
Evaluating Ecohydrological Model Sensitivity to Input Variability with an Information-Theory-Based Approach


Abstract
:1. Introduction
2. Materials and Methods
2.1. Multi-Layer Canopy Model and Forcing Data
- Air temperature (Ta) affects stomatal conductance of plant and evaporation from both soil and canopy. The Campbell 083E instrument located at the flux tower has a precision for measuring Ta of C.
- Wind speed (U) affects canopy evaporation and associated heat flux partitioning. The precision of the CSAT3 measurement instrument at the tower for U is m/s.
- Vapor pressure deficit (VPD) is the difference between saturation water vapor pressure (es) and actual water vapor pressure (ea). It is the measure of atmospheric desiccation strength [46] and indicates the atmospheric demand for water vapor. The ea is determined by a large number of drivers and is also related to Ta in that it is upper bounded by es.
- Shortwave radiation (Rg) is a principle driver of , vapor, and heat exchange available in the system which controls photosynthesis and leaf energy balance.
- Precipitation (PPT) is often zero at the 15-min resolution considered here, such that changing the precision of PPT would not have any effect for most time steps.
- Carbon dioxide concentration (Ca) is a model parameter and is constant.
- Air pressure (Pa) varies within a very small range, and the model is relatively unresponsive to fluctuations in Pa. In other words, quantizing Pa would not lead to measurable differences in model behavior relative to other inputs.
- Canopy structure is described by leaf area density (LAD) profiles and the total leaf area index (LAI). In the model, the LAI is independent of all other forcing conditions and is based on surveys of maize or soybean plants throughout each year. It typically increases monotonically through the growing season and does not vary on a sub-daily to daily timescale.
2.2. Information Theory to Manipulate Forcing Precision
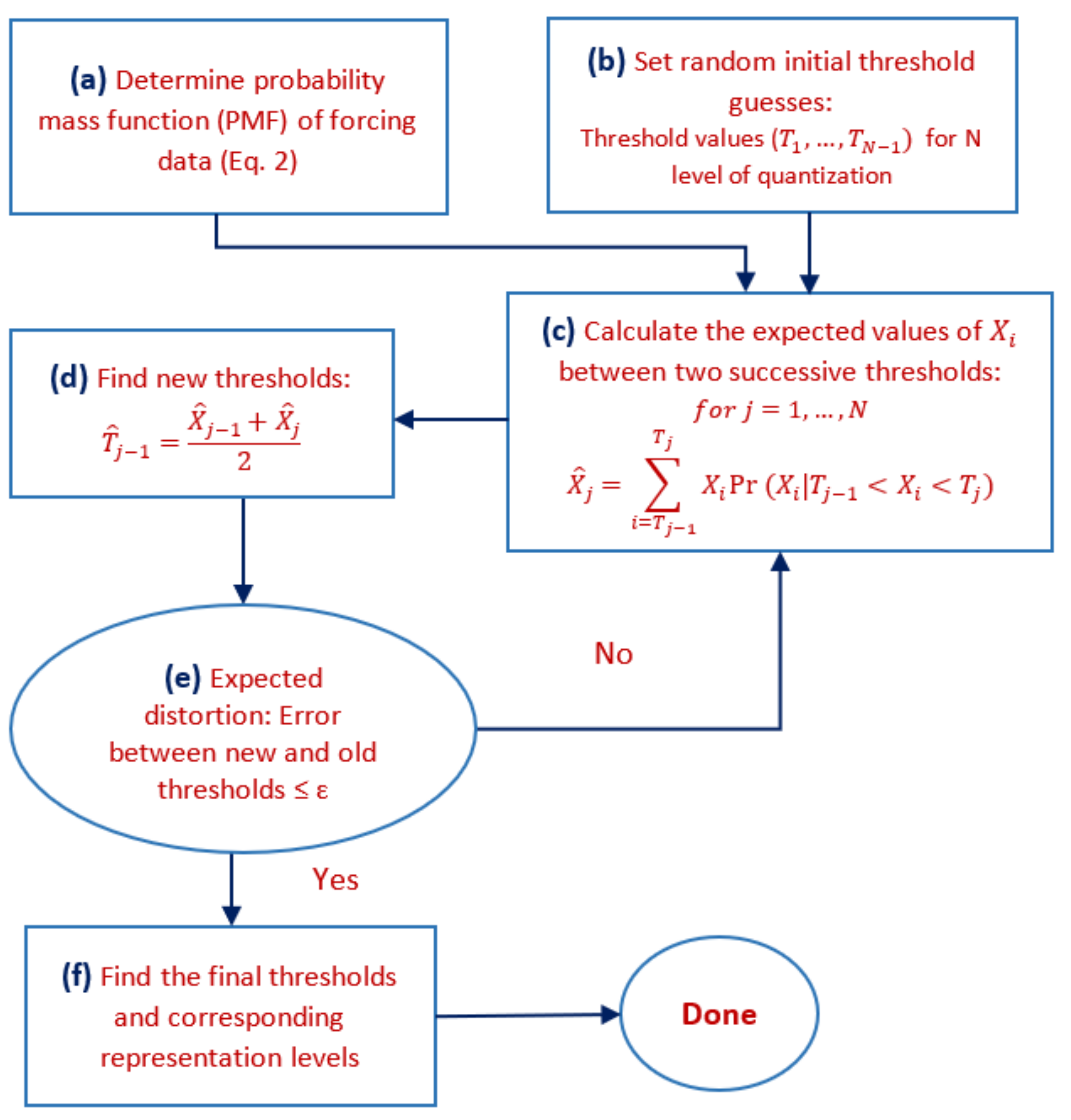
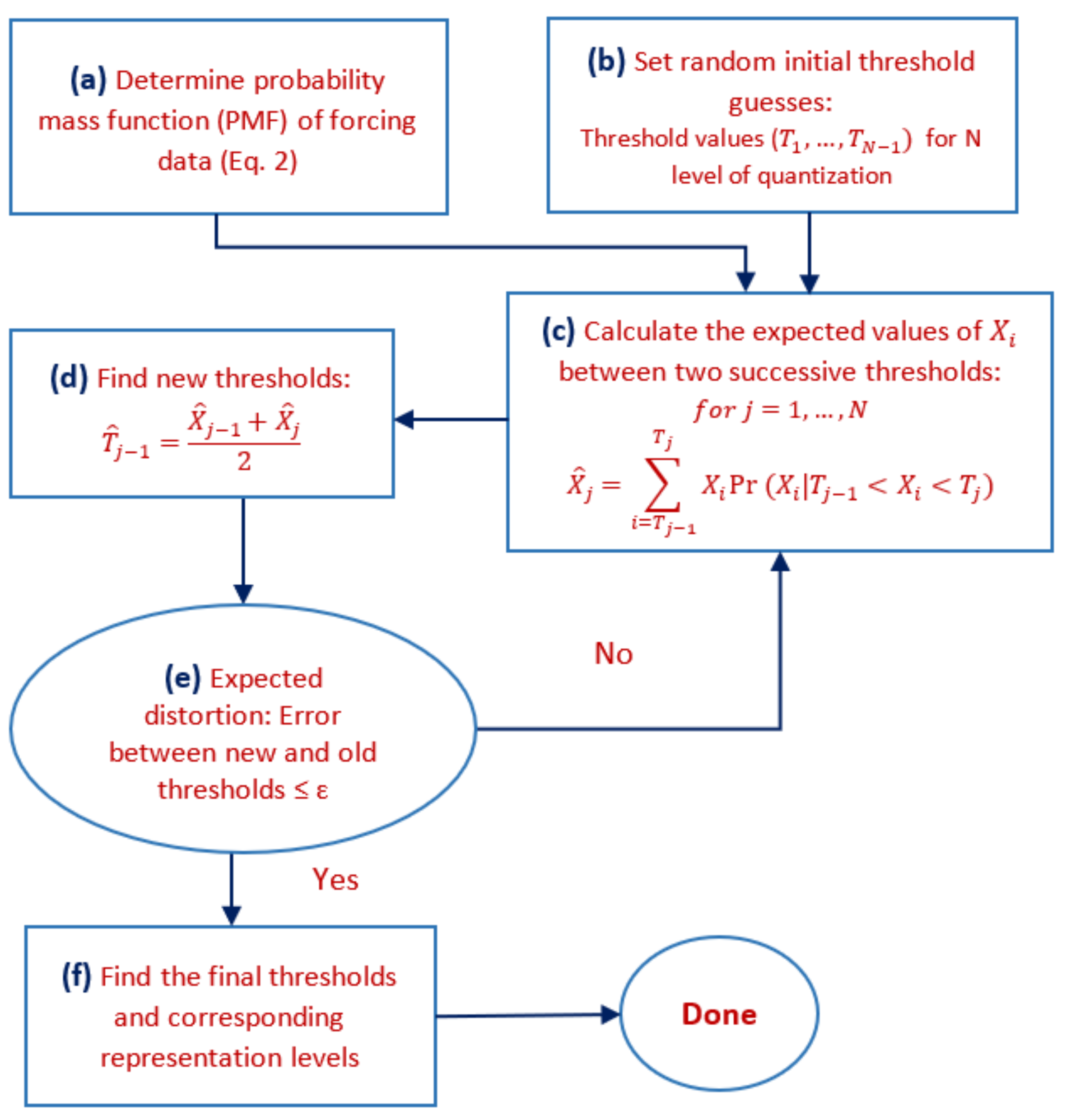
2.2.1. Quantization
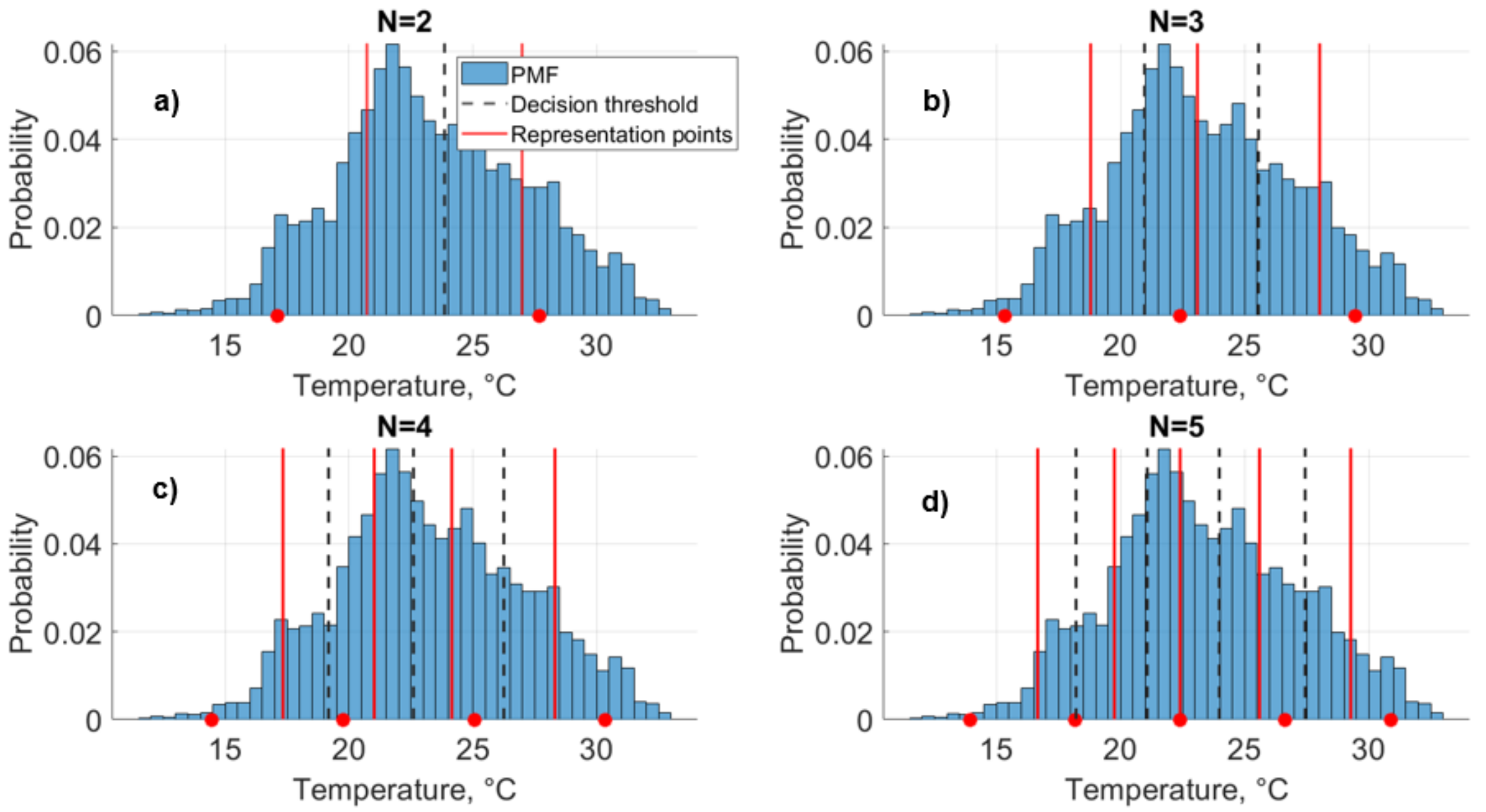
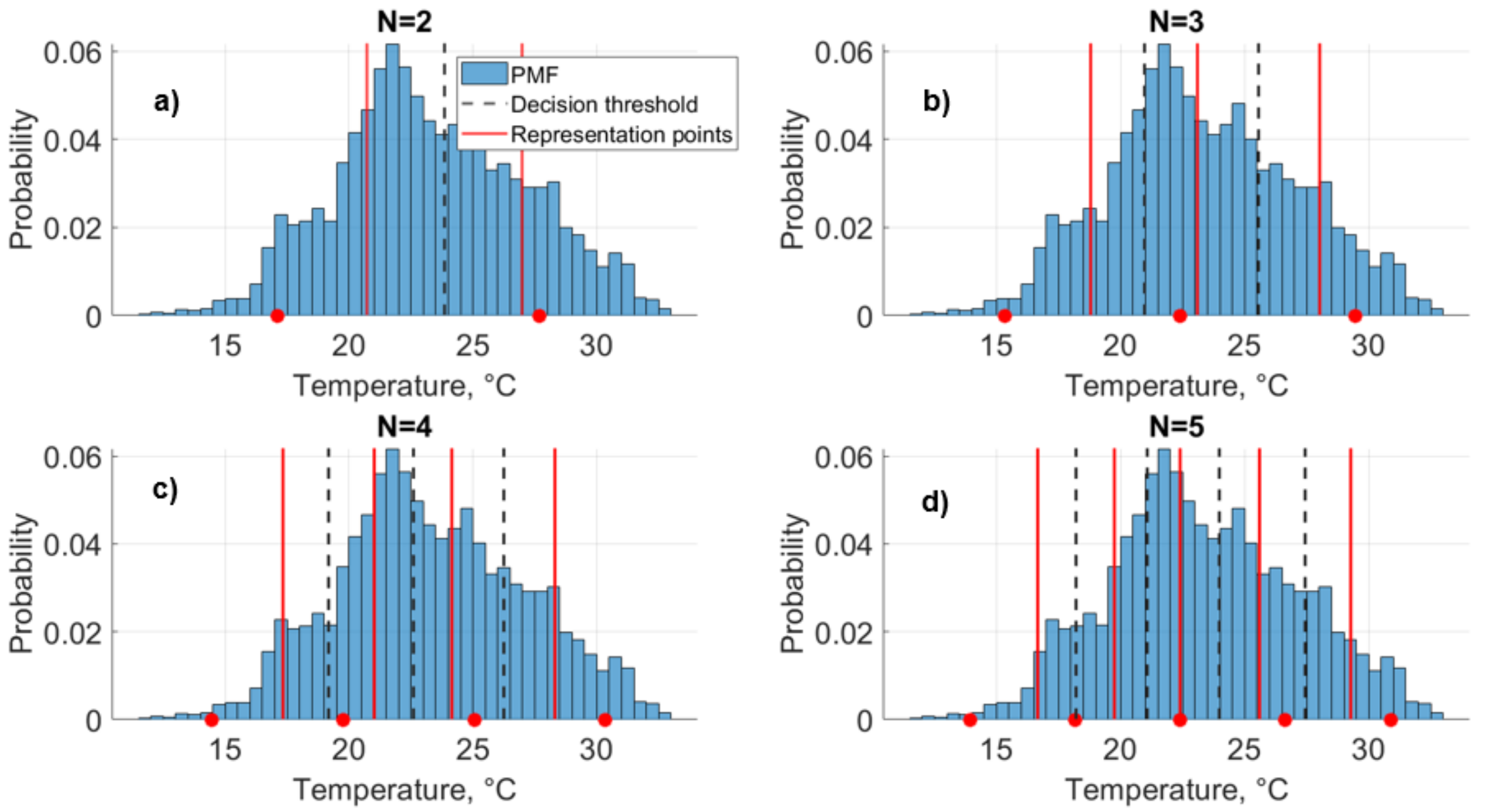
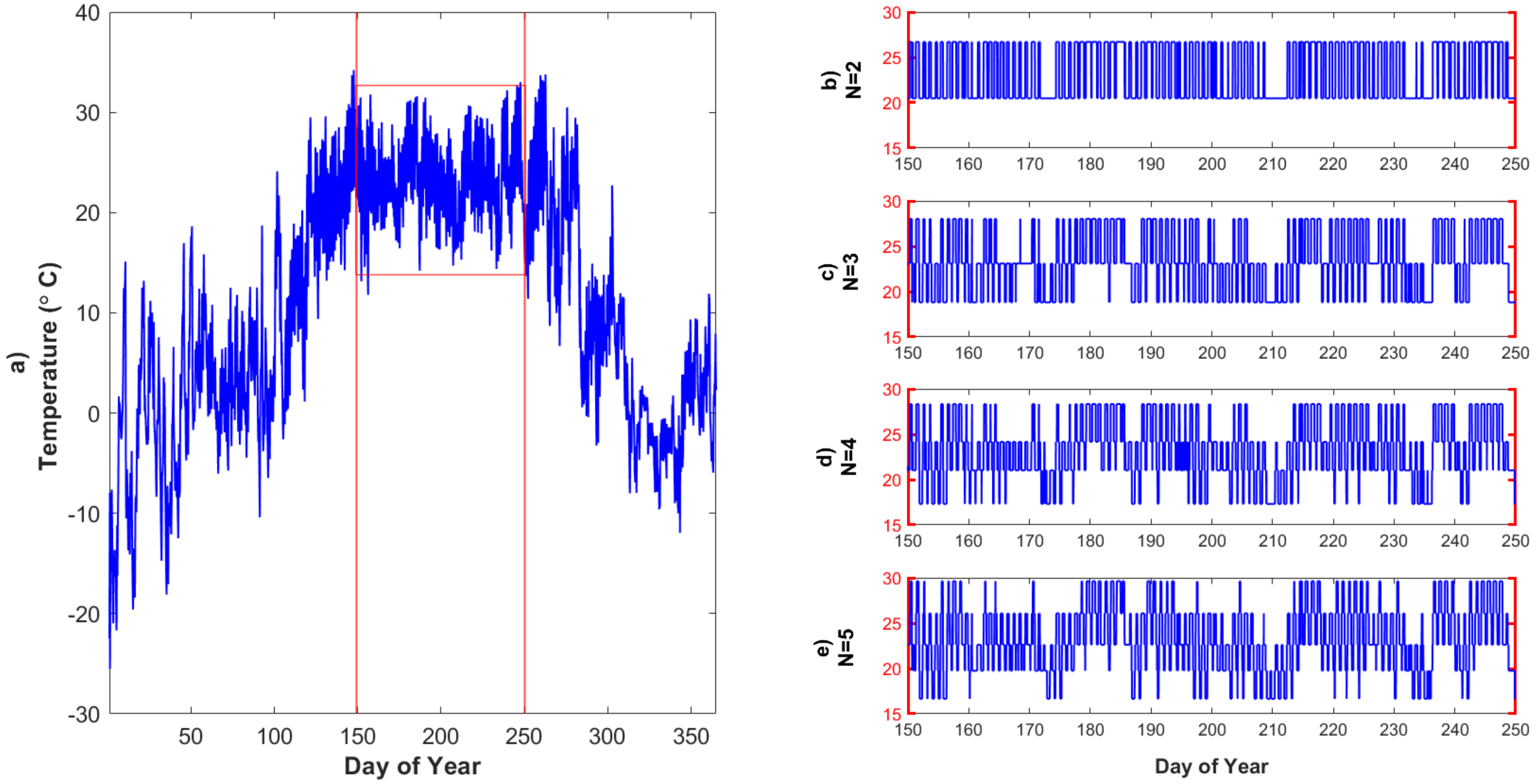
2.2.2. Illustrative Example of Quantization: Air Temperature
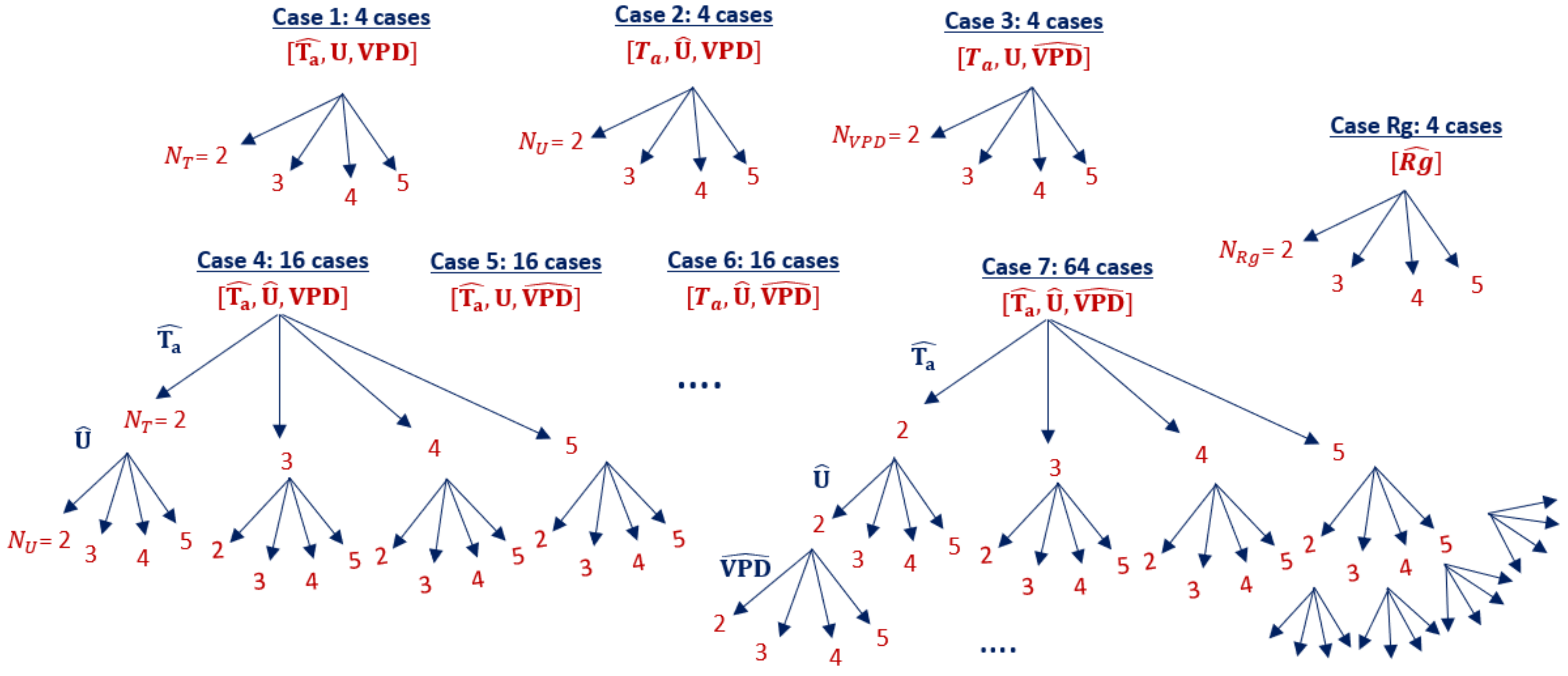
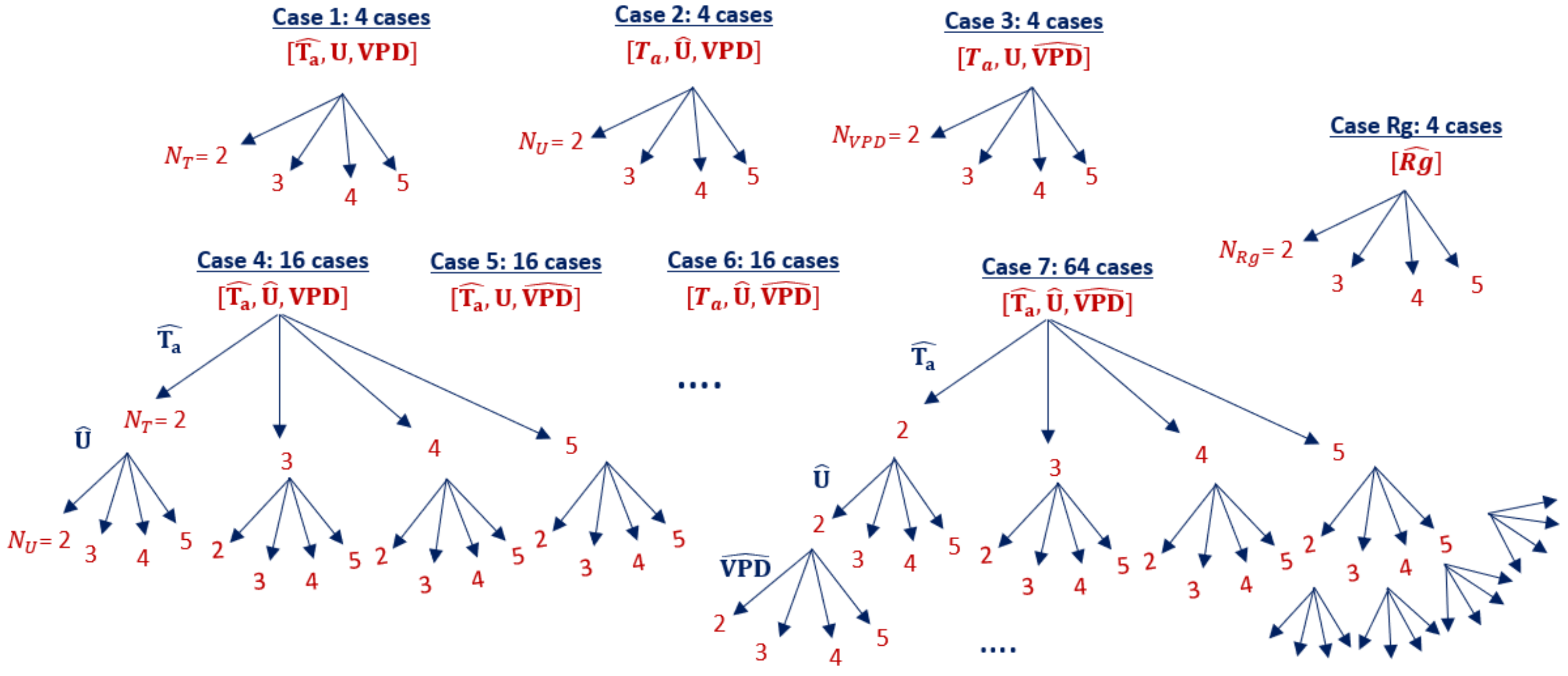
2.2.3. Quantized Model Cases
2.3. Sensitivity Analysis
3. Results
3.1. Effects of Quantizing Individual Forcing Variables
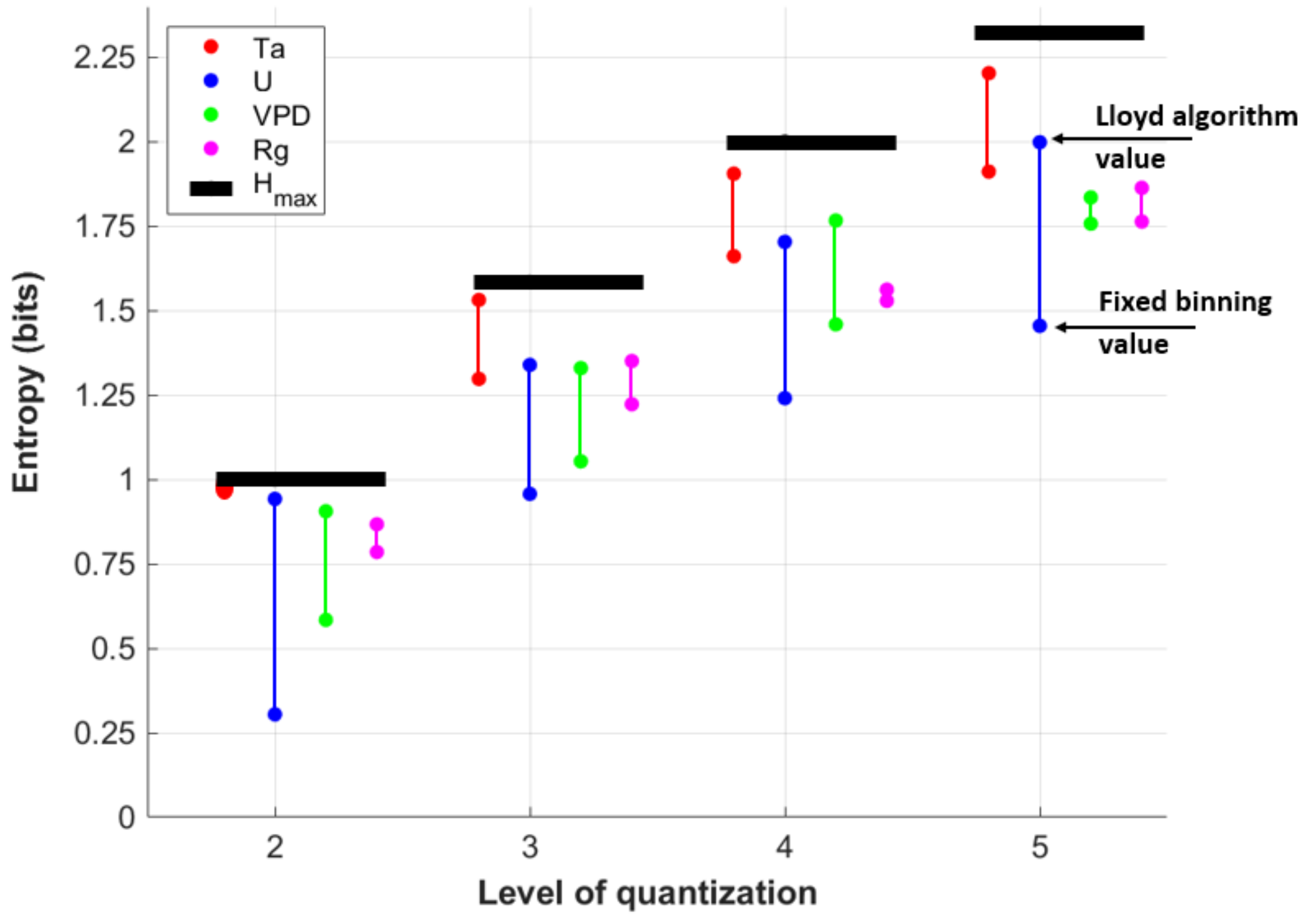
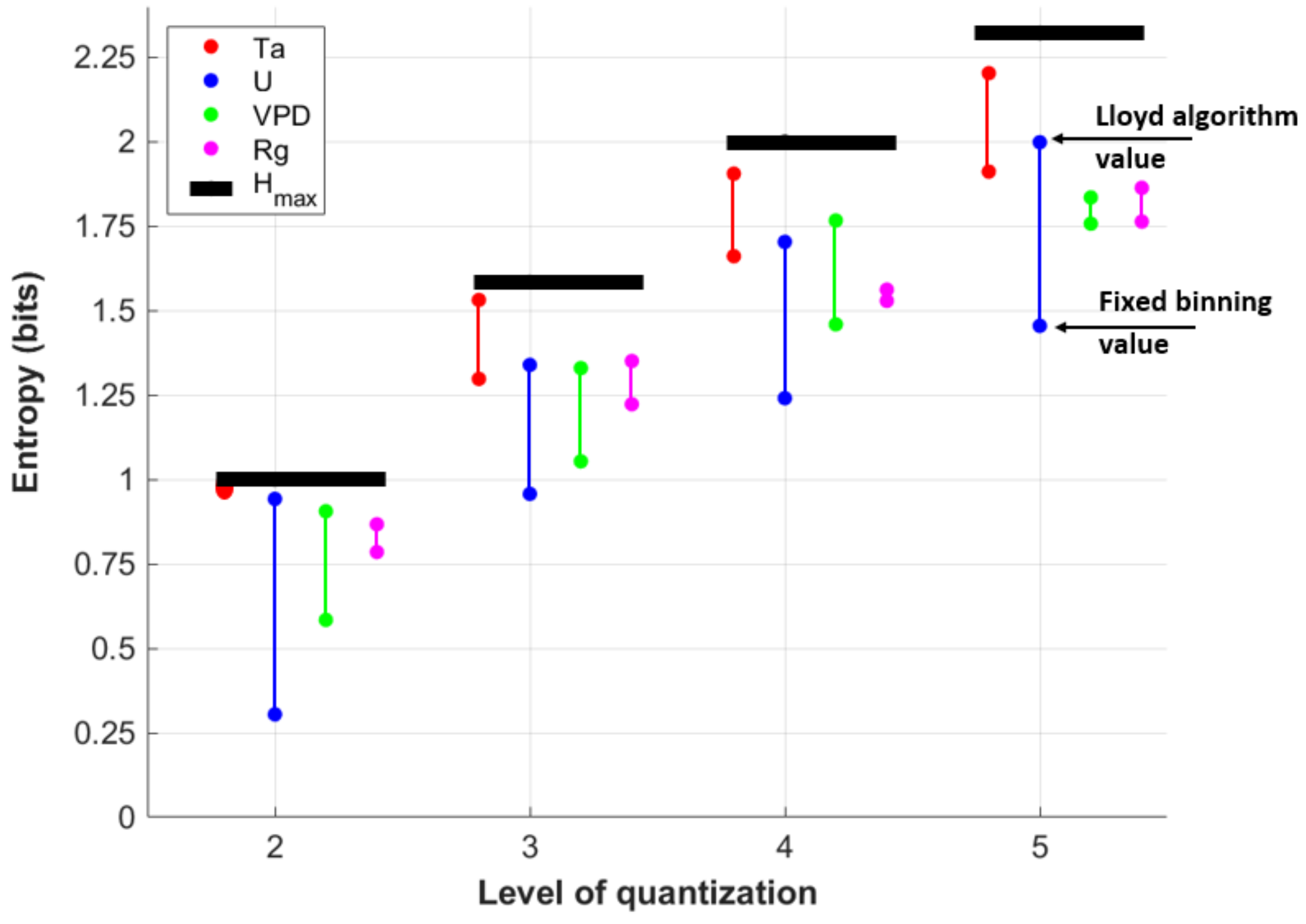
3.1.1. Entropy
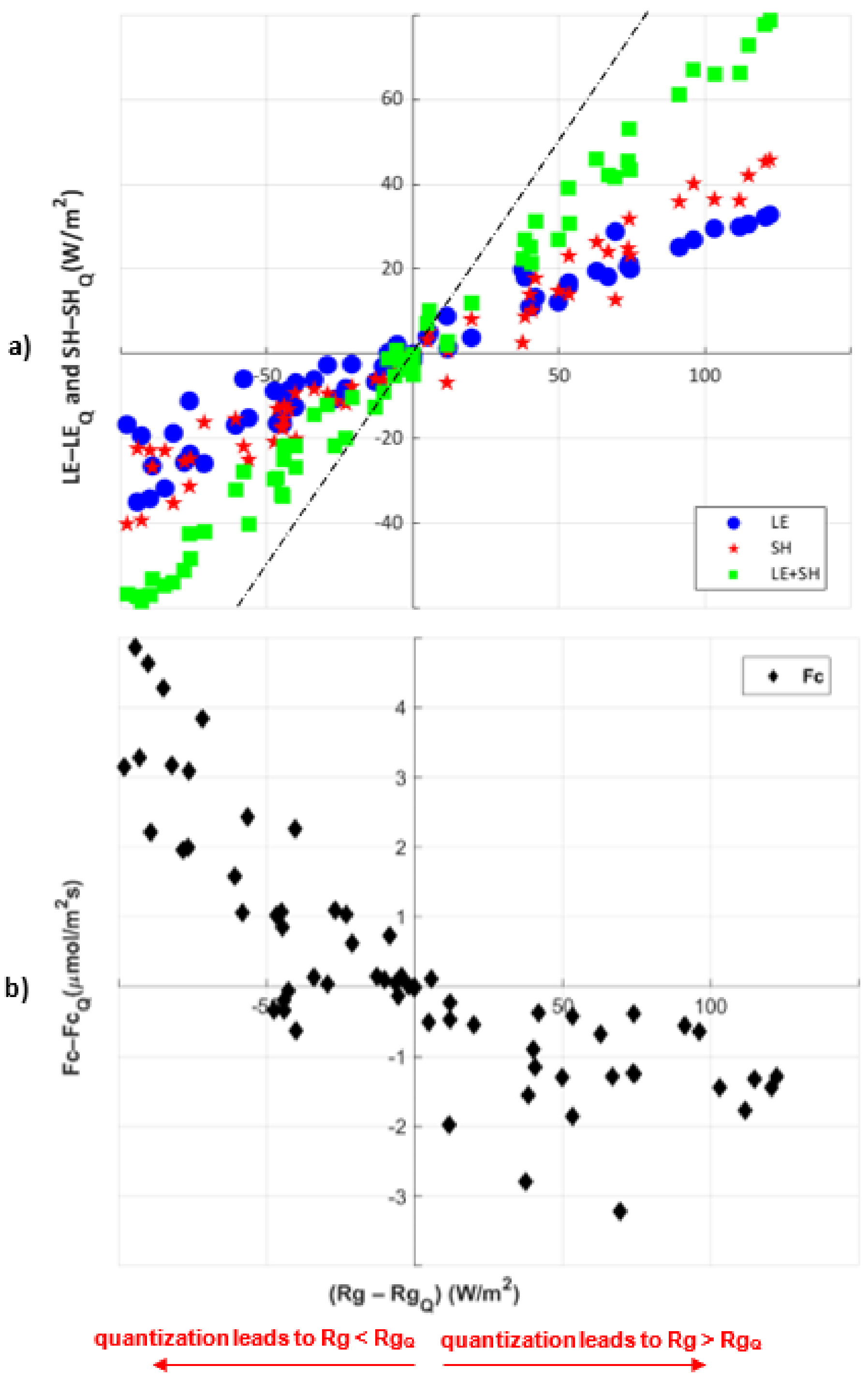
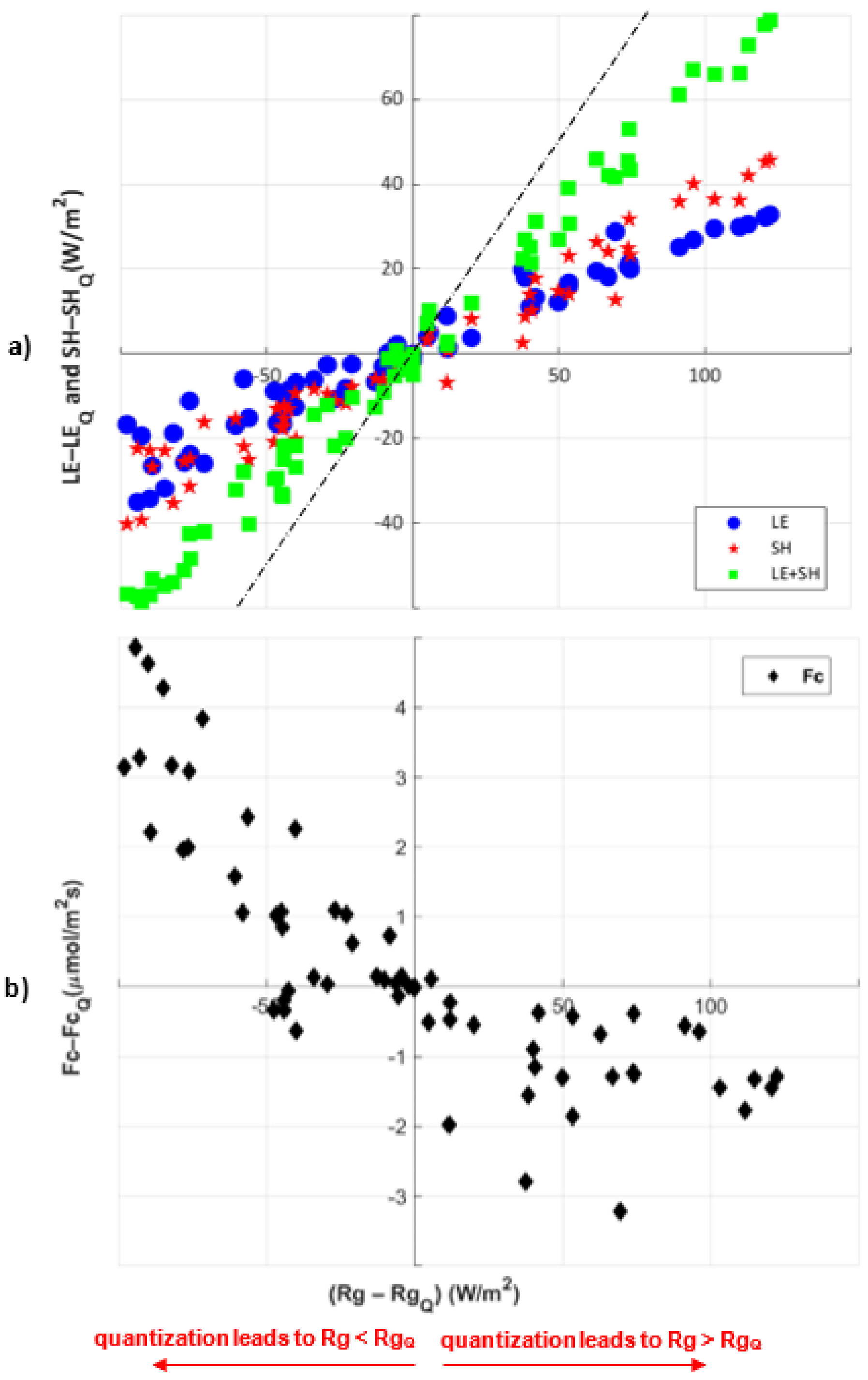
3.1.2. Quantizing Rg Only: Changing Energy Balance Precision
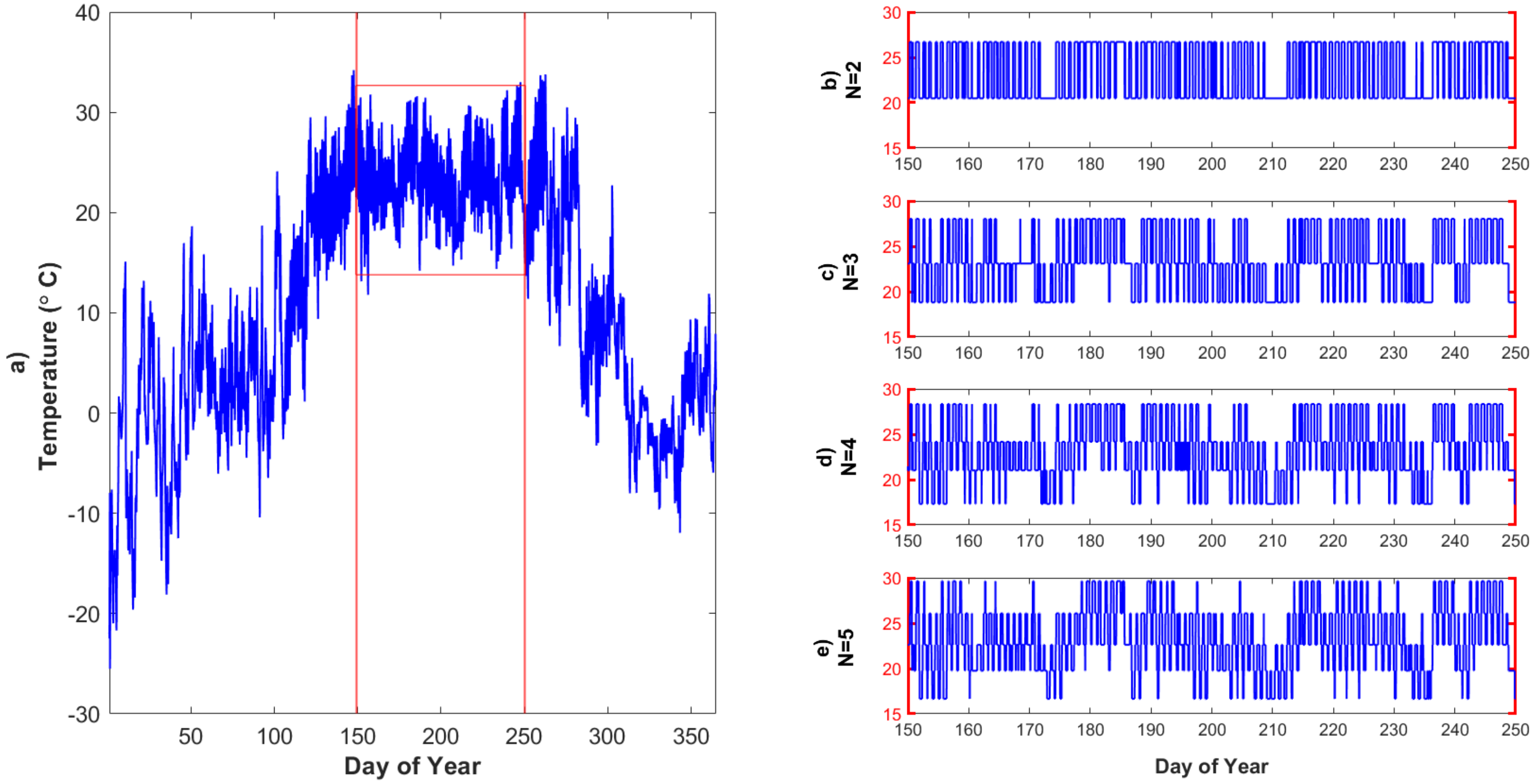
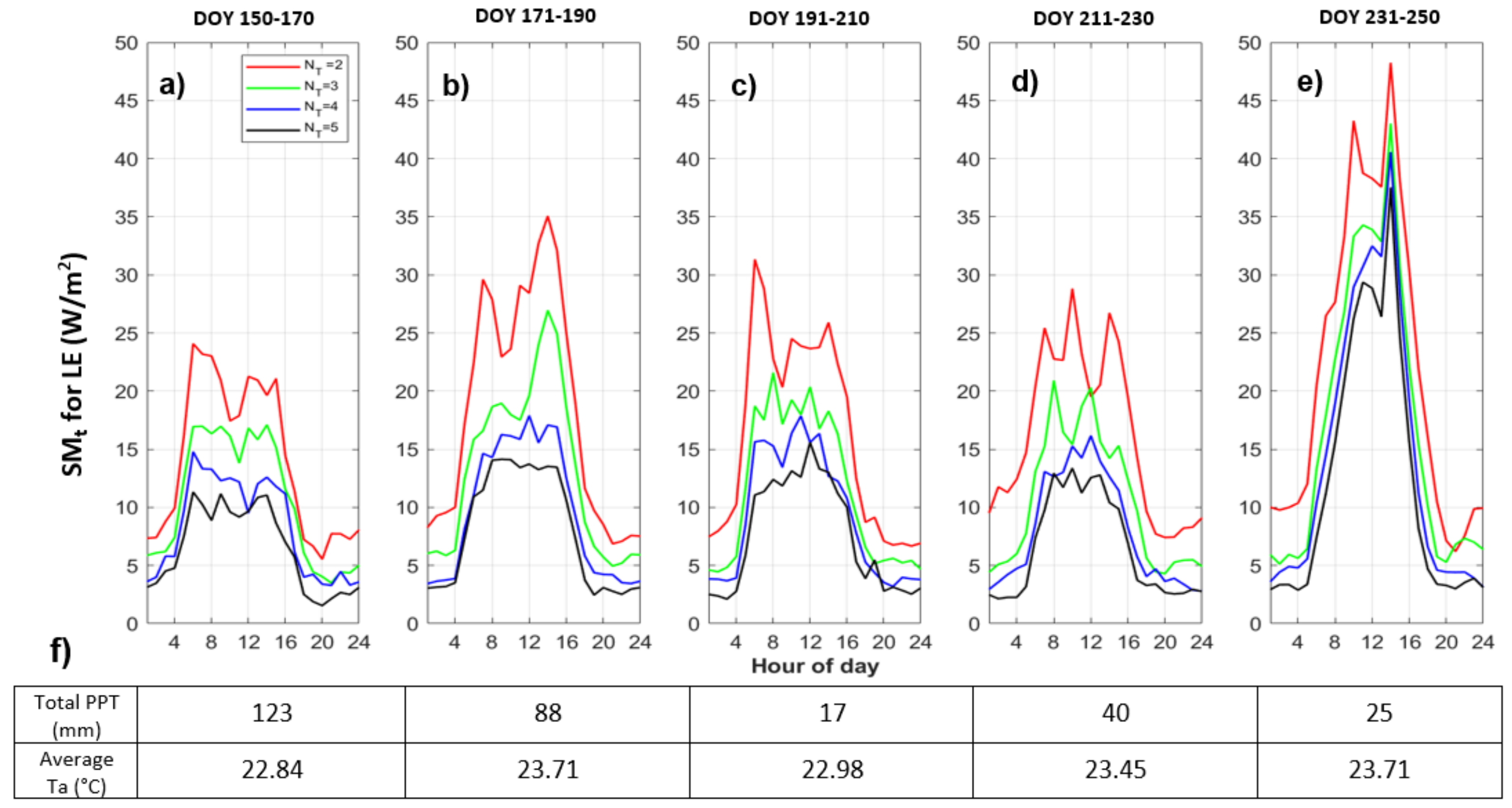
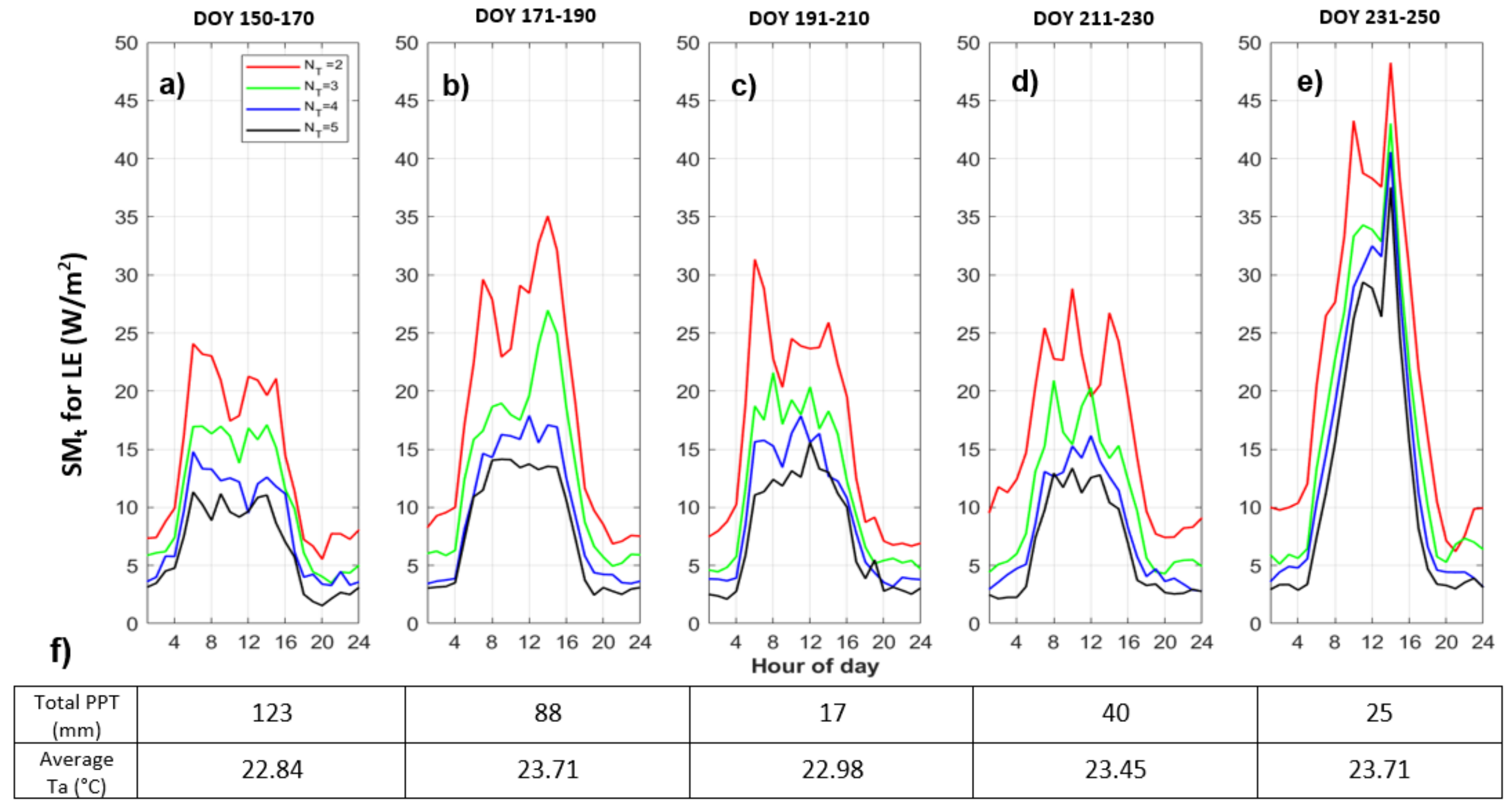
3.1.3. Quantizing Ta Only: Temporally Varying Responses to Quantization
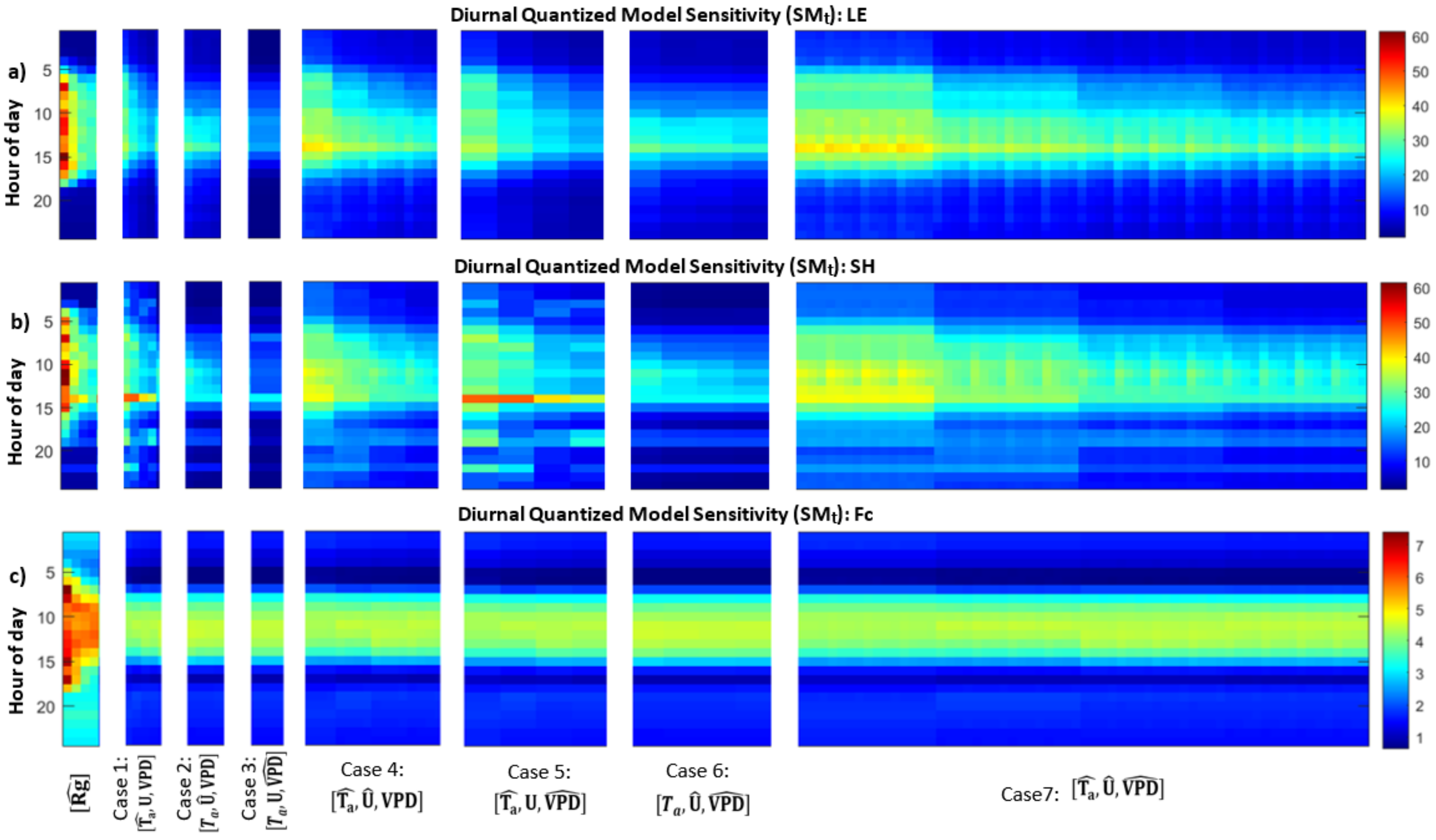
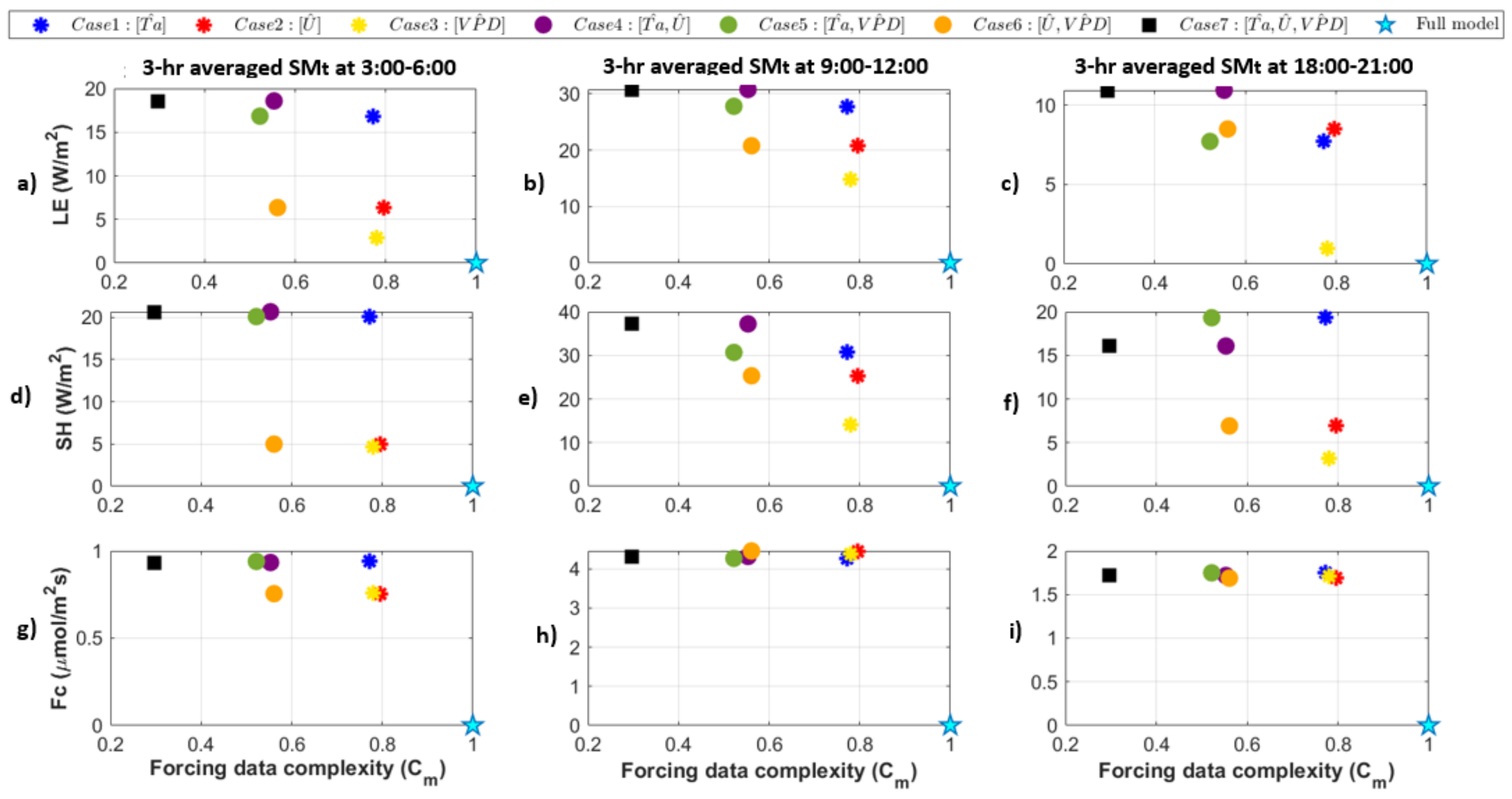
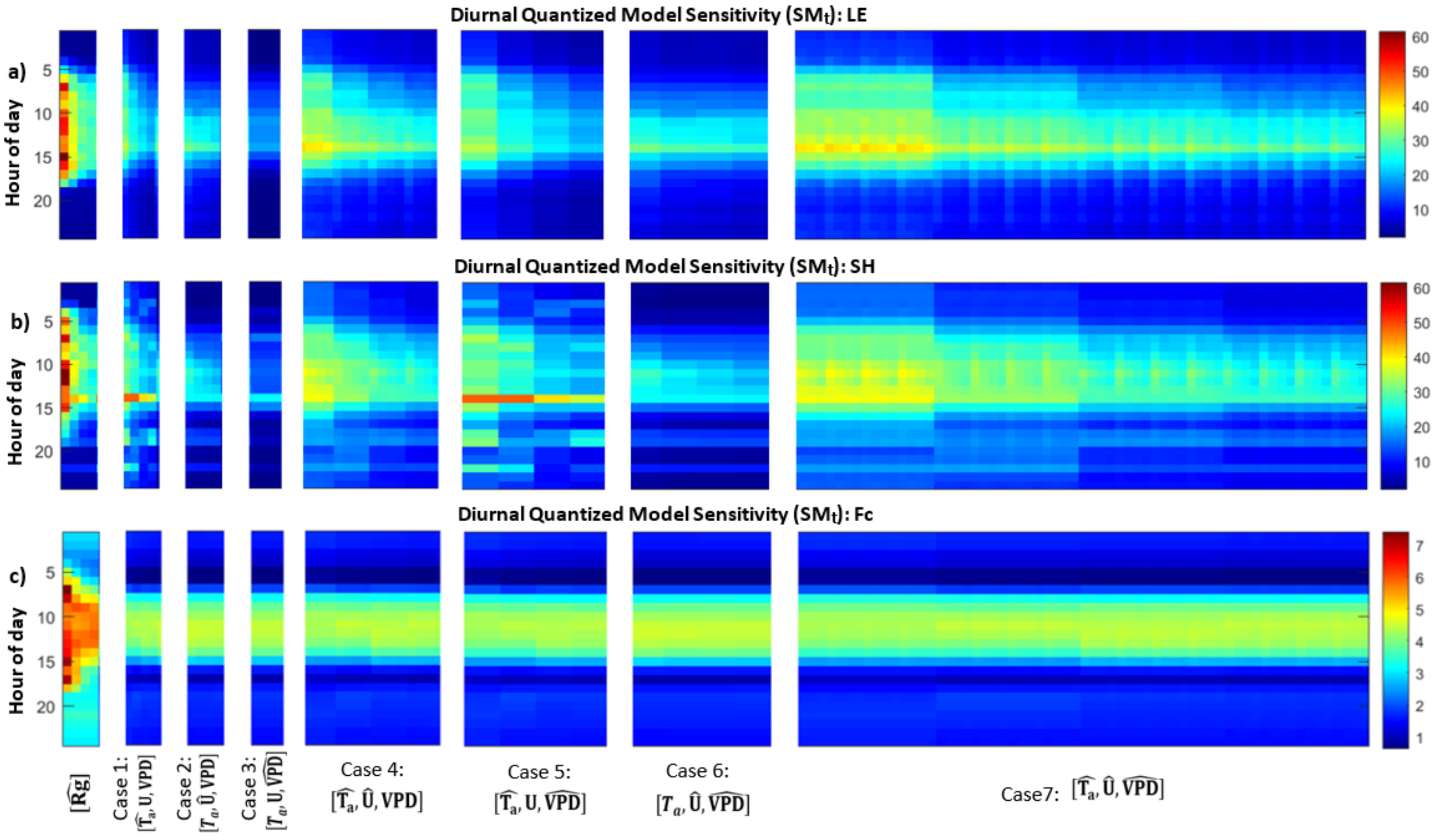
3.2. Model Sensitivity to Combinations of Forcing Precisions
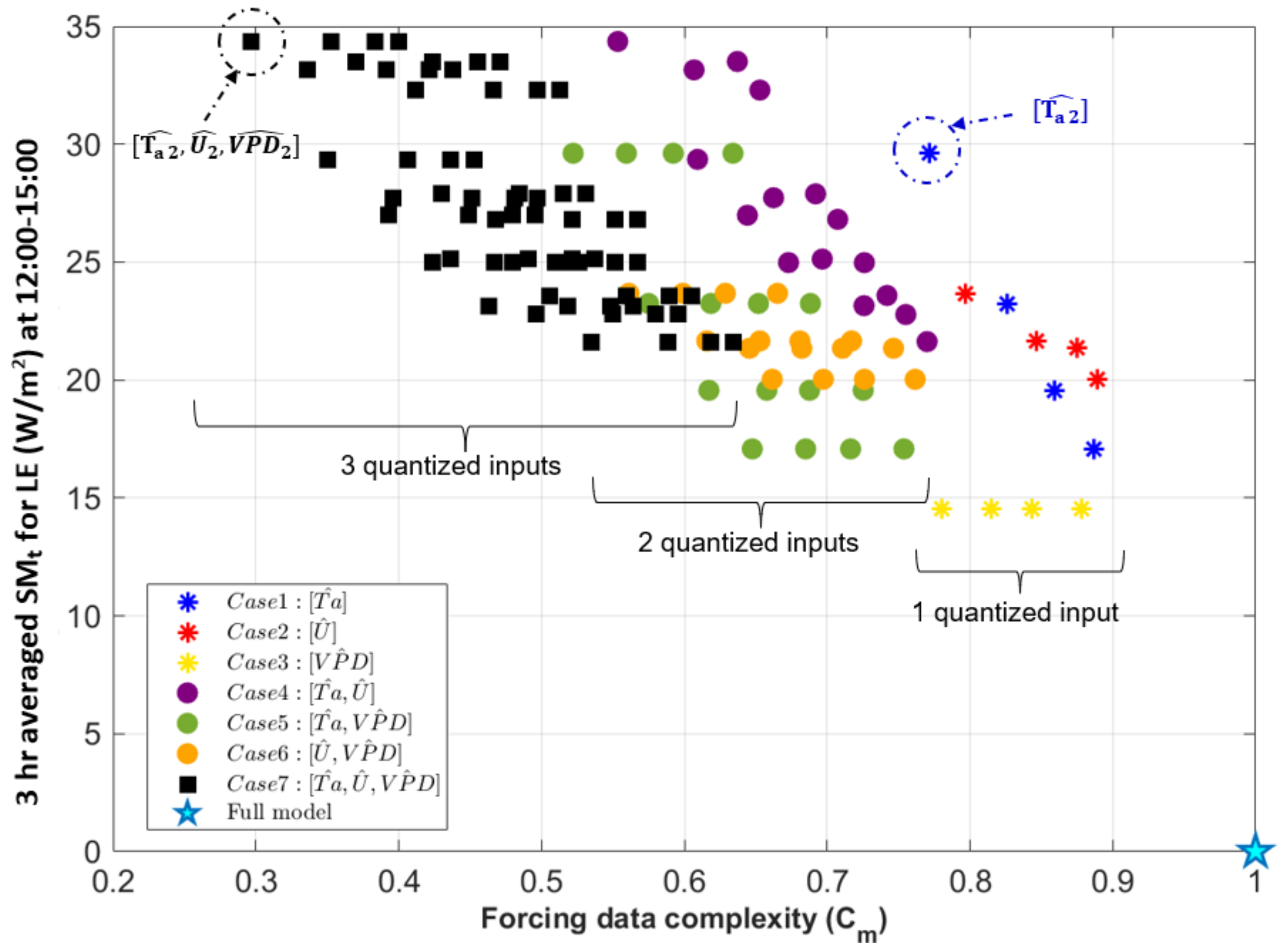
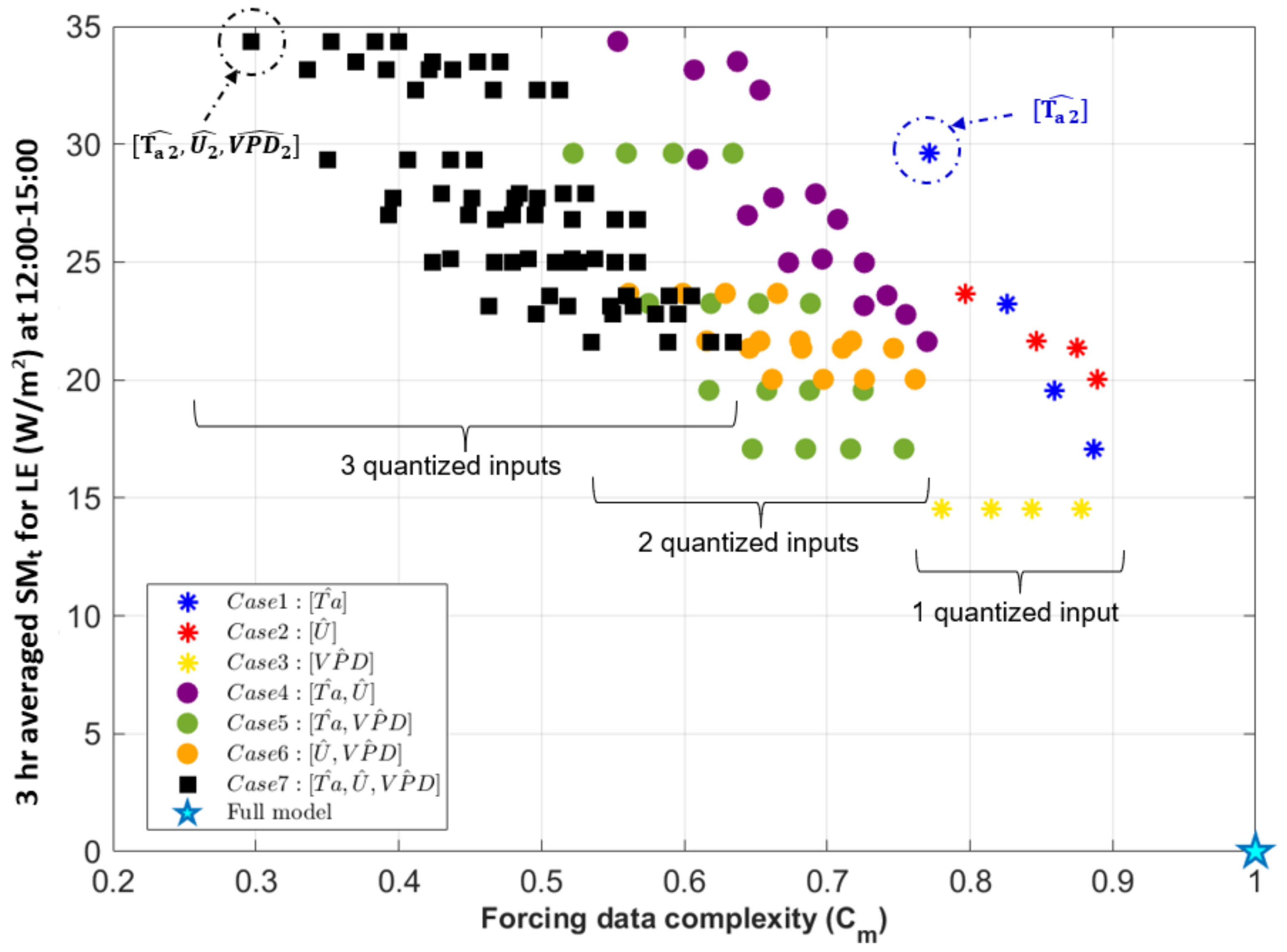
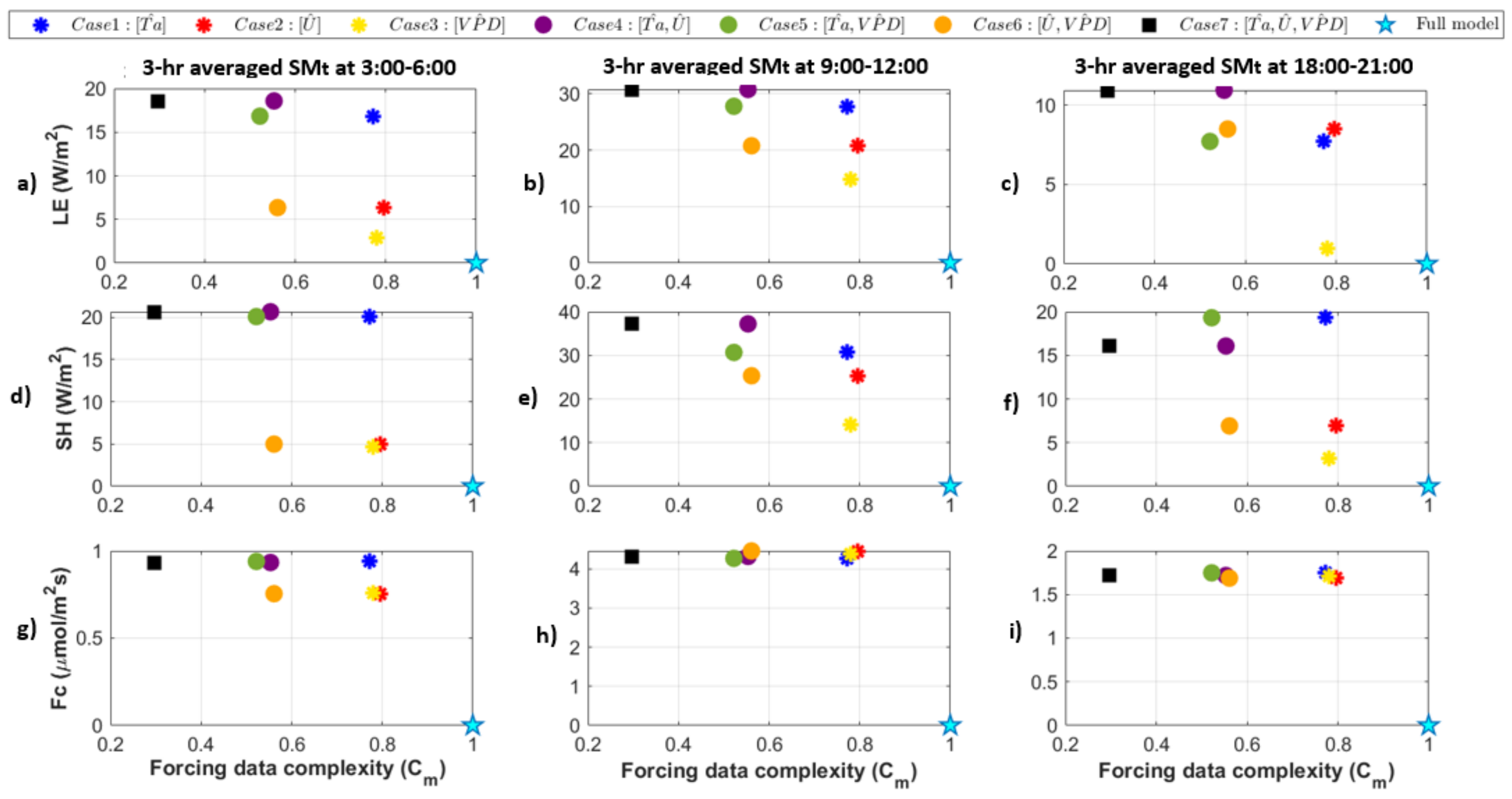
3.3. Forcing Complexity and Model Behaviors
- Quantized VPD (yellow asterisks in Figure 9) shows a horizontal pattern in the (, SMt) space, which means quantization decreases forcing data complexity, but different levels of quantization (between 2 and 5) do not affect model output for LE. This indicates that the modeled LE is somewhat responsive to a change away from the instrument precision of VPD but does not vary further as the precision VPD is decreased even more. In general, this forcing variable can be greatly simplified without changes in model sensitivity. Moreover, quantizing VPD leads to the lowest SMt indicating the lowest sensitivity at this time of day of Cases 1-3, for which a single variable is quantized.
- Quantized Ta (blue asterisks in Figure 9) similarly decreases forcing data complexity but results in different model behavior based on each level of quantization. For example, the scenario of Case 1 has the largest LE sensitivity among other individually quantized forcing variables at this time of day. This also translates to other quantized cases where Ta is quantized to levels (Case 4, 5, 7) that lead to higher model sensitivity.
- Finally, quantizing U (red asterisks in Figure 9) also influences both model behavior and forcing complexity. Quantization decreases forcing data complexity similarly, but model sensitivity is less than when Ta is quantized.
4. Discussion and Conclusions
- Energy balance constraints: When incoming solar radiation is quantized, sensible and latent heat fluxes shift to meet the energy balance with some gaps that can be attributed to other energy fluxes that are not analyzed here, specifically ground heat flux and longwave radiation. Canopy carbon fluxes respond more nonlinearly and depend on whether the quantization increases or decreases the apparent radiation.
- Temporal variability and dependence on system states: We next explored model effects of air temperature quantization for different growing season time windows. This highlighted the connection between model sensitivity to forcing precision and system states, such as wetness or vegetation conditions. For example, quantized air temperature most influences latent heat fluxes during a relatively hot and dry period at the end of the growing season. This connects to previous findings based on observed data that causal interactions in ecohydrologic systems vary seasonally and with wetness conditions [55].
- Joint effects of multiple forcing precisions: Finally, we quantized combinations of air temperature, vapor pressure deficit, and wind speed to different extents, and plotted model responses along a forcing complexity axis, where forcing complexity indicated the extent to which the joint entropy of the forcing variables was reduced. From this, we can determine which combinations of variables are “most compressible” in terms of their ability to reduce model forcing complexity and which lead to large changes in model behavior. For example, a quantization that leads to vary forcing complexity with a very small change in model behavior would indicate that the model is not sensitive to a particular input or combinations of inputs, and the model forcing or use of that input could be simplified in some way. On the other hand, this could also indicate that the model is not utilizing the full extent of available information in the forcing and could motivate other changes to the model structure. We saw a general trend in which simulated heat fluxes diverge more from the original model case as multiple variables were increasingly quantized, but there was a wide range of forcing complexities that led to the same model sensitivity. This illustrates that the effect of forcing precision varies depending on the degree of quantization (N) and the combination of variables involved. In other words, it is possible to determine a set of forcing variables that can be maximally simplified with minimal change in model behavior.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IT | Information Theory |
| SA | Sensitivity Analysis |
| SM | Sensitivity Metric |
| MLCan | Multi-Layer Canopy-soil-root |
| CINet | Critical Zone Interface Network |
| IMLCZO | Managed Landscape Critical Zone Observatory |
| RMSE | Root Mean Square Error |
| GSA | Global Sensitivity Analysis |
| SUMMA | Structure for Unifying Multiple Modeling Alternatives |
| JULES | Joint UK Land Environment Simulator |
| MMSE | Minimum Mean Square Error |
References
- Razavi, S.; Gupta, H.V. A new framework for comprehensive, robust, and efficient global sensitivity analysis: 1. Theory. Water Resour. Res. 2016, 52, 423–439. [Google Scholar] [CrossRef] [Green Version]
- Marshall, A.M.; Link, T.E.; Flerchinger, G.N.; Lucash, M.S. Importance of Parameter and Climate Data Uncertainty for Future Changes in Boreal Hydrology. Water Resour. Res. 2021, 57, e2021WR029911. [Google Scholar] [CrossRef]
- Beven, K.; Freer, J. Equifinality, data assimilation, and uncertainty estimation in mechanistic modeling of complex environmental systems using the GLUE methodology. J. Hydrol. 2001, 249, 11–29. [Google Scholar] [CrossRef]
- Franks, P.J.S. Models of harmful algal blooms. Limnol. Oceanogr. 1997, 42, 1273–1282. [Google Scholar] [CrossRef] [Green Version]
- Gupta, H.V.; Sorooshian, S.; Yapo, P.O. Toward improved calibration of hydrologic models: Multiple and noncommensurable measures of information. Water Resour. Res. 1998, 34, 751–763. [Google Scholar] [CrossRef]
- Schoups, G.; Van De Giesen, N.C.; Savenije, H.H. Model complexity control for hydrologic prediction. Water Resour. Res. 2008, 44, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Vrugt, J.A.; Gupta, H.V.; Bastidas, L.A.; Bouten, W.; Sorooshian, S. Effective and efficient algorithm for multiobjective optimization of hydrologic models. Water Resour. Res. 2003, 39, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Smith, M.B.; Seo, D.J.; Koren, V.I.; Reed, S.M.; Zhang, Z.; Duan, Q.; Moreda, F.; Cong, S. The distributed model intercomparison project (DMIP): Motivation and experiment design. J. Hydrol. 2004, 298, 4–26. [Google Scholar] [CrossRef]
- Saltelli, A.; Aleksankina, K.; Becker, W.; Fennell, P.; Ferretti, F.; Holst, N.; Li, S.; Wu, Q. Why so many published sensitivity analyses are false: A systematic review of sensitivity analysis practices. Environ. Model. Softw. 2019, 114, 29–39. [Google Scholar] [CrossRef]
- Razavi, S.; Gupta, H.V. What do we mean by sensitivity analysis? The need for comprehensive characterization of “global” sensitivity in Earth and Environmental systems models. Water Resour. Res. 2015, 51, 3070–3092. [Google Scholar] [CrossRef]
- Ruddell, B.L.; Drewry, D.T.; Nearing, G.S. Information Theory for Model Diagnostics: Structural Error is Indicated by Trade-Off Between Functional and Predictive Performance. Water Resour. Res. 2019, 55, 6534–6554. [Google Scholar] [CrossRef]
- Saltelli, A. Sensitivity Analysis for Importance Assessment. Risk Anal. 2002, 22, 579–590. [Google Scholar] [CrossRef] [PubMed]
- Nearing, G.S.; Ruddell, B.L.; Clark, M.P.; Nijssen, B.; Peters-Lidard, C. Benchmarking and process diagnostics of land models. J. Hydrometeorol. 2018, 19, 1835–1852. [Google Scholar] [CrossRef]
- Saltelli, A.; Ratto, M.; Andres, T.; Campolongo, F.; Cariboni, J.; Gatelli, D.; Saisana, M.; Tarantola, S. Global Sensitivity Analysis. The Primer; John Wiley & Sons: New York, NY, USA, 2008; Chapter 6. [Google Scholar] [CrossRef]
- Marshall, A.M.; Link, T.E.; Flerchinger, G.N.; Nicolsky, D.J.; Lucash, M.S. Ecohydrological modelling in a deciduous boreal forest: Model evaluation for application in non-stationary climates. Hydrol. Process. 2021, 35, e14251. [Google Scholar] [CrossRef]
- Legleiter, C.; Kyriakidis, P.; Mcdonald, R.; Nelson, J. Effects of uncertain topographic input data on two-dimensional flow modeling in a gravel-bed river. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Moreau, P.; Viaud, V.; Parnaudeau, V.; Salmon-Monviola, J.; Durand, P. An approach for global sensitivity analysis of a complex environmental model to spatial inputs and parameters: A case study of an agro-hydrological model. Environ. Model. Softw. 2013, 47, 74–87. [Google Scholar] [CrossRef]
- Clark, M.P.; Slater, A.G.; Rupp, D.E.; Woods, R.A.; Vrugt, J.A.; Gupta, H.V.; Wagener, T.; Hay, L.E. Framework for Understanding Structural Errors (FUSE): A modular framework to diagnose differences between hydrological models. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Baroni, G.; Tarantola, S. A General Probabilistic Framework for uncertainty and global sensitivity analysis of deterministic models: A hydrological case study. Environ. Model. Softw. 2014, 51, 26–34. [Google Scholar] [CrossRef]
- Hamm, N.A.; Hall, J.W.; Anderson, M.G. Variance-based sensitivity analysis of the probability of hydrologically induced slope instability. Comput. Geosci. 2006, 32, 803–817. [Google Scholar] [CrossRef]
- Gharari, S.; Gupta, H.V.; Clark, M.P.; Hrachowitz, M.; Fenicia, F.; Matgen, P.; Savenije, H.H.G. Understanding the Information Content in the Hierarchy of Model Development Decisions: Learning From Data. Water Resour. Res. 2021, 57, e2020WR027948. [Google Scholar] [CrossRef]
- Günther, D.; Marke, T.; Essery, R.; Strasser, U. Uncertainties in Snowpack Simulations—Assessing the Impact of Model Structure, Parameter Choice, and Forcing Data Error on Point-Scale Energy Balance Snow Model Performance. Water Resour. Res. 2019, 55, 2779–2800. [Google Scholar] [CrossRef] [Green Version]
- Magnusson, J.; Wever, N.; Essery, R.; Helbig, N.; Winstral, A.; Jonas, T. Evaluating snow models with varying process representations for hydrological applications. Water Resour. Res. 2015, 51, 2707–2723. [Google Scholar] [CrossRef] [Green Version]
- Essery, R.; Morin, S.; Lejeune, Y.; B Ménard, C. A comparison of 1701 snow models using observations from an alpine site. Adv. Water Resour. 2013, 55, 131–148. [Google Scholar] [CrossRef] [Green Version]
- Raleigh, M.S.; Lundquist, J.D.; Clark, M.P. Exploring the impact of forcing error characteristics on physically based snow simulations within a global sensitivity analysis framework. Hydrol. Earth Syst. Sci. 2015, 19, 3153–3179. [Google Scholar] [CrossRef] [Green Version]
- Weijs, S.V.; Ruddell, B.L. Debates: Does Information Theory Provide a New Paradigm for Earth Science? Sharper Predictions Using Occam’s Digital Razor. Water Resour. Res. 2020, 56, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Manshour, P.; Balasis, G.; Consolini, G.; Papadimitriou, C.; Paluš, M. Causality and Information Transfer Between the Solar Wind and the Magnetosphere–Ionosphere System. Entropy 2021, 23, 390. [Google Scholar] [CrossRef]
- Franzen, S.E.; Farahani, M.A.; Goodwell, A.E. Information Flows: Characterizing Precipitation-Streamflow Dependencies in the Colorado Headwaters With an Information Theory Approach. Water Resour. Res. 2020, 56, e2019WR026133. [Google Scholar] [CrossRef]
- Goodwell, A.E.; Kumar, P. Temporal Information Partitioning: Characterizing synergy, uniqueness, and redundancy in interacting environmental variables. Water Resour. Res. 2017, 53, 5920–5942. [Google Scholar] [CrossRef]
- Goodwell, A.E.; Kumar, P. Temporal Information Partitioning Networks (TIPNets): A process network approach to infer ecohydrologic shifts. Water Resour. Res. 2017, 53, 5899–5919. [Google Scholar] [CrossRef]
- Sendrowski, A.; Passalacqua, P. Process connectivity in a naturally prograding river delta. Water Resour. Res. 2017, 53, 1841–1863. [Google Scholar] [CrossRef]
- Balasis, G.; Donner, R.V.; Potirakis, S.M.; Runge, J.; Papadimitriou, C.; Daglis, I.A.; Eftaxias, K.; Kurths, J. Statistical Mechanics and Information-Theoretic Perspectives on Complexity in the Earth System. Entropy 2013, 15, 4844–4888. [Google Scholar] [CrossRef] [Green Version]
- Weijs, S.V.; Schoups, G.; van de Giesen, N. Why hydrological predictions should be evaluated using information theory. Hydrol. Earth Syst. Sci. 2010, 14, 2545–2558. [Google Scholar] [CrossRef] [Green Version]
- Nearing, G.S.; Mocko, D.M.; Peters-Lidard, C.D.; Kumar, S.V.; Xia, Y. Benchmarking NLDAS-2 Soil Moisture and Evapotranspiration to Separate Uncertainty Contributions. J. Hydrometeorol. 2016, 17, 745–759. [Google Scholar] [CrossRef] [PubMed]
- Sendrowski, A.; Sadid, K.; Meselhe, E.; Wagner, W.; Mohrig, D.; Passalacqua, P. Transfer Entropy as a Tool for Hydrodynamic Model Validation. Entropy 2018, 20, 58. [Google Scholar] [CrossRef] [Green Version]
- Tennant, C.; Larsen, L.; Bellugi, D.; Moges, E.; Zhang, L.; Ma, H. The utility of information flow in formulating discharge forecast models: A case study from an arid snow-dominated catchment. Water Resour. Res. 2020, 56, e2019WR024908. [Google Scholar] [CrossRef]
- Gong, W.; Yang, D.; Gupta, H.V.; Nearing, G. Estimating information entropy for hydrological data: One-dimensional case. Water Resour. Res. 2014, 50, 5003–5018. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2005; pp. 1–748. [Google Scholar] [CrossRef]
- Drewry, D.T.; Kumar, P.; Long, S.; Bernacchi, C.; Liang, X.Z.; Sivapalan, M. Ecohydrological responses of dense canopies to environmental variability: 1. Interplay between vertical structure and photosynthetic pathway. J. Geophys. Res. Biogeosci. 2010, 115. [Google Scholar] [CrossRef]
- Drewry, D.T.; Kumar, P.; Long, S.; Bernacchi, C.; Liang, X.Z.; Sivapalan, M. Ecohydrological responses of dense canopies to environmental variability: 2. Role of acclimation under elevated CO2. J. Geophys. Res. Biogeosci. 2010, 115, 1–22. [Google Scholar] [CrossRef]
- Ball, J.; Woodrow, I.; Berry, J. A Model Predicting Stomatal Conductance and Its Contribution to the Control of Photosynthesis Under Different Environmental Conditions. Prog. Photosynth. Res. 1987, 4, 221–224. [Google Scholar] [CrossRef]
- Leclerc, M.Y.; Foken, T. Footprints in Micrometeorology and Ecology; Spriner: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Schuepp, P.; Leclerc, M.; MacPherson, J.; Desjardins, R. Footprint prediction of scalar fluxes from analytical solutions of the diffusion equation. Bound.-Layer Meteorol. 1990, 50, 355–373. [Google Scholar] [CrossRef]
- Hernandez Rodriguez, L.C.; Goodwell, A.E.; Kumar, P. Inside the flux footprint: Understanding the role of organized land cover heterogeneity on land-atmospheric fluxes. Water Resour. Res. 2021; in review. [Google Scholar] [CrossRef]
- Seager, R.; Hooks, A.; Williams, A.P.; Cook, B.I.; Nakamura, J.; Henderson, N. Climatology, variability and trends in United States vapor pressure deficit, an important fire-related meteorological quantity. J. Appl. Meteorol. Climatol. 2015, 54, 1121–1141. [Google Scholar] [CrossRef]
- Sayood, K. Introduction to Data Compression, 5th ed.; The Morgan Kaufmann Series in Multimedia Information and Systems, Morgan Kaufmann; Elsevier: Amsterdam, The Netherlands, 2018; p. iv. [Google Scholar] [CrossRef]
- Scott, D.W. On optimal and data-based histograms. Biometrika 1979, 66, 605–610. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Vahid, A.; Suh, C.; Avestimehr, A.S. Interference channels with rate-limited feedback. IEEE Trans. Inf. Theory 2011, 58, 2788–2812. [Google Scholar] [CrossRef] [Green Version]
- Vahid, A.; Maddah-Ali, M.A.; Avestimehr, A.S. Approximate capacity region of the MISO broadcast channels with delayed CSIT. IEEE Trans. Commun. 2016, 64, 2913–2924. [Google Scholar] [CrossRef]
- Mappouras, G.; Vahid, A.; Calderbank, R.; Sorin, D.J. Extending flash lifetime in embedded processors by expanding analog choice. IEEE Trans. -Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2462–2473. [Google Scholar] [CrossRef]
- Vahid, A. Distortion-Based Outer-Bounds for Channels with Rate-Limited Feedback. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Melbourne, Australia, 11–16 July 2021. [Google Scholar]
- Gupta, H.V.; Ehsani, M.R.; Roy, T.; Sans-Fuentes, M.A.; Ehret, U.; Behrangi, A. Computing Accurate Probabilistic Estimates of One-D Entropy from Equiprobable Random Samples. Entropy 2021, 23, 740. [Google Scholar] [CrossRef]
- Goodwell, A.E.; Jiang, P.; Ruddell, B.L.; Kumar, P. Debates—Does Information Theory Provide a New Paradigm for Earth Science? Causality, Interaction, and Feedback. Water Resour. Res. 2020, 56, e2019WR024940. [Google Scholar] [CrossRef] [Green Version]
- Clark, M.P.; Nijssen, B.; Lundquist, J.D.; Kavetski, D.; Rupp, D.E.; Woods, R.A.; Freer, J.E.; Gutmann, E.D.; Wood, A.W.; Gochis, D.J.; et al. A unified approach for process-based hydrologic modeling: 2. Model implementation and case studies. Water Resour. Res. 2015, 51, 2515–2542. [Google Scholar] [CrossRef] [Green Version]
- Best, M.J.; Pryor, M.; Clark, D.B.; Rooney, G.G.; Essery, R.L.H.; Ménard, C.B.; Edwards, J.M.; Hendry, M.A.; Porson, A.; Gedney, N.; et al. The Joint UK Land Environment Simulator (JULES), model description—Part 1: Energy and water fluxes. Geosci. Model Dev. 2011, 4, 677–699. [Google Scholar] [CrossRef] [Green Version]
- Niu, G.Y.; Yang, Z.L.; Mitchell, K.E.; Chen, F.; Ek, M.B.; Barlage, M.; Kumar, A.; Manning, K.; Niyogi, D.; Rosero, E.; et al. The community Noah land surface model with multiparameterization options (Noah-MP): 1. Model description and evaluation with local-scale measurements. J. Geophys. Res. Atmos. 2011, 116. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Zhang, J.; Zhan, C.; Xuan, Y.; Ye, M.; Xu, C. Global sensitivity analysis in hydrological modeling: Review of concepts, methods, theoretical framework, and applications. J. Hydrol. 2015, 523, 739–757. [Google Scholar] [CrossRef] [Green Version]
- Sobol’, I.M. Sensitivity analysis for non-linear mathematical models. Math. Model. Comput. Exp. 1993, 1, 407–414. [Google Scholar]
- McKay, M.D. Evaluating Prediction Uncertainty; Technical Report; Nuclear Regulatory Commission: Washington, DC, USA, 1995. [Google Scholar]
- Khorashadi Zadeh, F.; Nossent, J.; Sarrazin, F.; Pianosi, F.; van Griensven, A.; Wagener, T.; Bauwens, W. Comparison of variance-based and moment-independent global sensitivity analysis approaches by application to the SWAT model. Environ. Model. Softw. 2017, 91, 210–222. [Google Scholar] [CrossRef] [Green Version]
- Raleigh, M.; Livneh, B.; Lapo, K.; Lundquist, J. How Does Availability of Meteorological Forcing Data Impact Physically Based Snowpack Simulations? J. Hydrometeorol. 2016, 17, 150904104740009. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Variable | Unit | Stdev | Opt Bin Width |
|---|---|---|---|
| Ta | C | 3.7878 | 0.5 |
| U | m s | 1.7032 | 0.3 |
| VPD | kPa | 0.6029 | 0.1 |
| Rg | W/m | 349.02 | 50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farahani, M.A.; Vahid, A.; Goodwell, A.E. Evaluating Ecohydrological Model Sensitivity to Input Variability with an Information-Theory-Based Approach. Entropy 2022, 24, 994. https://doi.org/10.3390/e24070994
Farahani MA, Vahid A, Goodwell AE. Evaluating Ecohydrological Model Sensitivity to Input Variability with an Information-Theory-Based Approach. Entropy. 2022; 24(7):994. https://doi.org/10.3390/e24070994
Chicago/Turabian StyleFarahani, Mozhgan A., Alireza Vahid, and Allison E. Goodwell. 2022. "Evaluating Ecohydrological Model Sensitivity to Input Variability with an Information-Theory-Based Approach" Entropy 24, no. 7: 994. https://doi.org/10.3390/e24070994
APA StyleFarahani, M. A., Vahid, A., & Goodwell, A. E. (2022). Evaluating Ecohydrological Model Sensitivity to Input Variability with an Information-Theory-Based Approach. Entropy, 24(7), 994. https://doi.org/10.3390/e24070994