1. Introduction
As a key component of the motor drive system for electric vehicles, a healthy state of the gearbox is critical to the safe operation of autonomous ships, since they are prone to suffer from faults due to heavy loads or mechanical deterioration [
1,
2,
3]. Therefore, fault diagnosis for critical components of the motor drive system is vitally important [
4]. However, early minor faults are a challenging diagnostic task, because the fault features are weak and easily submerged by strong noise interference, which makes them difficult to extract and identify [
5].
In general, the existing minor fault diagnosis methods can be classified into three categories: physical model-based methods, expert knowledge-based methods, and data-driven methods [
6,
7]. However, it is difficult to establish accurate physical models for complex systems, which limits the application of physical model-based methods in the engineering field [
8]. On the other hand, the expert knowledge-based methods require unique expertise in specific areas, which have limited their generalization [
9]. Data-driven methods have received wide attention from engineers since only monitoring data of the operation status are required [
10]. As a data-driven approach, deep learning has a good effect on the fault feature extraction of monitoring data. Compared with shallow learning methods, deep learning has the ability to approximate complex functions by means of layer-by-layer feature extraction [
11]. According to the difference in network structure, deep learning methods can be classified into four classes: deep belief network (DBN), convolutional neural network (CNN), recurrent neural network (RNN), and stacked auto-encoder (SAE) [
12,
13,
14,
15]. Since a 1D vibration signal can be easily collected, the deep neural network (DNN) constructed by SAE is preferred in gearbox fault diagnosis based on deep learning. However, the features of minor faults are generally very weak, and they can be easily buried in strong environmental noise and high-order harmonic components.
The comprehensive extraction capability of minor fault features is affected by strong noise or the limited feature extraction ability of traditional DNNs. The existing DNN-based minor fault diagnosis methods can be classified into three classes: DNN-based minor fault diagnosis method using preprocessing for denoising, DNN-based fault diagnosis method using post-processing for fusion, and fault diagnosis methods using DNN with more powerful feature extraction.
On the aspect of the preprocessing of DNNs, Chen et al. [
16] performed Fast Fourier Transform (FFT) to obtain the frequency spectrum of fault signals, and then the frequency spectrum was fed to SAE, which can effectively diagnose faults with weak symptoms in the time domain but significant symptoms in the frequency domain. However, FFT is a linear transform, so it cannot detect minor faults with nonlinear and non-stationary characteristics. Li et al. [
17] used Variational Mode Decomposition (VMD) as a preprocessing tool to decompose the original vibration signal with noise into different components. Then, the decomposed signal is fed to SAE, such that it can perform well in the fault diagnosis of a planetary gearbox with insignificant wear faults or others. However, the decomposition level of the VMD algorithm cannot be adaptively selected. Tang et al. [
18] used complete ensemble empirical mode decomposition with adaptive noise and Fast Fourier Transform as a preprocessing tool to extract time–frequency features; then, the extracted features are fed to SAE to achieve the accurate diagnosis of minor faults polluted by noise. Although signal preprocessing can alleviate the incapability of diagnosing minor faults submerged by strong noise, the minor fault features may be mis-removed by simply preprocessing the monitoring data. Thus, it is faced with the side effects of DNN-based fault diagnosis using preprocessing.
The problems mentioned above can be avoided by utilizing the post-processing methods of decision-level fusion. On the aspect of post-processing, Jin et al. [
19] designed a decision fusion mechanism for multiple feature extraction. Multiple optimization criteria are used to train a unique SDAE model, such that different features involved in a unique set of data are extracted from different points of view. Then, different classification results can be obtained by using these features, and a decision mechanism based on multi-response linear regression is developed to fuse these classification results, which effectively improves the accuracy of planetary gearbox minor fault detection. Zhang et al. [
20] proposed a decision fusion mechanism to fuse the classification of CNN and SDAE. For the purpose of the accurate diagnosis of minor faults, D-S evidence theory is used to incorporate a CNN’s capability to process 2D images and SDAE’s capability to process 1D sequences. Although decision-level fusion can effectively solve the problems faced by the preprocessing methods, information loss is serious since the fusion is only performed on the final output of SAE, without taking deep fusion into account.
For this goal, we need to design new networks or learning skills to achieve more powerful DNN feature extraction. Stacked denoising auto-encoder (SDAE) is a commonly used learning tool to alleviate noise effects. On the aspect of powerful feature extraction, Lu et al. [
21] used SDAE to decrease noise such that gearbox weak fault features buried by noise can be better recognized. Chen et al. [
22] developed an improved SDAE model with moving windows to reconstruct pure operating data from data polluted with different levels of noise. Rashidi [
23] proposed a correlative SAE and DNN, which realizes output-related fault diagnosis by building two new constructive and demoting loss functions relatively. Zhu et al. [
24] designed a stacked pruning sparse denoising auto-encoder to diagnose minor faults. The developed pruning strategy can eliminate the neurons contributed by pruning the output of SDAE. In such a sense, weak features of minor faults can be better extracted since the non-superior units are pruned out. However, this pruning method may eliminate all information, which is not a satisfactory outcome. Zhou et al. [
25] proposed a new DNN structure with a sparse gate to reduce the influence of less contributed neurons, thus achieving minor fault diagnosis with data affected by noise. Although SDAE does well in noise reduction, it is still limited by the poor feature representation capacity without using the idea of information fusion.
The question of how to gain a more comprehensive feature representation using a fusion strategy is significant. Shao et al. [
26] developed a fusion mechanism to fuse the features extracted by auto-encoders with different activation functions. The extracted features of two auto-encoders are merged before feeding into the classifier to accurately recognize the minor fault. Kong et al. [
27] built several SAEs with different activation functions for feature extraction from different aspects in the first step. They then designed a fusion mechanism with a feature pool to merge the different features, which can be used for minor fault diagnosis. Shi et al. [
28] developed a fusion mechanism to fuse the output of a DNN, using the raw data, FFT data, and WPT data as the input of the DNN, respectively. The purpose of fusion is to achieve more comprehensive features from the time domain, frequency domain, and time–frequency domain to recognize minor faults. Zhou et al. [
29] developed a deep multi-scale feature fusion mechanism to fuse the features extracted on adjacent layers of a unique SAE. It performs well in minor faults since it can combine features on adjacent layers to compensate for the information missing during the process of layer-by-layer feature extraction. Although Refs. [
26,
27,
28,
29] used the same network structure to extract different features by using different fusion mechanisms, a single mode of data is used to fuse features extracted from different aspects, which will inevitably result in feature redundancy. Designing a new learning algorithm to fuse data from different modes is significant in comprehensive feature extraction. Subsequently, Zhou et al. [
30] proposed an alternative fusion mechanism to fuse features extracted by SAE to the 1D vibration data and CNN to the 2D image data, respectively. Ravikumar et al. [
31] built a multi-scale deep residual learning and stacked LSTM model to achieve gearbox fault diagnosis by fusing features extracted using multiple CNN models and feeding them into a stacked LSTM model. Since this method fully uses heterogeneous data, it can achieve more accurate diagnosis for minor faults.
However, the methods mentioned above cannot effectively extract trend features involved in 1D time series. The fusion of LSTM to trend features and a CNN to static features can be used to solve these problems. Chen et al. [
32] proposed an embedded LSTM-CNN auto-encoder to extract trend features that contain both local features and degradation trend information from vibration data. The fused features can be fed into a fault classifier such that minor faults can be well diagnosed. Zhou et al. [
33] proposed a fusion network with a new training mechanism to diagnose gearbox minor faults, which is extracted by LSTM to the 1D time series and a CNN to the 2D image data. Although trend features can be extracted by LSTM, it is difficult to train with a large number of network parameters and may suffer from gradient disappearance when dealing with long time series.
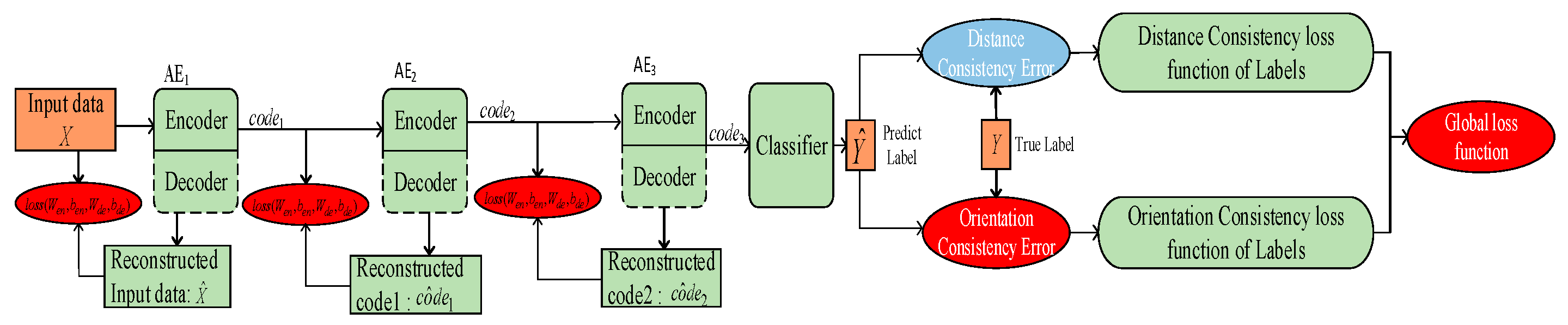
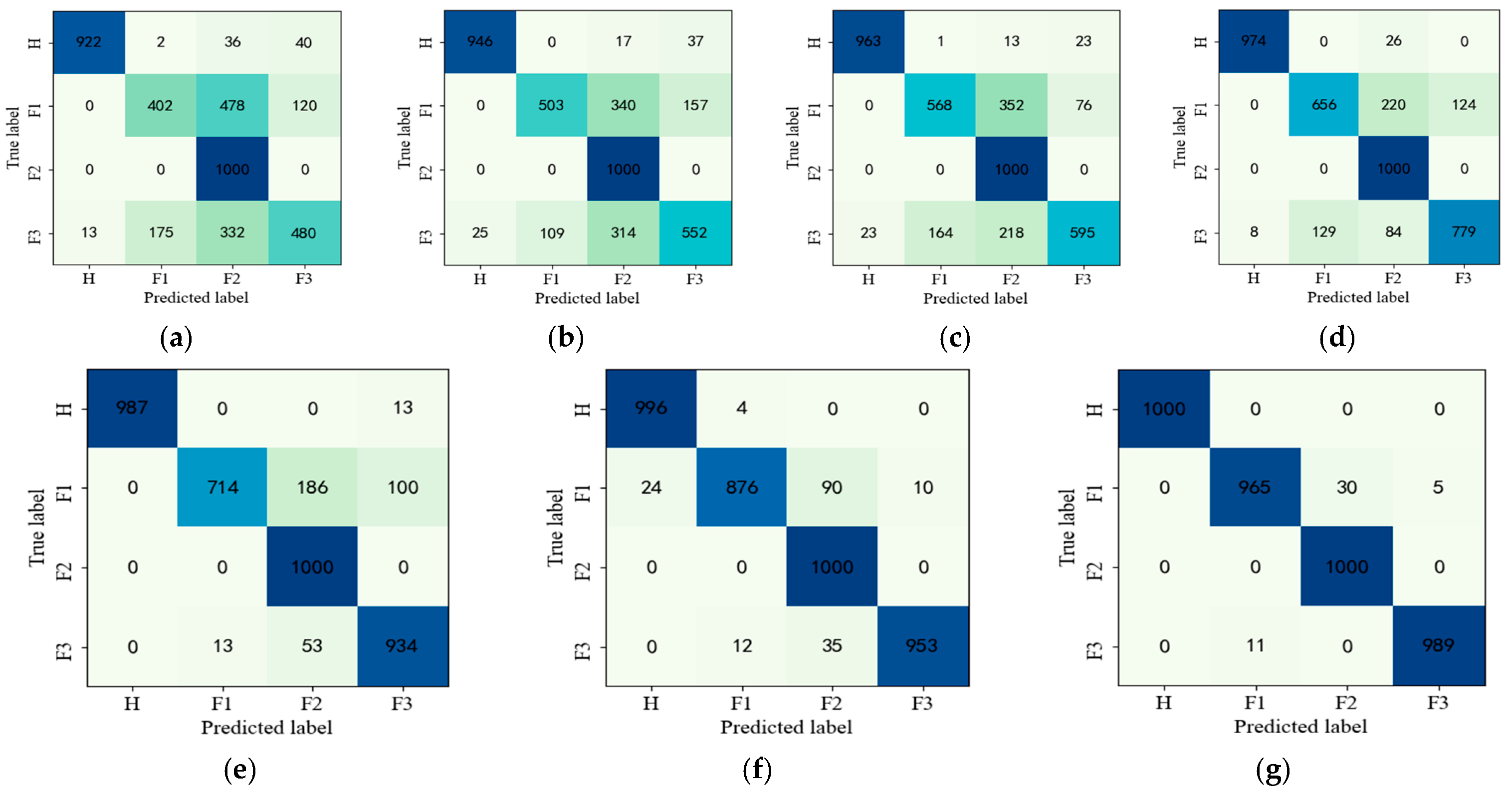
This paper focuses on solving the problem encountered by traditional DNNs to diagnose minor faults using a small number of training samples polluted with strong noise. A new training mechanism is established by designing a new loss function where trend feature consistency and fault orientation consistency are both taken into account, such that similar minor faults can be well discriminated. The contributions of this paper are as follows:
1. This paper establishes a new training mechanism for a DNN-based fault diagnosis model to make it more powerful for trend feature representation and the discrimination of similar faults that have equal or similar values of membership.
2. A new loss function for layer-by-by pre-training is designed by taking the consistency of auto-correlation and cross-correlation into account to characterize the trend features involved in the fault signal, such that the extracted features can be more accurate. The loss function considering the consistency of fault orientation is also designed for the backpropagation adjustment of the model to ensure its capability to discriminate similar faults.
3. In the engineering field, when there is only a small number of fault samples polluted by strong noise available, the proposed method is of much significance, since it can provide a more advanced learning mechanism for DNNs to accurately extract the potential weak features of minor faults. Thus, it provides an effective means to secure the accuracy of minor fault diagnosis.
The structure of this paper is as follows. In
Section 2, the relevant basic theories are briefly introduced.
Section 3 details the specific improvement measures of the proposed method.
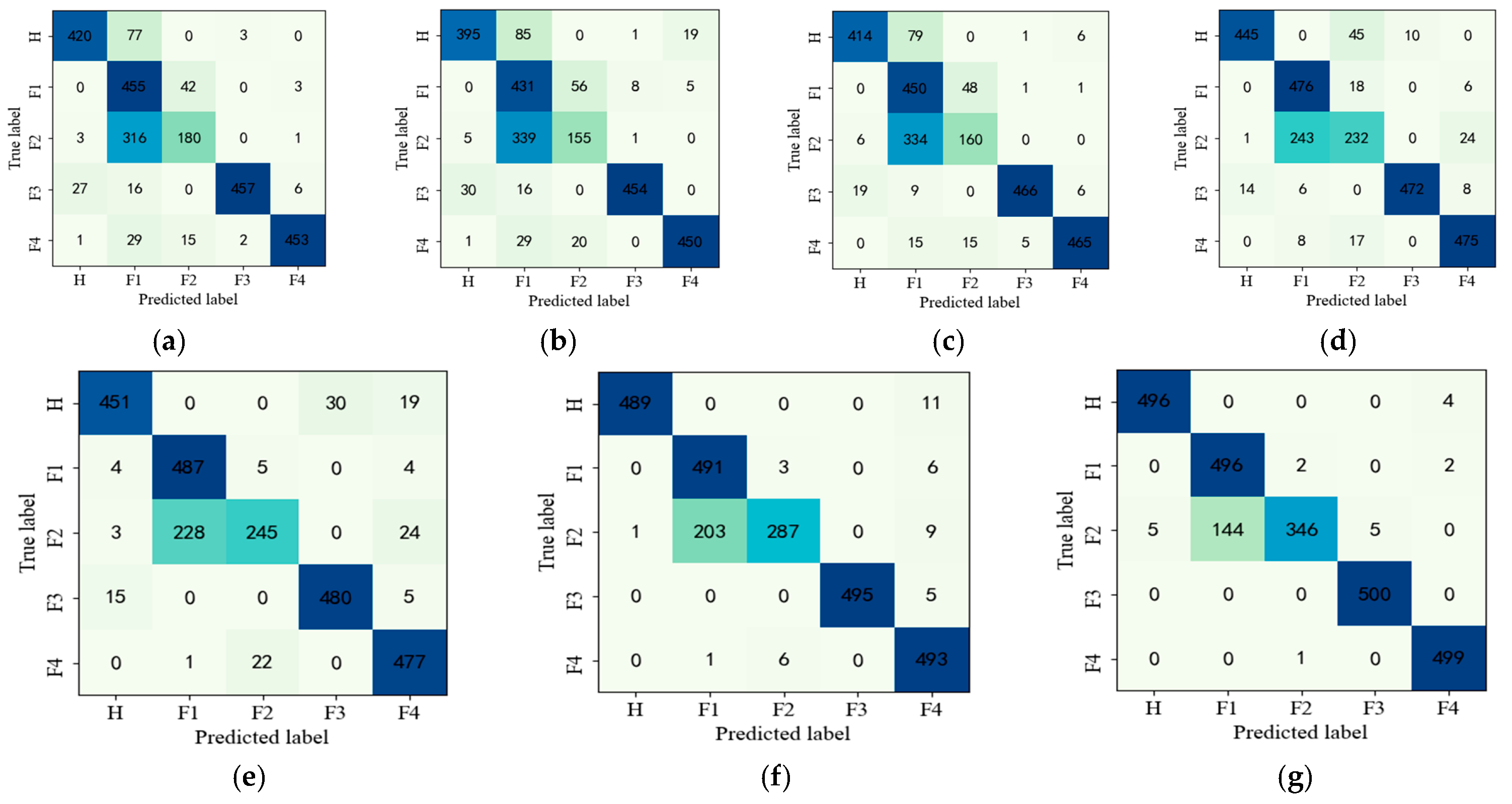
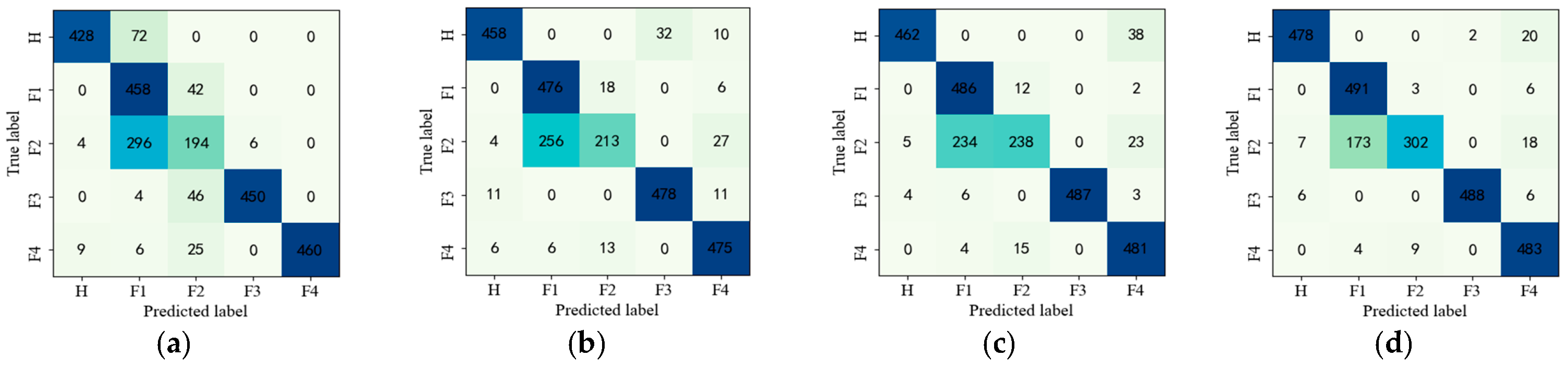
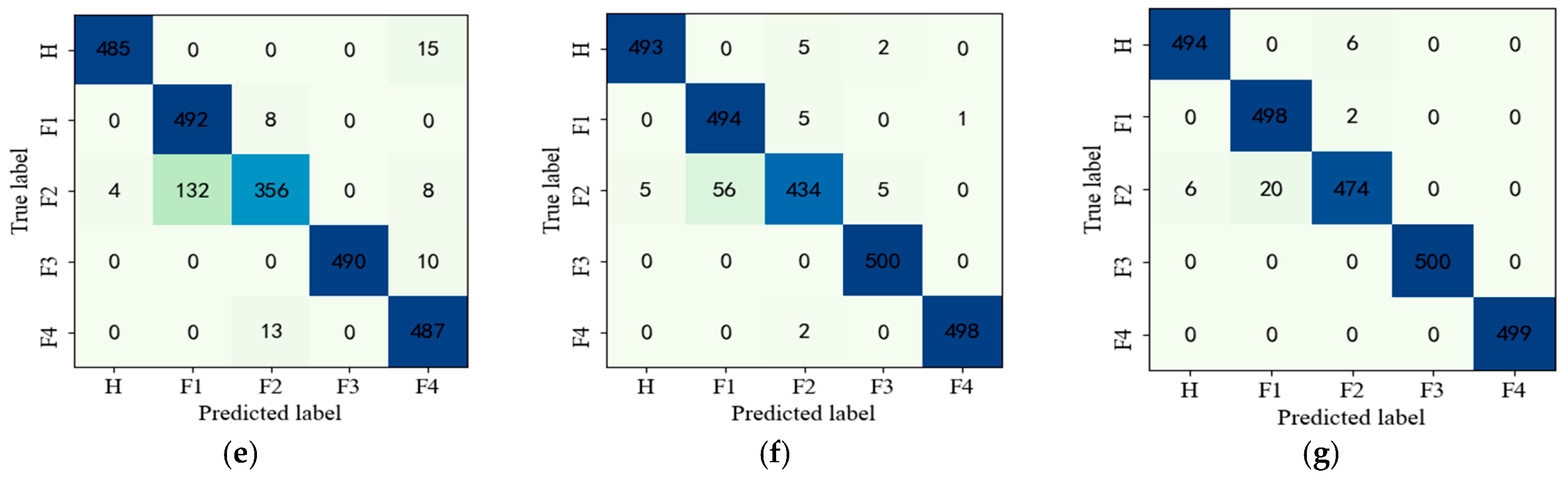
Section 4 validates the effectiveness and superiority of the proposed method on gearbox and bearing datasets and compared with other mainstream diagnostic techniques. Finally, the conclusions are summarized in
Section 5.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}