
Robust Spike-Based Continual Meta-Learning Improved by Restricted Minimum Error Entropy Criterion




Abstract
:1. Introduction
2. Materials and Methods
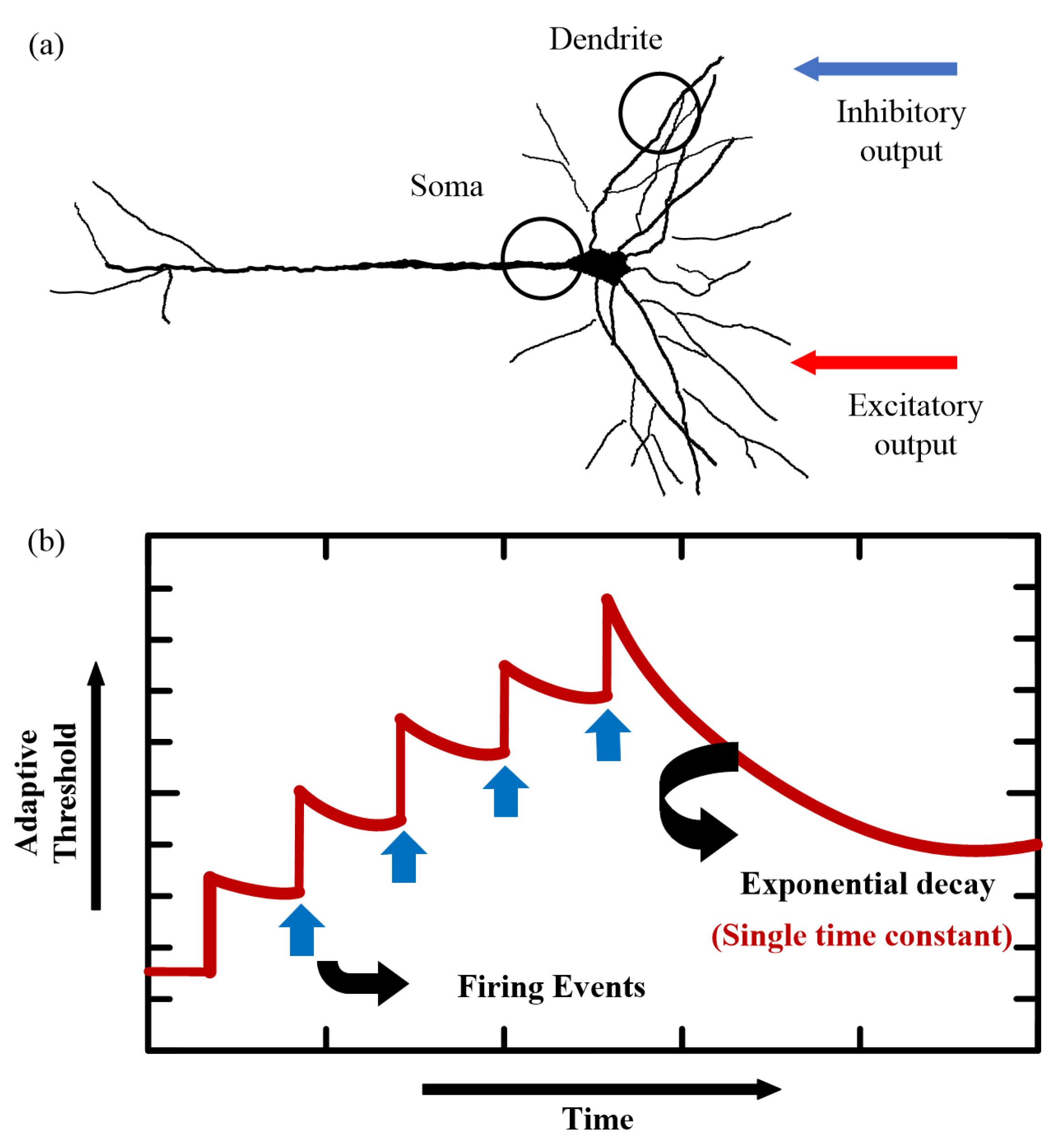
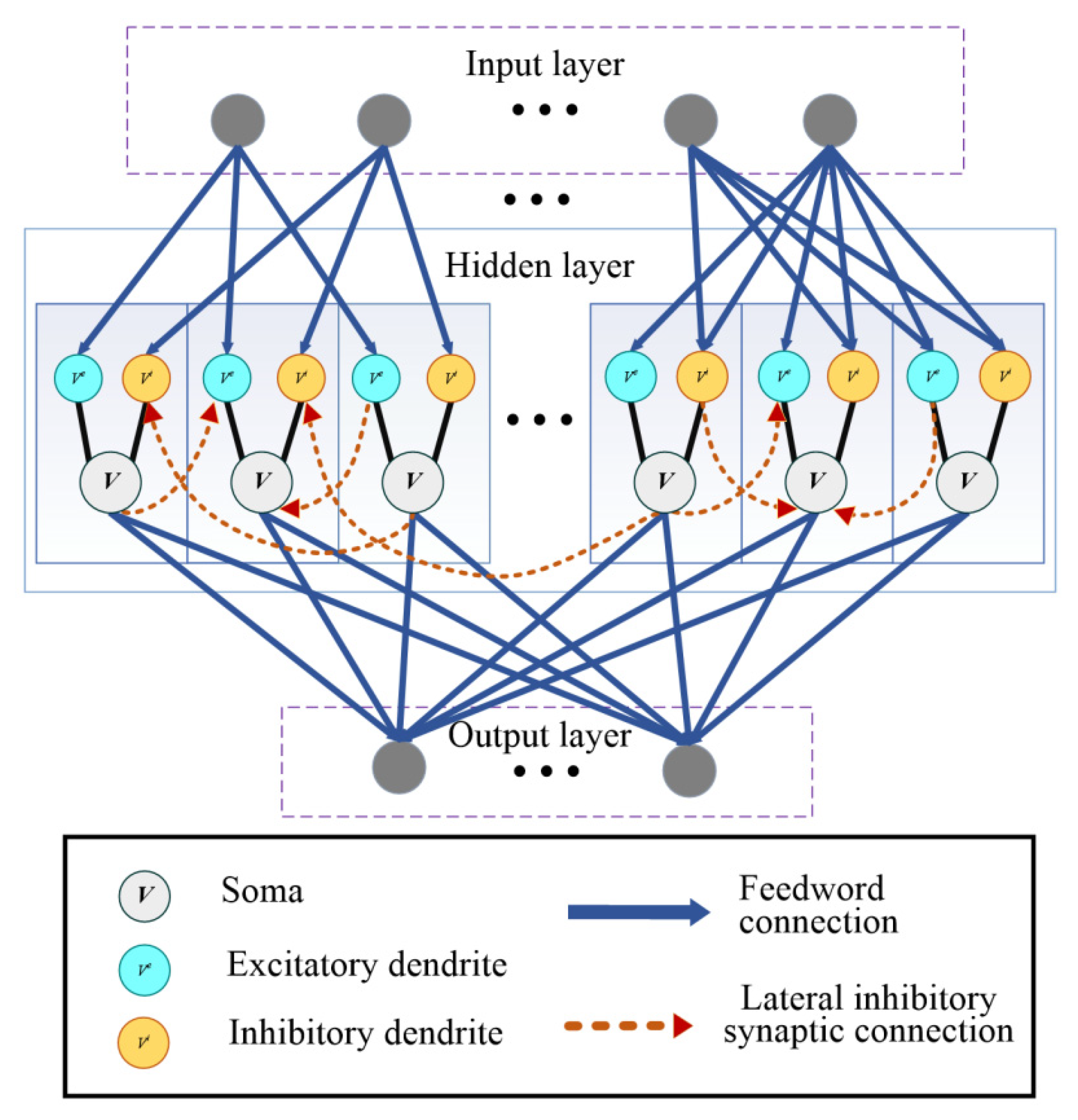
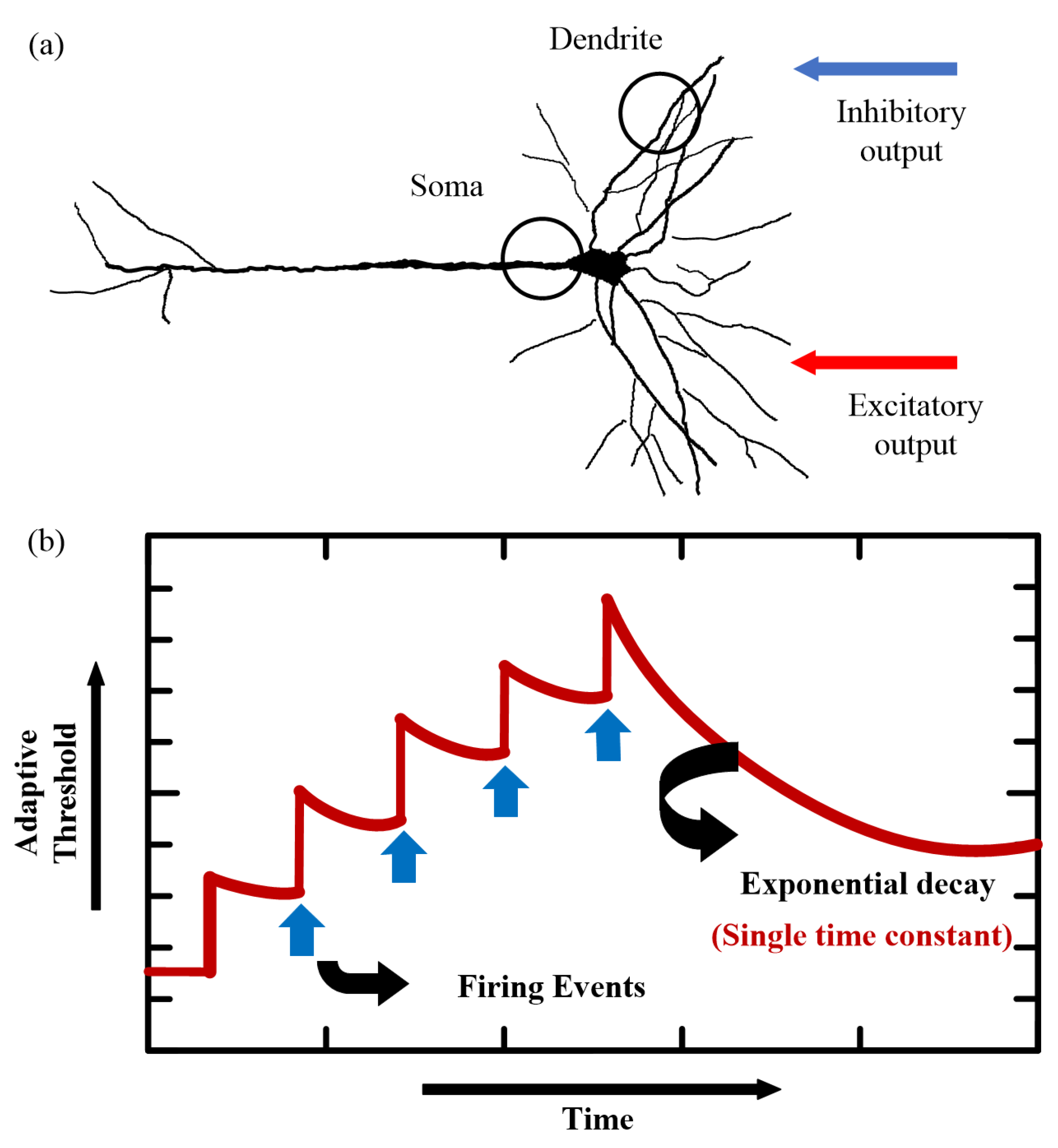
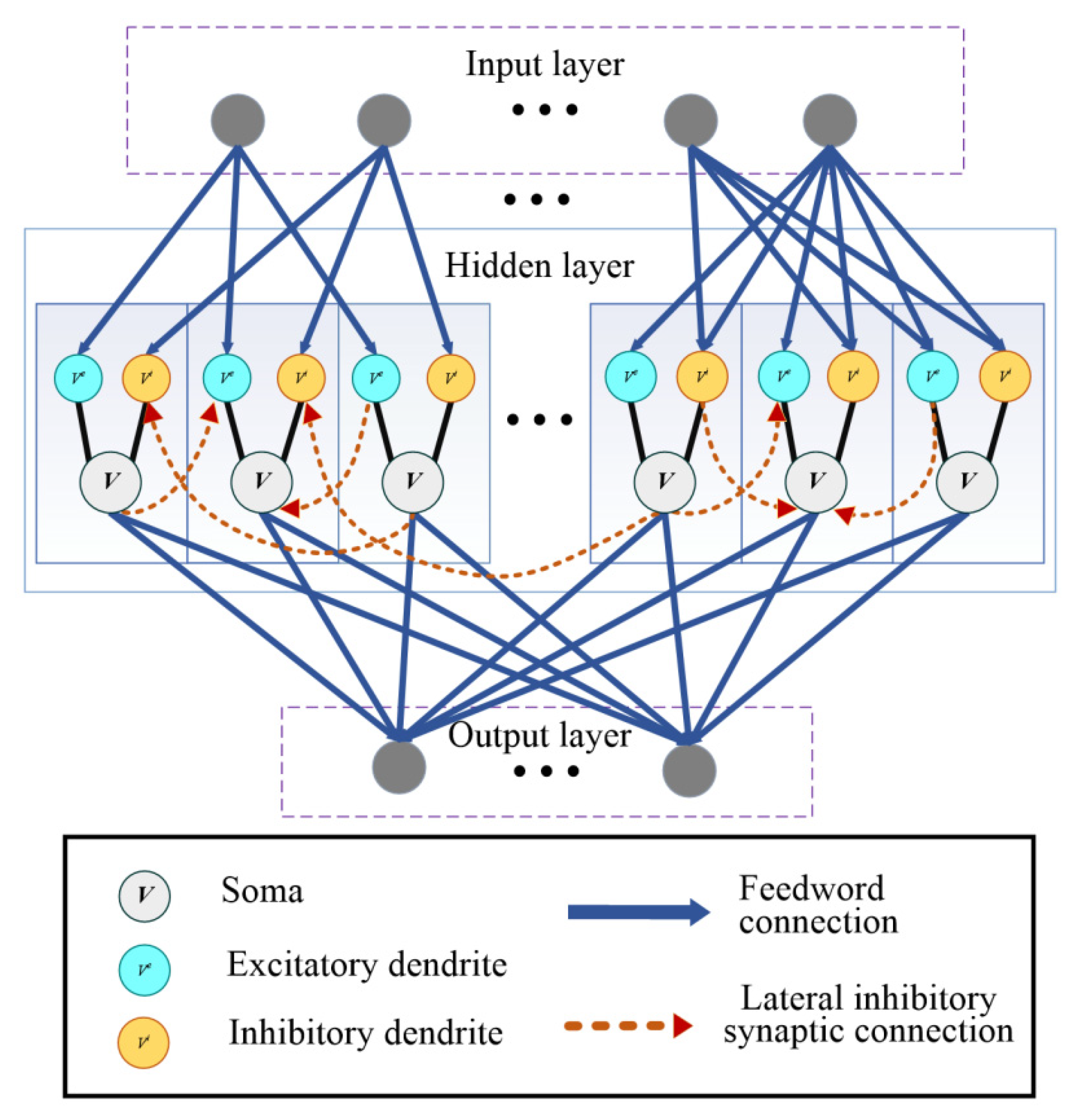
2.1. SNN Model
2.2. BPTT Training Algorithm
2.3. Minimum Error Entropy Criterion (MEEC)
2.4. Restricted MEEC
3. Results
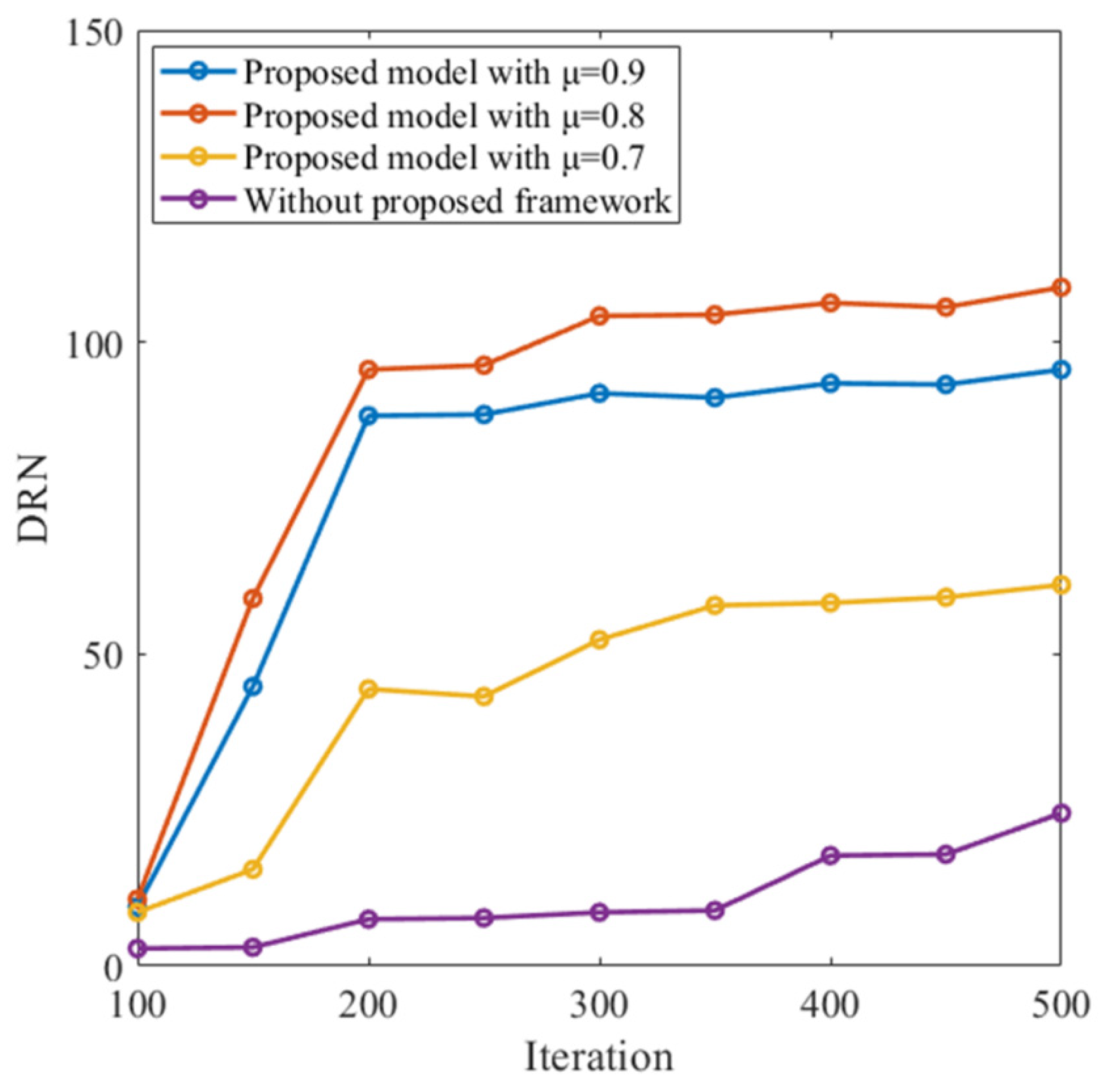
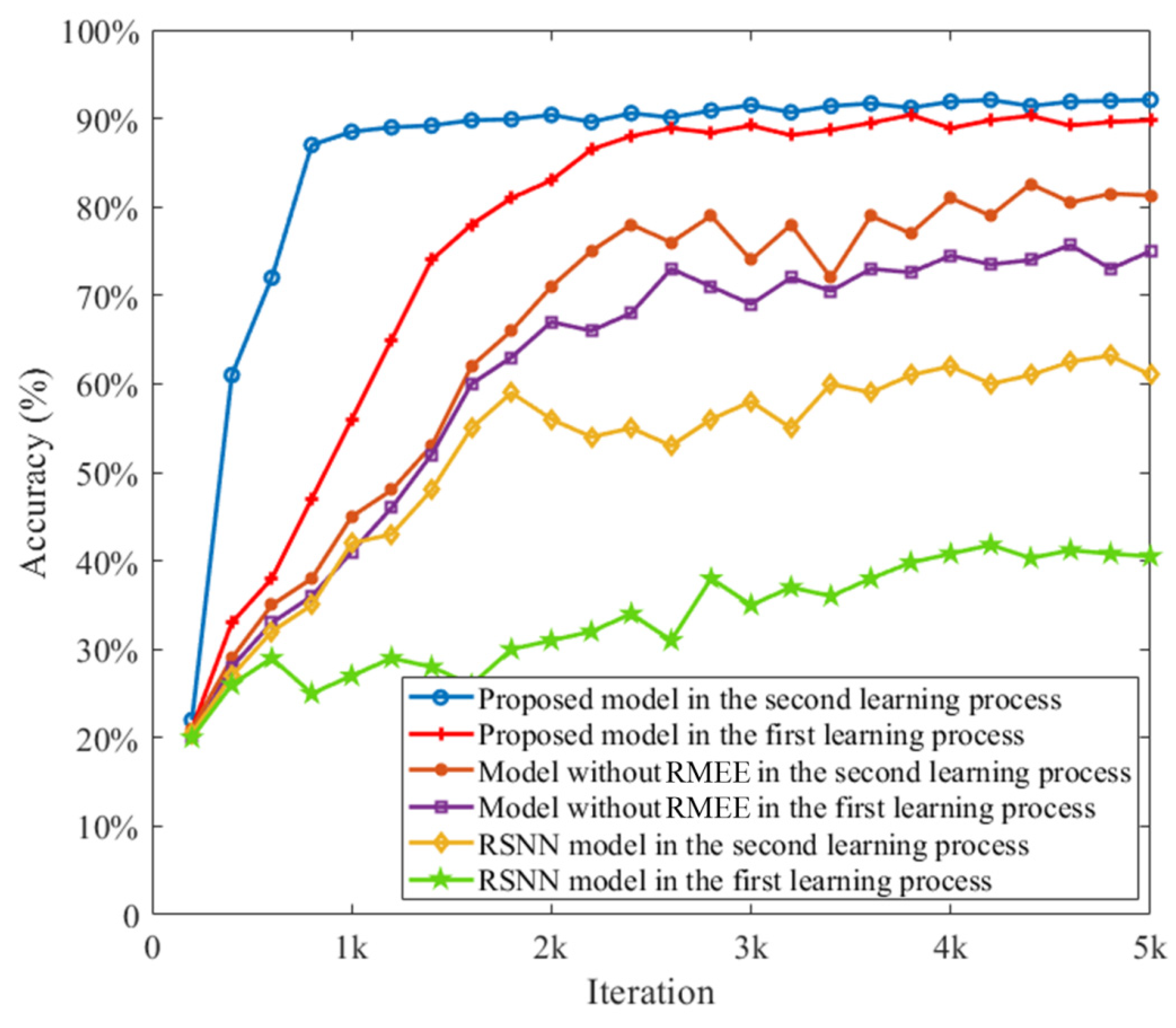
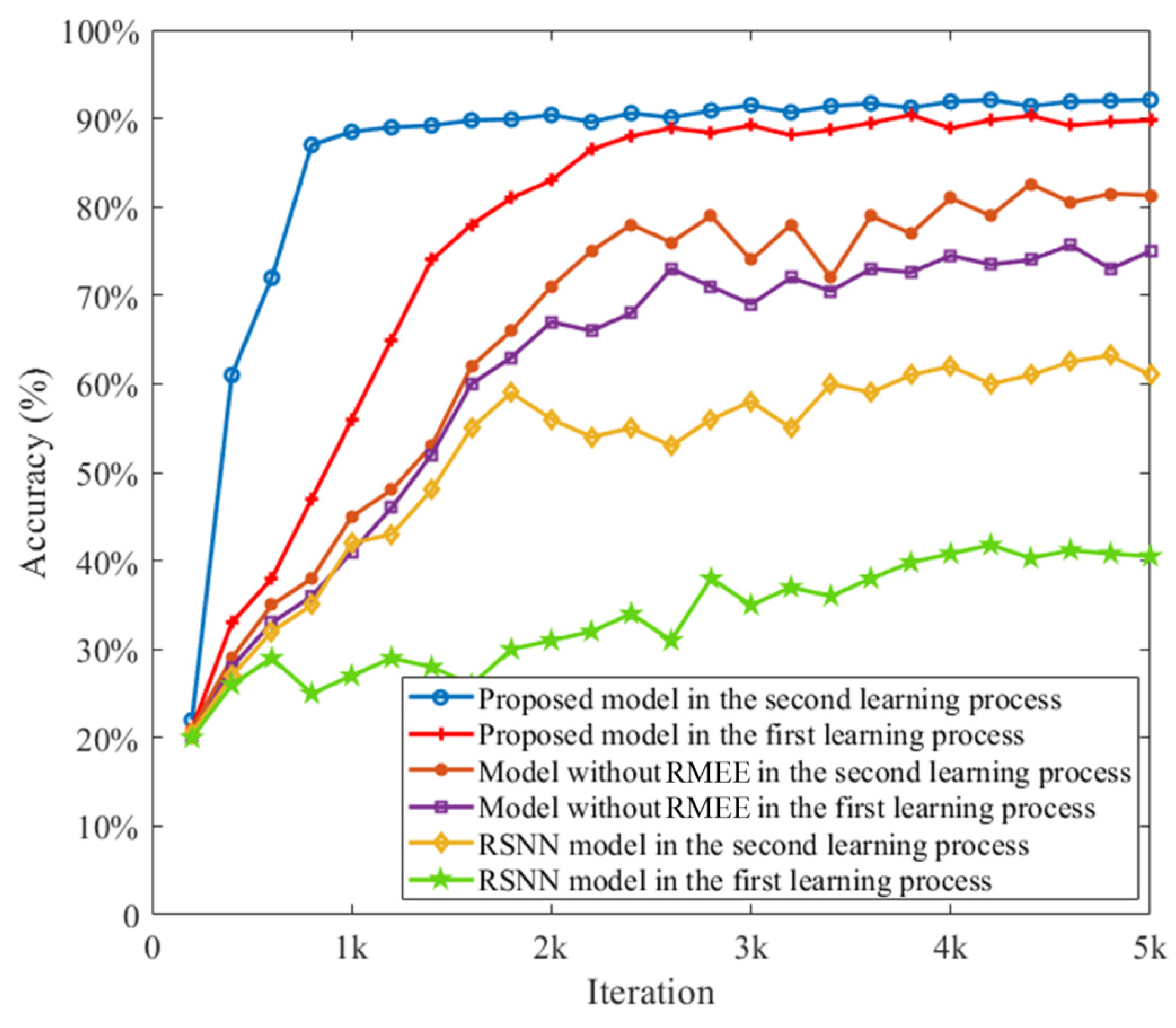
3.1. Proposed Network with RMEE Criterion
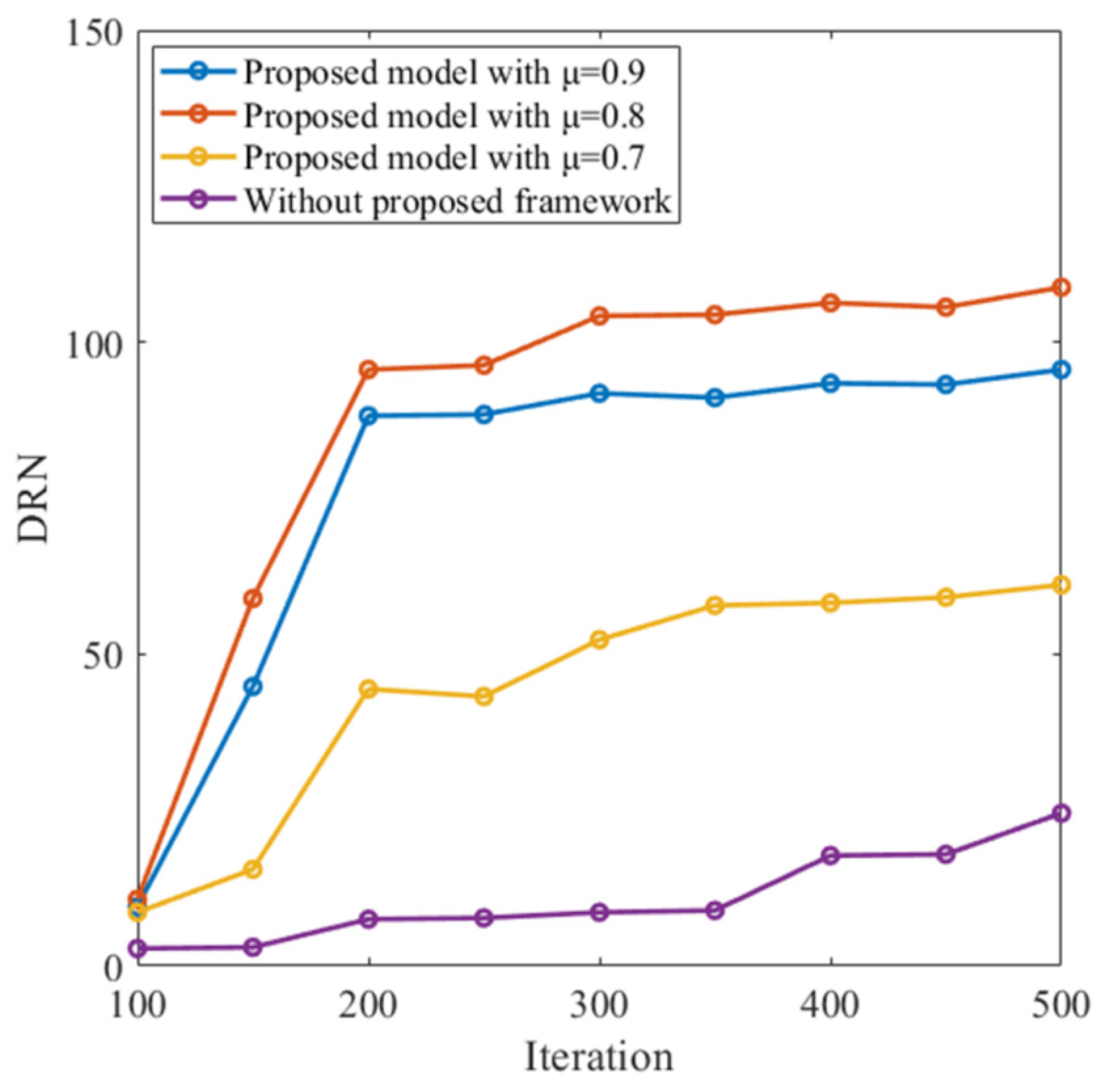
3.2. Autonomous Navigation
| Algorithm 1 Training process in the reward learning process |
| Input: number of full episodes , timesteps , fixed parameters , target firing rate , regularization hyper-parameters , , , bandwidth , predicted value function and sum of future rewards Output: total loss .
|
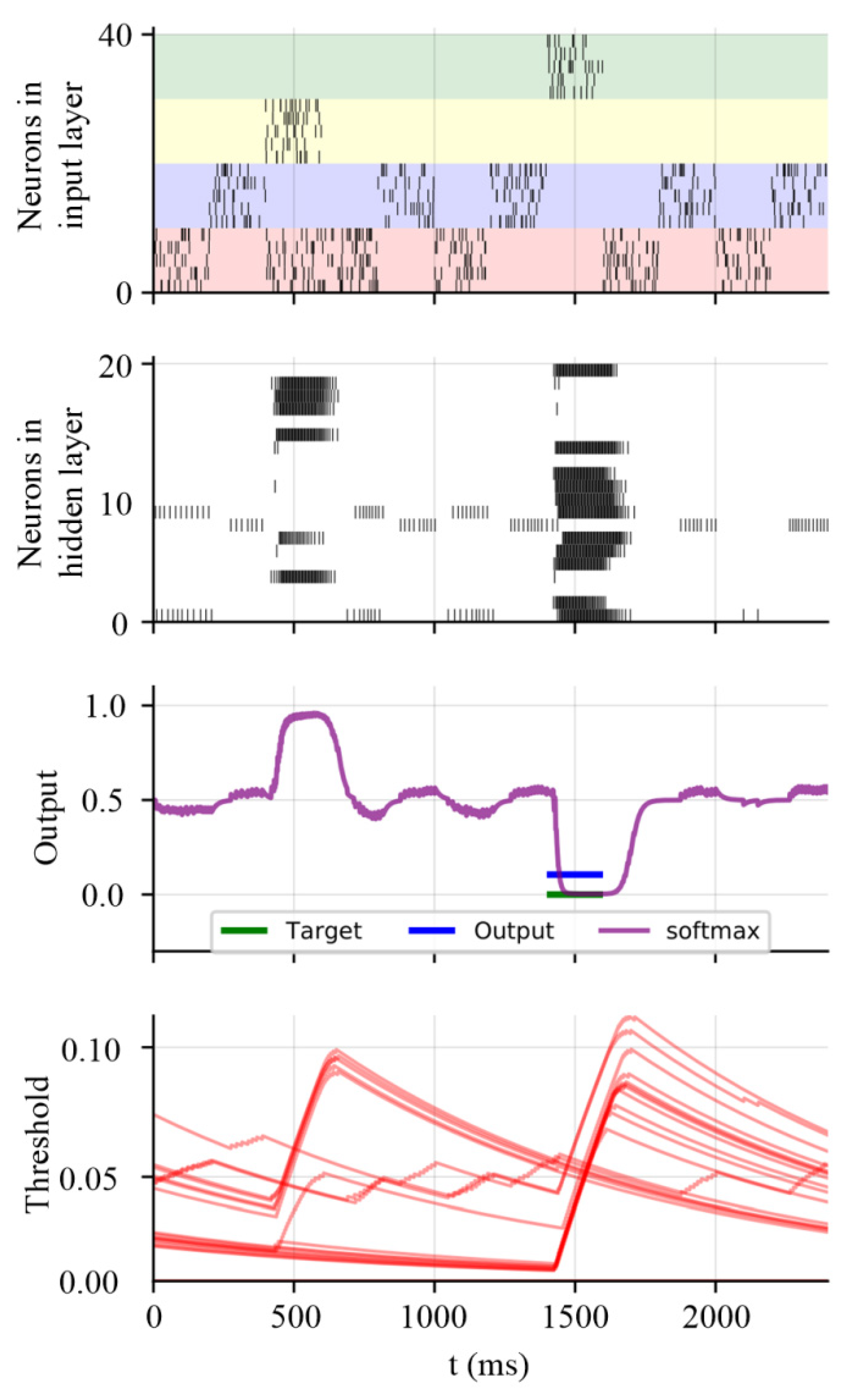
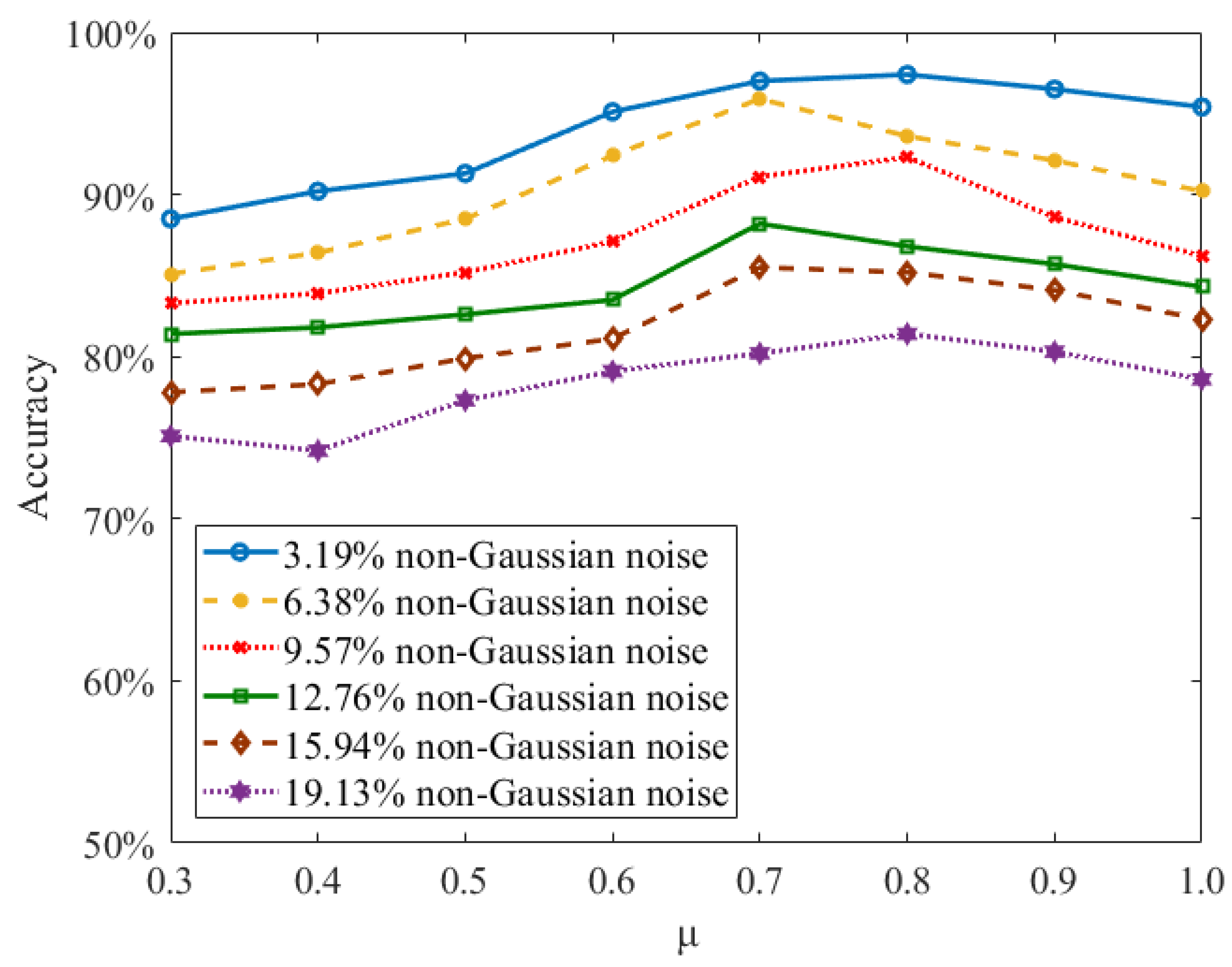
3.3. Working Memory Performance on Store–Recall Task with Non-Gaussian Noise
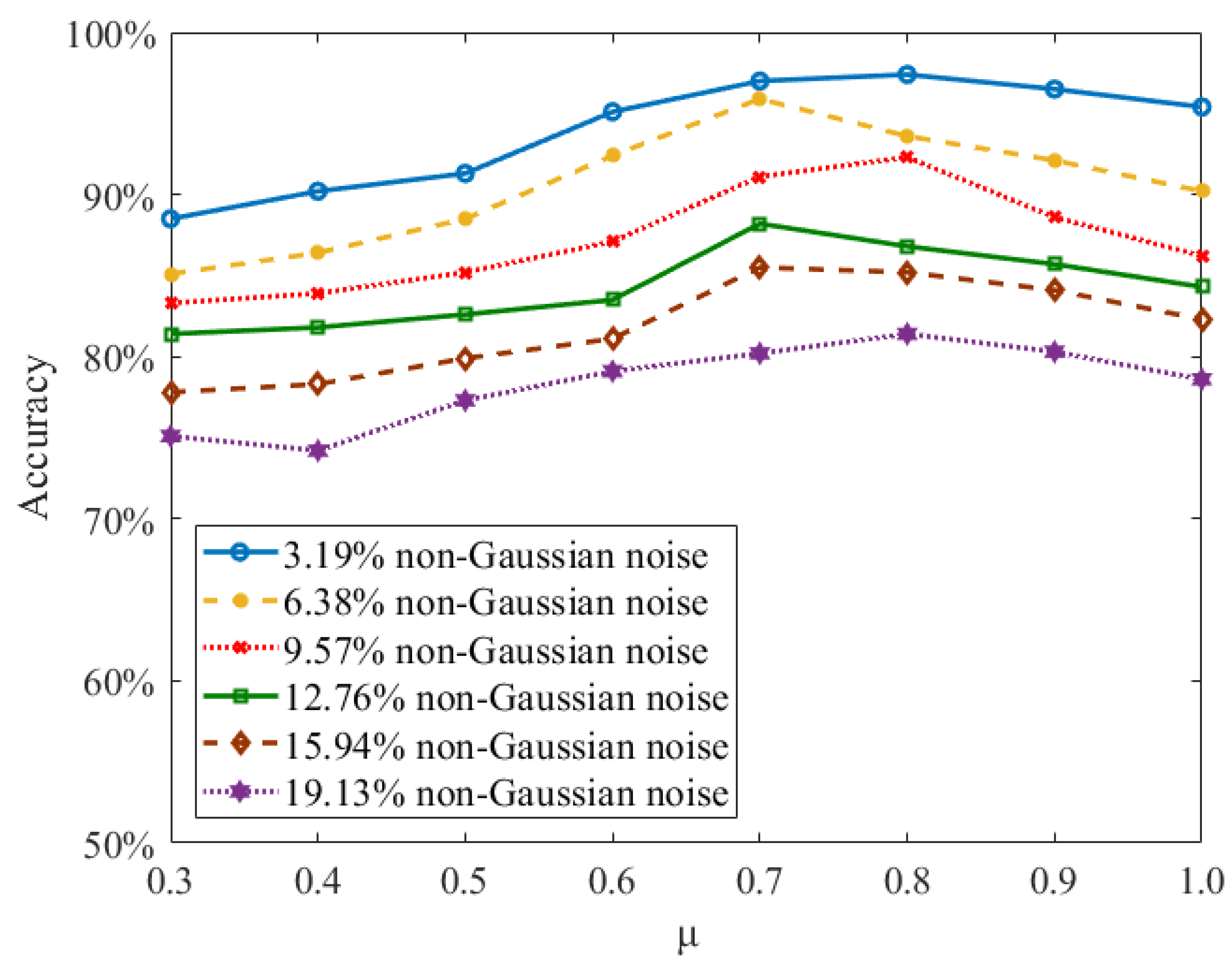
3.4. Meta-Learning Performance on Sequential MNIST Data Set with Non-Gaussian Noise
3.5. Effects of Loss Parameters on Learning Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 89–94. [Google Scholar] [CrossRef]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Zhou, Y.; Mahdavi, M.; Li, Z.; Socher, R.; Xiong, C. Online structured meta-learning. Adv. Neural Inf. Process. Syst. 2020, 33, 6779–6790. [Google Scholar]
- Javed, K.; White, M. Meta-learning representations for continual learning. Adv. Neural Inf. Process. Syst. 2019, 32, 172. [Google Scholar]
- Serrà, J.; Surís, D.; Miron, M.; Karatzoglou, A. Overcoming catastrophic forgetting with hard attention to the task. In Proceedings of the International Conference on Machine Learning (PMLR 80), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 4548–4557. [Google Scholar]
- Zeng, G.; Chen, Y.; Cui, B.; Yu, S. Continual learning of context-dependent processing in neural networks. Nat. Mach. Intell. 2019, 1, 364–372. [Google Scholar] [CrossRef]
- van de Ven, G.M.; Siegelmann, H.T.; Tolias, A.S. Brain-inspired replay for continual learning with artificial neural networks. Nat. Commun. 2020, 11, 4069. [Google Scholar] [CrossRef]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.; Panda, P.; Srinivasan, G.; Roy, K. Training deep spiking convolutional neural networks with stdp-based unsupervised pre-training followed by supervised fine-tuning. Front. Neurosci. 2018, 12, 435. [Google Scholar] [CrossRef]
- Xia, Q.; Yang, J.J. Memristive crossbar arrays for brain-inspired computing. Nat. Mat. 2019, 18, 309–323. [Google Scholar] [CrossRef]
- Pei, J.; Deng, L.; Song, S.; Zhao, M.; Zhang, Y.; Wu, S.; Wang, G.; Zou, Z.; Wu, Z.; He, W.; et al. Towards artificial general intelligence with hybrid Tianjic chip architecture. Nature 2019, 572, 106–111. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Yang, S.; Wang, J.; Hao, X.; Li, H.; Wei, X.; Deng, B.; Loparo, K.A. BiCoSS: Toward large-scale cognition brain with multigranular neuromorphic architecture. IEEE Trans. Neural Netw. Learn. Syst. 2021, 11, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Wang, J.; Zhang, N.; Deng, B.; Pang, Y.; Azghadi, M.R. Cerebellumorphic: Large-scale neuromorphic model and architecture for supervised motor learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 23, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Wang, J.; Deng, B.; Liu, C.; Li, H.; Fietkiewicz, C.; Loparo, K.A. Real-time neuromorphic system for large-scale conductance-based spiking neural networks. IEEE Trans. Cybern. 2019, 49, 2490–2503. [Google Scholar] [CrossRef]
- Bellec, G.; Salaj, D.; Subramoney, A.; Legenstein, R.; Maass, W. Long short-term memory and learning-to-learn in networks of spiking neurons. Adv. Neural Inf. Process. Syst. 2018, 31, 247. [Google Scholar]
- Li, Y.; Zhou, J.; Tian, J.; Zheng, X.; Tang, Y.Y. Weighted error entropy-based information theoretic learning for robust subspace representation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 19, 1–15. [Google Scholar] [CrossRef]
- Chen, J.; Song, L.; Wainwright, M.; Jordan, M. Learning to explain: An information-theoretic perspective on model interpretation. In Proceedings of the 35th International Conference on Machine Learning (PMLR 80), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 883–892. [Google Scholar]
- Xu, Y.; Cao, P.; Kong, Y.; Wang, Y. DMI: A novel information-theoretic loss function for training deep nets robust to label noise. Adv. Neural Inf. Process. Syst. 2019, 32, 76. [Google Scholar]
- Chen, B.; Xing, L.; Zhao, H.; Du, S.; Principe, J.C. Effects of outliers on the maximum correntropy estimation: A robustness analysis. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 4007–4012. [Google Scholar] [CrossRef]
- Chen, B.; Li, Y.; Dong, J.; Lu, N.; Qin, J. Common spatial patterns based on the quantized minimum error entropy criterion. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 4557–4568. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Xu, B.; Zhao, H.; Principe, J.C. Insights into the robustness of minimum error entropy estimation. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 731–737. [Google Scholar] [CrossRef]
- Chen, H.-Y.; Liang, J.-H.; Chang, S.-C.; Pan, J.-Y.; Chen, Y.-T.; Wei, W.; Juan, D.-C. Improving adversarial robustness via guided complement entropy. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4880–4888. [Google Scholar]
- Rachdi, M.; Waku, J.; Hazgui, H.; Demongeot, J. Entropy as a robustness marker in genetic regulatory networks. Entropy 2020, 22, 260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borin, J.A.M.S.; Humeau-Heurtier, A.; Virgílio Silva, L.E.; Murta, L.O. Multiscale entropy analysis of short signals: The robustness of fuzzy entropy-based variants compared to full-length long signals. Entropy 2021, 23, 1620. [Google Scholar] [CrossRef] [PubMed]
- Grienberger, C.; Milstein, A.D.; Bittner, K.C.; Romani, S.; Magee, J.C. Inhibitory suppression of heterogeneously tuned excitation enhances spatial coding in CA1 place cells. Nat. Neurosci. 2017, 20, 417–426. [Google Scholar] [CrossRef]
- Muñoz, W.; Tremblay, R.; Levenstein, D.; Rudy, B. Layer-specific modulation of neocortical dendritic inhibition during active wakefulness. Science 2017, 355, 954–959. [Google Scholar] [CrossRef] [Green Version]
- Poleg-Polsky, A.; Ding, H.; Diamond, J.S. Functional compartmentalization within starburst amacrine cell dendrites in the retina. Cell Rep. 2018, 22, 2898–2908. [Google Scholar] [CrossRef] [Green Version]
- Ranganathan, G.N.; Apostolides, P.F.; Harnett, M.T.; Xu, N.L.; Druckmann, S.; Magee, J.C. Active dendritic integration and mixed neocortical network representations during an adaptive sensing behavior. Nat. Neurosci. 2018, 21, 1583–1590. [Google Scholar] [CrossRef]
- Bellec, G.; Kappel, D.; Maass, W.; Legenstein, R. Deep rewiring: Training very sparse deep networks. arXiv 2017, arXiv:1711.05136. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, Y.; Chen, B.; Yoshimura, N.; Koike, Y. Restricted minimum error entropy criterion for robust classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 2, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Vasilaki, E.; Frémaux, N.; Urbanczik, R.; Senn, W.; Gerstner, W. Spike-based reinforcement learning in continuous state and action space: When policy gradient methods fail. PLoS Comput. Biol. 2009, 5, e1000586. [Google Scholar] [CrossRef]
- Wolff, M.J.; Jochim, J.; Akyürek, E.G.; Stokes, M.G. Dynamic hidden states underlying working-memory-guided behavior. Nat. Neurosci. 2017, 20, 864–871. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, S.; Gao, T.; Wang, J.; Deng, B.; Lansdell, B.; Linares-Barranco, B. Efficient spike-driven learning with dendritic event-based processing. Front. Neurosci. 2021, 15, 601109. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Zhu, P.; Principe, J.C. Survival information potential: A new criterion for adaptive system training. IEEE Trans. Signal Process. 2012, 60, 1184–1194. [Google Scholar] [CrossRef]
- Jiang, R.; Zhang, J.; Yan, R.; Tang, H. Few-shot learning in spiking neural networks by multi-timescale optimization. Neural Comput. 2021, 33, 2439–2472. [Google Scholar] [CrossRef]
- DeBole, M.V.; Appuswamy, R.; Carlson, P.J.; Cassidy, A.S.; Datta, P.; Esser, S.K.; Garreau, G.J.; Holland, K.L.; Lekuch, S.; Mastro, M.; et al. Truenorth: Accelerating from zero to 64 million neurons in 10 years. Computer 2019, 52, 20–29. [Google Scholar] [CrossRef]
- Furber, S.B.; Galluppi, F.; Temple, S.; Plana, L.A. The SpiNNaker project. Proc. IEEE 2014, 102, 652–665. [Google Scholar] [CrossRef]
- Krestinskaya, O.; James, A.P.; Chua, L.O. Neuromemristive circuits for edge computing: A review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4–23. [Google Scholar] [CrossRef] [Green Version]
- Yoo, J.; Shoaran, M. Neural interface systems with on-device computing: Machine learning and neuromorphic architectures. Curr. Opin. Biotechnol. 2021, 72, 95–101. [Google Scholar] [CrossRef]
- Cho, S.W.; Kwon, S.M.; Kim, Y.; Park, S.K. Recent progress in transistor-based optoelectronic synapses: From neuromorphic computing to artificial sensory system. Adv. Intell. Syst. 2021, 3, 2000162. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Rm | 1 Ω | Ri, Re | 1 Ω |
| τm | 20 ms | θi, θe | 0 mV |
| κ, κi, κe | 5 ms | κrec, κirec, κerec | 5 ms |
| α | 1.8 | τ0 | 0.01 |
| τa | 700 ms | gi, ge | 1 nS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Tan, J.; Chen, B. Robust Spike-Based Continual Meta-Learning Improved by Restricted Minimum Error Entropy Criterion. Entropy 2022, 24, 455. https://doi.org/10.3390/e24040455
Yang S, Tan J, Chen B. Robust Spike-Based Continual Meta-Learning Improved by Restricted Minimum Error Entropy Criterion. Entropy. 2022; 24(4):455. https://doi.org/10.3390/e24040455
Chicago/Turabian StyleYang, Shuangming, Jiangtong Tan, and Badong Chen. 2022. "Robust Spike-Based Continual Meta-Learning Improved by Restricted Minimum Error Entropy Criterion" Entropy 24, no. 4: 455. https://doi.org/10.3390/e24040455
APA StyleYang, S., Tan, J., & Chen, B. (2022). Robust Spike-Based Continual Meta-Learning Improved by Restricted Minimum Error Entropy Criterion. Entropy, 24(4), 455. https://doi.org/10.3390/e24040455