




Local Intrinsic Dimensionality, Entropy and Statistical Divergences



Abstract
:1. Introduction
- For univariate scenarios, if working with the tail of a distribution that has a single variable, we can conduct:
- –
- Temporal analysis: when a distribution models some property varying over time (e.g., survival analysis), we can analyze the entropy of a univariate distribution within an asymptotically short window of time, or the divergence between two univariate distributions within an asymptotically short window of time.
- –
- Distance-based analysis: when a distribution models distances from a query location to its nearest neighbors and the distances are induced by a global data distribution. Here, our results can be used for analysis of tail entropy or divergence between distributions within an asymptotically small distance interval. In the case of the latter, this can provide insight into multivariate properties, since under minimal assumptions the divergences between univariate distance distributions provide lower bounds for distances between multivariate distributions [4,5]. This is applicable for models such as generative adversarial networks (GANs), where it is important to test correspondence between synthetic and true distributions at a local level [6].
- For multivariate scenarios where we are analyzing distributions with multiple variables:
- –
- If an assumption of locally spherical symmetry of the distribution holds, then we can directly compute the tail entropy of a distribution or the divergence between two tail distributions in the vicinity of a single point. Such an assumption is suitable for analyzing data distributions for many types of physical systems such as fluids, glasses, metals and polymers, where local isotropy holds.
- Formulate technical lemmas which delineate when it is possible to substitute certain types of tail distributions by simple formulations that depend only on their associated LID values.
- Use these lemmas to compute univariate tail formulations of entropy, cross entropy, cumulative entropy, entropy power and generalized q-entropies, all in terms of the LID values of the original tail distributions.
- Use these lemmas to compute tail formulations of univariate statistical divergences and distances (Kullback–Leibler divergence, Jensen–Shannon divergence, Hellinger distance, divergence, -divergence, Wasserstein distance and distance).
- Extend the univariate results to a multivariate context, when local spherical symmetry of the distribution holds.
2. Related Work
3. Local Intrinsic Dimensionality
4. Definitions of Tail Entropies and Tail Dissimilarity Measures
- There exists a value such that F is monotonically increasing over ;
- F is continuous over ;
- F is differentiable over ; and
- The local intrinsic dimensionality exists and is positive.
- It can be interpreted as a diversity. Observe that when F is a (univariate) uniform distance distribution ranging over the interval , we have and . In other words, the entropy power is equal to the ‘effective diversity’ of the distribution (the number of neighbor distance possibilities).
- Given two different queries, each with its own neighborhood, one query with tail entropy power equal to 2 and the other with tail entropy power equal to 4, we can say that the distance distribution of the second query is twice as diverse as that of the first query.
5. Simplification of Tail Measures
- ;
- ; and
- for all fixed choices of t and w satisfying , is monotone and continuously partially differentiable with respect to z over the interval .
- ;
- for all , where is restricted to values of t in ; and
- for all fixed choices of u and w satisfying and , is monotone and continuously partially differentiable with respect to z over the interval .
- ;
- , and
- there exists a value such that for all fixed choices of t satisfying , is monotone with respect to z over the interval .
6. Derivation of the Limits of Tail Measures
6.1. Handling Derivatives of Smooth Growth Functions
6.2. Substitution of LID Functions by Constants
6.3. Elimination of Tail-Conditioned Smooth Growth Functions
6.4. Elimination of the Inverses of Tail-Conditioned Smooth Growth Functions
6.5. Normalization
6.6. Summary of Results
7. Extension to Multivariate Distributions
7.1. Multivariate Tail Distributions with Local Spherical Symmetry
7.2. Multivariate Tail Entropy Variants
7.3. Multivariate Cumulative Tail Entropy
7.4. Multivariate Tail Divergences
7.5. Observations
- A result for the Wasserstein Distance is not included, since its formulation does not generalize straightforwardly to higher dimensions, unlike the other divergence measures.
- The normalizations and weightings used depend only on the tail volume and (for the Tsallis entropy variants) the parameter q. This generalizes our earlier univariate results where normalization was performed with regard to the tail length w.
- All the multivariate tail variants considered Table 6 are elegant generalizations of their corresponding univariate formulations, and all explicitly depend on the ratios between the LIDs and the dimension of the space n ( and ), or on the ratio of two LID values (). Among these, the Normalized Entropy Power and the Normalized Cumulative Entropy are maximized when , which can occur when the tail distribution is uniform. The Varentropy is minimized when , which can occur when the variance of the log-likelihood for a uniform distribution is equal to zero.
- As mentioned in Related Work, a number of previous studies in deep learning have found that the local intrinsic dimension in learned representations is lower than the dimension of the full space [32,33,34,35] (i.e., ) and that the learning process progressively reduces local intrinsic dimension. Consider a concrete example where and and the learning process is reducing at a point from 12 to 11. The consequent effect on entropy can be interpreted from two different perspectives, either as an increase in tail distance entropy or a decrease in tail location entropy:
- Considering univariate normalized entropy power or normalized cumulative entropy (Table 1), reduction of corresponds to an increase in entropy. Here, the entropy is measuring the uncertainty of the univariate random variable modeling distances to nearest neighbors. Thus, reduction of corresponds to an increase in “distance entropy”.
- Considering multivariate normalized entropy power or multivariate normalized cumulative entropy (Table 6), reduction of corresponds to an decrease in entropy. Here, the entropy is measuring the uncertainty of the multivariate random variable modeling locations of nearest neighbors, assuming local spherical symmetry. So reduction of corresponds to a decrease in “location entropy”.
- 5.
- All four of the multivariate tail divergences listed in Table 6, as well as the Hellinger Distance, have radial integral formulations that are identical to their univariate counterparts. All the divergences and distances (including the Weighted L2 Distance) are minimized when .
- 6.
- By setting , we can recover the univariate results from Table 1. However, note that the range of integration used in Table 6 is a hypersphere of radius w, where for it is the interval . In contrast, the integral formulations listed in Table 1 were taken over the interval . For some results, this means a minor (constant factor of 2) difference between Table 1 and the result from Table 6 when .
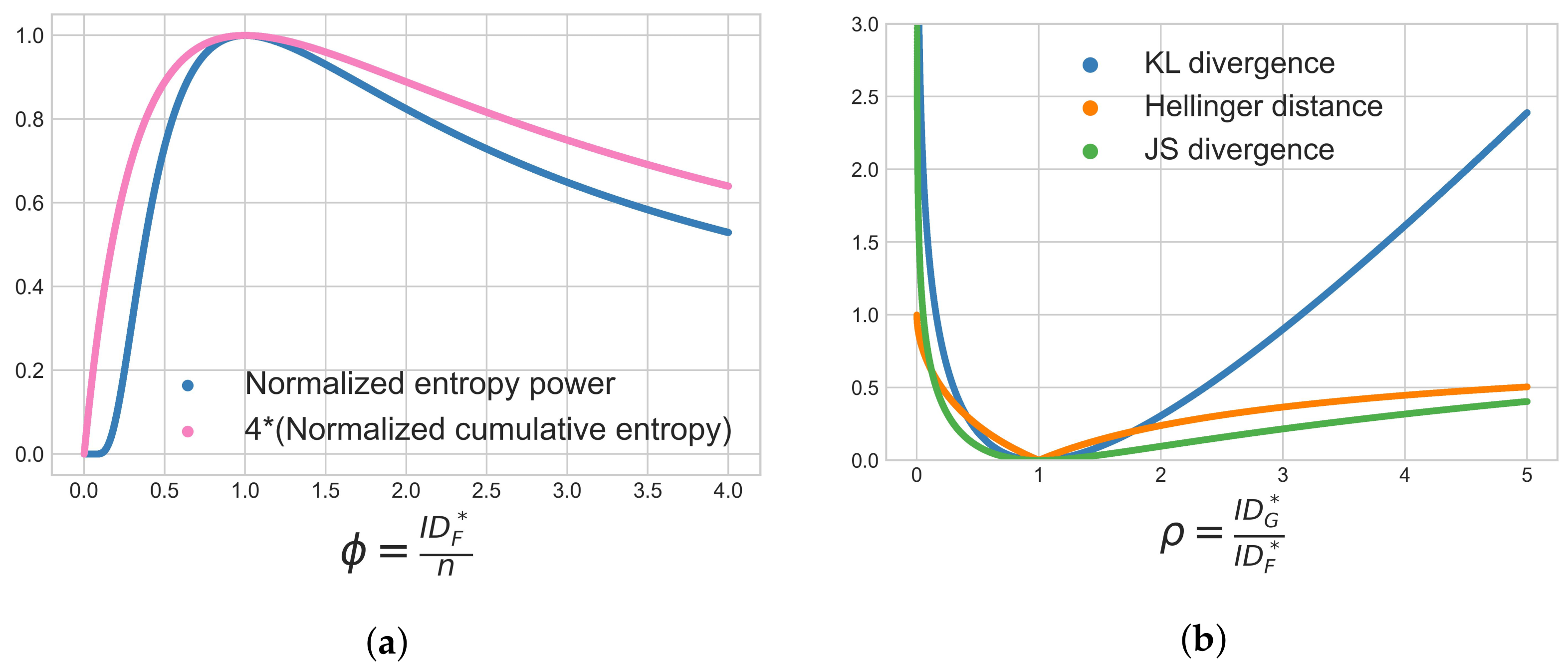
7.6. Visualization of Behavior
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Basseville, M. Divergence measures for statistical data processing—An annotated bibliography. Signal Process. 2013, 93, 621–633. [Google Scholar] [CrossRef]
- Houle, M.E. Local Intrinsic Dimensionality I: An Extreme-Value-Theoretic Foundation for Similarity Applications. In Proceedings of the International Conference on Similarity Search and Applications, Munich, Germany, 4–6 October 2017; pp. 64–79. [Google Scholar]
- Bailey, J.; Houle, M.E.; Ma, X. Relationships Between Local Intrinsic Dimensionality and Tail Entropy. In Proceedings of the Similarity Search and Applications—Proc. of the 14th International Conference, SISAP 2021, Dortmund, Germany, 29 September–1 October 2021. [Google Scholar]
- Heller, R.; Heller, Y. Multivariate tests of association based on univariate tests. In Advances in Neural Information Processing Systems 29 (NIPS 2016); Lee, D.D., Sugiyama, M., von Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 208–216. [Google Scholar]
- Maa, J.; Pearl, D.; Bartoszynski, R. Reducing multidimensional two-sample data to one-dimensional interpoint comparisons. Ann. Stat. 1996, 24, 1069–1074. [Google Scholar] [CrossRef]
- Li, A.; Qi, J.; Zhang, R.; Ma, X.; Ramamohanarao, K. Generative image inpainting with submanifold alignment. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, Hong Kong, 10–16 August 2019; pp. 811–817. [Google Scholar]
- Camastra, F.; Staiano, A. Intrinsic dimension estimation: Advances and open problems. Inf. Sci. 2016, 328, 26–41. [Google Scholar] [CrossRef]
- Campadelli, P.; Casiraghi, E.; Ceruti, C.; Rozza, A. Intrinsic Dimension Estimation: Relevant Techniques and a Benchmark Framework. Math. Probl. Eng. 2015, 2015, 759567. [Google Scholar] [CrossRef]
- Verveer, P.J.; Duin, R.P.W. An evaluation of intrinsic dimensionality estimators. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 81–86. [Google Scholar] [CrossRef]
- Bruske, J.; Sommer, G. Intrinsic dimensionality estimation with optimally topology preserving maps. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 572–575. [Google Scholar] [CrossRef]
- Pettis, K.W.; Bailey, T.A.; Jain, A.K.; Dubes, R.C. An intrinsic dimensionality estimator from near-neighbor information. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 25–37. [Google Scholar] [CrossRef]
- Navarro, G.; Paredes, R.; Reyes, N.; Bustos, C. An empirical evaluation of intrinsic dimension estimators. Inf. Syst. 2017, 64, 206–218. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Costa, J.A.; Hero III, A.O. Entropic Graphs for Manifold Learning. In Proceedings of the 37th Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 1, pp. 316–320. [Google Scholar]
- Hein, M.; Audibert, J.Y. Intrinsic dimensionality estimation of submanifolds in Rd. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 289–296. [Google Scholar]
- Rozza, A.; Lombardi, G.; Rosa, M.; Casiraghi, E.; Campadelli, P. IDEA: Intrinsic Dimension Estimation Algorithm. In Proceedings of the International Conference on Image Analysis and Processing, Ravenna, Italy, 14–16 September 2011; pp. 433–442. [Google Scholar]
- Rozza, A.; Lombardi, G.; Ceruti, C.; Casiraghi, E.; Campadelli, P. Novel High Intrinsic Dimensionality Estimators. Mach. Learn. 2012, 89, 37–65. [Google Scholar] [CrossRef]
- Ceruti, C.; Bassis, S.; Rozza, A.; Lombardi, G.; Casiraghi, E.; Campadelli, P. DANCo: An intrinsic dimensionality estimator exploiting angle and norm concentration. Pattern Recognit. 2014, 47, 2569–2581. [Google Scholar] [CrossRef]
- Facco, E.; d’Errico, M.; Rodriguez, A.; Laio, A. Estimating the intrinsic dimension of datasets by a minimal neighborhood information. Sci. Rep. 2017, 7, 12140. [Google Scholar] [CrossRef]
- Zhou, S.; Tordesillas, A.; Pouragha, M.; Bailey, J.; Bondell, H. On local intrinsic dimensionality of deformation in complex materials. Nat. Sci. Rep. 2021, 11, 10216. [Google Scholar] [CrossRef]
- Tordesillas, A.; Zhou, S.; Bailey, J.; Bondell, H. A representation learning framework for detection and characterization of dead versus strain localization zones from pre- to post- failure. Granul. Matter 2022, 24, 75. [Google Scholar] [CrossRef]
- Faranda, D.; Messori, G.; Yiou, P. Dynamical proxies of North Atlantic predictability and extremes. Sci. Rep. 2017, 7, 41278. [Google Scholar] [CrossRef]
- Messori, G.; Harnik, N.; Madonna, E.; Lachmy, O.; Faranda, D. A dynamical systems characterization of atmospheric jet regimes. Earth Syst. Dynam. 2021, 12, 233–251. [Google Scholar] [CrossRef]
- Kambhatla, N.; Leen, T.K. Dimension Reduction by Local Principal Component Analysis. Neural Comput. 1997, 9, 1493–1516. [Google Scholar] [CrossRef]
- Houle, M.E.; Ma, X.; Nett, M.; Oria, V. Dimensional Testing for Multi-Step Similarity Search. In Proceedings of the IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 299–308. [Google Scholar]
- Campadelli, P.; Casiraghi, E.; Ceruti, C.; Lombardi, G.; Rozza, A. Local Intrinsic Dimensionality Based Features for Clustering. In Proceedings of the International Conference on Image Analysis and Processing, Naples, Italy, 9–13 September 2013; pp. 41–50. [Google Scholar]
- Houle, M.E.; Schubert, E.; Zimek, A. On the correlation between local intrinsic dimensionality and outlierness. In Proceedings of the International Conference on Similarity Search and Applications, Lima, Peru, 7–9 October 2018; pp. 177–191. [Google Scholar]
- Carter, K.M.; Raich, R.; Finn, W.G.; Hero, A.O., III. FINE: Fisher Information Non-parametric Embedding. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2093–2098. [Google Scholar] [CrossRef]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.N.R.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–15. [Google Scholar]
- Amsaleg, L.; Bailey, J.; Barbe, D.; Erfani, S.M.; Houle, M.E.; Nguyen, V.; Radovanović, M. The Vulnerability of Learning to Adversarial Perturbation Increases with Intrinsic Dimensionality. In Proceedings of the IEEE Workshop on Information Forensics and Security, Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- Amsaleg, L.; Bailey, J.; Barbe, A.; Erfani, S.M.; Furon, T.; Houle, M.E.; Radovanović, M.; Nguyen, X.V. High Intrinsic Dimensionality Facilitates Adversarial Attack: Theoretical Evidence. IEEE Trans. Inf. Forensics Secur. 2021, 16, 854–865. [Google Scholar] [CrossRef]
- Ma, X.; Wang, Y.; Houle, M.E.; Zhou, S.; Erfani, S.M.; Xia, S.; Wijewickrema, S.N.R.; Bailey, J. Dimensionality-Driven Learning with Noisy Labels. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3361–3370. [Google Scholar]
- Ansuini, A.; Laio, A.; Macke, J.H.; Zoccolan, D. Intrinsic dimension of data representations in deep neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 6111–6122. [Google Scholar]
- Pope, P.; Zhu, C.; Abdelkader, A.; Goldblum, M.; Goldstein, T. The intrinsic dimension of images and its impact on learning. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Gong, S.; Boddeti, V.N.; Jain, A.K. On the intrinsic dimensionality of image representations. In Proceedings of the CVPR, Long Beach, CA, USA, 5–20 June 2019; pp. 3987–3996. [Google Scholar]
- Barua, S.; Ma, X.; Erfani, S.M.; Houle, M.H.; Bailey, J. Quality Evaluation of GANs Using Cross Local Intrinsic Dimensionality. arXiv 2019, arXiv:1905.00643. [Google Scholar]
- Romano, S.; Chelly, O.; Nguyen, V.; Bailey, J.; Houle, M.E. Measuring Dependency via Intrinsic Dimensionality. In Proceedings of the ICPR16, Cancun, Mexico, 4–8 December 2016; pp. 1207–1212. [Google Scholar]
- Lucarini, V.; Faranda, D.; de Freitas, A.; de Freitas, J.; Holland, M.; Kuna, T.; Nicol, M.; Todd, M.; Vaienti, S. Extremes and Recurrence in Dynamical Systems; Pure and Applied Mathematics: A Wiley Series of Texts, Monographs and Tracts; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Levina, E.; Bickel, P.J. Maximum Likelihood Estimation of Intrinsic Dimension. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004; pp. 777–784. [Google Scholar]
- Amsaleg, L.; Chelly, O.; Furon, T.; Girard, S.; Houle, M.E.; Kawarabayashi, K.; Nett, M. Extreme-Value-Theoretic Estimation of Local Intrinsic Dimensionality. Data Min. Knowl. Discov. 2018, 32, 1768–1805. [Google Scholar] [CrossRef]
- Hill, B.M. A Simple General Approach to Inference About the Tail of a Distribution. Ann. Stat. 1975, 3, 1163–1174. [Google Scholar] [CrossRef]
- Johnsson, K.; Soneson, C.; Fontes, M. Low bias local intrinsic dimension estimation from expected simplex skewness. IEEE TPAMI 2015, 37, 196–202. [Google Scholar] [CrossRef] [PubMed]
- Amsaleg, L.; Chelly, O.; Houle, M.E.; Kawarabayashi, K.; Radovanović, R.; Treeratanajaru, W. Intrinsic dimensionality estimation within tight localities. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 181–189. [Google Scholar]
- Farahmand, A.M.; Szepesvári, C.; Audibert, J.Y. Manifold-adaptive dimension estimation. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 265–272. [Google Scholar]
- Block, A.; Jia, Z.; Polyanskiy, Y.; Rakhlin, A. Intrinsic Dimension Estimation Using Wasserstein Distances. arXiv 2021, arXiv:2106.04018. [Google Scholar]
- Thordsen, E.; Schubert, E. ABID: Angle Based Intrinsic Dimensionality—Theory and analysis. Inf. Syst. 2022, 108, 101989. [Google Scholar] [CrossRef]
- Carter, K.M.; Raich, R.; Hero III, A.O. On Local Intrinsic Dimension Estimation and Its Applications. IEEE Trans. Signal Process. 2010, 58, 650–663. [Google Scholar] [CrossRef]
- Tempczyk, P.; Golinski, A.; Spurek, P.; Tabor, J. LIDL: Local Intrinsic Dimension estimation using approximate Likelihood. In Proceedings of the ICLR 2021 Workshop on Geometrical and Topological Representation Learning, Online, 7 May 2021. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing); Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Rioul, O. Information Theoretic Proofs of Entropy Power Inequalities. IEEE Trans. Inf. Theory 2011, 57, 33–55. [Google Scholar] [CrossRef]
- Jelinek, F.; Mercer, R.L.; Bahl, L.R.; Baker, J.K. Perplexity—A measure of the difficulty of speech recognition tasks. J. Acoust. Soc. Am. 1977, 62, S63. [Google Scholar] [CrossRef]
- Jost, L. Entropy and diversity. Oikos 2006, 113, 363–375. [Google Scholar] [CrossRef]
- Kostal, L.; Lansky, P.; Pokora, O. Measures of statistical dispersion based on Shannon and Fisher information concepts. Inf. Sci. 2013, 235, 214–223. [Google Scholar] [CrossRef]
- Stam, A.J. Some inequalities satisfied by the quantities of information of Fisher and Shannon. Inf. Control. 1959, 2, 101–112. [Google Scholar] [CrossRef]
- Di Crescenzo, A.; Longobardi, M. On cumulative entropies. J. Stat. Plan. Inference 2009, 139, 4072–4087. [Google Scholar] [CrossRef]
- Rao, M.; Chen, Y.; Vemuri, B.C.; Wang, F. Cumulative residual entropy: A new measure of information. IEEE Trans. Inf. Theory 2004, 50, 1220–1228. [Google Scholar] [CrossRef]
- Nguyen, H.V.; Mandros, P.; Vreeken, J. Universal Dependency Analysis. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 792–800. [Google Scholar] [CrossRef]
- Böhm, K.; Keller, F.; Müller, E.; Nguyen, H.V.; Vreeken, J. CMI: An Information-Theoretic Contrast Measure for Enhancing Subspace Cluster and Outlier Detection. In Proceedings of the 13th SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013; pp. 198–206. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Calì, C.; Longobardi, M.; Ahmadi, J. Some properties of cumulative Tsallis entropy. Phys. A Stat. Mech. Its Appl. 2017, 486, 1012–1021. [Google Scholar] [CrossRef]
- Pele, D.T.; Lazar, E.; Mazurencu-Marinescu-Pele, M. Modeling Expected Shortfall Using Tail Entropy. Entropy 2019, 21, 1204. [Google Scholar] [CrossRef]
- MacKay, D.J. Information Theory, Inference, and Learning Algorithms, 1st ed.; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Kac, M.; Kiefer, J.; Wolfowitz, J. On tests of normality and other tests of goodness of fit based on distance methods. Ann. Math. Stat. 1955, 26, 189–211. [Google Scholar] [CrossRef]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-GAN: Training generative neural samplers using variational divergence minimization. In Proceedings of the 30th Annual Conference on Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 271–279. [Google Scholar]
- Contreras-Reyes, J. Asymptotic form of the Kullback-Leibler divergence for multivariate asymmetric heavy-tailed distributions. Phys. A Stat. Mech. Its Appl. 2014, 395, 200–208. [Google Scholar] [CrossRef]
- Houle, M.E.; Kashima, H.; Nett, M. Generalized Expansion Dimension. In Proceedings of the IEEE 12th International Conference on Data Mining Workshops, Brussels, Belgium, 10 December 2012; pp. 587–594. [Google Scholar]
- Karger, D.R.; Ruhl, M. Finding nearest neighbors in growth-restricted metrics. In Proceedings of the 34th ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 741–750. [Google Scholar]
- Houle, M.E. Dimensionality, Discriminability, Density and Distance Distributions. In Proceedings of the IEEE 13th International Conference on Data Mining Workshops, Dallas, TX, USA, 7–10 December 2013; pp. 468–473. [Google Scholar]
- Karamata, J. Sur un mode de croissance régulière. Théorèmes fondamentaux. Bull. Société Mathématique Fr. 1933, 61, 55–62. [Google Scholar] [CrossRef]
- Coles, S.; Bawa, J.; Trenner, L.; Dorazio, P. An Introduction to Statistical Modeling of Extreme Values; Springer: Berlin/Heidelberg, Germany, 2001; Volume 208. [Google Scholar]
- Houle, M.E. Local Intrinsic Dimensionality II: Multivariate Analysis and Distributional Support. In Proceedings of the International Conference on Similarity Search and Applications, Munich, Germany, 4–6 October 2017; pp. 80–95. [Google Scholar]
- Song, K. Renyi information, log likelihood and an intrinsic distribution measure. J. Statist. Plann. Inference 2001, 93, 51–69. [Google Scholar] [CrossRef]
- Buono, F.; Longobardi, M. Varentropy of past lifetimes. arXiv 2020, arXiv:2008.07423. [Google Scholar]
- Maadani, S.; Borzadaran, G.R.M.; Roknabadi, A.H.R. Varentropy of order statistics and some stochastic comparisons. Commun. Stat. Theory Methods 2021, 51, 6447–6460. [Google Scholar] [CrossRef]
- Raqab, M.Z.; Bayoud, H.A.; Qiu, G. Varentropy of inactivity time of a random variable and its related applications. IMA J. Math. Control. Inf. 2021, 39, 132–154. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and efficient estimation by minimising a density power divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef]
- Hellinger, E. Neue Begründung der Theorie quadratischer Formen von unendlichvielen Veränderlichen. J. Für Die Reine Und Angew. Math. 1909, 136, 210–271. [Google Scholar] [CrossRef]
- Cichocki, A.; Amari, S. Families of Alpha- Beta- and Gamma- Divergences: Flexible and Robust Measures of Similarities. Entropy 2010, 12, 1532–1568. [Google Scholar] [CrossRef]
- Pearson, K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1900, 50, 157–175. [Google Scholar] [CrossRef]
- Kantorovich, L.V. Mathematical Methods of Organizing and Planning Production. Manag. Sci. 1939, 6, 366–422. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Cambridge, MA, USA, 2017; Volume 70, pp. 214–223. [Google Scholar]
- Houle, M.E. Local Intrinsic Dimensionality III: Density and Similarity. In Proceedings of the International Conference on Similarity Search and Applications, Copenhagen, Denmark, 30 September–2 October 2020. [Google Scholar]
- Itakura, F.; Saito, S. Analysis synthesis telephony based on the maximum likelihood method. In Proceedings of the 6th International Congress on Acoustics, Tokyo, Japan, 21–28 August 1968; pp. C17–C20. [Google Scholar]
- Fevotte, C.; Bertin, N.; Durrieu, J. Nonnegative Matrix Factorization with the Itakura-Saito Divergence: With Application to Music Analysis. Neural Comput. 2009, 21, 793–830. [Google Scholar] [CrossRef]
- Bregman, L.M. The relaxation method of finding the common points of convex sets and its application to the solution of problems in convex programming. USSR Comput. Math. Math. Phys. 1967, 7, 200–217. [Google Scholar] [CrossRef]
- Nielsen, F.; Nock, R. Sided and symmetrized Bregman centroids. IEEE Trans. Inf. Theory 2009, 55, 2882–2904. [Google Scholar] [CrossRef]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J. Clustering with Bregman Divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Fang, K.W.; Kotz, S.; Wang Ng, K. Symmetric Multivariate and Related Distributions; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Baker, J.A. Integration of Radial Functions. Math. Mag. 1999, 72, 392–395. [Google Scholar] [CrossRef]

{kind=link}
| Tail Measure | Formulation | Limit as |
|---|---|---|
| Entropy | = | Diverges (no reweighting possible) |
| Varentropy | = | |
| q-Entropy | = | if , diverges if |
| Normalized Cumulative Entropy | = | |
| Normalized Cumulative q-Entropy | = | if |
| Normalized Entropy Power | = | |
| Normalized q-Entropy Power | = | |
| if and | ||
| Cross Entropy | = | Diverges (no reweighting possible) |
| Normalized Cross Entropy Power | = | |
| KL Divergence | = | |
| JS Divergence | = | |
| Weighted L2 Distance | = | |
| ; | ||
| Hellinger Distance | = | |
| -Divergence | = | |
| -Divergence | = | |
| Normalized Wasserstein Distance | = | : |
| p even: |
| Tail Measure | Derivation Steps | Comments |
|---|---|---|
| Entropy | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | no reweighting | |
| Varentropy | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | ||
| q-Entropy | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | ||
| Cumulative Entropy | → | |
| → | using Lemma 1 | |
| → | weight by | |
| Cumulative q-Entropy | → | |
| → | using Lemma 1 | |
| → | weight by | |
| Entropy Power | → | |
| → | by substitution | |
| → | weight by | |
| q-Entropy Power | → | |
| → | by substitution | |
| → | weight by |
| Tail Measure | Derivation Steps | Comments |
|---|---|---|
| Cross Entropy | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | no reweighting | |
| Cross Entropy Power | → | |
| → | by substitution | |
| → | weight by | |
| KL Divergence | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | ||
| JS Divergence | → | |
| → | ||
| → | let | |
| → |
| Tail Measure | Derivation Steps | Comments |
|---|---|---|
| L2 Distance | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | weight by w | |
| Hellinger Distance | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | ||
| -Divergence | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | ||
| -Divergence | → | |
| → | using Theorem 1 | |
| → | using Lemma 3 | |
| → | using Lemma 1 | |
| → | ||
| → |
| Tail Measure | Derivation Steps | Comments |
|---|---|---|
| Wasserstein Distance | → | |
| → | ||
| → | using Lemma 2 | |
| → | weight by | |
| Wasserstein Distance | → | |
| , p even | → | |
| → | using Lemma 2 | |
| → | weight by |
| Tail Measure | Formulation | Limit as |
|---|---|---|
| Entropy | = | Diverges (no reweighting possible) |
| Varentropy | = | |
| = | ||
| q-Entropy | = | if |
| = | diverges if | |
| Normalized | = | |
| Cumulative Entropy | = | |
| Normalized | = | if |
| Cumulative q-Entropy | = | |
| Normalized Entropy Power | = | |
| Normalized q-Entropy Power | = | ; |
| if and | ||
| Cross Entropy | = | Diverges (no reweighting possible) |
| Normalized Cross Entropy Power | = | |
| Weighted | = | |
| L2 Distance | = | |
| ; | ||
| Hellinger Distance | = | |
| = | ||
| -Divergence | = | |
| = | ||
| -Divergence | = | |
| = | ||
| Require | ||
| KL Divergence | = | |
| JS Divergence | = |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bailey, J.; Houle, M.E.; Ma, X. Local Intrinsic Dimensionality, Entropy and Statistical Divergences. Entropy 2022, 24, 1220. https://doi.org/10.3390/e24091220
Bailey J, Houle ME, Ma X. Local Intrinsic Dimensionality, Entropy and Statistical Divergences. Entropy. 2022; 24(9):1220. https://doi.org/10.3390/e24091220
Chicago/Turabian StyleBailey, James, Michael E. Houle, and Xingjun Ma. 2022. "Local Intrinsic Dimensionality, Entropy and Statistical Divergences" Entropy 24, no. 9: 1220. https://doi.org/10.3390/e24091220
APA StyleBailey, J., Houle, M. E., & Ma, X. (2022). Local Intrinsic Dimensionality, Entropy and Statistical Divergences. Entropy, 24(9), 1220. https://doi.org/10.3390/e24091220