1. Introduction
The popularization of the Internet has significantly increased the role of social platforms in people’s daily lives, serving as convenient channels for communication and information exchange [
1]. Consequently, the number of social platform users has grown, leading to an exponential increase in the volume of information data. However, this growth has also given rise to the pervasive issue of fake news dissemination on these platforms, irrespective of its authenticity. This phenomenon is driven by the platforms’ pursuit of rapid development rather than a commitment to truth [
2]. The spread of fake news poses a grave threat to information security and exerts a substantial influence on politics [
3], the economy [
4], and individuals’ well-being, resulting in immeasurable harm to society at large [
5].
During the 2018 presidential elections in Brazil, false news regarding candidate Fernando Adula Bosonaro circulated [
6]. These news articles claimed that Bosonaro’s opponent supported terrorism and abortion, leading to widespread misconceptions and prejudice against the opponent. In the same year, a fake news story about the Amazon rainforest fires spread rapidly on social media [
7]. The fake news claimed that the Amazon rainforest fires were caused by arson by environmental groups, and this false information misinformed the public about rainforest conservation and sparked many false discussions and accusations. Additionally, in 2017, fake news falsely claimed that a bitcoin exchange had been hacked [
8]. This resulted in a significant decline in the price of bitcoin, triggering panic among investors who hastily sold their bitcoins, thereby causing substantial volatility and losses within the bitcoin market.
As these problems have become more and more serious, research scholars have come up with ways to automatically detect fake news [
9,
10]. Initially, fake news detection primarily relied on textual content analysis [
11,
12,
13,
14]. However, as machine learning techniques advanced, support vector machines (SVM) were employed to identify fake news. It should be noted that SVMs alone may not fully capture the intricate relationships present in news texts [
15]. Furthermore, the naive Bayesian classifier was also utilized as a baseline model, serving a similar purpose to SVM [
16]. Subsequently, deep learning techniques gained prominence, with the aforementioned models becoming prevalent across various tasks. For instance, Goldani et al. [
17] successfully applied a capsule network, originally used in computer vision, to detect fake news. In a similar vein, Raza et al. [
18] integrated news content and contextual information using the Transformer architecture for detection. Notably, as the inclination to share news articles with images grew, researchers recognized the potential of incorporating visual elements in the detection process.
Scholars have embarked on investigating the detection of fake news in a multimodal manner. Giachanou et al. [
19] employed neural networks to integrate text, visual, and semantic components. They utilized pre-trained GoogleNews-vectors-negative word vector models and the lexicon of affective reasoning (VADER) to process textual information, while also incorporating image tagging and LBP for the visual aspect. Similarly, Xue et al. [
20] took into account the extrinsic and intrinsic characteristics of fake news and combines them with the overall consistency to identify the differences in their features, especially in the images where a branching network is designed to enhance their message. Additionally, Wu et al. [
21] capitalized on people’s news consumption habits by comparing text and images. They designed a two-layer co-attention mechanism for image–text information, employed VGG to model the latent features of images, employed CNN to process the frequency domain information of images, and used co-attention to fuse the frequency and latent domain information. Finally, they combined these features with BERT for fake news detection. However, all of these multimodal approaches overlooked the fact that news headlines also constitute textual content and failed to account for the presence of multiple images within a single news article. Consequently, these limitations have resulted in unsatisfactory detection outcomes.
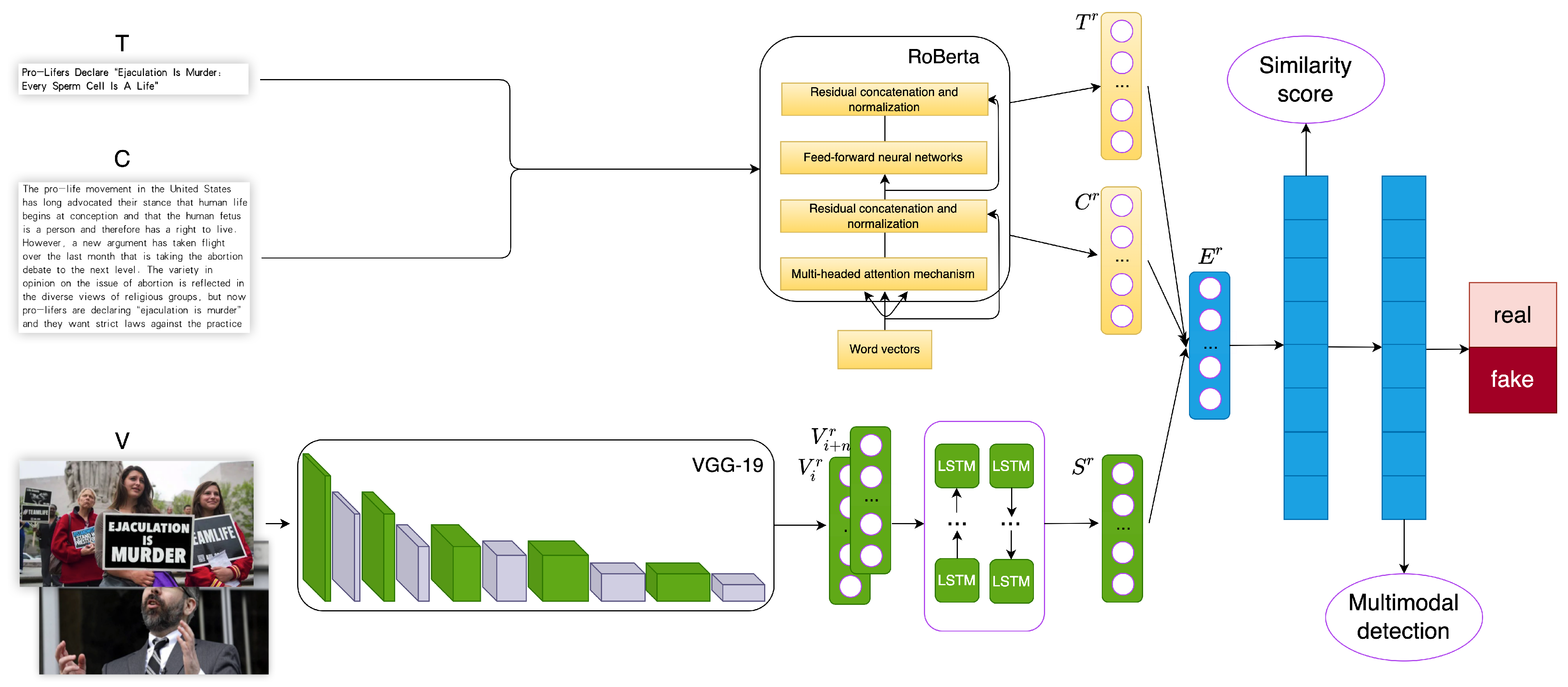
To address the following issues: (1) the limited utilization of multimodal information in unimodal detection, leading to unsatisfactory results; (2) the underutilization of multimodal information in recent multimodal detection approaches, such as neglecting headlines and multiple images; and (3) the simplistic fusion and detection of multimodal information without comprehensive consideration of matching distances between features, we propose an innovative model called the Three-Level Feature-Based Matching Distance Multimodal Fusion Model (TLFND). TLFND is based on RoBERTa [
22] for extracting two levels of text features (title and body) and VGG-19 for obtaining image features. We incorporate bidirectional long- and short-term memory (BILSTM) in image fusion to enhance the comprehensiveness of image features. Furthermore, we calculate the Chebyshev distance metric between the three features to determine the veracity of news, bringing them into a unified dimensional space. The model is optimized using a hinge loss function with a predefined threshold. Specifically, for true news with a label value of 0, we aim to maximize the distances, while for true news with a label value of 1, we strive to minimize the three-way distance below the threshold.
Based on the above contributions, the following summarization is presented:
Taking into account the strengths and weaknesses of previous research, we have developed an innovative model called TLFND (Three-Level Feature Similarity Distance-based Multimodal Fusion Model) for detecting fake news. This model effectively harnesses the power of news headlines, textual content, and multiple images to accurately identify fake news.
We propose an auxiliary task that uses the Chebyshev distance metric function as a distance metric between multiple modalities; calculates the distance to the center of mass using headlines, text, and fused images; optimizes the model using HingeEmbeddingLoss with set thresholds; and finally, designs an adaptive evolutionary algorithm to calculate the loss functions of the four components in order to detect false news more accurately.
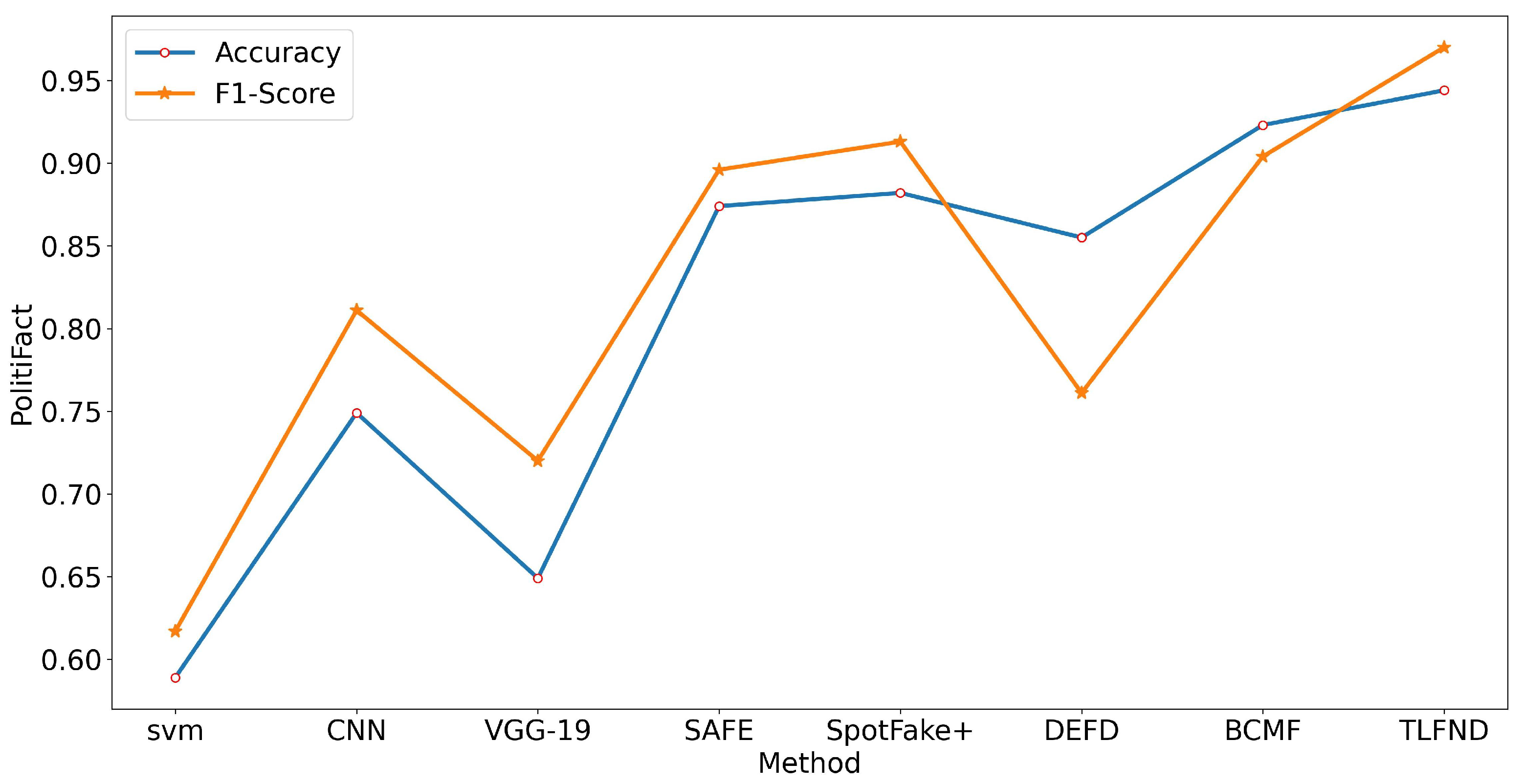
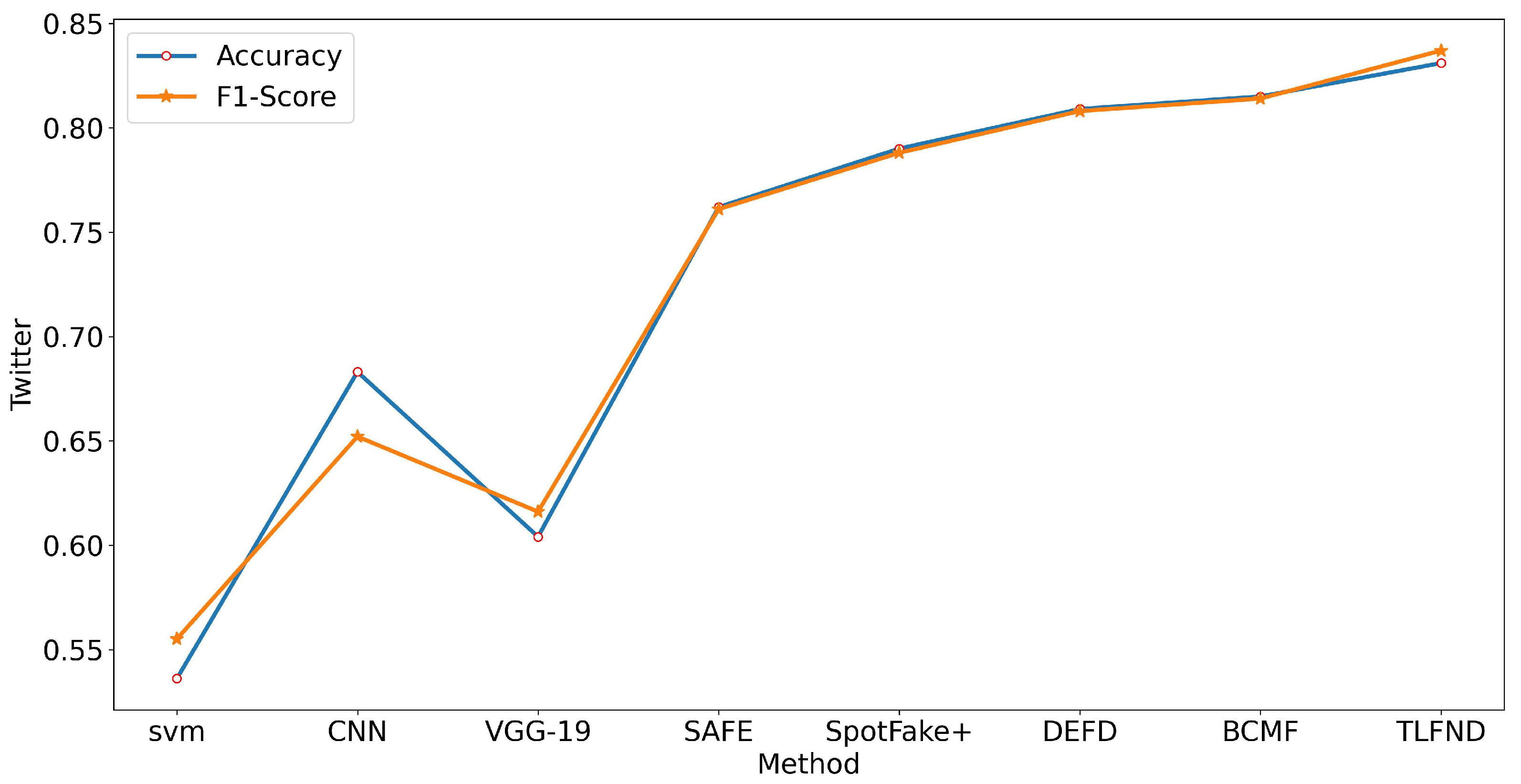
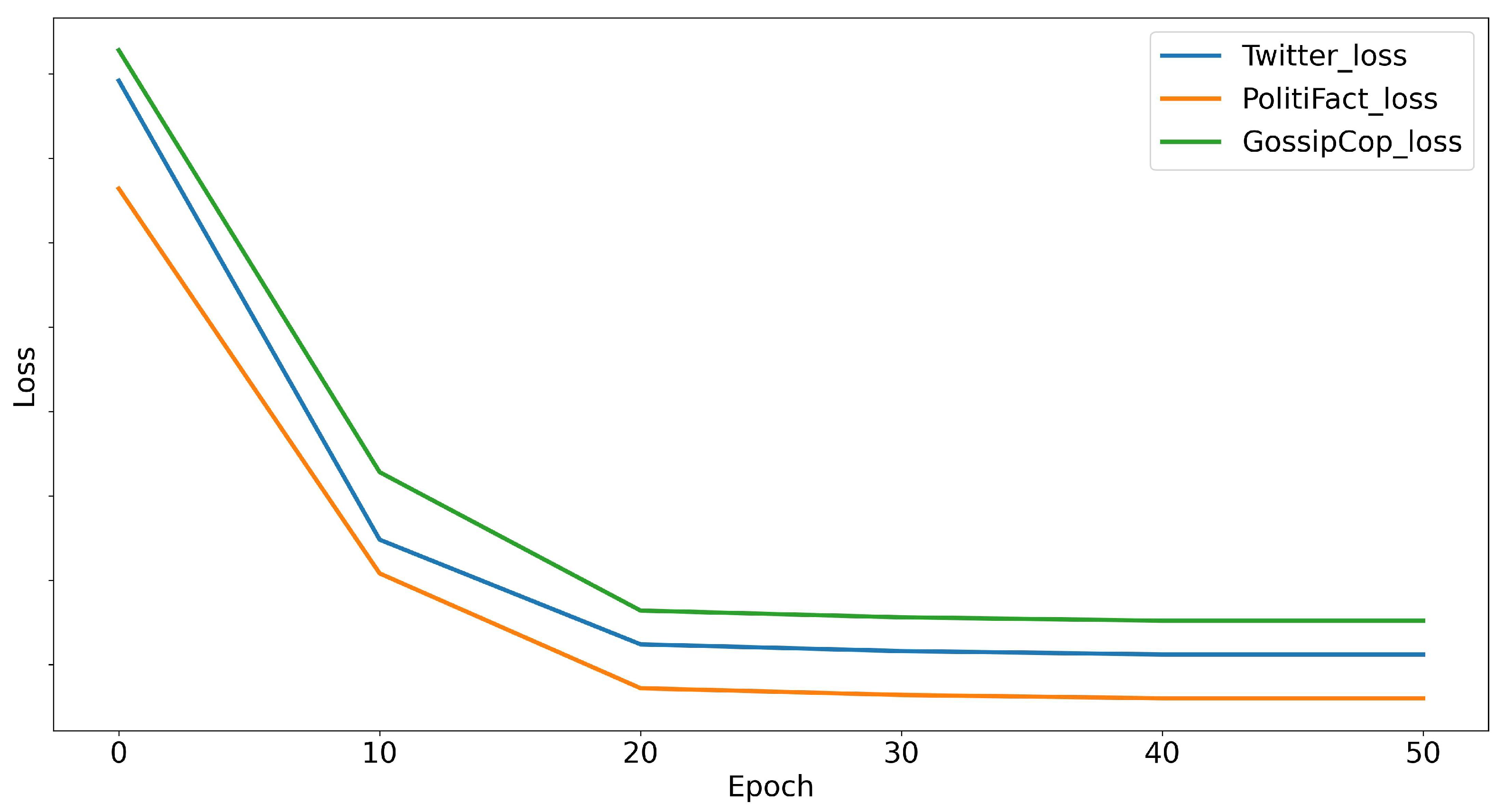
We conducted a comprehensive evaluation of the TLFND model using three widely used real-world datasets (PolitiFact, GossipCop, and Twitter). Through multiple sets of experiments and the incorporation of various evaluation metrics, our findings consistently demonstrated the superior performance of TLFND when compared to the current state-of-the-art multimodal fake news detection models.
The following sections of this paper are organized as follows: In
Section 2, we provide a comprehensive review of previous research efforts in the field of fake news detection.
Section 3 focuses on the symbolic representations used in this paper and discusses the structural framework of the TLFND model. In
Section 4, we delve into the various components of the TLFND model, providing detailed explanations of the technical aspects involved.
Section 5 presents the experimental setup, including the dataset, experimental parameters, baseline, and comparison results. Finally,
Section 6 concludes our study with a comprehensive summary of our findings.
3. Problem Statement
In this section, we discuss the symbolic representations utilized in this paper and describe the application process of the proposed TLFND model. In a news article, various components such as the title, content, image, and label (indicating true or false news) are present. We represent the collection of news articles as , the title as , the content as , the collection of images as , a single image in a news article as , and the label as . A false news article is denoted by , while a true news article is represented by .
To begin, we extract
features
and
features
using the RoBERTa model (described in
Section 4.1). Subsequently, we extract individual
features
using the pre-trained VGG-19 model (described in
Section 4.2). Afterward, we fuse the multiple
features into
in a BILSTM model operating in two opposite directions (described in
Section 4.2). Next, we concatenate
,
, and
to create a multimodal feature vector denoted as
. Finally, we input
and
into the matching distance calculation module (described in
Section 4.3).
6. Conclusions
To enhance the performance of multimodal methods in fake news detection tasks, we propose a groundbreaking model called TLFND. This model is based on the RoBERTa and VGG-19 models, combining their strengths to create a powerful fake news detection system. The TLFND model comprises four components: a two-level text feature extraction module, an extracted and fused image module, a three-level feature matching distance module, and a multimodal integrated recognition module. Compared to existing multimodal models, the TLFND model takes a significant step forward by considering two types of text: headlines and body text. It effectively fuses these text sources with multiple news images using BILSTM, resulting in a comprehensive understanding of the news content. Additionally, we introduce the Chebyshev distance metric for the first time, enabling accurate calculation of the matching distance between the three distinct features. To optimize the model’s performance, we employ an adaptive evolutionary algorithm. This algorithm computes the loss values of the four components, facilitating parameter optimization and learning through feedback signals. The TLFND model evolves and improves iteratively, delivering superior performance in fake news detection. We evaluated the TLFND model on three real-world public datasets, and the experimental results demonstrate its superiority. In all four metrics, the TLFND model outperforms other approaches, securing the top position. This achievement showcases the practical application of the TLFND model in the crucial task of binary false news detection, effectively countering the spread and impact of false information. Moreover, the TLFND model serves as a valuable reference for researchers in the field and holds potential for broader applications in various domains.
Looking ahead, our future research efforts will focus on adapting the TLFND model to different domains and conducting extensive testing and refinement to enhance its effectiveness and technical details. By continuously improving the model, we aim to make meaningful contributions to society’s fight against fake news.



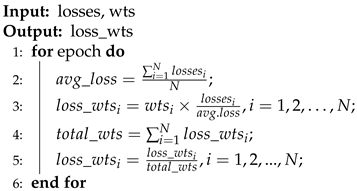


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}