Abstract
Memory-limited partially observable stochastic control (ML-POSC) is the stochastic optimal control problem under incomplete information and memory limitation. To obtain the optimal control function of ML-POSC, a system of the forward Fokker–Planck (FP) equation and the backward Hamilton–Jacobi–Bellman (HJB) equation needs to be solved. In this work, we first show that the system of HJB-FP equations can be interpreted via Pontryagin’s minimum principle on the probability density function space. Based on this interpretation, we then propose the forward-backward sweep method (FBSM) for ML-POSC. FBSM is one of the most basic algorithms for Pontryagin’s minimum principle, which alternately computes the forward FP equation and the backward HJB equation in ML-POSC. Although the convergence of FBSM is generally not guaranteed in deterministic control and mean-field stochastic control, it is guaranteed in ML-POSC because the coupling of the HJB-FP equations is limited to the optimal control function in ML-POSC.
1. Introduction
In many practical applications of the stochastic optimal control theory, several constraints need to be considered. In the cases of small devices [1,2] and biological systems [3,4,5,6,7,8], for example, incomplete information and memory limitation become predominant because their sensors are extremely noisy and their memory resources are severely limited. To take into account one of these constraints, incomplete information, partially observable stochastic control (POSC) has been extensively studied in the stochastic optimal control theory [9,10,11,12,13]. However, because POSC cannot take into account the other constraint, memory limitation, it is not practical enough for designing memory-limited controllers for small devices and biological systems. To resolve this problem, memory-limited POSC (ML-POSC) has recently been proposed [14]. Because ML-POSC formulates noisy observation and limited memory explicitly, ML-POSC can take into account both incomplete information and memory limitation in the stochastic optimal control problem.
However, ML-POSC cannot be solved in a similar way as completely observable stochastic control (COSC), which is the most basic stochastic optimal control problem [15,16,17,18]. In COSC, the optimal control function depends only on the Hamilton–Jacobi–Bellman (HJB) equation, which is a time-backward partial differential equation given a terminal condition (Figure 1a) [15,16,17,18]. Therefore, the optimal control function of COSC can be obtained by solving the HJB equation backward in time from the terminal condition, which is called the value iteration method [19,20,21]. In contrast, the optimal control function of ML-POSC depends not only on the HJB equation but also on the Fokker–Planck (FP) equation, which is a time-forward partial differential equation given an initial condition (Figure 1b) [14]. Because the HJB equation and the FP equation interact with each other through the optimal control function in ML-POSC, the optimal control function of ML-POSC cannot be obtained by the value iteration method.

Figure 1.
Schematic diagram of the relationship between the backward dynamics, the optimal control function, and the forward dynamics in (a) COSC, (b) ML-POSC, (c) deterministic control, and (d) MFSC. , , , and are the solutions of the HJB equation, the FP equation, the adjoint equation, and the state equation, respectively. is the optimal control function. The arrows indicate the dependence of variables. The variable at the head of an arrow depends on the variable at the tail of the arrow. (a) In COSC, because the optimal control function depends only on the HJB equation , it can be obtained by solving the HJB equation backward in time from the terminal condition, which is called the value iteration method. (b) In ML-POSC, because the optimal control function depends on the FP equation as well as the HJB equation (orange), it cannot be obtained by the value iteration method. In this paper, we propose FBSM for ML-POSC, which computes the HJB equation and the FP equation alternately. Because the coupling of the HJB equation and the FP equation is limited only to the optimal control function , the convergence of FBSM is guaranteed in ML-POSC. (c) In deterministic control, because the coupling of the adjoint equation and the state equation is not limited to the optimal control function (green), the convergence of FBSM is not guaranteed. (d) In MFSC, because the coupling of the HJB equation and the FP equation is not limited to the optimal control function (green), the convergence of FBSM is not guaranteed.
To propose an algorithm to solve ML-POSC, we first show that the system of HJB-FP equations can be interpreted via Pontryagin’s minimum principle on the probability density function space. Pontryagin’s minimum principle is one of the most representative approaches to the deterministic optimal control problem, which converts it into the two-point boundary value problem of the forward state equation and the backward adjoint equation [22,23,24,25]. We formally show that the system of HJB-FP equations is an extension of the system of adjoint and state equations from the deterministic optimal control problem to the stochastic optimal control problem.
The system of HJB-FP equations also appears in the mean-field stochastic control (MFSC) [26,27,28]. Although the relationship between the system of HJB-FP equations and Pontryagin’s minimum principle has been briefly mentioned in MFSC [29,30,31], its details have not yet been investigated. In this work, we investigate it in more detail by deriving the system of HJB-FP equations in a similar way to Pontryagin’s minimum principle. We note that our derivations are formal, not analytical, and more mathematically rigorous proofs remain future challenges. However, our results are consistent with many conventional results and also provide a useful perspective in proposing an algorithm.
We then propose the forward-backward sweep method (FBSM) for ML-POSC. FBSM is an algorithm to compute the forward FP equation and the backward HJB equation alternately, which can be interpreted as an extension of the value iteration method. FBSM has been proposed in Pontryagin’s minimum principle of the deterministic optimal control problem, which computes the forward state equation and the backward adjoint equation alternately [32,33,34]. Because FBSM is easy to implement, it has been used in many applications [35,36]. However, the convergence of FBSM is not guaranteed in deterministic control except for special cases [37,38] because the coupling of adjoint and state equations is not limited to the optimal control function (Figure 1c). In contrast, we show that the convergence of FBSM is generally guaranteed in ML-POSC because the coupling of the HJB-FP equations is limited only to the optimal control function (Figure 1b).
FBSM is called the fixed-point iteration method in MFSC [39,40,41,42]. Although the fixed-point iteration method is the most basic algorithm to solve MFSC, its convergence is not guaranteed for the same reason as deterministic control (Figure 1d). Therefore, ML-POSC is a special and nice class of optimal control problems where FBSM or the fixed-point iteration method is guaranteed to converge.
This paper is organized as follows: In Section 2, we formulate ML-POSC. In Section 3, we derive the system of HJB-FP equations of ML-POSC from the viewpoint of Pontryagin’s minimum principle. In Section 4, we propose FBSM for ML-POSC and prove its convergence. In Section 5, we apply FBSM to the linear-quadratic-Gaussian (LQG) problem. In Section 6, we verify the convergence of FBSM by numerical experiments. In Section 7, we discuss our work. In Appendix A, we briefly review Pontryagin’s minimum principle of deterministic control. In Appendix B, we derive the system of HJB-FP equations of MFSC from the viewpoint of Pontryagin’s minimum principle. In Appendix C, we show the detailed derivations of our results.
2. Memory-Limited Partially Observable Stochastic Control
In this section, we briefly review the formulation of ML-POSC [14], which is the stochastic optimal control problem under incomplete information and memory limitation.
2.1. Problem Formulation
This subsection outlines the formulation of ML-POSC [14]. The state of the system at time evolves by the following stochastic differential equation (SDE):
where obeys , is the control, and is the standard Wiener process. In COSC [15,16,17,18], because the controller can completely observe the state , it determines the control based on the state as . By contrast, in POSC [9,10,11,12,13] and ML-POSC [14], the controller cannot directly observe the state and instead obtains the observation , which evolves by the following SDE:
where obeys , and is the standard Wiener process. In POSC [9,10,11,12,13], because the controller can completely memorize the observation history , it determines the control based on the observation history as . In ML-POSC [14], by contrast, because the controller cannot completely memorize the observation history , it compresses the observation history into the finite-dimensional memory , which evolves by the following SDE:
where obeys , is the control, and is the standard Wiener process. The memory dimension is determined by the available memory size of the controller. In addition, the memory noise represents the intrinsic stochasticity of the memory to be used. Therefore, unlike the conventional POSC, ML-POSC can explicitly take into account the memory size and noise of the controller. Furthermore, because the memory dynamics (3) depends on the memory control , it can be optimized through the memory control , which is expected to realize the optimal compression of the observation history into the limited memory . In ML-POSC [14], the controller determines the state control and the memory control based on the memory as follows:
The objective function of ML-POSC is given by the following expected cumulative cost function:
where f is the cost function, g is the terminal cost function, is the probability of , , and given u and v as parameters, and is the expectation with respect to the probability p. Because the cost function f depends on the memory control , ML-POSC can explicitly take into account the memory control cost, which is also impossible with the conventional POSC.
ML-POSC is the problem of finding the optimal state control function and the optimal memory control function that minimize the expected cumulative cost function as follows:
ML-POSC first formulates the finite-dimensional and stochastic memory dynamics explicitly, then optimizes the memory control by considering the memory control cost. As a result, unlike the conventional POSC, ML-POSC is a practical framework for memory-limited controllers where the memory size, noise, and cost are imposed and non-negligible.
The previous work [14] has shown the validity and effectiveness of ML-POSC. In the LQG problem of conventional POSC, the observation history can be compressed into the Kalman filter without a loss of performance [10,18,43]. Because the Kalman filter is finite-dimensional, it can be interpreted as the finite-dimensional memory and discussed in terms of ML-POSC. The previous work [14] has proven that the optimal memory dynamics of ML-POSC become the Kalman filter in this problem, which indicates that ML-POSC is a consistent framework with the conventional POSC. Furthermore, the previous work [14] has demonstrated the effectiveness of ML-POSC in the LQG problem with memory limitation and in the non-LQG problem by numerical experiments.
2.2. Problem Reformulation
Although the formulation of ML-POSC in the previous subsection is intuitive, it is inconvenient for further mathematical investigations. To address this problem, we reformulate ML-POSC in this subsection. The formulation in this subsection is simpler and more general than that in the previous subsection.
First, we define an extended state as follows:
where . The extended state evolves by the following SDE:
where obeys , is the control, and is the standard Wiener process. ML-POSC determines the control based on the memory as follows:
The extended state SDE (8) includes the previous SDEs (1)–(3) as a special case because they can be represented as follows:
where .
The objective function of ML-POSC is given by the following expected cumulative cost function:
where is the cost function and is the terminal cost function. It is obvious that this objective function (11) is more general than that in the previous subsection (5).
ML-POSC is the problem of finding the optimal control function that minimizes the expected cumulative cost function as follows:
In the following sections, we mainly consider the formulation of this subsection because it is simpler and more general than that in the previous subsection. Moreover, we omit for simplicity of notation.
3. Pontryagin’s Minimum Principle
If the control is determined based on the extended state as , ML-POSC is the same problem with COSC of the extended state, and its optimality conditions can be obtained in the conventional way [15,16,17,18]. In reality, however, because ML-POSC determines the control based only on the memory as , its optimality conditions cannot be obtained in a similar way as COSC. In the previous work [14], the optimality conditions of ML-POSC were obtained by employing a mathematical technique of MFSC [30,31].
In this section, we obtain the optimality conditions of ML-POSC by employing Pontryagin’s minimum principle [22,23,24,25] on the probability density function space (Figure 2 (bottom right)). The conventional approach in ML-POSC [14] and MFSC [30,31] can be interpreted as a conversion from Bellman’s dynamic programming principle (Figure 2 (top right)) to Pontryagin’s minimum principle (Figure 2 (bottom right)) on the probability density function space.
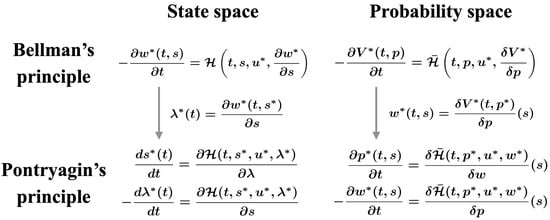
Figure 2.
The relationship between Bellman’s dynamic programming principle (top) and Pontryagin’s minimum principle (bottom) on the state space (left) and on the probability density function space (right). The left-hand side corresponds to deterministic control, which is briefly reviewed in Appendix A. The right-hand side corresponds to ML-POSC and MFSC, which are shown in Section 3 and Appendix B, respectively. The conventional approach in ML-POSC [14] and MFSC [30,31] can be interpreted as the conversion from Bellman’s dynamic programming principle (top right) to Pontryagin’s minimum principle (bottom right) on the probability density function space.
In Appendix A, we briefly review Pontryagin’s minimum principle in deterministic control (Figure 2 (left)). In this section, we obtain the optimality conditions of ML-POSC in a similar way as Appendix A (Figure 2 (right)). Furthermore, in Appendix B, we obtain the optimality conditions of MFSC in a similar way as Appendix A (Figure 2 (right)). MFSC is more general than ML-POSC except for the partial observability. In particular, the expected Hamiltonian is non-linear with respect to the probability density function in MFSC, while it is linear in ML-POSC.
Although our derivations are formal, not analytical, and more mathematically rigorous proofs remain future challenges, our results are consistent with the conventional results of COSC [15,16,17,18], ML-POSC [14], and MFSC [26,27,28,30,31], and also provide a useful perspective in proposing an algorithm.
3.1. Preliminary
In this subsection, we show a useful result in obtaining Pontryagin’s minimum principle. Given arbitrary control functions u and , can be calculated as follows:
where is the Hamiltonian, which is defined as follows:
is the backward diffusion operator, which is defined as follows:
where . is the solution of the following Hamilton–Jacobi–Bellman (HJB) equation driven by :
where . is the solution of the following Fokker–Planck (FP) equation driven by u:
where . is the forward diffusion operator, which is defined as follows:
is the conjugate of as follows:
We derive Equation (13) in Appendix C.1.
3.2. Necessary Condition
In this subsection, we show the necessary condition of the optimal control function of ML-POSC. It corresponds to Pontryagin’s minimum principle on the probability density function space (Figure 2 (bottom right)). If is the optimal control function of ML-POSC (12), then the following equation is satisfied:
where is the solution of the following HJB equation driven by :
where . is the conditional probability density function of state x given memory z, and is the solution of the following FP equation driven by :
where . We derive this result in Appendix C.2.
In deterministic control, Pontryagin’s minimum principle can be expressed by the derivatives of the Hamiltonian (Figure 2 (bottom left)). Similarly, the system of HJB-FP Equations (21) and (22) can be expressed by the variations of the expected Hamiltonian
as follows:
where and (Figure 2 (bottom right)). Therefore, the system of HJB-FP equations can be interpreted via Pontryagin’s minimum principle on the probability density function space.
3.3. Sufficient Condition
Pontryagin’s minimum principle (20) is only a necessary condition and generally not a sufficient condition. Pontryagin’s minimum principle (20) becomes a necessary and sufficient condition if the expected Hamiltonian is convex with respect to p and u. We obtain this result in Appendix C.3.
3.4. Relationship with Bellman’s Dynamic Programming Principle
From Bellman’s dynamic programming principle on the probability density function space (Figure 2 (top right)) [14], the optimal control function of ML-POSC is given by the following equation:
where is the value function on the probability density function space, which is the solution of the following Bellman equation:
where . More specifically, the optimal control function of ML-POSC is given by , where is the solution of the FP Equation (22).
Because the Bellman Equation (27) is a functional differential equation, it cannot be solved even numerically. To resolve this problem, the previous work [14] converted the Bellman Equation (27) into the HJB Equation (21) by defining
where is the solution of FP Equation (22). This approach can be interpreted as the conversion from Bellman’s dynamic programming principle (Figure 2 (top right)) to Pontryagin’s minimum principle (Figure 2 (bottom right)) on the probability density function space.
3.5. Relationship with Completely Observable Stochastic Control
In the COSC of the extended state, the control is determined based on the extended state as . Therefore, in the COSC of the extended state, Pontryagin’s minimum principle on the probability density function space is given by the following equation:
where is the solution of the HJB Equation (21). Because this proof is almost identical to that of Section 3.2, it is omitted in this paper.
While the optimal control function of ML-POSC (20) depends on the FP equation and the HJB equation, the optimal control function of COSC (29) depends only on the HJB equation. From this nice property of COSC, Equation (29) is not only a necessary condition but also a sufficient condition without assuming the convexity of the expected Hamiltonian. We derive this result in Appendix C.4.
This result is consistent with the conventional result of COSC [15,16,17,18]. Unlike ML-POSC and MFSC, COSC can be solved by Bellman’s dynamic programming principle on the state space. In COSC, Pontryagin’s minimum principle on the probability density function space is equivalent to Bellman’s dynamic programming principle on the state space. Because Bellman’s dynamic programming principle on the state space is a necessary and sufficient condition, Pontryagin’s minimum principle on the probability density function space may also become a necessary and sufficient condition.
4. Forward-Backward Sweep Method
In this section, we propose FBSM for ML-POSC and then prove its convergence by employing the interpretation of the system of HJB-FP equations by Pontryagin’s minimum principle introduced in the previous section.
4.1. Forward-Backward Sweep Method
In this subsection, we propose FBSM for ML-POSC, which is summarized in Algorithm 1. FBSM is an algorithm to compute the forward FP equation and the backward HJB equation alternately. More specifically, in the initial step of FBSM, we initialize the control function and obtain by computing the FP equation forward in time from the initial condition. In the backward step, we obtain by computing the HJB equation backward in time from the terminal condition and simultaneously update the control function from to by minimizing the conditional expected Hamiltonian. In the forward step, we obtain by computing the FP equation forward in time from the initial condition and simultaneously update the control function from to by minimizing the conditional expected Hamiltonian. By iterating the backward and forward steps, the objective function of ML-POSC monotonically decreases and finally converges to the local minimum at which the control function of ML-POSC satisfies Pontryagin’s minimum principle.
Pontryagin’s minimum principle is only a necessary condition of the optimal control function, not a sufficient condition. Therefore, the control function obtained by FBSM is not necessarily the global optimum except in the case where the expected Hamiltonian is convex. Nevertheless, the control function obtained by FBSM is expected to be superior to most control functions because it is locally optimal.
FBSM has been used in deterministic control [32,34,35,38] and MFSC [39,40,41,42]. However, the convergence of FBSM for these problems is not guaranteed because the backward dynamics depend on the forward dynamics even without the optimal control function (Figure 1c,d). In contrast, the convergence of FBSM is guaranteed in ML-POSC because the backward HJB equation does not depend on the forward FP equation without the optimal control function (Figure 1b). More specifically, in FBSM for ML-POSC, the objective function monotonically decreases and finally converges to Pontryagin’s minimum principle. In the following subsections, we prove this nice property of FBSM for ML-POSC.
| Algorithm 1: Forward-Backward Sweep Method (FBSM) |
|
4.2. Preliminary
In this subsection, we show an important result in proving the convergence of FBSM for ML-POSC. We suppose that is given and only is optimized as follows:
In ML-POSC, can be calculated as follows:
where is the solution of the following time-discretized HJB equation driven by :
where . is the conditional probability density function of state x given memory z, and is the solution of the following time-discretized FP equation driven by :
where . Equation (31) is obtained by the similar way to Pontyragin’s minimum principle in Appendix C.5 and also by the time discretization method in Appendix C.6.
Importantly, does not depend on in ML-POSC (Figure 3a) while and depend on in deterministic control (Figure 3b) and MFSC (Figure 3c), respectively. Therefore, can be obtained without modifying in ML-POSC, which is essentially different from deterministic control and MFSC. From this nice property, the convergence of FBSM is guaranteed in ML-POSC.
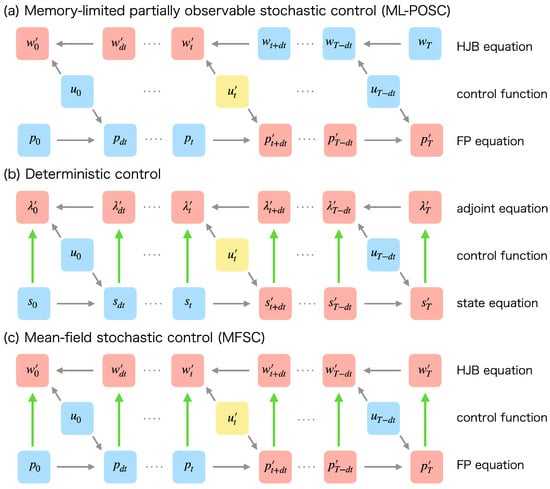
Figure 3.
Schematic diagram of the effect of updating the control function to the forward and backward dynamics in (a) ML-POSC, (b) deterministic control, and (c) MFSC. , , , and are the solutions of the HJB equation, the FP equation, the adjoint equation, and the state equation, respectively. is a given control function. The arrows indicate the dependence of variables. The variable at the head of an arrow depends on the variable at the tail of the arrow. (a) In ML-POSC, while the update from to (yellow) changes and to and , respectively (red), it does not change and (blue). From this property, the convergence of FBSM is guaranteed in ML-POSC. (b) In deterministic control, the update from to (yellow) changes to as well (red) because the adjoint equation depends on the state equation (green). Because FBSM does not take into account the change of , the convergence of FBSM is not guaranteed in deterministic control. (c) In MFSC, the update from to (yellow) changes to as well (red) because the HJB equation depends on the FP equation (green). Because FBSM does not take into account the change of , the convergence of FBSM is not guaranteed in MFSC.
4.3. Monotonicity
In FBSM for ML-POSC, the objective function is monotonically non-increasing with respect to the update of the control function at each time step. More specifically,
is satisfied in the backward step, and
is satisfied in the forward step. We prove this result in Appendix C.7. Furthermore, in FBSM for ML-POSC, the objective function is monotonically non-increasing with respect to the update of the control function at each iteration step as follows:
Equation (36) is obviously satisfied from Equations (34) and (35).
4.4. Convergence to Pontryagin’s Minimum Principle
We assume that has a lower bound. From Equation (36), FBSM for ML-POSC is guaranteed to converge to the local minimum. Furthermore, we assume that if the candidate of includes , then set at . Under these assumptions, FBSM for ML-POSC converges to Pontryagin’s minimum principle (20). More specifically, if holds, satisfies Pontryagin’s minimum principle (20). We prove this result in Appendix C.8.
Therefore, unlike deterministic control and MFSC, in FBSM for ML-POSC, the objective function monotonically decreases and finally converges to the local minimum at which the control function satisfies Pontryagin’s minimum principle (20).
5. Linear-Quadratic-Gaussian Problem
In this section, we apply FBSM to the LQG problem of ML-POSC [14]. In the LQG problem of ML-POSC, the system of HJB-FP equations is reduced from partial differential equations to ordinary differential equations.
5.1. Problem Formulation
In the LQG problem of ML-POSC, the extended state SDE (8) is given as follows [14]:
where obeys the Gaussian distribution where is the mean vector and is the precision matrix. The objective function (11) is given as follows:
where , , and . The LQG problem of ML-POSC is the problem of finding the optimal control function that minimizes the objective function as follows:
5.2. Pontryagin’s Minimum Principle
In the LQG problem of ML-POSC, Pontryagin’s minimum principle (20) can be calculated as follows [14]:
where is defined as follows:
where and are the mean vector and the precision matrix of the extended state, respectively, which correspond to the solution of the FP Equation (22). We note that is satisfied. and are the solutions of the following ordinary differential equations (ODEs):
where and . and are the control gain matrices of the deterministic and stochastic extended state, respectively, which correspond to the solution of the HJB Equation (21). and are the solutions of the following ODEs:
where . The ODE of (44) is the Riccati equation [16,17,18], which also appears in the LQG problem of COSC. In contrast, the ODE of (45) is the partially observable Riccati equation [14], which appears only in the LQG problem of ML-POSC. The above result is obtained in [14].
The ODE of (44) can be solved backward in time from the terminal condition. Using , the ODE of (42) can be solved forward in time from the initial condition. In contrast, the ODEs of (45) and (43) cannot be solved in a similar way as the ODEs of (44) and (42) because they interact with each other, which is a similar problem to the system of HJB-FP equations.
5.3. Forward-Backward Sweep Method
In the LQG problem of ML-POSC, FBSM is reduced from Algorithm 1 to Algorithm 2. and are defined by the right-hand sides of the ODEs of (43) and (45), respectively, as follows:
This result is obtained in Appendix C.9. Importantly, in the LQG problem of ML-POSC, FBSM computes the ODEs of (43) and (45) instead of the FP Equation (22) and the HJB Equation (21).
| Algorithm 2: Forward-Backward Sweep Method (FBSM) in the LQG problem |
|
6. Numerical Experiments
In this section, we verify the convergence of FBSM in ML-POSC by performing numerical experiments on the LQG and non-LQG problems. The setting of the numerical experiments is the same as the previous work [14].
6.1. LQG Problem
In this subsection, we verify the convergence of FBSM for ML-POSC by conducting a numerical experiment on the LQG problem. We consider state , observation , and memory , which evolve by the following SDEs:
where and obey the standard Gaussian distributions, is an arbitrary real number, and are independent standard Wiener processes, and and are the controls. The objective function to be minimized is given as follows:
Therefore, the objective of this problem is to minimize the state variance with small state and memory controls.
This problem corresponds to the LQG problem, which is defined by (37) and (38). By defining , , and , the SDEs (46)–(48) can be rewritten as follows:
which corresponds to (37). Furthermore, the objective function (49) can be rewritten as follows:
which corresponds to (38).
We apply the FBSM of the LQG problem (Algorithm 2) to this problem. is initialized by . To solve the ODEs of and , we use the fourth-order Runge–Kutta method. Figure 4 shows the control gain matrix and the precision matrix obtained by FBSM. The color of each curve represents the iteration k. The darkest curve corresponds to the first iteration , and the brightest curve corresponds to the last iteration . Importantly, and converge with respect to the iteration k.
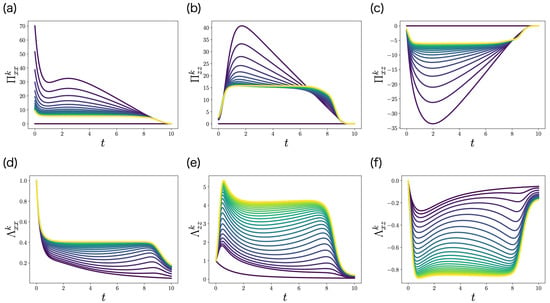
Figure 4.
The elements of the control gain matrix (a–c) and the precision matrix (d–f) obtained by FBSM (Algorithm 2) in the numerical experiment of the LQG problem of ML-POSC. Because and , and are not visualized. The darkest curve corresponds to the first iteration , and the brightest curve corresponds to the last iteration . is initialized by .
Figure 5a shows the objective function with respect to iteration k. The objective function monotonically decreases with respect to iteration k, which is consistent with Section 4.3. This monotonicity of FBSM is the nice property of ML-POSC that is not guaranteed in deterministic control and MFSC. The objective function finally converges, and satisfies Pontryagin’s minimum principle from Section 4.4.
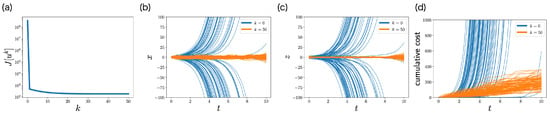
Figure 5.
Performance of FBSM in the numerical experiment of the LQG problem of ML-POSC. (a) The objective function with respect to the iteration k. (b–d) Stochastic simulation of state (b), memory (c), and the cumulative cost (d) for 100 samples. The expectation of the cumulative cost at corresponds to the objective function (49). Blue and orange curves correspond to the first iteration and the last iteration , respectively.
Figure 5b–d compare the performance of the control function at the first iteration and the last iteration by performing a stochastic simulation. At the first iteration , the distributions of state and memory are unstable, and the cumulative cost diverges. In contrast, at the last iteration , the distributions of state and memory are stabilized and the cumulative cost is smaller. This result indicates that FBSM improves the performance in ML-POSC.
Although Figure 5b–d look similar to Figure 2d–f in the previous work [14], they are comparing different things. While Figure 5b–d demonstrate the performance improvement by the FBSM iteration, the previous work [14] compares the performance of the partially observable Riccati Equation (45) with that of the conventional Riccati Equation (44).
6.2. Non-LQG Problem
In this subsection, we verify the convergence of FBSM in ML-POSC by conducting a numerical experiment on the non-LQG problem. We consider state , observation , and memory , which evolve by the following SDEs:
where and obey the Gaussian distributions and , respectively. is an arbitrary real number, and are independent standard Wiener processes, and is the control. For the sake of simplicity, memory control is not considered. The objective function to be minimized is given as follows:
where
The cost function is high in and , which represents the obstacles. In addition, the terminal cost function is the lowest at , which represents the desirable goal. Therefore, the system should avoid the obstacles and reach the goal with a small control. Because the cost function is non-quadratic, it is a non-LQG problem.
We apply the FBSM (Algorithm 1) to this problem. is initialized by . To solve the HJB equation and the FP equation, we use the finite-difference method. Figure 6 shows and obtained by FBSM at the first iteration and at the last iteration . From Appendix C.6, is given as follows:
Because , reflects the cost function corresponding to the obstacles and the goal (Figure 6a–e). In contrast, because , becomes more complex (Figure 6f–j). In particular, while does not depend on memory z, depends on memory z, which indicates that the control function is adjusted by the memory z. We note that (Figure 6e) and (Figure 6j) are the same because they are given by the terminal cost function as . Furthermore, while is a unimodal distribution (Figure 6k–o), is a bimodal distribution (Figure 6p–t), which can avoid the obstacles.
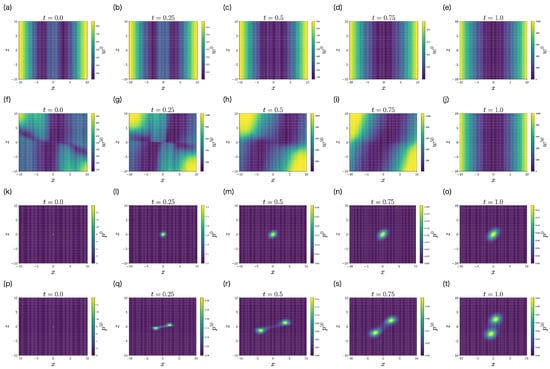
Figure 6.
The solutions of the HJB equation (a–j) and the FP equation (k–t) at the first iteration (a–e,k–o) and at the last iteration (f–j,p–t) of FBSM (Algorithm 1) in the numerical experiment of the non-LQG problem of ML-POSC. is initialized by .
Figure 7a shows the objective function with respect to iteration k. The objective function monotonically decreases with respect to iteration k, which is consistent with Section 4.3. This monotonicity of FBSM is the nice property of ML-POSC that is not guaranteed in deterministic control and MFSC. The objective function finally converges, and its satisfies Pontryagin’s minimum principle from Section 4.4.
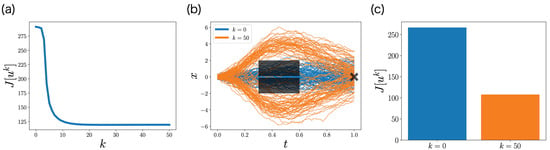
Figure 7.
Performance of FBSM in the numerical experiment of the non-LQG problem of ML-POSC. (a) The objective function with respect to the iteration k. (b) Stochastic simulation of the state for 100 samples. The black rectangles and the cross represent the obstacles and the goal, respectively. Blue and orange curves correspond to the first iteration and the last iteration , respectively. (c) The objective function (55), which is computed from 100 samples.
Figure 7b,c compare the performance of the control function at the first iteration and the last iteration by conducting the stochastic simulation. At the first iteration , the obstacles cannot be avoided, which results in a higher objective function. In contrast, at the last iteration , the obstacles can be avoided, which results in a lower objective function. This result indicates that FBSM improves the performance in ML-POSC.
Although Figure 7b,c look similar to Figure 3a,b in the previous work [14], they are comparing different things. While Figure 7b,c demonstrate the performance improvement by the FBSM iteration, the previous work [14] compares the performance of ML-POSC with the local LQG approximation of the conventional POSC.
7. Discussion
In this work, we first showed that the system of HJB-FP equations corresponds to Pontryagin’s minimum principle on the probability density function space. Although the relationship between the system of HJB-FP equations and Pontryagin’s minimum principle has been briefly mentioned in MFSC [29,30,31], its details have not yet been investigated. We addressed this problem by deriving the system of HJB-FP equations in a similar way to Pontryagin’s minimum principle. We then proposed FBSM to ML-POSC. Although the convergence of FBSM is generally not guaranteed in deterministic control [32,34,35,38] and MFSC [39,40,41,42], we proved the convergence in ML-POSC by noting the fact that the update of the current control function does not affect the future HJB equation in ML-POSC. Therefore, ML-POSC is a special and nice class where FBSM is guaranteed to converge.
Our derivation of Pontryagin’s minimum principle on the probability density function space is formal, not analytical. Therefore, more mathematically rigorous proofs should be pursued in future work. Nevertheless, because our results are consistent with the conventional results of COSC [15,16,17,18], ML-POSC [14], and MFSC [26,27,28,30,31], they would be reliable except for special cases. Furthermore, our results provide a unified perspective on FBSM in deterministic control [32,34,35,38] and the fixed-point iteration method in MFSC [39,40,41,42], which have been studied independently. It clarifies the different properties of ML-POSC from deterministic control and MFSC, which ensures the convergence of FBSM.
The regularized FBSM has recently been proposed in deterministic control, which is guaranteed to converge even in the general deterministic control [44,45]. Our work gives an intuitive reason why the regularized FBSM is guaranteed to converge. In the regularized FBSM, the Hamiltonian is regularized, which makes the update of the control function smaller. When the regularization is sufficiently strong, the effect of the current control function on the future backward dynamics would be negligible. Therefore, the regularized FBSM of deterministic control would be guaranteed to converge for a similar reason to the FBSM of ML-POSC. However, the convergence of the regularized FBSM is much slower because the stronger regularization makes the update of the control function smaller. The FBSM of ML-POSC does not suffer from such a problem because the future backward dynamics already do not depend on the current control function without regularization.
Our work gives a hint about a modification of the fixed-point iteration method to ensure convergence in MFSC. Although the fixed-point iteration method is the most basic algorithm in MFSC, its convergence is not guaranteed [39,40,41,42]. Our work showed that the fixed-point iteration method is equivalent to the FBSM on the probability density function space. Therefore, the idea of regularized FBSM may also be applied to the fixed-point iteration method. More specifically, the fixed-point iteration method may be guaranteed to converge by regularizing the expected Hamiltonian.
In FBSM, we solve the HJB equation and the FP equation using the finite-difference method. However, because the finite-difference method is prone to the curse of dimensionality, it is difficult to solve high-dimensional ML-POSC. To resolve this problem, two directions can be considered. One direction is the policy iteration method [21,46,47]. Although the policy iteration method is almost the same as FBSM, only the update of the control function is different. While FBSM updates the system of HJB-FP equations and the control function simultaneously, the policy iteration method updates them separately. In the policy iteration method, the system of HJB-FP equations becomes linear, which can be solved by the sampling method [48,49,50]. Because the sampling method is more tractable than the finite-difference method, the policy iteration method may allow high-dimensional ML-POSC to be solved. Furthermore, the policy iteration method has recently been studied in MFSC [51,52,53]. However, its convergence is not guaranteed except for special cases in MFSC. In a similar way to FBSM, the convergence of the policy iteration method may be guaranteed in ML-POSC.
The other direction is machine learning. Neural network-based algorithms have recently been proposed in MFSC, which can solve high-dimensional problems efficiently [54,55]. By extending these algorithms, high-dimensional ML-POSC may be solved efficiently. Furthermore, unlike MFSC, the coupling of the HJB-FP equations is limited only to the optimal control function in ML-POSC. By exploiting this nice property, more efficient algorithms may be devised for ML-POSC.
Author Contributions
Conceptualization, Formal analysis, Funding acquisition, Writing—original draft, T.T. and T.J.K.; Software, Visualization, T.T. All authors have read and agreed to the published version of the manuscript.
Funding
The first author received a JSPS Research Fellowship (Grant No. 21J20436). This work was supported by JSPS KAKENHI (Grant No. 19H05799) and JST CREST (Grant No. JPMJCR2011).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| COSC | Completely Observable Stochastic Control |
| POSC | Partially Observable Stochastic Control |
| ML-POSC | Memory-Limited Partially Observable Stochastic Control |
| MFSC | Mean-Field Stochastic Control |
| FBSM | Forward-Backward Sweep Method |
| HJB | Hamilton-Jacobi-Bellman |
| FP | Fokker-Planck |
| SDE | Stochastic Differential Equation |
| ODE | Ordinary Differential Equation |
| LQG | Linear-Quadratic-Gaussian |
Appendix A. Deterministic Control
In this section, we briefly review Pontryagin’s minimum principle in deterministic control [22,23,24,25].
Appendix A.1. Problem Formulation
In this subsection, we formulate deterministic control [22,23,24,25]. The state of the system at time evolves according to the following ordinary differential equation (ODE):
where the initial state is , and the control is . The objective function is given by the following cumulative cost function:
where f is the cost function and g is the terminal cost function. Deterministic control is the problem of finding the optimal control function that minimizes the cumulative cost function as follows:
Appendix A.2. Preliminary
In this subsection, we show a useful result in deriving Pontryagin’s minimum principle. Given arbitrary control functions u and , can be calculated as follows [16]:
where is the Hamiltonian, which is defined as follows:
is the solution of the following adjoint equation driven by :
where . and are the solutions of the state Equation (A1) driven by u and , respectively.
Appendix A.3. Necessary Condition
In this subsection, we show the necessary condition of the optimal control function of deterministic control. It corresponds to Pontryagin’s minimum principle on the state space (Figure 2 (bottom left)). If is the optimal control function of deterministic control (A3), then the following equation is satisfied [16]:
where is the solution of the following adjoint equation driven by :
where . is the solution of the following state equation driven by :
where . Because , Equation (A12) is consistent with Equation (A1).
In the following, we show that Equation (A10) is the necessary condition of the optimal control function of deterministic control. We define the control function:
where , and . From Equation (A4), can be calculated as follows:
Letting ,
Because is the optimal control function, the following inequality is satisfied:
Therefore, Equation (A10) is the necessary condition of the optimal control function of deterministic control.
Appendix A.4. Sufficient Condition
Pontryagin’s minimum principle (A10) is a necessary condition and generally not a sufficient condition. Pontryagin’s minimum principle (A10) becomes a necessary and sufficient condition if the Hamiltonian is convex with respect to s and u and the terminal cost function is convex with respect to s.
In the following, we show this result. We define the arbitrary control function . From Equation (A4), is given by the following equation:
Since is convex with respect to s and u and is convex with respect to s, the following inequalities are satisfied:
Hence, the following inequality is satisfied:
Because satisfies (A10), the following stationary condition is satisfied:
Hence, the following inequality is satisfied:
Therefore, Equation (A10) is the sufficient condition of the optimal control function of deterministic control if is convex with respect to s and u and is convex with respect to s.
Appendix A.5. Relationship with Bellman’s Dynamic Programming Principle
From Bellman’s dynamic programming principle on the state space (Figure 2 (top left)) [16], the optimal control function of deterministic control is given by the following equation:
where is the value function on the state space, which is the solution of the following Hamilton-Jacobi-Bellman (HJB) equation:
where . More specifically, the optimal control function of deterministic control is given by , where is the solution of the state Equation (A12).
The HJB Equation (A24) can be converted into the adjoint Equation (A11) by defining
where is the solution of the state Equation (A12). This approach can be interpreted as the conversion from Bellman’s dynamic programming principle (Figure 2 (top left)) to Pontryagin’s minimum principle (Figure 2 (bottom left)) on the state space.
In the following, we obtain this result. First, we define
By differentiating the HJB Equation (A24) with respect to s, the following equation is obtained:
where . Then the derivative of with respect to t can be calculated as follows:
By substituting Equation (A27) into Equation (A28), the following equation is obtained:
From the state Equation (A12), is satisfied. Therefore, satisfies the adjoint Equation (A11).
Appendix B. Mean-Field Stochastic Control
In this section, we show that the system of HJB-FP equations in MFSC corresponds to Pontryagin’s minimum principle on the probability density function space. Although the relationship between the system of HJB-FP equations and Pontryagin’s minimum principle has been mentioned briefly in MFSC [29,30,31], its details have not yet been investigated. In this section, we address this problem by deriving the system of HJB-FP equations in the similar way as Appendix A. Although our derivations are formal, not analytical, our results are consistent with the conventional results of MFSC [26,27,28,30,31].
Appendix B.1. Problem Formulation
In this subsection, we formulate MFSC [26,27,28]. The state of the system at time evolves by the following stochastic differential equation (SDE):
where obeys , is the probability density function of the state s, is the control, and is the standard Wiener process. The objective function is given by the following expected cumulative cost function:
where f is the cost function, g is the terminal cost function, is the probability of given u as a parameter, and is the expectation with respect to probability p. MFSC is the problem of finding the optimal control function that minimizes the expected cumulative cost function as follows:
Appendix B.2. Preliminary
In this subsection, we show a useful result in deriving Pontryagin’s minimum principle. Given arbitrary control functions u and , can be calculated as follows:
where and are the expected Hamiltonian and terminal cost function, respectively, which are defined as follows:
is the Hamiltonian, which is defined as follows:
is the backward diffusion operator, which is defined as follows:
where . is the solution of the following Hamilton-Jacobi-Bellman (HJB) equation driven by :
where . p is the solution of the following Fokker-Planck (FP) equation driven by u:
where . is the solution of the FP Equation (A39) driven by . is the forward diffusion operator, which is defined as follows:
is the conjugate of as follows:
Appendix B.3. Necessary Condition
In this subsection, we show the necessary condition of the optimal control function of MFSC. It corresponds to Pontryagin’s minimum principle on the probability density function space (Figure 2 (bottom right)). If is the optimal control function of MFSC (A32), then the following equation is satisfied:
where is the solution of the following HJB equation driven by :
where . is the solution of the following FP equation driven by :
where .
In the following, we show that Equation (A46) is the necessary condition of the optimal control function of MFSC. We define the control function
where , , and . From Equation (A33), can be calculated as follows:
Letting and ,
Because is the optimal control function, the following inequality is satisfied:
Therefore, Equation (A46) is the necessary condition of the optimal control function of MFSC.
Appendix B.4. Sufficient Condition
Pontryagin’s minimum principle (A46) is a necessary condition and generally not a sufficient condition. Pontryagin’s minimum principle (A46) becomes a necessary and sufficient condition if the expected Hamiltonian is convex with respect to p and u and the expected terminal cost function is convex with respect to p.
In the following, we show this result. We define the arbitrary control function . From Equation (A33), is given by the following equation:
Because is convex with respect to p and u and is convex with respect to p, the following inequalities are satisfied:
Hence, the following inequality is satisfied:
Because satisfies Equation (A46), the following stationary condition is satisfied:
Hence, the following inequality is satisfied:
Therefore, Equation (A46) is the sufficient condition of the optimal control function of MFSC if the expected Hamiltonian is convex with respect to p and u and the expected terminal cost function is convex with respect to p.
Appendix B.5. Relationship with Bellman’s Dynamic Programming Principle
From Bellman’s dynamic programming principle on the probability density function space (Figure 2 (top right)) [56,57,58], the optimal control function of MFSC is given by the following equation:
where is the value function on the probability density function space, which is the solution of the following Bellman equation:
where . More specifically, the optimal control function of MFSC is given by , where is the solution of the FP Equation (A48).
Because the Bellman Equation (A60) is a functional differential equation, it cannot be solved even numerically. To resolve this problem, the previous works [30,31] converted the Bellman Equation (A60) into the HJB Equation (A47) by defining
where is the solution of FP Equation (A48). This approach can be interpreted as the conversion from Bellman’s dynamic programming principle (Figure 2 (top right)) to Pontryagin’s minimum principle (Figure 2 (bottom right)) on the probability density function space.
Appendix C. Derivation of Main Results
Appendix C.1. Derivation of Result in Section 3.1
Appendix C.2. Derivation of Result in Section 3.2
In this subsection, we show that Equation (20) is the necessary condition of the optimal control function of ML-POSC. It corresponds to Pontryagin’s minimum principle on the probability density function space. We define the control function
where , , and . From Equation (13), can be calculated as follows:
Letting and ,
Because is the optimal control function, the following inequality is satisfied:
Therefore, Equation (20) is the necessary condition of the optimal control function of ML-POSC.
Appendix C.3. Derivation of Result in Section 3.3
In this subsection, we show that Equation (20) is the sufficient condition of the optimal control function of ML-POSC if the expected Hamiltonian is convex with respect to p and u. We define the arbitrary control function . From Equation (13), is given by the following equation:
Because is convex with respect to p and u, the following inequality is satisfied:
Because
the above inequality can be calculated as follows:
Hence, the following inequality is satisfied:
Because satisfies Equation (20), the following stationary condition is satisfied:
Hence, the following inequality is satisfied:
Therefore, Equation (20) is the sufficient condition of the optimal control function of ML-POSC if is convex with respect to p and u.
Appendix C.4. Derivation of Result in Section 3.5
In this subsection, we show that Equation (29) is the sufficient condition of the optimal control function of COSC without assuming the convexity of the expected Hamiltonian. We define the arbitrary control function . From Equation (13), is given by the following equation:
From (29), the following inequality is satisfied:
Therefore, Equation (29) is the sufficient condition of the optimal control function of COSC.
Appendix C.5. Derivation of Result in Section 4.2 by the Similar Way as Pontyragin’s Minimum Principle
Appendix C.6. Derivation of Result in Section 4.2 by the Time Discretized Method
In this subsection, we derive Equation (31) from Equation (30) by the time discretized method. Equation (30) can be calculated as follows:
where is the solution of the FP Equation (33) driven by , and is defined as follows:
From Ito’s lemma,
Because control is a function of memory z in ML-POSC, the minimization by can be exchanged with the expectation by as follows:
Therefore, Equation (31) is derived from Equation (30). Finally, we prove that is the solution of the HJB Equation (32) driven by . can be calculated as follows:
where . Therefore, defined by Equation (A79) is the solution of the HJB Equation (32) driven by .
Appendix C.7. Derivation of Result in Section 4.3
In this subsection, we mainly derive the inequality of the forward step (35). The inequality of the backward step (34) can be derived in a similar way. In the forward step, and are given, and is defined by
From the equivalence of Equations (30) and (31), the following equation is satisfied:
Therefore, the inequality of the forward step (35) is satisfied.
Appendix C.8. Derivation of Result in Section 4.4
In this subsection, we show that FBSM for ML-POSC converges to Pontryagin’s minimum principle (20). More specifically, we prove that if holds, satisfies Pontryagin’s minimum principle (20). We mainly consider the forward step. We can make a similar discussion in the backward step. If holds, then holds from Equation (35). Because holds, holds. Then, because holds, holds. Iterating this procedure from to , holds. Therefore, because the HJB equation and the FP equation depend on the same control function , satisfies Pontryagin’s minimum principle (20).
Appendix C.9. Derivation of Result in Section 5.3
In this subsection, we show that FBSM is reduced from Algorithm 1 to Algorithm 2 in the LQG problem of ML-POSC.
We first consider the initial step. We assume that the control function is initialized by
where is arbitrary and is the solution of given . When the control function is initialized by (A85), the solution of the FP equation is given by the Gaussian distribution , where is the solution of (42) and is the solution of given .
We then consider the backward step. When the solution of the FP equation is given by the Gaussian distribution , the solution of the HJB equation is given by the quadratic function , where , , and are the solutions of the following ODEs:
where , , and .
We finally consider the forward step. When the solution of the HJB equation is given by the quadratic function , the solution of the FP equation is given by the Gaussian distribution , where is the solution of (42) and is the solution of given . Therefore, FBSM is reduced from Algorithm 1 to Algorithm 2 in the LQG problem of ML-POSC. The details of these calculations are almost the same with [14].
References
- Fox, R.; Tishby, N. Minimum-information LQG control Part II: Retentive controllers. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 5603–5609. [Google Scholar] [CrossRef]
- Fox, R.; Tishby, N. Minimum-information LQG control part I: Memoryless controllers. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 5610–5616. [Google Scholar] [CrossRef]
- Li, W.; Todorov, E. An Iterative Optimal Control and Estimation Design for Nonlinear Stochastic System. In Proceedings of the 45th IEEE Conference on Decision and Control, San Diego, CA, USA, 13–15 December 2006; pp. 3242–3247. [Google Scholar] [CrossRef]
- Li, W.; Todorov, E. Iterative linearization methods for approximately optimal control and estimation of non-linear stochastic system. Int. J. Control. 2007, 80, 1439–1453. [Google Scholar] [CrossRef]
- Nakamura, K.; Kobayashi, T.J. Connection between the Bacterial Chemotactic Network and Optimal Filtering. Phys. Rev. Lett. 2021, 126, 128102. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, K.; Kobayashi, T.J. Optimal sensing and control of run-and-tumble chemotaxis. Phys. Rev. Res. 2022, 4, 013120. [Google Scholar] [CrossRef]
- Pezzotta, A.; Adorisio, M.; Celani, A. Chemotaxis emerges as the optimal solution to cooperative search games. Phys. Rev. E 2018, 98, 042401. [Google Scholar] [CrossRef]
- Borra, F.; Cencini, M.; Celani, A. Optimal collision avoidance in swarms of active Brownian particles. J. Stat. Mech. Theory Exp. 2021, 2021, 083401. [Google Scholar] [CrossRef]
- Davis, M.H.A.; Varaiya, P. Dynamic Programming Conditions for Partially Observable Stochastic Systems. SIAM J. Control. 1973, 11, 226–261. [Google Scholar] [CrossRef]
- Bensoussan, A. Stochastic Control of Partially Observable Systems; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar] [CrossRef]
- Fabbri, G.; Gozzi, F.; Święch, A. Stochastic Optimal Control in Infinite Dimension. In Probability Theory and Stochastic Modelling; Springer International Publishing: Cham, Switzerland, 2017; Volume 82. [Google Scholar] [CrossRef]
- Wang, G.; Wu, Z.; Xiong, J. An Introduction to Optimal Control of FBSDE with Incomplete Information; Springer Briefs in Mathematics; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Bensoussan, A.; Yam, S.C.P. Mean field approach to stochastic control with partial information. ESAIM Control. Optim. Calc. Var. 2021, 27, 89. [Google Scholar] [CrossRef]
- Tottori, T.; Kobayashi, T.J. Memory-Limited Partially Observable Stochastic Control and Its Mean-Field Control Approach. Entropy 2022, 24, 1599. [Google Scholar] [CrossRef]
- Kushner, H. Optimal stochastic control. IRE Trans. Autom. Control. 1962, 7, 120–122. [Google Scholar] [CrossRef]
- Yong, J.; Zhou, X.Y. Stochastic Controls; Springer: New York, NY, USA, 1999. [Google Scholar] [CrossRef]
- Nisio, M. Stochastic Control Theory. In Probability Theory and Stochastic Modelling; Springer: Tokyo, Japan, 2015; Volume 72. [Google Scholar] [CrossRef]
- Bensoussan, A. Estimation and Control of Dynamical Systems. In Interdisciplinary Applied Mathematics; Springer International Publishing: Cham, Switzerland, 2018; Volume 48. [Google Scholar] [CrossRef]
- Kushner, H.J.; Dupuis, P.G. Numerical Methods for Stochastic Control Problems in Continuous Time; Springer: New York, NY, USA, 1992. [Google Scholar] [CrossRef]
- Fleming, W.H.; Soner, H.M. Controlled Markov Processes and Viscosity Solutions, 2nd ed.; Number 25 in Applications of Mathematics; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; Wiley-Interscience: Hoboken, NJ, USA, 2014. [Google Scholar]
- Pontryagin, L.S. Mathematical Theory of Optimal Processes; CRC Press: Boca Raton, FL, USA, 1987. [Google Scholar]
- Vinter, R. Optimal Control; Birkhäuser Boston: Boston, MA, USA, 2010. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.; Syrmos, V.L. Optimal Control; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Aschepkov, L.T.; Dolgy, D.V.; Kim, T.; Agarwal, R.P. Optimal Control; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Bensoussan, A.; Frehse, J.; Yam, P. Mean Field Games and Mean Field Type Control Theory; Springer Briefs in Mathematics; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Carmona, R.; Delarue, F. Probabilistic Theory of Mean Field Games with Applications I; Number Volume 83 in Probability Theory and Stochastic Modelling; Springer Nature: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Carmona, R.; Delarue, F. Probabilistic Theory of Mean Field Games with Applications II; Volume 84, Probability Theory and Stochastic Modelling; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Carmona, R.; Delarue, F. The Master Equation for Large Population Equilibriums. In Stochastic Analysis and Applications 2014; Crisan, D., Hambly, B., Zariphopoulou, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 100, pp. 77–128. [Google Scholar] [CrossRef]
- Bensoussan, A.; Frehse, J.; Yam, S.C.P. The Master equation in mean field theory. J. Math. Pures Appl. 2015, 103, 1441–1474. [Google Scholar] [CrossRef]
- Bensoussan, A.; Frehse, J.; Yam, S.C.P. On the interpretation of the Master Equation. Stoch. Process. Their Appl. 2017, 127, 2093–2137. [Google Scholar] [CrossRef]
- Krylov, I.; Chernous’ko, F. On a method of successive approximations for the solution of problems of optimal control. USSR Comput. Math. Math. Phys. 1963, 2, 1371–1382. [Google Scholar] [CrossRef]
- Mitter, S.K. Successive approximation methods for the solution of optimal control problems. Automatica 1966, 3, 135–149. [Google Scholar] [CrossRef]
- Chernousko, F.L.; Lyubushin, A.A. Method of successive approximations for solution of optimal control problems. Optim. Control. Appl. Methods 1982, 3, 101–114. [Google Scholar] [CrossRef]
- Lenhart, S.; Workman, J.T. Optimal Control Applied to Biological Models; Chapman and Hall/CRC: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Sharp, J.A.; Burrage, K.; Simpson, M.J. Implementation and acceleration of optimal control for systems biology. J. R. Soc. Interface 2021, 18, 20210241. [Google Scholar] [CrossRef]
- Hackbusch, W. A numerical method for solving parabolic equations with opposite orientations. Computing 1978, 20, 229–240. [Google Scholar] [CrossRef]
- McAsey, M.; Mou, L.; Han, W. Convergence of the forward-backward sweep method in optimal control. Comput. Optim. Appl. 2012, 53, 207–226. [Google Scholar] [CrossRef]
- Carlini, E.; Silva, F.J. Semi-Lagrangian schemes for mean field game models. In Proceedings of the 52nd IEEE Conference on Decision and Control, Firenze, Italy, 10–13 December 2013; pp. 3115–3120, ISSN 0191-2216. [Google Scholar] [CrossRef]
- Carlini, E.; Silva, F.J. A Fully Discrete Semi-Lagrangian Scheme for a First Order Mean Field Game Problem. SIAM J. Numer. Anal. 2014, 52, 45–67. [Google Scholar] [CrossRef]
- Carlini, E.; Silva, F.J. A semi-Lagrangian scheme for a degenerate second order mean field game system. Discret. Contin. Dyn. Syst. 2015, 35, 4269. [Google Scholar] [CrossRef]
- Lauriere, M. Numerical Methods for Mean Field Games and Mean Field Type Control. arXiv 2021, arXiv:2106.06231. [Google Scholar]
- Wonham, W.M. On the Separation Theorem of Stochastic Control. SIAM J. Control. 1968, 6, 312–326. [Google Scholar] [CrossRef]
- Li, Q.; Chen, L.; Tai, C.; E, W. Maximum Principle Based Algorithms for Deep Learning. J. Mach. Learn. Res. 2018, 18, 1–29. [Google Scholar]
- Liu, X.; Frank, J. Symplectic Runge–Kutta discretization of a regularized forward–backward sweep iteration for optimal control problems. J. Comput. Appl. Math. 2021, 383, 113133. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Howard, R.A. Dynamic Programming and Markov Processes; John Wiley: Oxford, UK, 1960. [Google Scholar]
- Kappen, H.J. Linear Theory for Control of Nonlinear Stochastic Systems. Phys. Rev. Lett. 2005, 95, 200201. [Google Scholar] [CrossRef]
- Kappen, H.J. Path integrals and symmetry breaking for optimal control theory. J. Stat. Mech. Theory Exp. 2005, 2005, P11011. [Google Scholar] [CrossRef]
- Satoh, S.; Kappen, H.J.; Saeki, M. An Iterative Method for Nonlinear Stochastic Optimal Control Based on Path Integrals. IEEE Trans. Autom. Control. 2017, 62, 262–276. [Google Scholar] [CrossRef]
- Cacace, S.; Camilli, F.; Goffi, A. A policy iteration method for Mean Field Games. arXiv 2021, arXiv:2007.04818. [Google Scholar] [CrossRef]
- Laurière, M.; Song, J.; Tang, Q. Policy iteration method for time-dependent Mean Field Games systems with non-separable Hamiltonians. arXiv 2021, arXiv:2110.02552. [Google Scholar] [CrossRef]
- Camilli, F.; Tang, Q. Rates of convergence for the policy iteration method for Mean Field Games systems. arXiv 2022, arXiv:2108.00755. [Google Scholar] [CrossRef]
- Ruthotto, L.; Osher, S.J.; Li, W.; Nurbekyan, L.; Fung, S.W. A machine learning framework for solving high-dimensional mean field game and mean field control problems. Proc. Natl. Acad. Sci. USA 2020, 117, 9183–9193. [Google Scholar] [CrossRef]
- Lin, A.T.; Fung, S.W.; Li, W.; Nurbekyan, L.; Osher, S.J. Alternating the population and control neural networks to solve high-dimensional stochastic mean-field games. Proc. Natl. Acad. Sci. USA 2021, 118, e2024713118. [Google Scholar] [CrossRef]
- Laurière, M.; Pironneau, O. Dynamic programming for mean-field type control. C. R. Math. 2014, 352, 707–713. [Google Scholar] [CrossRef]
- Laurière, M.; Pironneau, O. Dynamic programming for mean-field type control. J. Optim. Theory Appl. 2016, 169, 902–924. [Google Scholar] [CrossRef]
- Pham, H.; Wei, X. Bellman equation and viscosity solutions for mean-field stochastic control problem. ESAIM Control. Optim. Calc. Var. 2018, 24, 437–461. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).