
Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment




Abstract
:1. Introduction
- From the experimental point of view, the inherent defects of the traditional PPO algorithm are analyzed, and the optimum space is obtained.
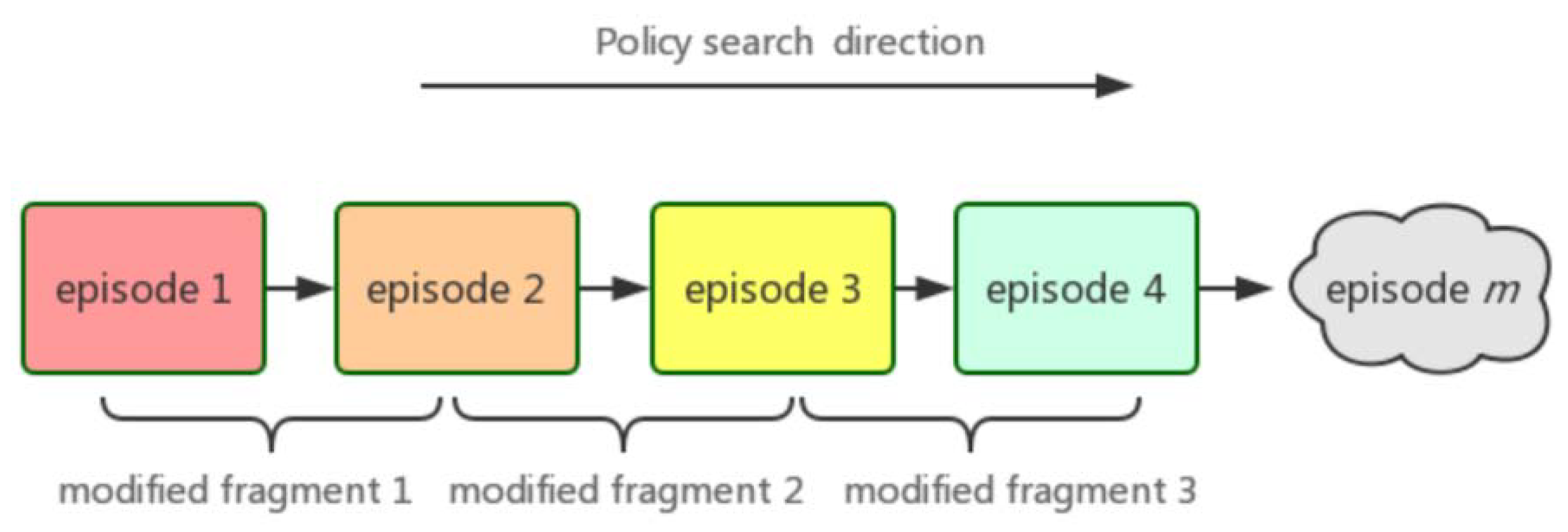
- The mathematical model of modified fragments is established to describe the process of reinforcement learning, and the change of probability distribution is used to explain the stationarity analysis of reinforcement learning.
- Through introducing the concept of entropy in information theory, the reward function H(R) is used to describe the policy distribution function, and H(R) is quantified by kernel density estimation. The change of H(R) distribution is evaluated and tested by Kullback-Leibler divergence (as a measure of relative entropy).
2. Related Work
2.1. Policy Gradient Algorithm
2.2. Proximal Policy Optimization Algorithm
| Algorithm 1: PPO |
| Input: Number of iterations episode Output: Rewards, losses initialization for iteration = 1, 2, 3, …, M do while actor = 1, 2, 3, …, N do run policy for T timesteps. compute advantage estimates ; end optimize surrogate ; ; end |
2.3. Entropy in Information Theory
3. Methods
3.1. Policy Distribution Theory and Relative Entropy
3.2. Fitting of Reward Function
3.3. Difference Measurement of Reward Function by Relative Entropy
| Algorithm 2: PDE |
| Input: Policy distribution function Output: Policy change outcomes initialization: manual partition of Modified Fragments , setting threshold D0. for iteration = 1, 2, 3, …, n do update according to Equation (7). update according to Equation (7). update according to Equation (10). if then Output information: The distribution of policies has changed. else Output information: The distribution of policies has not changed. end end |
3.4. Correct Proximal Policy Optimization Algorithm
| Algorithm 3: CPPO |
| initialization: Calculation of by PPO algorithm, state; classification of ; for j = 1, 2, 3, …, n do execute algorithm 1 and return the value of state; if state==true then //Updating β according to Equation (14); else ; end end |
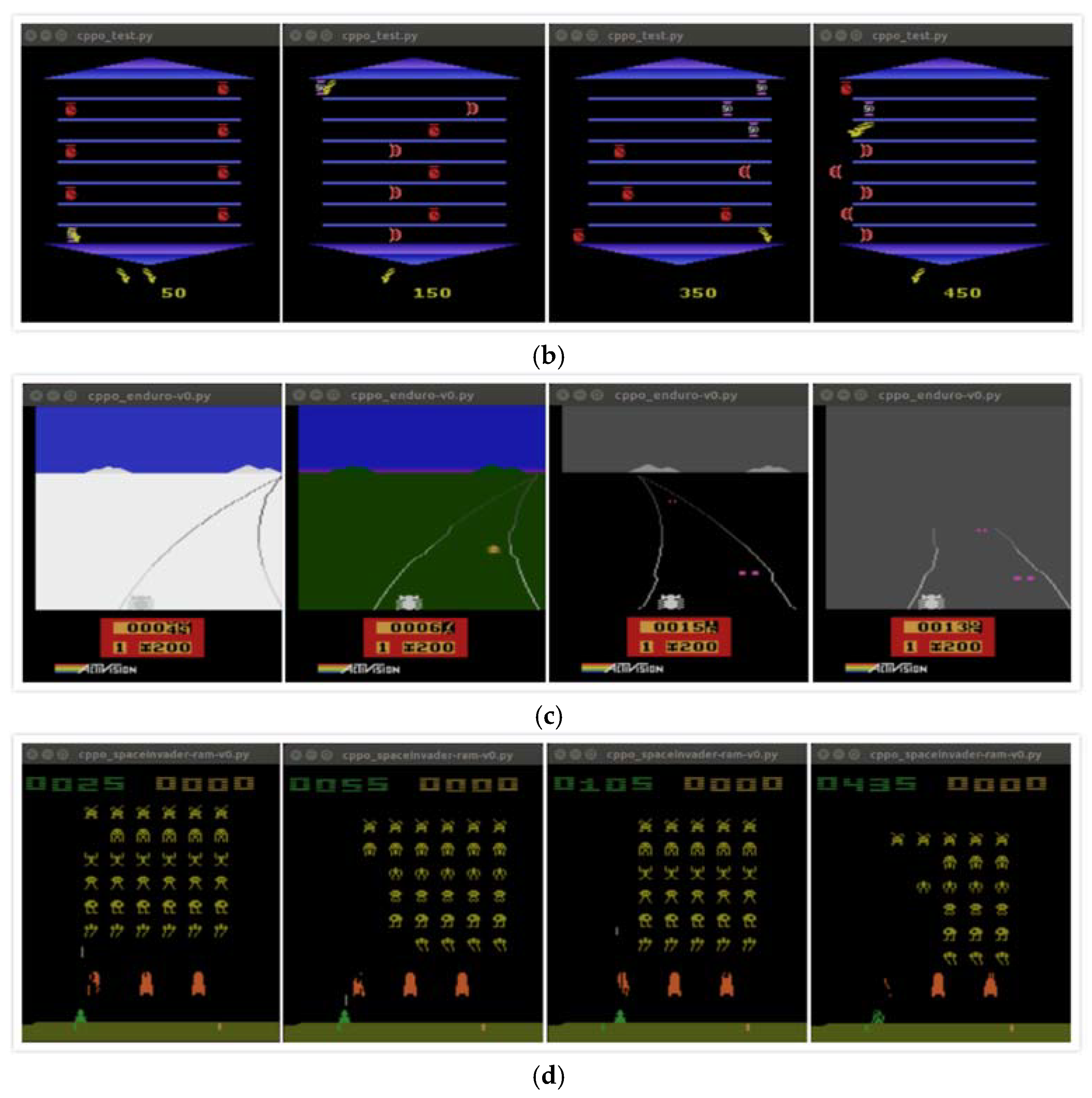
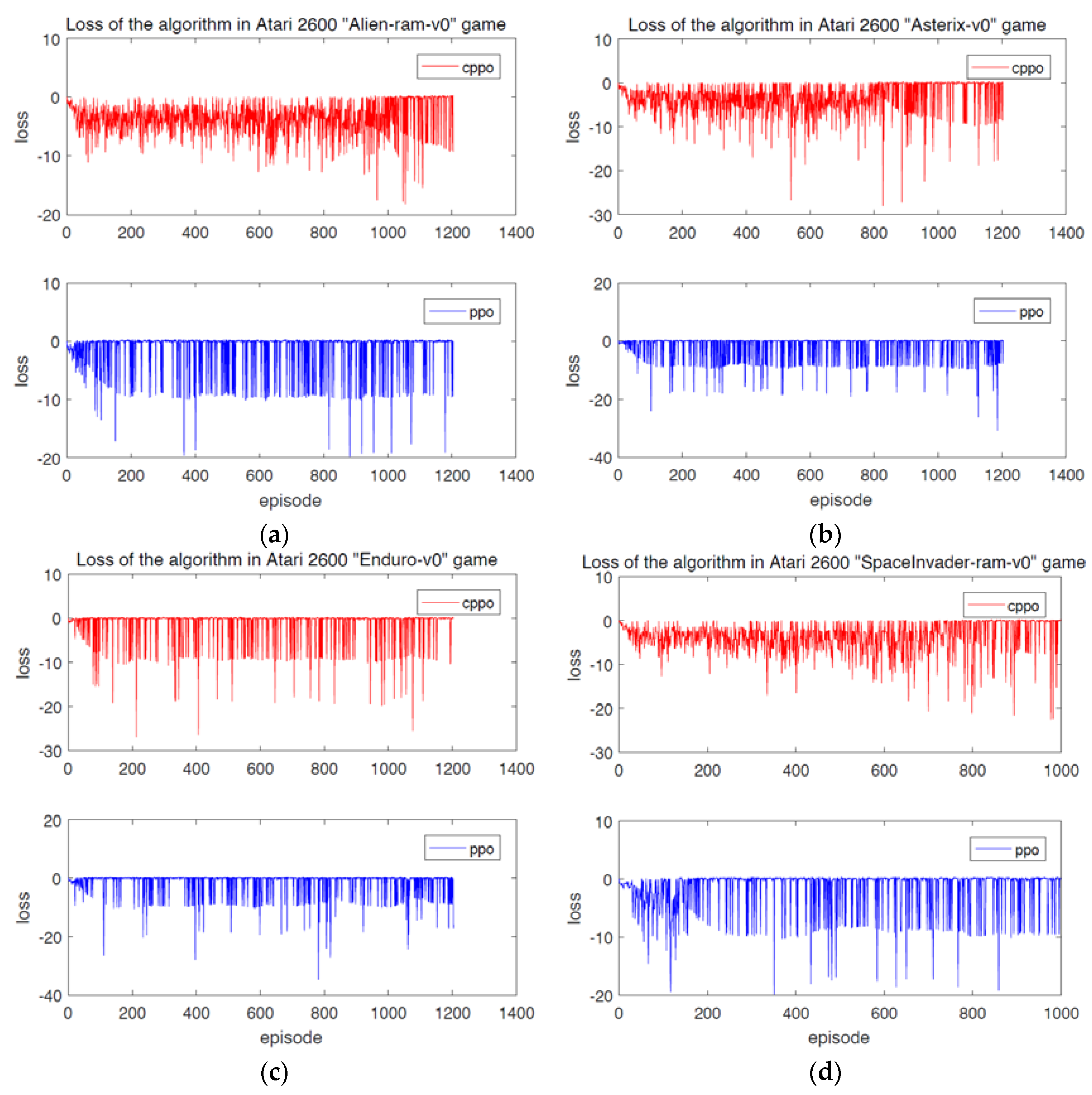
4. Experimental Simulation and Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Yan, D.; Xi, C.; Rein, H.; John, S.; Pieter, A. Benchmarking Deep Reinforcement Learning for Continuous Control. Proc. Mach. Learn. Res. 2016, 48, 1329–1338. [Google Scholar]
- Hussain, Q.A.; Nakamura, Y.; Yoshikawa, Y.; Ishiguro, H. Robot gains Social Intelligence through Multimodal Deep Reinforcement Learning. arXiv 2017, arXiv:1702.07492. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, A.K.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:07274. [Google Scholar]
- Hou, Y.; Liu, L.; Wei, Q.; Xu, X.; Chen, C. A novel DDPG method with prioritized experience replay. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Bannf, Canada, 5–8 October 2017; pp. 316–321. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. Proc. Mach. Learn. Res. 2015, 37, 1889–1897. [Google Scholar]
- Wang, Z.; Bapst, V.; Heess, N.; Mnih, V.; Munos, R.; Kavukcuoglu, K.; de Freitas, N. Sample efficient actor-critic with experience replay. arXiv 2016, arXiv:01224. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:06347. [Google Scholar]
- Youlve, C.; Kaiyun, B.; Zhaoyang, L. Asynchronous Distributed Proximal Policy Optimization Training Framework Based on GPU. In Proceedings of the 2021 Chinese Intelligent Automation Conference, Zhanjiang, China, 5–7 November 2021; Springer: Singapore, 2022; pp. 618–626. [Google Scholar]
- Wei, Z.; Xu, J.; Lan, Y.; Guo, J.; Cheng, X. Reinforcement Learning to Rank with Markov Decision Process. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; pp. 945–948. [Google Scholar]
- Ellerman, D. Logical information theory: New logical foundations for information theory. Log. J. IGPL 2017, 25, 806–835. [Google Scholar] [CrossRef] [Green Version]
- Pelz, M.; Velcsov, M.T. Entropy analysis of Boolean network reduction according to the determinative power of nodes. Phys. A Stat. Mech. Appl. 2022, 589, 126621. [Google Scholar] [CrossRef]
- Hoberman, S.; Ivanova, A. The properties of entropy as a measure of randomness in a clinical trial. J. Stat. Plan. Inference 2022, 216, 182–193. [Google Scholar] [CrossRef]
- Dai, E.; Jin, W.; Liu, H.; Wang, S. Towards Robust Graph Neural Networks for Noisy Graphs with Sparse Labels. arXiv 2022, arXiv:2201.00232. [Google Scholar]
- Wang, D.-Q.; Zhang, Z.; Yuan, J.-Y. Maximum likelihood estimation method for dual-rate Hammerstein systems. Int. J. Control Autom. Syst. 2017, 15, 698–705. [Google Scholar] [CrossRef]
- Vestner, M.; Litman, R.; Rodola, E.; Bronstein, A.; Cremers, D. Product manifold filter: Non-rigid shape correspondence via kernel density estimation in the product space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3327–3336. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Xue, Y.; Zhang, L.; Wang, B.; Zhang, Z.; Li, F. Nonlinear feature selection using Gaussian kernel SVM-RFE for fault diagnosis. Appl. Intell. 2018, 48, 3306–3331. [Google Scholar] [CrossRef]
- Yang, L.; Ren, Z.; Wang, Y.; Dong, H. A robust regression framework with laplace kernel-induced loss. Neural Comput. 2017, 29, 3014–3039. [Google Scholar] [CrossRef]
- Nielsen, F.; Sun, K. Guaranteed bounds on the Kullback–Leibler divergence of univariate mixtures. IEEE Signal Process. Lett. 2016, 23, 1543–1546. [Google Scholar] [CrossRef]
- Yu, D.; Yao, K.; Su, H.; Li, G.; Seide, F. KL-divergence regularized deep neural network adaptation for improved large vocabulary speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, Canada, 26–31 May 2013; pp. 7893–7897. [Google Scholar]
- Passalis, N.; Tefas, A. Entropy optimized feature-based bag-of-words representation for information retrieval. IEEE Trans. Knowl. Data Eng. 2016, 28, 1664–1677. [Google Scholar] [CrossRef]
- Zhang, X.G.; Yang, G. Kullback-Leibler Divergence-based Attacks against Remote State Estimation in Cyber-physical Systems. IEEE Trans. Ind. Electron. 2021, 69, 99. [Google Scholar] [CrossRef]
- Tang, Z.H.; Zhang, Z.J. The multi-objective optimization of combustion system operations based on deep data-driven models. Energy 2019, 182, 37–47. [Google Scholar] [CrossRef]
- Shang, H.; Li, Y.; Xu, J.; Qi, B.; Yin, J. A novel hybrid approach for partial discharge signal detection based on complete ensemble empirical mode decomposition with adaptive noise and approximate entropy. Entropy 2020, 22, 1039. [Google Scholar] [CrossRef] [PubMed]
- Usman, A.M.; Yusof, U.K.; Sabudin, M. Filter-Based Feature Selection Using Information Theory and Binary Cuckoo Optimisation Algorithm. J. Inf. Technol. Manag. 2022, 14, 203–222. [Google Scholar]
- Bota, P.; Fred, A.; Valente, J.; Wang, C.; da Silva, H.P. A dissimilarity-based approach to automatic classification of biosignal modalities. Appl. Soft Comput. 2022, 115, 108203. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Game Items | Alien−ram−v0 | Asterix−v0 | Enduro−v0 | SpaceInvader−ram−v0 |
|---|---|---|---|---|
| CPPO | 226,214 | 183,496 | 267,548 | 175,857 |
| PPO | 45,931 | 81,578 | 221,451 | 43,571 |
| Number of iterations | 1200 | 1200 | 1200 | 1000 |
| Iteration time | ≥6.5 h | ≥7 h | ≥7.5 h | ≤5 h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Wong, K.K.L.; Long, S.; Sun, Z. Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment. Entropy 2022, 24, 440. https://doi.org/10.3390/e24040440
Chen W, Wong KKL, Long S, Sun Z. Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment. Entropy. 2022; 24(4):440. https://doi.org/10.3390/e24040440
Chicago/Turabian StyleChen, Weimin, Kelvin Kian Loong Wong, Sifan Long, and Zhili Sun. 2022. "Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment" Entropy 24, no. 4: 440. https://doi.org/10.3390/e24040440
APA StyleChen, W., Wong, K. K. L., Long, S., & Sun, Z. (2022). Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment. Entropy, 24(4), 440. https://doi.org/10.3390/e24040440