
A Conceptual Multi-Layer Framework for the Detection of Nighttime Pedestrian in Autonomous Vehicles Using Deep Reinforcement Learning
 , , ,
, , ,  ,
,  ,
,  and
and
Abstract
1. Introduction
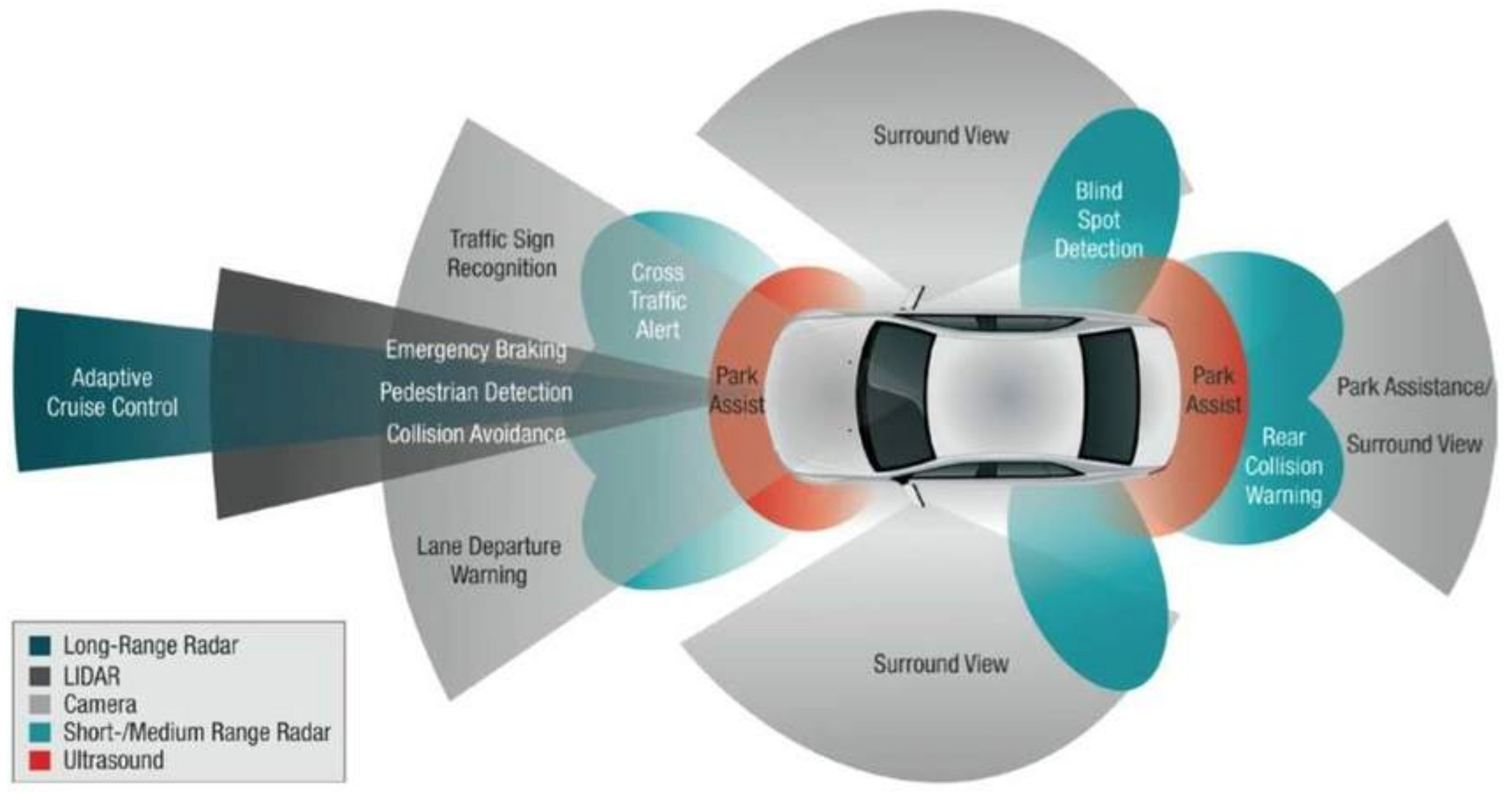
1.1. ADS Challenges and Solutions
1.2. Night Time Object Detection Challenges
- Viewpoint: while discussing night-time pedestrian detection, video frames are captured on small scale. Moreover, rain and occlusion are also some of the challenge cases due to poor visibility. Capturing downward and parallel angles in some cases also causes a higher miss rate in detection.
- Imbalance illumination: Light distribution is strenuous in different angles and also imbalance during nighttime because the main light source is the vehicle itself and street lights. These may cause false detection and poor detection rates.
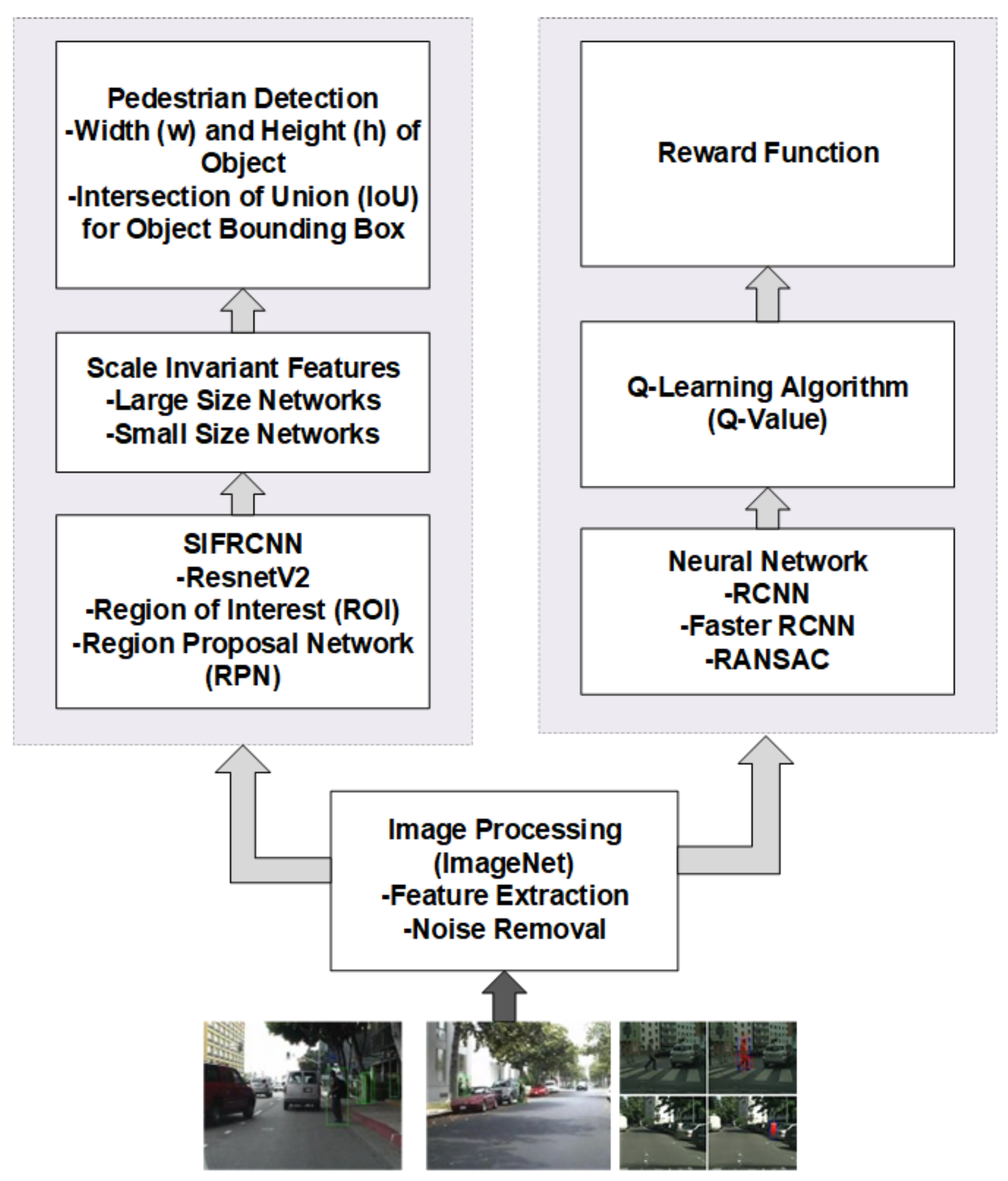
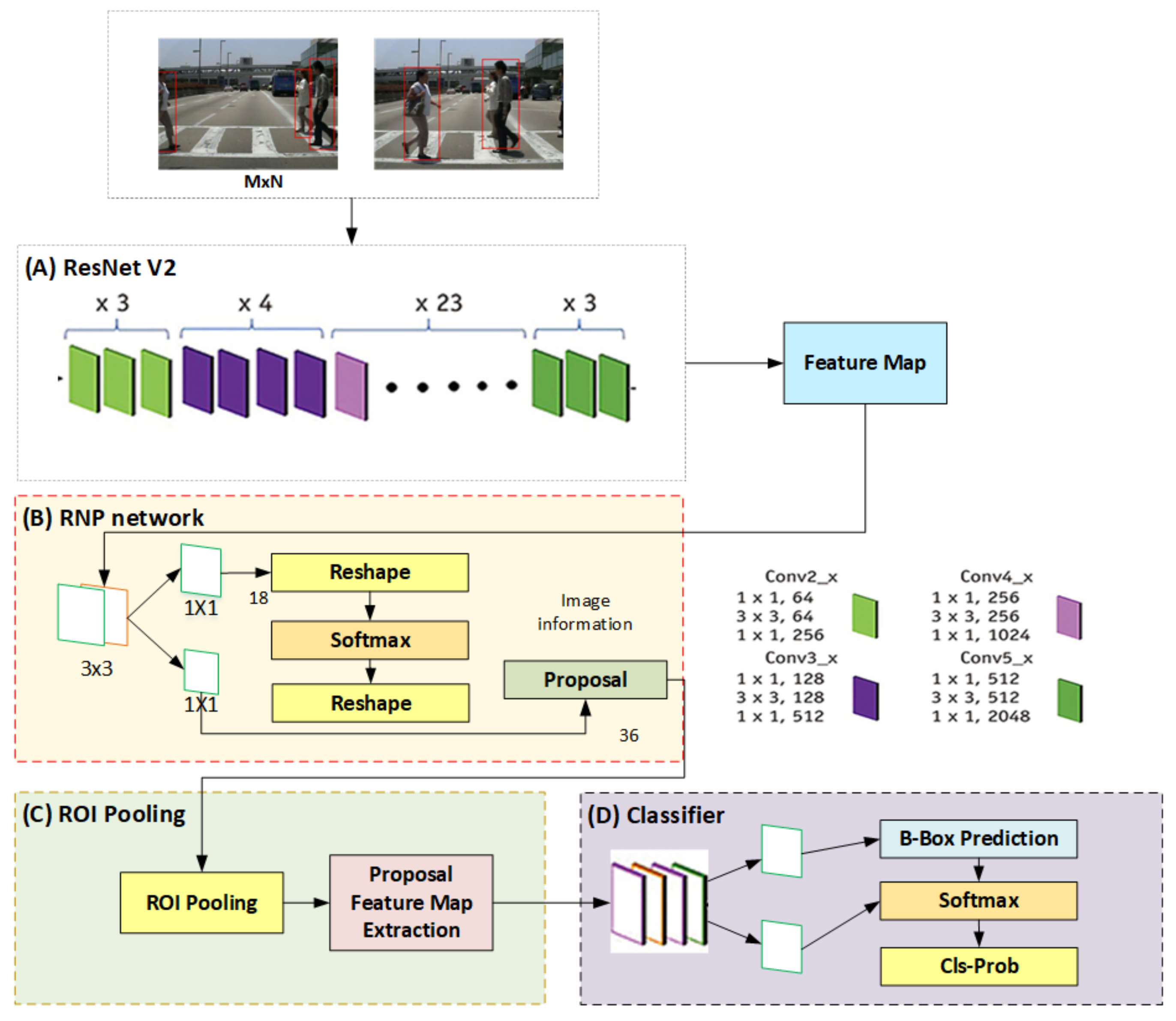
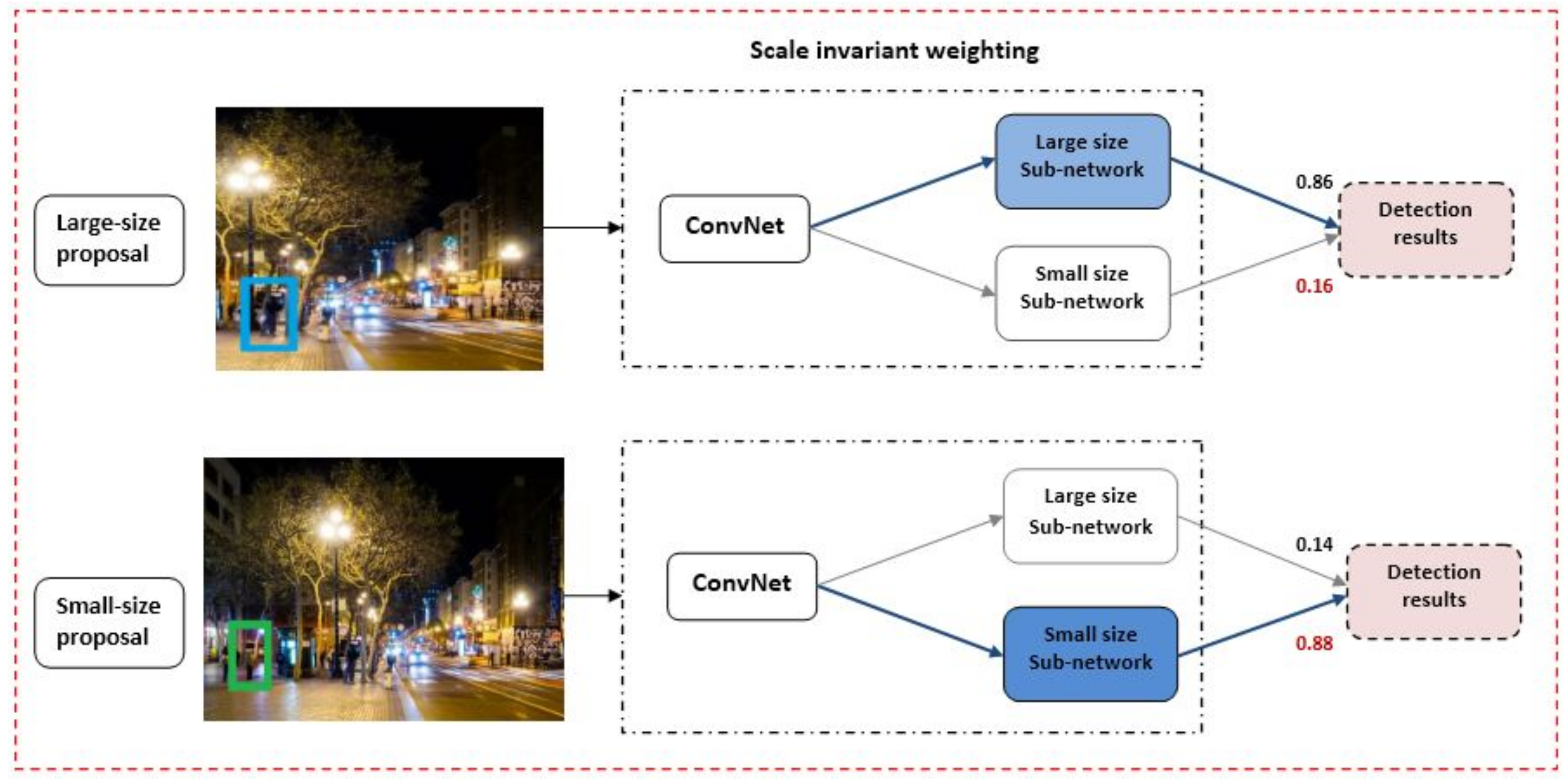
2. Scale Invariant Faster Region-Based Convolutional Neural Networks (SIFRCNN)
- ROI Pooling layer to extricate the equal-length vectors of image frames.
- Build a single-stage network to manage the segmentation and feature extraction neither like RCNN where it involves multiple stages, for instance, feature extraction, region generation, and classification.
- FRCNN has enabled to share of the computational load by using the ROI Pooling layer on the single network of proposals and has a much more accurate comparison to CNN.
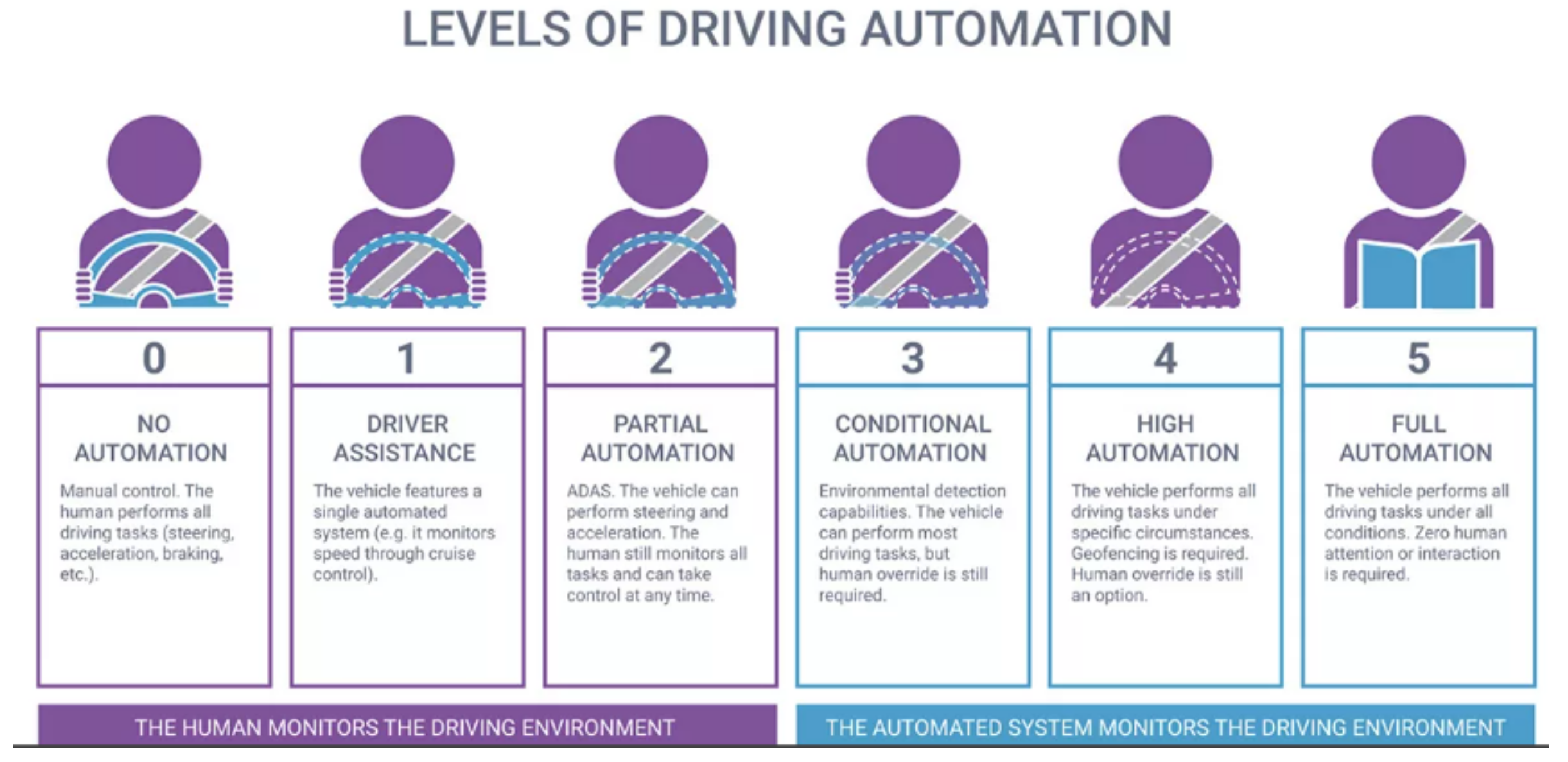
- This research presents the state-of-the-art SIFRCNN algorithm to detect real-time pedestrian action detection in different environments i.e., types of pedestrians such as a child, an adult, and a senior citizen, especially at nighttime. Moreover, SIFRCNN used two learning approaches to integrate the benefits into real-world solutions including autonomous navigation, hindrance detection, and avoidance in stochastic environments. The main target of the algorithm is to achieve ADS level 4 with high automation.
3. Historical Notes and Related Work
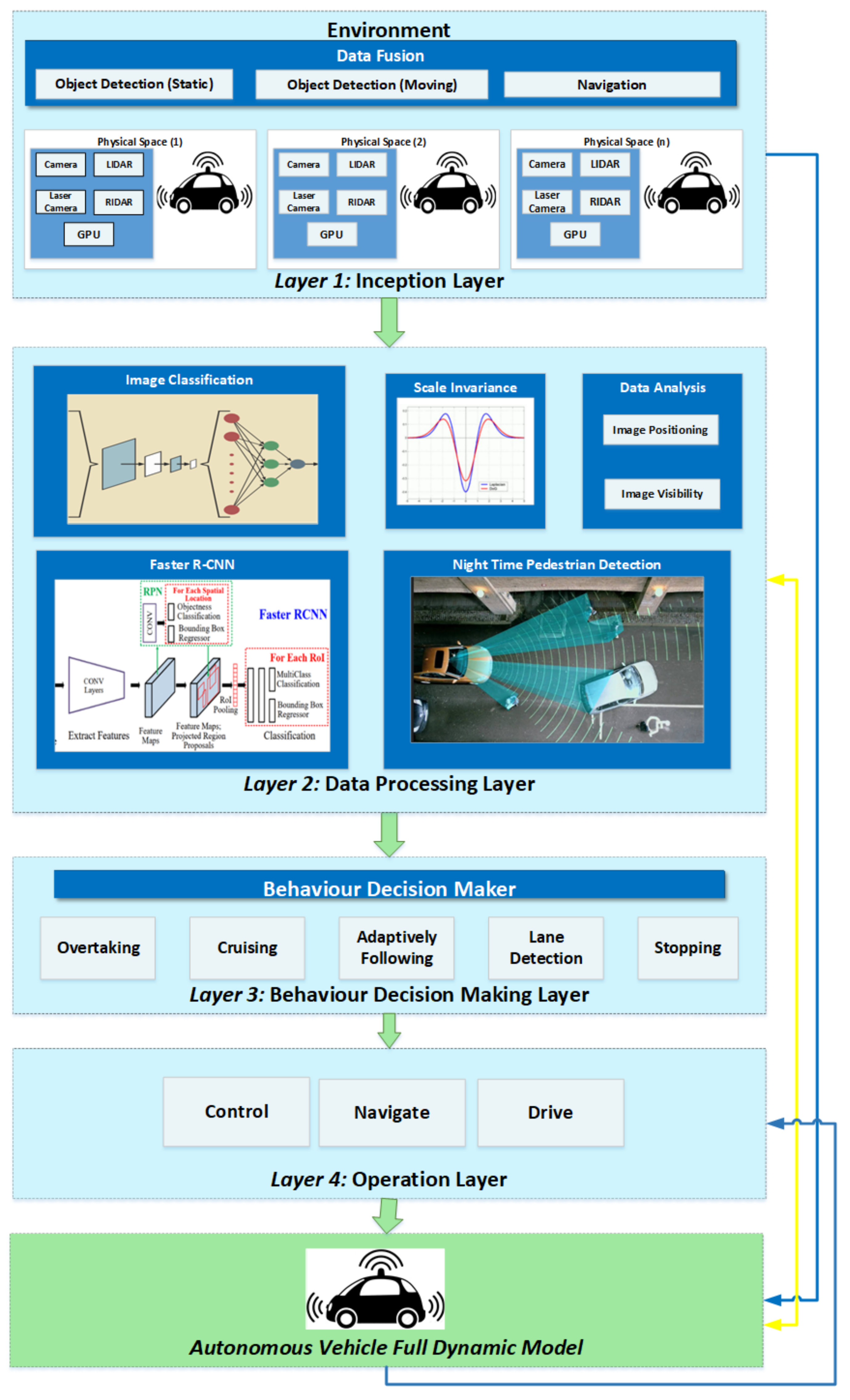
4. Proposed Framework and Architecture
4.1. Inception Layer
4.2. Data Processing Layer
4.2.1. Image Processing
4.2.2. Data Analysis
4.3. Behavior Decision Maker Layer
4.4. Operation Layer
4.5. Data Evaluation Algorithm
Random Sample Consensus (RANSAC) Algorithm
| Algorithm 1 Pseudo code for RANSAC Algorithm (Code Listing 1: RANSAC algorithm) |
| 1 Input: point set A = {ai | i = 1,...,p} |
| 2 Output: planes Pj = {pjk |k = 1,...,Q}: for j = 1,...,J |
| 3 j = 1; |
| 4 while (!area(B) < A){ |
| 5 m = 1; |
| 6 B = RANSAC Plane_Fitiing (A); |
| 7 C = Normal_Coherence_Check (B); |
| 8 D = Find_Largest-Patch (C); |
| 9 P = Patch_Number (C); |
| 10 if (area(D) = ?){ |
| 11 A = A − C; |
| 12 else{ |
| 13 while (area(D) > ? and m < M){ |
| 14 F = Iterative_Plane_Clustering (A,D); |
| 15 Pj = Find_Largest_Patch (F); |
| 16 A = A − Pj; C = C − D; |
| 17 D = Find _Largest_Patch (C); |
| 18 j = j + 1 ; m = m + 1; |
| 19 } |
| 20 } |
| 21 } |
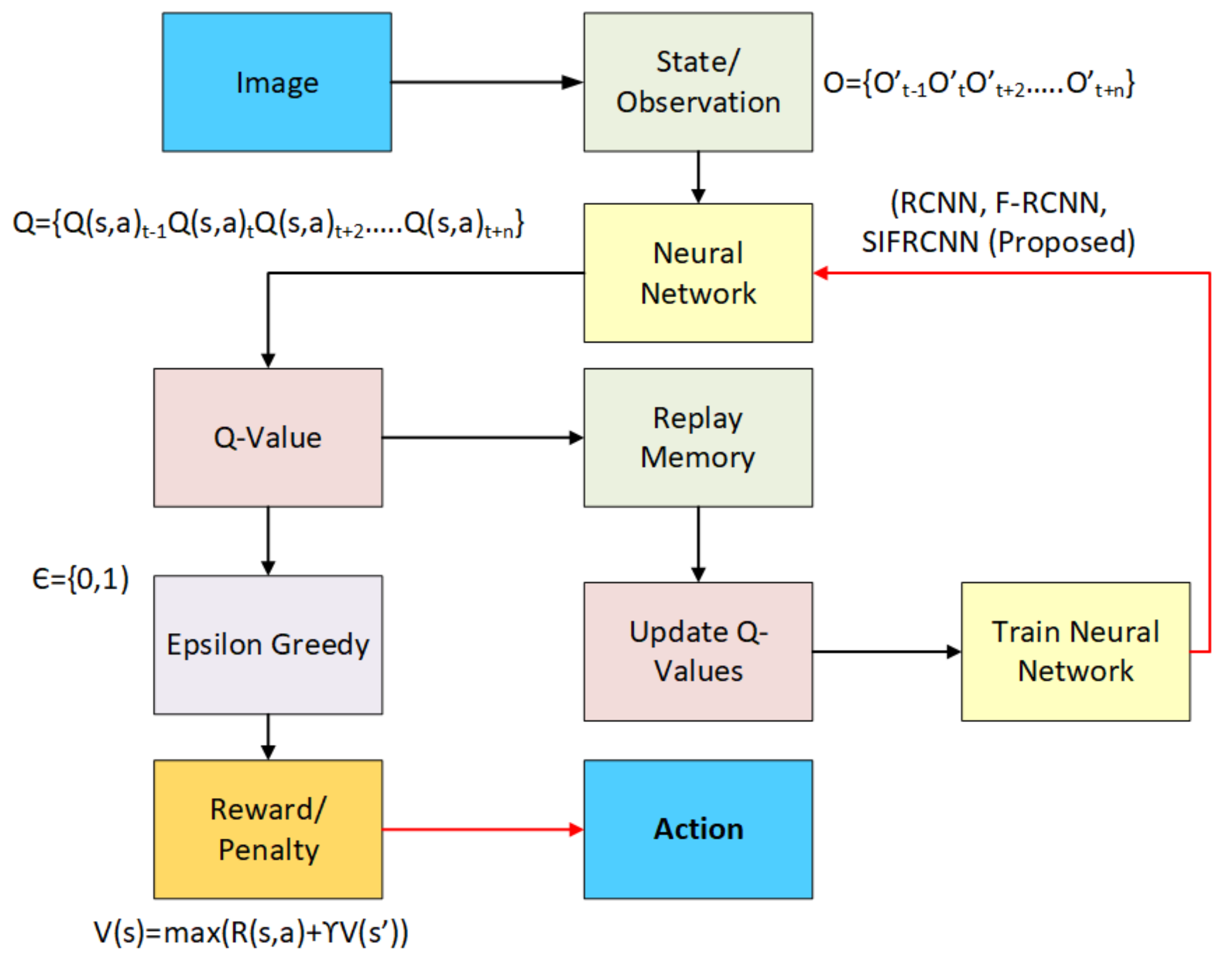
4.6. Reinforcement Learning for Autonomous Vehicles
Q-Learning Algorithm
| Algorithm 2 Pseudo code for learning algorithm for the selection of state action, policies, and rewards (Code Listing 2: Deep Q-learning algorithm) |
| 1 Initialize P (state, action) with some random value |
| 2 while (P! = terminal){ |
| 3 Initialize state |
| 4 While (state! = terminal){ |
| 5 Choose an action from the state by policy inferred from P |
| 6 Take action to action, observer, state’ |
| 7 P (state, action) ← P (state, action) + [r + max, |
| P (state’, action’) − P (state, action)] |
| 8 state ← state’ |
| 9 } |
| 10 } |
| Algorithm 3 Pseudo code for Vehicle controller Algorithm (Code Listing 3: Hand Crafted vehicle controller) |
| 1 vehicle-controller-policy (st){ |
| 2 vbrake ← 20 |
| 3 vmax ← 18 |
| 4 ɸthreshold ← 0.05 |
| 5 acc ← Do nothing |
| 6 steer ← Do nothing |
| 7 if (vt > brake){ |
| 8 acc ← Brake |
| 9 else if (vt < Vmax){ |
| 10 acc ← Accelerate |
| 11 else if (ɸt > ɸthreshold){ |
| 12 steer ← TurnLeft} |
| 13 else if (ɸt < −ɸthreshold){ |
| 14 steer ← TurnRight |
| 15 return (acc, steer) |
| 16 } |
| 17 } |
| 18 } |
| Algorithm 4 Reward function for the vehicle agent (Code Listing 4: Reward Function) |
| 1 REWARD (st, at){ |
| 2 vmin ← 5 |
| 3 vbrake ← 20 |
| 4 vmax ← 18 |
| 5 ɸthreshold ← 0.05 |
| 6 reward ← 0 |
| 7 if (vt > vbrake and acct = Brake){ |
| 8 reward ← reward + 1} |
| 9 else if (vt > vbrake and acct = accelerate){ |
| 10 reward ← reward − 1} |
| 11 else if (vt > vmax and acct = Brake){ |
| 12 reward ← reward − 1} |
| 13 else if (vt > vmax and acct = Accelerate){ |
| 14 reward ← reward + 1} |
| 15 else if (ɸt < −ɸthreshold and steer t = TurnRight){ |
| 16 reward ← reward + 1} |
| 17 else if (ɸt < −ɸthreshold and steer t = TurnLeft){ |
| 18 reward ← reward − 1} |
| 19 else if (ɸt > −ɸthreshold and steer t = TurnLeft){ |
| 20 reward ← reward + 1} |
| 21 else if (ɸt > ɸthreshold and steer t = TurnRight){ |
| 22 reward ← reward − 1} |
| 23 else if (vt < vmin and acct ≠ Accelerate){ |
| 24 reward ← reward − 1 |
| 25 return REWARD |
| 26 } |
5. Experiments and Results
5.1. Datasets
5.2. Training Details
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Kukkala, V.K.; Tunnell, J.; Pasricha, S.; Bradley, T. Advanced Driver-Assistance Systems: A Path Toward Autonomous Vehicles. IEEE Consum. Electron. Mag. 2018, 7, 18–25. [Google Scholar] [CrossRef]
- Ali, Y.; Zheng, Z.; Haque, M.M.; Yildirimoglu, M.; Washington, S. Detecting, analyzing, and modeling failed lane-changing attempts in traditional and connected environments. Anal. Methods Accid. Res. 2020, 28, 100138. [Google Scholar]
- Aranjuelo, N.; Unzueta, L.; Arganda-Carreras, I.; Otaegui, O. Multimodal deep learning for advanced driving systems. In Proceedings of the 10th International Conference on Articulated Motion and Deformable Objects (AMDO 2018), Palma de Mallorca, Spain, 12–13 July 2018; Springer: Cham, Switzerland, 2018; pp. 95–105. [Google Scholar]
- Arm. Accelerating Autonomous Vehicle Technology. 2020. Available online: https://spectrum.ieee.org/transportation/self-driving/accelerating-autonomous-vehicle-technology (accessed on 28 February 2021).
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3D object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Milakis, D.; van Wee, B. Implications of vehicle automation for accessibility and social inclusion of people on low income, people with physical and sensory disabilities, and older people. In Demand for Emerging Transportation Systems: Modeling Adoption, Satisfaction, and Mobility Patterns; Elsevier: Amsterdam, The Netherlands, 2020; pp. 61–73. [Google Scholar]
- Cui, G.; Wang, S.; Wang, Y.; Liu, Z.; Yuan, Y.; Wang, Q. Preceding Vehicle Detection Using Faster R-CNN Based on Speed Classification Random Anchor and Q-Square Penalty Coefficient. Electronics 2019, 8, 1024. [Google Scholar] [CrossRef]
- van der Heijden, R.; van Wees, K. Introducing advanced driver assistance systems: Some legal issues. Eur. J. Transp. Infrastruct. Res. 2019, 1, 309–326. [Google Scholar]
- Jarunakarint, V.; Uttama, S.; Rueangsirarak, W. Survey and Experimental Comparison of Machine Learning Models for Motorcycle Detection. In Proceedings of the 5th International Conference on Information Technology (InCIT), Chonburi, Thailand, 21–22 October 2020; pp. 320–325. [Google Scholar]
- Parvathi, S.; Selvi, S.T. Detection of maturity stages of coconuts in the complex background using Faster R-CNN model. Biosyst. Eng. 2021, 202, 119–132. [Google Scholar] [CrossRef]
- Mutzenich, C.; Durant, S.; Helman, S.; Dalton, P. Updating our understanding of situation awareness in relation to remote operators of autonomous vehicles. Cogn. Res. Princ. Implic. 2021, 6, 1–17. [Google Scholar] [CrossRef]
- Ivanov, A.M.; Shadrin, S.S. System of Requirements and Testing Procedures for Autonomous Driving Technologies. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 819, p. 012016. [Google Scholar]
- Lyu, N.; Duan, Z.; Xie, L.; Wu, C. Driving experience on the effectiveness of advanced driving assistant systems. In Proceedings of the 2017 4th International Conference on Transportation Information and Safety (ICTIS), Banff, AB, Canada, 8–10 August 2017; pp. 987–992. [Google Scholar]
- Synopsys. What is an Autonomous Car?—How Self-Driving Cars Work. Available online: https://www.synopsys.com/automotive/what-is-autonomous-car.html (accessed on 3 November 2022).
- Brazil, G.; Yin, X.; Liu, X. Illuminating pedestrians via simultaneous detection & segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4950–4959. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with regional proposed networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Meng, D.; Xu, S. Application of Railway Passenger Flow Statistics Based on Mask R-CNN. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2020; Volume 768, p. 075050. [Google Scholar]
- Wang, K.; Li, G.; Chen, J.; Long, Y.; Chen, T.; Chen, L.; Xias, Q. The adaptability and challenges of an autonomous vehicle to pedestrians in urban China. Accid. Anal. Prev. 2020, 145, 1–15. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, K.; Zhu, Z.; Wang, F.Y. Adversarial attacks on Faster R-CNN object detector. Neurocomputing 2020, 382, 87–95. [Google Scholar] [CrossRef]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric vision-based future vehicle localization for intelligent driving assistance systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9711–9717. [Google Scholar]
- Xu, Y.; Xiao, T.; Zhang, J.; Yang, K.; Zhang, Z. Scale-invariant convolutional neural networks. arXiv 2014, arXiv:1411.6369. [Google Scholar]
- Yudin, D.A.; Skrynnik, A.; Krishtopik, A.; Belkin, I.; Panov, A.I. Object Detection with Deep Neural Networks for Reinforcement Learning in the Task of Autonomous Vehicle Path Planning at the Intersection. Opt. Mem. Neural Netw. 2019, 28, 283–295. [Google Scholar] [CrossRef]
- Li, F.-F.; Andreeto, M.; Ranzato, M.; Perona, P. Caltech 101, version 1.0; CaltechDATA; Caltech Library: Pasadena, CA, USA, 2022. [Google Scholar] [CrossRef]
- Papers with Code—Caltech Pedestrian Dataset. Available online: https://paperswithcode.com/dataset/caltech-pedestrian-dataset (accessed on 7 November 2022).
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab AA, A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. arXiv 2020, arXiv:2002.00444. [Google Scholar] [CrossRef]
- Wang, K.; Zhou, W. Pedestrian and cyclist detection based on deep neural network fast R-CNN. Int. J. Adv. Robot. Syst. 2019, 16, 1–10. [Google Scholar] [CrossRef]
- Arooj, A.; Farooq, M.S.; Umer, T.; Rasool, G.; Wang, B. Cyber-Physical and Social Networks in IoV (CPSN-IoV): A Multimodal Architecture in Edge-Based Networks for Optimal Route Selection Using 5G Technologies. IEEE Access 2020, 8, 33609–33630. [Google Scholar] [CrossRef]
- Tehseen, R.; Farooq, M.S.; Abid, A. Earthquake prediction using expert systems: A systematic mapping study. Sustainability 2020, 12, 2420. [Google Scholar] [CrossRef]
- Khan, Y.D.; Khan, N.S.; Farooq, S.; Abid, A.; Khan, S.A.; Ahmad, F.; Mahmood, M.K. An efficient algorithm for recognition of human actions. Sci. World J. 2014, 2014, 875879. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Schiele, B. CityPersons: A Diverse Dataset for Pedestrian Detection. arXiv 2017, arXiv:1702.05693. [Google Scholar] [CrossRef]
- Papers with Code—CityPersons Dataset. Available online: https://paperswithcode.com/dataset/citypersons (accessed on 7 November 2022).
- Papers with Code—KAIST Multispectral Pedestrian Detection Benchmark Dataset. Available online: https://paperswithcode.com/dataset/kaist-multispectral-pedestrian-detection (accessed on 7 November 2022).
- Everett, M.; Chen, Y.F.; How, J.P. Collision avoidance in pedestrian-rich environments with deep reinforcement learning. IEEE Access 2021, 9, 10357–10377. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Wang, H.; Li, Y.; Wang, S. Fast pedestrian detection with attention-enhanced multi-scale RPN and soft-cascaded decision trees. IEEE Trans. Intell. Transp. Syst. 2019, 21, 5086–5093. [Google Scholar] [CrossRef]
- Moten, S.; Celiberti, F.; Grottoli, M.; van der Heide, A.; Lemmens, Y. X-in-the-loop advanced driving simulation platform for the design, development, testing and validation of ADAS. In Proceedings of the 2018 IEEE Intelligent Vehicle Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1–6. [Google Scholar]
- Szőke, L.; Aradi, S.; Bécsi, T.; Gáspár, P. Driving on Highway by Using Reinforcement Learning with CNN and LSTM Networks. In Proceedings of the 2020 IEEE 24th International Conference on Intelligent Engineering Systems (INES), Reykjavik, Iceland, 8–10 July 2020; pp. 121–126. [Google Scholar]
- Jiang, M.; Hai, T.; Pan, Z.; Wang, H.; Jia, Y.; Deng, C. Multi-agent deep reinforcement learning for the multi-object tracker. IEEE Access 2019, 7, 32400–32407. [Google Scholar] [CrossRef]
- Liu, Y.; Su, H.; Zeng, C.; Li, X. A robust thermal infrared vehicle and pedestrian detection method in complex scenes. Sensors 2021, 21, 1240. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technical Issues | Proposed Solution | Implemented in SIFRCNN by |
|---|---|---|
| Camera related Problems | Heterogeneous Feature Extraction | IoU, Restnet V2 |
| Camera Motion issues | Image stabilization | IoU, ImageNet |
| Object Deformations | Visual Segmentation | Scale Invariance Feature |
| Abrupt Motion detection | Intelligent detection Method | ROI, RPN |
| Background Scaling | Dynamic modeling Method | IoU, RPN, RCNN, Faster RCNN |
| Automated Task | Description |
|---|---|
| Motion planning | The vehicle learning agent learned to plan the trajectory and minimize the cost function to obtain smooth control behavior. |
| Overtaking | DRL has been used to learn an overtaking policy while avoiding accidents with pedestrians. |
| Lane keep | =RL system ensures that the vehicle follows the lane. Continuous action provided a smoother path to learning, while more limited conditions were slow the vehicle agent learning. |
| Lane change | When changing the lane or accelerating, Q-learning is used to learn which path to be followed. |
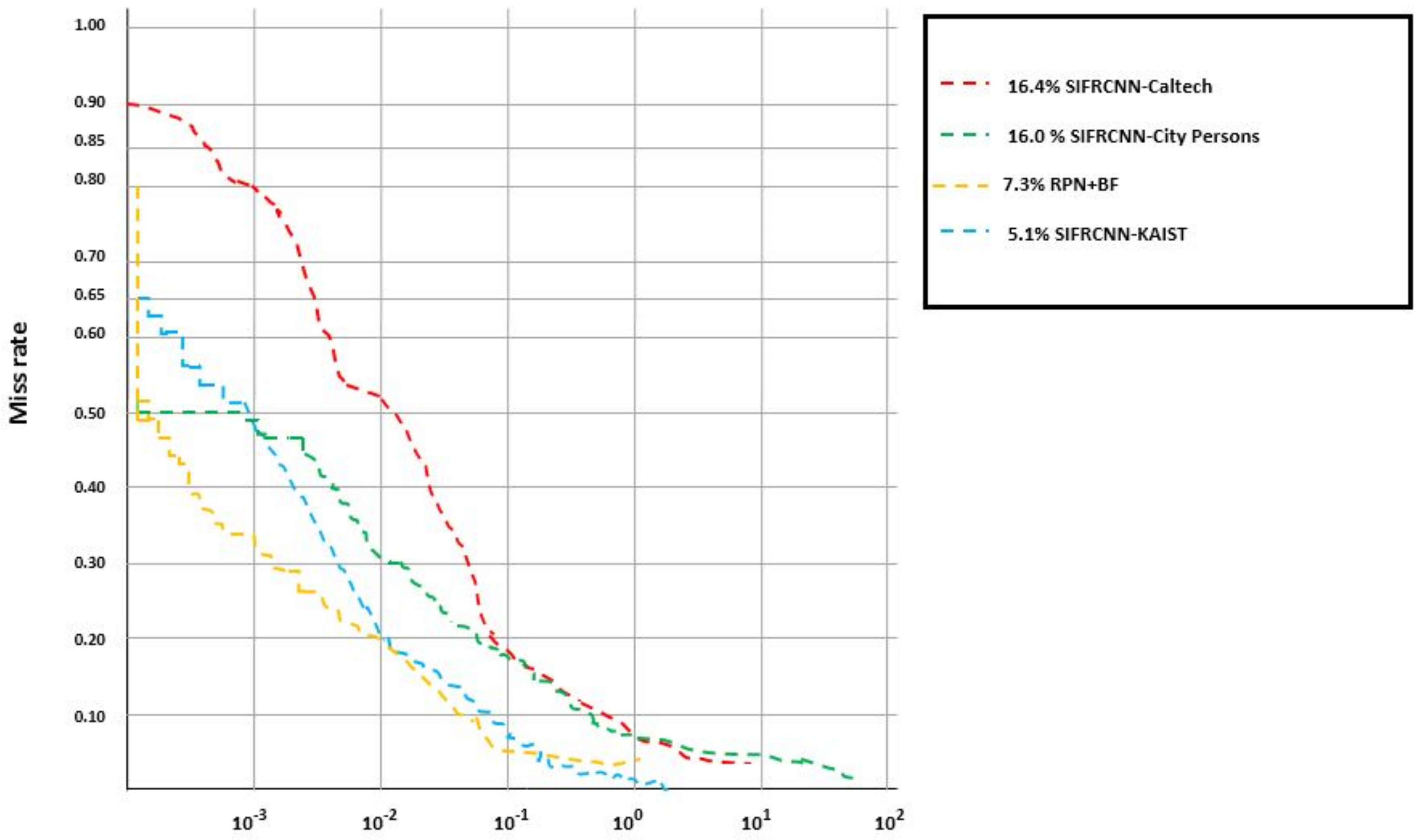
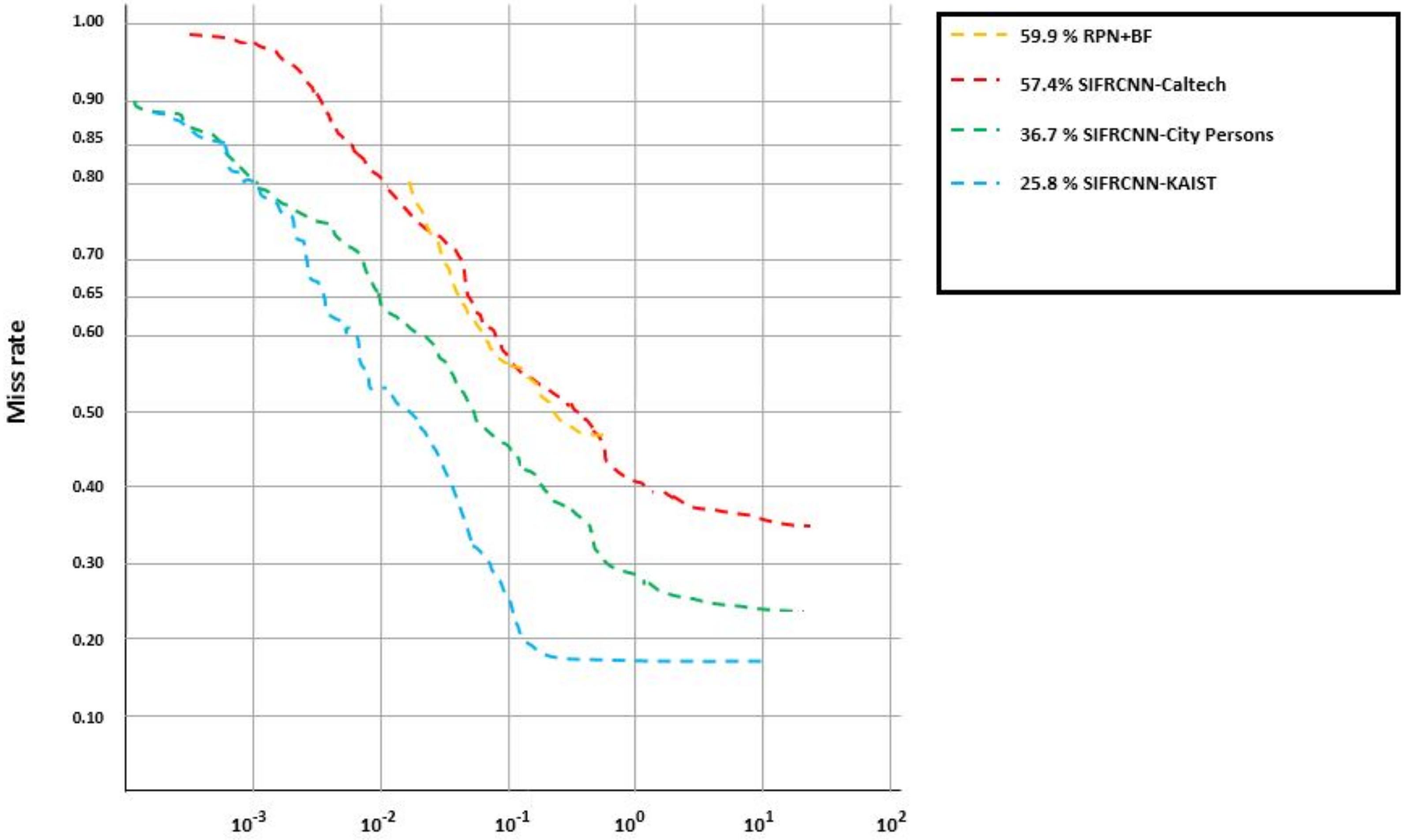
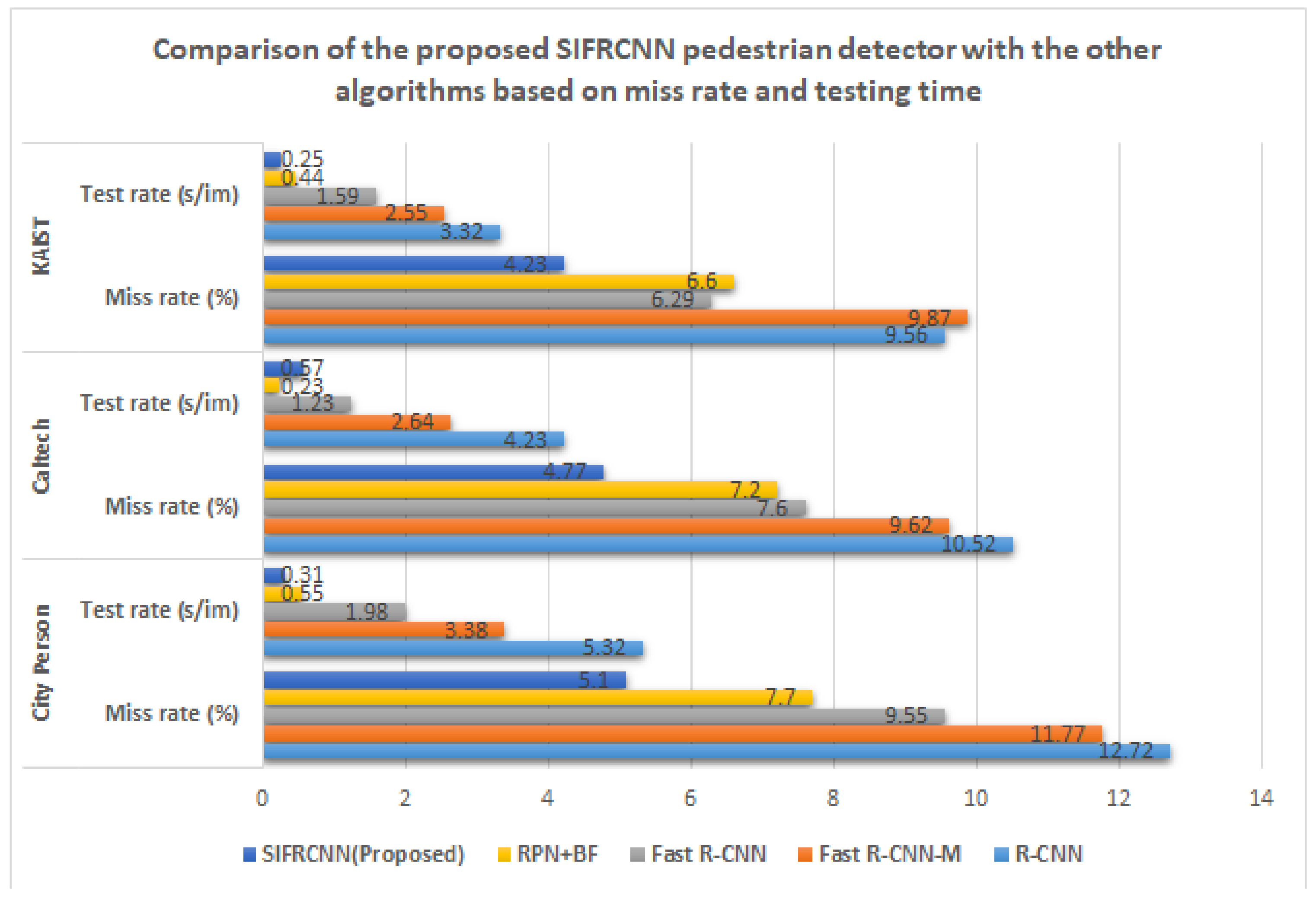
| Dataset | Method | R-CNN | Fast RCNN-M | Fast R-CNN | RPN+BF | SIFRCNN (Proposed) |
|---|---|---|---|---|---|---|
| City Person | Miss rate (%) | 12.72 | 11.77 | 9.55 | 7.7 | 5.1 |
| Test rate (s/im) | 5.32 | 3.38 | 1.98 | 0.55 | 0.31 | |
| Caltech | Miss rate (%) | 10.52 | 9.62 | 7.60 | 7.2 | 4.77 |
| Test rate (s/im) | 4.23 | 2.64 | 1.23 | 0.23 | 0.57 | |
| KAIST | Miss rate (%) | 9.56 | 9.87 | 6.29 | 6.6 | 4.23 |
| Test rate (s/im) | 3.32 | 2.55 | 1.59 | 0.44 | 0.25 |
| Dataset | Method | Anchor Scale | Small (mAP%) | Large (mAP%) | IoU |
|---|---|---|---|---|---|
| City Person | RCNN | 128 256 512 | 10.11% | 35.12% | 0.3 |
| 64 128 256 | 16.11% | 32.57% | 0.44 | ||
| 16 64 128 | 15.80% | 31.63% | 0.68 | ||
| Faster RCNN-M | 128 256 512 | 12.56% | 29.66% | 0.23 | |
| 64 128 256 | 16.33% | 28.32% | 0.56 | ||
| 16 64 128 | 12.99% | 33.80% | 0.3 | ||
| Faster RCNN | 128 256 512 | 19.23% | 22.23% | 0.5 | |
| 64 128 256 | 11.25% | 30.33% | 0.53 | ||
| 16 64 128 | 11.02% | 20.33% | 0.63 | ||
| RPN+BF | 128 256 512 | 10.23% | 33.20% | 0.31 | |
| 64 128 256 | 18.66% | 38.22% | 0.44 | ||
| 16 64 128 | 18.23% | 35.00% | 0.5 | ||
| SIFRCNN (Proposed) | 128 256 512 | 35.44% | 59.63% | 0.79 | |
| 64 128 256 | 60.55% | 60.59% | 0.8 | ||
| 16 64 128 | 66.35% | 62.56% | 0.76 | ||
| Caltech | RCNN | 128 256 512 | 25.00% | 38.30% | 0.5 |
| 64 128 256 | 28.20% | 40.55% | 0.2 | ||
| 16 64 128 | 18.50% | 33.65% | 0.37 | ||
| Faster RCNN-M | 128 256 512 | 10.22% | 34.50% | 0.4 | |
| 64 128 256 | 29.78% | 35.90% | 0.3 | ||
| 16 64 128 | 19.36% | 44.20% | 0.25 | ||
| Faster RCNN | 128 256 512 | 18.22% | 39.50% | 0.22 | |
| 64 128 256 | 13.05% | 29.60% | 0.44 | ||
| 16 64 128 | 18.23% | 41.02% | 0.38 | ||
| RPN+BF | 128 256 512 | 13.08% | 35.02% | 0.5 | |
| 64 128 256 | 29.88% | 28.80% | 0.49 | ||
| 16 64 128 | 18.50% | 25.60% | 0.35 | ||
| SIFRCNN (Proposed) | 128 256 512 | 39.20% | 58.23% | 0.81 | |
| 64 128 256 | 62.33% | 74.25% | 0.79 | ||
| 16 64 128 | 71.20% | 69.23% | 0.8 | ||
| KAIST | RCNN | 128 256 512 | 25.25% | 35.60% | 0.4 |
| 64 128 256 | 20.36% | 45.30% | 0.2 | ||
| 16 64 128 | 29.20% | 42.10% | 0.3 | ||
| Faster RCNN-M | 128 256 512 | 27.20% | 39.70% | 0.32 | |
| 64 128 256 | 32.20% | 44.50% | 0.28 | ||
| 16 64 128 | 37.50% | 49.00% | 0.49 | ||
| Faster RCNN | 128 256 512 | 29.90% | 33.67% | 0.5 | |
| 64 128 256 | 18.50% | 28.30% | 0.4 | ||
| 16 64 128 | 18.90% | 29.40% | 0.19 | ||
| RPN+BF | 128 256 512 | 19.62% | 34.02% | 0.25 | |
| 64 128 256 | 22.20% | 30.12% | 0.36 | ||
| 16 64 128 | 18.50% | 27.60% | 0.41 | ||
| SIFRCNN (Proposed) | 128 256 512 | 38.25% | 60.33% | 0.78 | |
| 64 128 256 | 78.22% | 60.58% | 0.87 | ||
| 16 64 128 | 69.90% | 70.09% | 0.79 |
| Hardware Specification for Validation | |
|---|---|
| System | Intel Core i9 |
| RAM | 16 GB |
| Graphics | NVIDIA RTX 2060 |
| HDD | 500 GB 7200 rpm |
| Process | Dataset | Time of Image Capturing | Total Images | Training Images | Testing Images | Total Pedestrian Detected |
|---|---|---|---|---|---|---|
| Origina training data | CityPerson | Daytime | 14,523 | 10,166 | 4357 | 18,233 |
| Caltech | Daytime | 15,840 | 11,088 | 4752 | 26,290 | |
| KAIST | Nighttime | 976 | 683 | 293 | 2166 | |
| Augmented data | CityPerson | Nighttime | 12,266 | 8586 | 3680 | 1856 |
| Caltech | Nighttime | 1584 | 1109 | 475 | 2629 | |
| KAIST | Nighttime | 828 | 580 | 248 | 1328 | |
| Validating data | CityPerson | Daytime | 489 | 342 | 147 | 1877 |
| Caltech | Nighttime | 300 | 210 | 90 | 62 | |
| KAIST | Nighttime | 797 | 558 | 239 | 399 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farooq, M.S.; Khalid, H.; Arooj, A.; Umer, T.; Asghar, A.B.; Rasheed, J.; Shubair, R.M.; Yahyaoui, A. A Conceptual Multi-Layer Framework for the Detection of Nighttime Pedestrian in Autonomous Vehicles Using Deep Reinforcement Learning. Entropy 2023, 25, 135. https://doi.org/10.3390/e25010135
Farooq MS, Khalid H, Arooj A, Umer T, Asghar AB, Rasheed J, Shubair RM, Yahyaoui A. A Conceptual Multi-Layer Framework for the Detection of Nighttime Pedestrian in Autonomous Vehicles Using Deep Reinforcement Learning. Entropy. 2023; 25(1):135. https://doi.org/10.3390/e25010135
Chicago/Turabian StyleFarooq, Muhammad Shoaib, Haris Khalid, Ansif Arooj, Tariq Umer, Aamer Bilal Asghar, Jawad Rasheed, Raed M. Shubair, and Amani Yahyaoui. 2023. "A Conceptual Multi-Layer Framework for the Detection of Nighttime Pedestrian in Autonomous Vehicles Using Deep Reinforcement Learning" Entropy 25, no. 1: 135. https://doi.org/10.3390/e25010135
APA StyleFarooq, M. S., Khalid, H., Arooj, A., Umer, T., Asghar, A. B., Rasheed, J., Shubair, R. M., & Yahyaoui, A. (2023). A Conceptual Multi-Layer Framework for the Detection of Nighttime Pedestrian in Autonomous Vehicles Using Deep Reinforcement Learning. Entropy, 25(1), 135. https://doi.org/10.3390/e25010135