1. Introduction
Modern industrial processes are characterized by large-scale components, extensive spatial structure, and strong sub-unit coupling [
1]. The hierarchical optimization and control structure is often used for high-dimensional complex systems. It contains a planning and scheduling layer, real-time optimization (RTO) layer, advanced process control (APC) layer, and a regular control layer [
2,
3]. Model predictive control (MPC) is a type of APC algorithm that deals with multi-input multi-output constraint systems. The successful implementation of MPC can generate considerable revenues for companies, but its practical application is not universal for smaller companies with insufficient capacities. Due to the time scale between layers being different, disturbances entering into the process during any control period will result in a shift in the static operating point, and dynamic control cannot work on the optimal point, thus affecting economic efficiency. The optimal results of the RTO layer may not be suitable for current operating conditions. A two-stage MPC structure is commonly used in the industry [
4,
5,
6,
7], so many scholars proposed double-layer model predictive control (DLMPC). The steady-state optimization (SSO) layer of the DLMPC is able to adjust constraints and optimize steady-state operating points based on the steady-state model, while the dynamic control layer accomplishes the tracking of set values based on the dynamic control (DC) model [
8,
9,
10,
11].
The premise of implementing hierarchical optimization and control structure is based on a decentralized control system, realizing the coordination optimization among subsystems with control algorithms. Compared to centralized control systems, decentralized control systems can reduce computational complexity. Tamás Keviczky et al., facing a class dynamic decoupling systems’ optimal control problem, designed a decentralized rolling horizon control (RHC) scheme, describing the coupling between systems through diagrams, which decomposes centralized RHC controllers into some small RHC controllers to reduce the complexity of the problem and analyzes the sufficient stability conditions for the proposed solution [
12]. For extensive dynamic processes with input constraints, Alessandro Alessio proposed decentralized model predictive control that approximated the global model by decomposing it into several smaller models for local predictions, giving sufficient conditions for asymptotic closed-loop stability in the absence of intermittent communication of measurement data [
13]. Focusing on the lack of intermittent measurement data communication between decentralized model prediction controllers, Davide Barcelli gave sufficient criteria for the asymptotic tracking of output setpoints and rejection of constant measurement disturbances, and proposed a decentralized model predictive control method for extensive process setpoint tracking [
14].
Although powerful algorithms quantify the interactions of decentralized control loops, decentralized control systems still lack the coupling between multiple variables [
15]. In contrast to decentralized control systems, distributed control methods enable controllers to communicate with each other to cooperate while operating individually. Each controller considers the dynamic interactions among systems [
16]. Aiming at the internet multi-objective optimal problem, Andrea Camisa proposed a distributed model predictive control (DMPC) calculation scheme of negotiation among agents based on cooperative game theory [
17]. M. Francisco introduced a new fuzzy inference system into the cooperative game algorithm to propose multi-agent fuzzy negotiation distributed model predictive control considering economic criteria and process constraints on the negotiation process of the agents [
18]. For the control of large urban traffic networks, Zhao Zhou et al. proposed a two-level hierarchical control framework, which uses the MPC method, with the upper level solving higher-level optimization problems for traffic-demand balance and the lower level adopting distributed control schemes within each sub-network to reduce the computational complexity [
19]. A negotiation strategy among agents was designed using fuzzy rules under a hierarchical DMPC control architecture. The agents negotiate in pairs at the lower layers based on coupling and communication networks, with the lower-level negotiation process avoiding a portfolio explosion [
20]. Under non-iterative, non-cooperative MPC algorithms, Marcello Farina proposed a DMPC algorithm that requires only partially connected communication networks and structural information [
21]. In terms of non-cooperative strategies, Haimin Hu proposed new distributed iterative learning model predictive control that uses the local states and input trajectories of the previous iteration to construct time-varying safety sets and terminal cost functions [
22]. For multi-area interconnected power systems, an algorithm based on Laguerre functions for DMPC containing the game-theoretic Nash equilibrium was proposed, with each regional DMPC controller coordinating with other controllers to find Nash equilibrium points [
23].
Many scholars have proposed distributed or decentralized MPC algorithms based on dual decomposition. Joseph J. Yame et al. proposed a new DMPC containing both decomposition subsystem and integrated coordination sub-controller stages [
24]. Takumi Namba et al. proposed a dual decomposition DMPC and applied it to a microgrid with the large-scale introduction of PV power [
25]. Yuji Wakasa et al. proposed a decentralized model predictive control algorithm based on dual decomposition, which enables the decentralized control approach to solve the original optimization problem accurately using iterations [
26]. Xi et al. proposed a decomposed–coordinated model predictive control (DCMPC) algorithm based on the theory of dual decomposition, but the algorithm is oriented towards DMC with only equation constraints without considering the case with constraints [
2]. The authors used hierarchical distributed predictive control as a key search term to review the relevant literature [
27,
28,
29,
30,
31]. At present, there are few research results on distributed control algorithms in the DLMPC structure. Yang Kai et al. proposed an integrated algorithm for real-time optimization and distributed control, with an overall economic optimization model for the upper layer and a distributed dynamic control structure for the lower layer [
32]. Shi et al. proposed a distributed two-layer structure strategy for large-scale systems, with an online adaptive constraint adjustment scheme for the upper layer considering the possible constraints and priority order in the process. Based on the Pareto optimal algorithm, the lower layer proposed a new cooperative distributed dynamic matrix control based on a Jacobi-type iterative cooperation approach to achieve a globally optimal solution [
33].
Centralized control optimization is often employed for industrial process control. However, the high computational effort of centralized control optimization challenges the MPC’s online optimization capabilities, exacerbating the difficulty of the widespread implementation of DLMPC algorithms in the industry. Reducing the more considerable computational complexity with a bit of sacrifice of control performance under satisfying the control goals is of greater significance in promoting the popularization of the industrial implementation of DLMPC algorithms. To reduce the computational complexity of industrial process control, research in this paper is oriented towards constrained multivariable distributed control systems. Based on decomposition–coordination MPC, we propose two strategies for adding constraints, and based on one of them we propose decomposition–coordination of DLMPC for constrained systems, with the following main contributions: Firstly, two methods are proposed to add variable constraints based on the original decomposition–coordination (dual decomposition method) MPC algorithm to solve the problem that the original method is not applicable to multivariable systems with constraints. In the first method, based on the dual decomposition method, the suboptimization problem with constraints for each subsystem forms a quadratic programming (QP) problem. The second method is the dual decomposition method based on the constrained zones, which analyzes the convergence relationship between the variables and the constraints. It proves that if the convergence factor is small enough, the solutions will eventually definitely converge to the boundaries of the constraints. Then, both proposed methods are discussed and analyzed based on their performances, concluding that the second method has superior online optimization capabilities, which are validated by Simulation 1. Further, a distributed DLMPC algorithm based on the dual decomposition of constraint zones is proposed, where the decomposition–coordinated dynamic control layer simultaneously tracks the steady-state optimized values of the controlled variable (CV) and manipulated variable (MV), which is also different from the original decomposition–coordinated dynamic control objective function, giving an optimal solution expression that added the tracking of the steady-state optimized values of the MV, and proving the effectiveness of the proposed algorithm through Simulation 2. The improved DLMPC algorithm in this paper satisfies the control goals and constraints while greatly reducing the computational complexity of the dynamic control layer, thus improving the online optimization capability of the algorithm. It is of interest and value to provide a fundamental theoretical study for the industrial implementation of distributed DLMPC.
This paper is arranged as follows:
Section 1 is the Introduction.
Section 2 provides an overview of DLMPC and DCMPC as a foundation for the later paper.
Section 3 proposes two improved dual decomposition methods, namely, the dual decomposition method based on subsystem QP and the dual decomposition method based on the constraint zones, discussing and analyzing the performance of the two methods.
Section 4 proposes a new DLMPC algorithm based on the dual decomposition method of the constraint zone. Based on the original DCMPC, which only tracks the external targets of the controlled variables, it adds the ability to track the external targets of the manipulated variable, to track the steady-state optimized value of the MV, and to give a characterization of the optimal solution under such an objective function.
Section 5 simulates and validates the algorithms proposed in
Section 3 and
Section 4, respectively, employing the Shell heavy oil fractionation model.
Section 6 is conclusions.
Partial abbreviations and notations are shown in
Table 1.
3. Constrained Decomposition–Coordination Strategy
The original DCMPC is oriented towards multivariable systems with no constraints (only one equation constraint). However, most systems have constraint requirements on the controlled and manipulated variables. This paper proposes an improved DCMPC method for constrained multivariable systems, incorporating the simple handling of inequality constraints to the original method. The improved DCMPC can meet the control requirements of systems with inequality constraints.
3.1. Problem Description
Suppose a constrained MIMO system, with
inputs and
outputs, has additional constraints on the CV, MV, and MV increments compared to the unconstrained system. The online optimization problem formed using a centralized optimization approach is shown in Equation (18).
Decomposing the original system into
SISO subsystems with linear additivity between the subsystems, the original centralized optimization problem is rewritten, as shown in Equation (19).
3.2. The Dual Decomposition Method Based on Subsystem QP
The first improved dual decomposition method proposed in this paper for constrained MIMO distributed systems introduces CV, MV, and MV incremental constraints into the solving process of each distributed system to form the subsystem QP problem.
The equation constraint that contains the association of
and
is first introduced into the objective function via a Lagrange multiplier to form the dual problem for
subsystems, as shown in Equation (20).
Therefore, the association of
and
in the constraints no longer remains. The constraints on
and
are already independently separable, so the optimization problem of Equation (20) is further decomposed into the QP problems corresponding to
and
, as shown in Equations (21) and (22).
Using the QP solution method, and can be obtained and brought into Equation (16) to update the coordination factor . The remaining steps are the same as the decomposition–coordination method and will not be repeated here.
3.3. The Dual Decomposition Method Based on the Subsystem Constrained Zone
The second improved dual decomposition method proposed in this paper for constrained MIMO distributed systems introduces CV, MV, and MV incremental constraints into each distributed system after the solution has been solved, and the zones formed by the constraints limit the solution.
Firstly, the problem is dealt with as an optimization problem with equality constraints, equivalent to Equation (9). Then, the steps of forming the Lagrange function are the same as the original method, as shown in Equations (10)–(12). In solving the optimal of the sub-problem stage, the proposed strategy adds the inequality constraints after obtaining
and
, as shown in Equations (23) and (24).
where
is the lower-unit triangular matrix of
. The above constraint limits are only for the case of containing
, when simultaneously containing increments of
are considered, as shown in Equation (25).
In the second stage, updating the coordination factor is the same as the original method based on calculated and , as shown in Equations (15)–(17). Equations (23) and (25) indicate that the manipulated variables must exist within the constraints. Whether Equation (25) can make controlled variables exist within the constraints needs further analysis.
Suppose
exists when
is calculated iteratively in
times, then
exists. According to Equation (17), when the iteration stop condition is satisfied, it approximately means
, as shown in Equation (26).
When
surpasses the upper limit of the constraint, then
holds through the constraint zone, and Equation (26) is rewritten as Equation (27).
When we substitute the equality constraints of Equations (9) and (14) into Equation (27), we obtain that seen in Equation (28).
We can notice that the sum in parentheses in Equation (28) is the predicted value of the controlled variable in the future time horizon generated by the control law . As long as the predetermined is a small-enough positive number, and the coordination factor is continuously updated to the iteration stop condition, it can be understood from Equation (17) that and can reach an associated equilibrium state. In the continuous iterative process, the result generated by the control law will eventually converge to . Similarly, converges to when . It is proved that the added inequality constraint strategy is also effective for the controlled variables.
3.4. Performance Comparison of the Proposed Algorithms
This paper proposes two improved methods based on the decomposition–coordination method for constrained distributed MPC systems. As demonstrated by the simulations in
Section 5.1, both methods can satisfy the demand for constraints. However, the first method has greater computational effort than the second.
The first method introduces the equation constraint containing the association of
and
into the dual problem
by Lagrange multipliers, so that
is only related to
and
, rather than to the other subsystem variables, thus decomposing the coupling between the subsystems. At the same time,
and
are independently separable in the constraints, so that
is further decomposed into the two QP problems
and
, which is equivalent to dividing the original centralized optimization problem into sub-optimization problems. For QP calculations containing a large matrix, this method can significantly reduce the computational scale. However, as suboptimization problems become more extensive, the computation time is not advantageous for some small and medium-sized computation scales. The second method is based on the original decomposition–coordination method, without adding the QP calculation, which is only through the logical determination of MV and CV constraints, so its computation time has a significant advantage compared with the first method. Compared with the centralized optimization method, the second method uses distributed parallel online iterative operations to avoid the high-dimensional matrix inverse calculation, so it has more superiority in computing control laws. The specific algorithm comparison analysis is detailed in
Section 5.1.
4. PDLMPC Algorithm
This paper proposes two improved dual decomposition methods for constrained multivariate systems. After the above discussion and analysis and subsequent validation, the online optimization performance of the dual decomposition method based on the constrained zone is more advantageous, so an improved PDLMPC method is introduced into the DLMPC architecture. In this method, the steady-state optimization layer adopts the centralized optimization method, and the dynamic control layer adopts the constrained decomposition–coordination method. The structure is shown in
Figure 2.
Different from the matrix dimension of the dynamic model, the steady-state model has a smaller one, and it is a one-step optimization. The prediction and control horizon are both one, so the centralized optimization will not generate a large computational burden. The centralized optimization problem for the steady-state layer of a constrained multivariable system is shown in Equation (29).
where
is the prediction error passed by the dynamic control layer. Solving Equation (24) to obtain the steady-state target values
and
, the online optimization problem of the dynamic control layer at time
is shown in Equation (30).
Firstly, the inequality constraints are ignored, and only the dual problem under equality constraints is considered, as shown in Equation (31).
At the first level, the dual problem
is minimized to solve
and
, as shown in Equations (32) and (33).
The steps for updating the coordination factor in the second stage are the same as the original method. That is, Equations (15)–(17) are performed. When the iteration is stopped, the optimal manipulated variable is applied to the controlled process. The deviation between the sampling result
at time
and the predicted value
at time
is taken as the prediction error
. The prediction error is transmitted to the steady-state optimization layer and the feedback correction module. The predicted initial value
is obtained after feedback correction and shifting, as shown in Equation (34).
In summary, the improved DLMPC algorithm based on the decomposition–coordination method for constrained multivariable systems is complete. The algorithm adopts the overall optimization mode in the steady-state layer, which can give a more comprehensive steady-state target value. Taking the steady-state target value as the setting point of the dynamic control layer can provide more global information for each subsystem and more reasonable tracking targets. The distributed architecture of the dynamic control layer ensures the information transmission between subsystems through decomposition and coordination. At the same time, a simple constraint method is proposed. Through theoretical analysis, it is proved that the method can ensure that MV and CV run in the constraint conditions. However, this method is also incomplete and needs specific skills and experience when setting coefficients such as weight of control, error weight, and iteration stop accuracy.
6. Conclusions
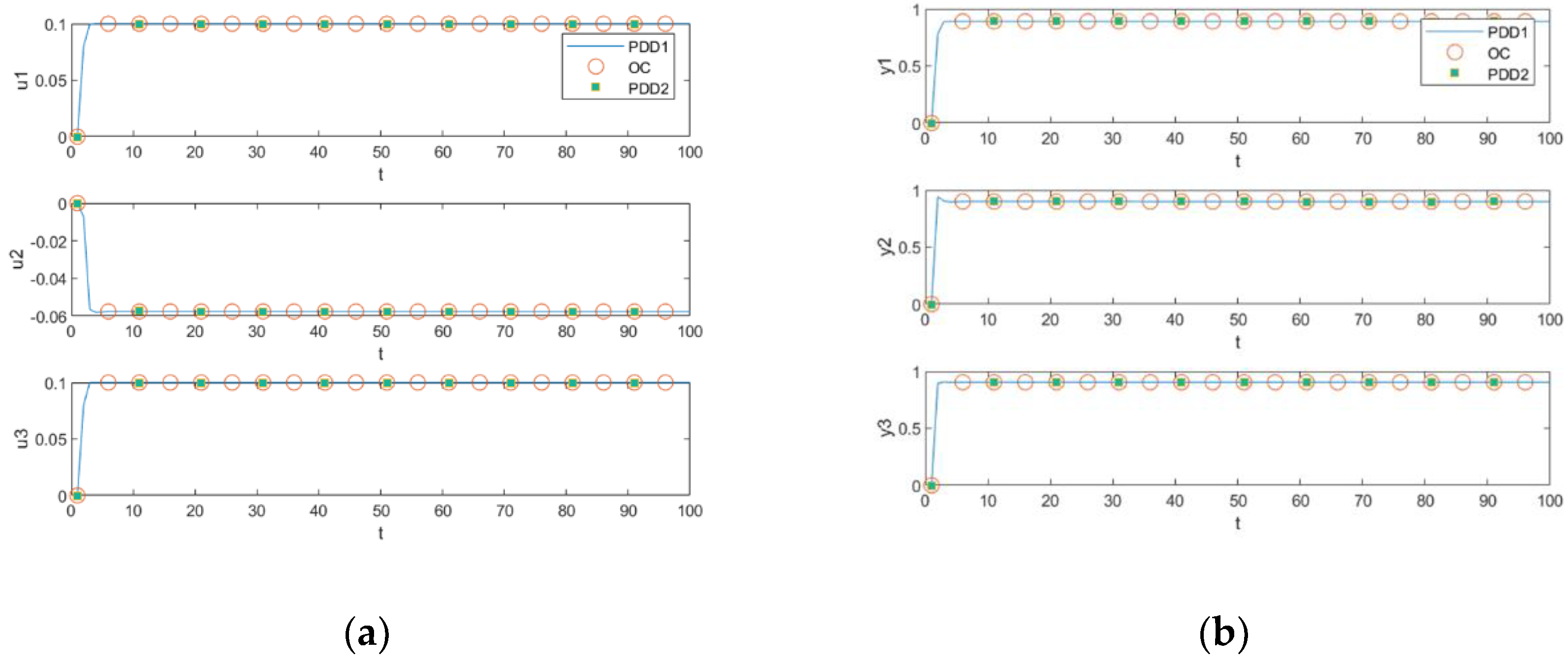
This paper proposes an improved distributed DLMPC approach facing a complex class of constrained systems in modern, extensive, industrial processes. Firstly, two methods for adding constraints are proposed based on the decomposition–coordination MPC. The first improved dual decomposition method introduces the constraints of MV and CV into solving the distributed subsystem, forming the QP problem with the dual function of the subsystem to solve it. The second is a dual decomposition method based on constrained zones, which introduces the constraints of MV and CV into the distributed subsystem after solving and . Furthermore, the convergence of the method is analyzed: as long as the parameters are set appropriately, the CV will eventually converge to the constraint boundary. The online optimization capabilities of the two proposed methods are discussed and compared, concluding that the second proposed method, the pairwise decomposition method based on constraint zones, has superior online optimization capability. This guess is proved by comparing the two proposed methods and the centralized optimization method through simulation. Based on the above work, an improved distributed DLMPC algorithm based on the pairwise decomposition method with constrained zones is proposed. Different from the objective function in the original decomposition–coordination method, the objective function used in the dynamic control layer of the improved distributed DLMPC algorithm tracks both the steady-state optimized values of MV and CV and the dynamic control layer of the decomposition–coordination with constraints designed for this objective function, which gives the characterization of the optimal solution as well as the strategy for processing the constraints. The proposed algorithm can reduce the computational complexity while achieving the control goals. The effectiveness and rationality of the proposed algorithm are validated through simulations and compared to the simulation results of DCDLMPC without constraints. It is evident that PDLMPC can make the manipulated variables constrained. Compared with ODLMPC, PDLMPC uses less running time and the control effect is similar, so it can meet the control requirements and achieve the control goals. Of course, the PDLMPC algorithm also has shortcomings; it has specific requirements for parameter settings, and further research will be carried out in the future to optimize the parameters of this algorithm.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}