
Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition


Abstract
:1. Introduction
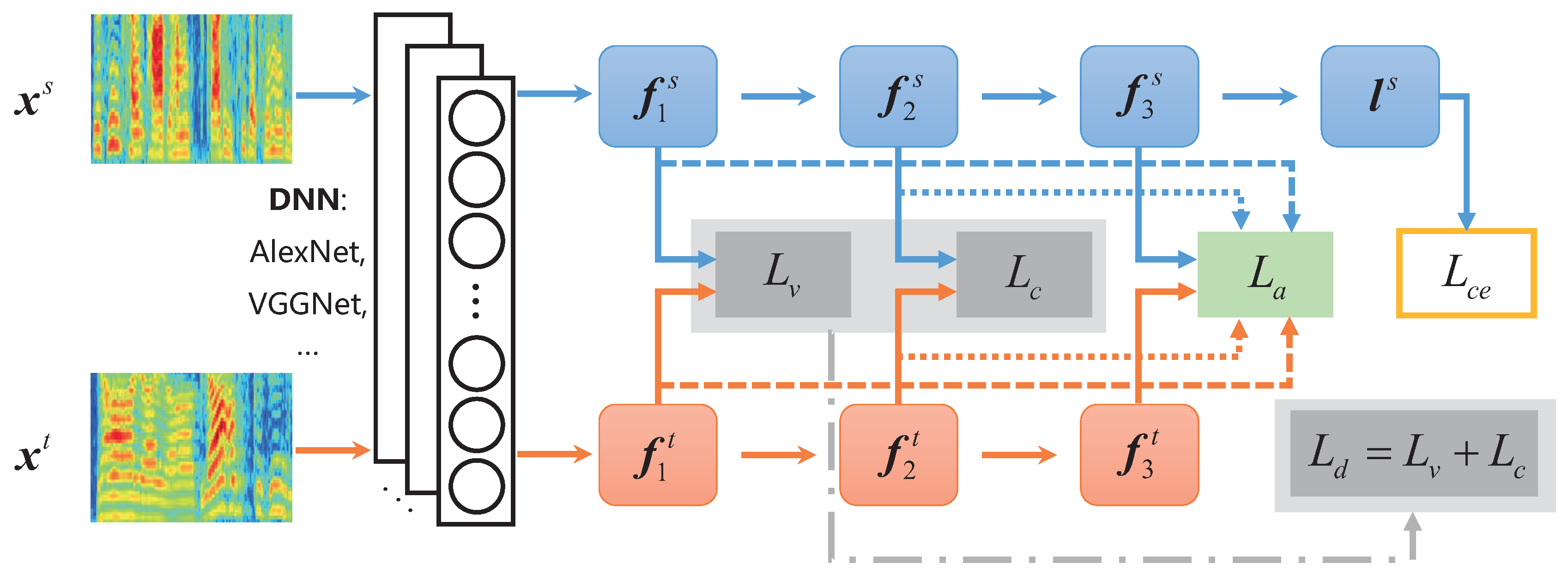
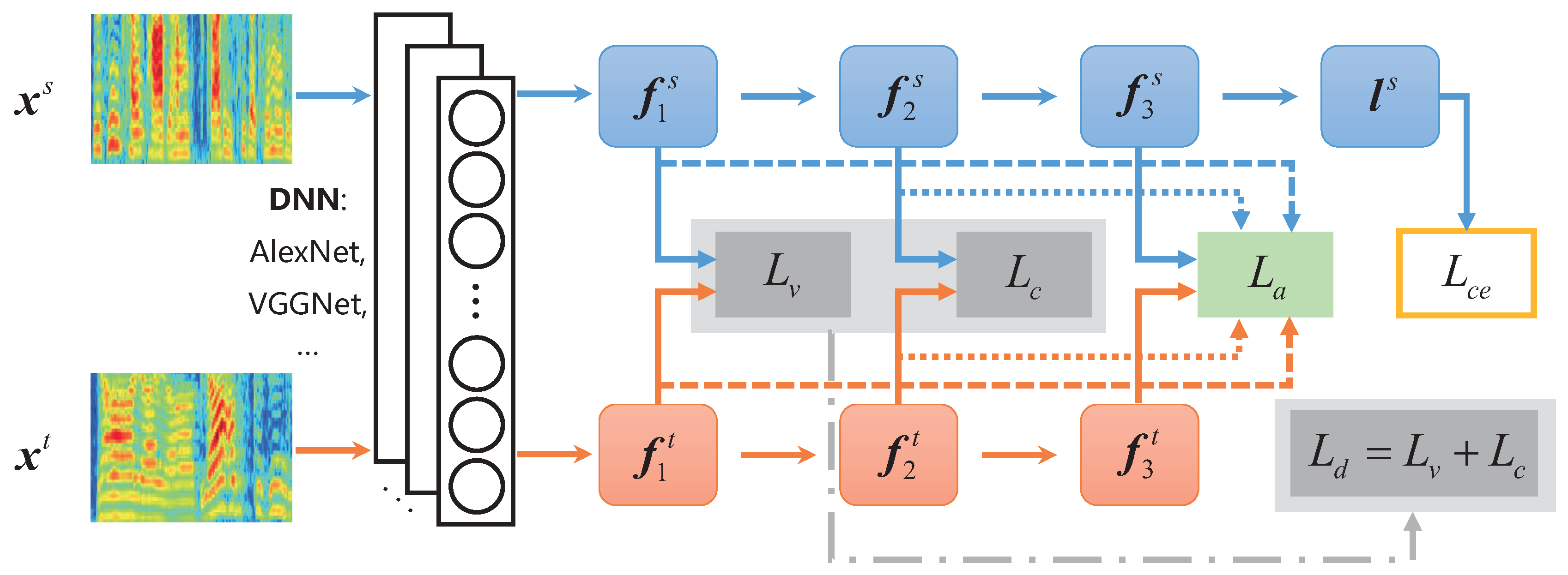
- This paper proposes a novel progressively discriminative transfer network for cross-corpus SER, which jointly considers the two aspects of eliminating the distribution discrepancy across the source and target domains, and enhancing the emotion discrimination of speech features during deep feature learning. Thus, it can avoid the dilemma that previous methods only consider one of two above aspects.
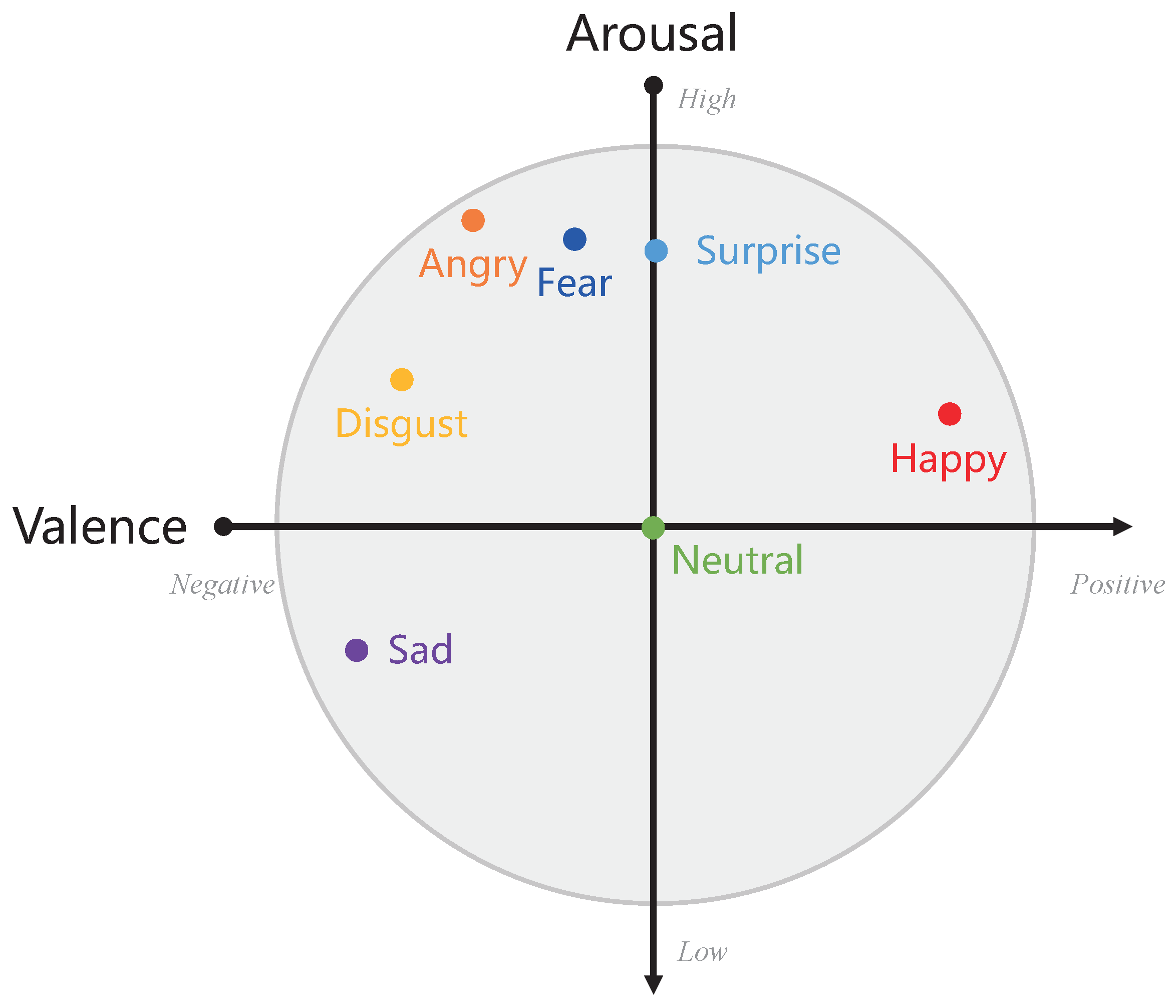
- As far as we know, it is the first work to introduce the prior knowledge of speech emotions, i.e., speech emotion features of high and low valences with their respective cluster centers, into the deep feature learning to enhance the emotion discrimination of speech representations.
- We adopt high-level features of fc layers to perform a practical distribution discrepancy measures under multi-layer features between the source and target domains through a multi-layer MMD metric.
2. The Proposed Method
2.1. Deep Feature Extraction
2.2. Emotion Discrimination Preservation
| Algorithm 1: Algorithm for the parameter optimization of PDTN. |
Input: the input features of source and target data: , ; training labels of source data: ; fc layers: ; learning rate: and trade-off parameters , , and . Initialize:, randomly. Output: the optimized parameters: , . while the total loss or iter maxIter do (1) Generate a mini-batch features of source and target data: (2) Extract the high-level features of source and target data: (3) Calculate the negative-valence and positive-valence feature centers and (4) Calculate the feature center of qth class in each mini-batch by the Equation (7); (5) if iter : Initialize global centers , , and (or ) in whole source data using steps (4) and (5); else: (7) Update the parameter and : (8) . end while |
2.3. Distribution Discrepancy Elimination
2.4. PDTN for Cross-Corpus SER
3. Experiments
3.1. Dataset
- eNTERFACE [28] is a public English multi-modal emotion dataset, which contains 1290 audio-visual samples with a sample rate of 48 kHz. In this dataset, six emotions, i.e., anger, disgust, fear, happiness, sadness, and surprise, are induced by the pre-prepared performance contents. Forty-three volunteers coming from different countries with males and females participated in the recording of the dataset.
- CASIA [29] includes 7200 emotional speech sentences with the Chinese language. Each sample is recorded with six emotions, i.e., anger, fear, happiness, neutral, sadness, and surprise, through some acting contents from four actors containing two males and two females. We utilize 1200 public speech samples with the sample rate of 16 kHz for the experiments.
- Emo-DB [30] is collected as a German emotional speech dataset with 535 speech samples by ten native speakers, including five males and five females. In Emo-DB, each sentence is recorded with 16 kHz under seven emotions, i.e., anger, boredom, disgust, fear, happiness, neutral, and sadness.
3.2. Experimental Setting
3.3. Comparison Methods
- Baseline methods: both backbone networks used to extract the high-level features for the experiments.
- DA-based methods: all domain adaptation-based methods for cross-corpus SER tasks by our own implementation.
3.4. Results and Discussions
3.5. Ablation Experiments
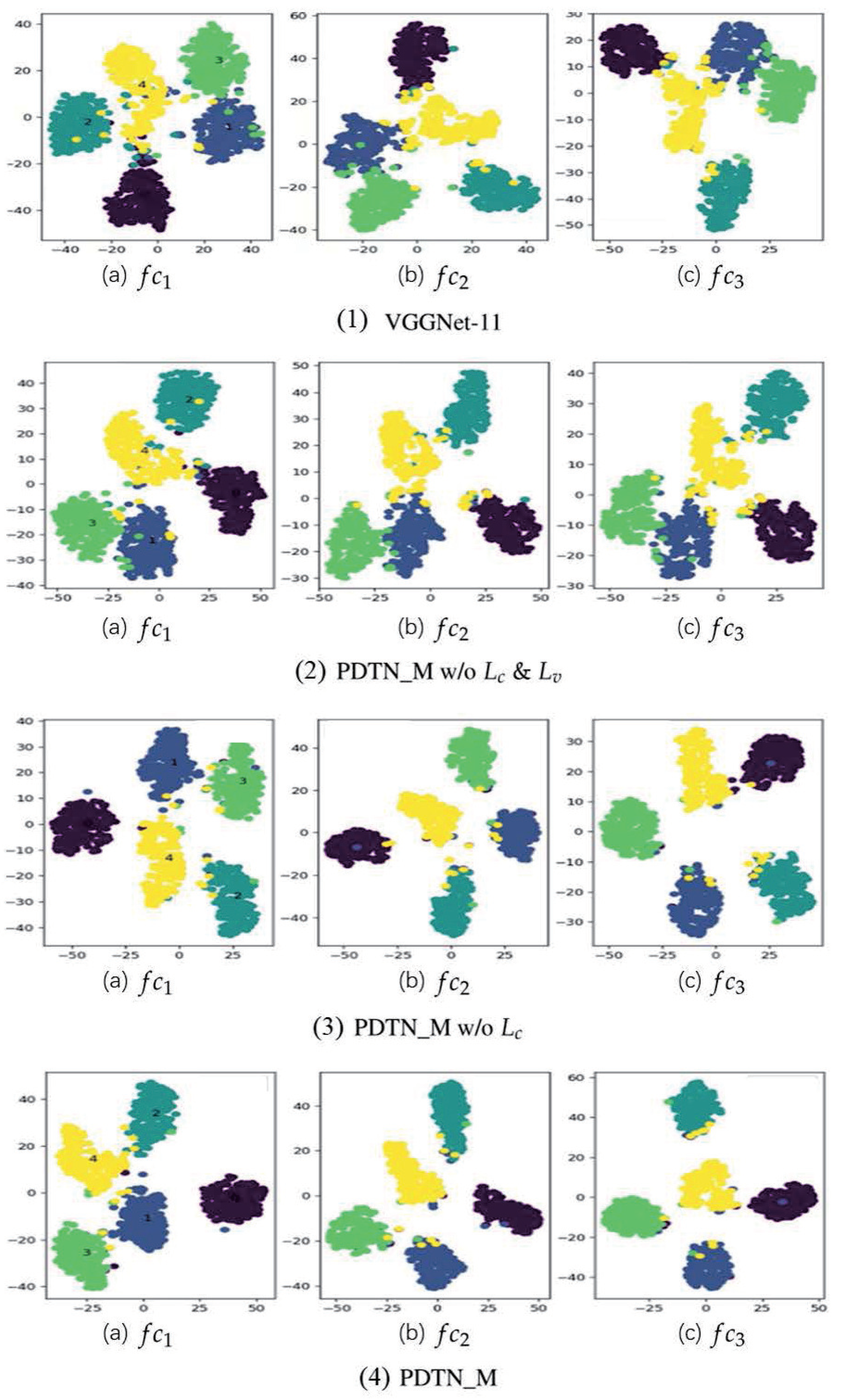
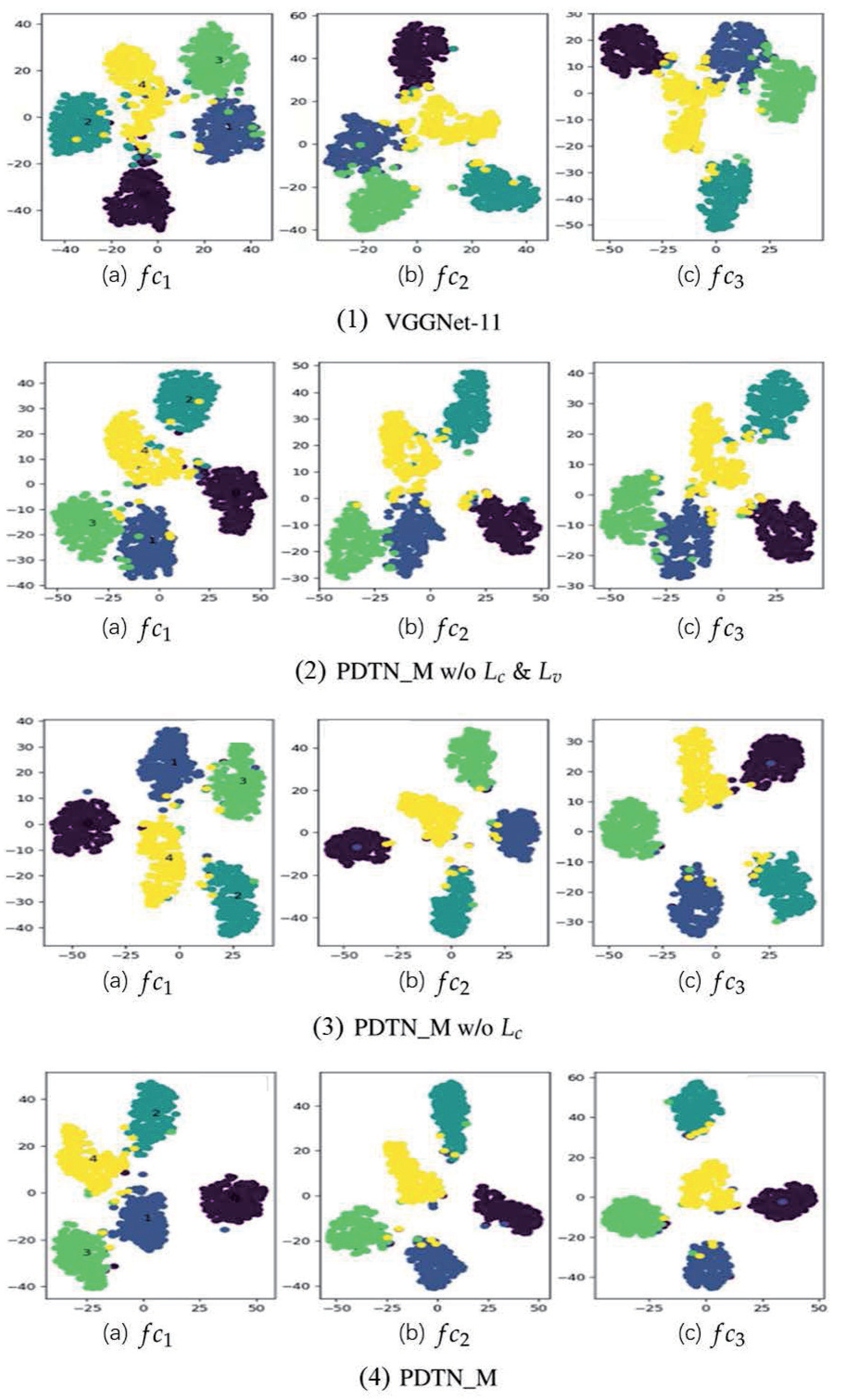
3.6. Visualization for Feature Distribution
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotion recognition in human-computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Schuller, B.W.; Picard, R.; André, E.; Gratch, J.; Tao, J. Intelligent signal processing for affective computing. IEEE Signal Process. Mag. 2021, 38, 9–11. [Google Scholar] [CrossRef]
- Lu, C.; Zheng, W.; Li, C.; Tang, C.; Liu, S.; Yan, S.; Zong, Y. Multiple spatio-temporal feature learning for video-based emotion recognition in the wild. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 646–652. [Google Scholar]
- Li, S.; Zheng, W.; Zong, Y.; Lu, C.; Tang, C.; Jiang, X.; Liu, J.; Xia, W. Bi-modality fusion for emotion recognition in the wild. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 589–594. [Google Scholar]
- Song, T.; Zheng, W.; Song, P.; Cui, Z. EEG emotion recognition using dynamical graph convolutional neural networks. IEEE Trans. Affect. Comput. 2018, 11, 532–541. [Google Scholar] [CrossRef]
- Song, P. Transfer Linear Subspace Learning for Cross-Corpus Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2019, 10, 265–275. [Google Scholar] [CrossRef]
- Shami, M.; Verhelst, W. Automatic classification of expressiveness in speech: A multi-corpus study. In Speaker Classification II; Springer: Berlin/Heidelberg, Germany, 2007; pp. 43–56. [Google Scholar]
- Schuller, B.; Vlasenko, B.; Eyben, F.; Wöllmer, M.; Stuhlsatz, A.; Wendemuth, A.; Rigoll, G. Cross-corpus acoustic emotion recognition: Variances and strategies. IEEE Trans. Affect. Comput. 2010, 1, 119–131. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zong, Y.; Zheng, W.; Zhang, T.; Huang, X. Cross-corpus speech emotion recognition based on domain-adaptive least-squares regression. IEEE Signal Process. Lett. 2016, 23, 585–589. [Google Scholar] [CrossRef]
- Song, P.; Zheng, W.; Ou, S.; Zhang, X.; Jin, Y.; Liu, J.; Yu, Y. Cross-corpus speech emotion recognition based on transfer non-negative matrix factorization. Speech Commun. 2016, 83, 34–41. [Google Scholar] [CrossRef]
- Song, P.; Zheng, W. Feature selection based transfer subspace learning for speech emotion recognition. IEEE Trans. Affect. Comput. 2018, 11, 373–382. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, L.; Zong, Y.; Zheng, W.; Zhao, L. Cross-Corpus Speech Emotion Recognition Using Joint Distribution Adaptive Regression. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3790–3794. [Google Scholar]
- Abdelwahab, M.; Busso, C. Domain adversarial for acoustic emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2423–2435. [Google Scholar] [CrossRef]
- Gideon, J.; McInnis, M.G.; Provost, E.M. Improving cross-corpus speech emotion recognition with adversarial discriminative domain generalization (ADDoG). IEEE Trans. Affect. Comput. 2019, 12, 1055–1068. [Google Scholar] [CrossRef]
- Lu, C.; Zong, Y.; Zheng, W.; Li, Y.; Tang, C.; Schuller, B.W. Domain Invariant Feature Learning for Speaker-Independent Speech Emotion Recognition. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2022, 30, 2217–2230. [Google Scholar] [CrossRef]
- Hassan, A.; Damper, R.; Niranjan, M. On acoustic emotion recognition: Compensating for covariate shift. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1458–1468. [Google Scholar] [CrossRef]
- Mao, Q.; Xu, G.; Xue, W.; Gou, J.; Zhan, Y. Learning emotion-discriminative and domain-invariant features for domain adaptation in speech emotion recognition. Speech Commun. 2017, 93, 1–10. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching. IEEE Trans. Multimed. 2017, 20, 1576–1590. [Google Scholar] [CrossRef]
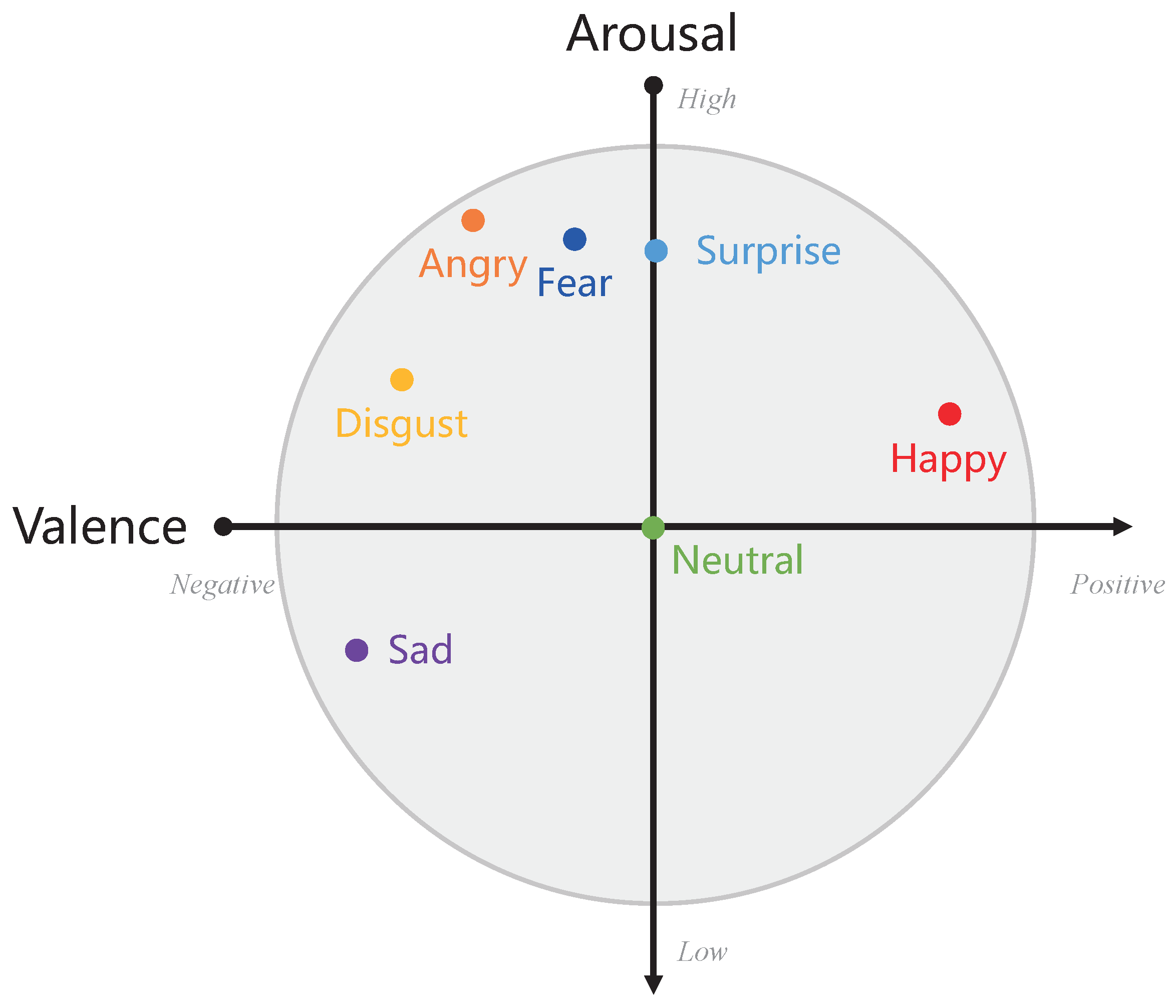
- Plutchik, R. A general psychoevolutionary theory of emotion. In Theories of Emotion; Elsevier: Amsterdam, The Netherlands, 1980; pp. 3–33. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Yang, L.; Shen, Y.; Mao, Y.; Cai, L. Hybrid Curriculum Learning for Emotion Recognition in Conversation. arXiv 2021, arXiv:2112.11718. [Google Scholar] [CrossRef]
- Rakshit, S.; Banerjee, B.; Roig, G.; Chaudhuri, S. Unsupervised multi-source domain adaptation driven by deep adversarial ensemble learning. In German Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 485–498. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, USA, 8–13 December 2014; Volume 27. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics—JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning (PMLR), Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 audio-visual emotion database. In Proceedings of the 22nd IEEE International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Zhang, J.T.F.L.M.; Jia, H. Design of speech corpus for mandarin text to speech. In The Blizzard Challenge 2008 Workshop; International Speech Communication Association: Baixas, France, 2008; pp. 1–4. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep subdomain adaptation network for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1713–1722. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Task | Dataset (# Total Number) | Emotion Category (# Samples of Each Emotion) |
|---|---|---|
| b e, e → b | b (375) | anger (127), disgust (46), fear (69), happiness (71), sadness (62) |
| e (1052) | anger (211), disgust (211), fear (211), happiness (208), sadness (211) | |
| b c, c → b | b (408) | anger (127), fear (69), happiness (71), neutral (79), sadness (62) |
| c (1000) | anger (200), fear (200), happiness (200), neutral (200), sadness (200) | |
| c → e, e → c | c (1052) | anger (200), fear 200, happiness (200), sadness (200), surprise (200) |
| e (1000) | anger (211), fear (211), happiness (208), sadness (211), surprise (211) |
| Method | e → b | b → e | b → c | c → b | e → c | c → e | Average |
|---|---|---|---|---|---|---|---|
| AlexNet [31] | 42.40/31.03 | 29.56/29.49 | 32.90/32.90 | 43.13/42.23 | 27.60/27.60 | 26.33/26.30 | 33.65/31.59 |
| VGGNet-11 [32] | 44.26/43.23 | 30.70/30.70 | 35.10/35.10 | 44.36/38.95 | 28.80/28.80 | 29.65/29.60 | 35.48/34.40 |
| DAN [27] | 49.82/40.41 | 36.12/36.13 | 39.00/39.00 | 50.98/49.85 | 29.00/29.00 | 31.46/31.47 | 39.89/37.64 |
| DANN [35] | 52.80/43.68 | 33.27/33.38 | 39.20/39.20 | 54.16/53.71 | 29.80/29.80 | 29.24/29.25 | 39.62/38.05 |
| Deep CORAL [24] | 53.07/43.38 | 35.07/35.03 | 38.30/38.30 | 50.73/48.28 | 31.00/31.00 | 30.89/30.89 | 39.84/37.81 |
| DSAN [34] | 52.16/46.90 | 36.29/36.25 | 40.30/40.30 | 51.81/50.69 | 29.70/29.70 | 32.61/32.61 | 40.47/39.41 |
| PDTN (AlexNet) | 54.60/47.12 | 38.30/38.32 | 42.80/42.80 | 57.59/57.21 | 35.10/35.10 | 35.50/35.50 | 43.99/ 42.70 |
| PDTN (VGGNet-11) | 56.80/54.48 | 38.49/38.60 | 44.70/44.60 | 62.01/61.65 | 35.20/35.20 | 35.74/35.43 | 45.49/44.99 |
| Method | e → b | b → e | b → c | c → b | e → c | c → e | Average |
|---|---|---|---|---|---|---|---|
| PDTN_S w/o | 52.80/50.40 | 35.83/35.81 | 40.20/40.20 | 55.39/54.85 | 34.10/34.10 | 34.03/33.97 | 42.05/41.54 |
| PDTN_M w/o | 53.00/51.07 | 36.31/36.36 | 41.60/41.50 | 58.33/54.55 | 33.80/33.80 | 34.88/34.77 | 42.99/42.01 |
| PDTN_M w/o | 54.44/51.56 | 38.02/37.97 | 44.00/43.90 | 59.06/58.66 | 34.60/34.60 | 35.93/35.67 | 44.34/43.31 |
| PDTN_M | 56.80/54.48 | 38.49/38.60 | 44.70/44.60 | 62.01/61.65 | 35.20/35.20 | 35.74/35.43 | 45.49/44.99 |
| PDTN_S | 54.66/51.87 | 36.43/36.32 | 44.40/44.40 | 57.84/ 56.53 | 34.50/34.50 | 35.45/35.14 | 43.88/43.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C.; Tang, C.; Zhang, J.; Zong, Y. Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition. Entropy 2022, 24, 1046. https://doi.org/10.3390/e24081046
Lu C, Tang C, Zhang J, Zong Y. Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition. Entropy. 2022; 24(8):1046. https://doi.org/10.3390/e24081046
Chicago/Turabian StyleLu, Cheng, Chuangao Tang, Jiacheng Zhang, and Yuan Zong. 2022. "Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition" Entropy 24, no. 8: 1046. https://doi.org/10.3390/e24081046
APA StyleLu, C., Tang, C., Zhang, J., & Zong, Y. (2022). Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition. Entropy, 24(8), 1046. https://doi.org/10.3390/e24081046