
Efficient Privacy-Preserving K-Means Clustering from Secret-Sharing-Based Secure Three-Party Computation


Abstract
:1. Introduction
1.1. Related Work
1.2. Our Contributions
- Our protocol provides full privacy guarantees, which allows different computing parties to cluster the combined datasets without revealing any other information except the final centroids.
- Our protocol is based on replicated secret sharing (RSS), which is a 2-out-of-3 threshold secret sharing proposed by Araki et al. [28] and is suitable for constructing efficient protocol over . Our protocol is secure against a single corrupt server under a semi-honest model. We analyze the security with universal composition framework [29].
- The experimental results demonstrate that our protocol reaches the same accuracy as the plaintext K-means clustering algorithm. With the fast network, our privacy-preserving scheme can deal with datasets of million points in an acceptable time.
1.3. Roadmap
2. Preliminaries
2.1. Basic Notation
2.2. Threat Model and Security Assumption
- : Compute ;Output , where is ’s output.
- : Run the protocol ;Output , where is the final view of .
2.3. The K-Means Clustering Algorithm
- Cluster centroids initialization: randomly choose K different points as initialized centroids for K groups, where is d-dimension vector , .
- Repeat the following until the stopping criterion (Lloyd’s steps):
- (a)
- For , compute the Euclidean distance between point and centroids by
- (b)
- Assign each data point to the closest cluster for . This can be done by computing firstly, and then generate a K-dimension one-hot vector where ‘1’ indicates the -th component of vector . We form matrix such that the i-th column of is the one-hot vector . Let be the k-th row of .
- (c)
- Recalculate the average of the points in each cluster. For each cluster , compute new cluster center withwhere is the point number of k-th cluster.
- (d)
- Check the stopping criterion and update the new cluster center with the average. For each , compute the Euclidean distance between and at first, and then the squared error can be computed byGiven a small error , if , then update with . Otherwise, stop the criterion and output .
3. Building Blocks
3.1. Correlated Randomness
- 3-out-of-3 randomness: holds .
- 2-out-of-3 randomness: holds .
3.2. Replicated Secret Sharing
- : To share a secret , the dealer samples three random values under the constraint that . For , gets . We write .
- : To reveal to all parties, sends to , then each party reconstructs x locally by computing . To reveal only to , sends to which reconstructs x locally.
3.3. Oblivious Selection Protocol
3.4. Secure Euclidean Squared Distance Protocol
3.5. Secure Comparison Protocol
3.6. Secure Assignment Protocol
3.7. Secure Division Protocol
4. Privacy-Preserving -Means Clustering
4.1. Secret Distribution
4.2. Cluster Initialization
4.3. Lloyd’s Steps
4.3.1. Approximation of Euclidean Distance
4.3.2. Assigning Data Points to the Closest Cluster
4.3.3. Recalculating Cluster Centers
4.3.4. Checking the Stopping Criterion and Updating Centroids
4.4. Main Construction
5. Security Analyses
- Calls simulator to simulate step 1, then appends its output to the view;
- Calls simulator to simulate step 2, then appends its output to the view;
- Calls simulator to simulate step 3, then appends its output to the view;
- Calls simulator to simulate step 3(b), then appends its output to the view.
- Calls simulator to simulate step 4(b), then appends its output to the view.
6. Experiments
6.1. Experimental Setup
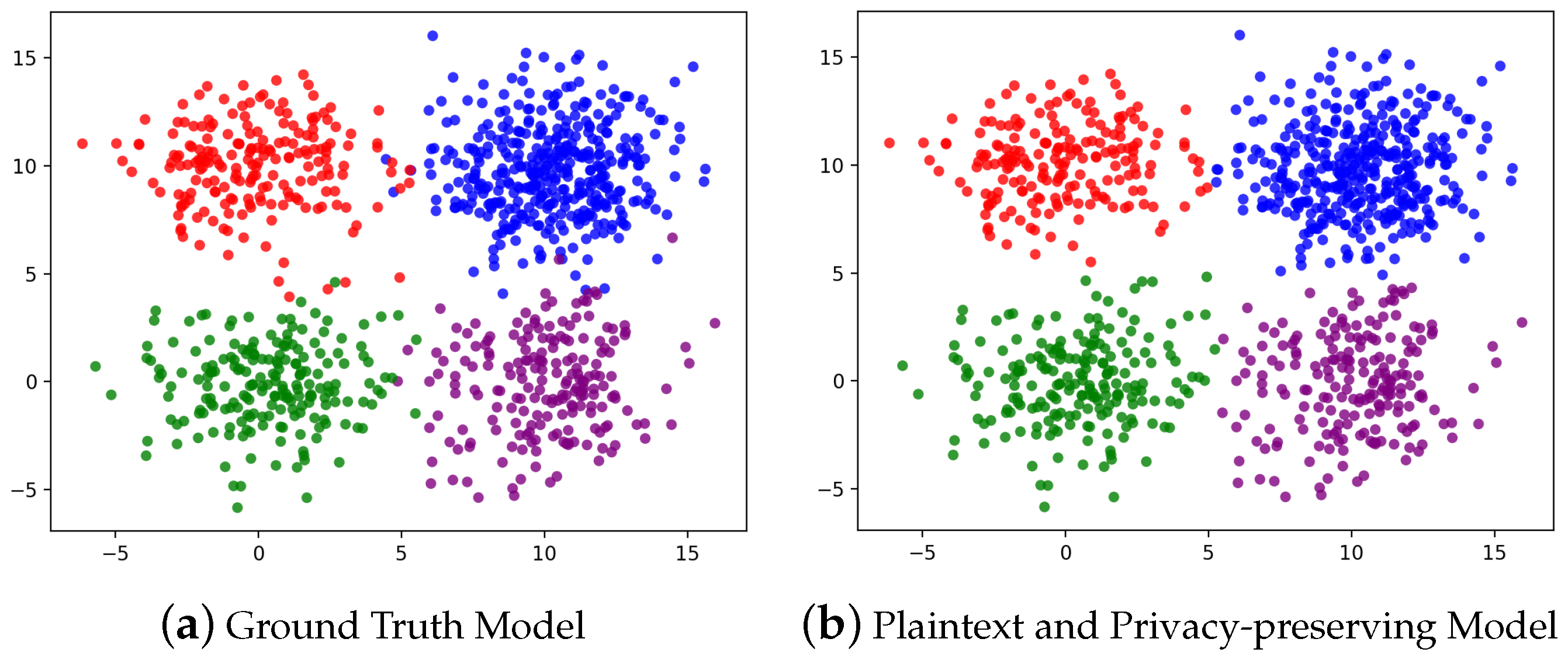
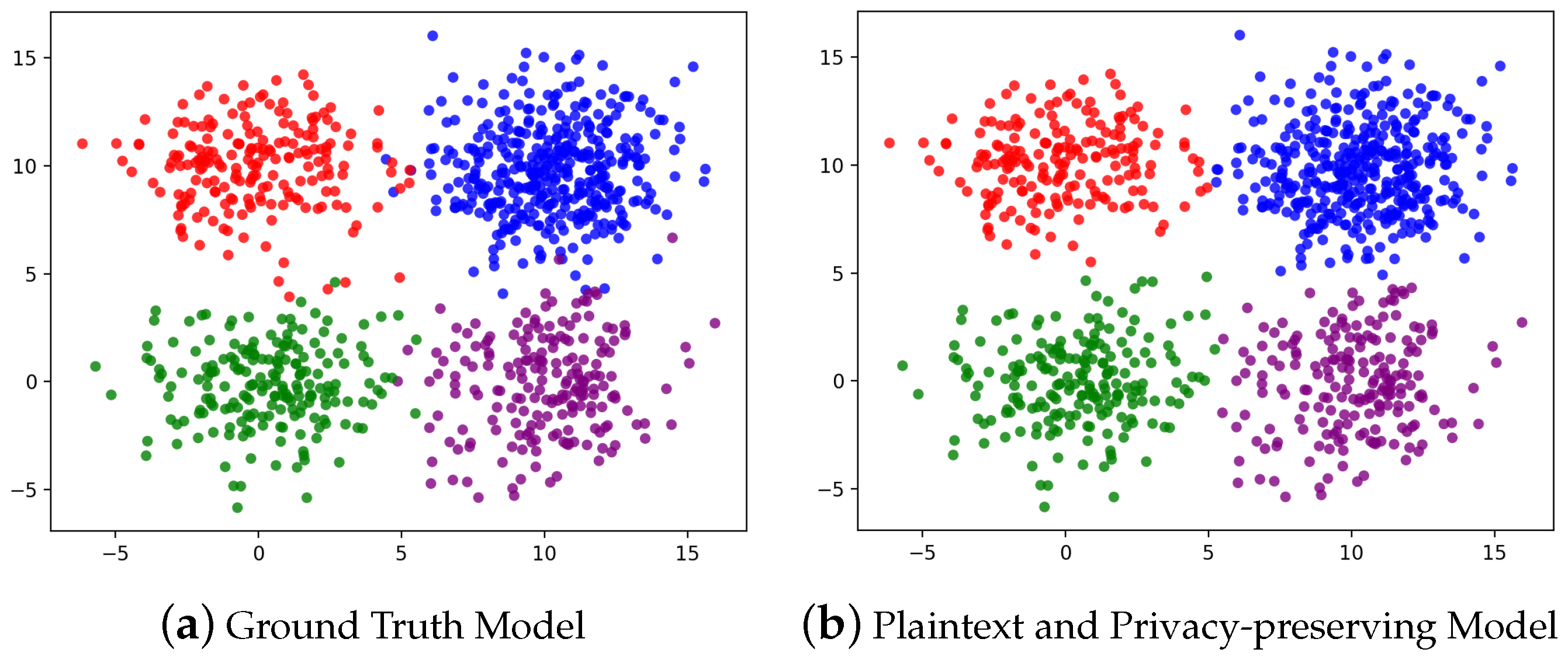
6.2. Accuracy
6.3. Runtime and Communication
6.4. Comparison with Mohassel et al. [27]
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lindell, Y.; Pinkas, B. Privacy Preserving Data Mining. J. Cryptol. 2002, 15, 177–206. [Google Scholar] [CrossRef]
- Tan, P.N.; Steinbach, M.; Karpatne, A.; Kumar, V. Introduction to Data Mining, 2nd ed.; Pearson: New York, NY, USA, 2018. [Google Scholar]
- Hegde, A.; Möllering, H.; Schneider, T.; Yalame, H. SoK: Efficient Privacy-Preserving Clustering. Proc. Priv. Enhancing Technol. 2021, 2021, 225–248. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, C.; Ye, R. Cryptanalysis and Improvement of Medical Image Encryption Using High-Speed Scrambling and Pixel Adaptive Diffusion. Signal Process. 2020, 167, 107286. [Google Scholar] [CrossRef]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On data banks and privacy homomorphisms. Found. Secur. Comput. 1978, 4, 169–180. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Proceedings of the Advances in Cryptology—EUROCRYPT ’99, Santa Barbara, CA, USA, 15–19 August 1999; pp. 223–238. [Google Scholar]
- Elgamal, T. A Public Key Cryptosystem and a Signature Scheme Based on Discrete Logarithms. IEEE Trans. Inf. Theory 1985, 31, 469–472. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C. Privacy-Preserving k-Means Clustering over Vertically Partitioned Data. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 206–215. [Google Scholar]
- Bunn, P.; Ostrovsky, R. Secure Two-Party k-Means Clustering. In Proceedings of the 14th ACM Conference on Computer and Communications Security—CCS ’07, Alexandria, VA, USA, 28–31 October 2007; p. 486. [Google Scholar]
- Rao, F.Y.; Samanthula, B.K.; Bertino, E.; Yi, X.; Liu, D. Privacy-Preserving and Outsourced Multi-User K-Means Clustering. In Proceedings of the 2015 IEEE Conference on Collaboration and Internet Computing (CIC), Hangzhou, China, 27–30 October 2015; pp. 80–89. [Google Scholar]
- Kim, H.J.; Chang, J.W. A Privacy-Preserving k-Means Clustering Algorithm Using Secure Comparison Protocol and Density-Based Center Point Selection. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; pp. 928–931. [Google Scholar]
- Jäschke, A.; Armknecht, F. Unsupervised Machine Learning on Encrypted Data. In Proceedings of the International Conference on Selected Areas in Cryptography, Calgary, AB, Canada, 15–17 August 2018; pp. 453–478. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. Faster Fully Homomorphic Encryption: Bootstrapping in Less Than 0.1 Seconds. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hanoi, Vietnam, 4–8 December 2016; pp. 3–33. [Google Scholar]
- Cai, Y.; Tang, C. Privacy of Outsourced Two-party K-means Clustering. Concurr. Comput. Pract. Exp. 2021, 33, e5473. [Google Scholar] [CrossRef]
- Liu, D. Practical Fully Homomorphic Encryption without Noise Reduction. IACR Cryptol. ePrint Arch. 2015, 2015, 468. [Google Scholar]
- Wang, Y. Notes on Two Fully Homomorphic Encryption Schemes without Bootstrapping. Cryptology ePrint Archive, Report 2015/519. 2015. Available online: https://eprint.iacr.org/2015/519 (accessed on 18 June 2022).
- Yao, A. Protocols for Secure Computations. In Proceedings of the FOCS, Chicago, IL, USA, 3–5 November 1982. [Google Scholar]
- Goldreich, O.; Micali, S.; Wigderson, A. How to Play Any Mental Game. In Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 25–27 May 1987; pp. 218–229. [Google Scholar]
- Yao, A.C.C. How to Generate and Exchange Secrets. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science, Toronto, ON, Canada, 27–29 October 1986; pp. 162–167. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Doganay, M.C.; Pedersen, T.B.; Saygin, Y.; Savaş, E.; Levi, A. Distributed Privacy Preserving K-Means Clustering with Additive Secret Sharing. In Proceedings of the 2008 International Workshop on Privacy and Anonymity in Information Society, Nantes, France, 29 March 2008; pp. 3–11. [Google Scholar]
- Patel, S.; Garasia, S.; Jinwala, D. An Efficient Approach for Privacy Preserving Distributed K-Means Clustering Based on Shamir’s Secret Sharing Scheme. In Proceedings of the IFIP International Conference on Trust Management, Surat, India, 21–25 May 2012; pp. 129–141. [Google Scholar]
- Patel, S.; Patel, V.; Jinwala, D. Privacy Preserving Distributed K-Means Clustering in Malicious Model Using Zero Knowledge Proof. In Proceedings of the International Conference on Distributed Computing and Internet Technology, Bhubaneswar, India, 5–8 February 2013; pp. 420–431. [Google Scholar]
- Upmanyu, M.; Namboodiri, A.M.; Srinathan, K.; Jawahar, C.V. Efficient Privacy Preserving K-Means Clustering. In Proceedings of the Pacific-Asia Workshop on Intelligence and Security Informatics, Hyderabad, India, 21 June 2010; pp. 154–166. [Google Scholar]
- Baby, V.; Chandra, N.S. Distributed Threshold K-Means Clustering for Privacy Preserving Data Mining. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 2286–2289. [Google Scholar]
- Mohassel, P.; Rosulek, M.; Trieu, N. Practical Privacy-Preserving k-Means Clustering. Proc. Priv. Enhancing Technol. 2020, 2020, 414–433. [Google Scholar] [CrossRef]
- Araki, T.; Furukawa, J.; Lindell, Y.; Nof, A.; Ohara, K. High-Throughput Semi-Honest Secure Three-Party Computation with an Honest Majority. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 805–817. [Google Scholar]
- Canetti, R. Universally Composable Security: A New Paradigm for Cryptographic Protocols. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Washington, DC, USA, 14–17 October 2001; pp. 136–145. [Google Scholar]
- Goldreich, O. The Foundations of Cryptography—Volume 2: Basic Applications; Cambridge University Press: New York, NY, USA, 2004. [Google Scholar]
- Mohassel, P.; Rindal, P. ABY3: A Mixed Protocol Framework for Machine Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 35–52. [Google Scholar]
- Wagh, S.; Tople, S.; Benhamouda, F.; Kushilevitz, E.; Mittal, P.; Rabin, T. Falcon: Honest-Majority Maliciously Secure Framework for Private Deep Learning. Proc. Priv. Enhancing Technol. 2021, 2021, 188–208. [Google Scholar] [CrossRef]
- Ito, M.; Saito, A.; Nishizeki, T. Secret Sharing Scheme Realizing General Access Structure. Electron. Commun. Jpn. 1989, 72, 56–64. [Google Scholar] [CrossRef]
- Catrina, O.; Saxena, A. Secure Computation with Fixed-Point Numbers. In Financial Cryptography and Data Security; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6052, pp. 35–50. [Google Scholar]
- Beaver, D. Precomputing Oblivious Transfer. In Proceedings of the Advances in Cryptology—CRYPTO’ 95, Santa Barbara, CA, USA, 27–31 August 1995; pp. 97–109. [Google Scholar]
- Goldschmidt, R.E. Applications of Division by Convergence. Ph.D. Thesis, Massachusetts Institute of Technology, Singapore, 1964. [Google Scholar]
- Damgård, I.; Pastro, V.; Smart, N.; Zakarias, S. Multiparty Computation from Somewhat Homomorphic Encryption. In Proceedings of the Advances in Cryptology—CRYPTO 2012, Santa Barbara, CA, USA, 19–23 August 2012; pp. 643–662. [Google Scholar]


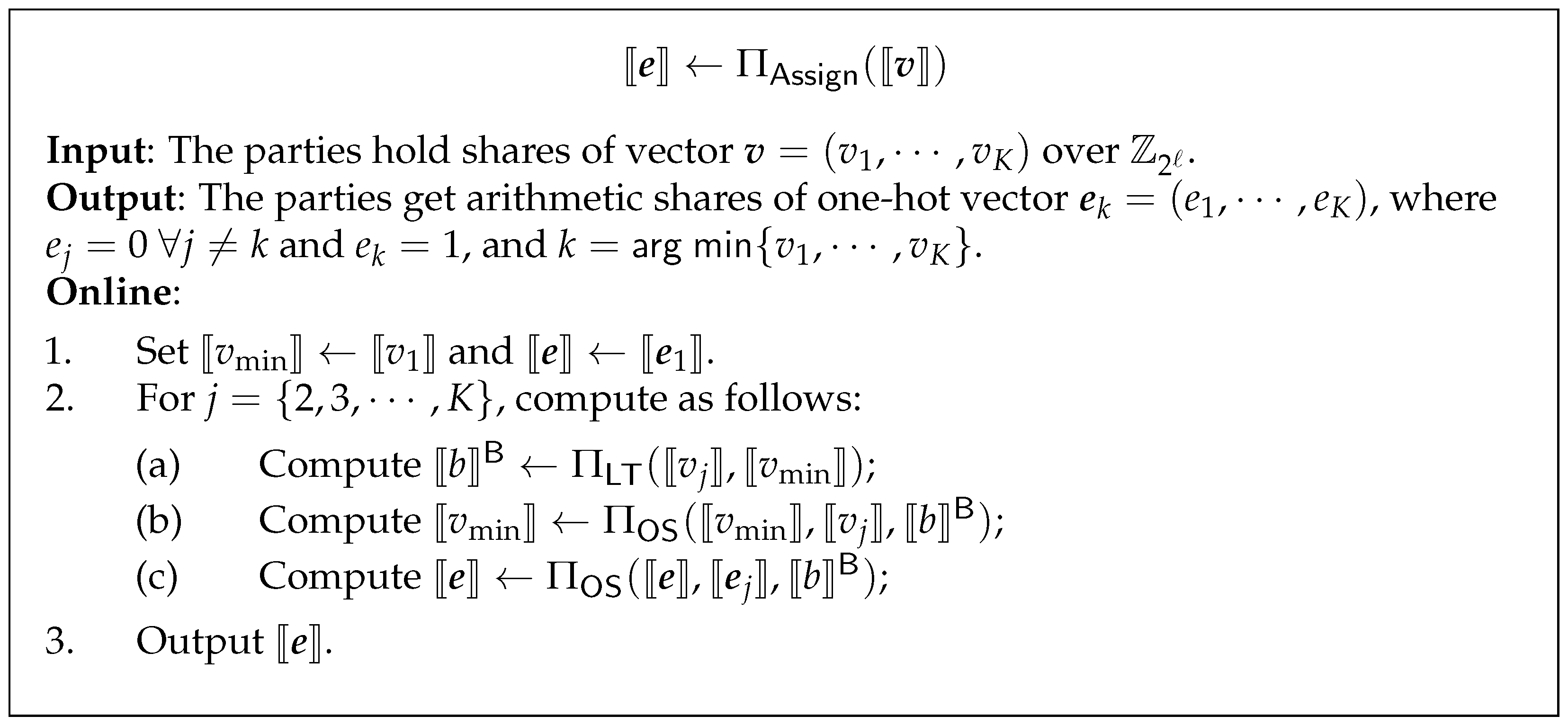



{kind=link}
{kind=link}
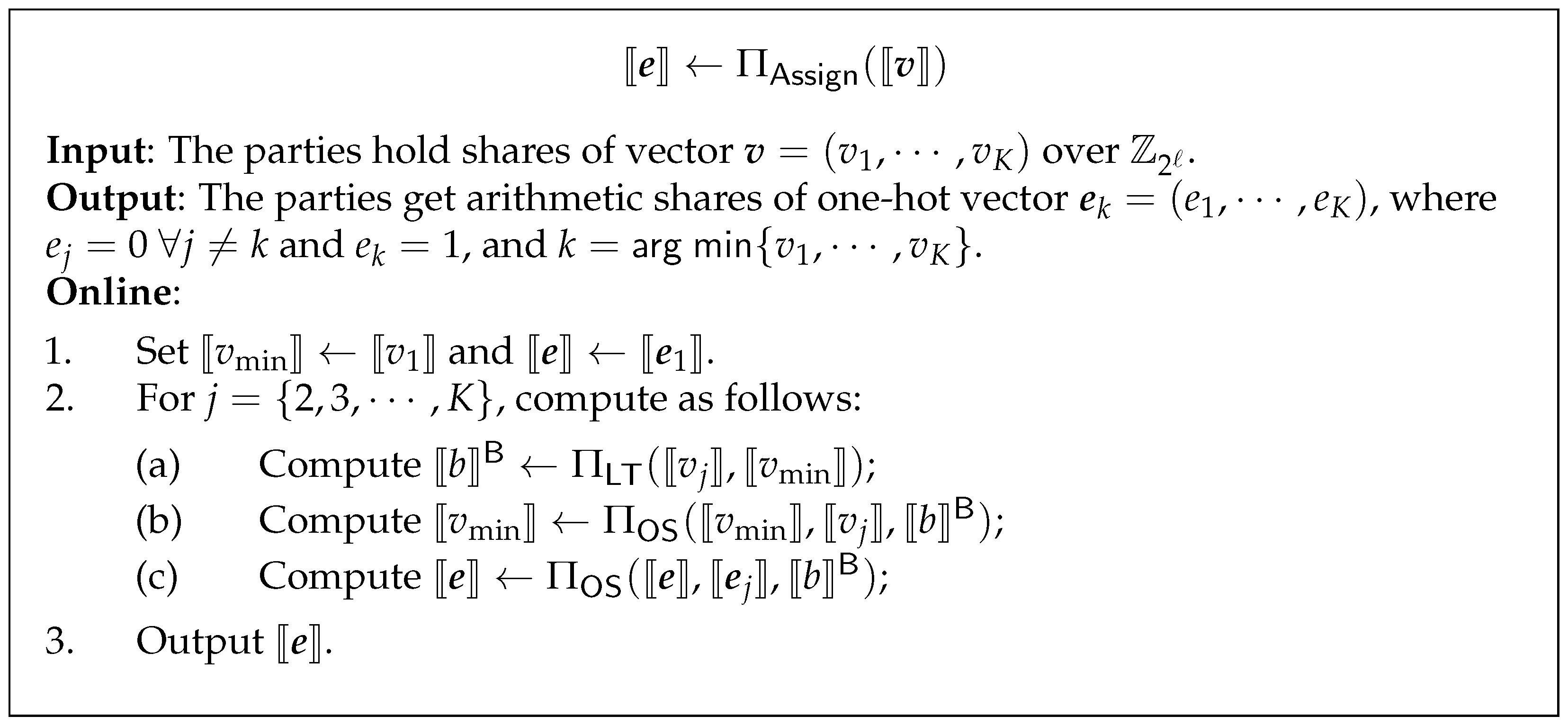{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Security | Technology | Domain | L1 | L2 | L3 | FDP |
|---|---|---|---|---|---|---|---|
| Doganay et al. [22] | Semi-honest | ASS | N/A | ✓ | ✓ | ✗ | ✗ |
| Upmanyu et al. [25] | Semi-honest | CRT-SS | ✓ | ✗ | ✗ | ✗ | |
| Patel et al. [23] | Semi-honest | SSS | ✗ | ✗ | ✓ | ✗ | |
| Patel et al. [24] | Malicious | SSS+ZKP | ✗ | ✗ | ✓ | ✗ | |
| Baby and Chandra [26] | N/A | CRT-SS | ✗ | ✗ | ✗ | ✗ | |
| Mohassel et al. [27] | Semi-honest | ASS+GC+OT | ✓ | ✓ | ✓ | ✓ | |
| This work | Semi-honest | RSS | ✓ | ✓ | ✓ | ✓ |
| Dataset | n | K | d | Accuracy |
|---|---|---|---|---|
| Iris | 150 | 3 | 4 | 92.67% |
| arff | 1000 | 4 | 2 | 98.20% |
| Self-generated | — |
| Parameters | Runtime | Comm. (MB) | |||
|---|---|---|---|---|---|
| n | K | d | LAN (s) | WAN (min) | |
| 10,000 | 2 | 5 | 63.8160 | 134.3737 | 37.1516 |
| 10 | 63.8020 | 134.3832 | 37.2976 | ||
| 20 | 63.6132 | 134.3962 | 37.5896 | ||
| 5 | 5 | 160.9406 | 336.0150 | 134.2790 | |
| 10 | 161.2164 | 336.1254 | 134.6440 | ||
| 20 | 161.3586 | 336.2652 | 135.3740 | ||
| 100,000 | 2 | 5 | 474.7150 | 1336.1333 | 370.1520 |
| 10 | 473.9687 | 1336.1968 | 370.2980 | ||
| 20 | 475.1037 | 1336.2415 | 370.5900 | ||
| Parameters | Runtime (min) | Communication (MB) | ||||||
|---|---|---|---|---|---|---|---|---|
| n | K | T | [27] | This Work | Improved Factor | [27] | This Work | Improved Factor |
| 2 | 10 | 1.77 | 0.09 | 19.5× | 2377 | 37 | 64.1× | |
| 20 | 3.36 | 0.19 | 17.9× | 4733 | 74 | 63.8× | ||
| 5 | 10 | 4.69 | 0.28 | 16.5× | 9121 | 134 | 68.0× | |
| 20 | 9.46 | 0.56 | 16.9× | 18220 | 268 | 68.0× | ||
| 2 | 10 | 15.33 | 0.74 | 20.8× | 23731 | 370 | 64.1× | |
| 20 | 29.74 | 1.15 | 20.4× | 47262 | 740 | 63.9× | ||
| 5 | 10 | 46.51 | 1.85 | 25.2× | 91128 | 1339 | 68.0× | |
| 20 | 91.61 | 3.65 | 25.1× | 181867 | 2678 | 67.9× | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, W.; Tang, C.; Chen, Y. Efficient Privacy-Preserving K-Means Clustering from Secret-Sharing-Based Secure Three-Party Computation. Entropy 2022, 24, 1145. https://doi.org/10.3390/e24081145
Wei W, Tang C, Chen Y. Efficient Privacy-Preserving K-Means Clustering from Secret-Sharing-Based Secure Three-Party Computation. Entropy. 2022; 24(8):1145. https://doi.org/10.3390/e24081145
Chicago/Turabian StyleWei, Weiming, Chunming Tang, and Yucheng Chen. 2022. "Efficient Privacy-Preserving K-Means Clustering from Secret-Sharing-Based Secure Three-Party Computation" Entropy 24, no. 8: 1145. https://doi.org/10.3390/e24081145
APA StyleWei, W., Tang, C., & Chen, Y. (2022). Efficient Privacy-Preserving K-Means Clustering from Secret-Sharing-Based Secure Three-Party Computation. Entropy, 24(8), 1145. https://doi.org/10.3390/e24081145