
PBQ-Enhanced QUIC: QUIC with Deep Reinforcement Learning Congestion Control Mechanism

 ,
, 
Abstract
:1. Introduction
- First, we developed a novel congestion control mechanism, referred to as proximal bandwidth-delay quick optimization (PBQ) by combining proximal policy optimization (PPO) [16] with traditional BBR [17]. It is able to effectively improve the convergence speed and link stability during the training phase. We then applied the presented PBQ to the QUIC protocol and formed a new version of QUIC, i.e., PBQ-enhanced QUIC, which aims to enhance its adaptivity and throughput performance.
- Second, for the purpose of reducing the action space and establishing the connection of the values of the congestion window (CWnd) for each interaction, we used continuous action ratio as the output action of PBQ’s agent. Additionally, in the design of the utility function, we used a relatively simple formulation of the objective function as the optimization objective and introduced a delay constraint. By doing so, our proposed PBQ-enhanced QUIC achieves higher throughput and maintains a low RTT.
- Third, we built a reinforcement learning environment for QUIC on the network simulation software ns-3, where we trained and tested PBQ-enhanced QUIC. The experimental results showed that our presented PBQ-enhanced QUIC achieves much better RTT and throughput performance than existing popular versions of QUIC, such as QUIC with BBR and QUIC with Cubic [18].
2. QUIC Protocol
2.1. The Basic Concept of QUIC
2.2. Handshake
2.3. Multiplexing
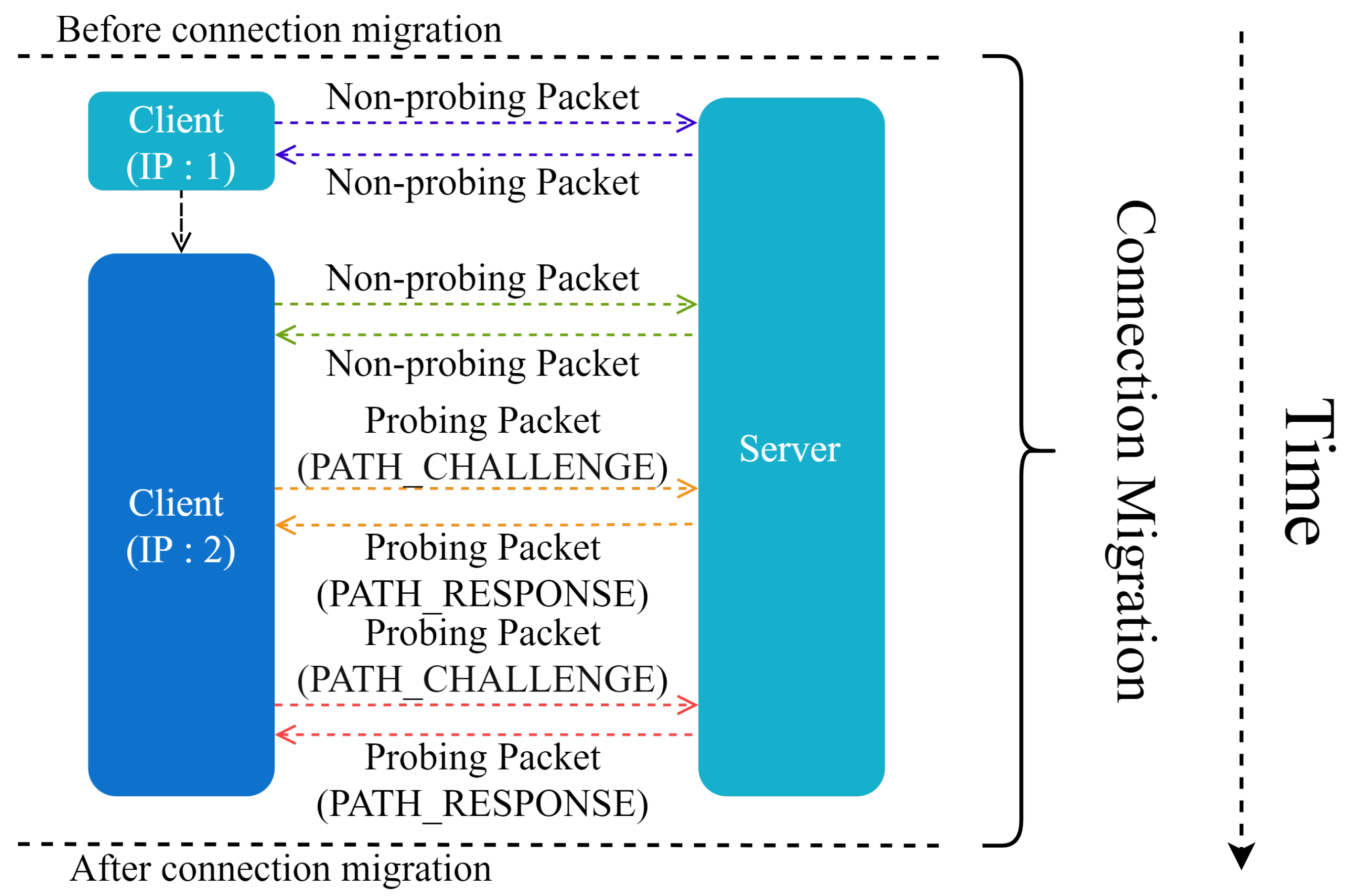
2.4. Connection Migration
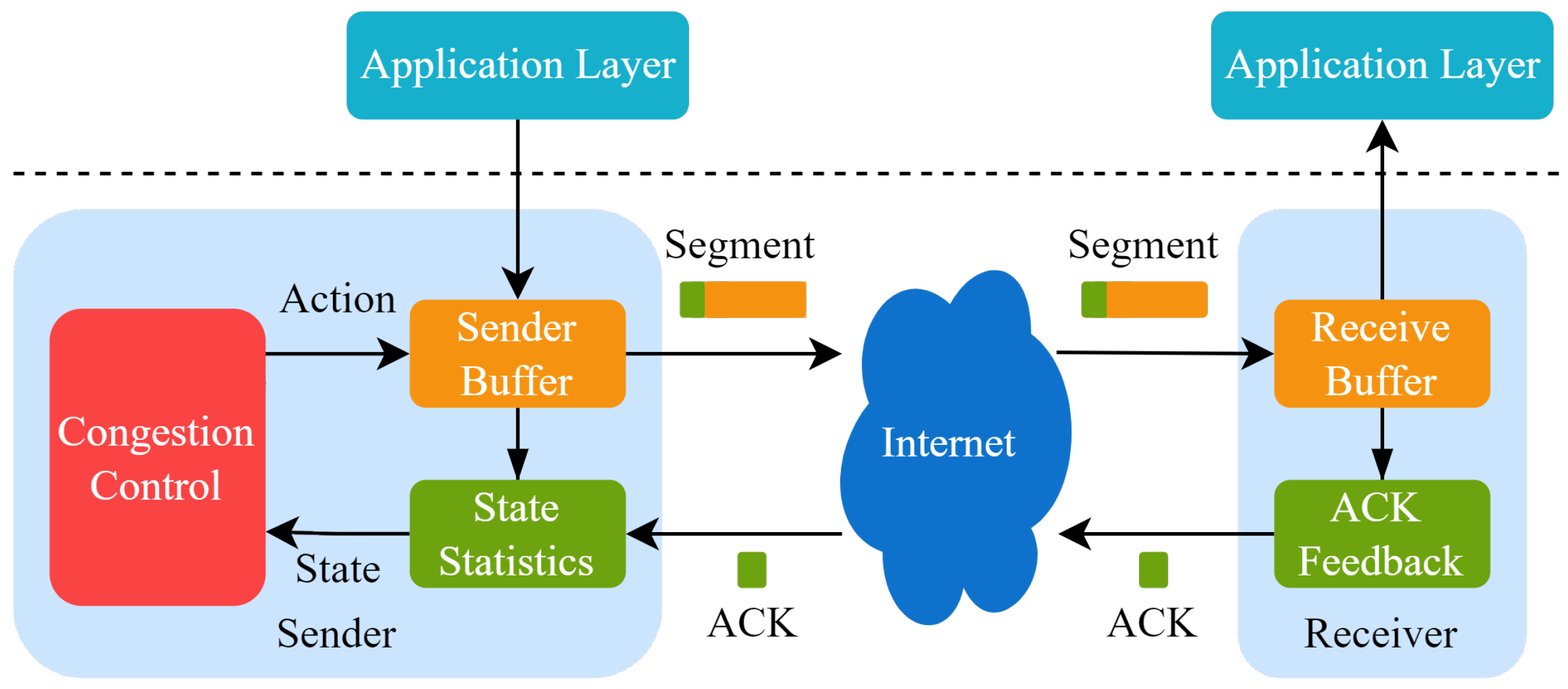
2.5. Congestion Control in QUIC
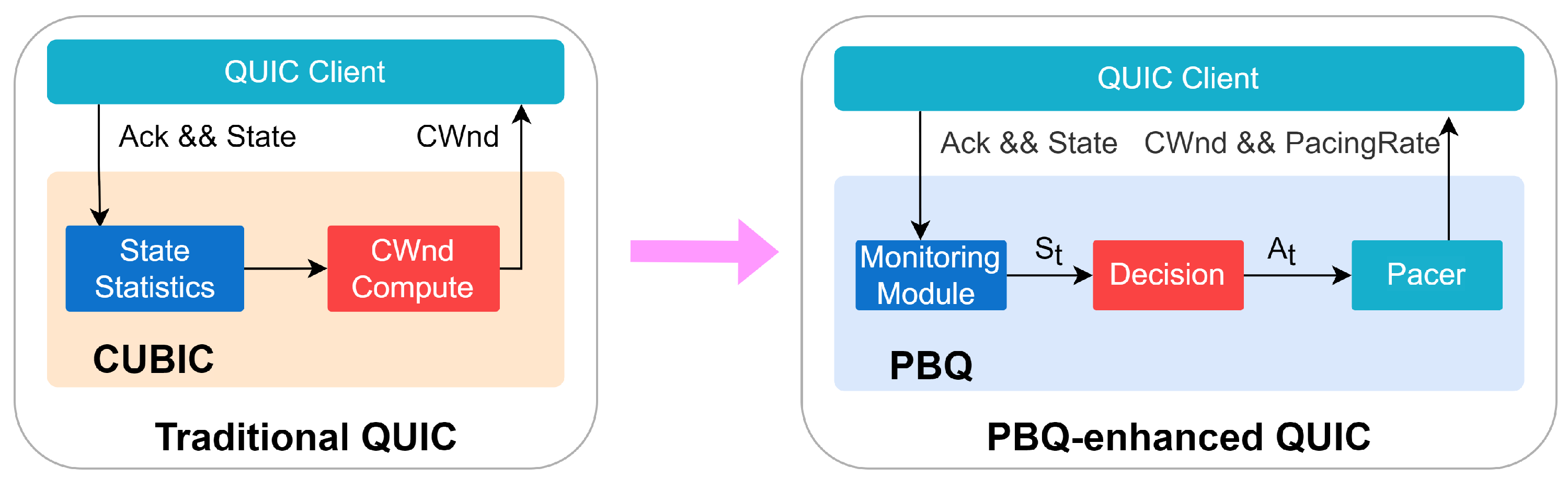
3. The PBQ-QUIC
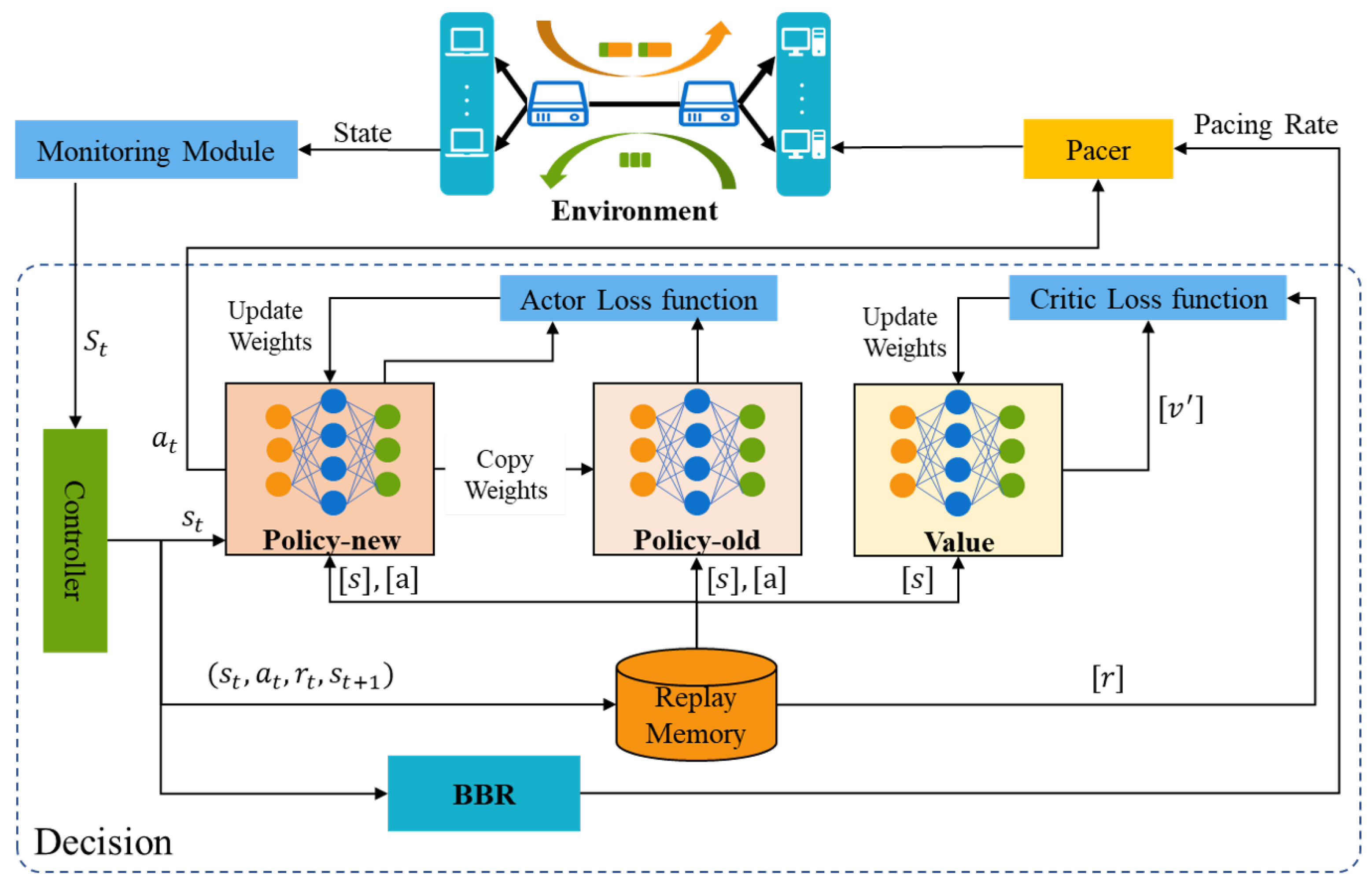
3.1. The Basic Idea of PBQ
- Monitoring Module
- Reward Function Design
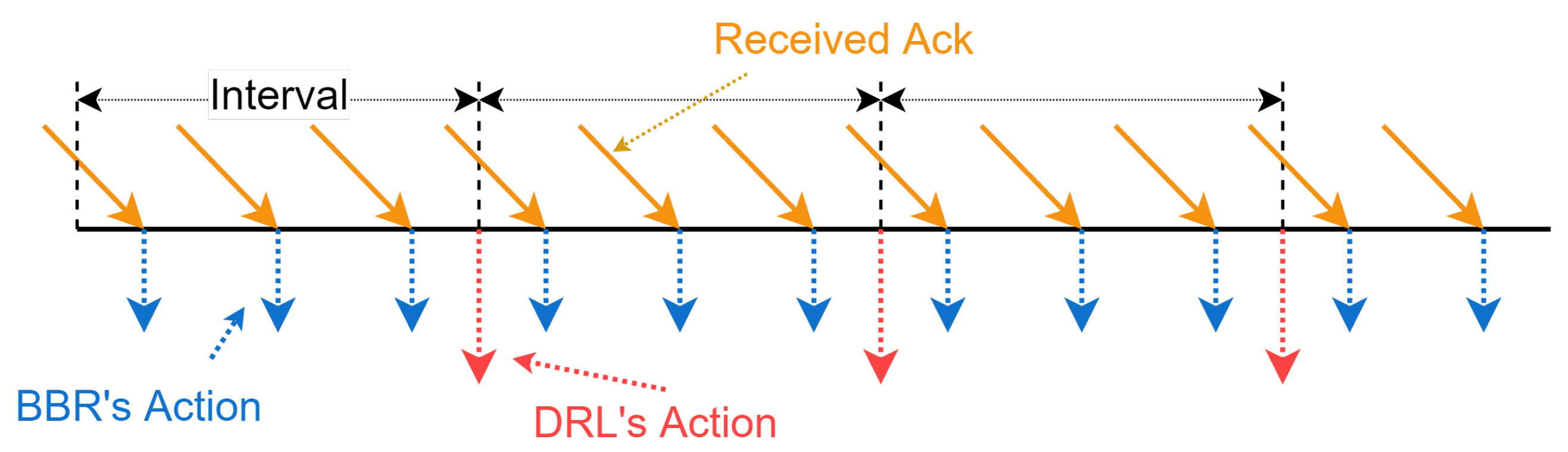
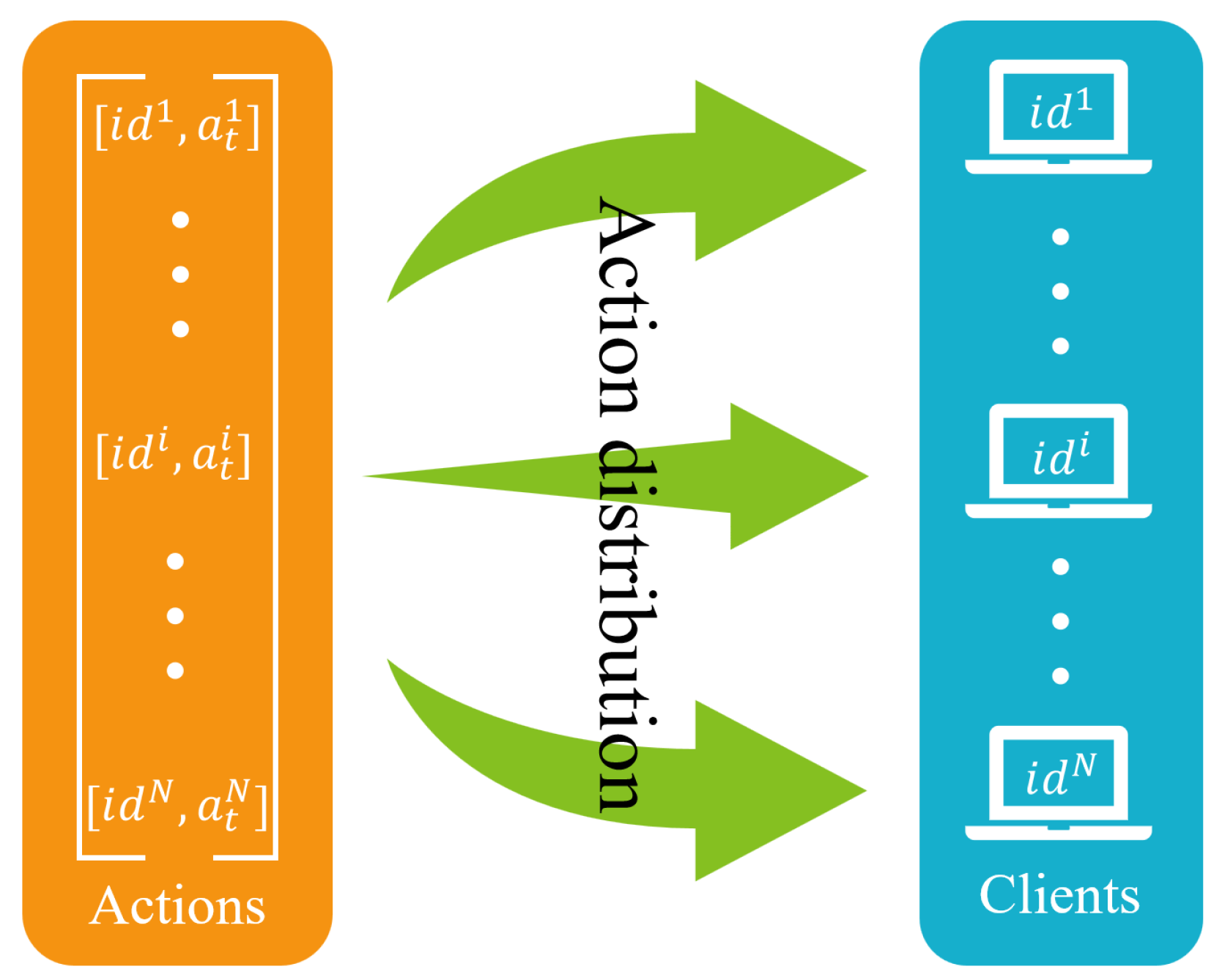
- Action Design
- Learning Algorithm for PBQ
| Algorithm 1 PBQ’s learning algorithm. |
|
- Pacer
3.2. PBQ-Enhanced QUIC
4. Simulation Performance
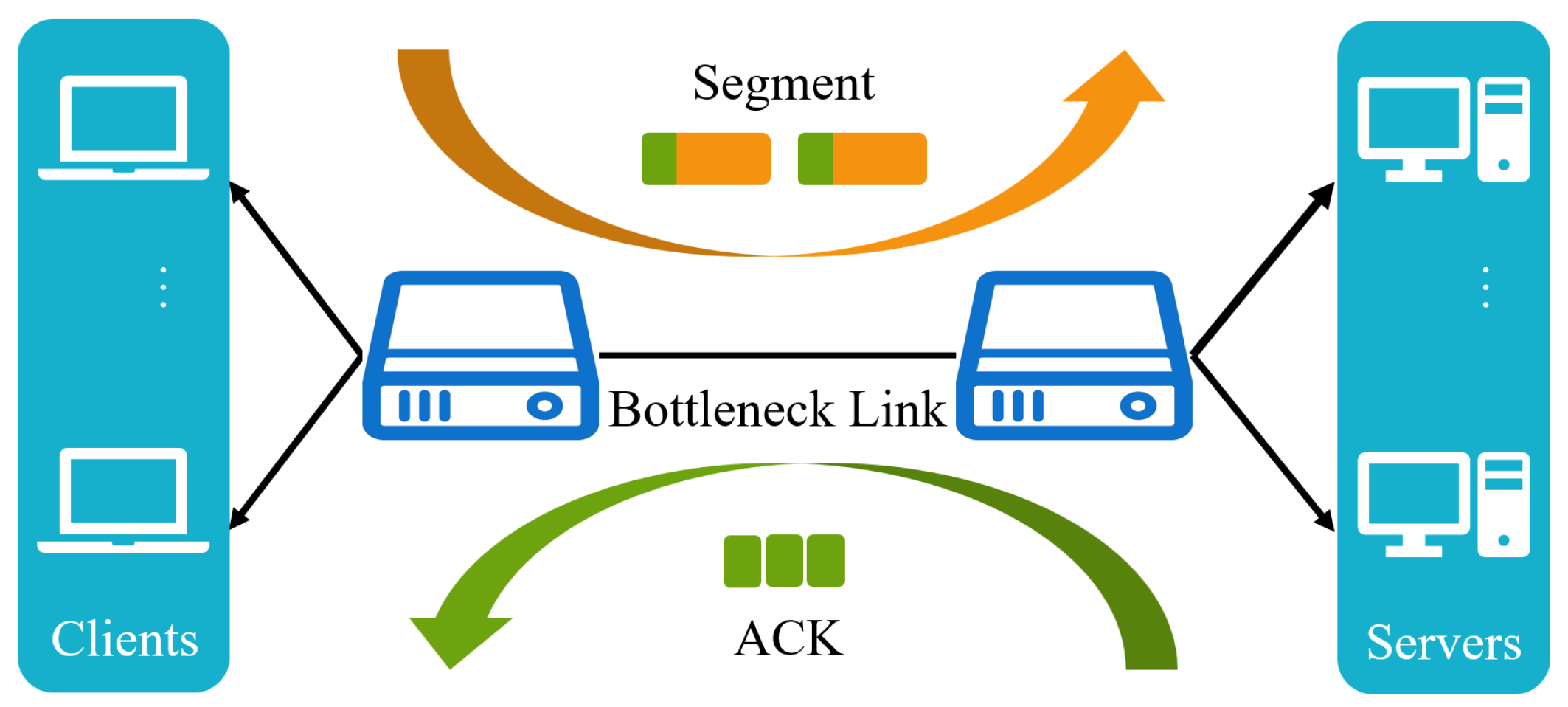
4.1. Our Simulation Environment
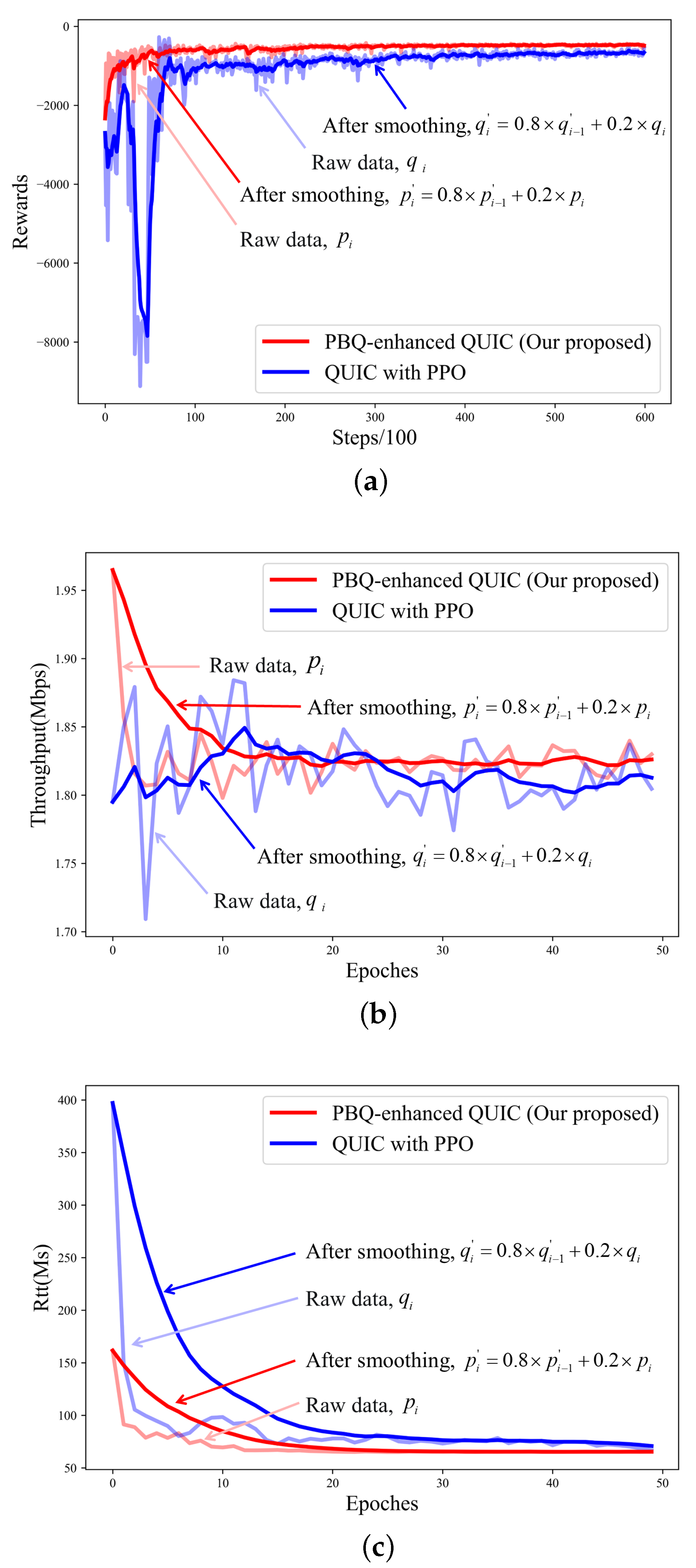
4.2. Training
4.3. Testing
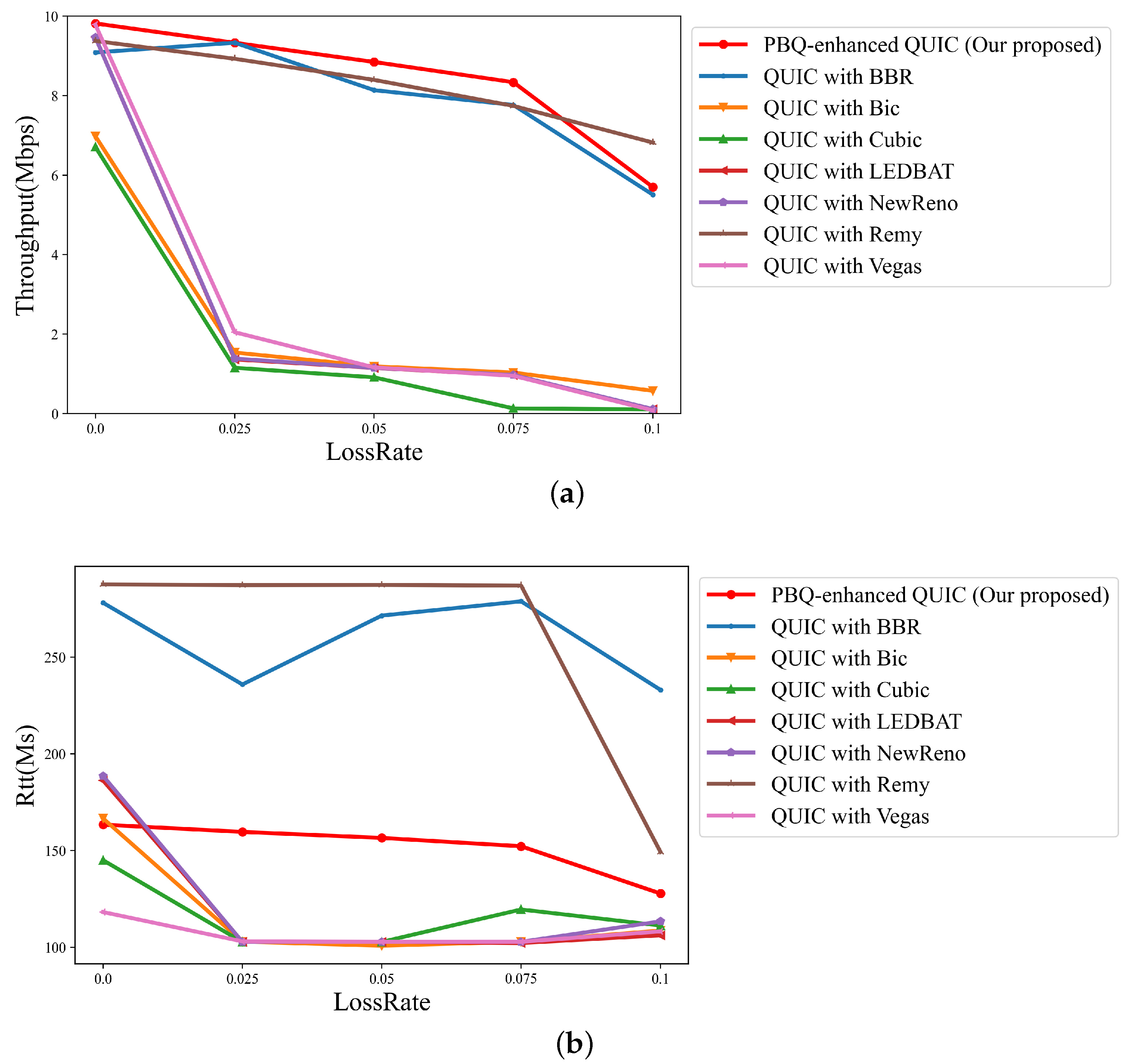
4.4. Packet Loss Rate
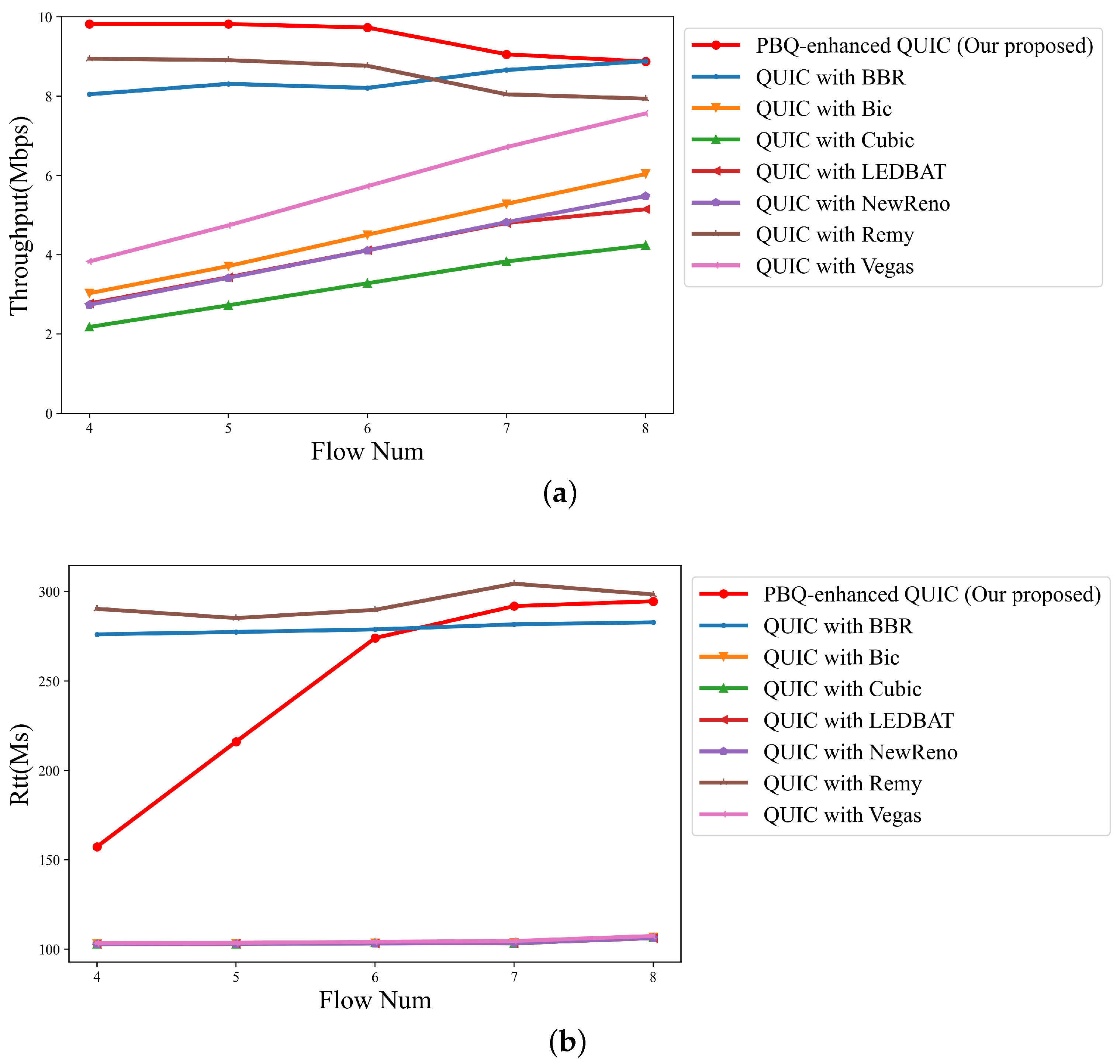
4.5. Flow Number
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TCP | Transmission Control Protocol |
| HOL | Head-of-line |
| QUIC | Quick UDP Internet Connection |
| RTT | Round-trip time |
| DRL | Deep reinforcement learning |
| PBQ | Proximal bandwidth-delay quick optimization |
| BBR | Bottleneck bandwidth and round-trip propagation time |
| PPO | Proximal policy optimization |
| CWnd | Congestion window |
| IoT | Internet of Things |
| UDP | User Datagram Protocol |
| BDP | Bandwidth-delay product |
| RL | Reinforcement learning |
| PCC | Performance-oriented congestion control |
| QTCP | Q-learning TCP |
| MsQUIC | Microsoft QUIC |
| RFC | Request for comments |
| ACK | Acknowledge character |
| IETF | Internet Engineering Task Force |
| TLS | Transport layer security |
| HTTP | Hyper Text Transfer Protocol |
| AIMD | Additive increase multiplicative decrease |
| C/S | Client/server |
| LEDBAT | Low extra delay background transport |
References
- Langley, A.; Riddoch, A.; Wilk, A.; Vicente, A.; Krasic, C.; Zhang, D.; Yang, F.; Kouranov, F.; Swett, I.; Iyengar, J.; et al. The QUIC Transport Protocol: Design and Internet-Scale Deployment. In Proceedings of the ACM SIGCOMM, Los Angeles, CA, USA, 21–25 August 2017. [Google Scholar]
- Jacobson, V. Congestion avoidance and control. ACM SIGCOMM Comput. Commun. Rev. 1988, 18, 314–329. [Google Scholar] [CrossRef]
- Sander, C.; Rüth, J.; Hohlfeld, O.; Wehrle, K. Deepcci: Deep learning-based passive congestion control identification. In Proceedings of the 2019 Workshop on Network Meets AI & ML, Beijing, China, 23 August 2019; pp. 37–43. [Google Scholar]
- Chen, X.; Xu, S.; Chen, X.; Cao, S.; Zhang, S.; Sun, Y. Passive TCP identification for wired and wireless networks: A long-short term memory approach. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 717–722. [Google Scholar]
- Brown, N.; Sandholm, T. Safe and nested subgame solving for imperfect-information games. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Winstein, K.; Balakrishnan, H. TCP ex Machina: Computer-Generated Congestion Control. In Proceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, Hong Kong, China, 27 August 2013. [Google Scholar]
- Dong, M.; Meng, T.; Zarchy, D.; Arslan, E.; Gilad, Y.; Godfrey, P.B.; Schapira, M. PCC Vivace: Online-Learning Congestion Control. In Proceedings of the 15th Usenix Symposium on Networked Systems Design and Implementation (Nsdi’18) 2018, Renton, WA, USA, 9–11 April 2018; pp. 343–356. [Google Scholar]
- Li, W.; Zhou, F.; Chowdhury, K.R.; Meleis, W. QTCP: Adaptive Congestion Control with Reinforcement Learning. IEEE Netw. Sci. Eng. 2019, 6, 445–458. [Google Scholar] [CrossRef]
- Abbasloo, S.; Yen, C.-Y.; Chao, H.J. Classic Meets Modern: A Pragmatic Learning-Based Congestion Control for the Internet. In Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, Online, 10–14 August 2020; pp. 632–647. [Google Scholar]
- Jay, N.; Rotman, N.; Godfrey, B.; Schapira, M.; Tamar, A. A Deep Reinforcement Learning Perspective on Internet Congestion Control. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 3050–3059. [Google Scholar]
- Clemente, L.; Seemann, M. Quic-Go. Available online: https://github.com/lucas-clemente/quic-go (accessed on 3 August 2016).
- Microsoft. Msquic. Available online: https://github.com/microsoft/msquic (accessed on 26 October 2019).
- Kharat, P.; Kulkarni, M. Modified QUIC protocol with congestion control for improved network performance. IET Commun. 2021, 15, 1210–1222. [Google Scholar] [CrossRef]
- Cloudflare. Quiche. Available online: https://github.com/cloudflare/quiche (accessed on 1 February 2021).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Cardwell, N.; Cheng, Y.; Gunn, C.S.; Yeganeh, S.H.; Jacobson, V. BBR: Congestion-Based Congestion Control: Measuring bottleneck bandwidth and round-trip propagation time. Queue 2016, 14, 20–53. [Google Scholar] [CrossRef]
- Ha, S.; Rhee, I.; Xu, L. CUBIC: A New TCP-Friendly High-Speed TCP Variant. ACM SIGOPS Oper. Syst. Rev. 2008, 42, 64–74. [Google Scholar] [CrossRef]
- Iyengar, J.; Thomson, M. RFC 9000 QUIC: A UDP-Based Multiplexed and Secure Transport. Omtermet Emgomeeromg Task Force; ACM Digital Library: New York, NY, USA, 2021. [Google Scholar]
- Yan, P.; Yu, N. The QQUIC Transport Protocol: Quantum-Assisted UDP Internet Connections. Entropy 2022, 24, 1488. [Google Scholar] [CrossRef]
- Kurose, J.F.; Ross, K.W. Computer Networking: A Top-Down Approach, 7th ed.; Pearson FT Press: Upper Saddle River, NJ, USA, 2016. [Google Scholar]
- Floyd, S.; Kohler, E.; Padhye, J. Profile for Datagram Congestion Control Protocol (DCCP) Congestion Control ID 3: TCP-Friendly Rate Control (TFRC); RFC: Marina del Rey, CA, USA, 2006; ISSN 2070-1721. [Google Scholar]
- Henderson, T.R.; Lacage, M.; Riley, G.F.; Dowell, C.; Kopena, J. Network simulations with the ns-3 simulator. Sigcomm Demonstr. 2008, 14, 527. [Google Scholar]
- Gawlowicz, P.; Zubow, A. ns-3 meets OpenAI Gym: The Playground for Machine Learning in Networking Research. In Proceedings of the 22nd International Acm Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Miami Beach, FL, USA, 25–29 November 2019; pp. 113–120. [Google Scholar]
- De Biasio, A.; Chiariotti, F.; Polese, M.; Zanella, A.; Zorzi, M. A QUIC Implementation for ns-3. In Proceedings of the 2019 Workshop on NS-3, University of Florence, Florence, Italy, 19 June 2019. [Google Scholar]
- Xu, L.; Harfoush, K.; Rhee, I. Binary increase congestion control (BIC) for fast long-distance networks. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; pp. 2514–2524. [Google Scholar]
- Rossi, D.; Testa, C.; Valenti, S.; Muscariello, L. LEDBAT: The new BitTorrent congestion control protocol. In Proceedings of the 19th International Conference on Computer Communications and Networks, Zurich, Switzerland, 2–5 August 2010; pp. 1–6. [Google Scholar]
- Floyd, S.; Henderson, T.; Gurtov, A. The NewReno Modification to TCP’s Fast Recovery Algorithm; RFC: Marina del Rey, CA, USA, 2004; ISSN 2070-1721. [Google Scholar]
- Brakmo, L.S.; O’Malley, S.W.; Peterson, L.L. TCP Vegas: New techniques for congestion detection and avoidance. ACM SIGCOMM Comput. Commun. Rev. 1994, 24, 24–35. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Description |
|---|---|
| Current congestion window | |
| Cata update interval | |
| Average delivering rate (throughput) | |
| Averaged RTT | |
| Average loss rate of packets |
| Attribute | Value |
|---|---|
| Number of flows | 2 |
| Bottleneck bandwidth | 2 Mbps |
| RTT | 30 ms |
| Queue capacity | 75 Kilobytes |
| Queue scheduling algorithm | First Input First Output (FIFO) |
| Attribute | Value |
|---|---|
| Number of flows | 2∼8 |
| Bottleneck bandwidth | 10 Mbps |
| RTT | 100 ms |
| Packet loss rate | 0%∼10% |
| Queue capacity | 75 Kilobytes |
| Queue scheduling algorithm | FIFO |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Li, S.; Ge, Y.; Xiong, G.; Zhang, Y.; Xiong, K. PBQ-Enhanced QUIC: QUIC with Deep Reinforcement Learning Congestion Control Mechanism. Entropy 2023, 25, 294. https://doi.org/10.3390/e25020294
Zhang Z, Li S, Ge Y, Xiong G, Zhang Y, Xiong K. PBQ-Enhanced QUIC: QUIC with Deep Reinforcement Learning Congestion Control Mechanism. Entropy. 2023; 25(2):294. https://doi.org/10.3390/e25020294
Chicago/Turabian StyleZhang, Zhifei, Shuo Li, Yiyang Ge, Ge Xiong, Yu Zhang, and Ke Xiong. 2023. "PBQ-Enhanced QUIC: QUIC with Deep Reinforcement Learning Congestion Control Mechanism" Entropy 25, no. 2: 294. https://doi.org/10.3390/e25020294
APA StyleZhang, Z., Li, S., Ge, Y., Xiong, G., Zhang, Y., & Xiong, K. (2023). PBQ-Enhanced QUIC: QUIC with Deep Reinforcement Learning Congestion Control Mechanism. Entropy, 25(2), 294. https://doi.org/10.3390/e25020294