




Cluster-Based Structural Redundancy Identification for Neural Network Compression

Abstract
:1. Introduction
- We propose a novel pruning scheme that does not depend on importance but is based on the similarity between filters for channel-level pruning.
- We introduce an effective method for measuring the relative importance of filters, avoiding the problems of over-pruning and under-pruning caused by threshold specification.
- The proposed scheme automatically determines each layer’s pruning rate according to each layer’s parameter distribution, which avoids the problem of unreasonable pruning structure caused by manually specifying the pruning rate.
- A large number of experiments prove the effectiveness of the algorithm proposed in this paper.
2. Related Work
2.1. Unstructured Pruning
2.2. Structured Pruning
2.3. Other Compression Techniques
3. Methodology
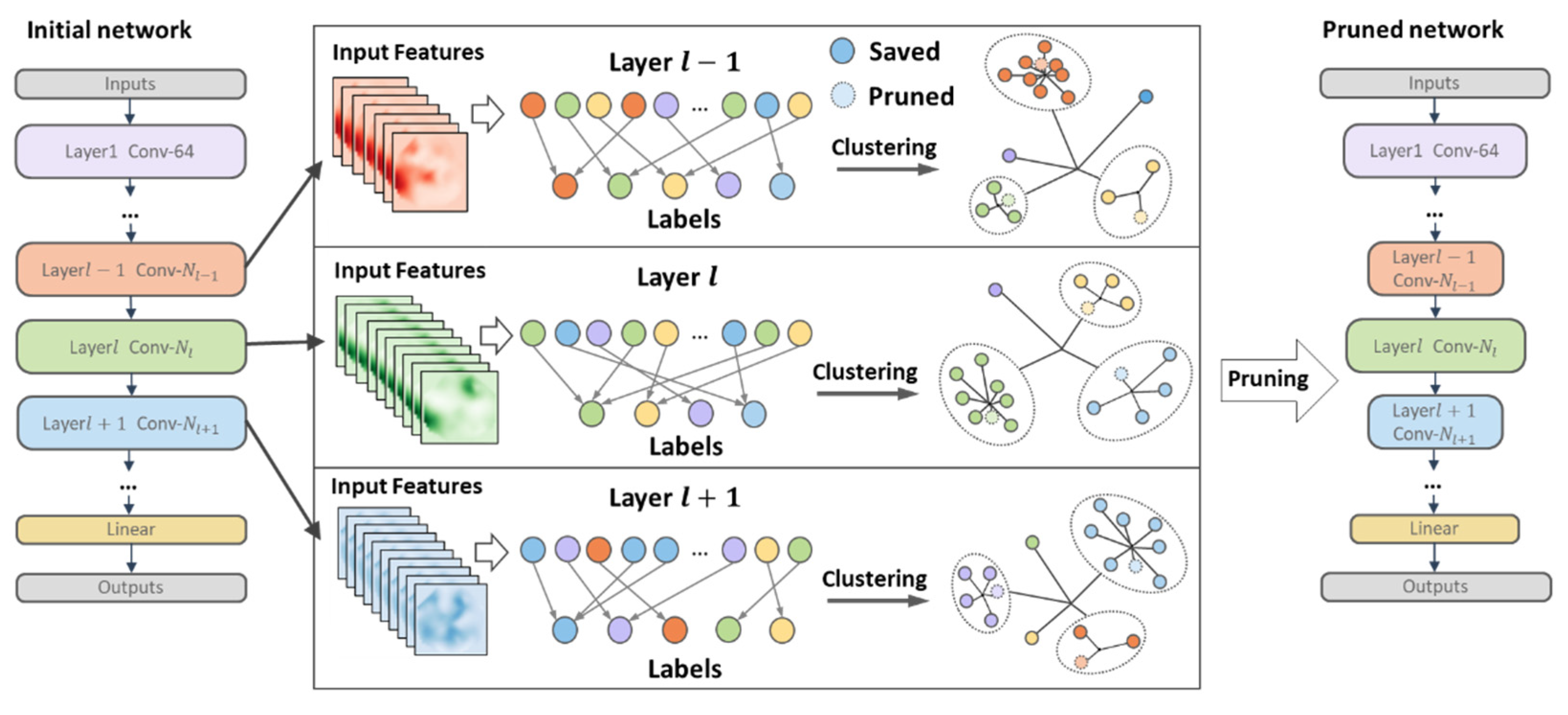
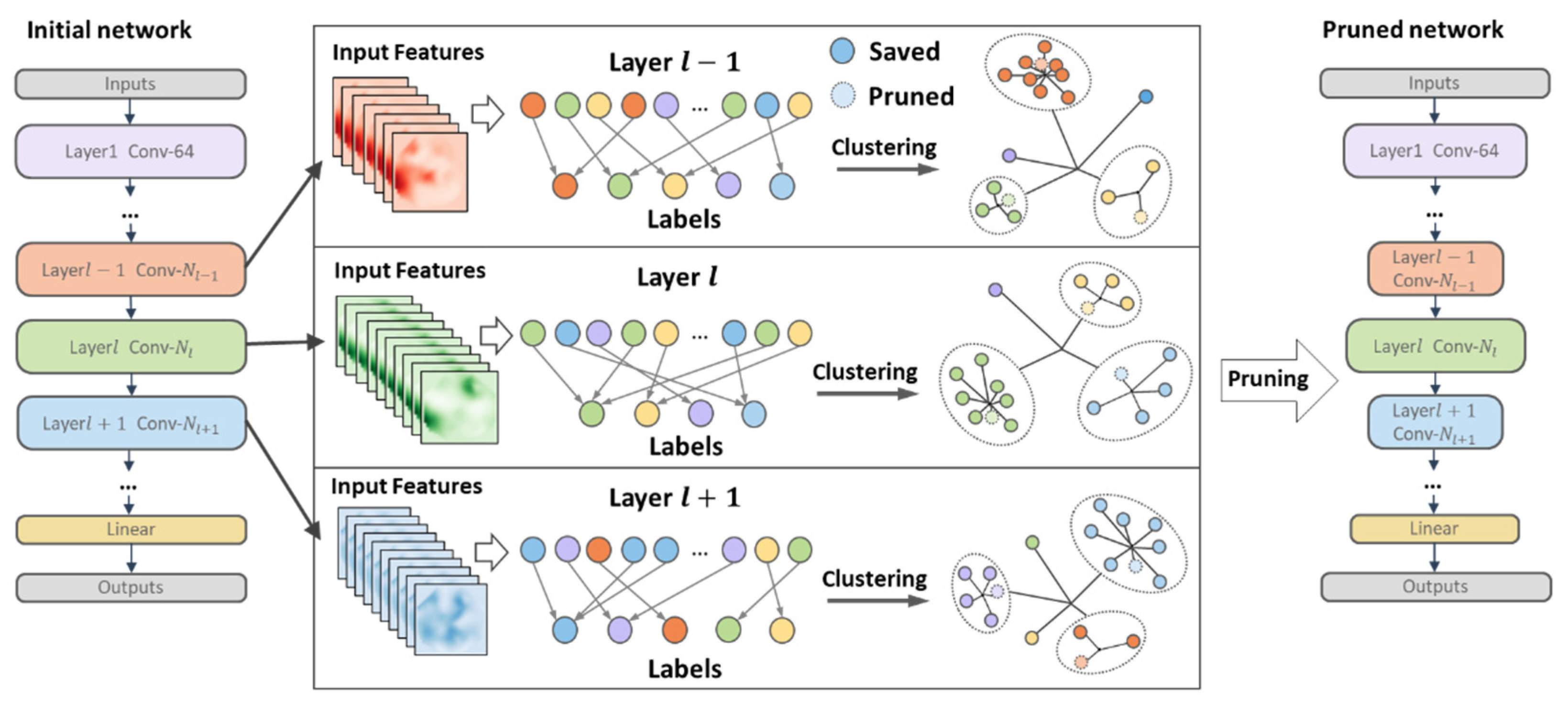
3.1. Overall Framework
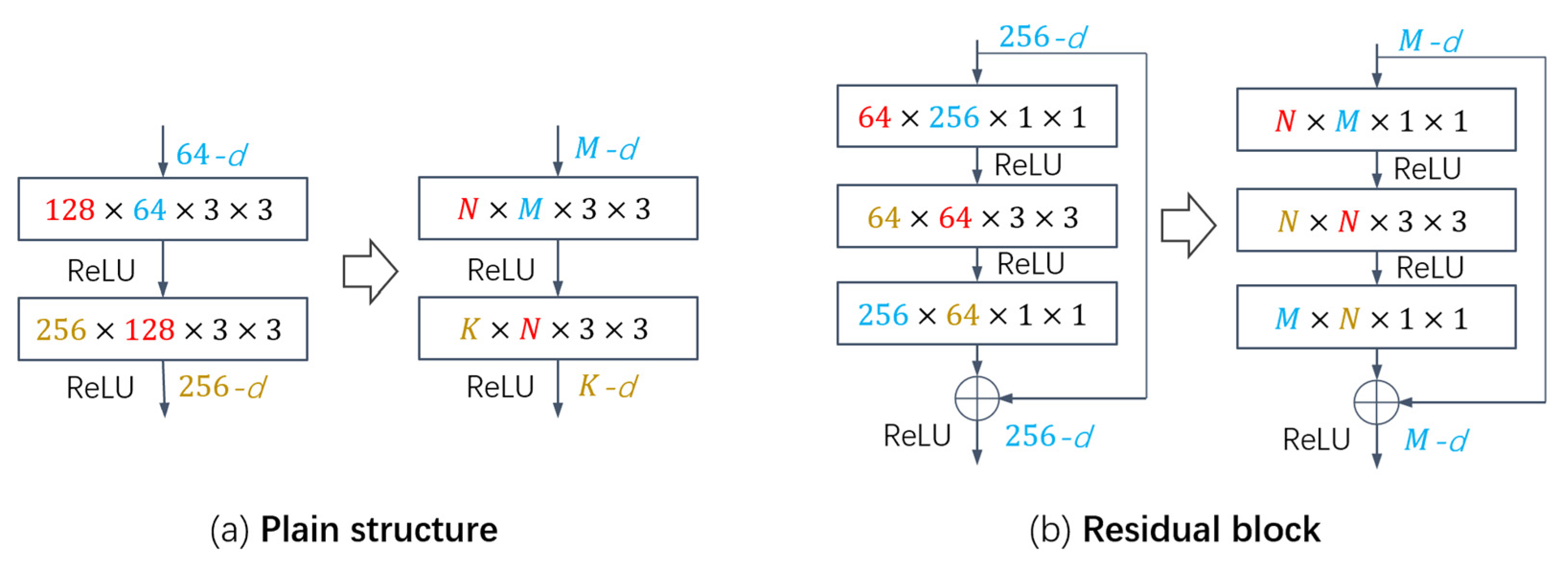
3.2. Motivation and Definitions
3.3. Cluster Pruning
3.4. Pruning Scheme
- For each convolutional layer, first initialize each cluster center and compare any filter in the layer with each cluster center to construct a distance matrix. In each iteration, is obtained in each row, and the corresponding filter is divided into the corresponding cluster , and, finally, the cluster set and cluster center are obtained.
- For each cluster set obtained, each filter in the set and the cluster center obtain a -dimensional vector according to Equation (2), and the filter corresponding to the minimum value in the vector is determined as the layer that needs to be pruned filter.
- After one pruning, calculate the pruning end condition, that is, the amount of computation or parameters after pruning, prune in a loop until the given pruning rate is reached and fine-tune the generated model to restore performance.
| Algorithm 1: Iterative pruning algorithm. |
| Input: Training dataset ; the model with , and each layer with ; FLOPs or params pruning rate: /. |
| Output: The pruned model |
| 1: |
| 2: while pruned rate = 0 to rate do |
| 3: for do |
| 4: initialize the clusters |
| 5: for do |
| 6: |
| 7: |
| 8: |
| 9: end for |
| 10: |
| 11: |
| 12: for do |
| 13: for do |
| 14: |
| 15: |
| 16: end for |
| 17: end for |
| 18: |
| 19: end for |
| 20: |
| 21: end while |
| 22: |
4. Experiments
4.1. Experimental Settings
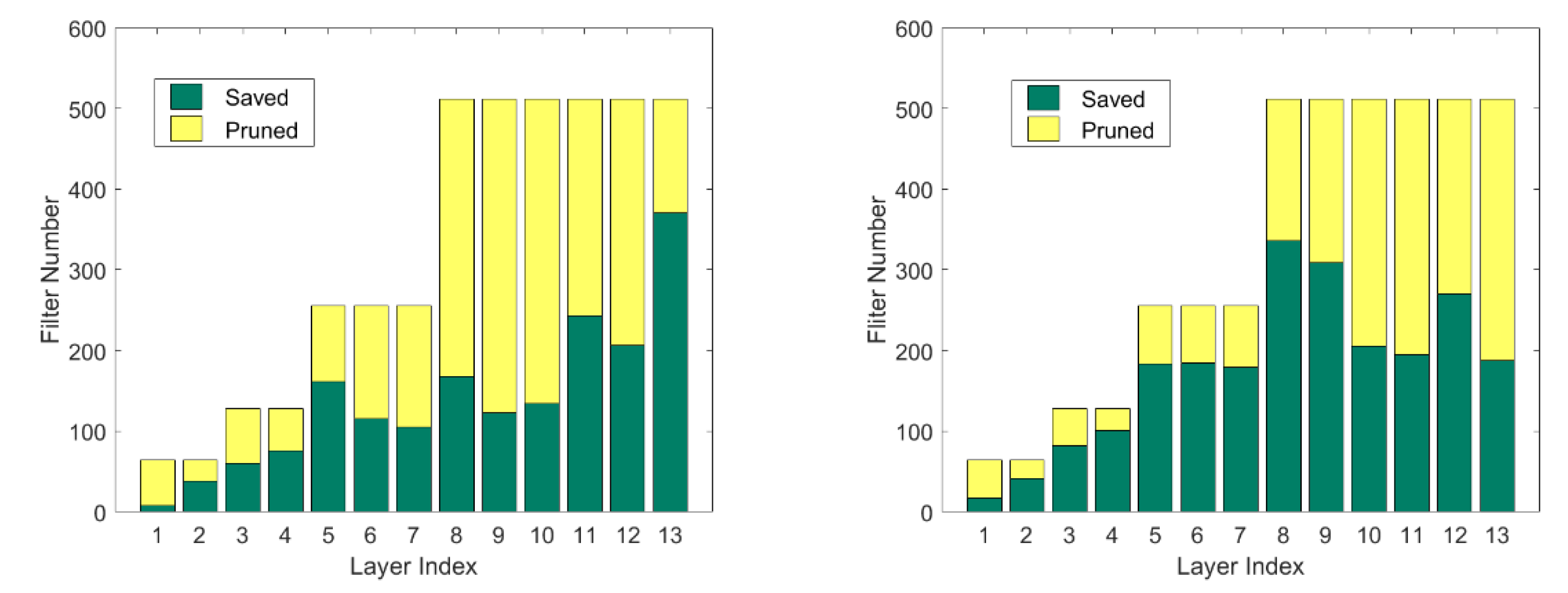
4.2. Results on CIFAR-10/100 Datasets
4.3. Results on ILSVRC-2012
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Song, C.; Liu, S.; Han, G.; Zeng, P.; Yu, H.; Zheng, Q. Edge intelligence based condition monitoring of beam pumping units under heavy noise in the industrial internet of things for industry 4.0. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Song, C.; Xu, W.; Han, G.; Zeng, P.; Wang, Z.; Yu, S. A cloud edge collaborative intelligence method of insulator string defect detection for power iiot. IEEE Internet Things J. 2020, 8, 7510–7520. [Google Scholar] [CrossRef]
- Song, C.; Sun, Y.; Han, G.; Rodrigues, J.J. Intrusion detection based on hybrid classifiers for smart grid. Comput. Electr. Eng. 2021, 93, 107212. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.-P. Binaryconnect: Training deep neural networks with binary weights during propagations. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. J. Mach. Learn. Res. 2017, 18, 6869–6898. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; Volume 2. [Google Scholar]
- Hassibi, B.; Stork, D. Second order derivatives for network pruning: Optimal brain surgeon. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; Volume 5. [Google Scholar]
- Hu, H.; Peng, R.; Tai, Y.-W.; Tang, C.-K. Network trimming: A datadriven neuron pruning approach towards efficient deep architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- He, Y.; Liu, P.; Wang, Z.; Hu, Z.; Yang, Y. Filter pruning via geometric median for deep convolutional neural networks acceleration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4340–4349. [Google Scholar]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1529–1538. [Google Scholar]
- Cai, L.; An, Z.; Yang, C.; Yan, Y.; Xu, Y. Prior gradient mask guided pruning-aware fine-tuning. In Proceedings of the AAAI Conference on Artificial Intelligence, virtually, 22 February–1 March 2022; Volume 1. [Google Scholar]
- Huang, Z.; Shao, W.; Wang, X.; Lin, L.; Luo, P. Convolution-weight distribution assumption: Rethinking the criteria of channel pruning. arXiv 2020, arXiv:2004.11627. [Google Scholar]
- Mozer, M.C.; Smolensky, P. Skeletonization: A technique for trimming the fat from a network via relevance assessment. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA; 1988; Volume 1. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning structured sparsity in deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Liu, B.; Wang, M.; Foroosh, H.; Tappen, M.; Pensky, M. Sparse convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 806–814. [Google Scholar]
- Ye, J.; Lu, X.; Lin, Z.; Wang, J.Z. Rethinking the smaller-normless-informative assumption in channel pruning of convolution layers. arXiv 2018, arXiv:1802.00124. [Google Scholar]
- Lee, N.; Ajanthan, T.; Torr, P.H. Snip: Single-shot network pruning based on connection sensitivity. arXiv 2018, arXiv:1810.02340. [Google Scholar]
- Luo, J.-H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Parkash, V.; Carcangiu, M.L. Endometrioid endometrial adenocarcinoma with psammoma bodies. Am. J. Surg. Pathol. 1997, 21, 399–406. [Google Scholar] [CrossRef]
- Ashok, A.; Rhinehart, N.; Beainy, F.; Kitani, K.M. N2n learning: Network to network compression via policy gradient reinforcement learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Peng, H.; Wu, J.; Chen, S.; Huang, J. Collaborative channel pruning for deep networks. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 5113–5122. [Google Scholar]
- Chen, W.; Wilson, J.; Tyree, S.; Weinberger, K.; Chen, Y. Compressing neural networks with the hashing trick. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 2285–2294. [Google Scholar]
- Xu, Y.; Wang, Y.; Zhou, A.; Lin, W.; Xiong, H. Deep neural network compression with single and multiple level quantization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 525–542. [Google Scholar]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Miyashita, D.; Lee, E.H.; Murmann, B. Convolutional neural networks using logarithmic data representation. arXiv 2016, arXiv:1603.01025. [Google Scholar]
- Gong, J.; Shen, H.; Zhang, G.; Liu, X.; Li, S.; Jin, G.; Maheshwari, N.; Fomenko, E.; Segal, E. Highly efficient 8-bit low precision inference of convolutional neural networks with intelcaffe. In Proceedings of the 1st on Reproducible Quality-Efficient Systems Tournament on Codesigning Pareto-Efficient Deep Learning, Williamsburg, VA, USA, 24 April 2018; p. 1. [Google Scholar]
- Zhao, R.; Hu, Y.; Dotzel, J.; de Sa, C.; Zhang, Z. Improving neural network quantization without retraining using outlier channel splitting. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 7543–7552. [Google Scholar]
- Nagel, M.; Baalen, M.v.; Blankevoort, T.; Welling, M. Datafree quantization through weight equalization and bias correction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 1325–1334. [Google Scholar]
- Maddison, C.J.; Mnih, A.; Teh, Y.W. The concrete distribution: A continuous relaxation of discrete random variables. arXiv 2016, arXiv:1611.00712. [Google Scholar]
- Hwang, K.; Sung, W. Fixed-point feedforward deep neural network design using weights+ 1, 0, and- 1. In Proceedings of the 2014 IEEE Workshop on Signal Processing Systems (SiPS), Belfast, Ireland, 20–22 October 2014; pp. 1–6. [Google Scholar]
- Zhu, X.; Zhou, W.; Li, H. Adaptive layerwise quantization for deep neural network compression. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Ba, J.; Caruana, R. Do deep nets really need to be deep? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Li, J.; Zhao, R.; Huang, J.-T.; Gong, Y. Learning small-size dnn with output-distribution-based criteria. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Ye, J.; Ji, Y.; Wang, X.; Ou, K.; Tao, D.; Song, M. Student becoming the master: Knowledge amalgamation for joint scene parsing, depth estimation, and more. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2829–2838. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- Wang, P.; Cheng, J. Fixed-point factorized networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4012–4020. [Google Scholar]
- Kim, Y.-D.; Park, E.; Yoo, S.; Choi, T.; Yang, L.; Shin, D. Compression of deep convolutional neural networks for fast and low power mobile applications. arXiv 2015, arXiv:1511.06530. [Google Scholar]
- Lebedev, V.; Ganin, Y.; Rakhuba, M.; Oseledets, I.; Lempitsky, V. Speeding-up convolutional neural networks using fine-tuned cp-decomposition. arXiv 2014, arXiv:1412.6553. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 8 April 2009).
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Wang, Z.; Li, C.; Wang, X. Convolutional neural network pruning with structural redundancy reduction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14913–14922. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, (PMLR), Atlanta, GA, USA, 17–19 June 2013; pp. 1139–1147. [Google Scholar]
- Dong, X.; Huang, J.; Yang, Y.; Yan, S. More is less: A more complicated network with less inference complexity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5840–5848. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
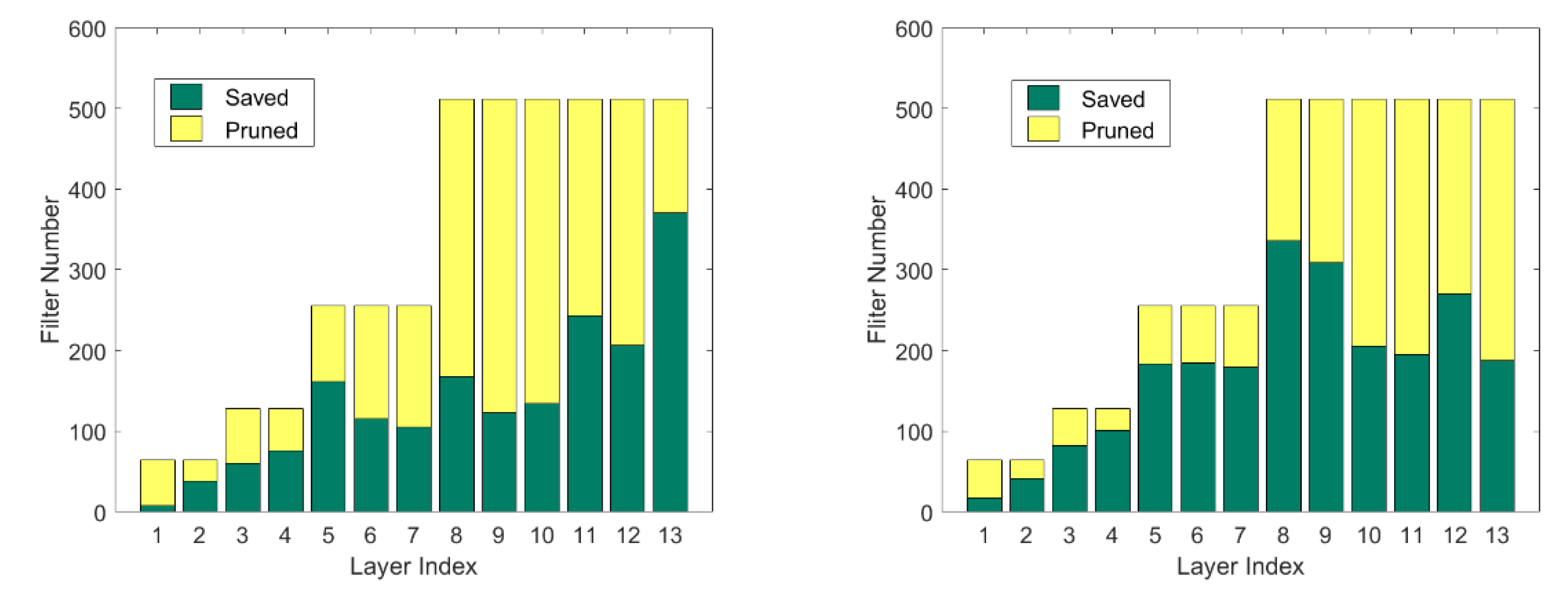{kind=link}
| Model/Data | Method | Baseline Top-1 Acc (%) | Pruned Top-1 Acc (%) | Top-1(↓) Acc (%) | FLOPs (↓) (%) | Params (↓) (%) |
|---|---|---|---|---|---|---|
| VGG16/CIFAR10 | L1 | 93.58 | 93.31 | 0.27 | 34.20 | 64.00 |
| FPGM | 93.58 | 93.23 | 0.34 | 34.20 | 64.00 | |
| Ours | 93.92 | 93.70 | 0.22 | 40.98 | 42.46 | |
| Taylor | 93.92 | 91.24 | 2.78 | 78.03 | 84.56 | |
| Hrank | 93.96 | 91.23 | 2.73 | 76.50 | 92.00 | |
| Ours | 93.92 | 92.49 | 1.43 | 87.49 | 91.20 | |
| VGG16/CIFAR100 | L1 | 73.45 | 71.21 | 2.24 | 50.44 | 50.23 |
| Taylor | 73.45 | 70.34 | 2.36 | 51.48 | 59.89 | |
| FPGM | 73.45 | 71.39 | 2.06 | - | 48.93 | |
| Ours | 73.45 | 71.91 | 1.54 | 54.11 | 62.49 |
| Model/Data | Method | Baseline Top-1 Acc (%) | Pruned Top-1 Acc (%) | Top-1 (↓) Acc (%) | FLOPs (↓) (%) |
|---|---|---|---|---|---|
| ResNet-32/CIFAR10 | L1 | 91.82 | 80.01 | 11.81 | 43.76 |
| SFP | 91.33 | 91.60 | +0.27 | 53.16 | |
| FPGM | 91.33 | 91.90 | +0.57 | 53.16 | |
| Ours | 91.82 | 92.11 | +0.29 | 55.36 | |
| ResNet-56/CIFAR10 | L1 | 93.04 | 91.31 | 1.75 | 27.60 |
| SFP | 93.59 | 92.26 | 1.33 | 52.60 | |
| FPGM | 93.59 | 92.89 | 0.70 | 52.60 | |
| HRank | 93.26 | 93.17 | 0.09 | 50.00 | |
| SRR-GR | 93.38 | 93.75 | +0.37 | 53.80 | |
| Ours | 92.55 | 93.09 | +0.54 | 60.10 | |
| ResNet-110/CIFAR10 | L1 | 93.53 | 92.94 | 0.61 | 38.60 |
| SFP | 93.68 | 93.38 | 0.30 | 40.80 | |
| FPGM | 93.68 | 93.73 | +0.05 | 52.30 | |
| Hrank | 93.50 | 92.65 | 0.85 | 68.60 | |
| Ours | 93.60 | 93.17 | 0.43 | 70.59 | |
| ResNet-32/CIFAR100 | L1 | 66.48 | 58.11 | 8.37 | 43.76 |
| SFP | 66.48 | 64.27 | 2.21 | 53.16 | |
| FPGM | 66.48 | 66.64 | 0.16 | 53.16 | |
| Ours | 66.48 | 66.87 | +0.39 | 50.51 | |
| ResNet-56/CIFAR100 | SFP | 69.08 | 68.03 | 1.05 | 63.16 |
| FPGM | 69.08 | 67.75 | 1.33 | 63.16 | |
| PGMPF | 72.92 | 70.21 | 2.71 | 52.6 | |
| Ours | 69.08 | 68.57 | 0.51 | 63.48 | |
| ResNet-110/CIFAR100 | Ours | 71.26 | 70.28 | 0.98 | 57.73 |
| Model/Data | Method | Baseline Top-1 Acc (%) | Pruned Top-1 Acc (%) | Top-1 (↓) Acc (%) | Baseline Top-5 Acc (%) | Pruned Top-5 Acc (%) | Top-5 (↓) Acc (%) | FLOPs (↓) (%) |
|---|---|---|---|---|---|---|---|---|
| ResNet-18 | MIL | 69.98 | 66.33 | 3.65 | 86.94 | 89.24 | 2.30 | 34.6 |
| SFP | 70.28 | 67.10 | 3.18 | 89.63 | 87.78 | 1.85 | 41.8 | |
| FPGM | 70.28 | 67.81 | 2.47 | 89.63 | 88.11 | 1.52 | 41.8 | |
| PGMPF | 70.23 | 66.67 | 3.56 | 89.51 | 87.36 | 2.15 | 53.5 | |
| Ours | 70.48 | 68.66 | 1.82 | 89.60 | 88.44 | 1.16 | 53.8 | |
| ResNet-34 | MIL | 73.42 | 72.99 | 0.43 | 91.36 | 91.19 | 0.17 | 24.8 |
| L1 | 73.23 | 72.17 | 1.06 | - | - | - | 24.2 | |
| SFP | 73.92 | 71.83 | 2.09 | 91.62 | 90.33 | 1.29 | 41.1 | |
| FPGM | 73.92 | 72.11 | 1.81 | 91.62 | 90.69 | 0.93 | 41.1 | |
| PGMPF | 73.27 | 70.64 | 2.63 | 91.43 | 89.87 | 1.56 | 52.7 | |
| Ours | 73.90 | 72.55 | 1.35 | 91.59 | 90.79 | 0.80 | 52.1 | |
| ResNet-50 | ThiNet | 75.30 | 74.03 | 1.27 | 92.20 | 92.11 | 0.09 | 36.79 |
| SFP | 76.15 | 74.61 | 1.54 | 92.87 | 92.06 | 0.81 | 41.8 | |
| FPGM | 76.15 | 75.03 | 1.12 | 92.87 | 92.40 | 0.47 | 42.2 | |
| HRank | 76.15 | 74.98 | 1.17 | 92.87 | 92.33 | 0.54 | 43.76 | |
| SRR-GR | 76.13 | 75.76 | 0.37 | 92.86 | 92.60 | 0.19 | 44.10 | |
| PGMPF | 76.01 | 75.11 | 0.90 | 92.93 | 92.41 | 0.52 | 53.5 | |
| Ours | 75.82 | 72.47 | 0.35 | 92.95 | 92.68 | 0.27 | 53.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Song, C.; Zeng, P.; Xia, C. Cluster-Based Structural Redundancy Identification for Neural Network Compression. Entropy 2023, 25, 9. https://doi.org/10.3390/e25010009
Wu T, Song C, Zeng P, Xia C. Cluster-Based Structural Redundancy Identification for Neural Network Compression. Entropy. 2023; 25(1):9. https://doi.org/10.3390/e25010009
Chicago/Turabian StyleWu, Tingting, Chunhe Song, Peng Zeng, and Changqing Xia. 2023. "Cluster-Based Structural Redundancy Identification for Neural Network Compression" Entropy 25, no. 1: 9. https://doi.org/10.3390/e25010009
APA StyleWu, T., Song, C., Zeng, P., & Xia, C. (2023). Cluster-Based Structural Redundancy Identification for Neural Network Compression. Entropy, 25(1), 9. https://doi.org/10.3390/e25010009