
Multi-Sensor Vibration Signal Based Three-Stage Fault Prediction for Rotating Mechanical Equipment

Abstract
:1. Introduction
- More formative vibration signals, used for training the fault prediction model, are collected from multiple sensors to improve the accuracy of the prediction method;
- Deep features of varies degradation periods and fault types can be extracted by CNN and LSTM automatically without relying on manual intervention and professional knowledge;
- The degradation period and fault type can be predicted simultaneously in advance with high accuracy.
2. Problem Formulation and Main Fault Prediction Framework
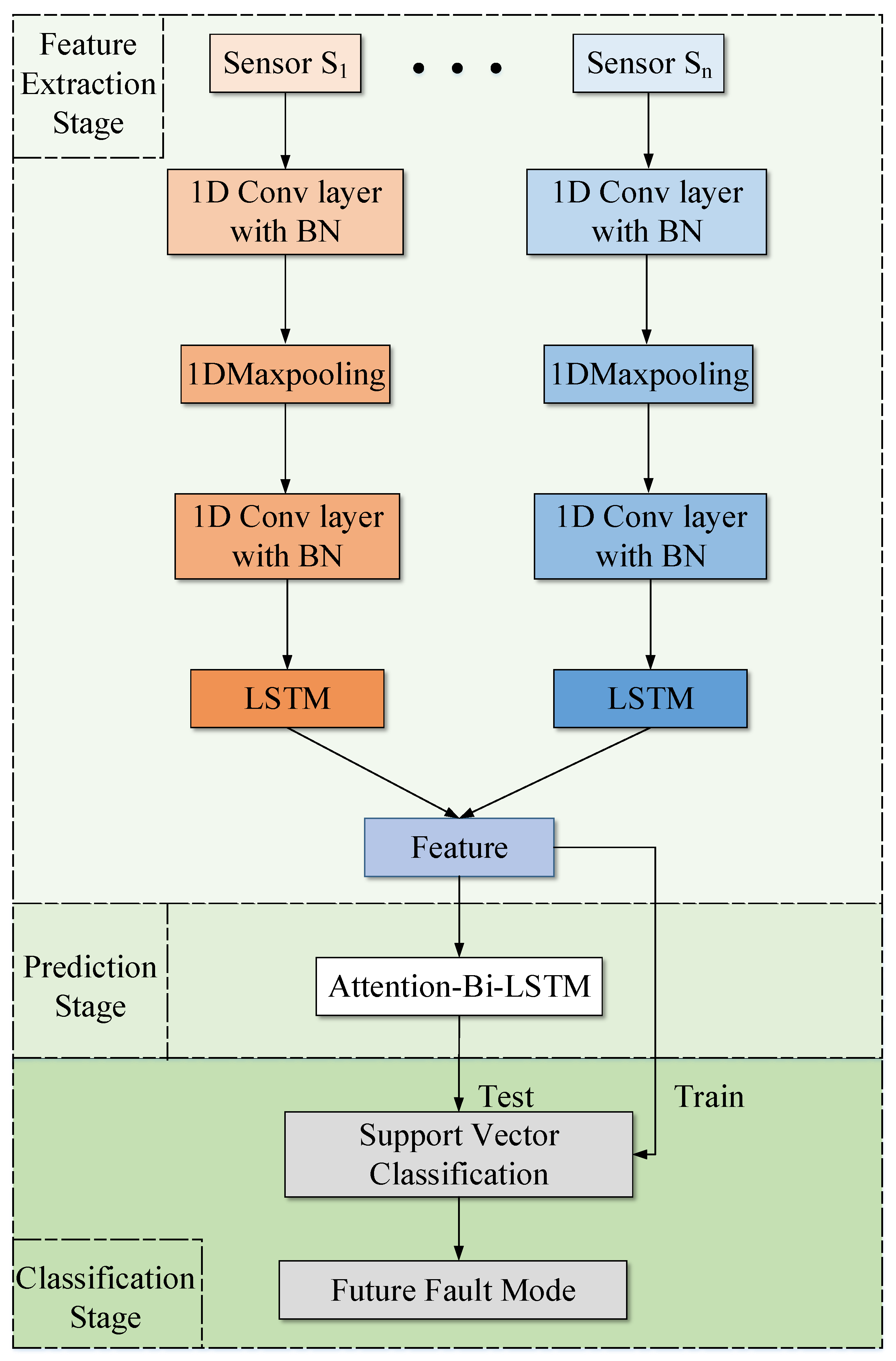
- In the feature extraction stage, the original vibration signals collected by multiple sensors are sent to the CNN-LSTM network for the extraction of spatiotemporal features, which contain operating status information;
- In the prediction stage, the attention-Bi-LSTM is trained to predict the trend of the features;
- In the classification stage, based on the spatiotemporal features and their trends, the SVC model is formulated to identify the degradation period and the future fault type.
3. Deep Learning Network-Based Three-Stage Fault Prediction
3.1. Feature Extraction Stage
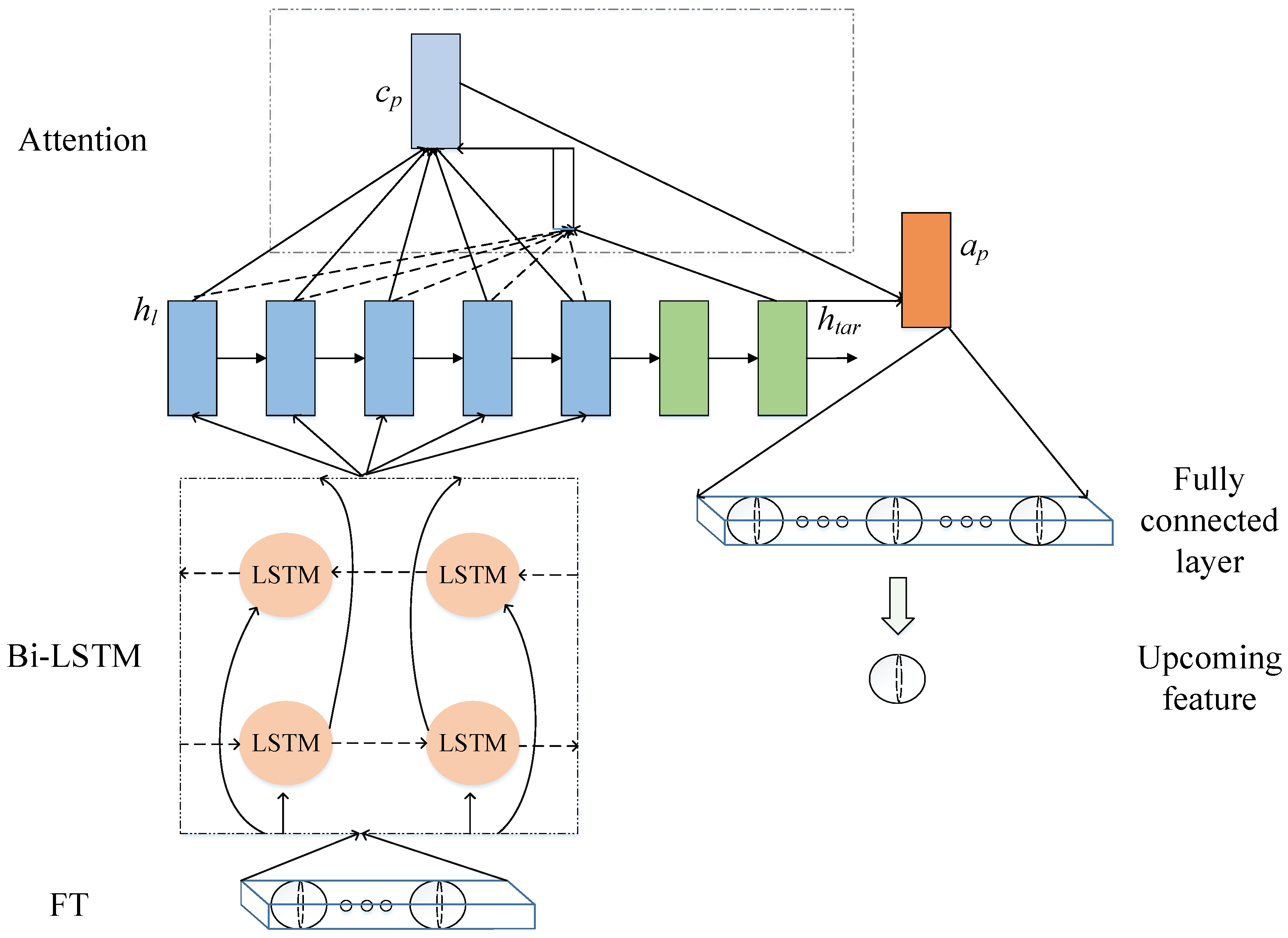
3.2. Prediction Stage
3.3. Classification Stage
3.4. Implementing the Proposed Fault Prediction Strategy
| Algorithm 1 Fault prediction algorithm |
|
4. Validating the Proposed Method
4.1. The Description of the Dataset
4.2. Feature Extraction
4.2.1. Training Process
4.2.2. Verifying the Validity of the Feature Extraction Model
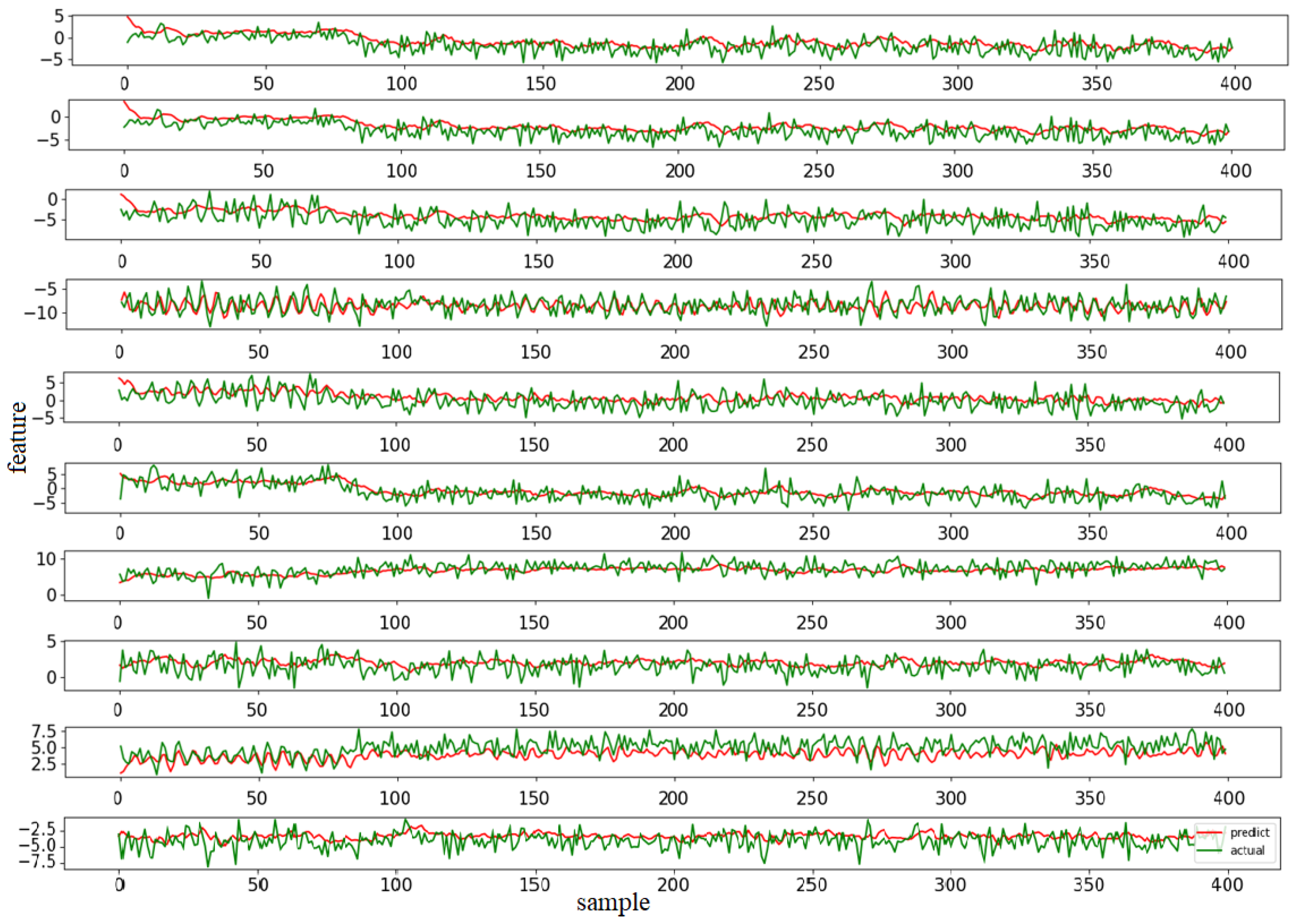
4.3. Trend Prediction
4.3.1. Training Process
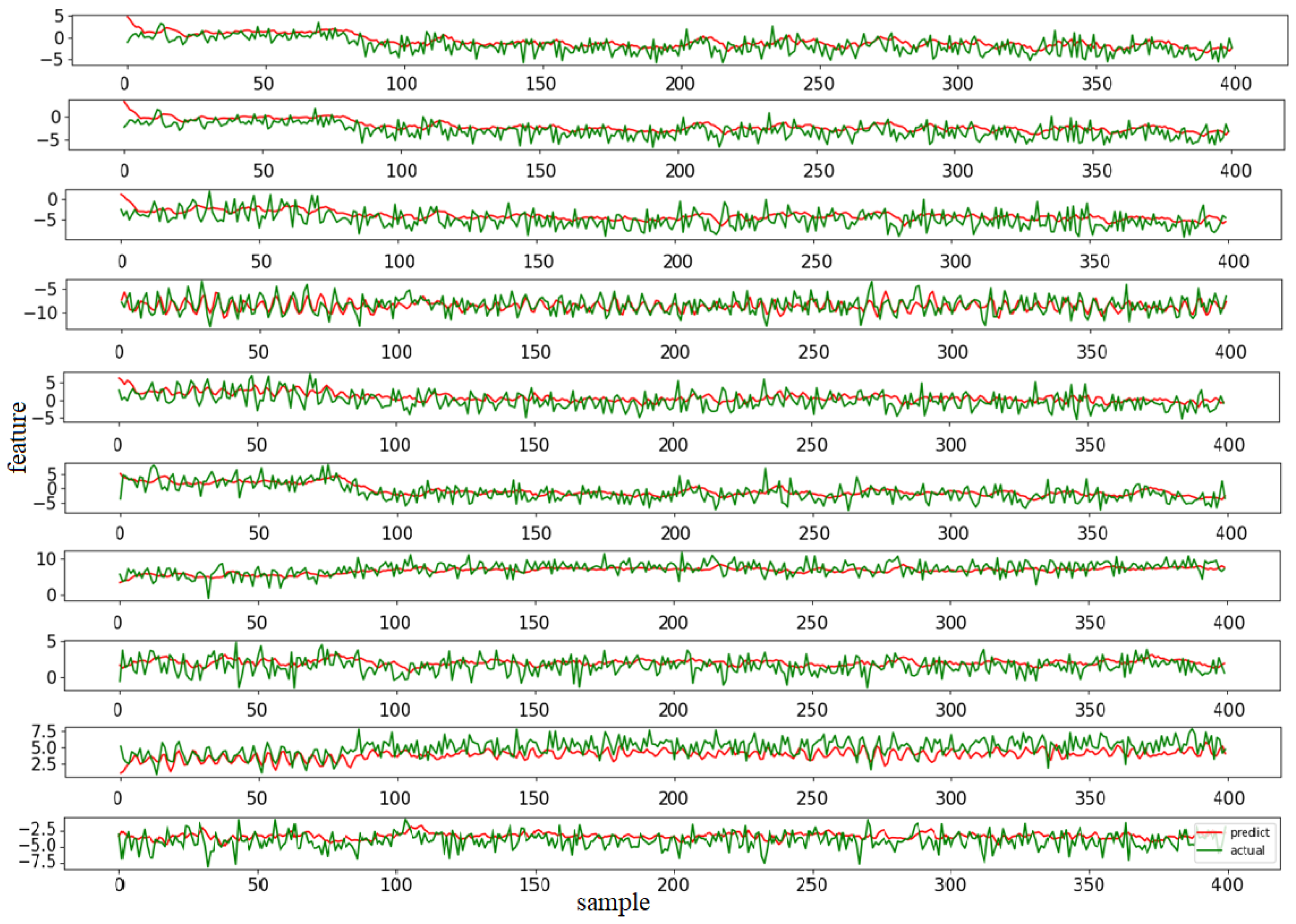
4.3.2. Testing Results
4.3.3. Comparison with Other Models
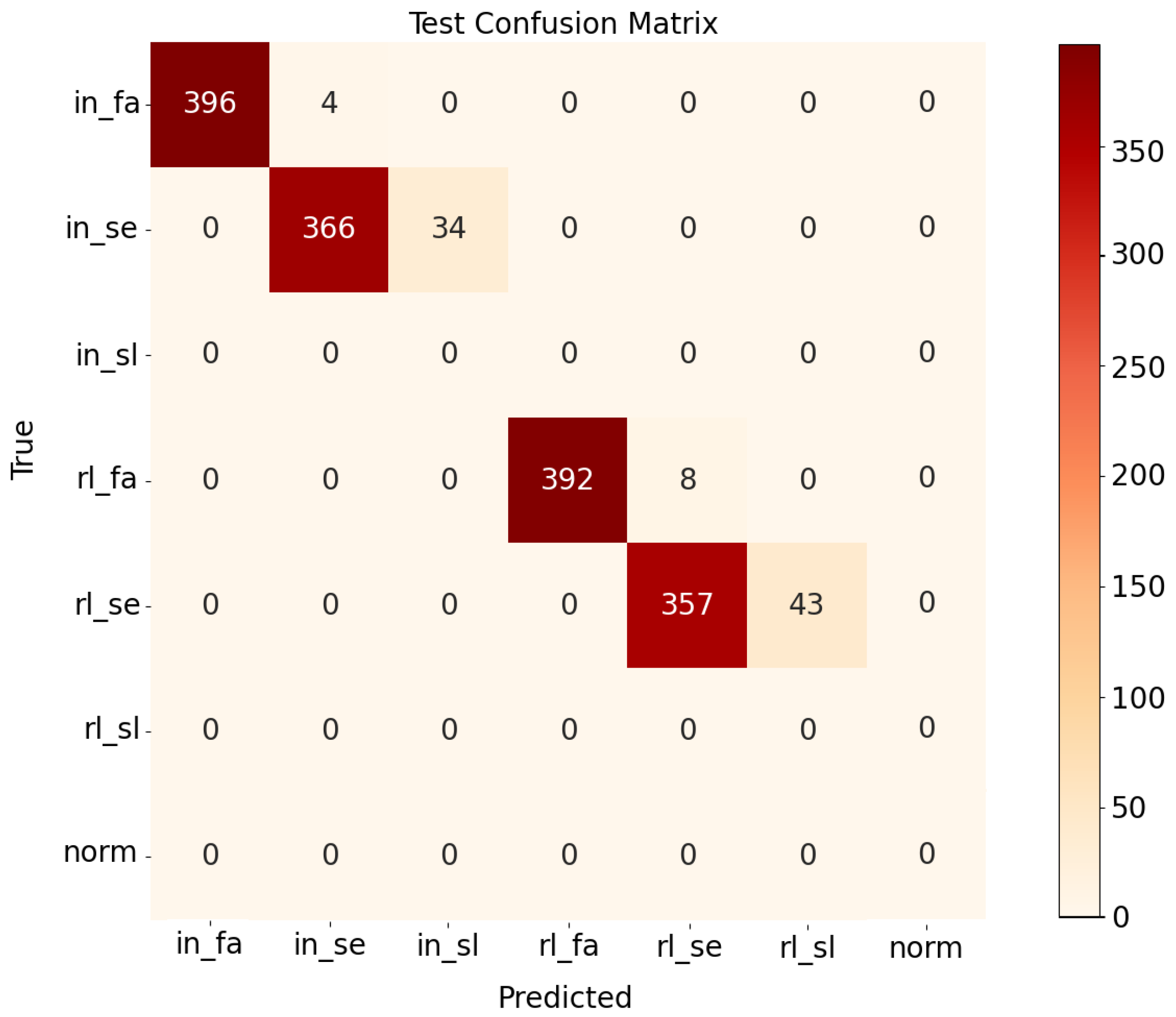
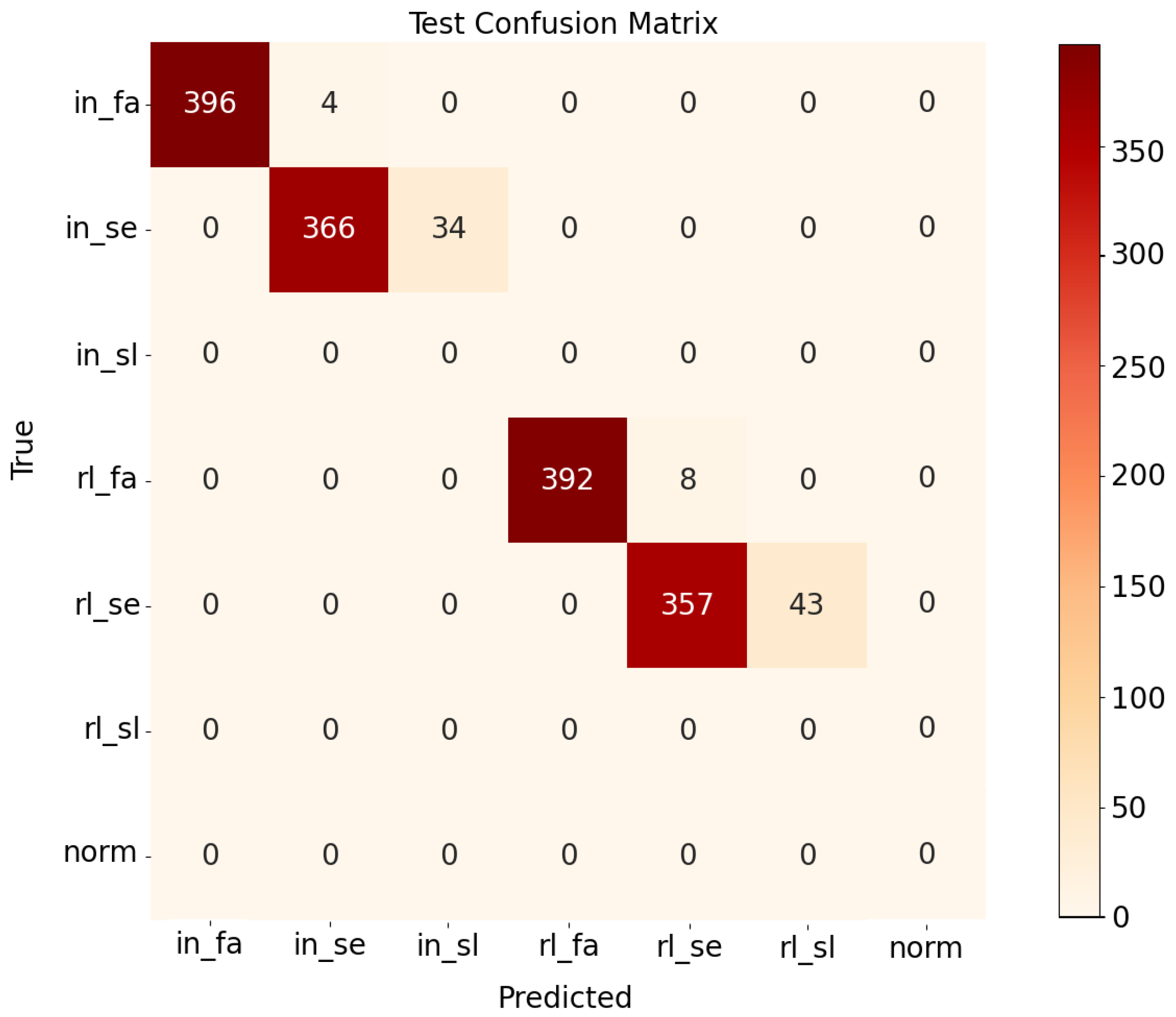
4.4. Classification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Baraldi, P.; Di Maio, F.; Zio, E. Unsupervised clustering for fault diagnosis in nuclear power plant components. Int. J. Comput. Intell. Syst. 2013, 6, 764–777. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Bartlett, E.B. Nuclear power plant fault diagnosis using neural networks with error estimation by series association. IEEE Trans. Nucl. Sci. 1996, 43, 2373–2388. [Google Scholar]
- Gong, Y.; Su, X.; Qian, H.; Yang, N. Research on fault diagnosis methods for the reactor coolant system of nuclear power plant based on DS evidence theory. Ann. Nucl. Energy 2018, 112, 395–399. [Google Scholar] [CrossRef]
- Lu, B.; Upadhyaya, B.R. Monitoring and fault diagnosis of the steam generator system of a nuclear power plant using data-driven modeling and residual space analysis. Ann. Nucl. Energy 2005, 32, 897–912. [Google Scholar] [CrossRef]
- Rai, V.K.; Mohanty, A.R. Bearing fault diagnosis using FFT of intrinsic mode functions in Hilbert–Huang transform. Mech. Syst. Signal Process. 2007, 21, 2607–2615. [Google Scholar] [CrossRef]
- Fakhfakh, T.; Bartelmus, W.; Chaari, F.; Zimroz, R.; Haddar, M. Condition Monitoring of Machinery in Non-Stationary Operations; STFT Based Approach for Ball Bearing Fault Detection in a Varying Speed Motor; Springer: Berlin/Heidelberg, Germany, 2012; pp. 41–50. [Google Scholar]
- Chen, J.; Li, Z.; Pan, J.; Chen, G.; Zi, Y.; Yuan, J.; Chen, B.; He, Z. Wavelet transform based on inner product in fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2016, 70, 1–35. [Google Scholar] [CrossRef]
- Eren, L.; Ince, T.; Kiranyaz, S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, S.; Jin, B. Sequential fault diagnosis based on LSTM neural network. IEEE Access 2018, 6, 12929–12939. [Google Scholar] [CrossRef]
- Qiao, M.; Yan, S.; Tang, X.; Xu, C. Deep convolutional and LSTM recurrent neural networks for rolling bearing fault diagnosis under strong noises and variable loads. IEEE Access 2020, 8, 66257–66269. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, D.; Peng, X. A review: Prognostics and health management. J. Electron. Meas. Instrum. 2010, 24, 1–9. [Google Scholar] [CrossRef]
- Liu, J.; Wang, W.; Ma, F.; Yang, Y.B.; Yang, C.S. A data-model-fusion prognostic framework for dynamic system state forecasting. Eng. Appl. Artif. Intell. 2012, 25, 814–823. [Google Scholar] [CrossRef] [Green Version]
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A model-based method for remaining useful life prediction of machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- Ren, L.; Sun, Y.; Wang, H.; Zhang, L. Prediction of bearing remaining useful life with deep convolution neural network. IEEE Access 2018, 6, 13041–13049. [Google Scholar] [CrossRef]
- Xia, M.; Li, T.; Shu, T.; Wan, J.; De Silva, C.W.; Wang, Z. A two-stage approach for the remaining useful life prediction of bearings using deep neural networks. IEEE Trans. Ind. Inform. 2018, 15, 3703–3711. [Google Scholar] [CrossRef]
- Xu, W.; Liu, W.B.; Zhou, M.; Yang, J.F.; Xing, C.H. Application of Neural Network Model for Grey Relational Analysis in Bearing Fault Prediction. Bearing 2012. [Google Scholar] [CrossRef]
- Xu, H.; Ma, R.; Yan, L.; Ma, Z. Two-stage prediction of machinery fault trend based on deep learning for time series analysis. Digit. Signal Process. 2021, 117, 103150. [Google Scholar] [CrossRef]
- Park, J.W.; Sim, S.H.; Jung, H.J. Displacement estimation using multimetric data fusion. IEEE/ASME Trans. Mechatron. 2013, 18, 1675–1682. [Google Scholar] [CrossRef]
- Olofsson, B.; Antonsson, J.; Kortier, H.G.; Bernhardsson, B.; Robertsson, A.; Johansson, R. Sensor fusion for robotic workspace state estimation. IEEE/ASME Trans. Mechatron. 2015, 21, 2236–2248. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Tang, Y. Deep learning using linear support vector machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- The Bearing Dataset was Provided by the Center for Intelligent Maintenance Systems (IMS), University of Cincinnati. Available online: https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/ (accessed on 2 November 2021).
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on rolling element bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Hong, S.; Zhou, Z.; Zio, E.; Hong, K. Condition assessment for the performance degradation of bearing based on a combinatorial feature extraction method. Digit. Signal Process. 2014, 27, 159–166. [Google Scholar] [CrossRef]
- Yan, M.; Xie, L.; Muhammad, I.; Yang, X.; Liu, Y. An effective method for remaining useful life estimation of bearings with elbow point detection and adaptive regression models. ISA Trans. 2021. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Bearing | Fault Type | Sensor Number |
|---|---|---|---|
| 1-1 | - | 2 | |
| dataset1 | 1-2 | - | 2 |
| 1-3 | inner race defect | 2 | |
| 1-4 | roller element defect | 2 |
| File Numbers | Period | Norm | Slight | Severe | Failure |
|---|---|---|---|---|---|
| Bearing | |||||
| 1-3 H | 1–1850 | 1851–2119 | 2120–2151 | 2152–2156 | |
| 1-3 V | 1–1850 | 1851–2119 | 2120–2151 | 2152–2156 | |
| 1-4 H | 1–1600 | 1601–2128 | 2129–2151 | 2152–2156 | |
| 1-4 V | 1–1600 | 1601–2128 | 2129–2151 | 2152–2156 | |
| Layer | Type | Kernel Size/Stride/Numbers | Activation Function | Padding | BN |
|---|---|---|---|---|---|
| 1-1 | Sensor H | - | - | - | N |
| 1-2 | Sensor V | - | - | - | N |
| 2-1 | 1D Convolution | 64/16/16 | RELU | same | Y |
| 2-2 | 1D Convolution | 64/16/16 | RELU | same | Y |
| 3-1 | 1D Maxpooling | 2/2 | - | valid | N |
| 3-2 | 1D Maxpooling | 2/2 | - | valid | N |
| 4-1 | 1D Convolution | 32/8/32 | RELU | same | Y |
| 4-2 | 1D Convolution | 32/8/32 | RELU | same | Y |
| 5-1 | LSTM | 100 | Tanh/Sigmoid | - | N |
| 5-2 | LSTM | 100 | Tanh/Sigmoid | - | N |
| 6-1 | LSTM | 40 | Tanh/Sigmoid | - | N |
| 6-2 | LSTM | 40 | Tanh/Sigmoid | - | N |
| 7 | Concatenate | - | - | - | N |
| 8 | Dense1 | 128 | - | - | N |
| 9 | Dense2 | 10(feature) | - | - | N |
| 10 | Softmax | - | - | - | N |
| 11 | Cross-entropy | - | - | - | N |
| Sensor Type | Accuracy |
|---|---|
| Sensor H | 0.892 |
| Sensor V | 0.832 |
| Sensor H and Sensor V | 0.928 |
| Layer | Units | Activation Function |
|---|---|---|
| Input | - | - |
| Bi-LSTM | 100 | Tanh/Sigmoid |
| Attention | - | - |
| Dense | 75 | RELU |
| Dense | 1 | - |
| Input | RMSE |
|---|---|
| Three inputs | 2.221 |
| Six inputs | 1.818 |
| Nine inputs | 1.906 |
| Algorithm | RMSE |
|---|---|
| LSTM | 1.875 |
| Bi-LSTM | 1.828 |
| Attention-LSTM | 1.838 |
| Attention-Bi-LSTM | 1.818 |
| Window Size × the Number of Windows | The Accuracy of Fault Mode Prediction | Sampling Time (s) | Fault Prediction Time (s) |
|---|---|---|---|
| 4096 × 5 | 0.8 | 0.2 | 0.244 |
| 2048 × 10 | 0.86 | 0.1 | 0.248 |
| 256 × 80 | 0.944 | 0.0125 | 0.255 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, H.; Li, H.; Zhang, Y.; Wang, S.; Gu, K.; Ren, M. Multi-Sensor Vibration Signal Based Three-Stage Fault Prediction for Rotating Mechanical Equipment. Entropy 2022, 24, 164. https://doi.org/10.3390/e24020164
Peng H, Li H, Zhang Y, Wang S, Gu K, Ren M. Multi-Sensor Vibration Signal Based Three-Stage Fault Prediction for Rotating Mechanical Equipment. Entropy. 2022; 24(2):164. https://doi.org/10.3390/e24020164
Chicago/Turabian StylePeng, Huaqing, Heng Li, Yu Zhang, Siyuan Wang, Kai Gu, and Mifeng Ren. 2022. "Multi-Sensor Vibration Signal Based Three-Stage Fault Prediction for Rotating Mechanical Equipment" Entropy 24, no. 2: 164. https://doi.org/10.3390/e24020164
APA StylePeng, H., Li, H., Zhang, Y., Wang, S., Gu, K., & Ren, M. (2022). Multi-Sensor Vibration Signal Based Three-Stage Fault Prediction for Rotating Mechanical Equipment. Entropy, 24(2), 164. https://doi.org/10.3390/e24020164