1. Introduction
With the development of the three generations of artificial intelligence [
1], the technology of multi-agent systems (MASs) has been widely used in many areas of society, such as multi-agent motion planning, complex IT systems, computer communication technology, and so on [
2,
3,
4,
5]. Pursuit–evasion games have been widely investigated in MASs during recent years. They have been extended to various fields, to include maneuvering target tracking, surveillance early warning, anti-intrusion protection, and intelligent transportation [
6,
7]. The goal of these studies is to provide good strategies for pursuers and evaders. For pursuers, their goal is to round up the evaders as much as possible through cooperative decision-making. For evaders, they need to choose the best strategy based on the actions of pursuers to design an escape path to prevent being captured [
8].
To address this problem, a series of research activities on agent-based pursuit–evasion games has been carried out in the differential gaming field. Isaacs [
9] proposed a one-to-one robot hunting problem where partial differential equations describing the pursuer and the evader were created and solved analytically. Furthermore, a generalized maximum–minimum solving method of the Hamilton Jacobi equation for pursuit–evasion games was provided by Krasovskii [
10]. Because in complex control problems, directly solving differential equations is very complicated and consumes many computing resources, researchers proposed some intelligent optimization algorithms that provide new ideas for solving the differential equation problems associated with pursuit–evasion games. Chen et al. [
11] simulated fish foraging behavior and proposed a cooperative pursuit strategy that studied pursuit and evasion when trackers have a constrained turning rate. Wang et al. [
12] introduced an alliance generation algorithm that generates a synergistic strategy based on the emotional factors of multirobot systems. This ensured that a team’s agents worked towards a common goal. However, there are many constraints and state variables involved in the complicated control process governing these issues, which make the solution intricate especially in a complex and dynamic scenario with multi-agent confrontation. Therefore, more intelligent algorithms are needed to effectively solve the problem of pursuit–evasion games.
By combining deep learning’s ability to perceive highly dimensional data [
13] and reinforcement learning’s decision-making ability [
14], deep reinforcement learning (DRL) provides a new optimization scheme for intelligent decision-making or control. Because techniques based on deep reinforcement learning do not require the establishment of a differential game model and agents can learn the optimal confrontation strategy only through interaction with the environment [
15], some scholars introduced deep reinforcement learning in pursuit–evasion games and acquired the Nash equilibrium of the problem. Xu et al. [
16] established a multi-agent reinforcement learning model for UAV pursuit–evasion in which relative motion state equations were employed. As a result, the pursuit–evasion issue was converted into a zero-sum game addressed through minimax-Q learning. In predatory games, Park et al. [
17] set up a co-evolution framework for predator and prey to allow multiple agents to learn good policies by deep reinforcement learning. Gu et al. [
18] presented an attention-based fault-tolerant model, which could also be applied to pursuit–evasion games, and the key idea was to utilize the multihead attention mechanism to select the correct and useful information for estimating the critics. To solve the complicated training problems caused by discrete action sets introduced by deep Q networks [
19], Liu et al. [
20] transformed a space rendezvous optimization problem between a space vehicle and noncooperative target into a pursuit–evasion differential game. They introduced a branching architecture with a group of parallel neural networks and shared decision modules. To overcome the unstable recognition ability of pursuers, Qadir et al. [
21] proposed a novel approach for self-organizing feature maps and deep reinforcement learning based on the agent group role membership function model. Experiments verified the effectiveness of this method for facilitating the capture of evaders by mobile agents. Singh et al. [
22] built on the actor–critic model-free multi-agent deep deterministic policy gradient algorithm to operate over the continuous spaces of pursuit–evasion games. In their approach, the evader’s strategy is not learned. It is based on Voronoi regions that pursuers try to minimize and evaders try to maximize.
Although they represent progress, previous studies on DRL-based pursuit–evasion games are still in their early stages. In these studies, pursuing platforms are assumed to be equipped with error-free identification and measurement systems that allow them to acquire precise information about the position, velocity, and other characteristics of evaders and cooperators [
6,
23]. However, sensors and other equipment configured in an unmanned system encounter positioning, sensing, and actuator error in reality [
24,
25]. These errors cause the environment to become uncertain, thereby affecting the strategies of the pursuers and evaders and making their performance worse. Therefore, this research is about designing a robust algorithm for MASs to effectively mitigate these errors and that would be significant for application research in real-world multi-agent decision-making.
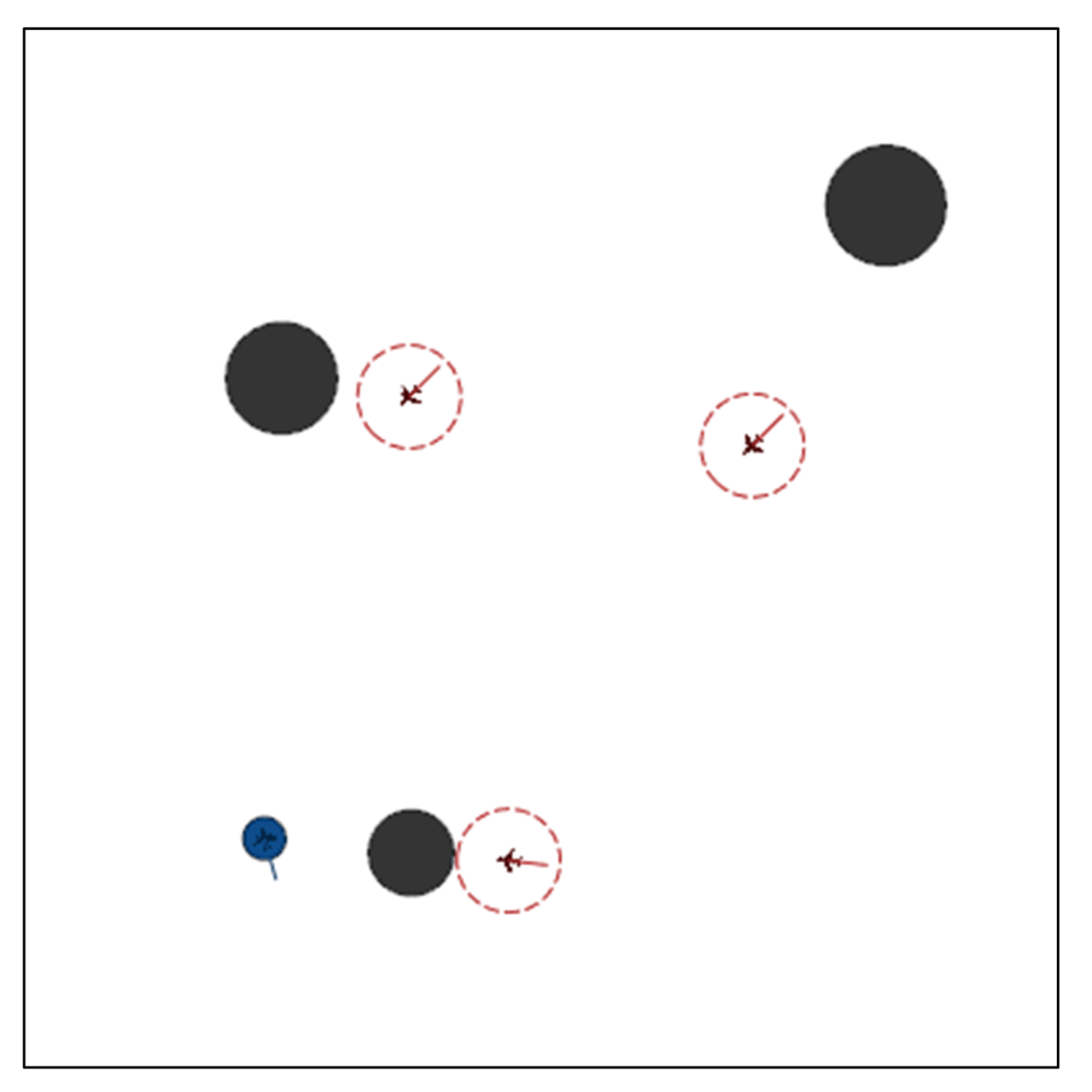
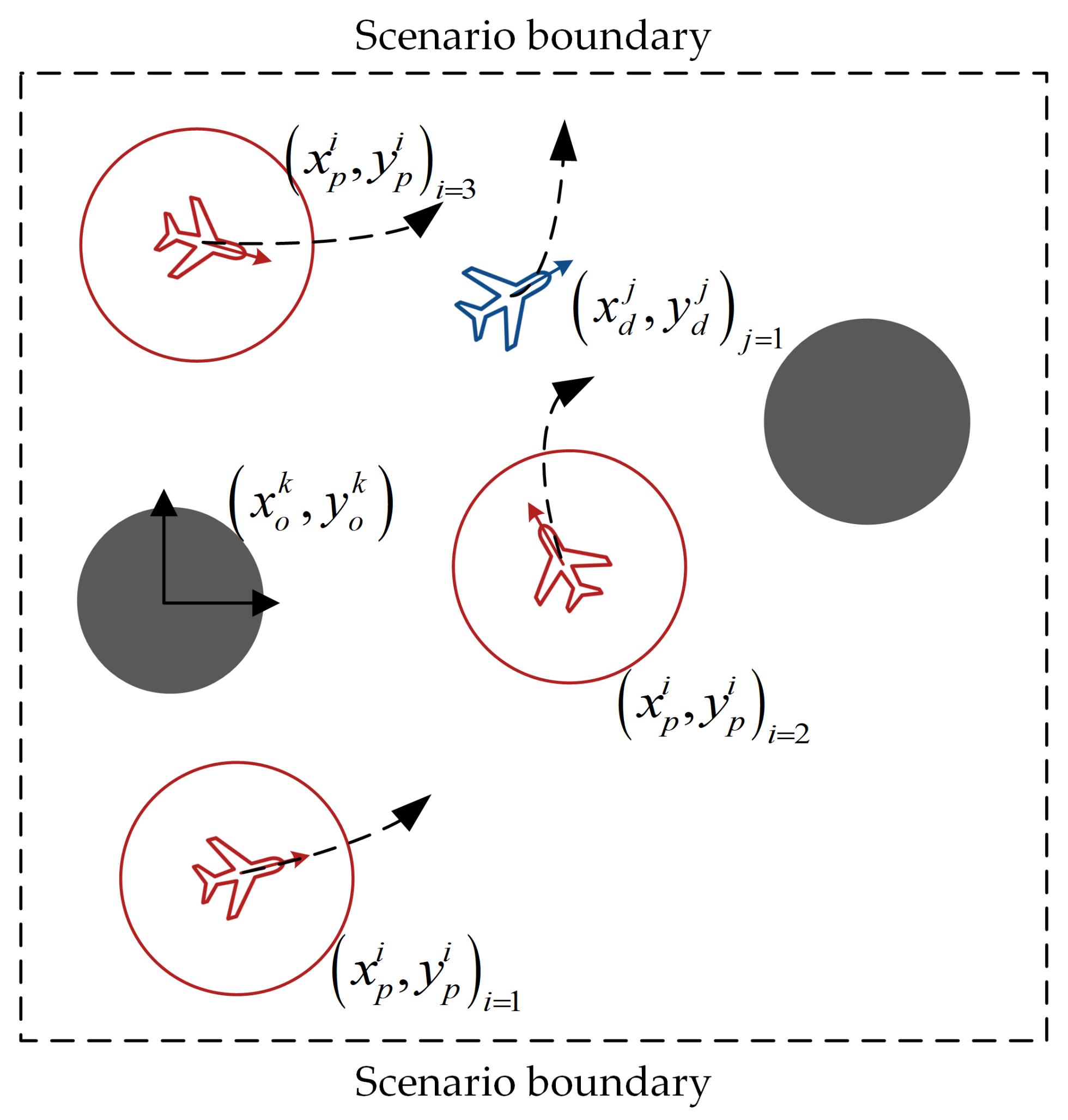
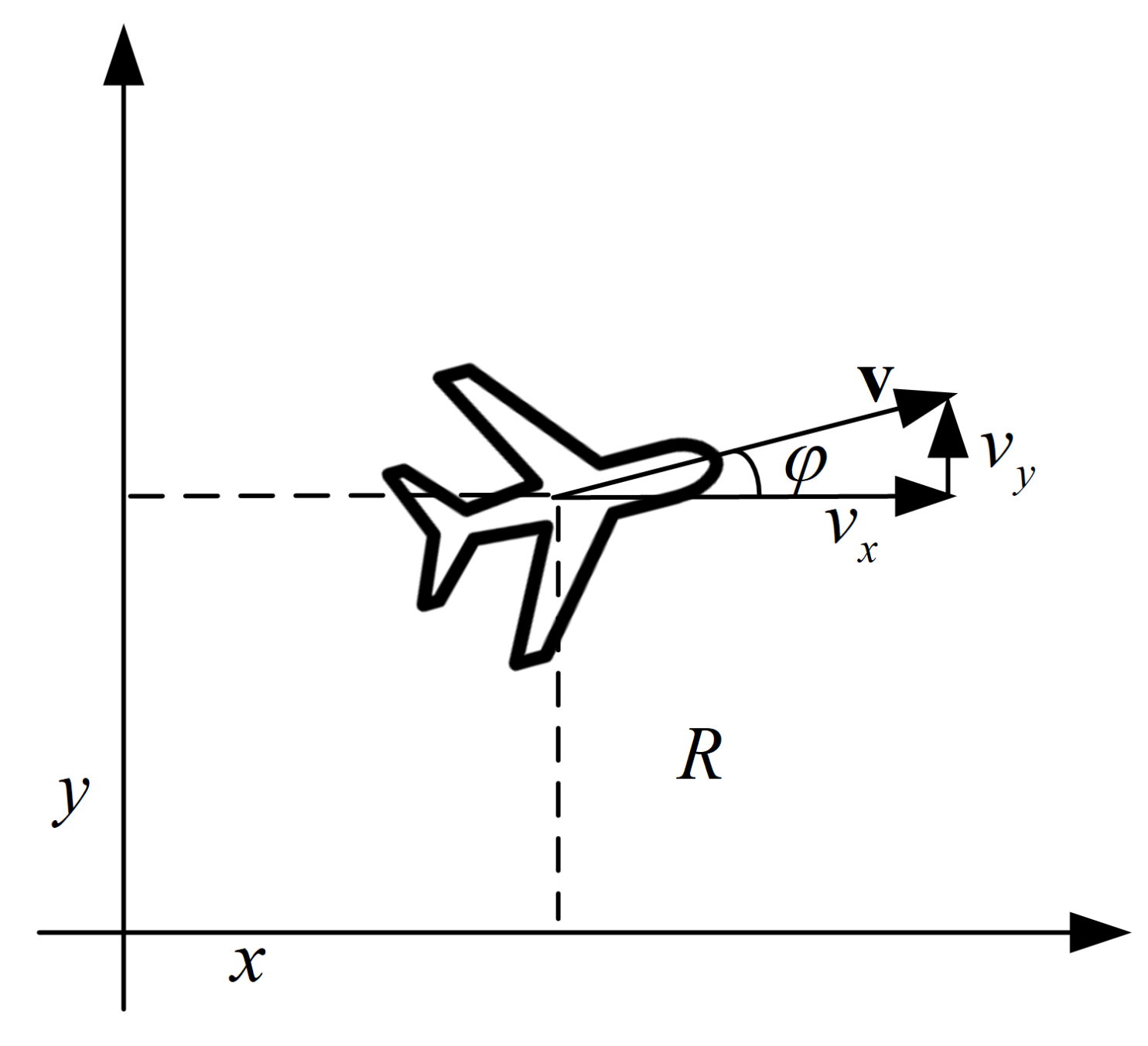
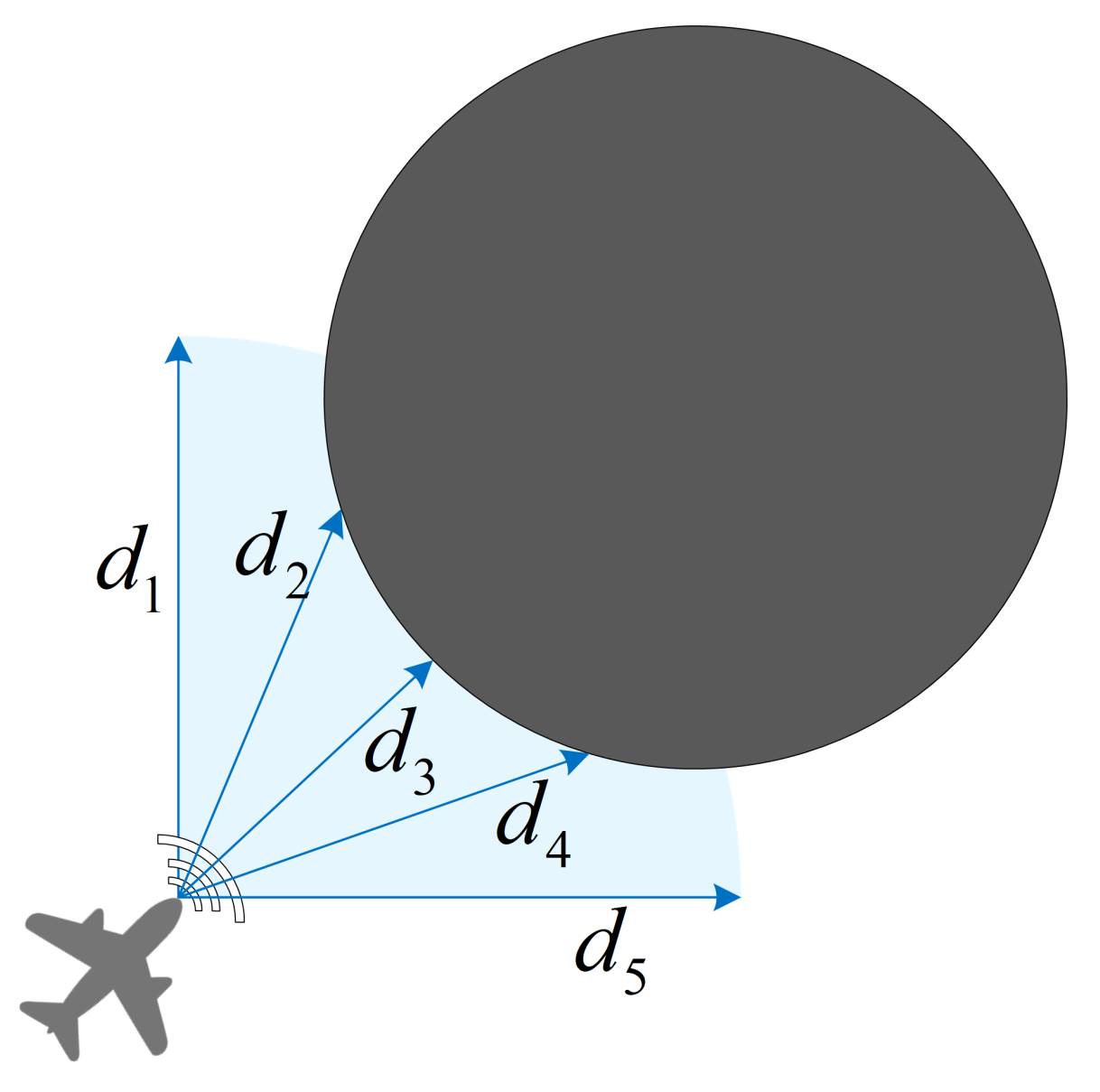
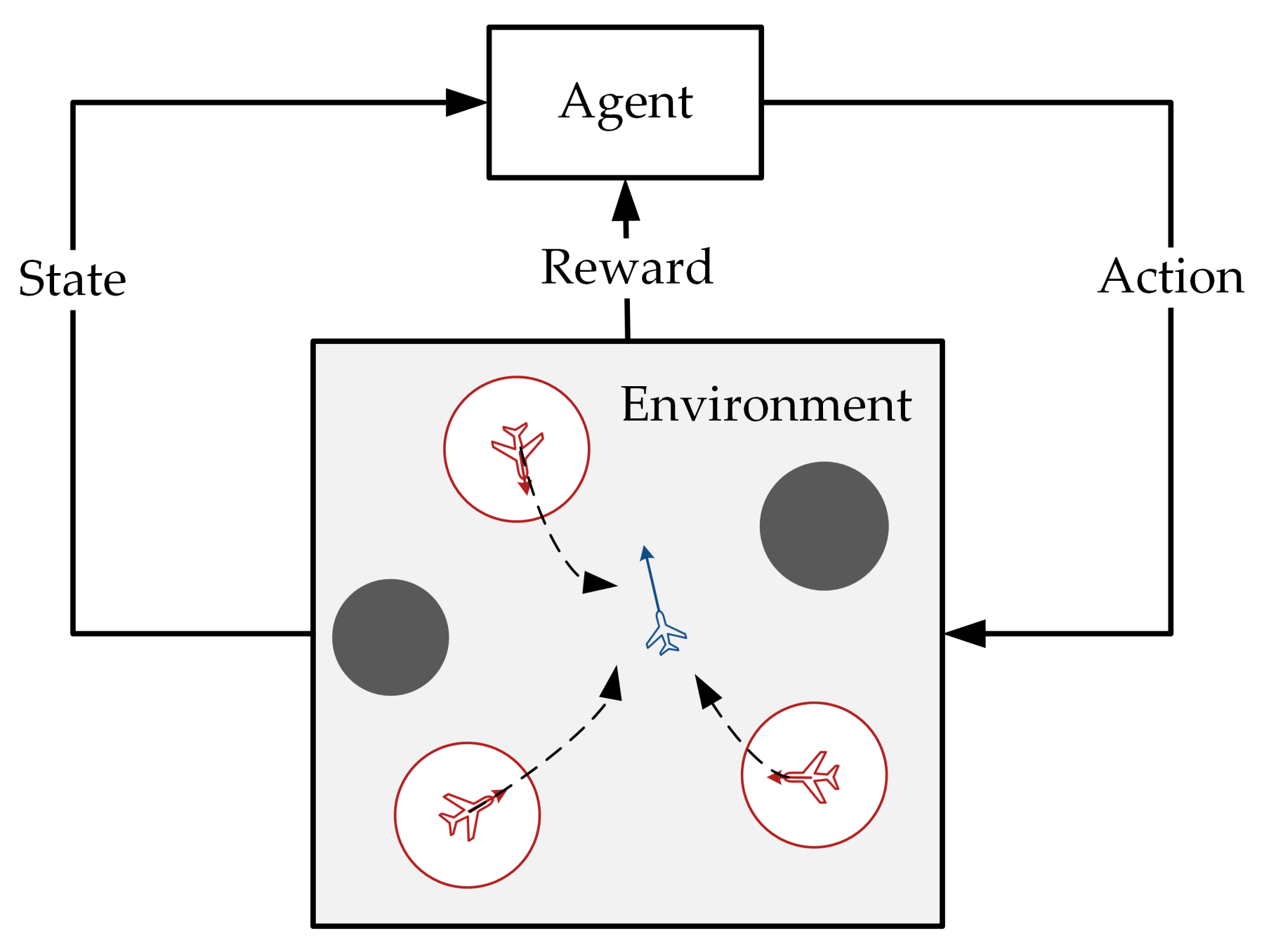
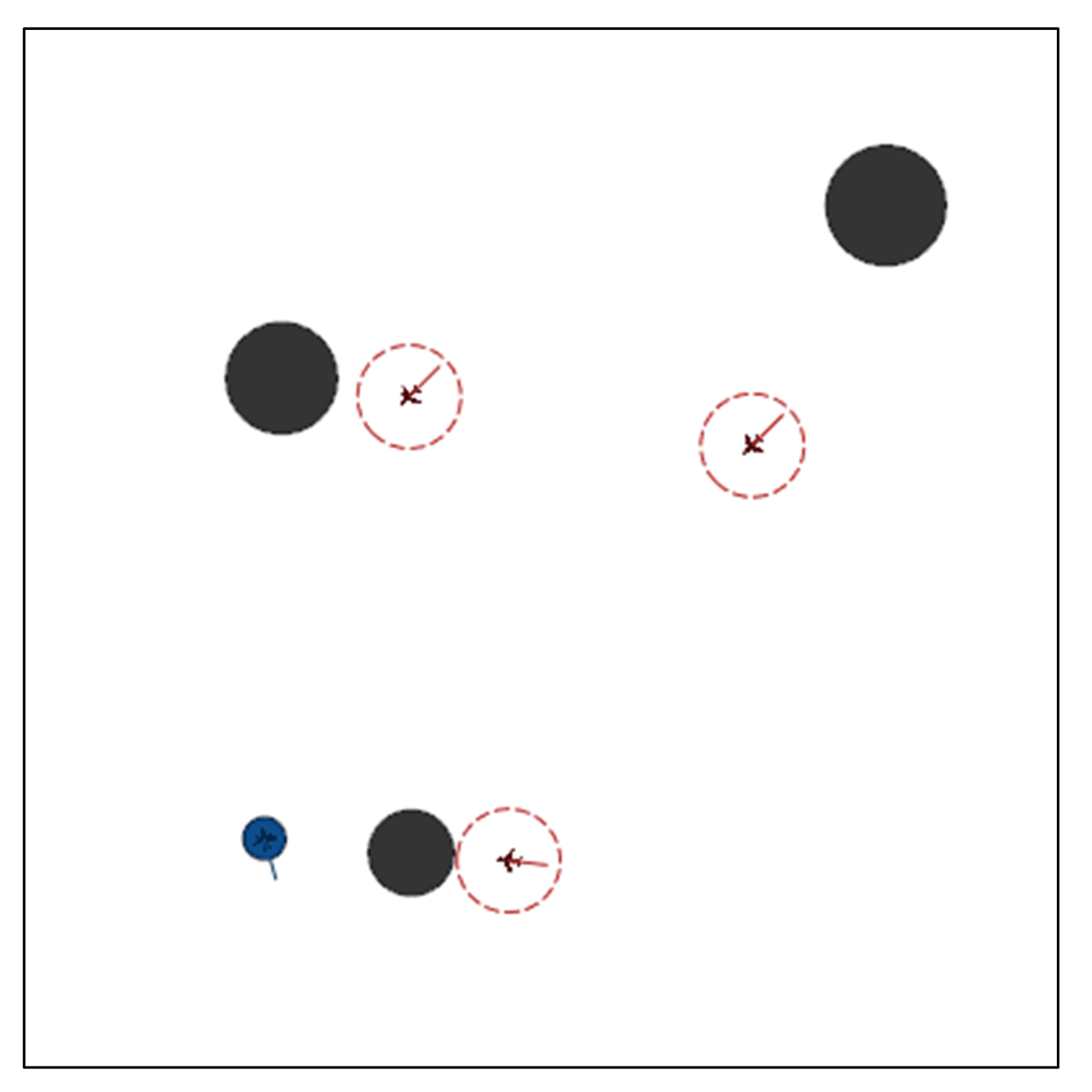
This paper introduces a novel multi-agent algorithm to address the decision-making problem of pursuit–evasion games. The algorithm can solve pursuit–evasion games in complex virtual and real environments, where there are static or moving obstacles and pursuers and evaders need to avoid them while making decisions. Specifically, we make the following contributions in this paper:
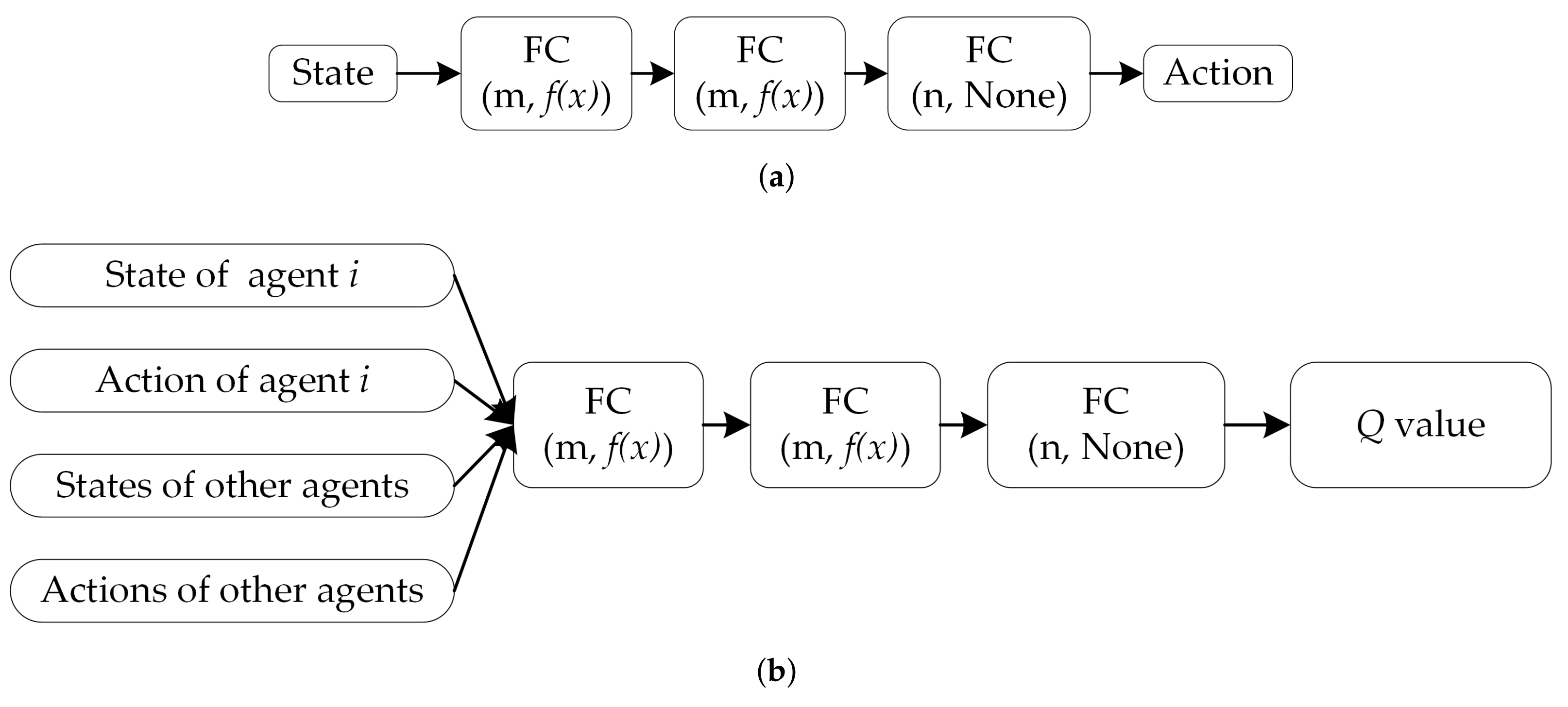
(1) We develop an actor–critic-based motion control framework based on the multi-agent deep deterministic policy gradient (MADDPG) [
26], which can take the state and behavior of other partners into account and is used to provide collaborative decision-making capabilities for each agent in the MAS;
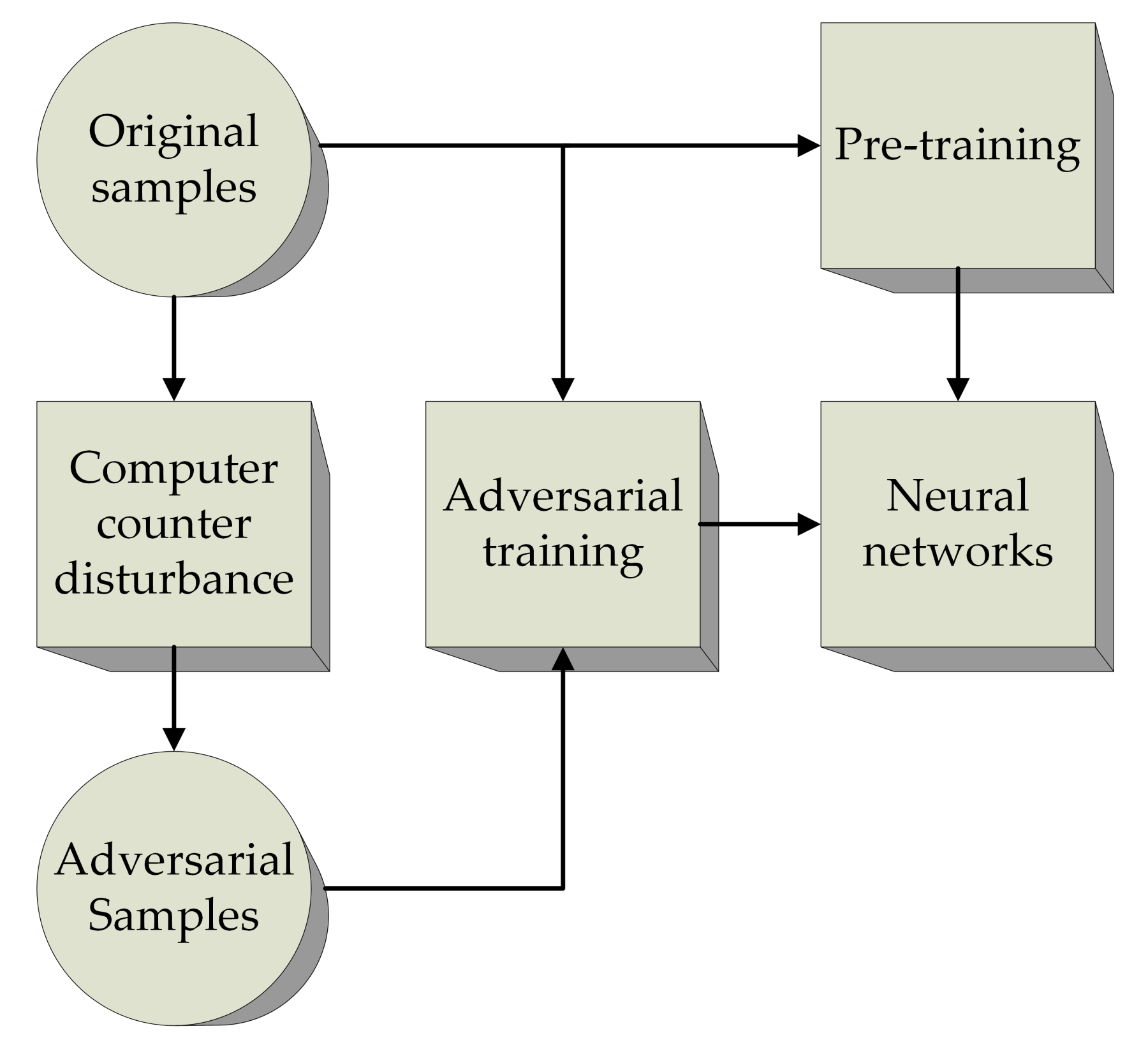
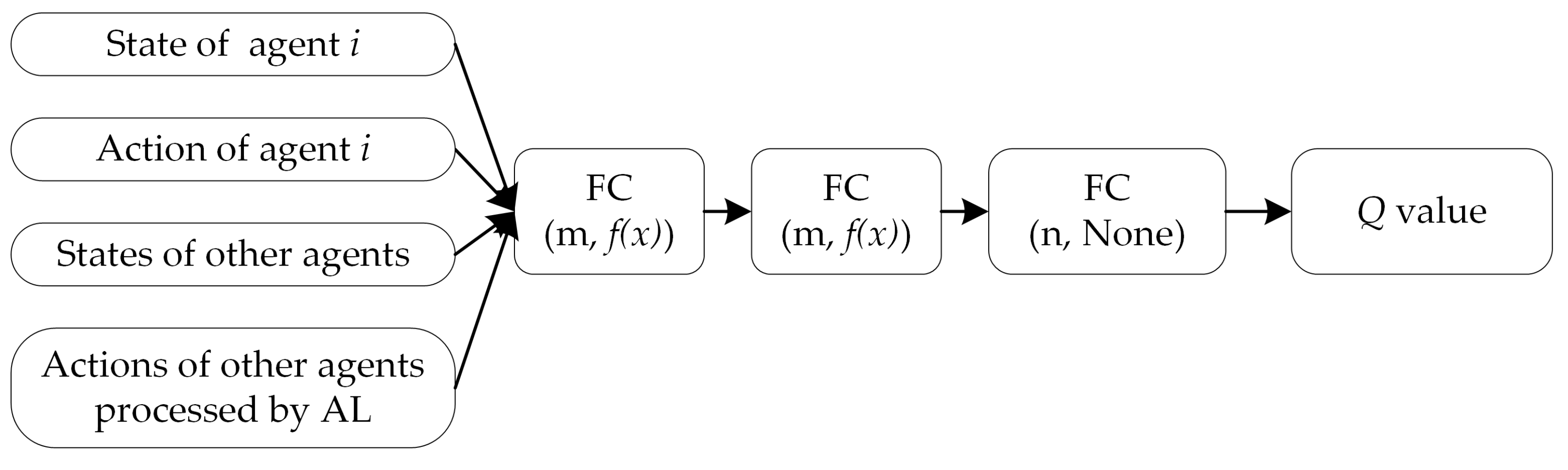
(2) We propose an advanced algorithm called A2-MADDPG, which uses two skills to make the training strategy robust. The first is adversarial attack tricks for agents. It proposes to sample the status after stochastic Gaussian noise is applied, and this approach can train a robust agent to cope with measurement errors in the real world. The second is the optimized adversarial learning technique [
27]. It is introduced to improve agent stability and to assist in adapting to noise produced by interactions between multiple agents;
(3) We verified the effectiveness and robustness of the algorithm in simulation experiments. We compared the performance of the proposed method with two common and advanced algorithms, namely the MADDPG and the independent multiagent deep deterministic policy gradient (IMDDPG), where the IMDDPG is a natural extension of the DDPG [
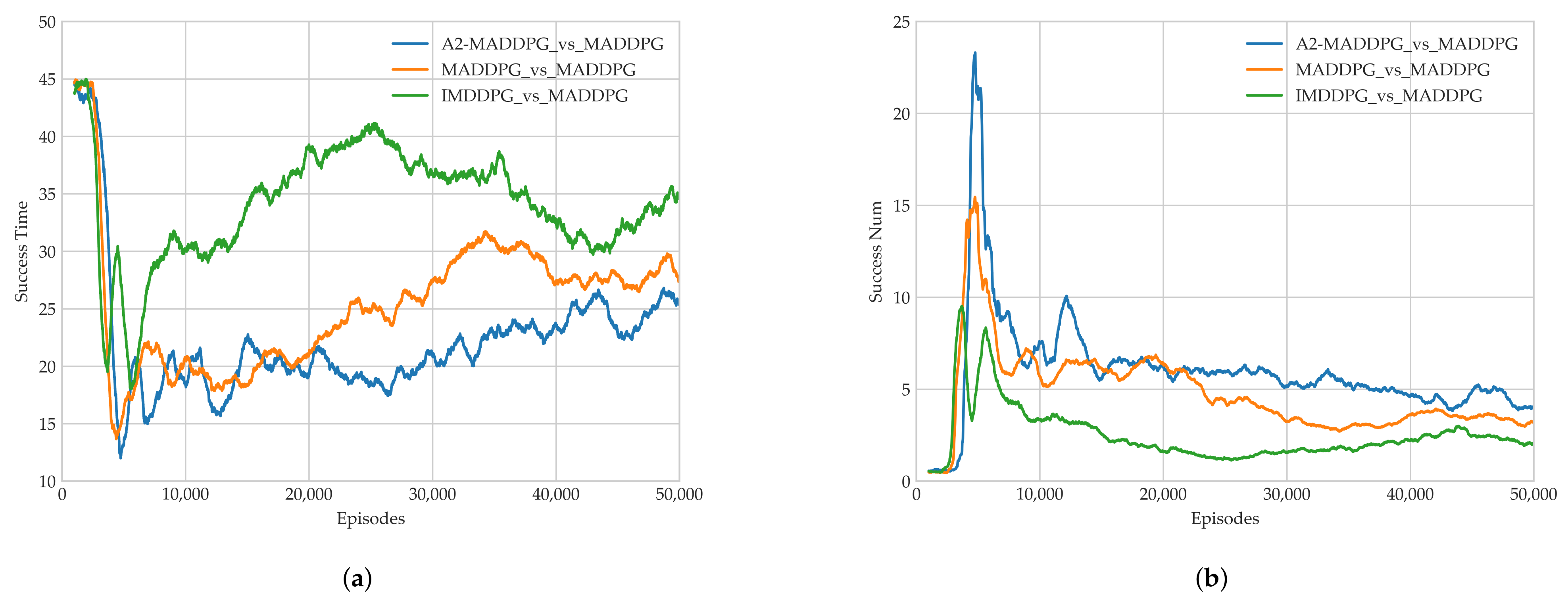
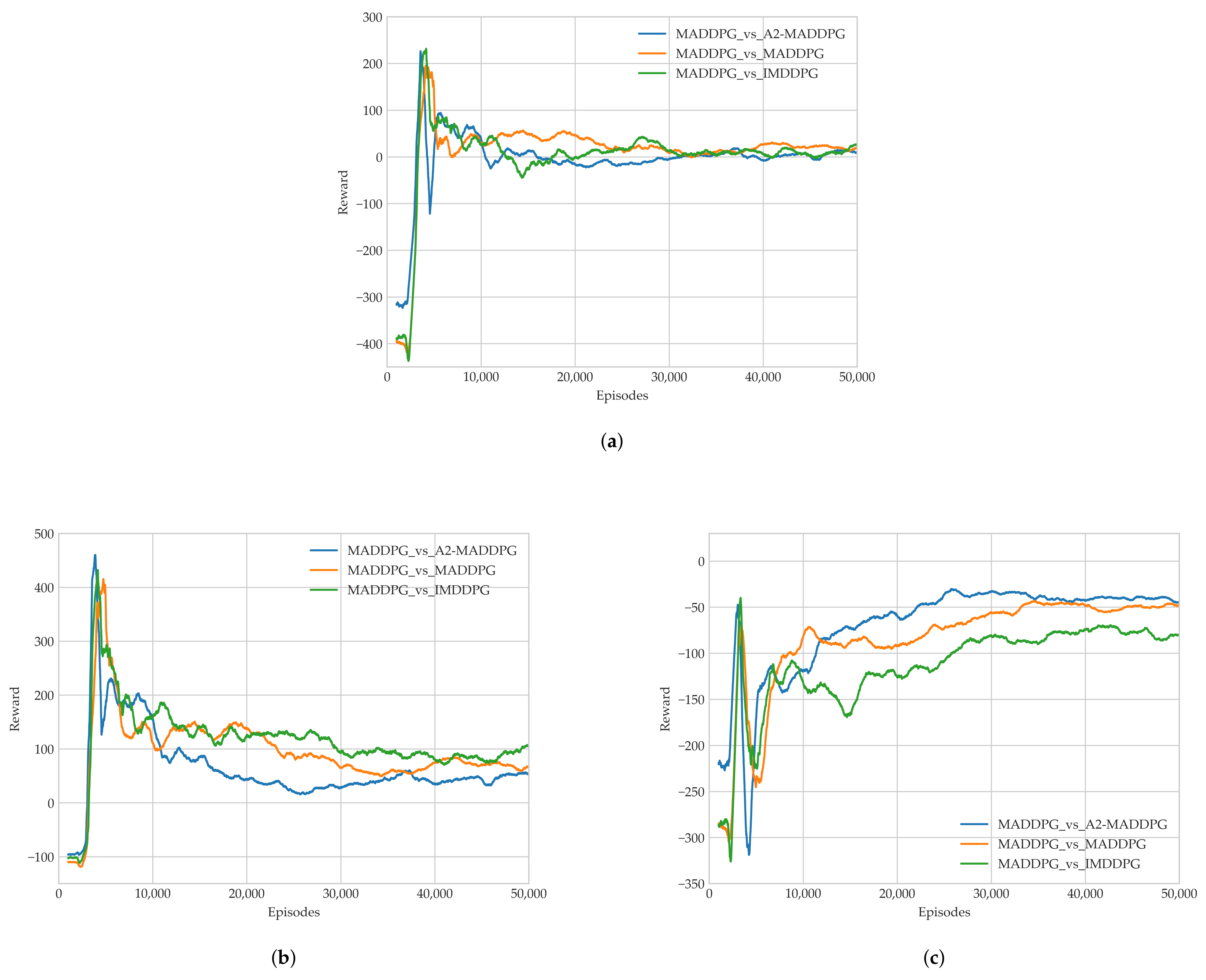
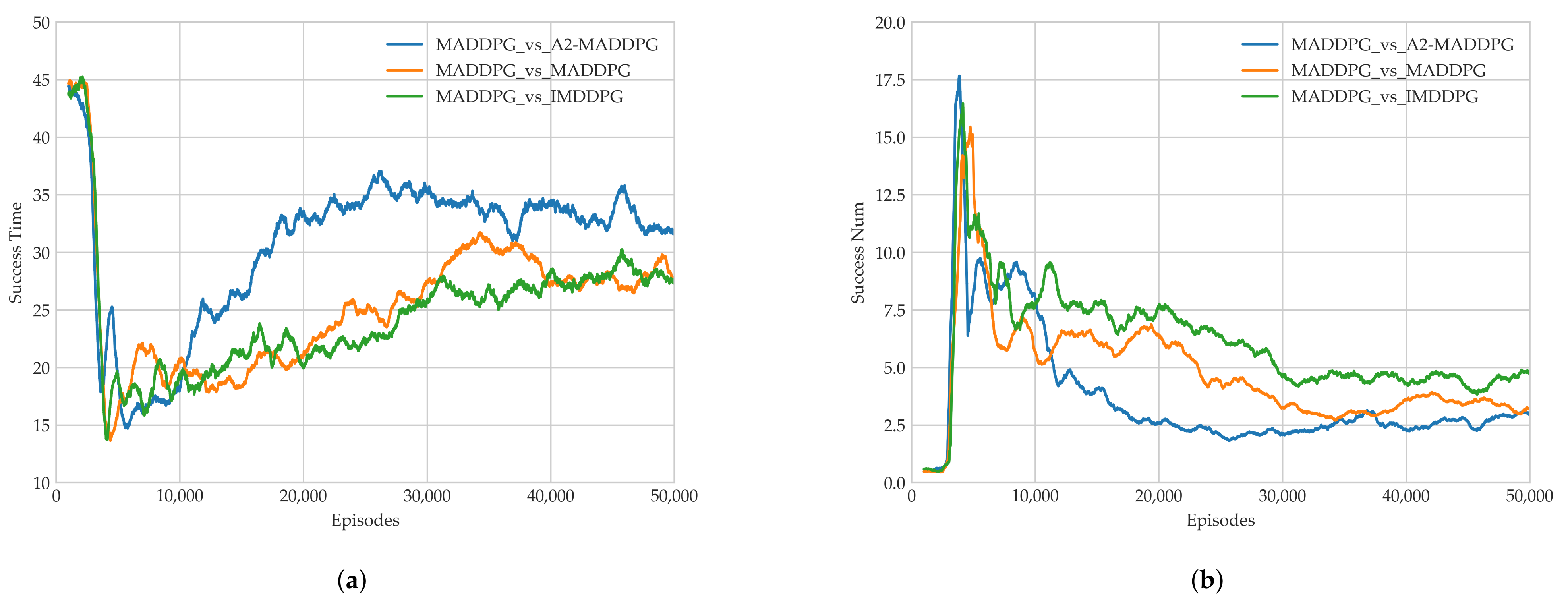
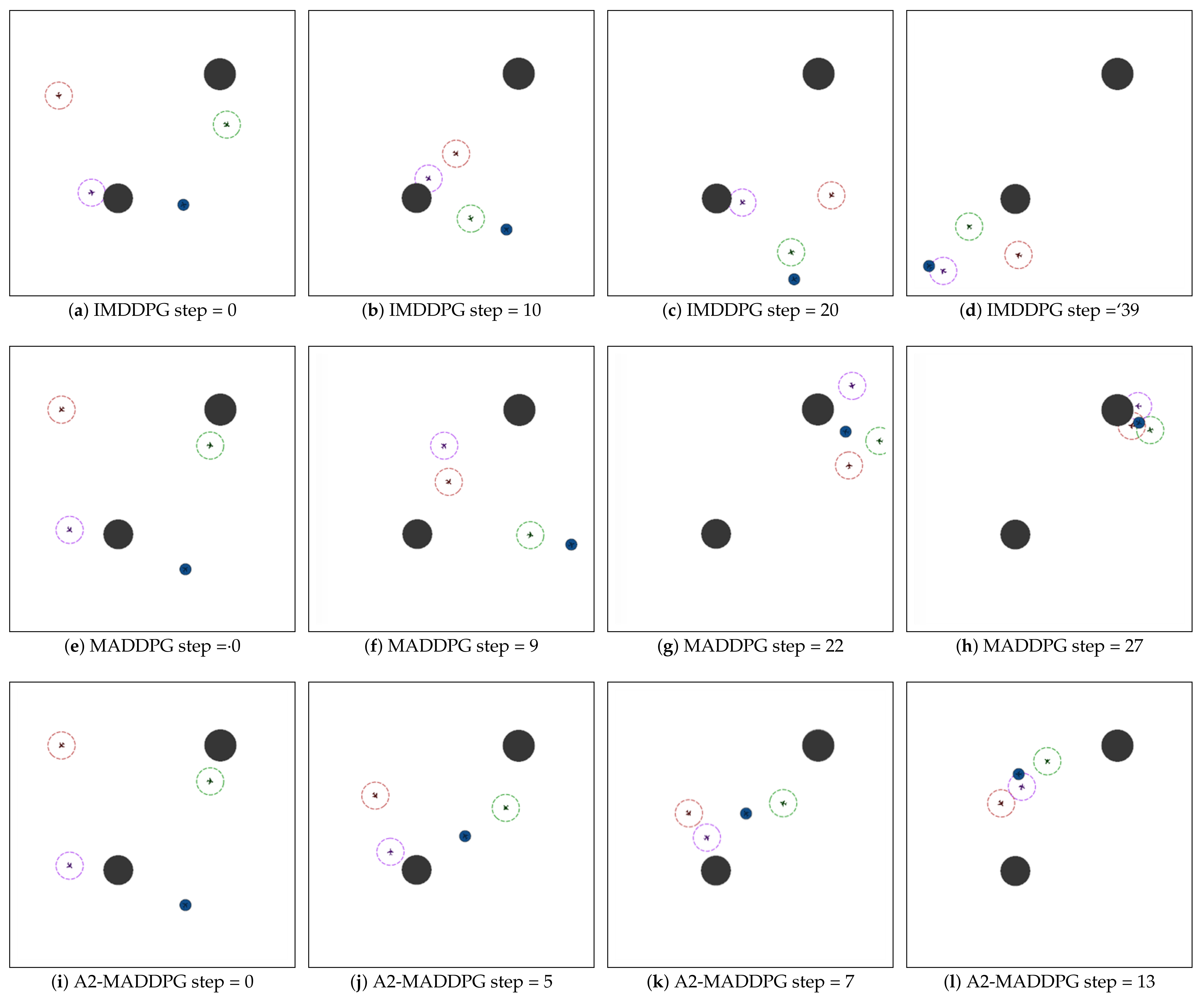
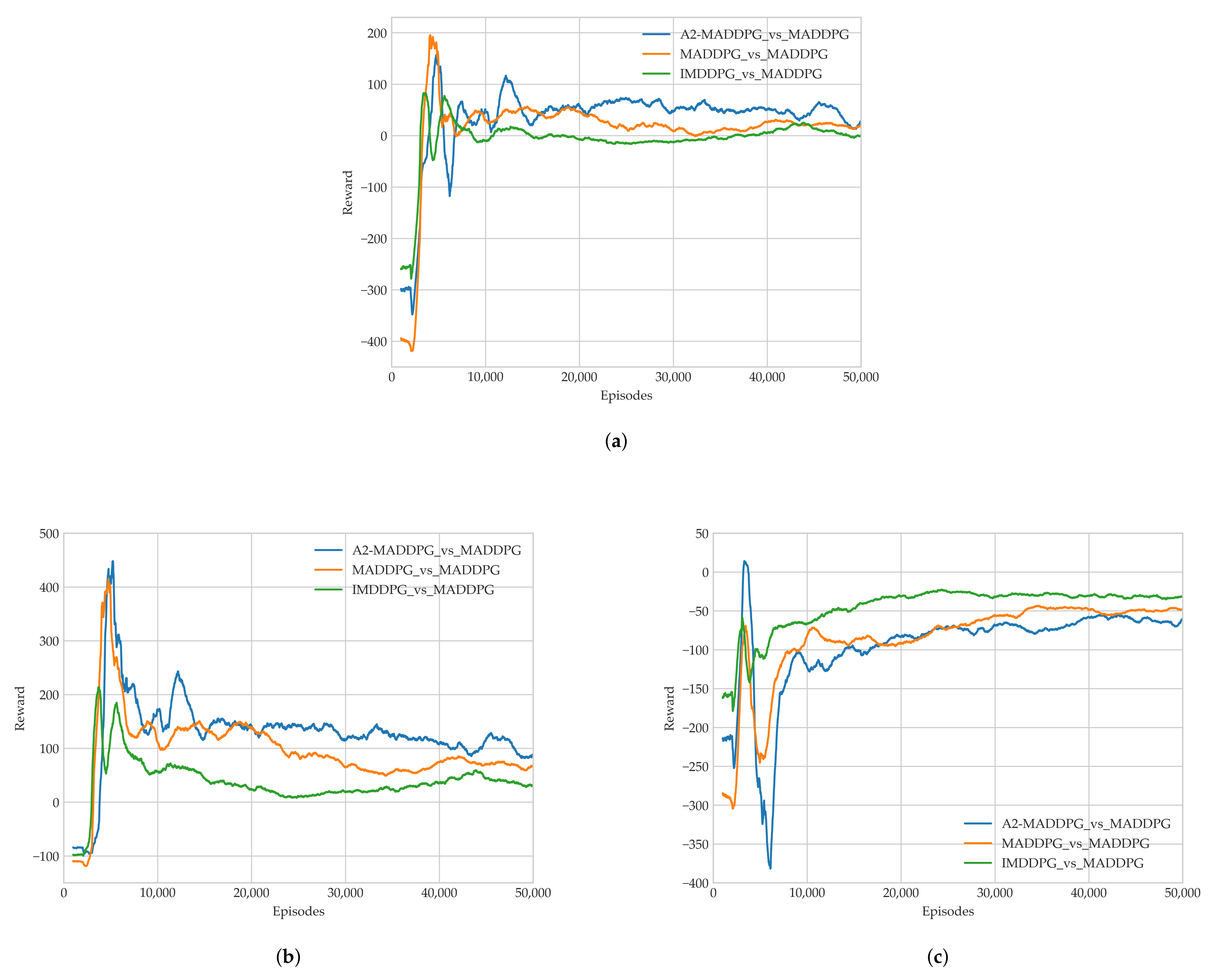
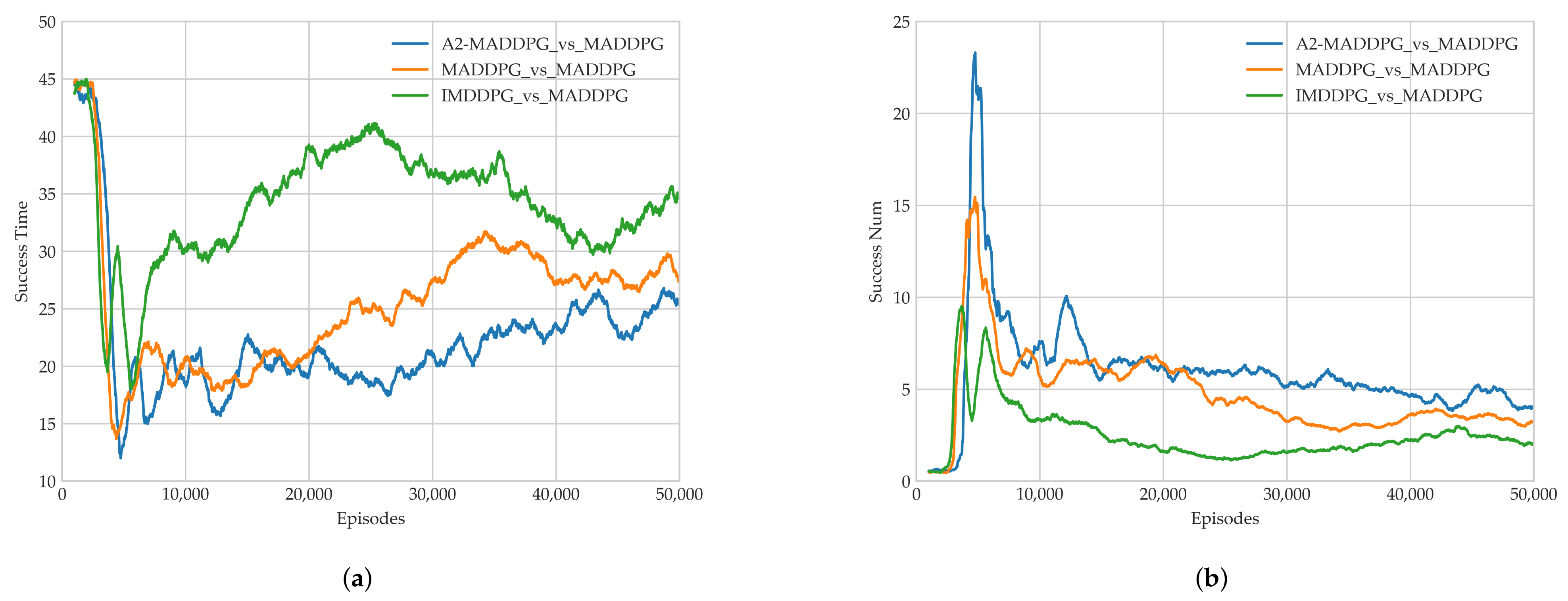
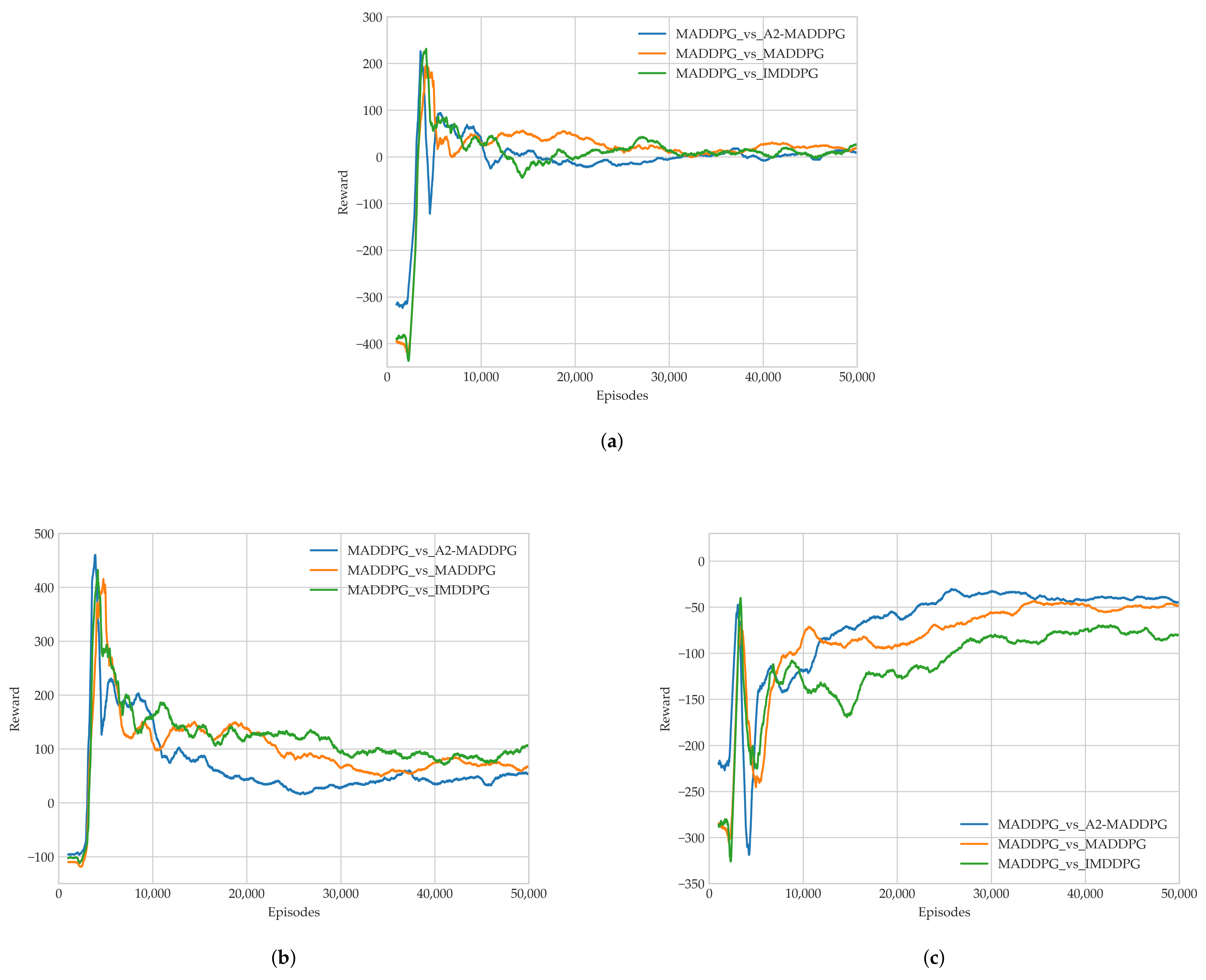
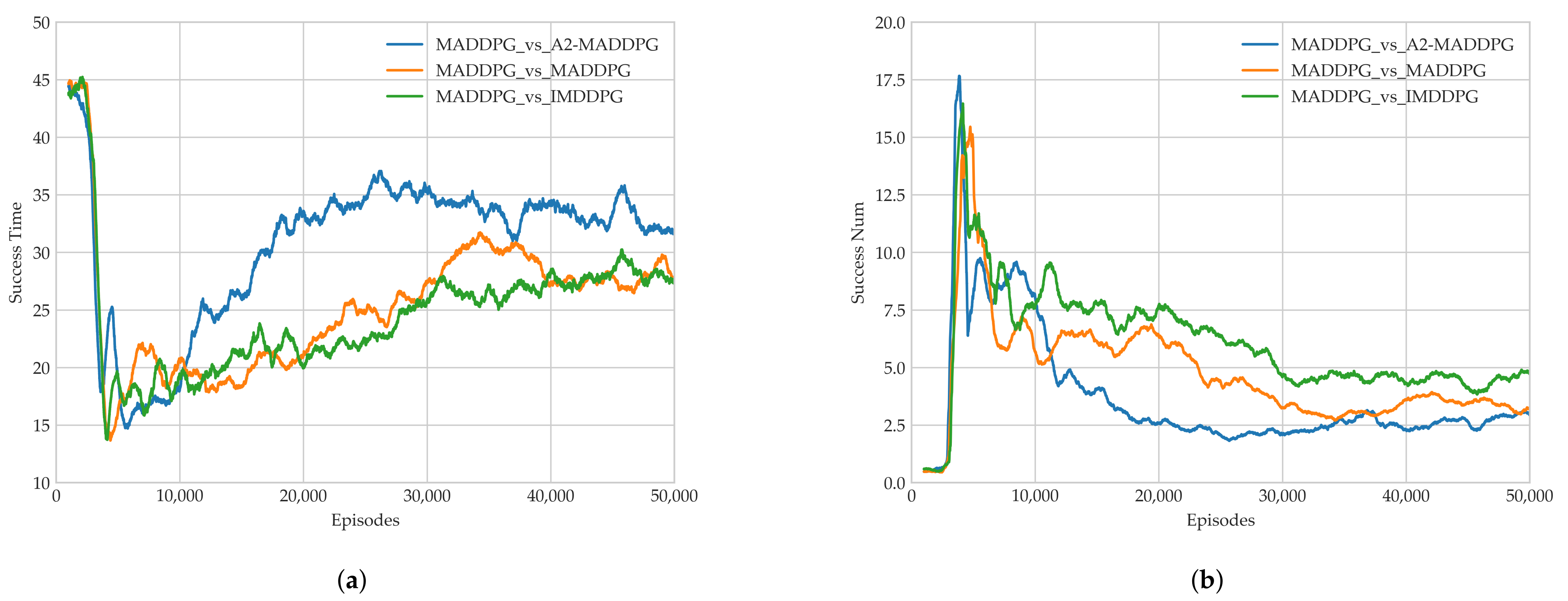
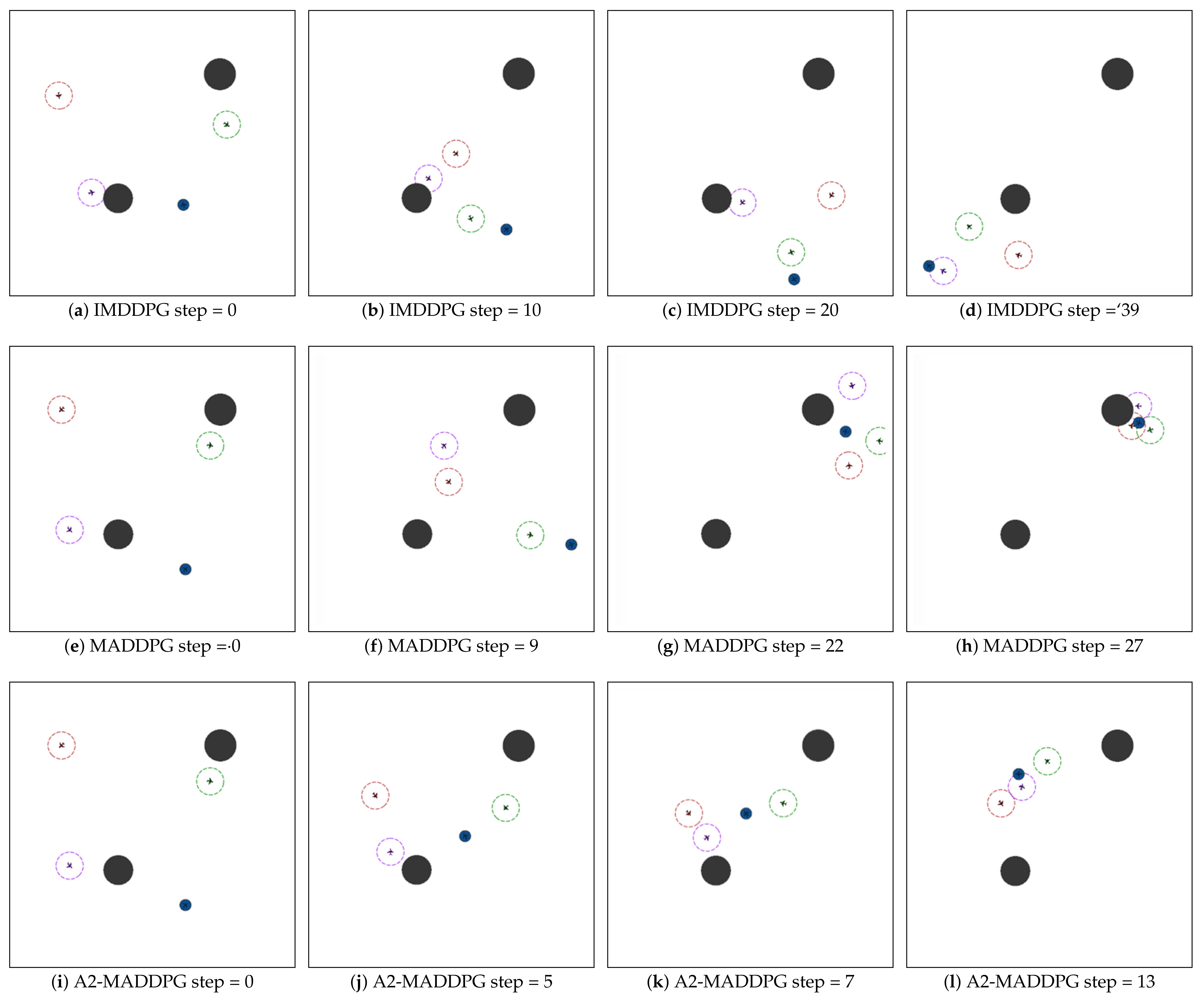
28] in the field of multi-agents. Through a series of experiments, we show that the proposed method presents excellent performance for both pursuers and evaders compared with the MADDPG and IMDDPG in the case of the same hyperparameter settings and simulation environment parameter settings, and it can help them both develop robust motion strategies.
The rest of the paper is structured as follows:
Section 2 provides background information about multi-agent pursuit–evasion games and describes related theoretical approaches.
Section 3 introduces a framework for collaborative pursuit missions and an improved A2-MADDPG algorithm where an adversarial attack trick and an adversarial learning-based optimization method are combined with the MADDPG.
Section 4 verifies the robustness and high performance of the algorithm through simulation experiments.
Section 5 provides a conclusion and envisages future work.






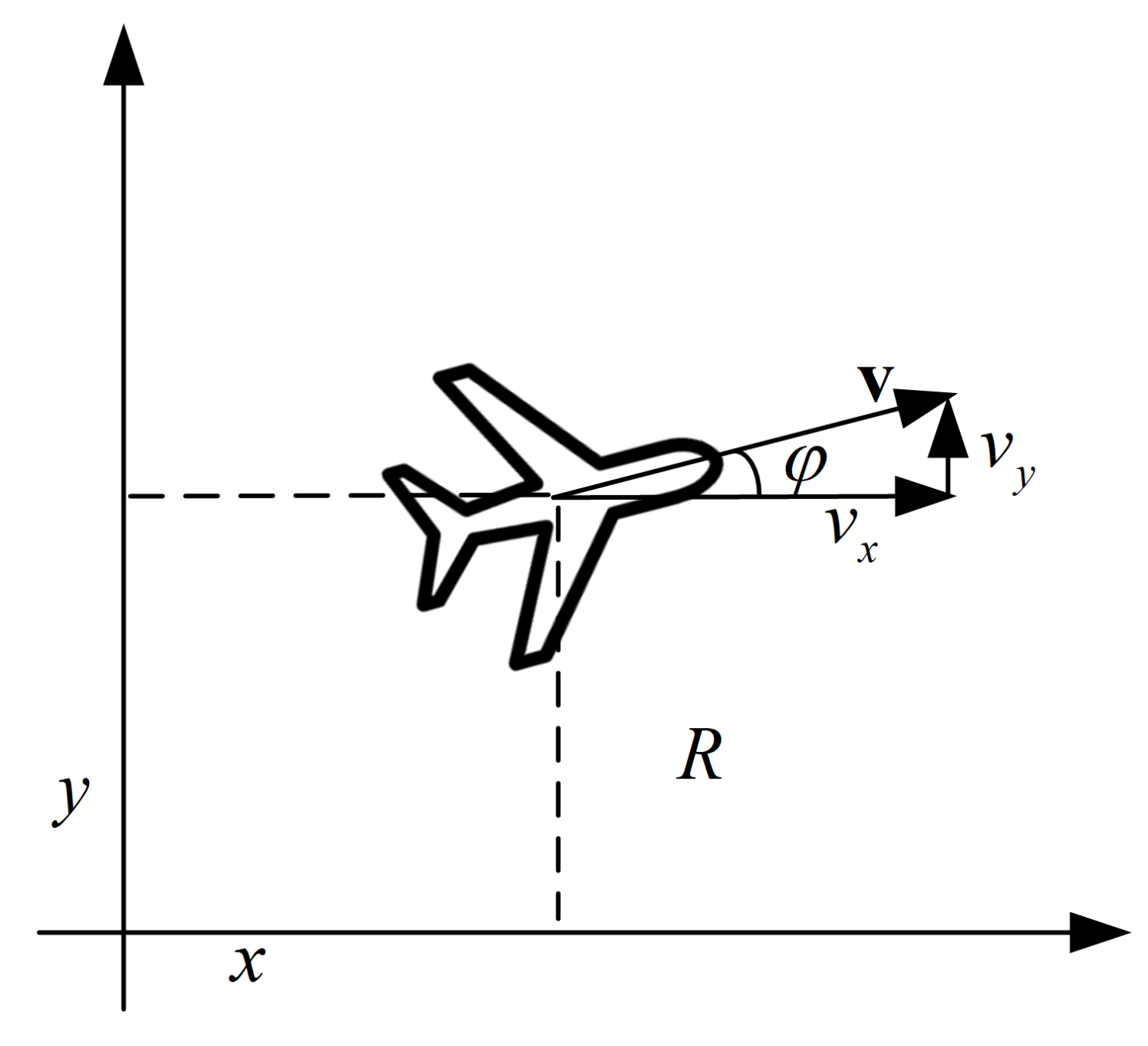
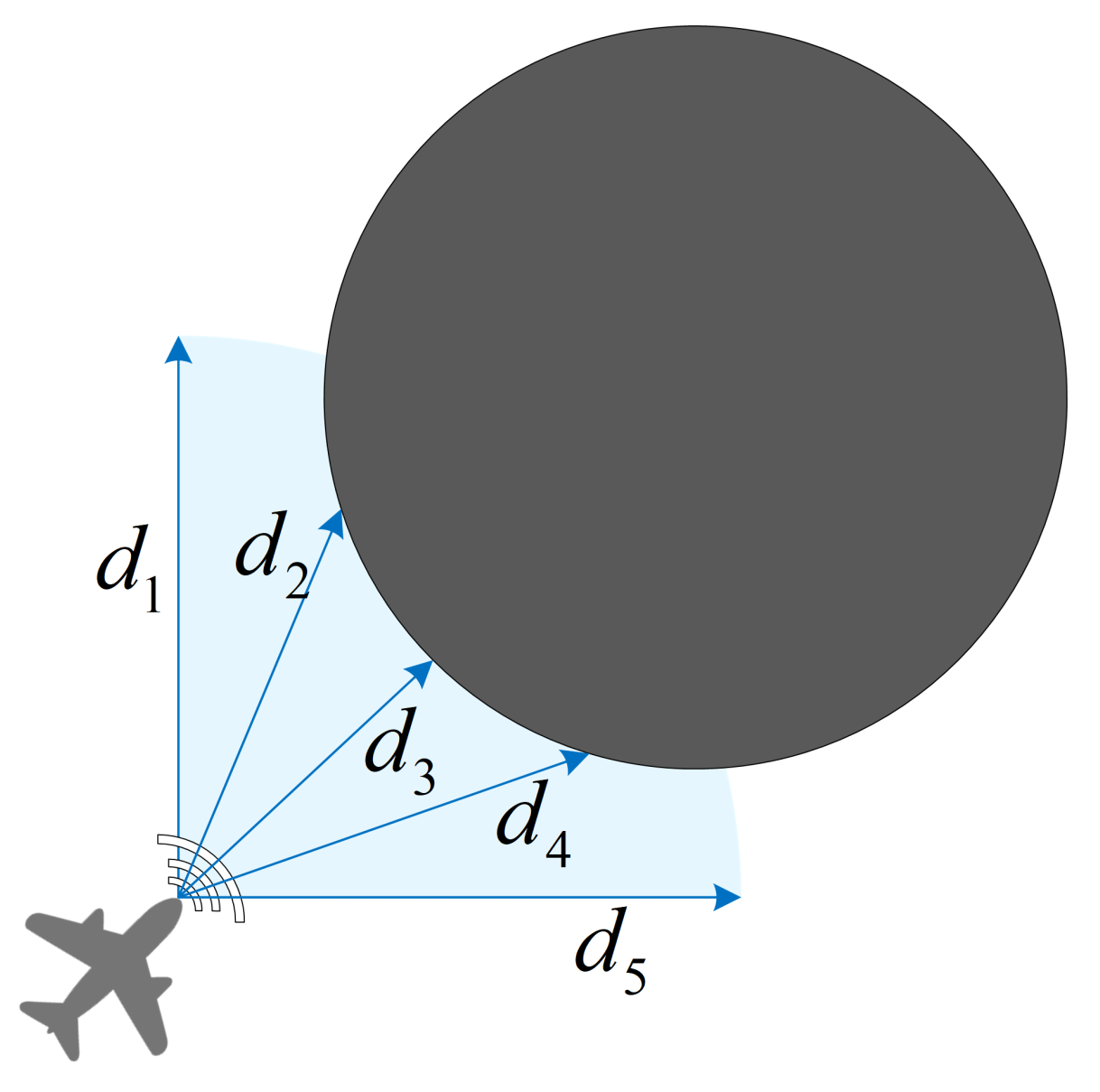

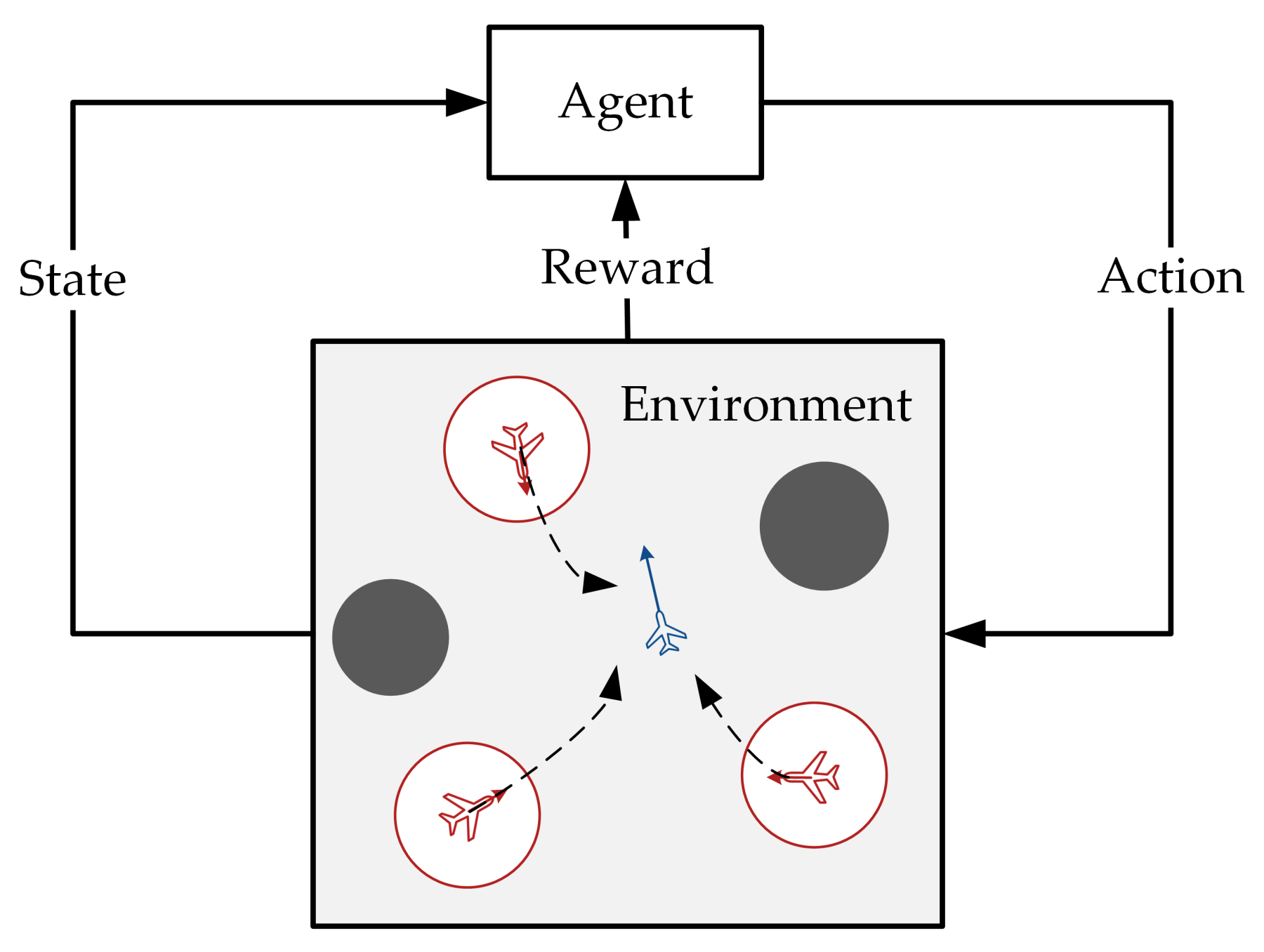
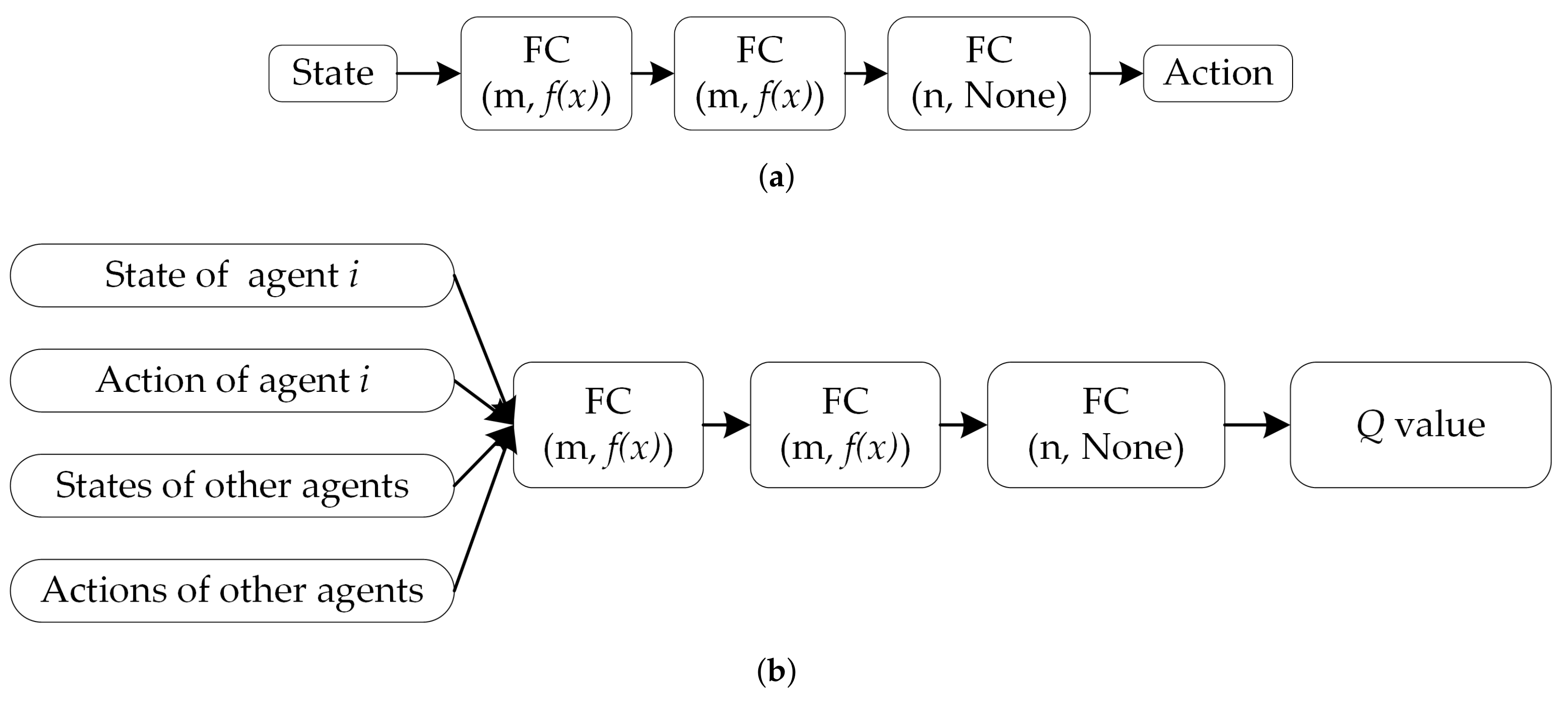



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}