1. Introduction
Many problems of information theory involve the action of a noise operator on a code distribution, transforming it into some other distribution. For instance, one can think of Bernoulli noise acting on a code in the Hamming space or Gaussian noise acting on a lattice in the Euclidean space. We are interested in characterizing the cases when the output distribution is close to the uniform distribution on the space. Versions of this problem have been considered under different names, including resolvability [
1,
2,
3], smoothing [
4,
5], discrepancy [
6,
7], and the entropy of noisy functions [
8,
9,
10]. Direct applications of smoothing include secrecy guarantees in both the binary symmetric wiretap channel [
2,
3,
11] and the Gaussian wiretap channel [
12,
13], error correction in the binary symmetric channel (BSC) [
14,
15], converse coding theorems of information theory [
1,
16,
17,
18], strong coordination [
11,
19,
20,
21,
22], secret key generation [
13,
23], and worst-to-average case reductions in cryptography [
5,
24]. Some aspects of this problem also touch upon approximation problems in statistics and machine learning [
25,
26,
27].
Our main results are formulated for the smoothing in the binary Hamming space
. For
, and
define
as the action of
r on the functions on the space. We set
r to be a probability mass function (pmf) and call the function
the
noisy version of
f with respect to
r, and refer to
r and
as a
noise kernel and a
noise operator, respectively. By
smoothing f with respect to
r, we mean applying the noise kernel
r to
f. We often assume that
is a radial kernel, i.e., its value on the argument
depends only on the Hamming weight of
x.
There are several ways to view the smoothing operation. Interpreting it as a shift-invariant linear operator, we note that, from Young’s inequality, so smoothing contracts the -norm. Upon applying , the noisy version of f becomes “flatter”; hence, the designation “smoothing”. Note that if f is a pmf, then is also a pmf, and so this view allows us to model the effect of communication channels with additive noise.
The class of functions that we consider are (normalized) indicators of subsets (codes) in . A code defines a pmf and, thus, can be viewed as a noisy version of the code (we also sometimes call it a noisy distribution) with respect to the kernel r. The main question of interest for us is the proximity of this distribution to or the “smoothness” of the noisy code distributions. To quantify closeness to , we use the Kullback–Leibler (KL) and Rényi divergences (equivalently, norms), and the smoothness measured in is termed the -smoothness (-smoothness).
We say that a code is
perfectly smoothable with respect to the noise kernel
r if the resultant noisy distribution becomes uniform. Our main emphasis is on the asymptotic version of perfect smoothing and its implications for some of the basic information-theoretic problems. A sequence of codes
is asymptotically smoothed by the kernel sequence
if the distance between
and
approaches 0 as
n increases. This property is closely related to the more general problem of
channel resolvability introduced by Han and Verdú in [
1]. Given a discrete memoryless channel
and a distribution
, we observe a distribution
on the output of the channel. The task of channel resolvability is to find
supported on a subset
that approximates
with respect to the KL divergence. As shown in [
1], there exists a threshold value of the rate such that it is impossible to approximate
using codes of lower rate, while any output process can be approximated by a well-chosen code of a rate larger than the threshold. Other proximity measures between distributions were considered for this problem in [
3,
28,
29]. Following the setting in [
3], we consider Rényi divergences for measuring the closeness to uniformity. We call the minimum rate required to achieve perfect asymptotic smoothing the
-smoothing capacity of the noise kernels
, where the proximity to uniformity is measured by the
-Rényi divergence. In this work, we characterize the
-smoothing capacity of the sequence
using its Rényi entropy rate.
Asymptotic smoothing. We will limit ourselves to studying smoothing bounds under the action of the Bernoulli noise or ball noise kernels, defined formally below. A common approach to deriving bounds on the norm of a noisy function is through hypercontractivity inequalities [
30,
31,
32]. In its basic version, given a code
of size
M, it yields the estimate
where
is the Bernoulli kernel (see
Section 2 for formal definitions) and
. This upper bound does not differentiate codes yielding higher or lower smoothness, which in many situations may not be sufficiently informative. Note that other tools, such as “Mrs. Gerber’s lemma” [
30,
33] or strong data-processing inequalities, also suffer from the same limitation.
A new perspective of the bounds for smoothing has recently been introduced in the works of Samorodnitsky [
8,
9,
10]. Essentially, his results imply that codes satisfying certain regularity conditions have good smoothing properties. Their efficiency is highlighted in recent papers [
14,
34], which leveraged results for code performance on the binary erasure channel (BEC) to prove strong claims about the error correction capabilities of the codes when used on the BSC. Using Samorodnitsky’s inequalities, we show that the duals of some BEC capacity-achieving codes achieve
-smoothing capacity for
with respect to the Bernoulli noise. This includes the duals of polar codes and doubly transitive codes, such as the Reed–Muller (RM) codes.
Smoothing and the wiretap channel. Wyner’s wiretap channel [
35] models communication in the presence of an eavesdropper. Code design for this channel pursues reliable communication between the legitimate parties, while at the same time leaking as little information as possible about the transmitted messages to the eavesdropper. The connection between secrecy in wiretap channels and resolvability was first mentioned by Csiszár [
36] and later developed by Hayashi [
2]. It rests on the observation that to achieve secrecy it suffices to make the distribution of an eavesdropper’s observations conditioned on the transmitted message nearly independent of the message. The idea of characterizing secrecy based on smoothness works irrespective of the measure of secrecy [
2,
3,
11], and it was also employed for nested lattice codes used over the Gaussian wiretap channel in [
12].
Secrecy on the wiretap channel can be defined in two ways, measured by the information gained by the eavesdropper, and it depends on whether this quantity is normalized to the number of channel uses (weak secrecy) or not (strong secrecy). This distinction was first highlighted by Maurer [
37], and it has been adopted widely in the recent literature. Early papers devoted to code design for the wiretap channel relied on random codes, but, for simple channel models such as BSC or BEC, this has changed with the advent of explicit capacity-approaching code families. Weak secrecy results based on LDPC codes were presented in [
38], but initial attempts to attain strong secrecy encountered some obstacles. To circumvent this, the first works on code construction [
39,
40] had to assume that the main channel is noiseless. The problem of combining strong secrecy and reliability for general wiretap channels was resolved in [
41], but that work had to assume that the two communicating parties share a small number of random bits unavailable to the eavesdropper. Apart from the polar coding scheme of [
41], explicit code families that support reliable communication with positive rate and strong secrecy have not previously appeared in the literature. In this work, we show that nested RM codes perform well in binary symmetric wiretap channels based on their smoothing properties. While our work falls short of proving that nested RM codes achieve capacity, we show that they can transmit messages reliably and secretly at rates close to capacity.
Ball noise and decoding error. Ball-noise smoothing provides a tool for estimating the error probability of decoding on the BSC. We derive impossibility and achievability bounds for the
-smoothness of noisy distributions with respect to the ball noise. Smoothing of a code with respect to the
norm plays a special role because, in this case, the second norm (the variance) of the resulting distribution can be expressed via the pairwise distance between codewords, enabling one to rely on tools from Fourier analysis. The recent paper by Debris-Alazard et al. [
4] established universal bounds for the smoothing of codes or lattices, with cryptographic reductions in mind. The paper by Sprumont and Rao [
15] addressed bounds for error probability of list decoding at rates above BSC capacity. A paper by one of the present authors [
42] studied the variance of the number of codewords in balls of different radii (a quantity known as the quadratic discrepancy [
43,
44]).
The main contributions of this paper are the following:
Characterizing the -smoothing capacities of noise operators on the Hamming space for .
Identifying some explicit code families that attain a smoothing capacity of the Bernoulli noise for ;
Obtaining rate estimates for the RM codes used on the BSC wiretap channel under the strong secrecy condition;
Showing that codes possessing sufficiently good smoothing properties are suitable for error correction.
In
Section 2, we set up the notation and introduce the relevant basic concepts. Then, in
Section 3, we derive expressions for the
-smoothing capacities for
, and in
Section 4, we use these results to analyze the smoothing of code families under the action of the Bernoulli noise.
Section 5 is devoted to the application of these results for the binary symmetric wiretap channel. In particular, we show that RM codes can achieve rates close to the capacity of the BSC wiretap channel, while at the same time guaranteeing strong secrecy. In
Section 6, we establish threshold rates for smoothing under ball noise, and derive bounds for the error probability of decoding on the BSC, including the list case, based on the distance distribution. Concluding the paper,
Section 7 briefly points out that the well-known class of uniformly packed codes are perfectly smoothable with respect to “small” noise kernels.
3. Perfect Smoothing—The Asymptotic Case
For a given family of noise kernels , there exists a threshold rate such that it is impossible to approximate uniformity with codes of rate below the threshold irrespective of the chosen code, while at the same time, there exist families of codes with a rate above the threshold that allows perfect approximation in the limit of infinite length. For instance, for the Bernoulli noise applied to a code , the smoothed distribution is nonuniform unless or . At the same time, it is possible to approach the uniform distribution asymptotically for large n once the code sequence satisfies certain conditions. Intuitively, it is clear that, for a fixed noise kernel, it is easier to approximate uniformity if the code rate is sufficiently high. In this section, we characterize the threshold rate for (asymptotically) perfect smoothing. Of course, the threshold also depends on the proximity measure that we are using. In this section, we use perfect smoothing to mean “asymptotically perfect”. If the proximity measure for smoothing is not specified, this means that we are using the KL divergence. We obtain the threshold rates for perfect smoothing measured with respect to the -divergence for several values of . In the subsequent sections, we work out the details for the Bernoulli and ball noise operators, which also have some implications for communication problems.
Definition 1. Let be a sequence of codes of increasing length n and let We say that the sequence is asymptotically perfectly -smoothable with respect to the noise kernels ifor equivalently (7) and (8) if One can also define a dimensionless measure for perfect asymptotic smoothing by considering the limiting process
Proposition 1. Convergence in (13) implies perfect smoothing for all and is equivalent to it for Proof. Let
for some fixed
n. Since by the triangle inequality,
(
13) is not weaker than the mode of convergence in Definition 1 for all
. For
, we use Clarkson’s inequalities ([
45], p. 388). Their form depends on
; namely, for
, we have
For
, the inequality has the form
where
is the Hölder conjugate. These equations show that, for
,
implies
establishing the claimed equivalence. □
Definition 2. Let be a sequence of noise kernels. We say that the rate R is achievable for perfect -smoothing if there exists a sequence of codes such that as and is perfectly -smoothable.
Note that if is achievable, then any rate is also achievable. Indeed, consider a (linear) code of rate that has good smoothing properties. Construct by taking the union of non-overlapping shifts of . Then the rate of is , and since each shift has good smoothing properties, the same is true for . Therefore, let us define the main concept of this section.
Definition 3. Given a sequence of kernels , define the -smoothing capacity as Note that this quantity is closely related to the resolvability: if, rather than optimizing on the output process in (
12), we set the output distribution to uniform and take
then
equals
for the channel
given by the noise kernel
To avoid future confusion, we refer to the capacity of reliable transmission as Shannon’s capacity.
The following lemma provides a lower bound for
-smoothness. It follows from Lemma 2 in [
3], and we give a direct proof for completeness.
Lemma 1. Let be a code of size and let r be a noise kernel. Then, for Proof. We will first prove that
for
:
Together with (
7), this implies that the claimed inequality holds for
.
A similar calculation shows that for , yielding the claim for . The limiting cases , , and follow by continuity of and for all □
Define
Lemma 1 shows that it is impossible to achieve perfect
-smoothing if
A question of interest is whether there exist sequences of codes of
that achieve perfect
-smoothing. The next theorem shows that this is the case for
.
Theorem 3. Let be a sequence of noise kernels and let . Then, The proof relies on a random coding argument and is given in
Appendix B. This result will be used below to characterize the smoothing capacity of the Bernoulli and ball noise operators.
Remark 2. Equality (16) does not hold in the case . From Theorem 4 below, the Bernoulli noise does not satisfy (16) for . To construct a counterexample for , consider the noise kernel that is almost uniform except for one distinguished point, for instance, for and Performing the calculations, we then obtain that while Remark 3. It is worth noting that is a decreasing function of α for
4. Bernoulli Noise
In this section, we characterize the value for a range of values of . Then, we provide explicit code families that attain the -smoothing capacities.
As already mentioned, the resolvability for
with respect to
-divergence was considered by Yu and Tan [
3]. Their results, stated in Corollary 1, yield an expression for
for
. The next theorem summarizes the current knowledge about
where the claims for
form new results.
Proof. The claims for follow from Corollary 1. The results for follow from Theorem 3 since . □
Having quantified the smoothing capacities, let us examine the code families with strong smoothing properties. Since the -smoothing capacity and the Shannon capacity coincide, it is natural to speculate that codes that achieve the Shannon capacity when used on the BSC would also attain the -smoothing capacity. However, the following result demonstrates that the capacity-achieving codes do not yield perfect smoothing. For typographical reasons, we abbreviate by from this section onward.
Proposition 2. Let be a sequence of codes achieving a capacity of . Then, Proof. The second part of the statement is Theorem 2 in [
46]. The first part is obtained as follows: Let
be a capacity-achieving sequence of codes in
. Then, from [
47] (Theorem 49), there exists a constant
such that
for large
n. Therefore,
which implies
. □
Apart from random codes, only polar codes are known to achieve
-smoothing capacity. Before stating the formal result, recall that polar codes are formed by applying several iterations of a linear transformation to the input, which results in creating virtual channels for individual bits with Shannon’s capacity close to zero or to one, plus a vanishing proportion of intermediate-capacity channels. While by Proposition 2, that polar codes that achieve the BSC capacity cannot achieve
-smoothing capacity, adding some intermediate-bit channels to the set of data bits makes this possible. This idea was first introduced in [
39] and expressed in terms of resolvability in [
48].
Theorem 5 ([
48], Proposition 1).
Let be the channel and be the virtual channels formed after applying n steps of the polarization procedure. For , define . Let be the polar code corresponding to the virtual channels . Then, . Note that . Hence, the polar code construction presented above achieves the perfect smoothing threshold with respect to the KL divergence. Furthermore, since the convergence in the divergence for is weaker than the convergence in , the same polar code sequence is perfectly -smoothable for . Noting that the smoothing threshold for is by Theorem 4, we conclude that the above polar code sequence achieves smoothing capacity in -divergence for .
As mentioned earlier, the smoothing properties of code families other than random codes and polar codes have not been extensively studied. We show that the duals of capacity-achieving codes in the BEC exhibit good smoothing properties using the tools developed in [
10]. As the first step, we establish a connection between the smoothing of a generic linear code and the erasure correction performance of its dual code.
Lemma 2. Let be a linear code and let be a random uniform codeword of . Let be the output of the erasure channel for the input . Then,where for and for . Using this lemma, we show that the duals of the BEC capacity-achieving codes (with growing distance) exhibit good smoothing properties. In particular, they achieve -smoothing capacities for .
Theorem 6. Let be a sequence of linear codes with rate . Suppose that the dual sequence achieves Shannon’s capacity of the BEC with , and assume that If , then,Additionally, for , if , then,In particular, the sequence achieves -smoothing capacity for . Proof. Since the dual codes achieve the capacity of the BEC, it follows from ([
49], Theorem 5.2) that, if their distance grows with
n, then their decoding error probability vanishes. In particular, if
then,
for all
Hence, from Fano’s inequality,
Now, if
, then there exists
such that
. Therefore, from Lemma 2,
Similarly,
Together with Theorem 4, we have now proved the final claim. □
The known code families that achieve the capacity of the BEC include polar codes, LDPC codes, and doubly transitive codes, such as constant-rate RM codes. LDPC codes do not fit the assumptions because of low dual distance, but the other codes do. This yields explicit families of codes that achieve the -smoothing capacity.
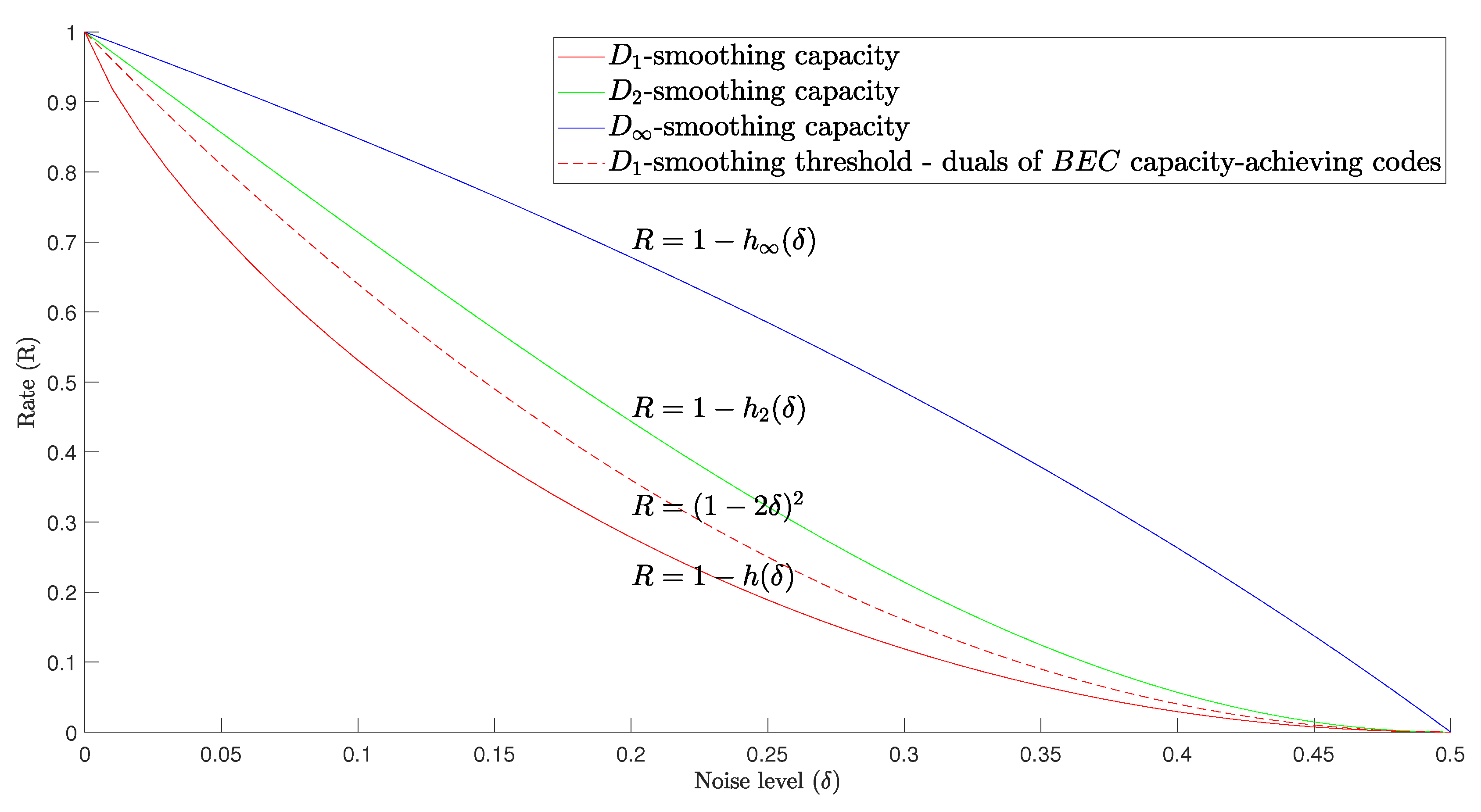
We illustrate the results of this section in
Figure 1, where the curves show the achievability and impossibility rates for perfect smoothing with respect to the Bernoulli noise. Given a code (sequence) of rate
R, putting it through a noise
below the Shannon capacity cannot achieve perfect smoothing. The sequence of polar codes from [
39], cited in Theorem 5, is smoothable at rates equal to the Shannon capacity, although these codes do not provide a decoding guarantee at that noise level. At the second curve from the bottom, the duals of the codes that achieve Shannon’s capacity in BEC achieve perfect
-smoothing; at the third (fourth) curve, these codes are perfectly
- (or
-) smoothable, and they achieve the corresponding smoothing capacity.
Remark 4. Observe that the strong converse of the channel coding theorem does not imply perfect smoothing. To give a quick example, consider a code formed of all the vectors in the ball. Let and let us use this code on a BSC, where and . From the choice of the parameters, the rate of is above capacity, and, therefore, from the strong converse. At the same time,where the transition from the ball noise to the Bernoulli noise (the second equality) is shown in [30]. Since for all we conclude that Remark 5. In this paper, we mostly study the trade-off between the rate of codes and the level of the noise needed to achieve perfect smoothing. A recent work of Debris-Alazard et al. [4] considered guarantees for smoothing derived from the distance distribution of codes and their dual distance (earlier, similar calculations were performed in [42,50]). Our approach enables us to find the conditions for perfect smoothing similar to [4] but relying on fewer assumptions. Proposition 3. Let be a sequence of codes whose dual distance where . If , then, Proof. Notice that if . With this, the proof is a straightforward application of Lemma 2. □
Compared to [
4], this claim removes the restrictions on the support of the dual distance distribution of the codes
5. Binary Symmetric Wiretap Channels
In this section, we discuss applications of perfect smoothing to the BSC wiretap channel. Wyner’s wiretap channel model
[
35] for the case of BSCs is defined as follows: The system is formed of three terminals,
and
E. Terminal
A communicates with
B by sending messages
M chosen from a finite set
. Communication from
A to
B occurs over a BSC
with crossover probability
, and it is observed by the eavesdropper
E via another BSC
with crossover probability
A message
is encoded into a bit sequence
and sent from
A to
B in
n uses of the channel
Terminal
B observes the sequence
where
is the noise vector, while terminal
E observes the sequence
with
. We assume that the messages are encoded into a subset of
which imposes some probability distribution on the input of the channels. The goal of the encoding is to ensure reliability and secrecy of communication. The reliability requirement amounts to the condition
as
, where
is the estimate of
M made by
B. To ensure secrecy, we require the
strong secrecy condition . This is in contrast to the condition
studied in the early works on the wiretap channel, which is now called weak secrecy. Denote by
the transmission rate. The
secrecy capacity is defined as the supremum of the rates that permit reliable transmission, which also conforms to the secrecy condition.
The nested coding scheme, proposed by Wyner [
35], has been the principal tool of constructing well-performing transmission protocols for the wiretap channel [
38,
39,
41]. To describe it, let
and
be two linear codes such that
and
. We assign each message
m to a unique coset of
in
. The sequence transmitted by
A is a uniform random vector from the coset. As long as the rate of the code
is below the capacity of
, we can ensure the reliability of communication from
A to
B.
Strong secrecy can be achieved relying on perfect smoothing. Denote by a leader of the coset that corresponds to the message m. The basic idea is that if is close to a uniform distribution for all m, these conditional pmfs are almost indistinguishable from each other, and terminal E has no means of inferring the transmitted message from the observed bit string Z.
As mentioned earlier, the weak secrecy results for the wiretap channel based on LDPC codes and on polar codes were presented in [
38,
39], respectively. The problem that these schemes faced, highlighted in Theorems 2 and 5, is that code sequences that achieve BSC capacity have a rate gap of at least
to the capacity value. At the same time, the rate of perfectly smoothable codes must exceed the capacity by a similar quantity [
51]. For this reason, the authors of [
39] included the intermediate virtual channels in their polar coding scheme, which gave them strong secrecy, but interfered with transmission reliability. A similar general issue arose earlier in attempting to use LDPC codes for the wiretap channel [
40].
Contributing to the line of work connecting smoothing and thewiretap channel [
2,
3,
11], we show that nested coding schemes
where the code
is good for error correction in
and
is perfectly smoothable with respect to
, attain strong secrecy and reliability for a BSC wiretap channel
. As observed in Lemma 2, the duals of the good erasure-correcting codes are perfectly smoothable for certain noise levels and, hence, they form a good choice for
in this scenario.
The following lemma establishes a connection between the smoothness of a noisy distribution of a code and strong secrecy.
Lemma 3. Consider the nested coding scheme for the BSC wiretap channel introduced above. If then
Proof. We have
Now, note that
so
is independent of
m. Therefore, for all
This lemma enables us to formulate conditions for reliable communication while guaranteeing the strong secrecy condition. Namely, it suffices to take a pair (a sequence of pairs) of nested codes such that as If at the same time the code corrects errors on a BSC then the scheme fulfills both the reliability and strong secrecy requirements under noise levels and for channels and , respectively, supporting transmission from A to B at rate . Together with the results established earlier, we can now make this claim more specific.
Theorem 7. Let and be sequences of linear codes that achieve the capacity of the BEC for their respective rates. Suppose that and
- 1
;
- 2
.
If and , then the nested coding scheme based on and can transmit messages with rate from A to B, satisfying the reliability and strong secrecy conditions.
Proof. From Corollary A1, the conditions and guarantee transmission reliability. Furthermore, by Theorem 6, the conditions and imply that , which in its turn implies strong secrecy by Lemma 3. □
To give an example of a code family that satisfies the assumptions of this theorem, consider the RM codes of constant rate. Namely, let
be two sequences of RM codes whose rates converge to
and
, respectively. Note that the duals of the RM codes are themselves RM codes. By a well-known result [
52], the RM codes achieve the capacity of the BEC, and for any sequence of constant-rate RM codes, the distance scales as
. Therefore, the RM codes satisfy the assumptions of Theorem 7.
Note that for the RM codes, we can obtain a stronger result, based on their error correction properties on the BSC. Involving this additional argument brings them closer to the secrecy capacity under the strong secrecy assumption.
Theorem 8. Let and be two sequences of RM codes satisfying whose rates approach and respectively. If and , then the nested coding scheme based on and supports transmission on a BSC wiretap channel with rate guaranteeing communication reliability and strong secrecy.
Proof. Very recently, Abbe and Sandon [
53], building upon the work of Reeves and Pfister [
54], proved that RM codes achieve capacity in symmetric channels. Therefore, the condition
guarantees reliability. The rest of the proof is similar to that of Theorem 7. □
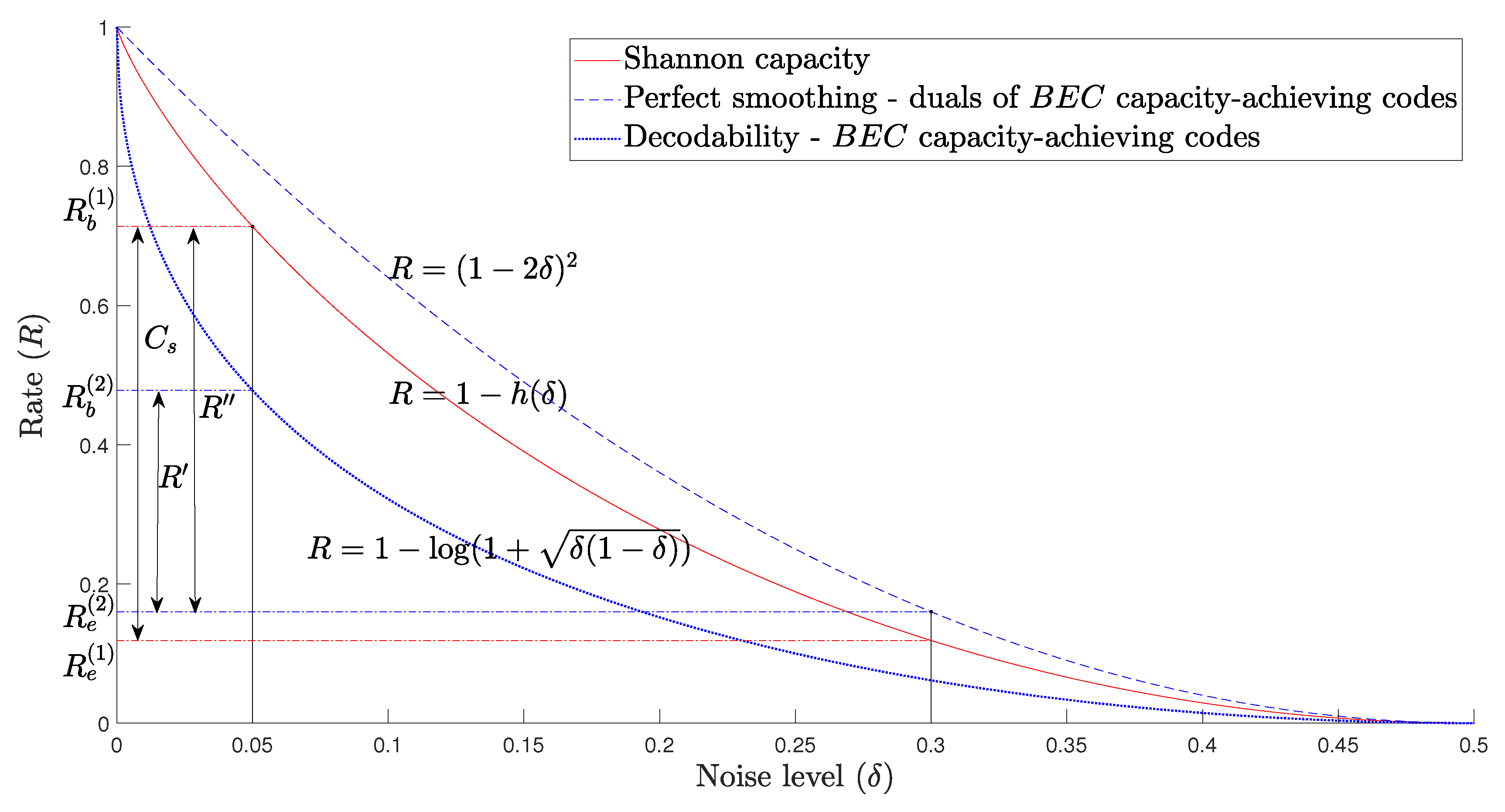
Theorems 7 and 8 stop short of constructing codes that attain the secrecy capacity of the channel (this is similar to the results of [
14] for the transmission problem over the BSC). To quantify the gap to capacity, we plot the smoothing and decodability rate bounds in
Figure 2.
As an example, let us set the noise parameters
and
and denote the corresponding secrecy capacity by
. Suppose that we use a BEC capacity-achieving code as code
and a dual of a BEC capacity-achieving code as code
in the nested scheme. The value
is the largest rate at which we can guarantee both reliability and strong secrecy. In the example in
Figure 2,
and
. The only assumption required here is that the codes
and
have good erasure correction properties.
As noted, generally, the RM codes support a higher communication rate than the . Let be their achievable rate. For the same noise parameters as above, we obtain which is closer to than .
Remark 6. The fact that the RM codes achieve capacity in symmetric channels immediately implies that nested RM codes achieve the secrecy capacity in the BSC wiretap channel under weak secrecy. While it is tempting to assume that, coupled with the channel duality theorems of [55,56], this result also implies that RM codes fulfil the strong secrecy requirement on the BSC wiretap channel, an immediate proof looks out of reach [57]. Secrecy from -Divergence
Classically, the (strong) secrecy in the wiretap channel is measured by
. In [
11], slightly weaker secrecy measures were considered besides the mutual information. However, more stringent secrecy measures may be required in certain scenarios;
-divergence-based secrecy measures were introduced by Yu and Tan [
3] as a solution to this problem.
Observe that the secrecy measured by
for
is stronger than the mutual-information-based secrecy. This is because for
Given a wiretap channel with an encoding-decoding scheme, we say the
-secrecy is satisfied if
The following theorem establishes that it is possible to achieve the rate with RM codes for .
Theorem 9. Let . Let and be two sequences of RM codes satisfying whose rates approach and respectively. If and , then the nested coding scheme based on and supports transmission on a BSC wiretap channel guaranteeing α-secrecy with rate provided that .
Evidently, to achieve a stringent version of secrecy, it is necessary to reduce the rate of the message. The capacity of the -wiretap channel is , while the known highest rate that assures -secrecy and reliability is . Hence, to achieve -secrecy, we must give up of the attainable rate.
6. Ball Noise and Error Probability of Decoding
This section focuses on achieving the best possible smoothing with respect to the ball noise. As an application, we show that codes that possess good smoothing properties with respect to the ball noise are suitable for error correction in the BSC.
6.1. Ball Noise
Recall that the perfect smoothing of a sequence of codes is only possible if the rate is greater than the corresponding -smoothing capacity. In addition to characterizing the -smoothing capacities of the ball noise, we quantify the best smoothing one can expect with rates below the -smoothing capacity. We will use these results in the upcoming subsection when we derive upper bounds for the decoding error probability on a BSC. The next theorem summarizes our main result on smoothing with respect to the ball noise.
Theorem 10. Let be the sequence of ball noise operators, where is the radius of the ball. Let Let be a code of length n and rate Then, we have the following bounds:There exist sequences of codes of rate that achieve asymptotic equality in (19) for all At the same time, if , then there exist sequences of codes achieving asymptotic equality in (20). Proof. The inequality in (
19) is trivial. Let us prove that asymptotically it can be achieved with equality. From Theorem 3, there exists a sequence of codes
such that
given that
. Hence, for
Hence, the equality case in (
19) is achievable for all
.
Let us prove (20). From Lemma 1, we have
because
.
We are left to show that for
(20) can be achieved with equality in the limit of large
n. We use a random coding argument to prove this. Let
be an
code whose codewords are chosen independently and uniformly. In Equation (
A6),
Appendix B, we define the expected norm of the noisy function. Here, we use this quantity for the ball noise kernel. For
, define
From Lemma A2, for any rational
,
for
such that
.
Assume that
. Let us prove that
for rational values of
using induction. Let
be rational and note that
. Since
when the argument is less than 1, we can write (
21) as follows:
Now, assume that (
21) holds for all rational
for some integer
and prove that, in this case, it holds also for
By the induction hypothesis,
Therefore, for every rational
, there exists a sequence of codes satisfying
which is equivalent to the equality in (20).
Let us extend this result to non-negative reals. Let
and let us choose a rational
such that
. We know that there exists a sequence of codes satisfying
From (20) and from Remark 1,
Hence, the asymptotic equality in (20) is achievable for all
. □
The above theorem characterizes the -smoothing capacities with respect to ball noise.
Corollary 2. Let . Let be a sequence of ball noise operators, where is the radius corresponding to the n-th kernel. Then, The norms of can be used to bound the decoding error probability on a BSC. While estimating these norms for a given code is generally complicated, the second norm affords a compact expression based on the distance distribution of the code. In the next section, we bound the decoding error probability using the second norm of . The following proposition provides closed-form expressions for .
Proposition 4. where is defined in (1) and is the Lloyd polynomial of degree t (A2). The proof is immediate from Proposition A1 in combination with (
A2) and (
A4).
6.2. Probability of Decoding Error on a BSC
The idea that the smoothing of codes under some conditions implies good decoding performance has appeared in a number of papers using different language. The smoothing of capacity-achieving codes was considered in [
18,
46]. Hązła et al. [
14] showed that if a code (sequence) is perfectly smoothable with respect to the Bernoulli noise, then the dual code is good for decoding (see Theorem A4, Corollary A1). Going from smoothing to decodability involves representing the
-smoothness of codes with respect to the Bernoulli noise as a potential energy form and comparing it to the Bhattacharyya bound for the dual codes. One limitation of this approach is that it cannot infer decodability for rates
(this is the region above the blue solid curve in
Figure 2). Rao and Sprumont [
15] and Hązła [
34] proved that sufficient smoothing of codes implies the decodability of the codes themselves rather than their duals. However, these results are concerned with list decoding for rates above the Shannon capacity, resulting in an exponential list size, which is arguably less relevant from the perspective of communication.
Except for [
15], the cited papers utilize perfect or near-perfect smoothing to infer decodability. For codes whose rates are below the capacity, perfect smoothing is impossible. At the same time, codes that possess sufficiently good smoothing properties are good for decoding. This property is at the root of the results for list decoding in [
15]; however, their bounds were insufficient to make conclusions about list decoding below capacity.
Consider a channel where, for the input , the output Y is given by with . Define as the number of codewords in the ball . Hence, for a received vector y, the possible number of codewords that can yield y is given by . Intuitively, the decoding error is small if for typical errors. Therefore, is of paramount interest in decoding problems. Since the typical errors for both ball noise and the Bernoulli noise are almost the same, this allows us to obtain a bound for decodability in the BSC channel. Using this approach, we show that the error probability of decoding on a can be expressed via the second moment of the number of codewords in the ball of radius .
Assume, without loss of generality, that is a linear code and is used for transmission. Let Y be the random Bernoulli vector of errors, and note that . The calculation below does not depend on whether we rely on unique or list decoding within a ball of radius t, so let us assume that the decoder outputs candidate codewords conditioned on the received vector y, which is a realization of
In this case, the list decoding error can be written as
Theorem 11. Let t and be integers such that . Then, for any Proof. Define
. Clearly,
Let us estimate the first of these probabilities.
Remark 7. In the case of , the bound in (24) can be considered a slightly weaker version of Poltyrev’s bound [58], Lemma 1. By allowing this weakening, we obtain a bound in a somewhat more closed form, also connecting the decodability with smoothing. We also prove a simple bound for the error probability of list decoding expressed in terms of the code’s distance distribution (and, from (A4), also in terms of the dual distance distribution). The latter result seems not to have appeared in earlier literature. The following version of this lemma provides an error bound, which is useful in the asymptotic setting.
Proposition 5. Let where Then, Proof. Set
. A direct calculation shows that
By the Hoeffding bound,
Together with Lemma 11, this implies our statements. □
A question of prime importance is whether the right-hand side quantities in Proposition 5 converge to 0. For , one can easily see that for random codes, , where , showing that this is, in fact, the case.
From Proposition 4, it is clear that the potential energy is a measure of the smoothness of . This implies that codes that are sufficiently smoothable with respect to are decodable in the BSC with vanishing error probability. In other words, Proposition 5 establishes a connection between the smoothing and the decoding error probability.
7. Perfect Smoothing—The Finite Case
In this section, we briefly overview another form of perfect smoothing, which is historically the earliest application of these ideas in coding theory. It is not immediately related to the information-theoretic problems considered in the other parts.
We are interested in radial kernels that yield perfect smoothing for a given code. We often write instead of if and call the radius of r. Note that the logarithm of the support size of r (as a function on the space ) is exactly the 0-Rényi entropy of r. Therefore, kernels with smaller radii can be perceived as less random, supporting the view of the radius as a general measure of randomness.
Definition 4. We say a code is perfectly smoothable with respect to r if for all , and, in this case, we say that r is a perfectly smoothing kernel for .
Intuitively, such a kernel should have a sufficiently large radius. In particular, it should be as large as the covering radius of the code or otherwise smoothing does not affect the vectors that are away from the code. To obtain a stronger condition, recall that the external distance of code is
Proposition 6. Let r be a perfectly smoothing kernel of code . Then,
Proof. Note that perfect smoothing of
with respect to
r is equivalent to
which by Proposition A1 is equivalent to the following condition:
Therefore,
By definition,
where
is the Krawtchouk matrix. Define
and
then,
This relation implies that there exists a linear combination of Krawtchouk polynomials of degree at most
with
roots. Therefore,
□
Since , this inequality strengthens the obvious condition At the same time, there are codes that are perfectly smoothable by a radial kernel r such that .
Definition 5 ([
59]).
A code is uniformly packed in the wide sense if there exists rational numbers such thatwhere is the weight distribution of the code . Our main observation here is that some uniformly packed codes are perfectly smoothable with respect to noise kernels that are minimal in a sense. The following proposition states this more precisely.
Proposition 7. Let be a code that is perfectly smoothable by a radial kernel of radius . Then, is uniformly packed in the wide sense with for all i.
Proof. By definition, if is perfectly smoothable with respect to r, then , which is tantamount to for all . This condition can be written as for all , completing the proof. □
To illustrate this claim, we list several families of uniformly packed codes ([
59,
60,
61]) that are perfectly smoothable by a kernel of radius equal to the covering radius of the code.
- (i)
Perfect codes: , where is the covering radius.
- (ii)
2-error-correcting BCH codes of length
. The smoothing kernel
r is given by
- (iii)
Preparata codes. The smoothing kernel
r is given by
- (iv)
Binary
Goethals-like codes [
60]. The smoothing kernel
r is given by
Here,
L is a generic notation for the normalizing factor. More examples are found in a related class of
completely regular codes [
62].
Definition 5 does not include the condition that
, and, in fact, there are codes that are uniformly packed in the wide sense, but some of the
’s are negative, and, thus, they are not smoothable by a noise kernel of radius
. One such family is the 3-error-correcting binary BCH codes of length
[
60].



{kind=link}
{kind=link}