1. Introduction
The most valuable resource in the information society is data. It seems that “there is no such thing as too much data”, but let us try to look at this catchphrase as data scientists. The “curse of dimensionality” is a problem that consists of the exponential growth of the amount of data that has occurred simultaneously with the growth of the dimensionality of the space for data representation. This term was introduced by Richard Bellman in 1961. Scientists dealing with mathematical modelling and computational methods were the first to face this problem. Now, this problem is faced again as machine learning and artificial intelligence methods are implemented. In this study, we will illustrate the relevance of this problem using the k-nearest neighbour method, which is popular for solving classification problems [
1,
2,
3,
4]. The essence of the method is as follows: the instance belongs to the same class as that which the majority of its nearest neighbour instances in the parametric space belong. To ensure high-quality work with this method, the saturation density of the parametric space with instances must be sufficiently high. How are the parametric space dimensions, the density of instances, and their number related to each other? To uniformly cover a unit interval [0, 1] with a density 0,01, we need 100 points, where the coverage density is defined as the ratio of the number of points evenly distributed in the target interval to the length of the latter. Now, imagine a 10-dimensional cube. To achieve the same coverage density, we already need 10
20 points, that is, 10
18 times more points compared to the original 1-dimensional space. This example demonstrates the reason for the inefficiency of the brute force method in typical machine learning problems (classification, clustering, and regression) [
5,
6,
7,
8,
9]. The paradox is that it is impossible to solve the mentioned applied problems using a small number of parameters and achieve adequate results. One can simply turn a blind eye to the problem of dimensionality, which is the paradigm of deep learning, where using non-parameterized models achieves a significant increase in their quality despite the colossal increase in the number of calculations and accepting as an axiom the potential instability of the training process. But this recipe is unacceptable in the context of the machine learning ideology. The following
Table 1 contains a more detailed comparison of these two methods.
Therefore, managing the dimensionality of data while preserving their quality and the representativeness of the parametric space is an urgent scientific problem for machine learning.
The most widely used method for reducing data dimensionality is singular value decomposition (SVD, [
10,
11,
12]). The matrices obtained as a result of SVD have a very specific interpretation in the machine learning methodology. They can be used according to the proven method both for principal component analysis (PCA, [
13,
14,
15]) and (with certain reservations) for non-negative matrix factorization (NMF, [
16,
17,
18]). SVD can also be used to improve the results of independent component analysis (ICA, [
19,
20,
21]). It is convenient to apply SVD because there are no restrictions on the structure of the original data matrix (square when using the LU [
22] or Schur distribution [
23]; square, symmetric, or positive definite when using the Cholesky distribution [
24]; matrix with positive elements when applying NMF). The essence of SVD is the representation of the original matrix
X as a product of matrices of the form
, where
U is a unitary matrix of order
m and ∑ is a rectangular diagonal matrix of dimension (
m ×
n), where
m is a number of instances and
n is a number of measured observables, with singular elements on the main diagonal and
is a matrix of order
n, obtained as a result of conjugate transpose of the matrix
V. The matrix ∑ is important for the dimensionality management problem. The squared singular elements of this matrix are interpreted as the variance
σ2 of the corresponding component. Based on the value of these variances, the researcher can select the required number of components. What is the best value
? Some recommend maintaining the inequality
, while others believe that
is sufficient. The original answer to this question is provided by Horn’s parallel analysis based on Monte Carlo simulation [
25]. The disadvantage of both SVD and PCA is the high computational complexity of obtaining a singular distribution (well-known randomized algorithms [
26] slightly mitigate this limitation). A more serious limitation is the sensitivity of SVD/PCA to outliers and the type of distribution of the original data. Most researchers believe that SVD/PCA works consistently with normally distributed data, but it has been empirically found that, as the data dimensionality increases, there are exceptions even to this rule. Therefore, SVD/PCA methods cannot guarantee the stability of the data dimensionality reduction procedure.
NMF is used to obtain the decomposition of a non-negative matrix
into non-negative matrices
and
:
X =
WH. By choosing
, we can solve the problem of reducing the dimensionality of the original matrix quite effectively. The problem is that, unlike SVD, finding the
X =
WH decomposition does not have an exact solution. There are specialized formulations of quadratic programming problems, such as the support vector machine (SVM, [
27,
28,
29]) [
30]. However, we understand that this means that NMF has the same limitations that have been pointed out for SVD/PCA.
The ICA method crossed into machine learning from the signal processing theory and, in its original formulation, was intended for the decomposition of a signal with additive components. At the same time, it was believed that these components have an abnormal distribution, and the sources of their origin are independent. To determine independent components, either minimization of mutual information based on Kullback–Leibler divergence [
19] or minimization of “non-Gaussianity” [
20,
21] (using measures such as kurtosis coefficient and negentropy) are used. In the context of the dimensionality reduction problem, the application of ICA is trivial: to represent the input data as a mixture of components, divide them and select a certain number. There is no analytically consistent criterion for component selection.
We have often mentioned machine learning methods in the context of the data dimensionality management problem. However, there are competitors originating from the artificial intelligence field, i.e., the autoencoders [
31,
32,
33]. This is an original class of neural networks, created so that the signal given to the input layer is reproduced as accurately as possible at the output of the neural network. The number of hidden layers should be at least one, and the activation functions of neurons on these layers should be non-linear (most often
sigmoid,
tanh,
ReLu). If the number of neurons in the hidden layer is less than the number of neurons in the input layer, and we reproduce the input signal at the same time with sufficient accuracy as the output of the trained autoencoder, then the parameters of the neurons of the hidden layer are a compact approximate representation of the input signal. The advantage of this approach is that the neural network works for us. It is also very easy to orient the autoencoder to solve the data dimensionality increasing problem: it is sufficient that there are more neurons on the hidden layer than on the input layer. Disadvantages are also known: empirical search for the optimal configuration of the neural network (number of hidden layers, number of neurons on those layers, and selection of their activation functions), empirical selection of both the training algorithm and its parameters), and the neural network regularization methods (
L1,
L2,
dropout). And we have not yet focused on the specific drawback of autoencoders, i.e., the tendency to degenerate hidden layers in the training process.
In recent years, there has been a growing interest in the research of data analysis, particularly within the context of regression analysis applied to inhomogeneous datasets. The existing research [
34] explores the challenges presented by data that can be gathered from various sources or recorded at different time intervals, resulting in inherent inhomogeneities that complicate the process of regression modelling. The conventional framework of independent and identically distributed errors, typically associated with a single underlying model, is inadequate for handling such data. As the authors claim, traditional alternatives, like time-varying coefficients models or mixture models, can be computationally burdensome and impractical. So, the paper [
34] proposes an aggregation technique based on normalized entropy (neagging) in contrast with such well-known aggregation procedures as bagging and magging. This approach has shown great promise, and the paper provides practical examples to illustrate its effectiveness using real-world datasets across various scenarios. However, the authors position their solution for working with large amounts of data or Big data. The issue of applicability of the mentioned procedures for compactification of small variable data has not been considered.
Taking into account the strengths and weaknesses of the mentioned methods, we will formulate the necessary attributes of scientific research.
The research object is the process of stochastic empirical data collection compactification.
The research subjects are probability theory and mathematical statistics, information theory, computational methods, mathematical programming methods, and experiment planning theory.
The research purpose is to formalize the process of finding the optimal probability distribution density of stochastic characteristic parameters of the empirical data compactification model with the maximum relative entropy between the original and compactified entities.
The research objectives are:
- -
formalize the concept of calculating the variable entropy estimation of the probability distribution density of the characteristic parameters of the stochastic empirical data collection;
- -
formalize the process of the stochastic empirical data collection compactification with the maximization of the relative entropy between the original and compactified entities;
- -
justify the adequacy of the proposed mathematical apparatus and demonstrate its functionality with an example.
The Motivation. One derives quantitative information on a class of objects by measuring a set of observables (“characteristic parameters”) on a sample of objects taken from the class of interest. A set of values taken by the chosen observables on one of the objects is an instance. One of the basic problems in general data analysis is finding the optimal number of instances and the optimal (minimal) number of observables, that allow, in the presence of noise, to build regression models, estimate correlations between observables, and classify and cluster the objects in a machine learning approach. In this perspective, which is a very relevant one, the authors propose a model of noisy data based on a conditional, relative entropy [Equation (6)]. The article introduces a consistent and tunable method of “compactification” that performs quite well concerning other established methods, such as PCA and random projection methods.
2. Models and Methods
2.1. Statement of the Research
Let us characterize the researched process using a model in terms of linear programming, that is, by a function that summarizes n weighted characteristic parameters , where the weights w are interval stochastic values: , the properties of which are characterized by the probability distribution density P(w).
Suppose that, as a result of
m observations of the investigated process, empirical data with the structure
were obtained, where
V is the training collection and each empirical parametric vector
,
, corresponds to an empirical initial value
,
. When substituting data
V into the model
z, the equality of
must be fulfilled and which is provided by the training of the model
z.
We consider that the values
yi of the original empirical vector
y contain interference, which are represented by stochastic vector values
,
,
, with the probability density function
of a stochastic vector
. Taking into account interferences, we present expression (1) as
where
,
,
.
In the context of the formulated equation, the machine learning methodology is focused on determining the estimates
and
of the corresponding probability distribution densities. The basis for this is model (2) and a set of empirical data
V. Based on the known estimates of
and
, it is possible to outline the domain of stochastic vectors
. Such a problem will be referred to as a
d-problem. The authors devoted the article [
35] directly to the solution of the
d-problem.
On the other hand, the problem of compactification of the parametric space V of model (2) is solved by reducing the dimension of the characteristic parameters from n to r units, r < n, is also of practical value. Such a problem will be referred to as a c-problem.
Suppose that, as a result of the compactification of the original empirical data with the structure , a shortened parametric space is obtained where each parametric vector , , or , corresponds to the original interval stochastic value , , with the probability distribution density A(a).
To describe compactified data
, we define the model
and the vector of observations is expressed as
where the stochastic vector
is formed by interval values
with the probability distribution density
. The vectors
s defined by expression (4) are interpreted as
,
,
.
Our further actions will be aimed at formulating:
- -
optimality criterion of the compactified data matrix Y(m×r);
- -
a method for calculating the elements of the optimal compactified data matrix Y(m×r);
- -
a method for comparing the probability distribution densities of outputs of models (2) and (4) as an indicator of the effectiveness of the proposed compactification concept.
2.2. The Concept of Entropy-Optimal Compactification of Stochastic Empirical Data
Let us focus on the analytical formalization of the entropic properties of empirical data, summarized by the matrix V. Let there be m independent instances in the collection of class X, each of which is characterized by the values of n attributes (characteristic parameters). The selection of instances in the collection X is random. In this context, the matrix X summarizes , , , stochastic attributes whose values are real numbers: , , , satisfying the condition , where W is determined by the region of origin of instances of the class X.
We normalize the values of the elements of the matrix relative to the selected scale with a resolution of Δ: , , , . The step Δ is chosen to ensure sufficient variability of the resulting integer values of the stochastic elements of the matrix , , .
Let us formalize the process of forming the values of the elements of the matrix
H. Let us have
A atomic units of the resource, which are distributed among
m ×
n elements of the matrix
H, and the probability of a resource unit falling into the element
is characterized by the probability
,
,
. The probability distribution of such a process is defined as
If the Moivre–Stirling approximation of factorials of large numbers is applied to the logarithmic representation of expression (5), we obtain an expression that characterizes the process described above based on the relative entropy:
where
,
,
.
Taking into account the proposed physical interpretation of the process of the matrix
H values formation, it is appropriate to introduce such a characteristic parameter as the resource units a priori distribution, i.e.,
,
,
. Taking this parameter into account, expression (6) can be redefined as
Equality (7) is defined with accuracy up to the constant
Aln
A. The essential connection between the sources of origin of the elements of the matrices
X and
H allows us to define the cross-entropy function as
Based on expression (8), we write:
where
,
, and
, and the second term is the relative uncertainty characteristic of the stochastic matrix
X.
Function (8) is concave for the entire range of values of the argument
X and reaches a single extremum at the point
,
,
,
. The extreme value of function (8) is equal to
The value (10) characterizes the maximum uncertainty of the matrix X for a defined matrix V. Let us emphasize other useful properties of function (8).
Let us define a matrix
L with elements
,
, and
. Considering
, expression (8) can be rewritten as
where the symbols Sp and T represent the operations of trace finding and matrix transposition, respectively.
Based on the definition
, we obtain the following inequality for the logarithmic function:
where
.
Having transformed expression (11) and taking into account inequality (12), we determine the upper limit of cross entropy (8):
Function (13) is concave and follows all the properties of function (8).
Consider a non-degenerate matrix of empirical data with positive elements. Let us set the desired dimension of the parametric space: r, r < n, and enter into the matrix , , and . We obtain a direct projection of the matrix onto the parametric space Rmr: . We obtain the inverse projection on the space Rmn using the matrix , and the values of all elements which are positive: . The dimensionality of both the obtained matrix X and the original matrix V is the same: (m × n).
Let us express the cross-entropy functional
, taking into account the existence of the matrices
and
:
where
The optimal configuration of the values of the positive matrices
Q and
S in the entropy basis is described by the expression
We will search for the extremum of the objective function (15) by the iterative gradient projection method [
36,
37], taking into account the need to cut off elements with negative values (observing condition
).
Let us analytically express the partial derivatives of the function
in terms of the arguments, i.e., the elements of matrices
Q and
S:
where
,
,
,
,
,
,
, and
.
Let us derive vectors and as a result vectorization of matrices Q and S, respectively. We identify the gradient vector of the relative entropy functional (14) with components (16) . We identify the gradient vector of the relative entropy functional (14) with components (17). We initialize the iterative procedure for finding the extremum of the objective function (15) based on the gradient projection method and in terms of the introduced entities.
For the 0th iteration, we take , , , .
For the
nth iteration, we write:
where parameters
,
regulate increments in the corresponding dimension.
Iterative process (18) ends when the dynamics of the change in the value of the relative entropy functional becomes less than the threshold
δ:
where
is the information capacity of the positive matrix
. By analogy, we write:
, where
.
The computational complexity of the implementation of the iterative procedure just described increases nonlinearly with the increase in the dimension of the analyzed empirical matrices. Considering this circumstance, it is acceptable to define the elements of the matrix of the reduced dimension
Q based on the approximately defined relative entropy functional
. For example, let us use the approximation of the logarithmic function at the point
:
. For points
we find:
Let us present the expression (20) in the matrix form:
where the symbol
represents the Frobenius scalar product:
.
With a fixed matrix of empirical data
V, we will minimize the functional
on the set of positive matrices
Q and
S:
The procedure for finding
also uses components (16), and (17), which should be adapted to the scalar form of representation of the entities involved. Applying the rules of matrix differentiation to the functional (21), we obtain the following scalar interpretations of components (16), and (17):
where
;
and
are the gradients of matrices
Q and
S, respectively. The results of expressions (23), and (24) will be matrices of dimension (
n ×
r).
We initialize the iterative procedure for finding the extremum of objective function (22) based on the gradient descent method and in terms of entities (23), and (24).
For the 0th iteration: we take X(0), V(0).
For the
nth iteration, we write:
The iterative process (25) ends when the dynamics of the change in the value of the functional becomes less than the set threshold δ: .
In [
35], the authors described the basic concept of solving the
d- and
c-problems mentioned in
Section 2.1 for empirical data of the type
V and
Y, respectively. The result is the optimal probability distribution densities of characteristic parameters and interference (for the
d-problem:
,
, and for the
c-problem:
,
, respectively). The mathematical apparatus presented in
Section 2.2 allows, based on linear models (2), and (4), to calculate normalized
probability distributions
and
to determine the absolute difference between these functions in terms of relative entropy [
38,
39,
40,
41].
To preserve the integrity of the presentation of the material, we will demonstrate how the basic concept of solving the
d-problem is implemented in the context of model (2). Let’s define the functional
on the probability distribution densities
and
. We need to solve the optimization problem with the following objective function and constraints:
The solution to the optimization problem (26) in analytical form looks like
where the Lagrange multipliers
θ are determined as a result of solving the system of balance equations
in the interpretation
.
In the context of the model (2), the probability distribution density
F(
u) of the observation vector
u is defined as
where
Fd(
u) is the desired probability distribution density of the
d-problem model, and
is the density of the stochastic vector
. From expression (27) we find
.
Considering the interval nature of the vector z: , we write . Having normalized the function , we express the probability distribution density of the vector z as .
To determine the probability distribution density in the context of the model (4) (c-problem), it is necessary to repeat the sequence of actions embodied in expression (27) based on the empirical data matrix Y.
To compare the functions
and
, it is necessary to normalize them on the common carrier
:
To find the absolute share of information losses between functions
and
due to compaction Δ
E we define in terms of the relative entropy of
RE as
Note that the minimum ΔE = 0 is reached at .
3. Results
Let us begin the experimental Section by demonstrating the functionality of the mathematical apparatus proposed in
Section 2.2 on a simple abstract example.
Suppose we have initial empirical data of the form . In the context of model (2), we write . Suppose that , . The output component is defined by the vector .
Let , then , where is the matrix for the direct projection. The compactification model (4) for the above values and conditions looks like this , where , . The inverse projection operation is analytically characterized as , where is the matrix for the inverse projection.
Our example is characterized by a small dimension, so we will use procedure (18) to determine the cross entropy. In this context, the cross entropy E between the original empirical matrix and the matrix obtained as a result of direct-inverse projection will be analytically determined by the expression . The function reaches an extremum at , . Accordingly, the optimal compactified matrix has the form .
The optimal probability distribution densities of the characteristic parameters and interference for the matrix V defined at the beginning of the Section are characterized by the functions and . To compare the functions and , it is necessary to normalize them on the common carrier, so, using (28), we find , . Then, with the defined functions (2), (4), and , the absolute share of information losses (29) of reducing the dimensionality of the space of characteristic parameters from n = 2 to r = 1 is equal to , which allows us to consider the result of the proposed compactification procedure of the original empirical matrix V as adequate.
To prove the effectiveness of the proposed compactification method (18) (Met3), the method should be compared with popular analogues, namely, with the principal component analysis method (Met1) and the random projection method (Met2). Considering the linear nature of functions (2) and (4), we will experiment in the context of solving the verification problem (dichotomous classification) with a linear classifier. Let’s formulate such a problem based on the terminology used.
We define the linear classifier model as
where
and the values of the weights
are unknown a priori.
Empirical data with the structure are available, and where is an instance of a class with a number . The training of the classifier (30) is reduced to the minimization of the empirical risk function of the form . To test the trained classifier (30), test empirical data with the structure were used.
The results of the classification are synchronously compared with the corresponding elements of the vector and taken into account in the form of the value of the function , where . Accordingly, classification accuracy is defined as .
The conducted experiment consisted of solving the verification problem using classifier (30) for:
e0—basic empirical dataset ;
{e1, e2, e3}—the dataset , the dimension of the attributes of the matrices V and U which underwent compactification from the initial n to the specified r elements by the method {Met1, Met2, Met3}.
The value was iteratively reduced: , forming a set of datasets at each of the stages {e1, e2} with the corresponding compactification degree. The number of compactification procedures e3 was determined by the set of threshold values (19).
For experiments, as necessary, tables of synthetic data of the required size were generated. For this, the sklearn.datasets.make_classification(n_class = 2, n_clusters = 2, n_redundant = 0, class_sep = 1.0, n_informative = {10, 15}) function of the Python programming language was used. Before use, all generated data were normalized to fall within the unit interval [0, 1]. The experiments were carried out using scipy.stats.bootstrap cross-validation.
The algorithmic designs of the {Met1, Met2, Met3} methods were implemented by the functions of the scipy and sklearn libraries. The classifier (30) was implemented as a support vector machine with a linear kernel using the function sklearn.svm.SVC. The Met1 Met2 methods were implemented using the sklearn.decomposition.PCA and sklearn.random_projection.GaussianRandomProjection functions, respectively. The basis for the implementation of the author’s method (18) was the scipy.optimize.minimize function (after inverting the objective function (15)). At the same time, the attribute ftol was considered to be related to the threshold (19).
As already mentioned in
Section 2.2, the author’s empirical data compactification method proposed in the form of procedure (18) is comparatively computationally complex (this is what prompted the authors to formalize the “simplified” iterative procedure (25)). However,
Met1,
Met2 analogues have their disadvantages, which appear when compacting large-dimensional data. For example, with a sufficiently large number of instances of data
m and their heterogeneity,
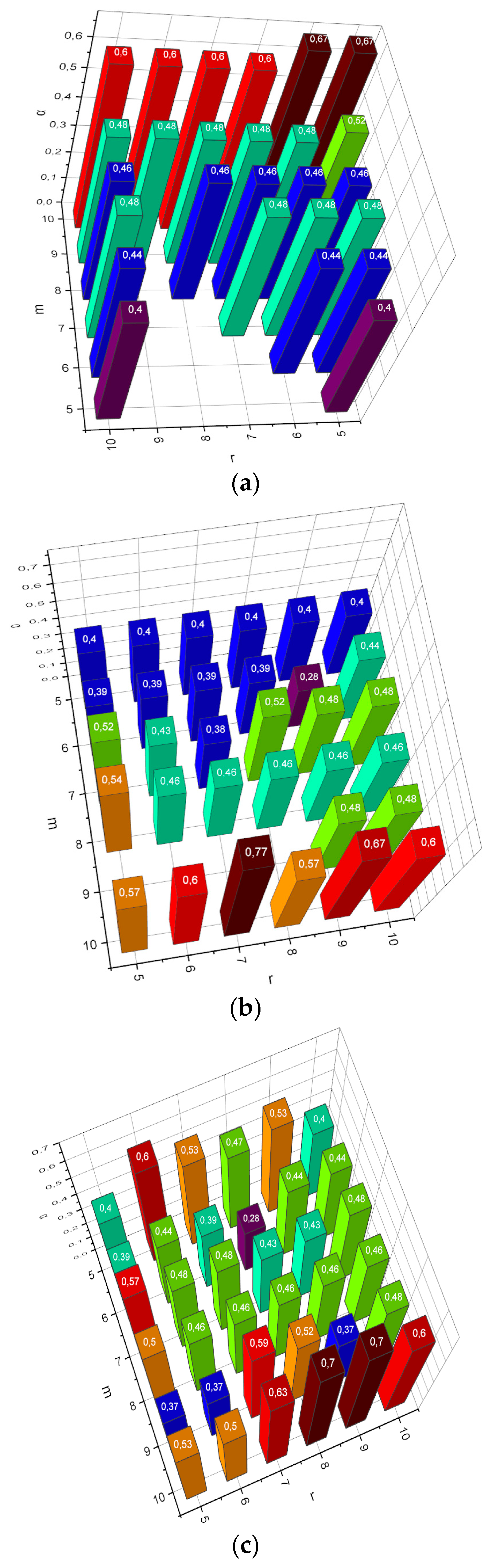
Met1 becomes unstable. We will conduct the first experiment of the form
α =
f(
m,
Met,
r) for
,
,
,
Met = {
Met1,
Met2,
Met3}. The obtained results are visualized in
Figure 1.
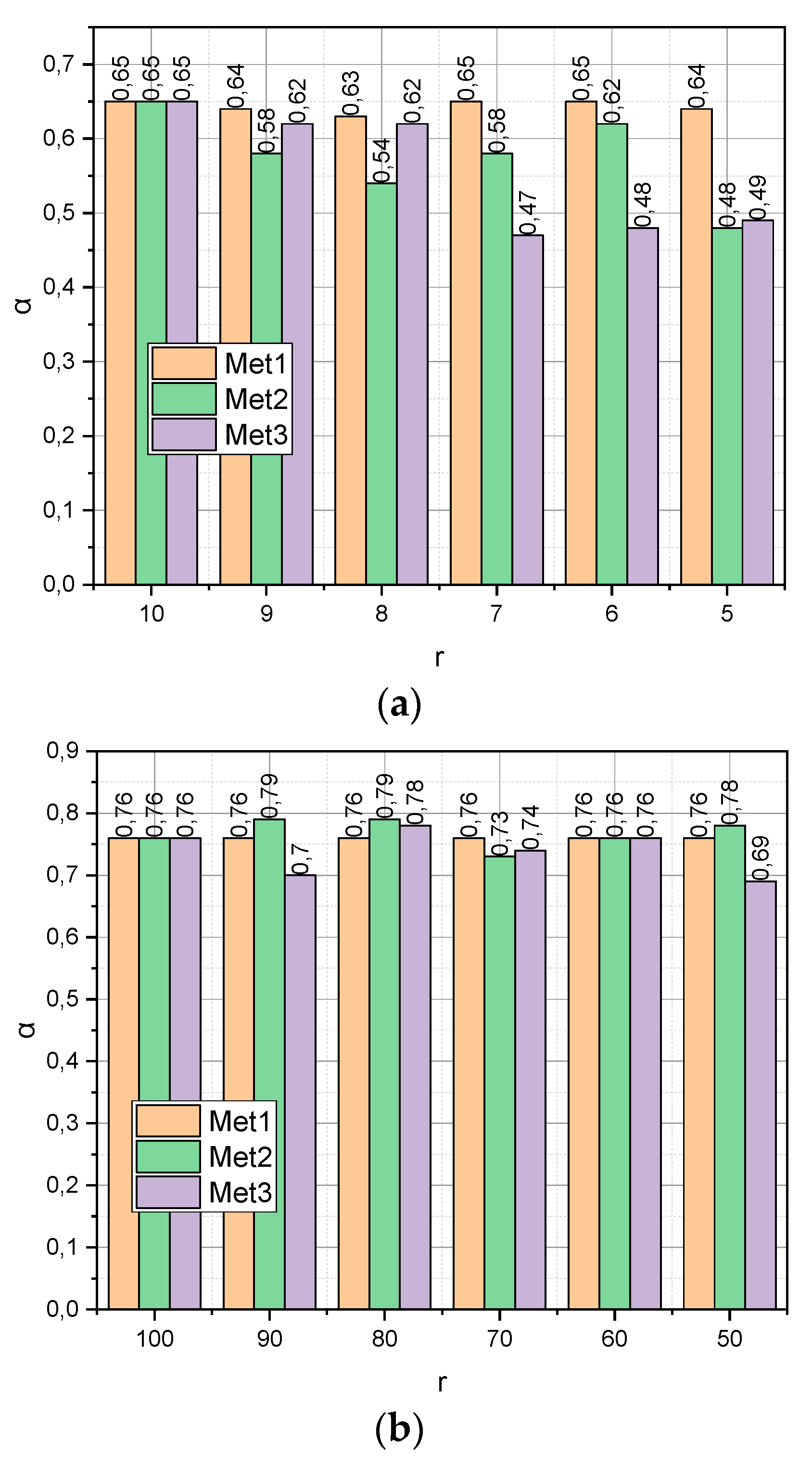
The previous experiment characterized the ultra-compact empirical data compactification procedure:
,
. Now, let us investigate how the verification accuracy
α depends on the compactification of the initial data, for which
,
. The experiments were carried out for two generated datasets
DS1 and
DS2. The first was characterized by dimension (
m = 100,
n = 10) and the second by dimension (10
4, 10
2). When processing the first dataset, we set
r = {100, 90,…, 50} When working with the second dataset, we set
r = {100, 90,…, 50} The obtained results are presented in
Figure 2.
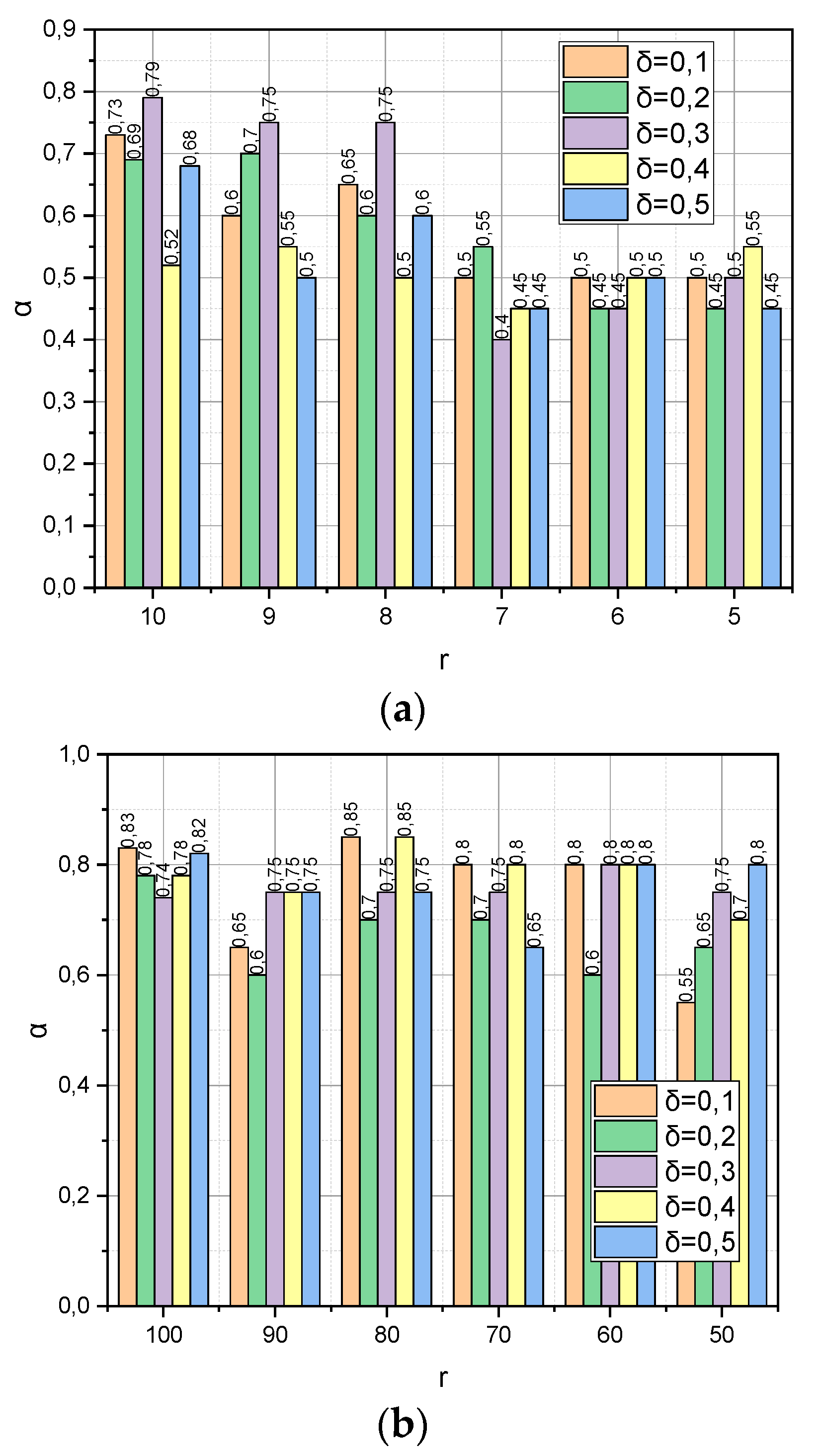
The following experiment is specific to
Met3 because it concerns the detection of the dependence between the verification accuracy
α and the dynamics of such parameters as the compactification degree
r and the value of the threshold
(see expression (19)). To preserve the common information background, the remaining parameters were borrowed from the previous experiment without changes, namely:
,
r(
DS1) = {10, 9,…, 5}, and
r(
DS2) = {100, 90,…, 50}. The resulting dependencies are visualized in
Figure 3.
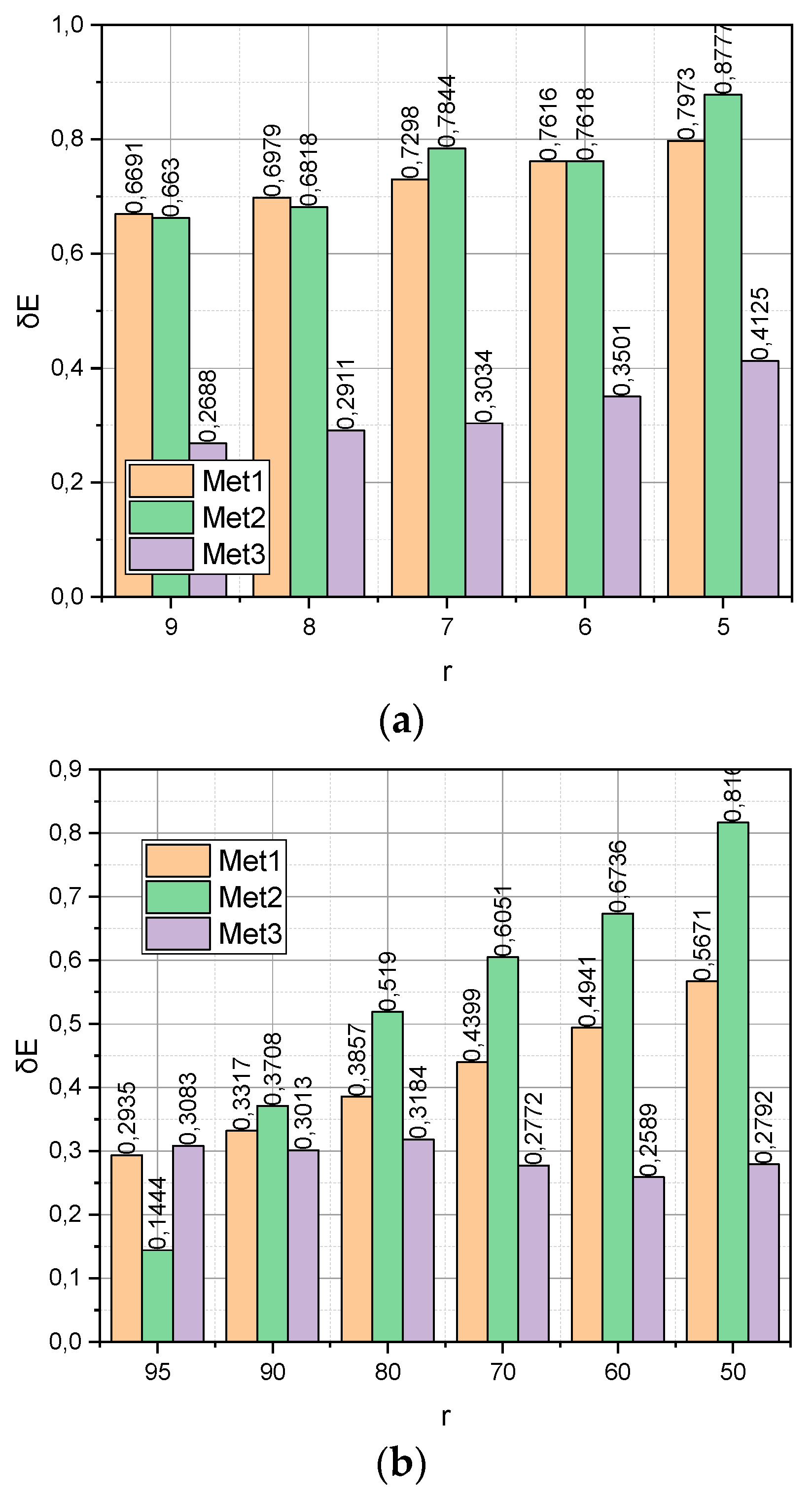
The empirical data compactification process is accompanied by an information loss. The absolute error as an indicator of information loss during compactification can be calculated by expression (29). The relative share of information losses during compactification can be calculated directly by expression (19) when implementing the compactification procedure (18).
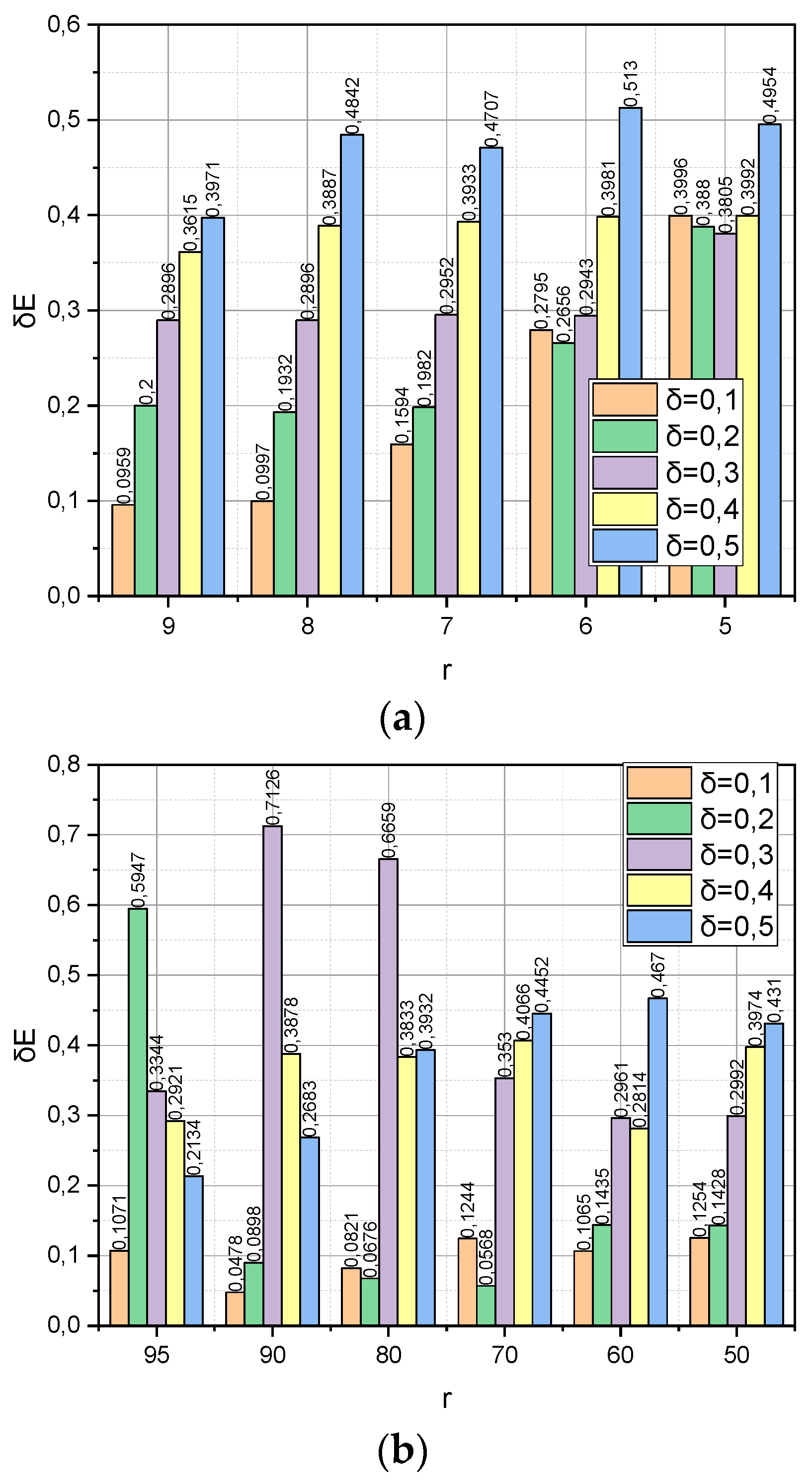
Figure 4 presents the calculated dependences of the relative share of information loss
on the compactification method
for datasets
with the corresponding ranges of changes in the compaction degree
.
Finally, we will conclude the Experimental Section with a study of
Met3, the detection of the dependence between the relative share of information loss
, and the dynamics of such parameters as the compactification degree
and the threshold value
(see expression (19)). To ensure a holistic perception of the material of the Section, the remaining parameters were borrowed from the previous experiment. The resulting dependencies are shown in
Figure 5.
4. Discussion
The research subject was chosen to reveal the characteristic features of the research object. This axiom works in all areas of science. Data analysis is no exception. There can be a huge, large, or small amount of data. The case with a small amount of data may be complicated by the fact that the source of the data, the process of its collection, or both, may not be under the researchers’ control. In this case, data scientists will have to work with small stochastic data. The mathematical apparatus presented in
Section 2.2 is focused on the problem of analyzing such data. Objective functions (15), and (22) implement the principle of maximum entropy formulated by Willard Gibbs in the context of compactification of (small) stochastic empirical data. Gibbs’ work says that the most characteristic probability distributions of the states of an uncertain object are distributions that maximize the chosen measure of uncertainty, taking into account the available reliable information about the investigated object. The effectiveness of this approach is demonstrated by the results presented in
Figure 1. Recall that, in this experiment, the compactification of extremely small data was carried out (the number of instances
in the data collection approached the number of attributes
n). From
Figure 1a,b, it can be seen that both the principal component analysis method (
Met1) and the random projection method (
Met2) demonstrated cases of non-functionality in situations when
m <
r, where
r was the desired number of attributes in the compactified collection. The author’s method (
Met3) remained functional under any requirements determined by the experiment.
As shown in
Figure 1, the results characterized the small empirical data compactification process:
m ≈
n,
, then the results presented in
Figure 2 show how the verification accuracy
α depends on the compactification of the initial data, for which
(a sufficient amount of empirical data,
Figure 2a) or
(“big” empirical data,
Figure 2b). From
Figure 2a, it can be seen that
of function
shows a monotonic linear character, in contrast to functions
and
. This circumstance indicates that it was the author’s method that made it possible to find the optimal configuration of the characteristic parameters space. Instead, the change of
in all functions
from
Figure 2b is characterized by a non-linear character. It can also be seen that, with
, it is the author’s compactification method
that generates the least informative parametric space in comparison with analogues. This fact can be explained by the fact that optimization method (18) does not have time to come close to the optimal distribution ensemble for the maximum number of iterations set of the algorithm (attribute
for the function
). The way out in such a situation can be the application of the approximate version of algorithm (18), represented by expressions (25).
Figure 3 demonstrates the dependence of the verification accuracy
α on the dynamics of such parameters as the compactification degree
r and the threshold value
(see expression (19)) of the completion of the iterative procedure (18). Let us notice that threshold
is also a parameter that determines the maximum allowable reduction of the information capacity for the compactification data matrix. The usefulness of parameter
lies in the fact that, based on its value, we can choose the permissible compaction degree
, not empirically (as, for example, in
) but analytically; if, after reducing the dimensionality of the dimension of the characteristic parameters to the value
, the estimate
has decreased too much, then the compactification process should be stopped and the algorithm should be rolled back to the previous value of
. This is exactly the behaviour we observe in
Figure 3a. Instead, as shown in
Figure 3b, the situation is not stable. The probable explanation for this is similar to the one we mentioned regarding
Figure 2b.
Figure 4 presents the calculated dependences of the relative share of information loss
on the compactification method
for datasets
with the corresponding ranges of changes in the compactification degree
r. It can be seen that it is the function
with the growth
r that grows significantly more slowly, surpassing competitors by almost two times. Note that this advantage was observed both for the “large” dataset
DS1 and for the “Big” dataset
DS2.
Figure 5 shows the relationship formalized by expression (19) between the relative share of information loss
and the dynamics of such parameters as the compactification degree
r and the threshold value
. It is interesting that, for the dataset
DS1 (
Figure 5a), all values of
r the condition
are fulfilled, that is, algorithm (18) managed to find optimal distributions without exceeding the set limit on the permissible number of iterations. On the other hand, the circumstances were different for the “Big” dataset
DS2. This can explain the unstable nature of the values presented in
Figure 5b.
In general, the results presented in
Section 3 prove both the functionality and the effectiveness of the mathematical apparatus presented in
Section 2 in comparison with classical analogues, namely, the principal component analysis method and the random projection method. The obvious advantage of the author’s method is the demonstrated stability of the small stochastic data compactification process and the possibility of analytical control of the loss of information capacity of the compactification data matrix. On the other hand, the disadvantage of the author’s method is the computational complexity, which is especially evident when processing large data matrices. However, to mitigate this limitation, the authors propose an approximating simplified version (25) of the basic compactification procedure (18).
To implement the cross-entropy version of the author’s compactification method, the method of conditional optimization on a non-negative orthant (CONNO) is adapted, and implemented in the scipy library. We note that, for some combinations of input data, the basic version of the CONNO method does not find a solution for the given optimization parameters. To test this concept, a series of experiments were adopted. The first series of experiments focused on identifying the dependence of classification accuracy on the number of objects (i.e., sample size). The study of this dependence for three compactification methods (PCA, RP, and author’s) is important to identify areas of their application. It is known that entropy maximization methods and their derivatives, in particular the author’s method, are usually used when the amount of data is limited compared to the dimension of the feature space. With “Big Data,” there are no fundamental restrictions on their use, but computational difficulties increase significantly. The next series of experiments was focused on identifying the dependence of classification accuracy in conditions where the number of measurements significantly exceeds the number of characteristic parameters. The next series of experiments was focused on identifying the dependence of classification accuracy for the author’s method on the acceptable reduction in the information capacity of the dataset. The next series of experiments was focused on assessing information losses from compactification implemented using and for the author’s method. The experiments described above have already been carried out and results that positively characterize the author’s method have been obtained. The problem is that, in its final form, the description, results obtained, and discussion are already more than 10 pages long. Increasing the size of this (already massive) article does not seem practical; therefore, if the mentioned experimental results interest you, dear reader, then I ask you to contact the corresponding author and he will be happy to share with you the results mentioned above.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}