification is 3.3 times more in the erroneous (
Table 18) than in the correct (
Table 19) document.
6. Discussion
6.1. Changing Duration and Adding a New Atomic Step
In the previous section, the entropy of correction, formatting, and modification tasks in the three sample documents were detailed, and the results presented using the newly introduced concept of “text-entropy”. In the discussion section, we focus on the question, how the entropy of a task changes when:
It is found that changes in the duration of atomic steps is a subcategory of the insertion of a new atomic step. Consequently, this latter, more general modification is analyzed.
Figure 18 presents the modification of the correct
frenchfood document. An additional fictitious atomic step is added to the steps listed in
Table 11 (with a t = 100 s duration mapped in
Figure 18). The time assigned to the action is in the range of [1, 1000] with a 1 s difference.
It is found that in both cases the entropy increases until we reach a certain amount of time (tmax), which is understood as further knowledge pieces are added as input data. However, when tmax is reached the entropy starts to decrease, this also means that without adding further atomic steps to the process, the time conceals further events. We call this concept hidden or time-concealed data.
6.2. Where We Stand
Millions of ill-treated Word documents circulate both in closed communities and on the internet providing bad samples. In both cases, the available documents include educational materials meant to teach word processing and offering exercises on the subject. In general, it is found that these matters and problems are invisible to IT professionals, corporate managers, and researchers in both the fields of information systems and computer education.
In
Figure 19,
Figure 20 and
Figure 21 erroneous Word tutorials and exam papers are presented. The samples show that even educational documents do not fulfill the requirements of the properly structured and formatted text and are set up as bad examples.
These exam papers repeat exactly the kind of errors our research analyzed. The examples prove the negligent text-handling habits and demonstrate errors that exist in the teaching–learning process of text-editing in general.
The selected errors are the following:
centering paragraph with Tab character (
Figure 19),
incorrect use of expression: open an application instead of start/run (
Figure 19).
6.3. Building Corpora
To our knowledge, open-source datasets of Word documents do not exist. Another problem, considering corpora, is that the copyright issues are not defined. Consequently no one knows under what conditions such corpora can be created and used. This explains our choice of samples in the paper, where the Word documents are from our private collection.
Author-data is rarely available, consequently there is no place to ask for permission.
There are no designated data banks of corpora through which copyright issues might be handled.
This entire process is a black box.
Documents found on the public internet are not guaranteed to stay there.
7. Conclusions
This paper presents how text-entropy can be calculated from text handling processes, which are primarily formatting, correction, and modification (including the creation of a text). The word processing tasks can be algorithmized, broken into events (atomic steps) to which durations of time can be assigned. These lengths of time serve as sources of probabilities, bases of information entropy, and, from now on, of text-entropy.
In the present study, three erroneous MS Word documents were selected to demonstrate how text-entropy can be applied to real-world digital texts. In this process, we have to build the algorithm of the tasks, measure the time spent on the events, and finally calculate the entropy of the completed tasks.
In the comparison of the erroneous and the correct documents, the text-entropy can be calculated from the entropy of modification tasks. In the present analysis, first level modifications [
19]—typing, changing font size, inserting picture—are conducted in the
medicine and the
frenchfood documents, and inserting formulae in the
equation documents. Furthermore, the entropy of correction and formatting of the original (erroneous) documents must be taken into consideration when calculating text-entropy. These pieces provide data about the complexity of documents, and on how correct or how erroneous they are.
We found that modifying a properly structured and formatted digital text is less demanding than its erroneous counterpart. It means that less data must be put on the communication channel than in the case of erroneous documents. The analysis also revealed that not only the quantity of the data is lower, but the quality of the data (the required knowledge pieces) is higher. As the consequence of these two findings, it is proven that the modification time of erroneous documents is severalfold that of the correct ones, even in the case of minimal first level tasks. It is also proven that to avoid the multiplication of time- and resource-consuming tasks, we need to correct the documents before their modification.
With the concept and the methods provided in the present paper, we were able to find an objective measurement—the entropy of digital texts—that can describe the quality of documents. Based on this value, it can be told how correct or how erroneous a digital text-based document is.
The analyses can be further extended to several directions. First, we must emphasize that the algorithms were set up and the steps were conducted by the members of our research group, who are professionals in text management and handling word processors. Less experienced end-users might need more time and different algorithms to conduct the modifications, which can generate results different from those presented here. Furthermore, it is clear from the results that end-users, primarily students must be taught how to design and create properly structured and formatted digital texts, and how to work effectively with digital texts by using complex word processors. As the results of our analyses revealed, the focus of education should be realigned from the interface of an application to the content and structure of the digital texts.
It is also found that the presented approach for calculating text-entropy provides a method that can be followed both in educational and industrial (business/office/firm) environments to test the correctness of documents and reveal their discrepancies, if there is any. The aim of introducing this concept and testing method is to reduce the use and waste of both human and machine resources in the process of handling digital text-based documents.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
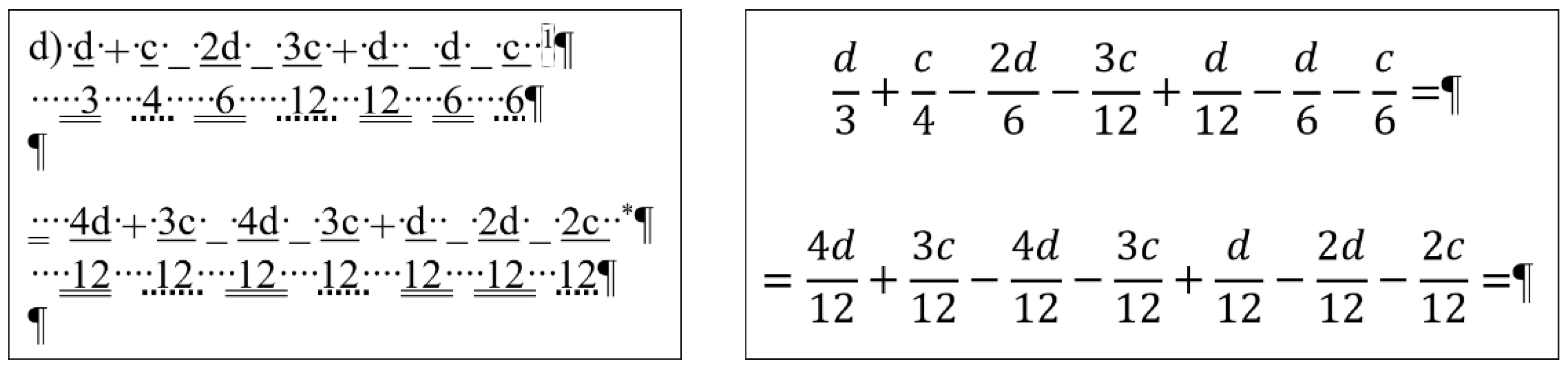{kind=link}
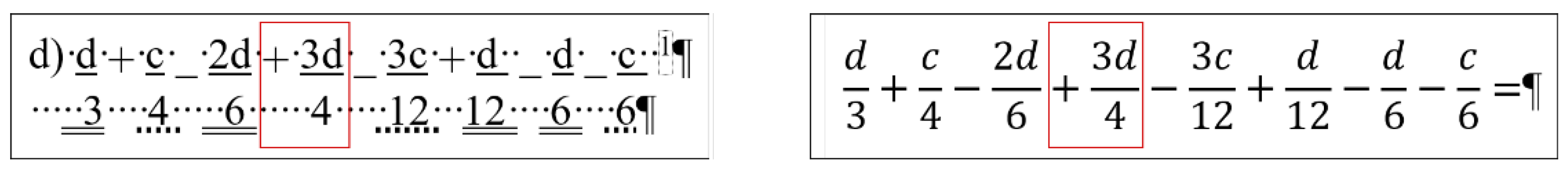{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}