
Analysis on Optimal Error Exponents of Binary Classification for Source with Multiple Subclasses

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Background
1.2. Contributions
1.3. Related Work
1.4. Organization
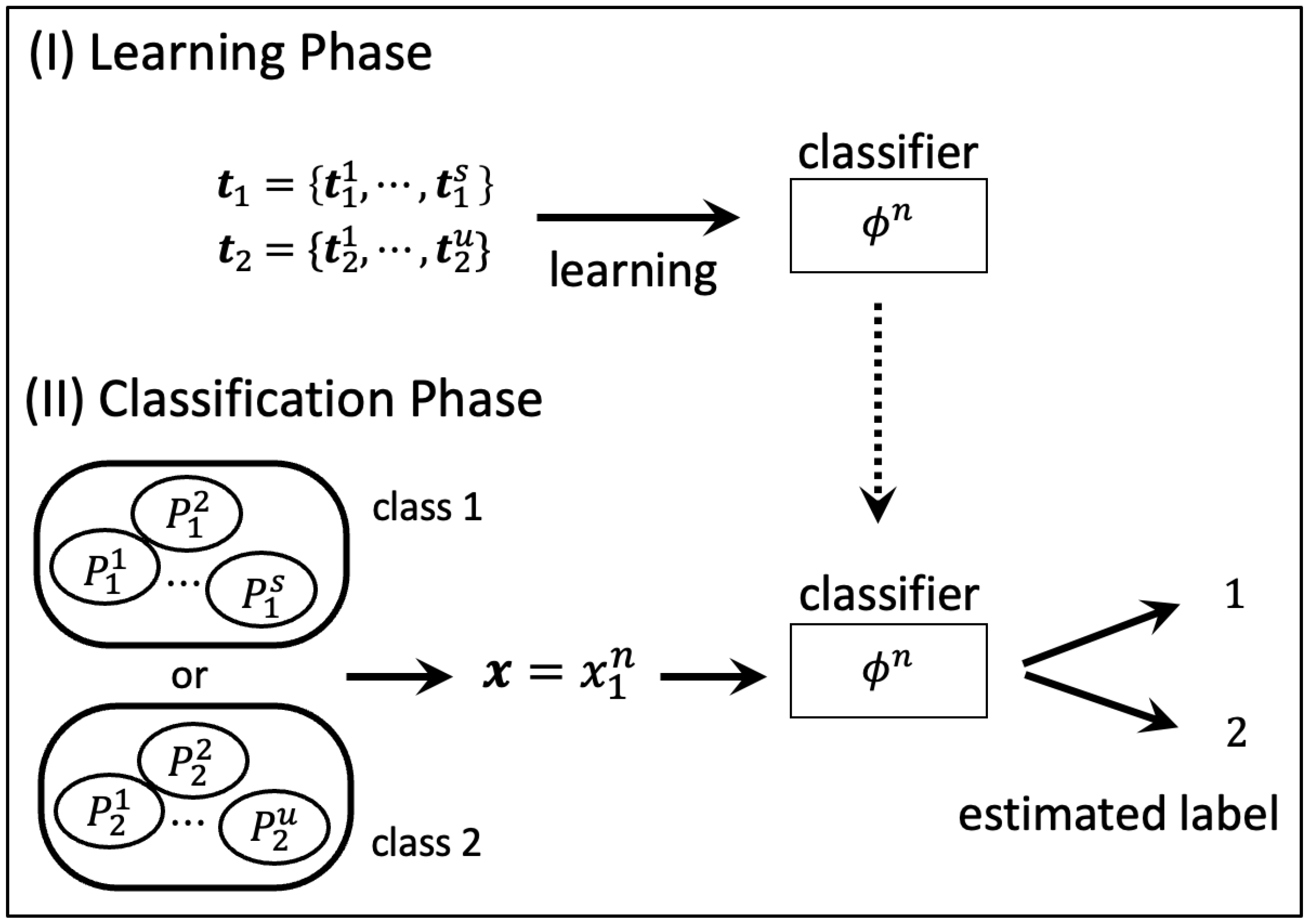
2. Problem Formulation
2.1. Notation
2.2. Source with Multiple Subclasses
2.3. System Model
2.4. Maximum Error Exponent
3. Main Result
3.1. A Test to Achieve Maximum Error Exponent
3.2. First-Order Maximum Error Exponent
3.3. Proof of Theorem 2
3.3.1. Achievability Part
3.3.2. Converse Part
3.4. Second-Order Maximum Error Exponent
4. Generalization to Mixed Memoryless Sources with General Mixture
5. Numerical Calculation
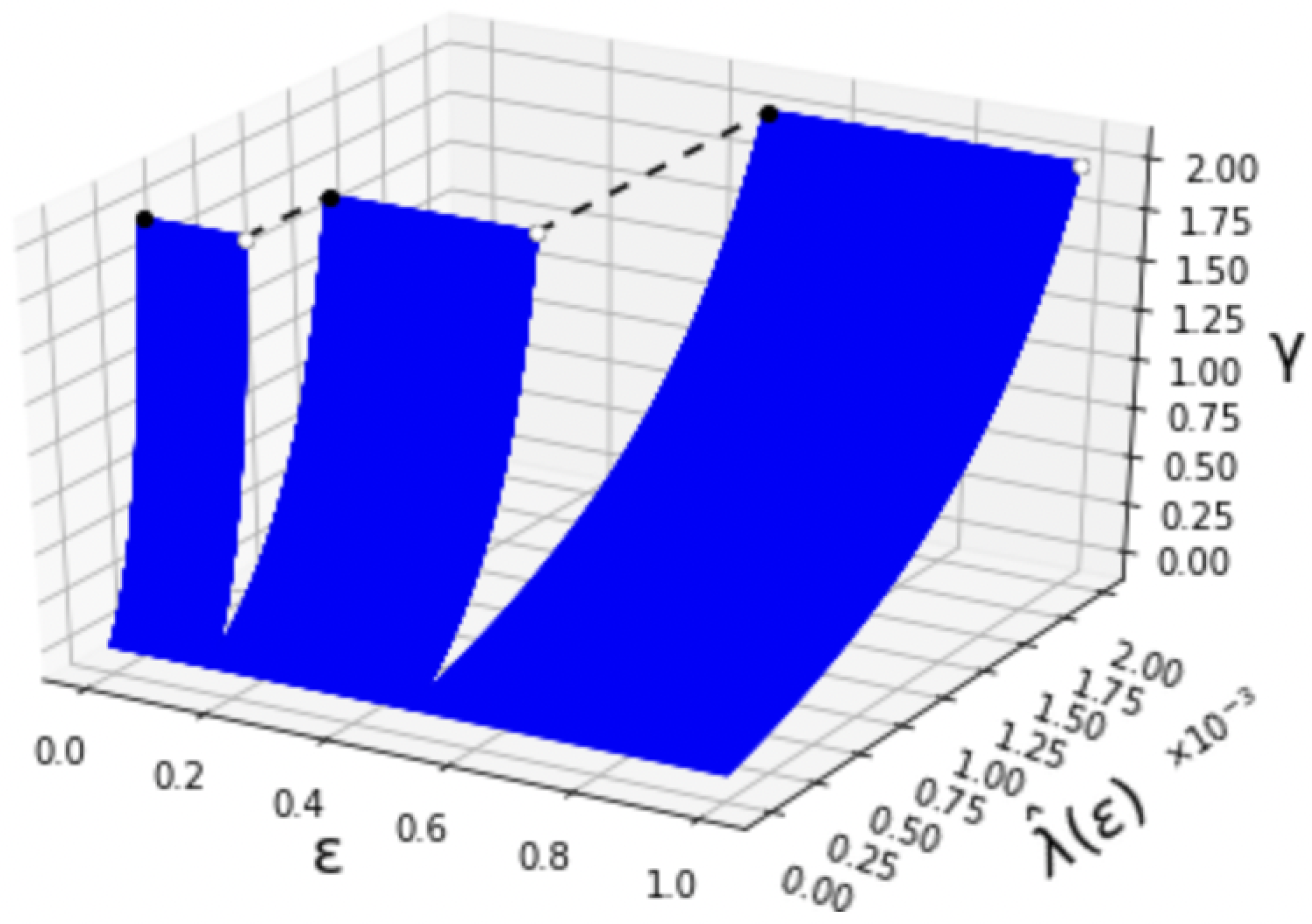
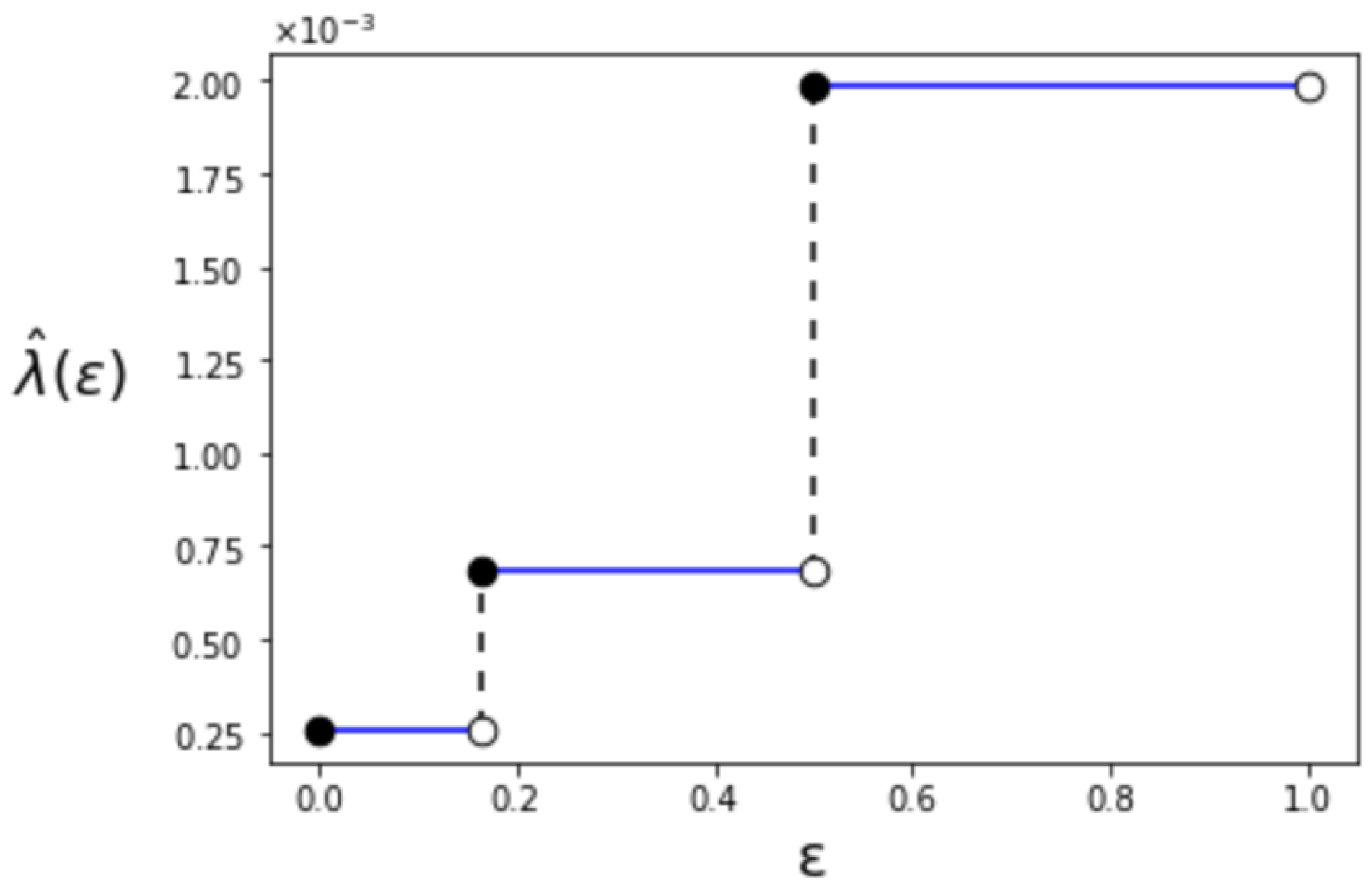
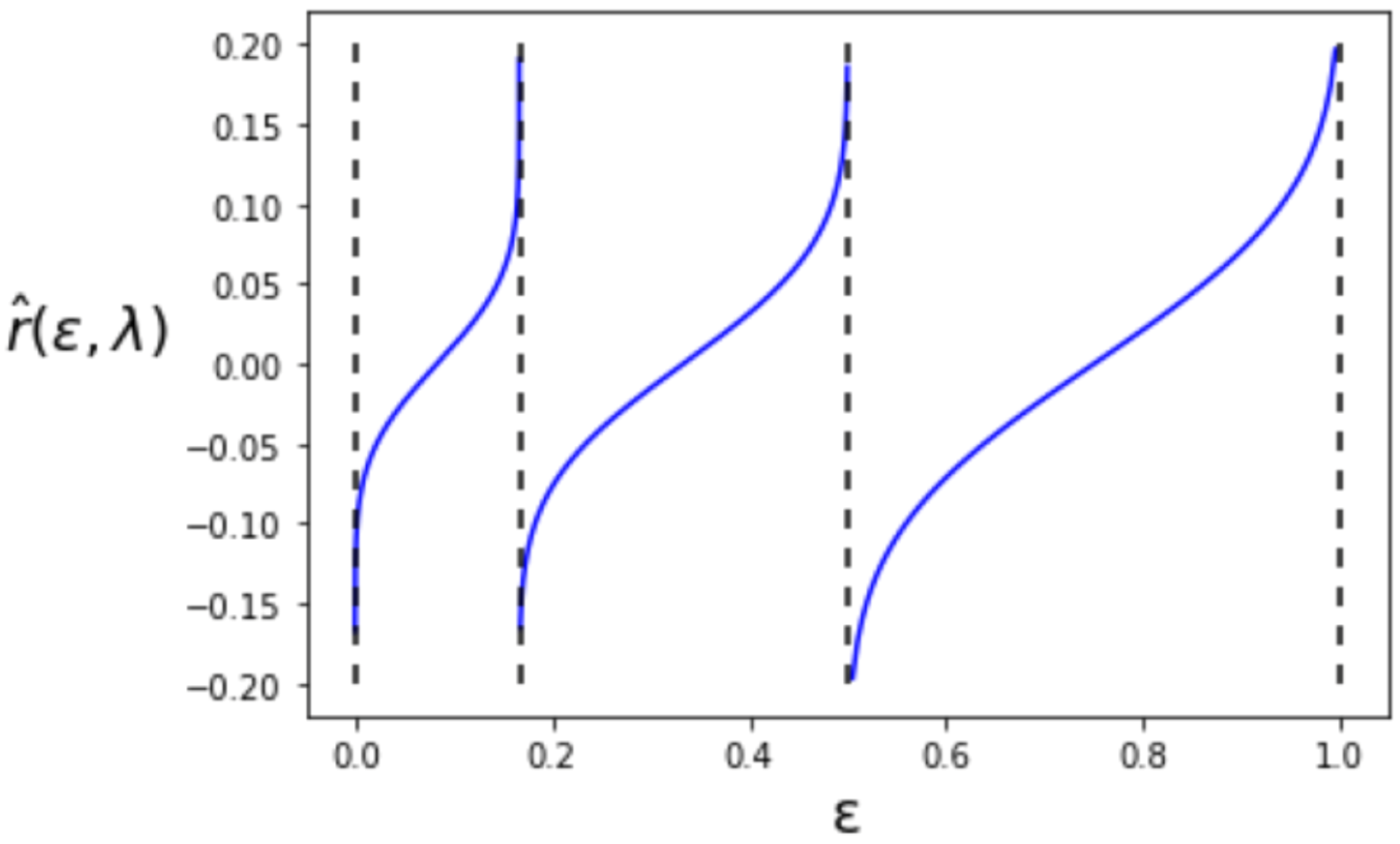
5.1. First-Order Maximum Error Exponent
5.2. Second-Order Maximum Error Exponent
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
Appendix C
Appendix D
Appendix E
Appendix E.1. Achievability Part
Appendix E.2. Converse Part
Appendix F
References
- Merhav, N.; Ziv, J. A Bayesian approach for classification of Markov sources. IEEE Trans. Inf. Theory 1991, 37, 1067–1071. [Google Scholar] [CrossRef]
- Saito, S.; Matsushima, T. Evaluation of error probability of classification based on the analysis of the Bayes code. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 21–26. [Google Scholar]
- Gutman, M. Asymptotically optimal classification for multiple tests with empirically observed statistics. IEEE Trans. Inf. Theory 1989, 35, 401–408. [Google Scholar] [CrossRef]
- Hsu, H.-W.; Wang, I.-H. On binary statistical classification from mismatched empirically observed statistics. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 2538–3533. [Google Scholar]
- Zhou, L.; Tan, V.Y.F.; Motani, M. Second-order asymptotically optimal statistical classification. Inf. Inference J. IMA 2020, 9, 81–111. [Google Scholar]
- Han, T.S.; Nomura, R. First- and second-order hypothesis testing for mixed memoryless sources. Entropy 2018, 20, 174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Polyanskiy, Y.; Poor, H.V.; Verdú, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307–2359. [Google Scholar] [CrossRef]
- Yagi, H.; Han, T.S.; Nomura, R. First- and second-order coding theorems for mixed memoryless channels with general mixture. IEEE Trans. Inf. Theory 2016, 62, 4395–4412. [Google Scholar] [CrossRef]
- Ziv, J. On classification with empirically observed statistics and universal data compression. IEEE Trans. Inf. Theory 1988, 34, 278–286. [Google Scholar] [CrossRef]
- Kelly, B.G.; Wagner, A.B.; Tularak, T.; Viswanath, P. Classification of homogeneous data with large alphabets. IEEE Trans. Inf. Theory 2013, 59, 782–795. [Google Scholar] [CrossRef] [Green Version]
- Unnikrishnan, J.; Huang, D. Weak convergence analysis of asymptotically optimal hypothesis tests. IEEE Trans. Inf. Theory 2016, 62, 4285–4299. [Google Scholar] [CrossRef]
- He, H.; Zhou, L.; Tan, V.Y.F. Distributed detection with empirically observed statistics. IEEE Trans. Inf. Theory 2020, 66, 4349–4367. [Google Scholar] [CrossRef]
- Saito, S.; Matsushima, T. Evaluation of error probability of classification based on the analysis of the Bayes code: Extension and example. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, VIC, Australia, 12–20 July 2021; pp. 1445–1450. [Google Scholar]
- Csiszár, I. The method of types. IEEE Trans. Inf. Theory 1998, 44, 2505–2523. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. On a variational definition for the Jensen-Shannon symmetrization of distances based on the information radius. Entropy 2021, 23, 464. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuramata, H.; Yagi, H. Analysis on Optimal Error Exponents of Binary Classification for Source with Multiple Subclasses. Entropy 2022, 24, 635. https://doi.org/10.3390/e24050635
Kuramata H, Yagi H. Analysis on Optimal Error Exponents of Binary Classification for Source with Multiple Subclasses. Entropy. 2022; 24(5):635. https://doi.org/10.3390/e24050635
Chicago/Turabian StyleKuramata, Hiroto, and Hideki Yagi. 2022. "Analysis on Optimal Error Exponents of Binary Classification for Source with Multiple Subclasses" Entropy 24, no. 5: 635. https://doi.org/10.3390/e24050635
APA StyleKuramata, H., & Yagi, H. (2022). Analysis on Optimal Error Exponents of Binary Classification for Source with Multiple Subclasses. Entropy, 24(5), 635. https://doi.org/10.3390/e24050635