
Modified Maximum Entropy Method and Estimating the AIF via DCE-MRI Data Analysis


Abstract
1. Introduction
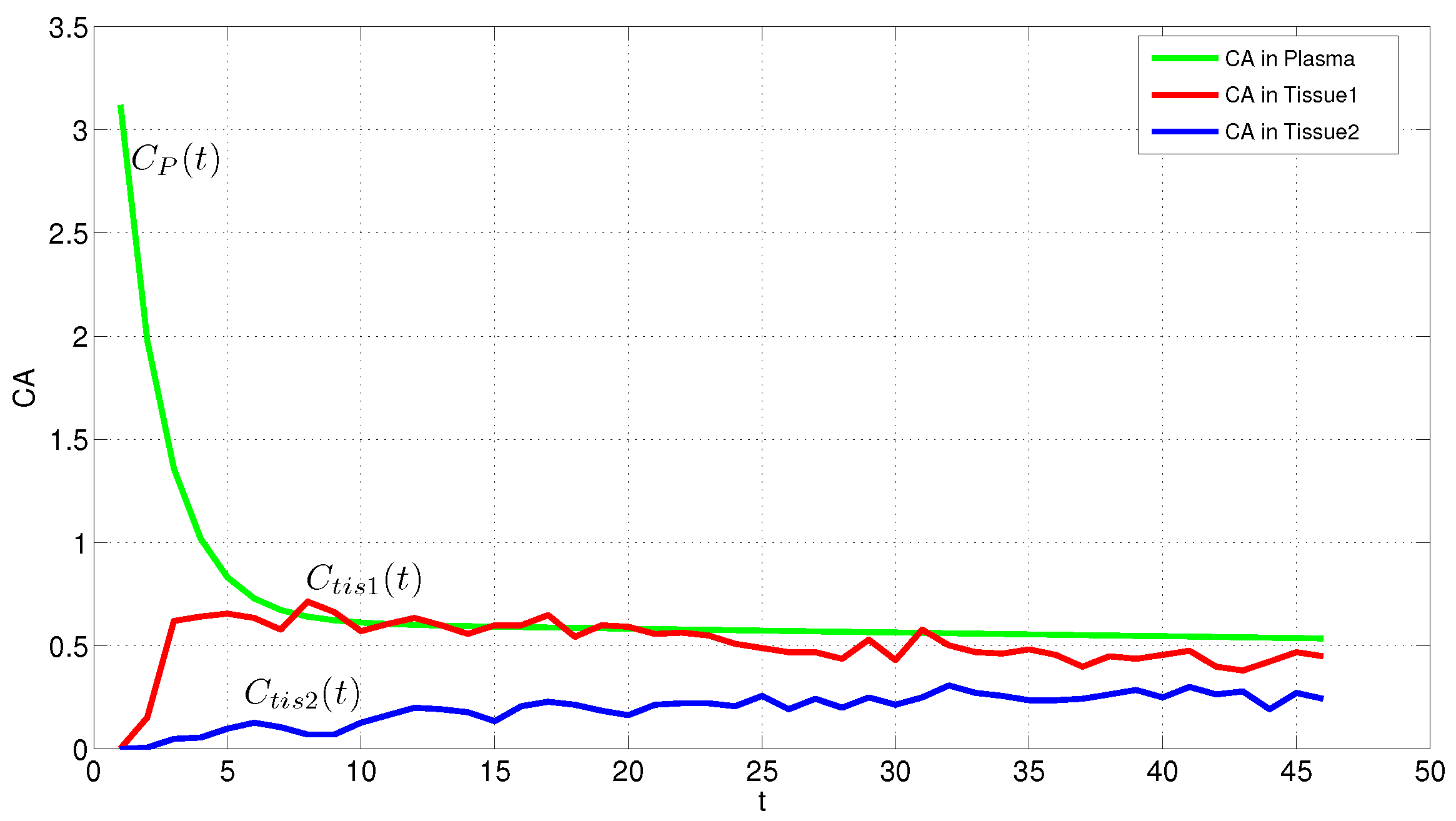
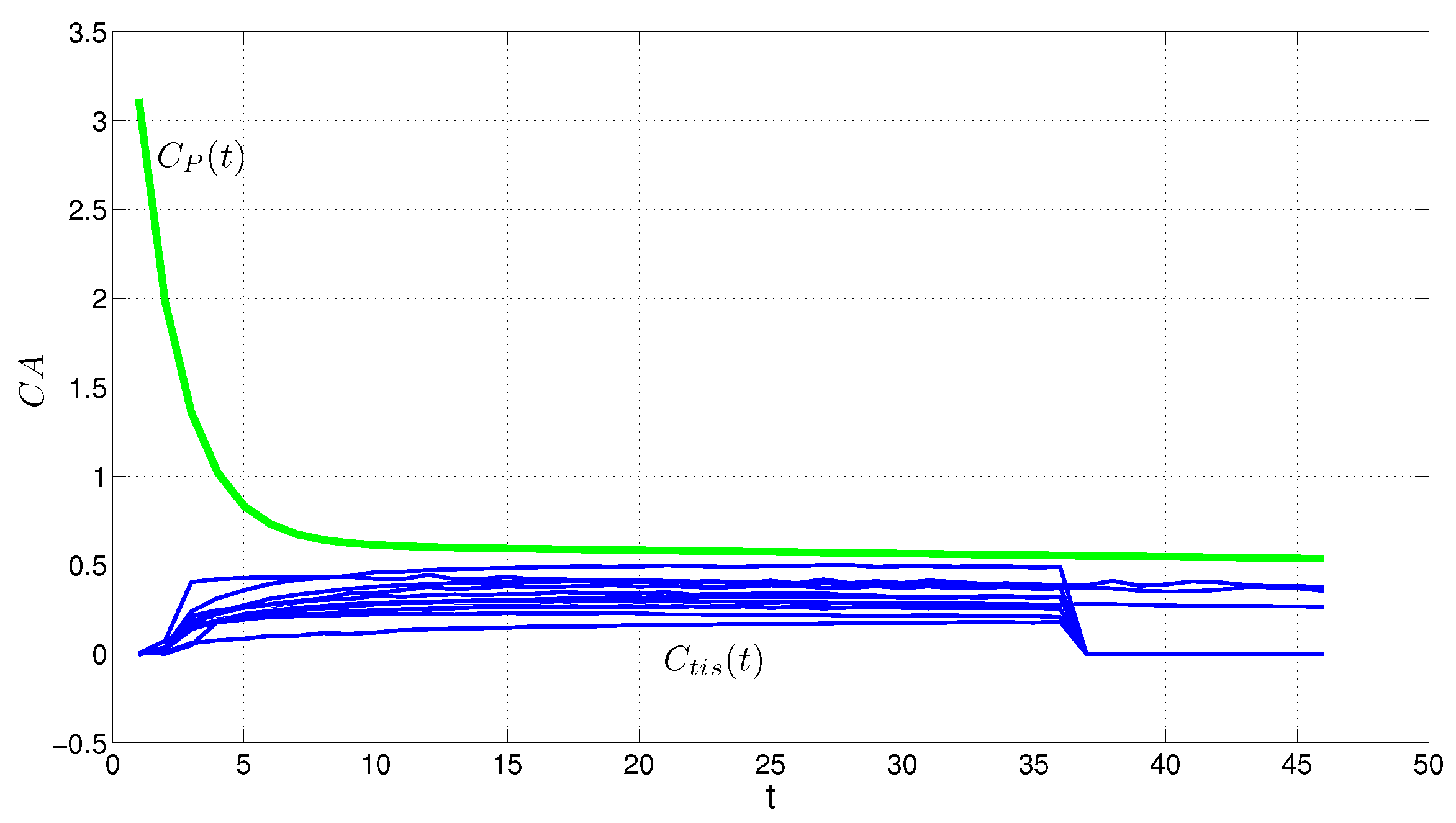
Data Description
2. Theory and Methods
2.1. Kinetic Model
2.2. Maximum a Posterior Approach
2.3. Maximum Entropy Method
2.4. Teaching-Learning Based Optimization
2.4.1. Teacher Phase
2.4.2. Learner Phase
2.5. Implementation
- (1)
- Determining and their numerical expectations using dataset via Taylor’s theorem [4],
- (2)
- Using TLBO (or an alternative optimization method, see below) to determine the unknown function with the Shannon’s entropy as target function. The general form is given in Equation (15), ( and ),
- (3)
- (4)
- Estimating the kinetic parameters , we replace and in Equation (8) and resolve them via MAP,
- (5)
- Using the Kullback–Leibler divergence to check the accuracy of the estimated AIF, in comparison with the empirical distribution of dataset ,
- (6)
- With the predicted values and the observed values :
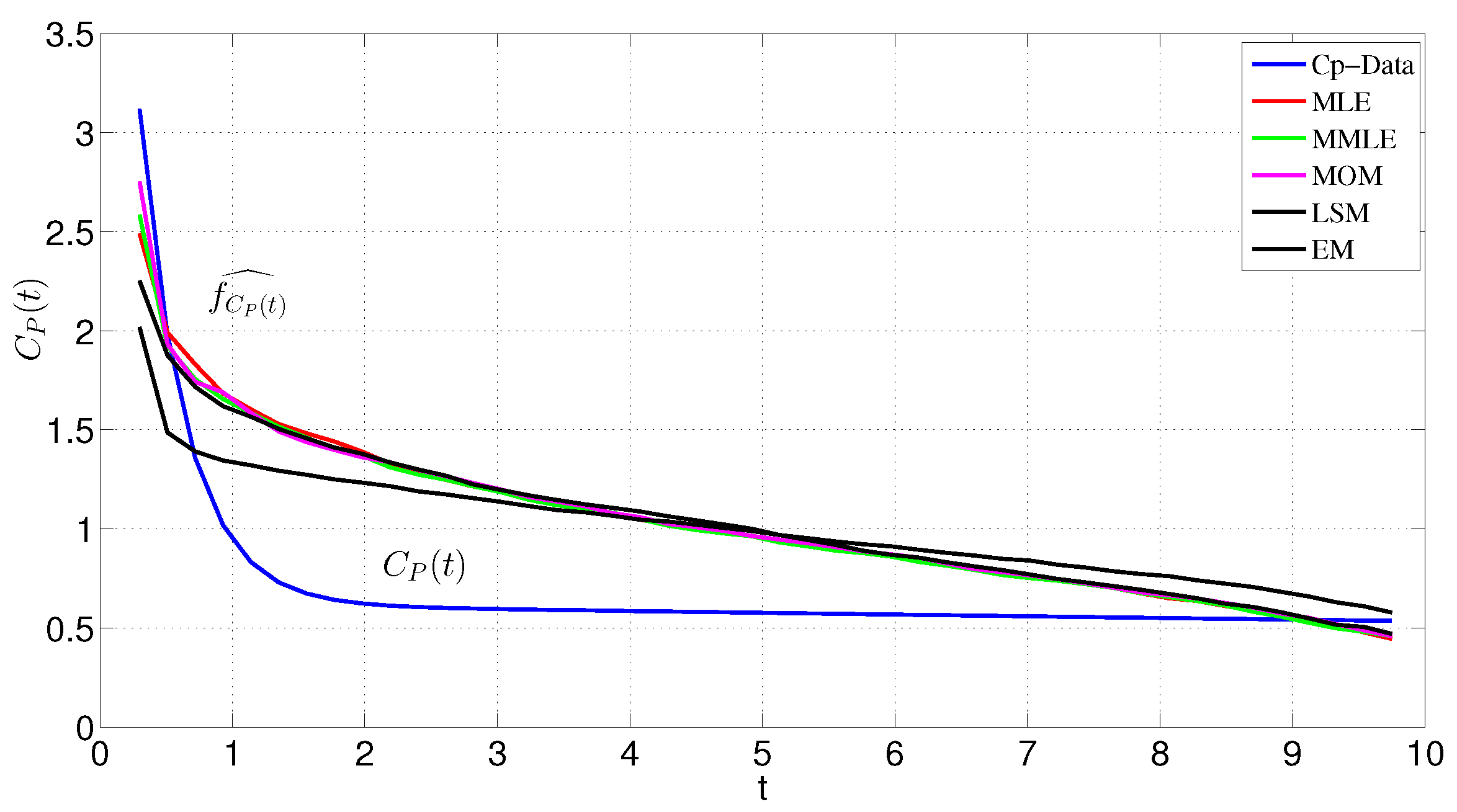
3. Alternative Parameter Estimation
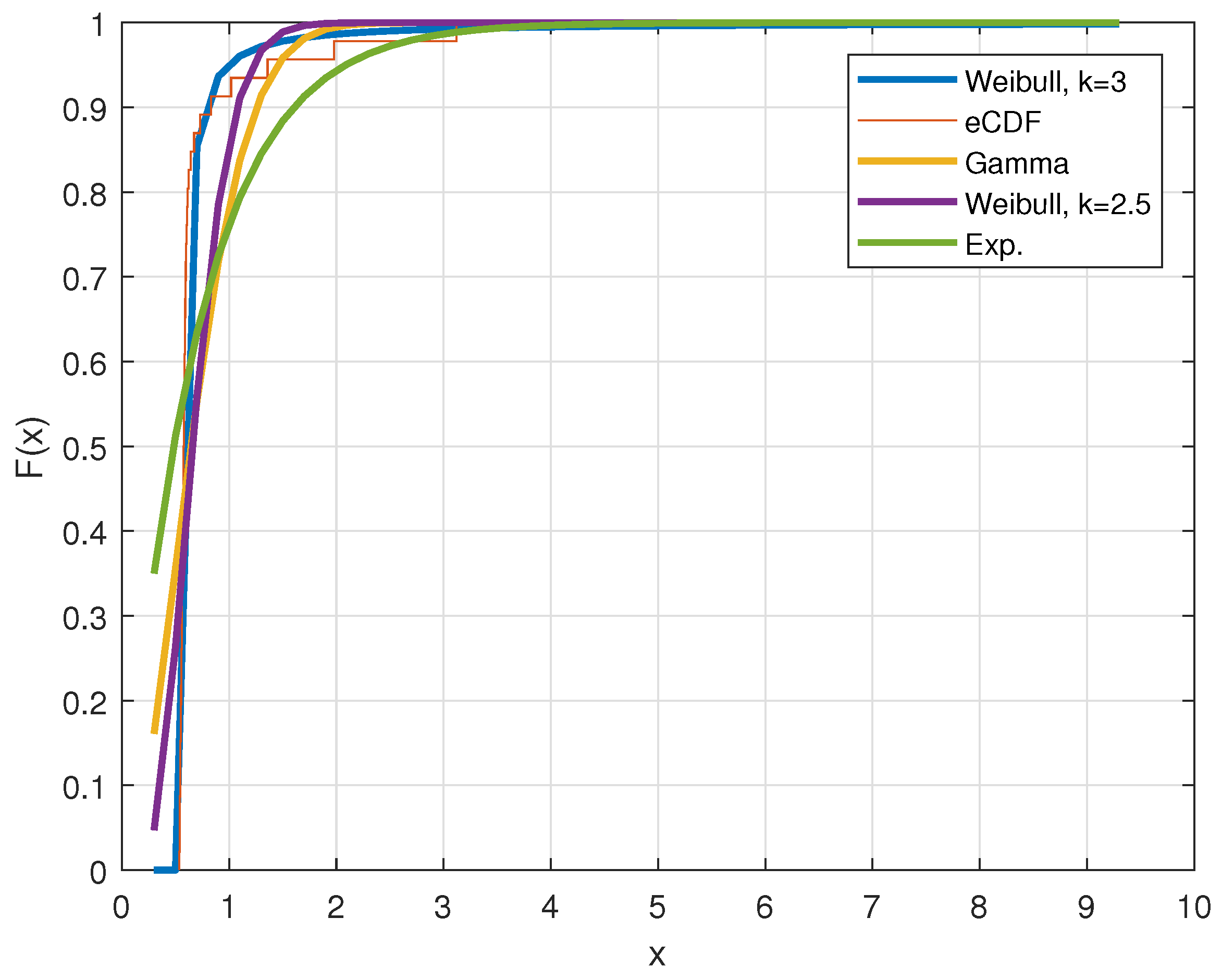
3.1. Weibull Distribution
3.2. Methods of Moments
3.3. Empirical Measurement Method
3.4. Maximum Likelihood Method
3.5. Modified Maximum Likelihood Method
3.6. Non-Linear Least Squares Method
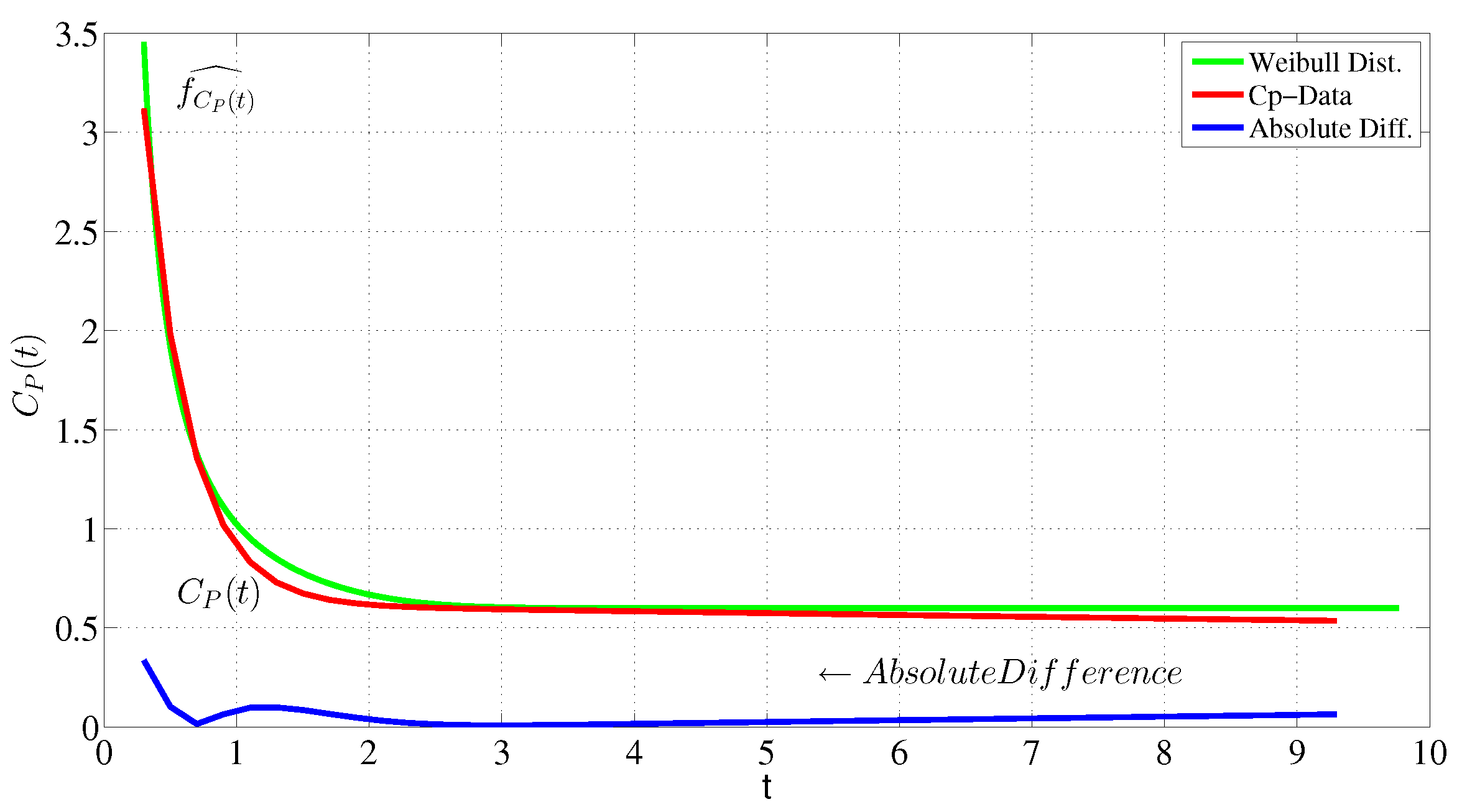
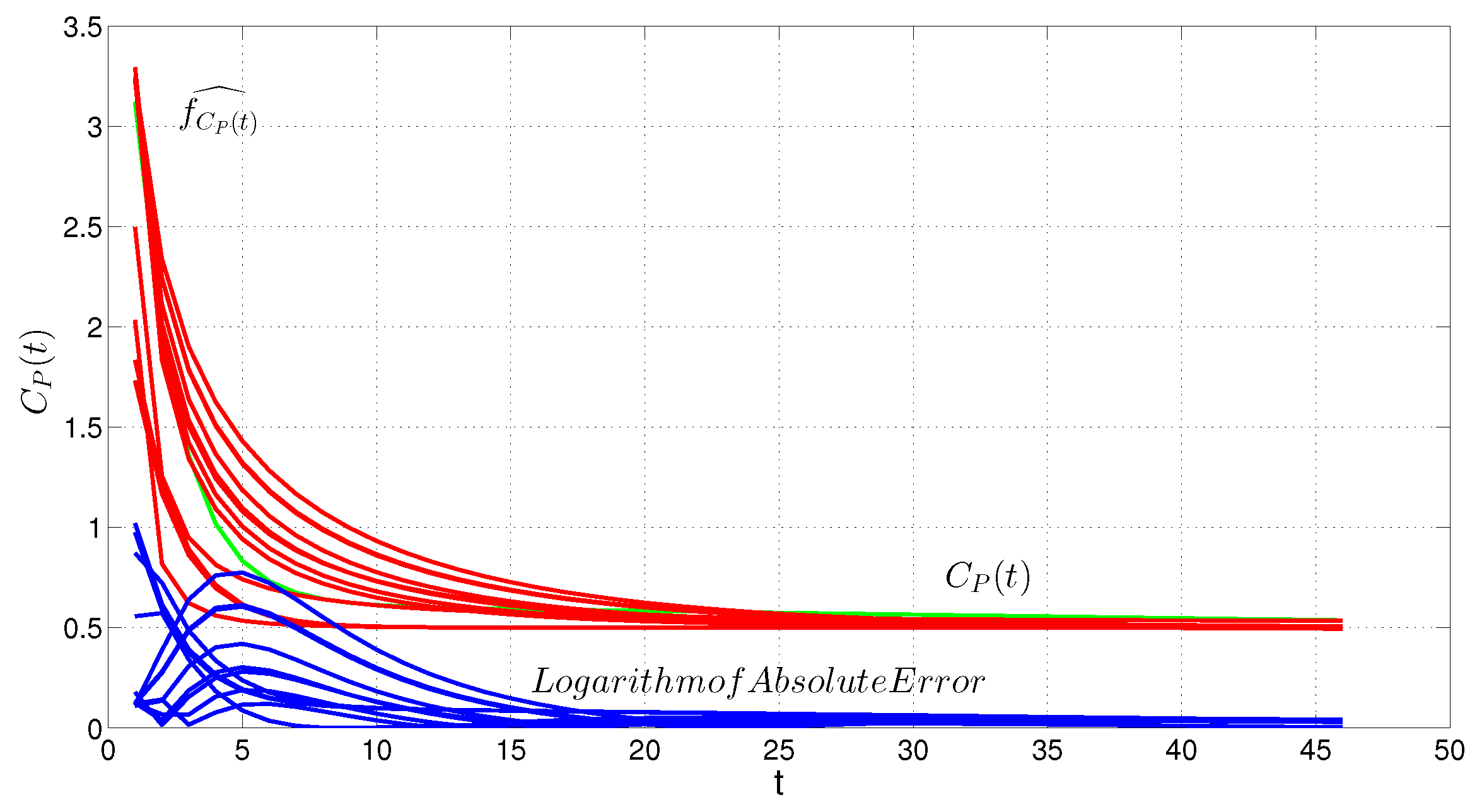
4. Example of Application
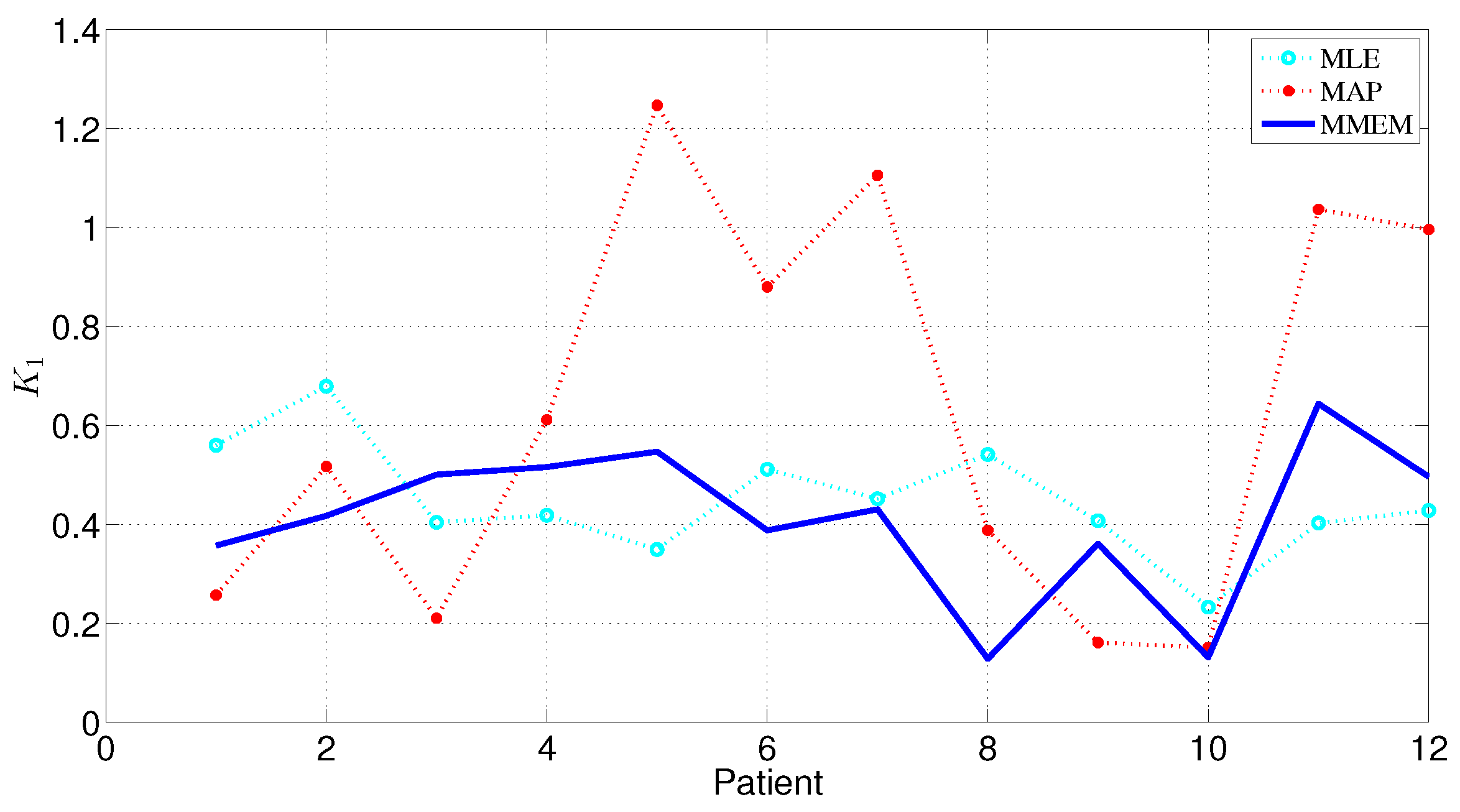
5. Evaluation
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Pougaza, D.B.; Djafari, A.M. Maximum Entropy Copulas. AIP Conf. Proc. 2011, 1305, 2069–2072. [Google Scholar]
- Ebrahimi, N.; Soofi, E.S.; Soyer, R. Multivariate maximum entropy identification, transformation, and dependence. J. Multivar. Anal. 2008, 99, 1217–1231. [Google Scholar] [CrossRef]
- Thomas, A.; Cover, T.M. Elements of Information Theory; John Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Cofré, R.; Herzog, R.; Corcoran, D.; Rosas, F.E. A comparison of the maximum entropy principle across biological spatial scales. Entropy 2019, 21, 1009. [Google Scholar] [CrossRef]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Ozer, H.G. Residue Associations in Protein Family Alignments. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2008. [Google Scholar]
- Seno, F.; Trovato, A.; Banavar, J.R.; Maritan, A. Maximum entropy approach for deducing amino acid interactions in proteins. Phys. Rev. Lett. 2008, 100, 078102. [Google Scholar] [CrossRef]
- Weigt, M.; White, R.A.; Szurmant, H.; Hoch, J.A.; Hwa, T. Identification of direct residue contacts in protein–protein interaction by message passing. Proc. Natl. Acad. Sci. USA 2009, 106, 67–72. [Google Scholar] [CrossRef]
- Pitera, J.W.; Chodera, J.D. On the use of experimental observations to bias simulated ensembles. J. Chem. Theory Comput. 2012, 8, 3445–3451. [Google Scholar] [CrossRef] [PubMed]
- Hopf, T.A.; Colwell, L.J.; Sheridan, R.; Rost, B.; Sander, C.; Marks, D.S. Three-dimensional structures of membrane proteins from genomic sequencing. Cell 2012, 149, 1607–1621. [Google Scholar] [CrossRef]
- Roux, B.; Weare, J. On the statistical equivalence of restrained-ensemble simulations with the maximum entropy method. J. Chem. Phys. 2013, 138, 02B616. [Google Scholar] [CrossRef] [PubMed]
- Cavalli, A.; Camilloni, C.; Vendruscolo, M. Molecular dynamics simulations with replica-averaged structural restraints generate structural ensembles according to the maximum entropy principle. J. Chem. Phys. 2013, 138, 03B603. [Google Scholar] [CrossRef]
- Jennings, R.C.; Belgio, E.; Zucchelli, G. Does maximal entropy production play a role in the evolution of biological complexity? A biological point of view. Rendiconti Lincei Scienze Fisiche e Naturali 2020, 31, 259–268. [Google Scholar] [CrossRef]
- Ekeberg, M.; Lövkvist, C.; Lan, Y.; Weigt, M.; Aurell, E. Improved contact prediction in proteins: Using pseudolikelihoods to infer Potts models. Phys. Rev. E 2013, 87, 012707. [Google Scholar] [CrossRef]
- Boomsma, W.; Ferkinghoff-Borg, J.; Lindorff-Larsen, K. Combining experiments and simulations using the maximum entropy principle. PLoS Comput. Biol. 2014, 10, e1003406. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Wolynes, P.G. Topology, structures, and energy landscapes of human chromosomes. Proc. Natl. Acad. Sci. USA 2015, 112, 6062–6067. [Google Scholar] [CrossRef] [PubMed]
- Cesari, A.; Reißer, S.; Bussi, G. Using the maximum entropy principle to combine simulations and solution experiments. Computation 2018, 6, 15. [Google Scholar] [CrossRef]
- Farré, P.; Emberly, E. A maximum-entropy model for predicting chromatin contacts. PLoS Comput. Biol. 2018, 14, e1005956. [Google Scholar] [CrossRef]
- D’haeseleer, P.; Liang, S.; Somogyi, R. Genetic network inference: From co-expression clustering to reverse engineering. Bioinformatics 2000, 16, 707–726. [Google Scholar] [CrossRef] [PubMed]
- Lezon, T.R.; Banavar, J.R.; Cieplak, M.; Maritan, A.; Fedoroff, N.V. Using the principle of entropy maximization to infer genetic interaction networks from gene expression patterns. Proc. Natl. Acad. Sci. USA 2006, 103, 19033–19038. [Google Scholar] [CrossRef]
- Dhadialla, P.S.; Ohiorhenuan, I.E.; Cohen, A.; Strickland, S. Maximum-entropy network analysis reveals a role for tumor necrosis factor in peripheral nerve development and function. Proc. Natl. Acad. Sci. USA 2009, 106, 12494–12499. [Google Scholar] [CrossRef] [PubMed]
- Remacle, F.; Kravchenko-Balasha, N.; Levitzki, A.; Levine, R.D. Information-theoretic analysis of phenotype changes in early stages of carcinogenesis. Proc. Natl. Acad. Sci. USA 2010, 107, 10324–10329. [Google Scholar] [CrossRef]
- Sanguinetti, G.; Huynh-Thu, V.A. Gene regulatory network inference: An introductory survey. In Gene Regulatory Networks; Springer: New York, NY, USA, 2019; pp. 1–23. [Google Scholar]
- Locasale, J.W.; Wolf-Yadlin, A. Maximum entropy reconstructions of dynamic signaling networks from quantitative proteomics data. PLoS ONE 2009, 4, e6522. [Google Scholar] [CrossRef]
- Graeber, T.; Heath, J.; Skaggs, B.; Phelps, M.; Remacle, F.; Levine, R.D. Maximal entropy inference of oncogenicity from phosphorylation signaling. Proc. Natl. Acad. Sci. USA 2010, 107, 6112–6117. [Google Scholar] [CrossRef] [PubMed]
- Sharan, R.; Karp, R.M. Reconstructing Boolean models of signaling. J. Comput. Biol. 2013, 20, 249–257. [Google Scholar] [CrossRef]
- Schneidman, E.; Berry, M.J.; Segev, R.; Bialek, W. Weak pairwise correlations imply strongly correlated network states in a neural population. Nature 2006, 440, 1007–1012. [Google Scholar] [CrossRef]
- Shlens, J.; Field, G.D.; Gauthier, J.L.; Grivich, M.I.; Petrusca, D.; Sher, A.; Litke, A.M.; Chichilnisky, E. The structure of multi-neuron firing patterns in primate retina. J. Neurosci. 2006, 26, 8254–8266. [Google Scholar] [CrossRef]
- Quadeer, A.A.; McKay, M.R.; Barton, J.P.; Louie, R.H. MPF–BML: A standalone GUI-based package for maximum entropy model inference. Bioinformatics 2020, 36, 2278–2279. [Google Scholar] [CrossRef]
- Tang, A.; Jackson, D.; Hobbs, J.; Chen, W.; Smith, J.L.; Patel, H.; Prieto, A.; Petrusca, D.; Grivich, M.I.; Sher, A.; et al. A maximum entropy model applied to spatial and temporal correlations from cortical networks in vitro. J. Neurosci. 2008, 28, 505–518. [Google Scholar] [CrossRef] [PubMed]
- Cocco, S.; Leibler, S.; Monasson, R. Neuronal couplings between retinal ganglion cells inferred by efficient inverse statistical physics methods. Proc. Natl. Acad. Sci. USA 2009, 106, 14058–14062. [Google Scholar] [CrossRef] [PubMed]
- Roudi, Y.; Nirenberg, S.; Latham, P.E. Pairwise maximum entropy models for studying large biological systems: When they can work and when they ca not. PLoS Comput. Biol. 2009, 5, e1000380. [Google Scholar] [CrossRef]
- Tkačik, G.; Prentice, J.S.; Balasubramanian, V.; Schneidman, E. Optimal population coding by noisy spiking neurons. Proc. Natl. Acad. Sci. USA 2010, 107, 14419–14424. [Google Scholar] [CrossRef]
- Ohiorhenuan, I.E.; Mechler, F.; Purpura, K.P.; Schmid, A.M.; Hu, Q.; Victor, J.D. Sparse coding and high-order correlations in fine-scale cortical networks. Nature 2010, 466, 617–621. [Google Scholar] [CrossRef]
- Yeh, F.C.; Tang, A.; Hobbs, J.P.; Hottowy, P.; Dabrowski, W.; Sher, A.; Litke, A.; Beggs, J.M. Maximum entropy approaches to living neural networks. Entropy 2010, 12, 89–106. [Google Scholar] [CrossRef]
- Granot-Atedgi, E.; Tkačik, G.; Segev, R.; Schneidman, E. Stimulus-dependent maximum entropy models of neural population codes. PLoS Comput. Biol. 2013, 9, e1002922. [Google Scholar] [CrossRef]
- Tkačik, G.; Marre, O.; Mora, T.; Amodei, D.; Berry II, M.J.; Bialek, W. The simplest maximum entropy model for collective behavior in a neural network. J. Stat. Mech. Theory Exp. 2013, 2013, P03011. [Google Scholar] [CrossRef]
- Ferrari, U.; Obuchi, T.; Mora, T. Random versus maximum entropy models of neural population activity. Phys. Rev. E 2017, 95, 042321. [Google Scholar] [CrossRef]
- Rostami, V.; Mana, P.P.; Grün, S.; Helias, M. Bistability, non-ergodicity, and inhibition in pairwise maximum-entropy models. PLoS Comput. Biol. 2017, 13, e1005762. [Google Scholar] [CrossRef]
- Nghiem, T.A.; Teleńczuk, B.; Marre, O.; Destexhe, A.; Ferrari, U. Maximum entropy models reveal the correlation structure in cortical neural activity during wakefulness and sleep. bioRxiv 2018, 243857. [Google Scholar] [CrossRef]
- Yeo, G.; Burge, C.B. Maximum entropy modeling of short sequence motifs with applications to RNA splicing signals. J. Comput. Biol. 2004, 11, 377–394. [Google Scholar] [CrossRef]
- Mora, T.; Walczak, A.M.; Bialek, W.; Callan, C.G. Maximum entropy models for antibody diversity. Proc. Natl. Acad. Sci. USA 2010, 107, 5405–5410. [Google Scholar] [CrossRef]
- Santolini, M.; Mora, T.; Hakim, V. A general pairwise interaction model provides an accurate description of in vivo transcription factor binding sites. PLoS ONE 2014, 9, e99015. [Google Scholar] [CrossRef]
- Fariselli, P.; Taccioli, C.; Pagani, L.; Maritan, A. DNA sequence symmetries from randomness: The origin of the Chargaff’s second parity rule. Brief. Bioinform. 2020, 22, 2172–2181. [Google Scholar] [CrossRef]
- Fernandez-de Cossio-Diaz, J.; Mulet, R. Maximum entropy and population heterogeneity in continuous cell cultures. PLoS Comput. Biol. 2019, 15, e1006823. [Google Scholar] [CrossRef]
- Jackson, A.; Constable, C.; Gillet, N. Maximum entropy regularization of the geomagnetic core field inverse problem. Geophys. J. Int. 2007, 171, 995–1004. [Google Scholar] [CrossRef]
- De Martino, A.; De Martino, D. An introduction to the maximum entropy approach and its application to inference problems in biology. Heliyon 2018, 4, e00596. [Google Scholar] [CrossRef]
- Khalifa, F.; Soliman, A.; El-Baz, A.; Abou El-Ghar, M.; El-Diasty, T.; Gimel’farb, G.; Ouseph, R.; Dwyer, A.C. Models and methods for analyzing DCE-MRI: A review. Med. Phys. 2014, 41, 124301. [Google Scholar] [CrossRef]
- Fennessy, F.M.; McKay, R.R.; Beard, C.J.; Taplin, M.E.; Tempany, C.M. Dynamic contrast-enhanced magnetic resonance imaging in prostate cancer clinical trials: Potential roles and possible pitfalls. Transl. Oncol. 2014, 7, 120–129. [Google Scholar] [CrossRef]
- Huang, W.; Li, X.; Chen, Y.; Li, X.; Chang, M.C.; Oborski, M.J.; Malyarenko, D.I.; Muzi, M.; Jajamovich, G.H.; Fedorov, A.; et al. Variations of dynamic contrast-enhanced magnetic resonance imaging in evaluation of breast cancer therapy response: A multicenter data analysis challenge. Transl. Oncol. 2014, 7, 153. [Google Scholar] [CrossRef]
- Sobhani, F.; Xu, C.; Murano, E.; Pan, L.; Rastegar, N.; Kamel, I.R. Hypo-vascular liver metastases treated with transarterial chemoembolization: Assessment of early response by volumetric contrast-enhanced and diffusion-weighted magnetic resonance imaging. Transl. Oncol. 2016, 9, 287–294. [Google Scholar] [CrossRef][Green Version]
- Usuda, K.; Iwai, S.; Funasaki, A.; Sekimura, A.; Motono, N.; Matoba, M.; Doai, M.; Yamada, S.; Ueda, Y.; Uramoto, H. Diffusion-weighted magnetic resonance imaging is useful for the response evaluation of chemotherapy and/or radiotherapy to recurrent lesions of lung cancer. Transl. Oncol. 2019, 12, 699–704. [Google Scholar] [CrossRef]
- Stoyanova, R.; Huang, K.; Sandler, K.; Cho, H.; Carlin, S.; Zanzonico, P.B.; Koutcher, J.A.; Ackerstaff, E. Mapping tumor hypoxia in vivo using pattern recognition of dynamic contrast-enhanced MRI data. Transl. Oncol. 2012, 5, 437. [Google Scholar] [CrossRef]
- Schmid, V.J.; Whitcher, B.; Padhani, A.R.; Taylor, N.J.; Yang, G.Z. Bayesian methods for pharmacokinetic models in dynamic contrast-enhanced magnetic resonance imaging. IEEE Trans. Med. Imaging 2006, 25, 1627–1636. [Google Scholar] [CrossRef]
- Tofts, P.S.; Brix, G.; Buckley, D.L.; Evelhoch, J.L.; Henderson, E.; Knopp, M.V.; Larsson, H.B.; Lee, T.Y.; Mayr, N.A.; Parker, G.J.; et al. Estimating kinetic parameters from dynamic contrast-enhanced T1-weighted MRI of a diffusable tracer: Standardized quantities and symbols. J. Magn. Reson. Imaging Off. J. Int. Soc. Magn. Reson. Med. 1999, 10, 223–232. [Google Scholar] [CrossRef]
- Shao, J.; Zhang, Z.; Liu, H.; Song, Y.; Yan, Z.; Wang, X.; Hou, Z. DCE-MRI pharmacokinetic parameter maps for cervical carcinoma prediction. Comput. Biol. Med. 2020, 118, 103634. [Google Scholar] [CrossRef]
- Lingala, S.G.; Guo, Y.; Bliesener, Y.; Zhu, Y.; Lebel, R.M.; Law, M.; Nayak, K.S. Tracer kinetic models as temporal constraints during brain tumor DCE-MRI reconstruction. Med. Phys. 2020, 47, 37–51. [Google Scholar] [CrossRef]
- Zou, J.; Balter, J.M.; Cao, Y. Estimation of pharmacokinetic parameters from DCE-MRI by extracting long and short time-dependent features using an LSTM network. Med. Phys. 2020, 47, 3447–3457. [Google Scholar] [CrossRef]
- Dikaios, N. Stochastic Gradient Langevin dynamics for joint parameterization of tracer kinetic models, input functions, and T1 relaxation-times from undersampled k-space DCE-MRI. Med. Image Anal. 2020, 62, 101690. [Google Scholar] [CrossRef]
- Tofts, P.S.; Kermode, A.G. Measurement of the blood-brain barrier permeability and leakage space using dynamic MR imaging. 1. Fundamental concepts. Magn. Reson. Med. 1991, 17, 357–367. [Google Scholar] [CrossRef]
- Larsson, H.B.W.; Tofts, P.S. Measurement of blood-brain barrier permeability using dynamic Gd-DTPA scanning—A comparison of methods. Magn. Reson. Med. 1992, 24, 174–176. [Google Scholar] [CrossRef]
- Brix, G.; Kiessling, F.; Lucht, R.; Darai, S.; Wasser, K.; Delorme, S.; Griebe, J. Microcirculation and microvasculature in breast tumors: Pharmacokinetic analysis of dynamic MR image series. Magn. Reson. Med. 2004, 52, 420–429. [Google Scholar] [CrossRef]
- Berg, B.; Stucht, D.; Janiga, G.; Beuing, O.; Speck, O.; Thovenin, D. Cerebral Blood Flow in a Healthy Circle of Willis and Two Intracranial Aneurysms: Computational Fluid Dynamics Versus Four-Dimensional Phase-Contrast Magnetic Resonance Imaging. ASME J. Biomech. Eng. 2014, 15, 041003. [Google Scholar] [CrossRef]
- Orton, M.R.; Collins, D.J.; Walker-Samuel, S.; d’Arcy, J.A.; Hawkes, D.J.; Atkinson, D.; Leach, M.O. Bayesian estimation of pharmacokinetic parameters for DCE-MRI with a robust treatment of enhancement onset time. Phys. Med. Biol. 2007, 52, 2393–2408. [Google Scholar] [CrossRef]
- Dikaios, N.; Arridge, S.; Hamy, V.; Punwani, S.; Atkinson, D. Direct parametric reconstruction from undersampled (k, t)-space data in dynamic contrast enhanced MRI. Med. Image Anal. 2014, 18, 989–1001. [Google Scholar] [CrossRef]
- Bender, R.; Heinemann, L. Fitting nonlinear regression models with correlated errors to individual pharmacodynamic data using SAS software. J. Pharmacokinet. Biopharm. 1995, 23, 87–100. [Google Scholar] [CrossRef]
- Cheng, H.L.M. T1 measurement of flowing blood and arterial input function determination for quantitative 3D T1-weighted DCE-MRI. J. Magn. Reson. Imaging JMRI 2007, 25, 1073–1078. [Google Scholar] [CrossRef]
- Gauthier, M. Impact of the arterial input function on microvascularization parameter measurements using dynamic contrast-enhanced ultrasonography. World J. Radiol. 2012, 4, 291. [Google Scholar] [CrossRef]
- Cheng, H.L.M. Investigation and optimization of parameter accuracy in dynamic contrast-enhanced MRI. J. Magn. Reson. Imaging 2008, 28, 736–743. [Google Scholar] [CrossRef]
- Lavini, C. Simulating the effect of input errors on the accuracy of Tofts’ pharmacokinetic model parameters. Magn. Reson. Imaging 2015, 33, 222–235. [Google Scholar] [CrossRef]
- Peled, S.; Vangel, M.; Kikinis, R.; Tempany, C.M.; Fennessy, F.M.; Fedorov, A. Selection of fitting model and arterial input function for repeatability in dynamic contrast-enhanced prostate MRI. Acad. Radiol. 2019, 26, e241–e251. [Google Scholar] [CrossRef]
- Huang, W.; Chen, Y.; Fedorov, A.; Li, X.; Jajamovich, G.H.; Malyarenko, D.I.; Aryal, M.P.; LaViolette, P.S.; Oborski, M.J.; O’Sullivan, F.; et al. The impact of arterial input function determination variations on prostate dynamic contrast-enhanced magnetic resonance imaging pharmacokinetic modeling: A multicenter data analysis challenge. Tomography 2016, 2, 56–66. [Google Scholar] [CrossRef]
- Huang, W.; Chen, Y.; Fedorov, A.; Li, X.; Jajamovich, G.H.; Malyarenko, D.I.; Aryal, M.P.; LaViolette, P.S.; Oborski, M.J.; O’Sullivan, F.; et al. The impact of arterial input function determination variations on prostate dynamic contrast-enhanced magnetic resonance imaging pharmacokinetic modeling: A multicenter data analysis challenge, part II. Tomography 2019, 5, 99–109. [Google Scholar] [CrossRef]
- Keil, V.C.; Mädler, B.; Gieseke, J.; Fimmers, R.; Hattingen, E.; Schild, H.H.; Hadizadeh, D.R. Effects of arterial input function selection on kinetic parameters in brain dynamic contrast-enhanced MRI. Magn. Reson. Imaging 2017, 40, 83–90. [Google Scholar] [CrossRef]
- Parker, G.J.; Roberts, C.; Macdonald, A.; Buonaccorsi, G.A.; Cheung, S.; Buckley, D.L.; Jackson, A.; Watson, Y.; Davies, K.; Jayson, G.C. Experimentally-derived functional form for a population-averaged high-temporal-resolution arterial input function for dynamic contrast-enhanced MRI. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2006, 56, 993–1000. [Google Scholar] [CrossRef]
- Rata, M.; Collins, D.J.; Darcy, J.; Messiou, C.; Tunariu, N.; Desouza, N.; Young, H.; Leach, M.O.; Orton, M.R. Assessment of repeatability and treatment response in early phase clinical trials using DCE-MRI: Comparison of parametric analysis using MR-and CT-derived arterial input functions. Eur. Radiol. 2016, 26, 1991–1998. [Google Scholar] [CrossRef]
- Rijpkema, M.; Kaanders, J.H.; Joosten, F.B.; van der Kogel, A.J.; Heerschap, A. Method for quantitative mapping of dynamic MRI contrast agent uptake in human tumors. J. Magn. Reson. Imaging Off. J. Int. Soc. Magn. Reson. Med. 2001, 14, 457–463. [Google Scholar] [CrossRef]
- Ashton, E.; Raunig, D.; Ng, C.; Kelcz, F.; McShane, T.; Evelhoch, J. Scan-rescan variability in perfusion assessment of tumors in MRI using both model and data-derived arterial input functions. J. Magn. Reson. Imaging Off. J. Int. Soc. Magn. Reson. Med. 2008, 28, 791–796. [Google Scholar] [CrossRef]
- Weinmann, H.J.; Laniado, M.; Mützel, W. Pharmokinetics of Gd-DTPA/Dimeglumine after intravenous injection into healthy volunteers. Physiol. Chem. Phys. Med. NMR 1984, 16, 167–172. [Google Scholar]
- Fritz-Hansen, T.; Rostrup, E.; Larsson, H.B.W.; Sø ndergaard, L.; Ring, P.; Henriksen, O. Measurement of the Arterial Concentration of Gd-DTPA Using MRI: A step toward Quantitative Perfusion Imaging. Magn. Reson. Med. 1996, 36, 225–231. [Google Scholar] [CrossRef]
- Farsani, Z.A.; Schmid, V.J. Maximum Entropy Approach in Dynamic Contrast-Enhanced Magnetic Resonance Imaging. Methods Inf. Med. 2017, 56, 461–468. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Zou, F.; Chen, D.; Xu, Q. A survey of teaching–learning-based optimization. Neurocomputing 2019, 335, 366–383. [Google Scholar] [CrossRef]
- Parker, G.J.; Suckling, J.; Tanner, S.F.; Padhani, A.R.; Revell, P.B.; Husband, J.E.; Leach, M.O. Probing tumor microvascularity by measurement, analysis and display of contrast agent uptake kinetics. J. Magn. Reson. Imaging 1997, 7, 564–574. [Google Scholar] [CrossRef]
- d’Arcy, J.A.; Collins, D.J.; Padhani, A.R.; Walker-Samuel, S.; Suckling, J.; Leach, M.O. Magnetic resonance imaging workbench: Analysis and visualization of dynamic contrast-enhanced MR imaging data. Radiographics 2006, 26, 621–632. [Google Scholar] [CrossRef][Green Version]
- Buckley, D.; Parker, G. Measuring Contrast Agent Concentration in T1-Weighted Dynamic Contrast-Enhanced MRI. In Dynamic Contrast-Enhanced Magntic Resoncance Imaging in Oncology; Jackson, A., Parker, G.J.M., Buckley, D.L., Eds.; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2005; Chapter 5; pp. 69–80. [Google Scholar]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Choyke, P.; Dwyer, A.; Knopp, M. Functional tumor imaging withdynamic contrast-enhanced magnetic resonance imaging. Magn. Reson. Med. 2003, 17, 509–520. [Google Scholar]
- Murase, K. Efficient method for calculating kinetic parameters using T1-weighted dynamic contrast-enhanced magnetic resonance imaging. Magn. Reson. Med. 2004, 51, 858–862. [Google Scholar] [CrossRef] [PubMed]
- Mohammad-Djafari, A. Bayesian Image Processing. In Proceedings of the Fifth International Conference on Modelling, Computation and Optimization in Information Systems and Management Sciences (MCO 2004), Metz, France, 1–3 July 2004. [Google Scholar]
- Mohammad-Djafari, A.; Demoment, G. Estimating priors in maximum entropy image processing. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; pp. 2069–2072. [Google Scholar]
- Mohammad-Djafari, A. A full Bayesian approach for inverse problems. In Maximum Entropy and Bayesian Methods; Springer: Berlin/Heidelberg, Germany, 1996; pp. 135–144. [Google Scholar]
- Hadamard, J. Le Probleme de Cauchy et les Équations aux Dérivées Partielles Linéaires Hyperboliques; Paris Russian Translation; 1932; Volume 220. [Google Scholar]
- Turchin, V.F. Solution of the Fredholm equation of the first kind in a statistical ensemble of smooth functions. USSR Comput. Math. Math. Phys. 1967, 7, 79–96. [Google Scholar] [CrossRef]
- Denisova, N. Bayesian maximum-a posteriori approach with global and local regularization to image reconstruction problem in medical emission tomography. Entropy 2019, 21, 1108. [Google Scholar] [CrossRef]
- Sparavigna, A.C. Entropy in image analysis. Entropy 2019, 21, 502. [Google Scholar] [CrossRef] [PubMed]
- Skilling, J. The axioms of maximum entropy. In Maximum-Entropy and Bayesian Methods in Science and Engineering; Springer: Berlin/Heidelberg, Germany, 1988; pp. 173–187. [Google Scholar]
- Elfving, T. An Algorithm for Maximum Entropy Image Reconstruction form Noisy Data. Mathl. Comput. Model. 1989, 12, 729–745. [Google Scholar] [CrossRef]
- Akpinar, S.; Akpinar, E.K. Wind energy analysis based on maximum entropy principle (MEP)-type distribution function. Energy Convers. Manag. 2007, 48, 1140–1149. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R. Statistical Inference 2; Duxbury: Belmont, CA, USA, 2002. [Google Scholar]
- García, J.A.M.; Mena, A.J.G. Optimal distributed generation location and size using a modified teaching-learning based optimization algorithm. Int. J. Electr. Power Energy Syst. 2013, 50, 65–75. [Google Scholar] [CrossRef]
- Bain, L.J.; Antle, C.E. Estimation of parameters in the weibdl distribution. Technometrics 1967, 9, 621–627. [Google Scholar] [CrossRef]
- Stevens, M.; Smulders, P. The estimation of the parameters of the Weibull wind speed distribution for wind energy utilization purposes. Wind Eng. 1979, 3, 132–145. [Google Scholar]
- Justus, C.; Hargraves, W.; Mikhail, A.; Graber, D. Methods for estimating wind speed frequency distributions. J. Appl. Meteorol. 1978, 17, 350–353. [Google Scholar] [CrossRef]
- Morgan, E.C.; Lackner, M.; Vogel, R.M.; Baise, L.G. Probability distributions for offshore wind speeds. Energy Convers. Manag. 2011, 52, 15–26. [Google Scholar] [CrossRef]
- Akdağ, S.A.; Dinler, A. A new method to estimate Weibull parameters for wind energy applications. Energy Convers. Manag. 2009, 50, 1761–1766. [Google Scholar] [CrossRef]
- Werapun, W.; Tirawanichakul, Y.; Waewsak, J. Comparative study of five methods to estimate Weibull parameters for wind speed on Phangan Island, Thailand. Energy Procedia 2015, 79, 976–981. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, Y.J.; Liu, Z.Y. Study on the Maximum Entropy Principle applied to the annual wind speed probability distribution: A case study for observations of intertidal zone anemometer towers of Rudong in East China Sea. Appl. Energy 2014, 114, 931–938. [Google Scholar] [CrossRef]
- Li, T.; Griffiths, W.; Chen, J. Weibull modulus estimated by the non-linear least squares method: A solution to deviation occurring in traditional Weibull estimation. Metall. Mater. Trans. A 2017, 48, 5516–5528. [Google Scholar] [CrossRef]
- Seguro, J.; Lambert, T. Modern estimation of the parameters of the Weibull wind speed distribution for wind energy analysis. J. Wind. Eng. Ind. Aerodyn. 2000, 85, 75–84. [Google Scholar] [CrossRef]
- Cook, N.J. “Discussion on modern estimation of the parameters of the Weibull wind speed distribution for wind speed energy analysis” by J.V. Seguro, T.W. Lambert. J. Wind. Eng. Ind. Aerodyn. 2001, 89, 867–869. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimated Distribution | MAE | Entropy | |
|---|---|---|---|
| Gamma | 0.0775 | 0.0285 | 0.0303 |
| Exponential | 0.0375 | 0.0363 | 0.0872 |
| Weibull | 0.0470 | 0.0438 | 0.2026 |
| Weibull | 0.0403 | 0.0389 | 0.1755 |
| Weibull | 0.0471 | 0.0342 | 0.1471 |
| Methods | K | C |
|---|---|---|
| EM | 1.6469 | 0.7787 |
| MOM | 1.9125 | 0.7850 |
| MLE | 1.8005 | 0.7890 |
| MMLE | 2.0201 | 0.7758 |
| NLSM | 2.7767 | 0.7518 |
| MMEM | 2.6 | 1.7380 |
| Methods | RMSE | Chi-Square | Adjust | |
|---|---|---|---|---|
| EM | 0.286 | 0.0755 | 0.631 | 0.622 |
| MOM | 0.255 | 0.0691 | 0.670 | 0.663 |
| MLE | 0.278 | 0.1191 | 0.570 | 0.580 |
| MMLE | 0.274 | 0.0771 | 0.636 | 0.628 |
| NLSM | 0.194 | 0.2854 | 0.535 | 0.525 |
| MMEM | 0.0320 | 7.5687 × 10 | 0.995 | 0.995 |
| Patient | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 0.1637 | 0.1016 | 0.7175 | 0.1650 | 0.5959 | 1.0477 | |
| 0.0210 | 0.3688 | 0.1073 | 0.2079 | 0.1233 | 0.0072 | |
| Patient | 7 | 8 | 9 | 10 | 11 | 12 |
| 0.6309 | 0.7980 | 0.1085 | 0.4327 | 0.544 | 1.0225 | |
| 0.0701 | 0.3861 | 0.2377 | 0.0839 | 0.235 | 0.0271 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amini Farsani, Z.; Schmid, V.J. Modified Maximum Entropy Method and Estimating the AIF via DCE-MRI Data Analysis. Entropy 2022, 24, 155. https://doi.org/10.3390/e24020155
Amini Farsani Z, Schmid VJ. Modified Maximum Entropy Method and Estimating the AIF via DCE-MRI Data Analysis. Entropy. 2022; 24(2):155. https://doi.org/10.3390/e24020155
Chicago/Turabian StyleAmini Farsani, Zahra, and Volker J. Schmid. 2022. "Modified Maximum Entropy Method and Estimating the AIF via DCE-MRI Data Analysis" Entropy 24, no. 2: 155. https://doi.org/10.3390/e24020155
APA StyleAmini Farsani, Z., & Schmid, V. J. (2022). Modified Maximum Entropy Method and Estimating the AIF via DCE-MRI Data Analysis. Entropy, 24(2), 155. https://doi.org/10.3390/e24020155