Figure 1.
We used Grad-CAM to visualize our image features on baseline, TSN and SMNet (ours).
Figure 1.
We used Grad-CAM to visualize our image features on baseline, TSN and SMNet (ours).
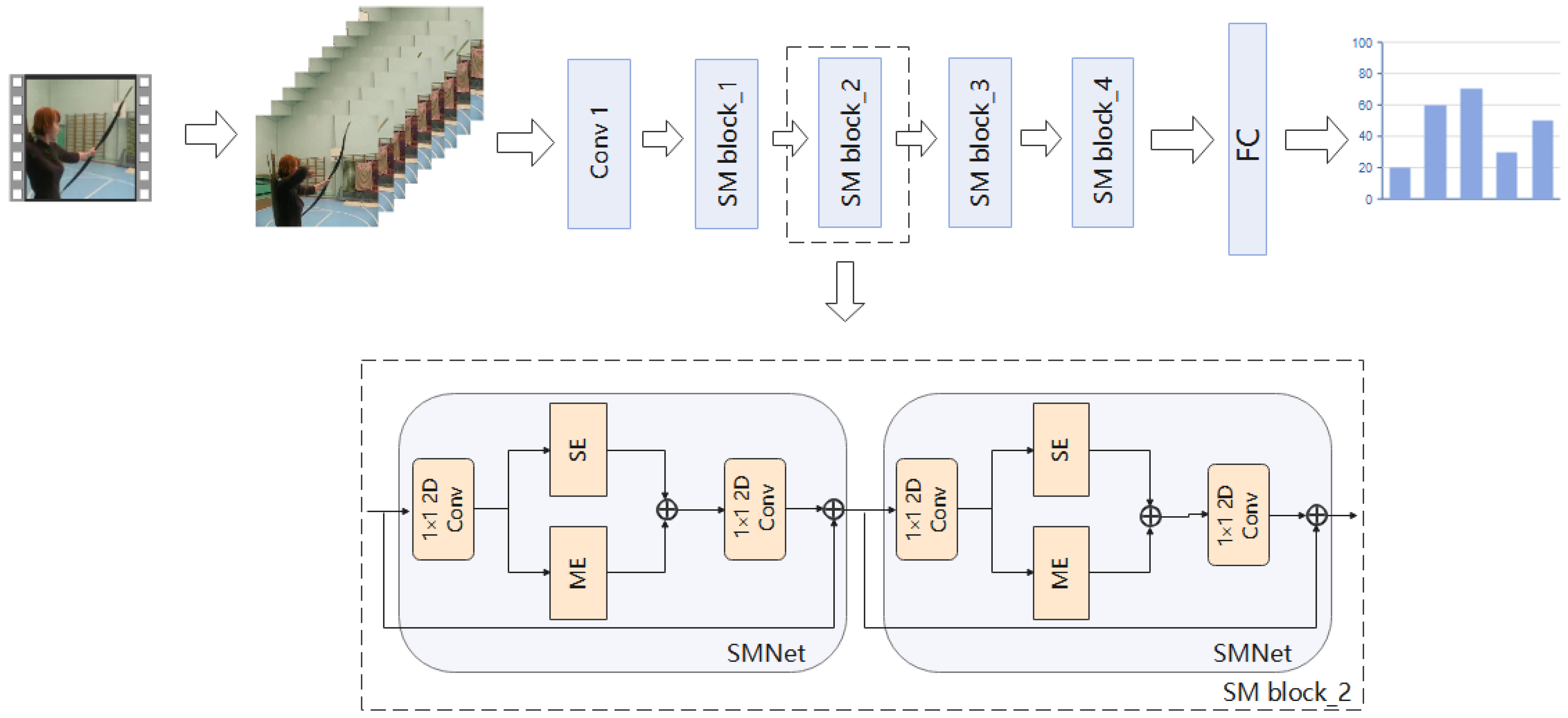
Figure 2.
In the overall model framework. We use the sparse time sampling strategy proposed by TSN to sample the input video. Given a video, we divide it into N segments, and then randomly select a frame from each segment to form an input sequence. In order to model spatio-temporal movements, we have designed the SMNet module. SMNet contains a SE module, which is designed to extract accurate spatio-temporal information, and a ME module, which is designed to extract fine motion information. In order to improve the accuracy of the model, we superimposed several SMNet modules (four SMNet modules were superimposed in the experiment) in the residual block of ResNet-50. Details are given in
Section 4.4 Ablation experiments.
Figure 2.
In the overall model framework. We use the sparse time sampling strategy proposed by TSN to sample the input video. Given a video, we divide it into N segments, and then randomly select a frame from each segment to form an input sequence. In order to model spatio-temporal movements, we have designed the SMNet module. SMNet contains a SE module, which is designed to extract accurate spatio-temporal information, and a ME module, which is designed to extract fine motion information. In order to improve the accuracy of the model, we superimposed several SMNet modules (four SMNet modules were superimposed in the experiment) in the residual block of ResNet-50. Details are given in
Section 4.4 Ablation experiments.
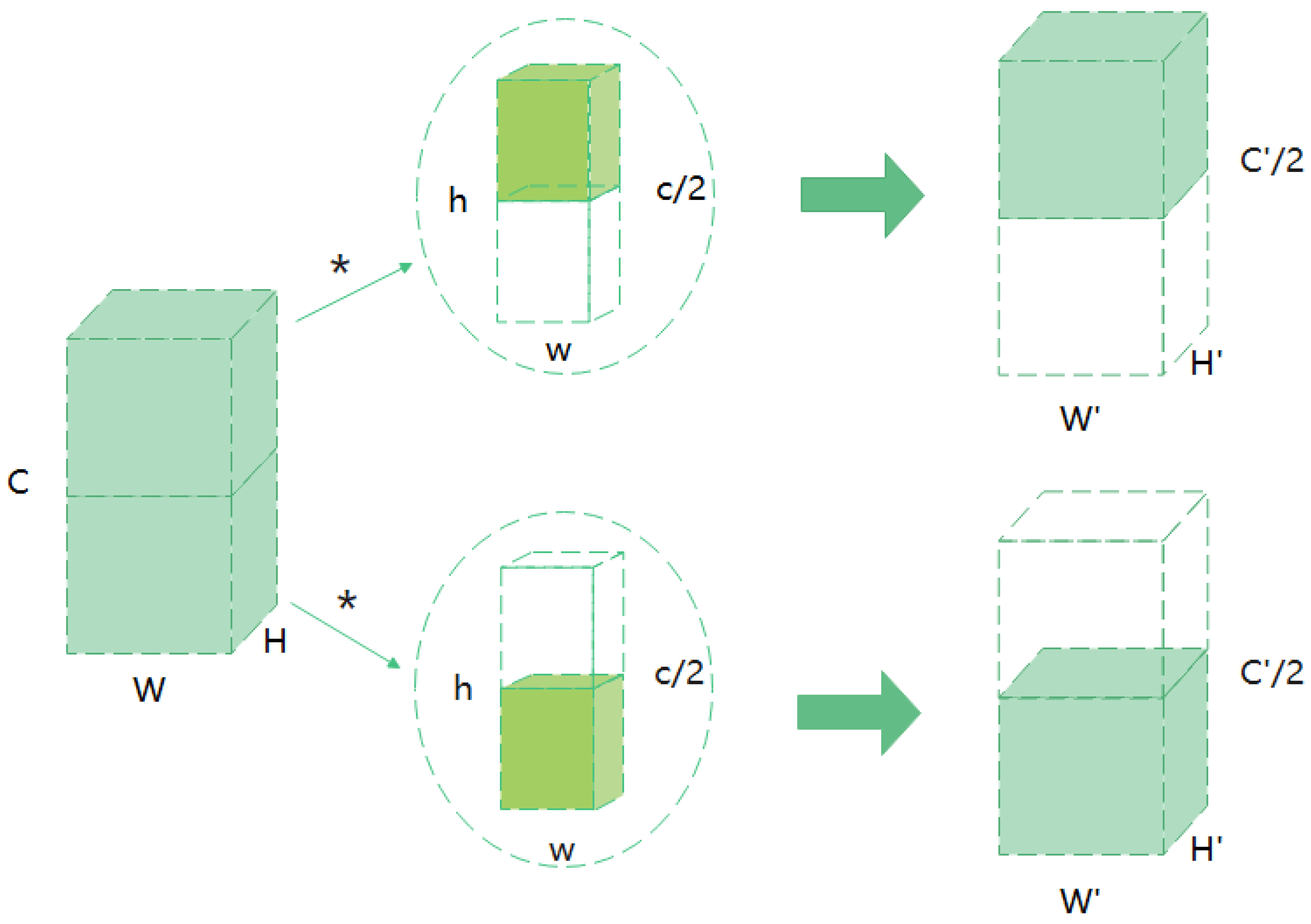
Figure 3.
Structure of group convolution. We group the input feature maps (W × H × C ), and each convolution kernel is divided into groups accordingly. Here both the feature map and the convolution kernel are divided into two groups. Then, we perform convolution calculation to obtain the output data of each group, and then concatenate them. * represents a convolution operation.
Figure 3.
Structure of group convolution. We group the input feature maps (W × H × C ), and each convolution kernel is divided into groups accordingly. Here both the feature map and the convolution kernel are divided into two groups. Then, we perform convolution calculation to obtain the output data of each group, and then concatenate them. * represents a convolution operation.
Figure 4.
Different actions with similar backgrounds.Frisbee Catch and Soccer Penalty.
Figure 4.
Different actions with similar backgrounds.Frisbee Catch and Soccer Penalty.
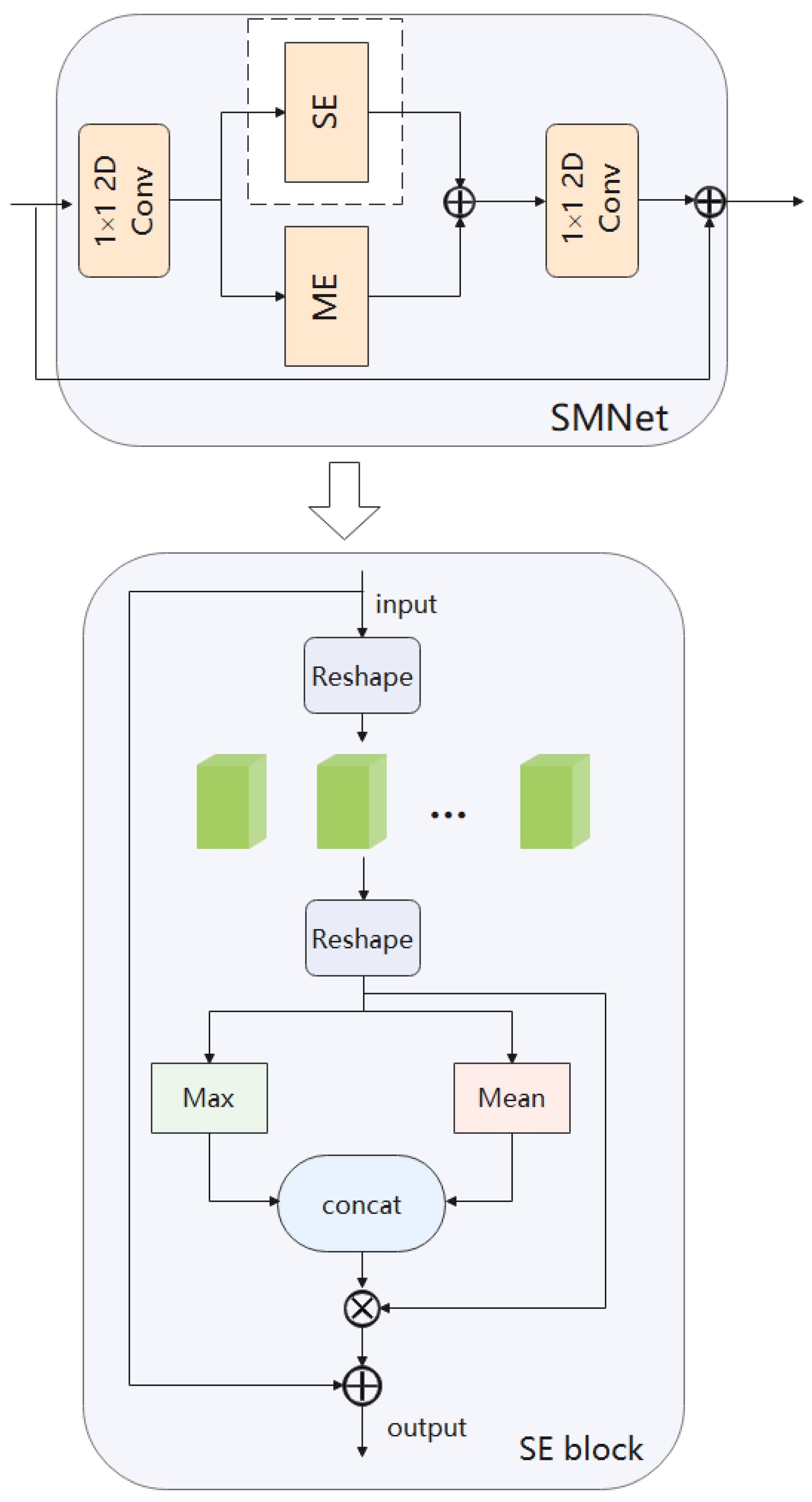
Figure 5.
Spatial attention structure module. We perform average pooling and maximum pooling along the channel direction, and concatenate the two feature maps.
Figure 5.
Spatial attention structure module. We perform average pooling and maximum pooling along the channel direction, and concatenate the two feature maps.
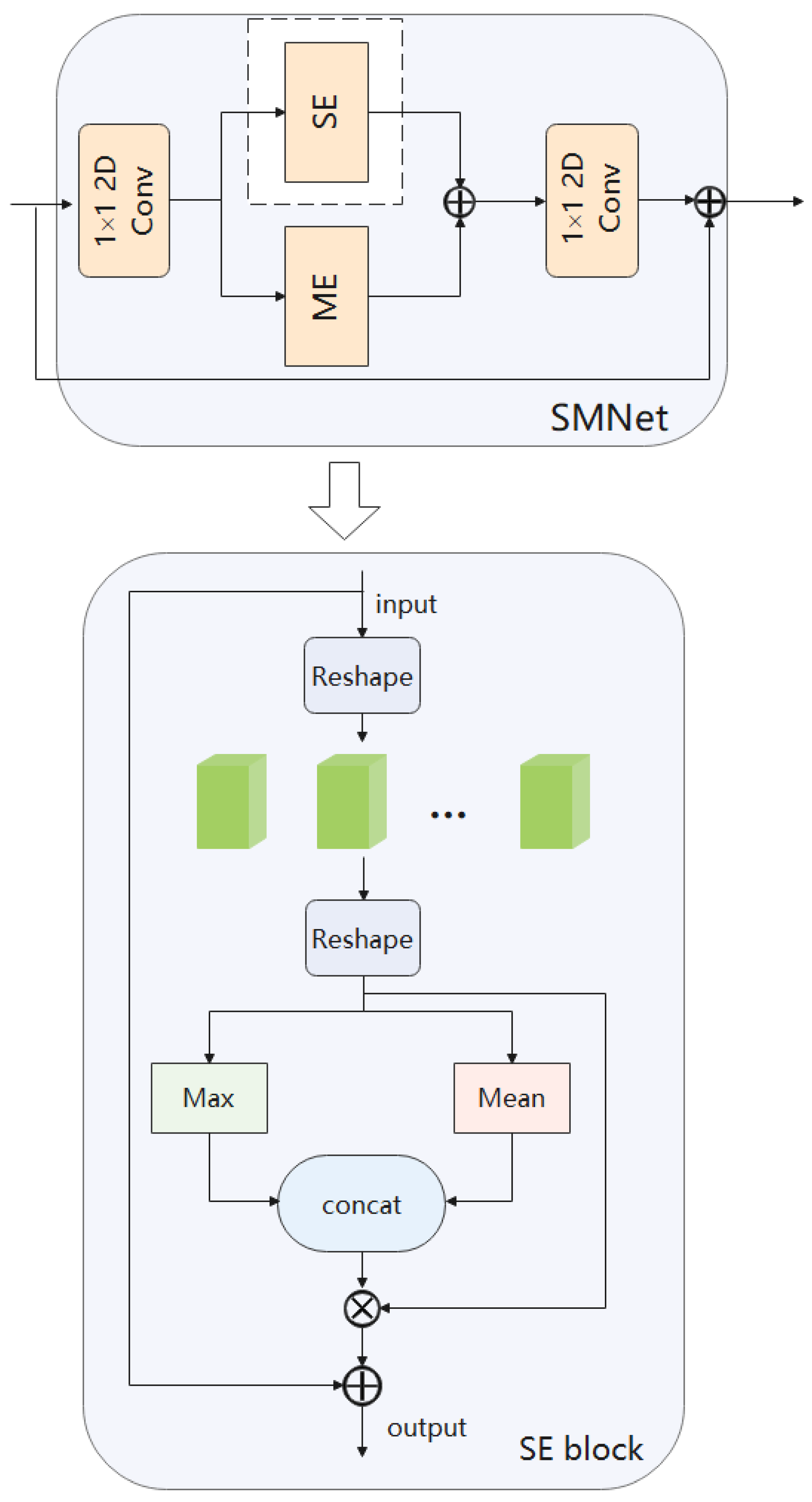
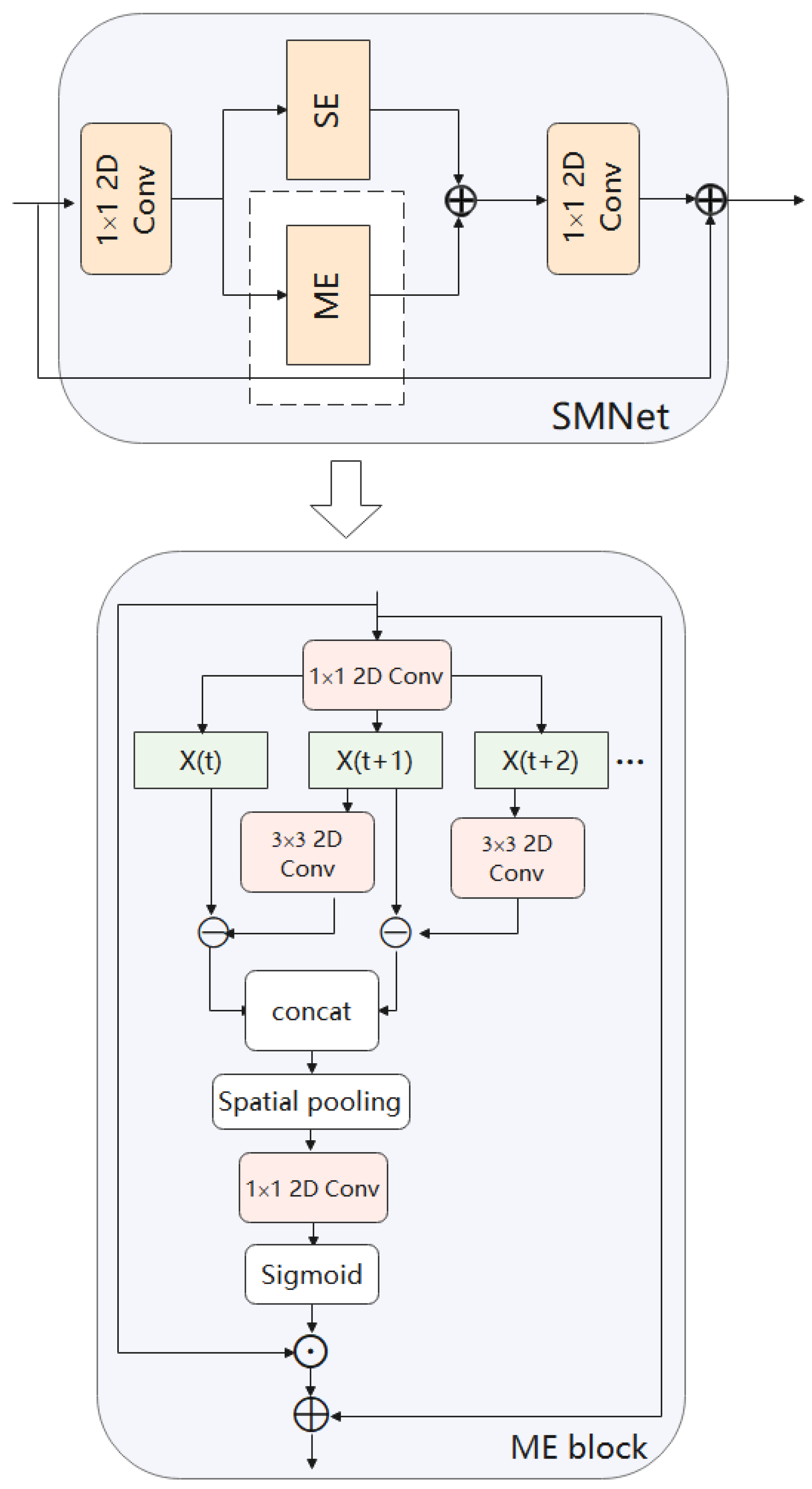
Figure 6.
SE model. Using 1D group convolution acting in the time dimension to fuse information in the time domain. Using an attention mechanism on the spatial domain to learn about relationships on space.
Figure 6.
SE model. Using 1D group convolution acting in the time dimension to fuse information in the time domain. Using an attention mechanism on the spatial domain to learn about relationships on space.
Figure 7.
ME model. Use the difference between frames to represent motion information. In the temporal dimension, a difference operation is performed on two adjacent frames to produce motion representations. Then they are merged along the temporal channel to obtain the motion features.
Figure 7.
ME model. Use the difference between frames to represent motion information. In the temporal dimension, a difference operation is performed on two adjacent frames to produce motion representations. Then they are merged along the temporal channel to obtain the motion features.
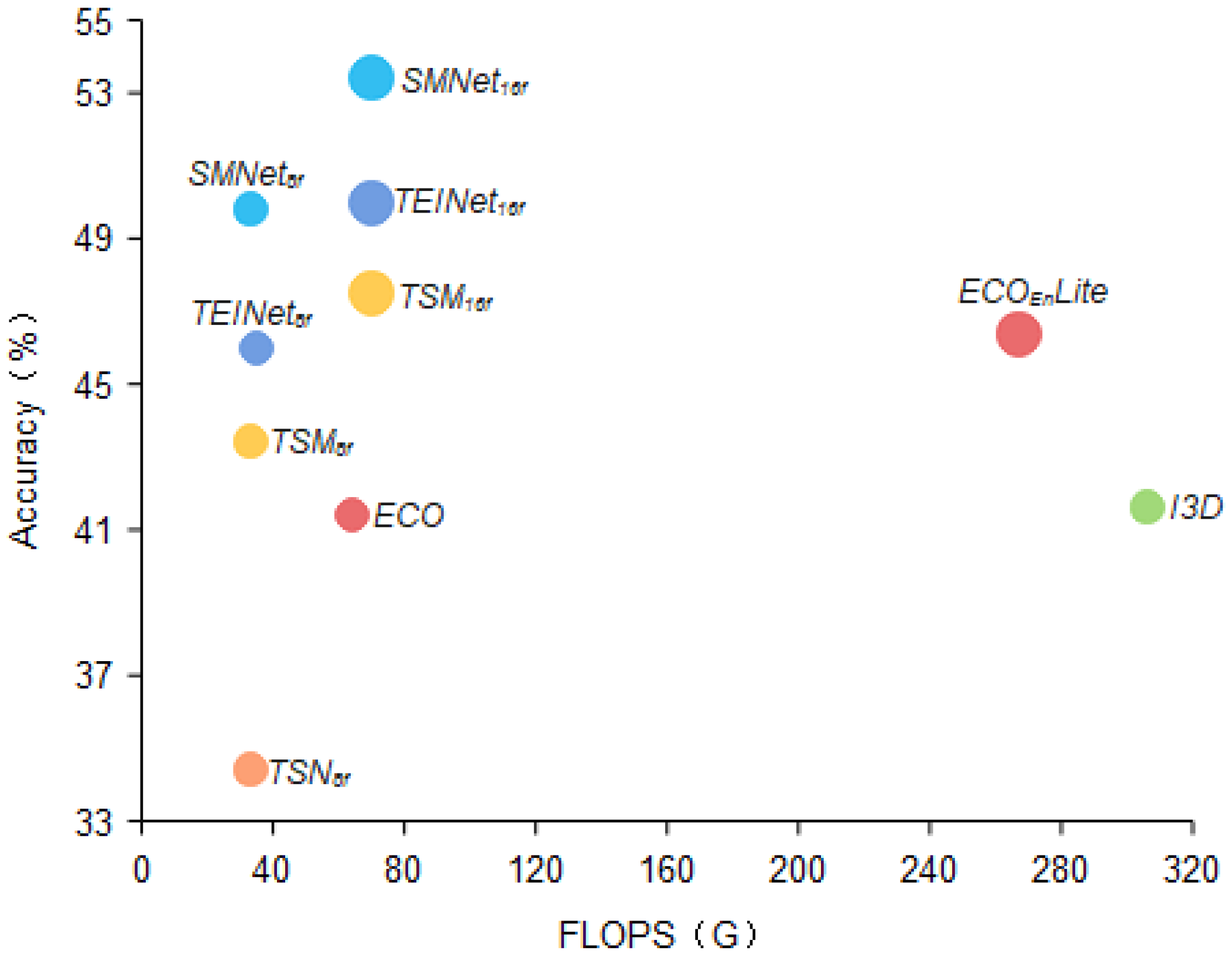
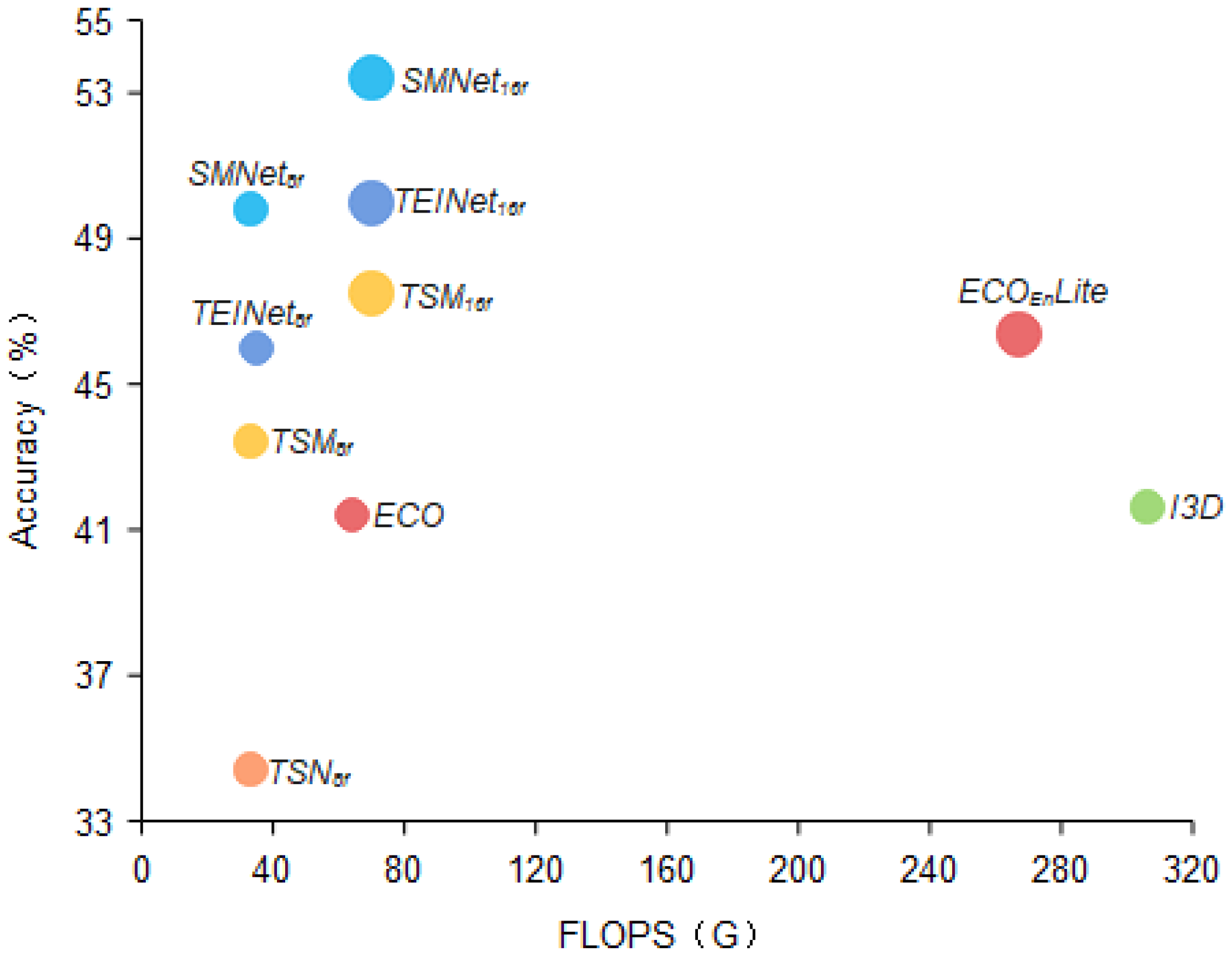
Figure 8.
Video classification performance comparison. We compare in terms of Top-1 accuracy as well as computational cost for the Something-Something V1 dataset. We propose SMNet compares well with TEINet [
11], TSM [
12], ECO [
34], and I3D [
18] in terms of trade-offs between accuracy and efficiency.
Figure 8.
Video classification performance comparison. We compare in terms of Top-1 accuracy as well as computational cost for the Something-Something V1 dataset. We propose SMNet compares well with TEINet [
11], TSM [
12], ECO [
34], and I3D [
18] in terms of trade-offs between accuracy and efficiency.
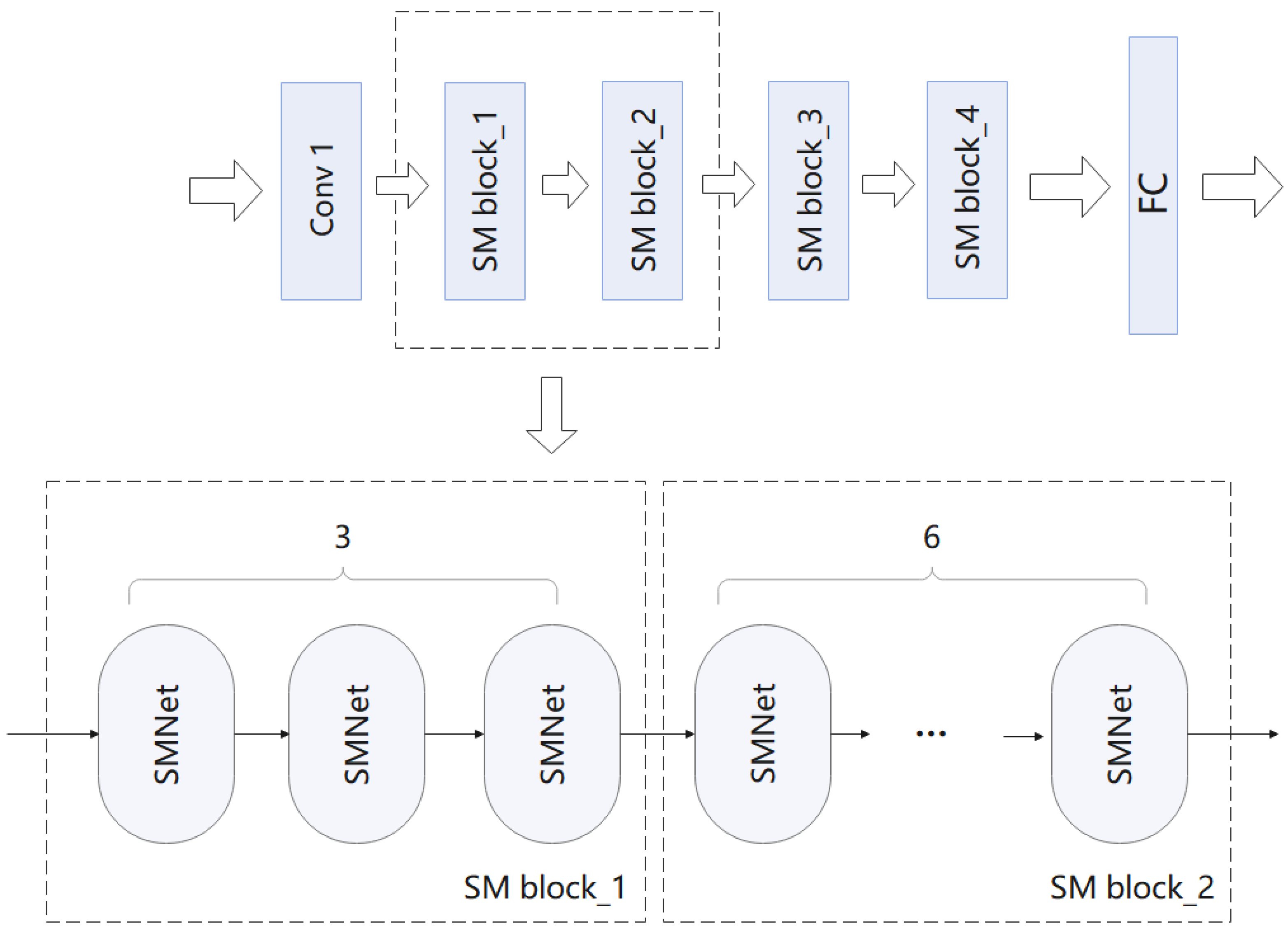
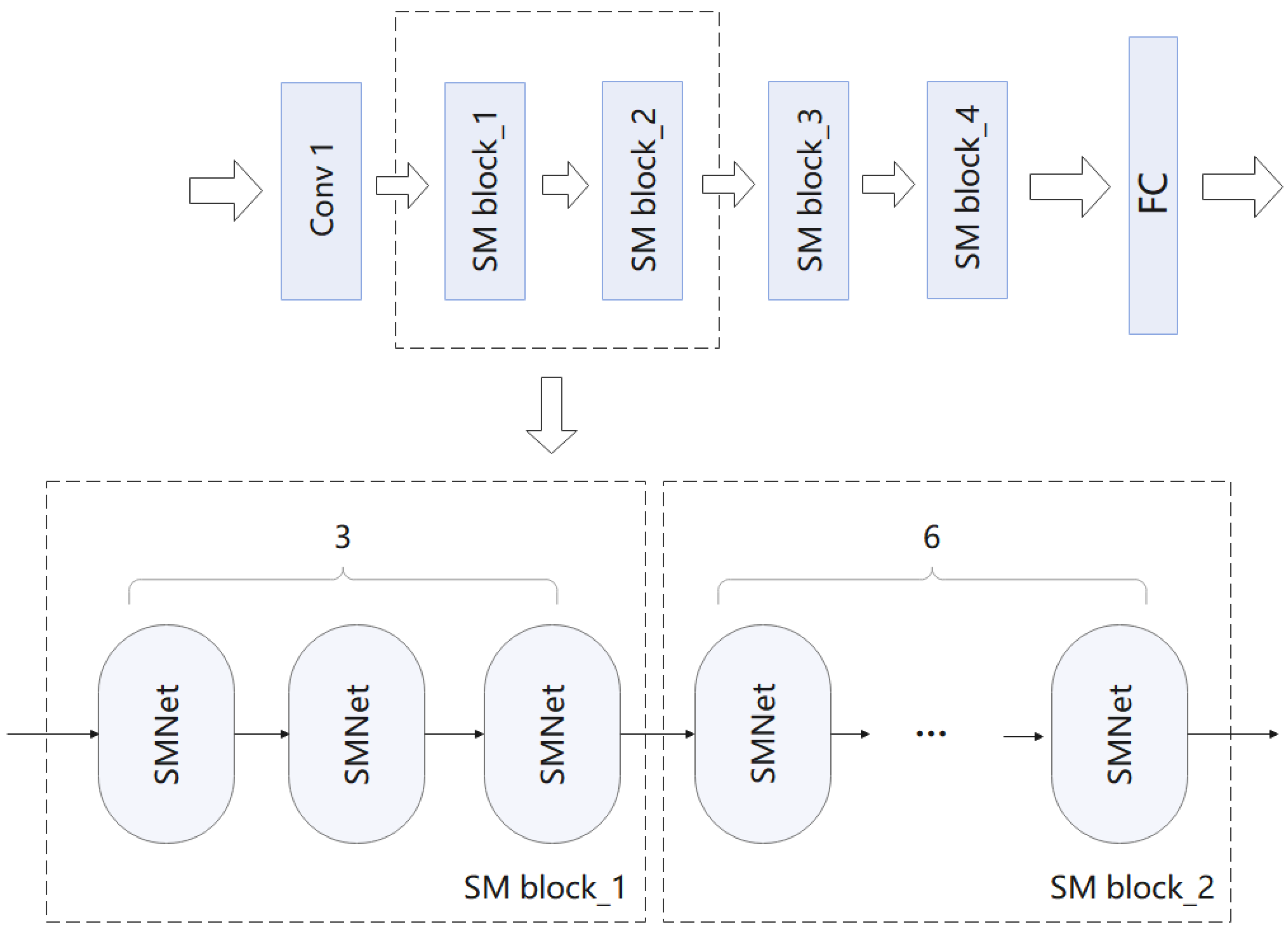
Figure 9.
The way multiple SMNet modules are stacked in ResNet-50.
Figure 9.
The way multiple SMNet modules are stacked in ResNet-50.
Table 1.
With input frames of 8, 16, 8 + 16, we compare with recent 2D action recognition frameworks and some 3D action recognition frameworks on the Something-Something V1 dataset.
Table 1.
With input frames of 8, 16, 8 + 16, we compare with recent 2D action recognition frameworks and some 3D action recognition frameworks on the Something-Something V1 dataset.
| Method | Backbone | Frames | Val Top-1 (%) | Val Top-5 (%) |
|---|
| 2D CNNs: | | | | |
| TSN-RGB [2] | ResNet-50 | 8 | 19.7 | 46.6 |
| TSN-Multiscale [33] | BNInception | 8 | 34.4 | - |
| TSM-RGB [13] | ResNet-50 | 8 | 43.4 | 73.2 |
| TEINet [11] | ResNet-50 | 8 | 47.4 | - |
| STM-RGB [17] | ResNet-50 | 8 | 49.2 | 79.3 |
| TEA [16] | ResNet-50 | 8 | 48.9 | 78.1 |
| SMNet (ours) | ResNet-50 | 8 | 49.8 | 79.6 |
| TSM-RGB [13] | ResNet-50 | 16 | 44.8 | 74.5 |
| TEINet [11] | ResNet-50 | 16 | 49.9 | - |
| STM-RGB [17] | ResNet-50 | 16 | 50.7 | 80.4 |
| TEA [16] | ResNet-50 | 16 | 51.9 | 80.3 |
| ECO [34] | BNInception+3D
ResNet-18 | 16 | 41.4 | - |
| SMNet (ours) | ResNet-50 | 16 | 53.4 | 82.3 |
| TEINet [11] | ResNet-50 | 8 + 16 | 52.2 | - |
| TSM [12] | ResNet-50 | 8 + 16 | 49.7 | 78.5 |
| TANet [35] | ResNet-50 | 8 + 16 | 50.6 | 79.3 |
| ECOEnLite [34] | BNInception+3D
ResNet-18 | 92 | 46.4 | - |
| SMNet (ours) | ResNet-50 | 8 + 16 | 55.2 | 84.3 |
| 3D CNNs: | | | | |
| S3D-G [36] | Inception | 64 | 48.2 | 78.7 |
| I3D [18] | ResNet-50 | 64 | 41.6 | 72.2 |
Table 2.
With input frames of 8, 16, 8 + 16, we compare with recent 2D action recognition frameworks on the Something-Something V2 dataset.
Table 2.
With input frames of 8, 16, 8 + 16, we compare with recent 2D action recognition frameworks on the Something-Something V2 dataset.
| Method | Backbone | Frames | Val Top-1(%) | Val Top-5(%) |
|---|
| TSN-RGB [2] | ResNet-50 | 8 | - | 86.2 |
| TSN-Multiscale [33] | BNInception | 8 | 48.8 | 77.6 |
| TSM [12] | ResNet-50 | 8 | 56.7 | 83.7 |
| TEINet [11] | ResNet-50 | 8 | 61.3 | - |
| STM [17] | ResNet-50 | 8 | 62.3 | 88.8 |
| SMNet (ours) | ResNet-50 | 8 | 63.2 | 87.6 |
| TSM [12] | ResNet-50 | 16 | 58.7 | 84.8 |
| TEINet [11] | ResNet-50 | 16 | 62.1 | - |
| STM [17] | ResNet-50 | 16 | 64.2 | 89.8 |
| TEA [16] | ResNet-50 | 16 | 64.5 | 89.8 |
| SMNet (ours) | ResNet-50 | 16 | 65.7 | 90.1 |
| TEINet [11] | ResNet-50 | 8 + 16 | 65.5 | 89.8 |
| TSM Two-Stream [12] | ResNet-50 | 8 + 16 | 63.5 | 88.6 |
| SmallBigNet [38] | ResNet-50 | 8 + 16 | 63.3 | 88.8 |
| SMNet (ours) | ResNet-50 | 8 + 16 | 67.8 | 91.9 |
Table 3.
With different numbers of input frames, we compare with recent 2D action recognition frameworks and some 3D action recognition frameworks on the Kinetics-400 dataset.
Table 3.
With different numbers of input frames, we compare with recent 2D action recognition frameworks and some 3D action recognition frameworks on the Kinetics-400 dataset.
| Method | Backbone | Frames | Val Top-1(%) | Val Top-5(%) |
|---|
| 2D CNNs: | | | | |
| SmallBigNet [38] | ResNet-50 | 8 × 3 × 10 | 76.3 | 92.5 |
| TEINet [11] | ResNet-50 | 16 × 3 × 10 | 76.2 | 92.5 |
| TEA [16] | ResNet-50 | 16 × 3 × 10 | 76.1 | 92.5 |
| TSM [12] | ResNet-50 | 16 × 3 × 10 | 74.7 | 91.4 |
| TANet [35] | ResNet-50 | 16 × 4 × 3 | 76.9 | 92.9 |
| TSN [2] | InceptionV3 | 25 × 10 × 1 | 72.5 | 90.2 |
| R (2+1) D [39] | ResNet-34 | 32 × 1 × 10 | 74.3 | 91.4 |
| TAM [40] | bLResNet-50 | 48 × 3 × 3 | 73.5 | 91.2 |
| SMNet (ours) | ResNet-50 | 8 × 3 × 10 | 76.1 | 92.7 |
| SMNet (ours) | ResNet-50 | 16 × 3 × 10 | 76.8 | 93.3 |
| 3D CNNs: | | | | |
| SlowOnly [22] | ResNet-50 | 8 × 3 × 10 | 74.8 | 91.6 |
| ARTNet [41] | ResNet-18 | 16 × 10 × 25 | 70.7 | 89.3 |
| NL I3D [32] | ResNet-50 | 128 × 3 × 10 | 76.5 | 92.6 |
| CorrNet [37] | ResNet-50 | 32 × 1 × 10 | 77.2 | - |
| S3D-G [36] | InceptionV1 | 64 × 3 × 10 | 74.7 | 93.4 |
Table 4.
With input frames 8 + 16. We have compared this with the state-of-the-art transformer model on the Something-Something V2 dataset.
Table 4.
With input frames 8 + 16. We have compared this with the state-of-the-art transformer model on the Something-Something V2 dataset.
| Method | Pretrain | Val Top-1(%) | Val Top-5(%) |
|---|
| VidTr-L [42] | IN-21K+K-400 | 60.2 | - |
| Tformer-L [43] | IN-21K | 62.5 | - |
| ViViT-L [44] | RIN-21K+K-400 | 65.4 | 89.8 |
| MViT-B [45] | K-400 | 67.1 | 90.8 |
| Mformer [46] | IN-21K+K-400 | 66.5 | 90.1 |
| Mformer-L [46] | IN-21K+K-400 | 68.1 | 91.2 |
| Mformer-HR [46] | IN-21K+K-400 | 67.1 | 90.6 |
| SMNet (ours) | ImgNet | 67.8 | 91.9 |
Table 5.
The calculation amount of the model and the comparison of parameters on Something-Something V1 dataset.
Table 5.
The calculation amount of the model and the comparison of parameters on Something-Something V1 dataset.
| Method | Backbone | Frames | FLOPs | Param |
|---|
| TSN [2] | ResNet-50 | 8 | 33 G | 24.3 M |
| TSM [12] | ResNet-50 | 8 | 32.9 G | 23.9 M |
| STM [17] | ResNet-50 | 8 | 33.3 G | 24.0 M |
| ECO [34] | BNInception+3D ResNet-18 | 16 | 64 G | 47.5 M |
| ECOEnLite [34] | BNInception+3D ResNet-18 | 92 | 267 G | 150 M |
| I3D [6] | ResNet-50 | 64 | 306 G | 28.0 M |
| SMNet (ours) | ResNet-50 | 8 | 33.1 G | 23.9 M |
Table 6.
Comparative results of random and sparse sampling. We conduct experiments on the Something-Something V1 dataset. For random sampling, we sampled 8 frames in the whole segment. For sparse sampling, we divide the video equally into 8 segments and sample each segment randomly.
Table 6.
Comparative results of random and sparse sampling. We conduct experiments on the Something-Something V1 dataset. For random sampling, we sampled 8 frames in the whole segment. For sparse sampling, we divide the video equally into 8 segments and sample each segment randomly.
| Sampling Strategy | Number of Segments | Number of Input
Sequence Frames | Val Top-1 (%) |
|---|
| Random sampling | 1 | 8 | 45.7 |
| Sparse sampling | 8 | 8 | 49.8 |
Table 7.
Test the module in different positions of ResNet on the Something-Something V2 dataset. The SMNet module is inserted into the residual block, the and residual blocks, the , and residual blocks and the , , and residual blocks of ResNet to compare the impact of the insertion position and the number of modules inserted on the accuracy.
Table 7.
Test the module in different positions of ResNet on the Something-Something V2 dataset. The SMNet module is inserted into the residual block, the and residual blocks, the , and residual blocks and the , , and residual blocks of ResNet to compare the impact of the insertion position and the number of modules inserted on the accuracy.
| Stage | Top-1 (%) | Top-5 (%) |
|---|
| baseline | 60.5 | 85.3 |
| 61.1 | 85.7 |
| 61.5 | 86.3 |
| 62.1 | 86.8 |
| 63.2 | 87.6 |
Table 8.
We inserted different numbers of SMNet blocks at different locations. At one stage we replaced all the ResNet blocks with a different number of SMNet modules, the other stages remained the same.
Table 8.
We inserted different numbers of SMNet blocks at different locations. At one stage we replaced all the ResNet blocks with a different number of SMNet modules, the other stages remained the same.
| Stage | Number of the SMNets | Val Top-1(%) |
|---|
| 3 | 61.1 |
| 4 | 61.3 |
| 6 | 61.9 |
| 3 | 61.5 |
| 16 | 63.2 |
Table 9.
Compare the fusion strategies between modules on the Something-Something V2 dataset. Operate the SE and ME modules in parallel and in series respectively to compare accuracy.
Table 9.
Compare the fusion strategies between modules on the Something-Something V2 dataset. Operate the SE and ME modules in parallel and in series respectively to compare accuracy.
| Fusion Strategy | Top-1 (%) | Top-5 (%) |
|---|
| serial | 61.7 | 86.9 |
| parallel | 63.2 | 87.6 |
Table 10.
Experiment on the number of groups of group convolution on the Something-Something V2 dataset.
Table 10.
Experiment on the number of groups of group convolution on the Something-Something V2 dataset.
| Group Number | FLOPs | Top-1 (%) | Top-5 (%) |
|---|
| 2 | 33.4 G | 62.8 | 87.1 |
| 4 | 33.1 G | 63.2 | 87.6 |
| 6 | 33.1 G | 63.1 | 87.4 |
| 8 | 33.1 G | 62.9 | 87.5 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}