
Similarity-Based Adaptive Window for Improving Classification of Epileptic Seizures with Imbalance EEG Data Stream


Abstract
1. Introduction
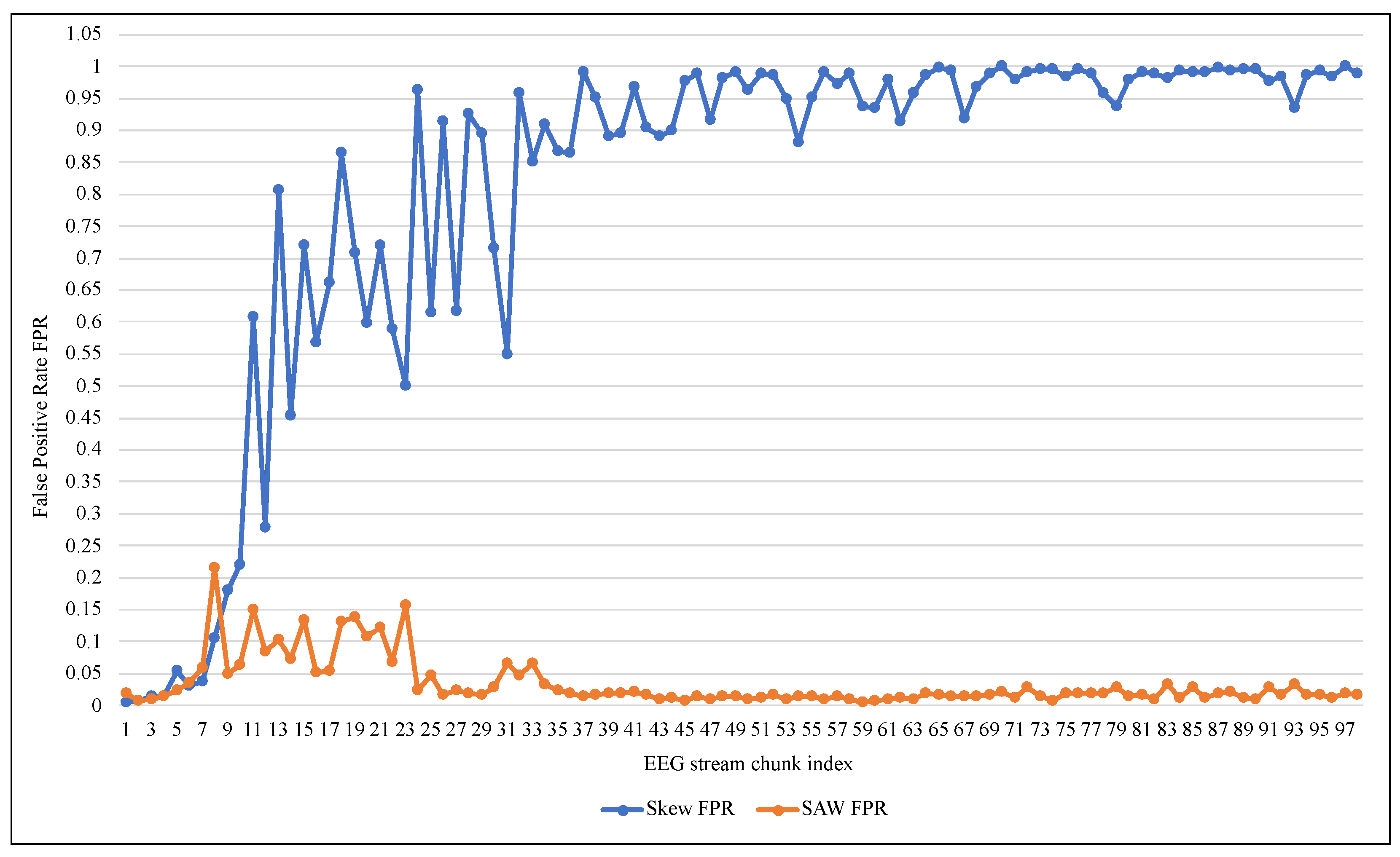
- Preserving the classifier’s ability to detect normal EEG signals by keeping all the data elements from the negative class without undersampling, thereby reducing false positive alarms.
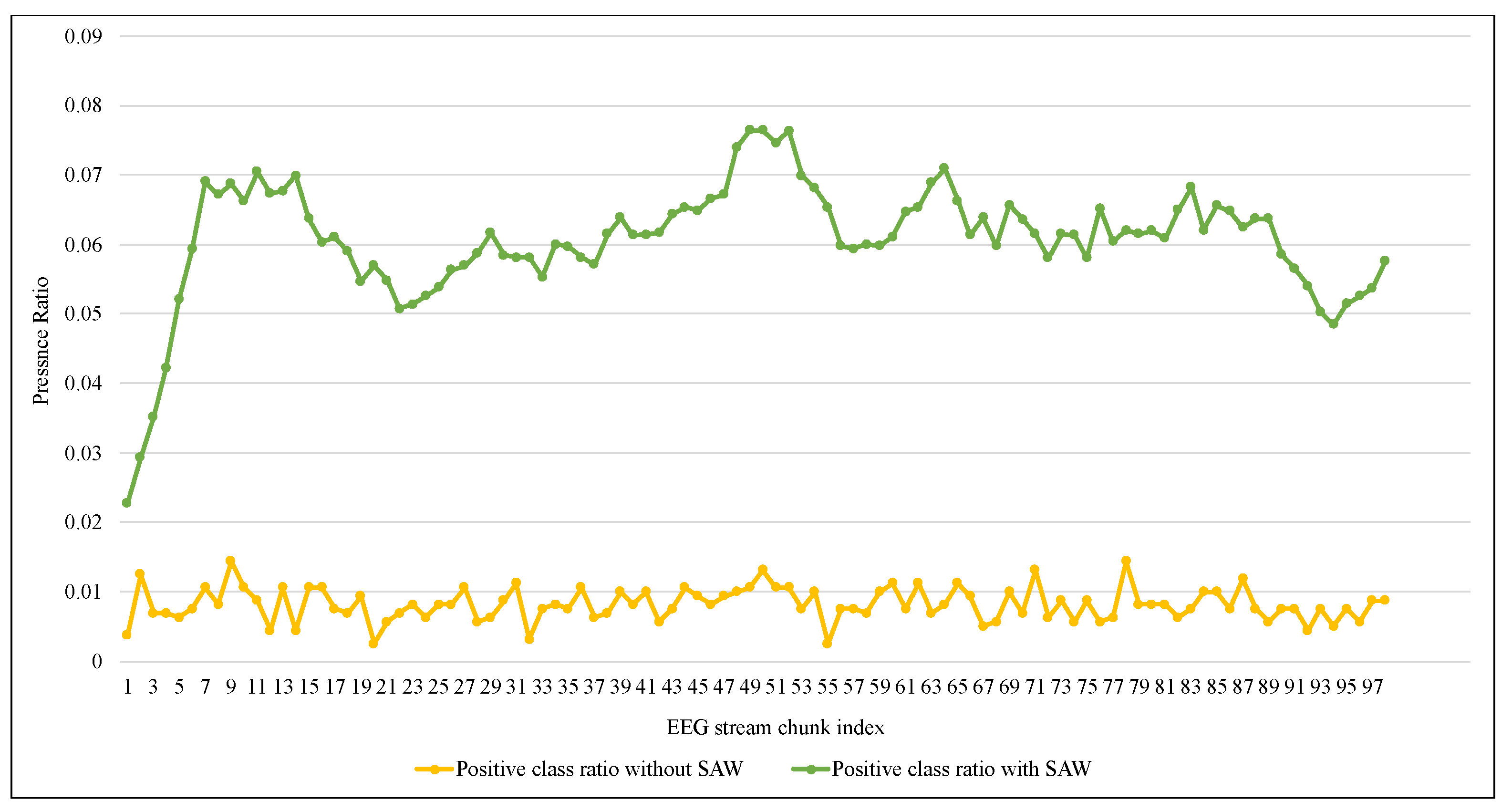
- Improving the classifier effectiveness for detecting the seizure signals by strengthening the presence of positive class within the current window using elements from the previous window. These items are selected based on their similarity to the current window’s items and their recency.
- Reducing the required computational resources for the proposed method by choosing the center of the current window as a representative point for calculating the similarity instead of all window items.
2. Literature Review
2.1. Imbalance EEG Data Stream
2.2. Adaptive Classification
2.3. Similarity Analysis
2.4. Evaluation of Classification Performance
2.5. Related Works
3. Methodology
3.1. EEG Stream Preprocesing
3.2. Similarity-Based Adaptive Window (SAW)
| Algorithm 1 SAW for imbalanced EEG. |
Input: EEG preprocessed data stream S, ATH ← Threshold of the maximum PIA
|
- Both current and previous windows have no positive instances (i.e., seizure signals), in this case the next steps of SAW will not be applied.
- Previous window does not have positive instances, then SAW next steps will not be applied and the current window instances will stay the same without any modification. As SAW is an accumulative procedure, this case can occur rarely.
- Current window does not have positive instances, then BRS will be formed directly from P(T-1) elements that have PIA < ATH.
- Both current and previous windows have positive instances, in this case SAW steps will be applied as in Algorithm 1.
3.3. ARF
- A base learner: the classification technique used to classify the targeted data. In this work, VFDT is utilized as a base learner. The ensemble size (i.e., number of base learners) and the size of the decision tree (i.e., number of terminal nodes) are user-defined parameters that affect the building ensemble model process.
- Resampling method: specify how to choose the data subset for each base learner. ARF utilizes online bagging that uses Poisson(1) distribution for this task.
- ADWIN for drift detection method. It has two parameters: Warning threshold and Drift threshold. Their task is to detect when ARF built a background tree and replace the current tree with it.
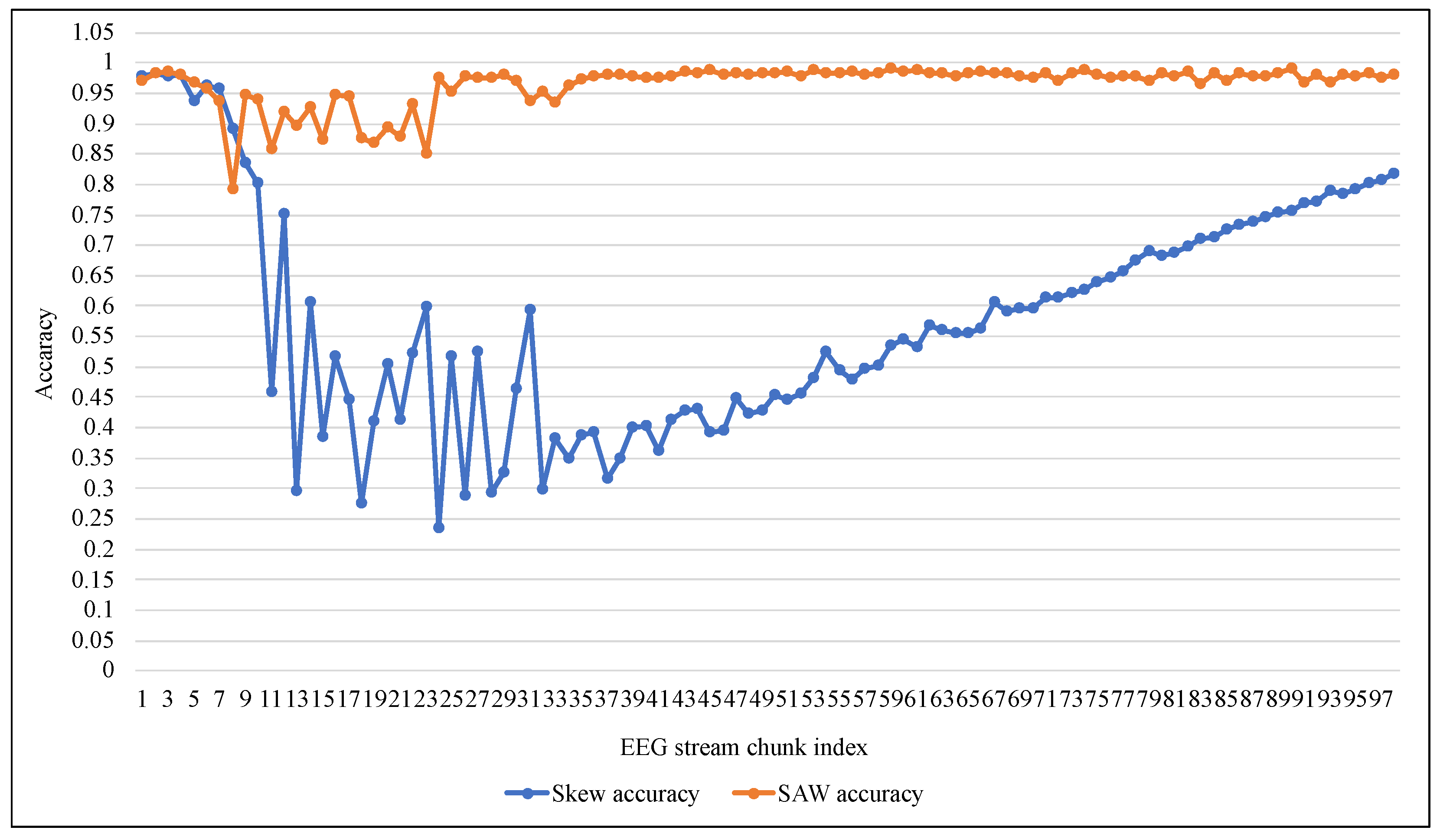
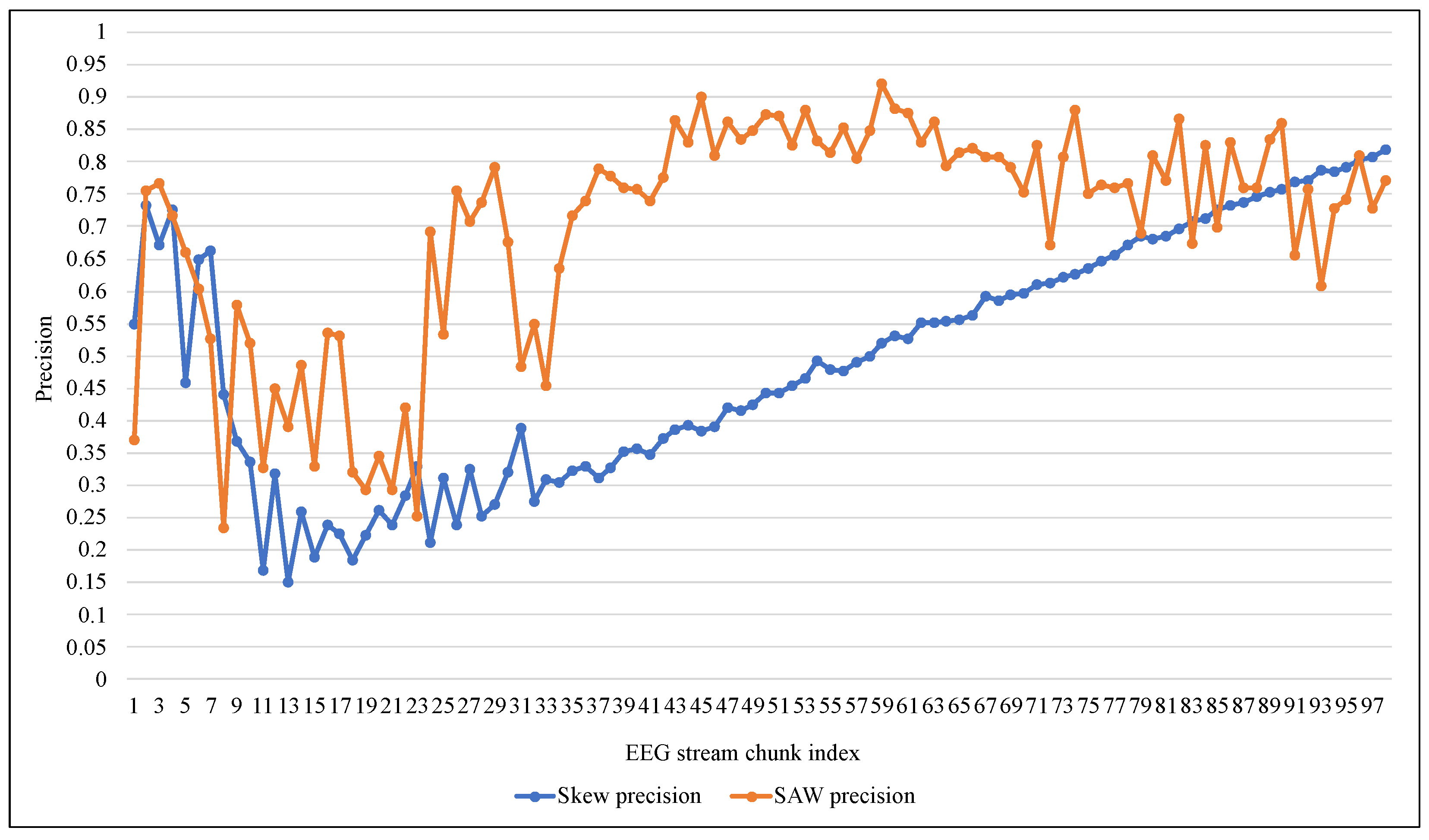
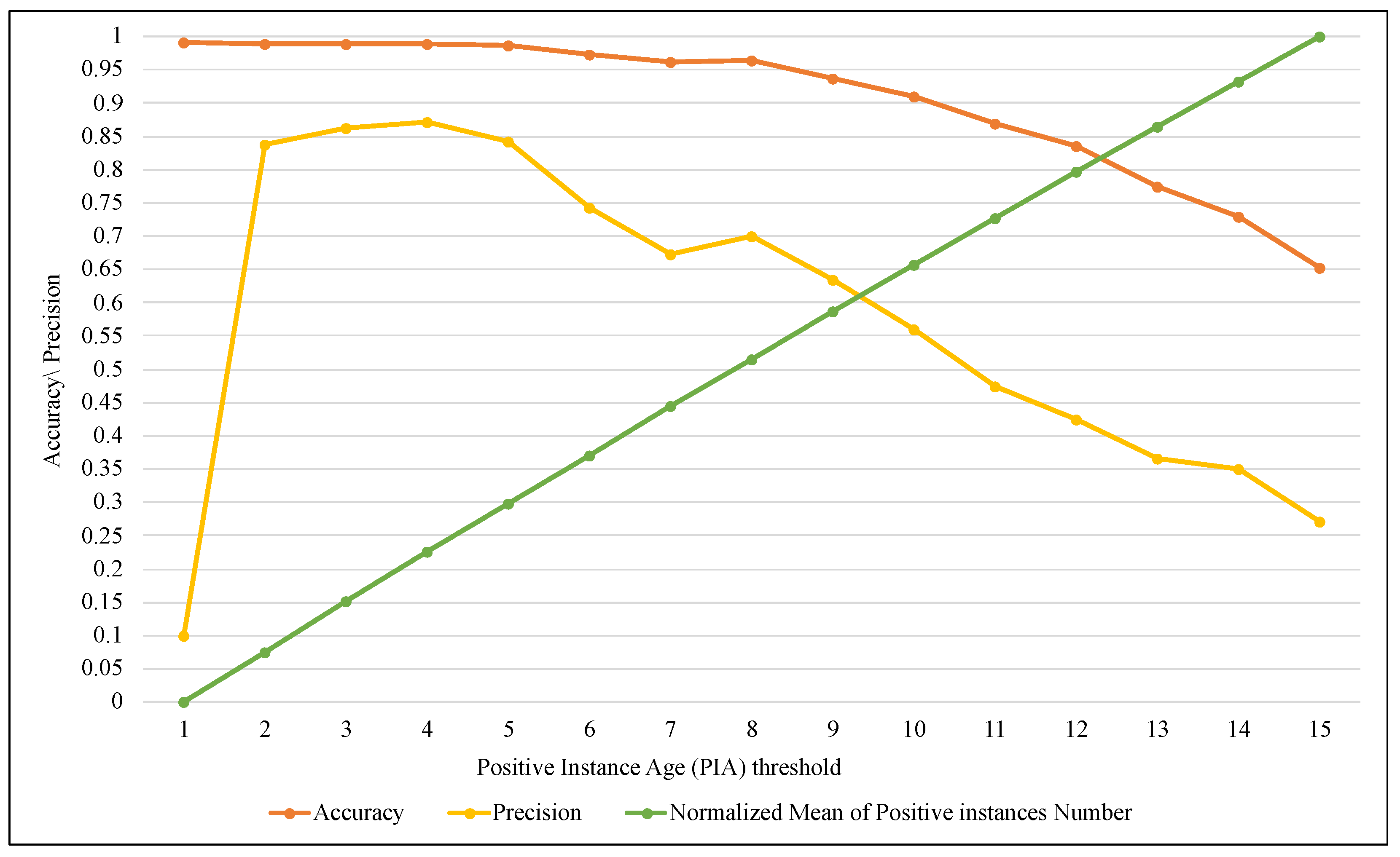
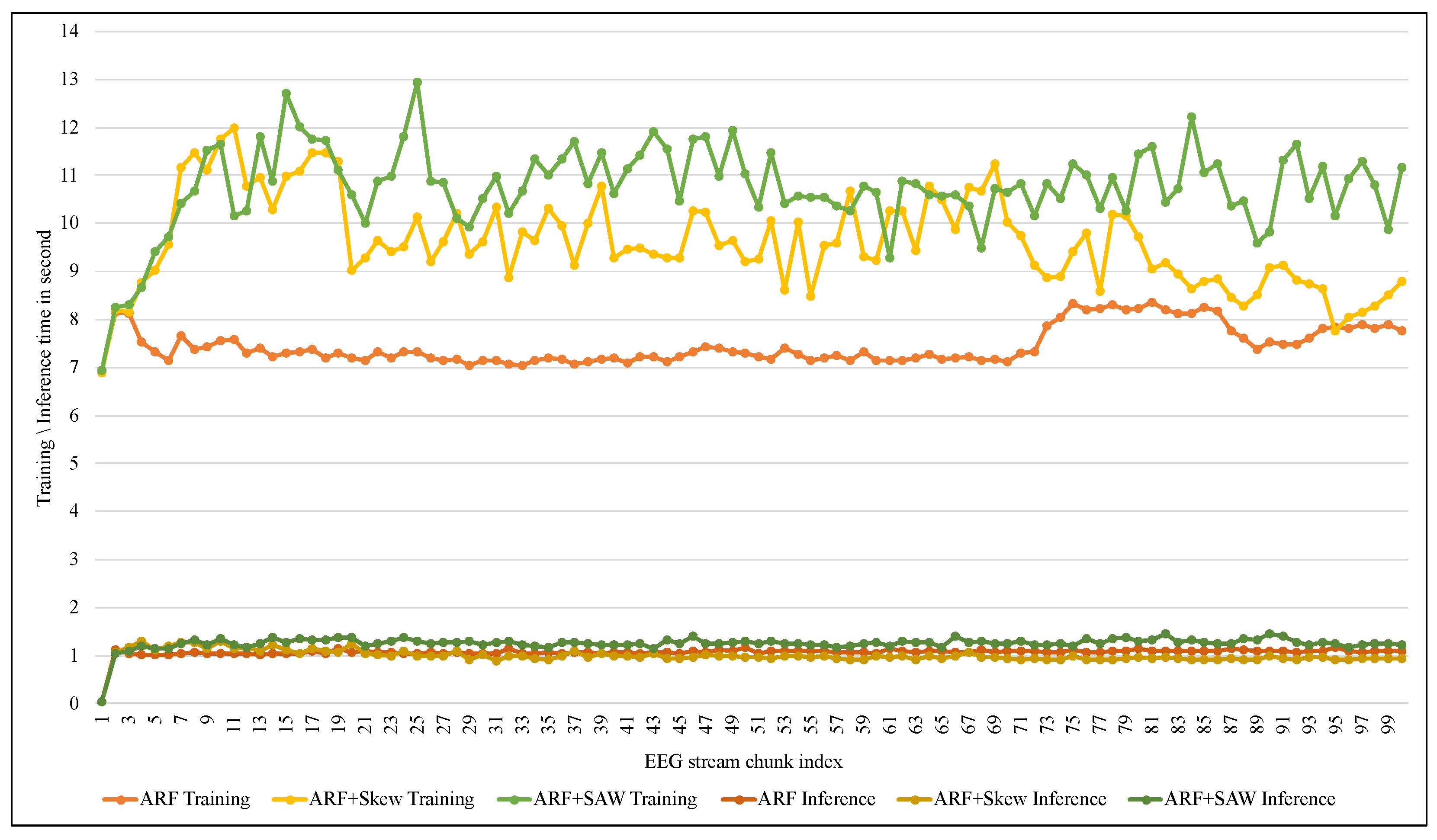
4. Implementation and Results
4.1. The Implementation Platform
4.2. Experiment Results
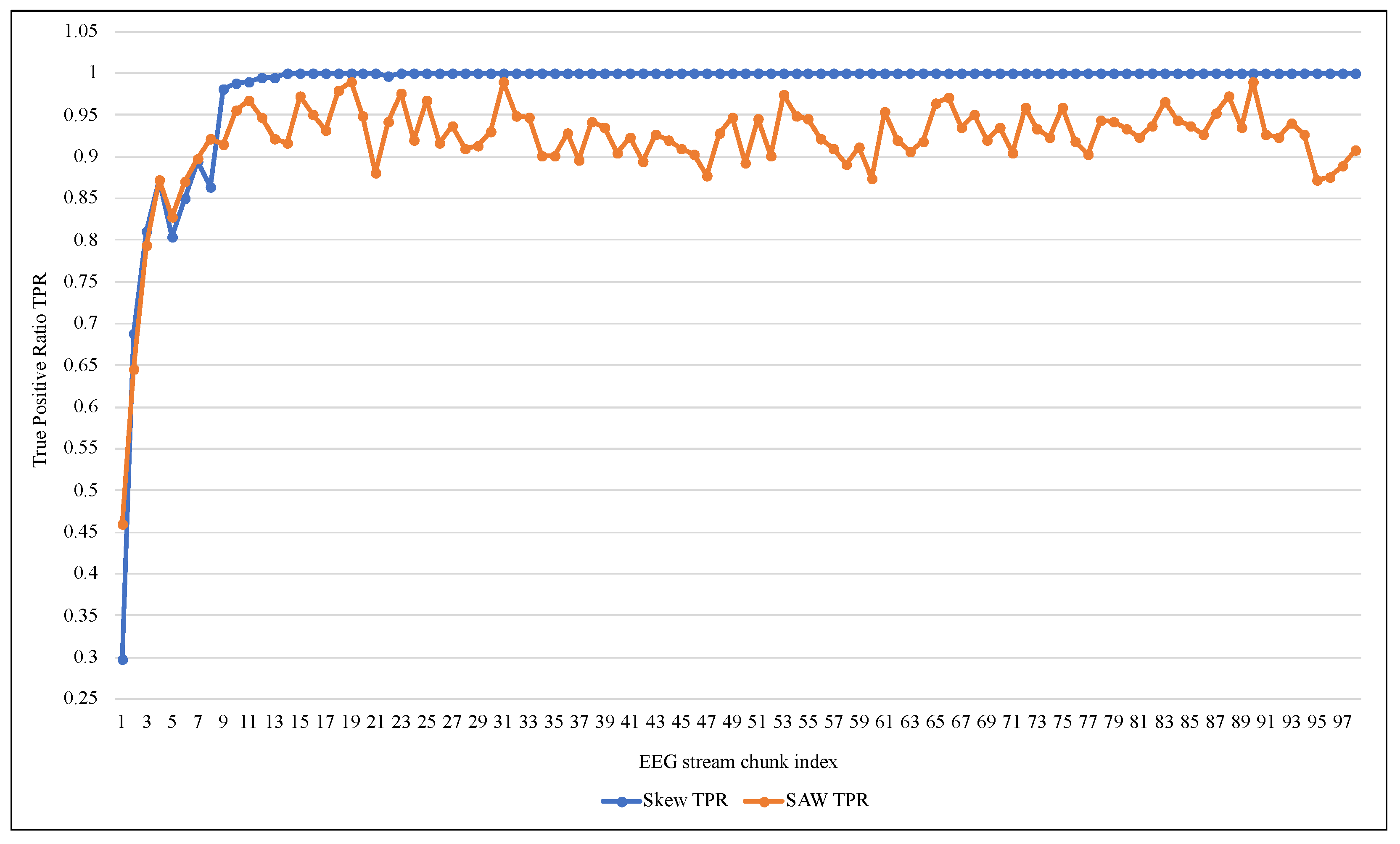
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EEG | Electroencephalography |
| FFT | Fast Fourier transform |
| DFT | Discrete Fourier Transform |
| ADWIN | ADaptive WINdowing |
| VFDT | Very Fast Decision Tree |
| EFDT | Extreme Fast Decision Tree |
| K-NN | K-Nearest Neighbor |
| SAW | Similarity-based Adaptive Window |
| BRS | Balance Rare-class Set |
| PIA | Positive Instance Age |
| ARF | Adaptive random forest |
| TNR | True Negative Rate |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| FNR | False Negative Rate |
References
- World Health Organization. Epilepsy. Key Facts . 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/epilepsy (accessed on 22 June 2022).
- Beghi, E.; Giussani, G.; Nichols, E.; Abd-Allah, F.; Abdela, J.; Abdelalim, A.; Abraha, H.N.; Adib, M.G.; Agrawal, S.; Alahdab, F.; et al. Global, regional, and national burden of epilepsy, 1990–2016: A systematic analysis for the Global Burden of Disease Study 2016. Lancet Neurol. 2019, 18, 357–375. [Google Scholar] [CrossRef]
- Meziani, A.; Djouani, K.; Medkour, T.; Chibani, A. A Lasso quantile periodogram based feature extraction for EEG-based motor imagery. J. Neurosci. Methods 2019, 328, 108434. [Google Scholar] [CrossRef]
- Von Bünau, P.; Meinecke, F.C.; Scholler, S.; Müller, K.R. Finding stationary brain sources in EEG data. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; pp. 2810–2813. [Google Scholar]
- Luján, M.Á.; Jimeno, M.V.; Mateo Sotos, J.; Ricarte, J.J.; Borja, A.L. A survey on eeg signal processing techniques and machine learning: Applications to the neurofeedback of autobiographical memory deficits in schizophrenia. Electronics 2021, 10, 3037. [Google Scholar] [CrossRef]
- Abdulkader, S.N.; Atia, A.; Mostafa, M.S.M. Brain computer interfacing: Applications and challenges. Egypt. Inform. J. 2015, 16, 213–230. [Google Scholar] [CrossRef]
- Alyasseri, Z.A.A.; Khader, A.T.; Al-Betar, M.A.; Papa, J.P.; Alomari, O.A. EEG feature extraction for person identification using wavelet decomposition and multi-objective flower pollination algorithm. IEEE Access 2018, 6, 76007–76024. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, T.; Li, T. Detecting epileptic seizures in EEG signals with complementary ensemble empirical mode decomposition and extreme gradient boosting. Entropy 2020, 22, 140. [Google Scholar] [CrossRef]
- Rechy-Ramirez, E.J.; Hu, H. Stages for Developing Control Systems Using EMG and EEG Signals: A Survey; School of Computer Science and Electronic Engineering, University of Essex: Essex, UK, 2011; pp. 1744–8050. [Google Scholar]
- Gama, J. Knowledge Discovery from Data Streams; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Online learning from imbalanced data streams. In Proceedings of the 2011 International Conference of Soft Computing and Pattern Recognition (SoCPaR), Dalian, China, 14–16 October 2011; pp. 347–352. [Google Scholar]
- Du, H.; Zhang, Y.; Gang, K.; Zhang, L.; Chen, Y.C. Online ensemble learning algorithm for imbalanced data stream. Appl. Soft Comput. 2021, 107, 107378. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10. [Google Scholar]
- Gao, J.; Fan, W.; Han, J.; Yu, P.S. A general framework for mining concept-drifting data streams with skewed distributions. In Proceedings of the 2007 Siam International Conference on Data Mining, Houston, TX, USA, 27–29 April 2007; SIAM: Philadelphia, PA, USA, 2007; pp. 3–14. [Google Scholar]
- Gao, J.; Ding, B.; Fan, W.; Han, J.; Philip, S.Y. Classifying data streams with skewed class distributions and concept drifts. IEEE Internet Comput. 2008, 12, 37–49. [Google Scholar] [CrossRef]
- Jenssen, S.; Gracely, E.J.; Sperling, M.R. How long do most seizures last? A systematic comparison of seizures recorded in the epilepsy monitoring unit. Epilepsia 2006, 47, 1499–1503. [Google Scholar] [CrossRef] [PubMed]
- Heckbert, P. Fourier transforms and the fast Fourier transform (FFT) algorithm. Comput. Graph. 1995, 2, 15–463. [Google Scholar]
- Ding, F.; Luo, C. The entropy-based time domain feature extraction for online concept drift detection. Entropy 2019, 21, 1187. [Google Scholar] [CrossRef]
- Rutkowski, L.; Jaworski, M.; Duda, P. Stream Data Mining: Algorithms and Their Probabilistic Properties; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Fatlawi, H.K.; Kiss, A. An Adaptive Classification Model for Predicting Epileptic Seizures Using Cloud Computing Service Architecture. Appl. Sci. 2022, 12, 3408. [Google Scholar] [CrossRef]
- Šulc, Z.; Řezanková, H. Comparison of similarity measures for categorical data in hierarchical clustering. J. Classif. 2019, 36, 58–72. [Google Scholar] [CrossRef]
- Bisandu, D.B.; Prasad, R.; Liman, M.M. Data clustering using efficient similarity measures. J. Stat. Manag. Syst. 2019, 22, 901–922. [Google Scholar] [CrossRef]
- Hwang, C.M.; Yang, M.S.; Hung, W.L. New similarity measures of intuitionistic fuzzy sets based on the Jaccard index with its application to clustering. Int. J. Intell. Syst. 2018, 33, 1672–1688. [Google Scholar] [CrossRef]
- Kang, Z.; Xu, H.; Wang, B.; Zhu, H.; Xu, Z. Clustering with similarity preserving. Neurocomputing 2019, 365, 211–218. [Google Scholar] [CrossRef]
- Óskarsdóttir, M.; Van Calster, T.; Baesens, B.; Lemahieu, W.; Vanthienen, J. Time series for early churn detection: Using similarity based classification for dynamic networks. Expert Syst. Appl. 2018, 106, 55–65. [Google Scholar] [CrossRef]
- Guo, Y.; Du, R.; Li, X.; Xie, J.; Ma, Z.; Dong, Y. Learning Calibrated Class Centers for Few-Shot Classification by Pair-Wise Similarity. IEEE Trans. Image Process. 2022, 31, 4543–4555. [Google Scholar] [CrossRef] [PubMed]
- Zha, D.; Lai, K.H.; Zhou, K.; Hu, X. Towards similarity-aware time-series classification. In Proceedings of the 2022 SIAM International Conference on Data Mining (SDM), Alexandria, VA, USA, 28–30 April 2022; SIAM: Philadelphia, PA, USA, 2022; pp. 199–207. [Google Scholar]
- Choi, S. Combined kNN Classification and hierarchical similarity hash for fast malware detection. Appl. Sci. 2020, 10, 5173. [Google Scholar] [CrossRef]
- Park, S.; Yuan, Y.; Choe, Y. Application of graph theory to mining the similarity of travel trajectories. Tour. Manag. 2021, 87, 104391. [Google Scholar] [CrossRef]
- Gazdar, A.; Hidri, L. A new similarity measure for collaborative filtering based recommender systems. Knowl.-Based Syst. 2020, 188, 105058. [Google Scholar] [CrossRef]
- Jiang, S.; Fang, S.C.; An, Q.; Lavery, J.E. A sub-one quasi-norm-based similarity measure for collaborative filtering in recommender systems. Inf. Sci. 2019, 487, 142–155. [Google Scholar] [CrossRef]
- Bag, S.; Kumar, S.K.; Tiwari, M.K. An efficient recommendation generation using relevant Jaccard similarity. Inf. Sci. 2019, 483, 53–64. [Google Scholar] [CrossRef]
- Feng, C.; Liang, J.; Song, P.; Wang, Z. A fusion collaborative filtering method for sparse data in recommender systems. Inf. Sci. 2020, 521, 365–379. [Google Scholar] [CrossRef]
- Fedoryszak, M.; Frederick, B.; Rajaram, V.; Zhong, C. Real-time event detection on social data streams. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2774–2782. [Google Scholar]
- Ding, Y.; Luo, W.; Zhao, Y.; Li, Z.; Zhan, P.; Li, X. A Novel Similarity Search Approach for Streaming Time Series. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2019; Volume 1302, p. 022084. [Google Scholar]
- Lei, R.; Wang, P.; Li, R.; Jia, P.; Zhao, J.; Guan, X.; Deng, C. Fast rotation kernel density estimation over data streams. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 892–902. [Google Scholar]
- Zhao, F.; Gao, Y.; Li, X.; An, Z.; Ge, S.; Zhang, C. A similarity measurement for time series and its application to the stock market. Expert Syst. Appl. 2021, 182, 115217. [Google Scholar] [CrossRef]
- Juszczuk, P.; Kozak, J.; Kania, K. Using similarity measures in prediction of changes in financial market stream data—Experimental approach. Data Knowl. Eng. 2020, 125, 101782. [Google Scholar] [CrossRef]
- Degirmenci, A.; Karal, O. Efficient density and cluster based incremental outlier detection in data streams. Inf. Sci. 2022, 607, 901–920. [Google Scholar] [CrossRef]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Data Sets; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Han, J.; Pei, J.; Tong, H. Data Mining: Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Ren, S.; Liao, B.; Zhu, W.; Li, Z.; Liu, W.; Li, K. The gradual resampling ensemble for mining imbalanced data streams with concept drift. Neurocomputing 2018, 286, 150–166. [Google Scholar] [CrossRef]
- Hu, J.; Yang, H.; King, I.; Lyu, M.R.; So, A.M.C. Kernelized online imbalanced learning with fixed budgets. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Dissanayake, T.; Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Geometric Deep Learning for Subject Independent Epileptic Seizure Prediction Using Scalp EEG Signals. IEEE J. Biomed. Health Inform. 2021, 26, 527–538. [Google Scholar] [CrossRef]
- Billeci, L.; Tonacci, A.; Varanini, M.; Detti, P.; de Lara, G.Z.M.; Vatti, G. Epileptic seizures prediction based on the combination of EEG and ECG for the application in a wearable device. In Proceedings of the 2019 IEEE 23rd International Symposium on Consumer Technologies (ISCT), Ancona, Italy, 19–21 June 2019; pp. 28–33. [Google Scholar]
- Li, Z.; Huang, W.; Xiong, Y.; Ren, S.; Zhu, T. Incremental learning imbalanced data streams with concept drift: The dynamic updated ensemble algorithm. Knowl.-Based Syst. 2020, 195, 105694. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Generalized class-specific kernelized extreme learning machine for multiclass imbalanced learning. Expert Syst. Appl. 2019, 121, 244–255. [Google Scholar] [CrossRef]
- Chen, B.; Xia, S.; Chen, Z.; Wang, B.; Wang, G. RSMOTE: A self-adaptive robust SMOTE for imbalanced problems with label noise. Inf. Sci. 2021, 553, 397–428. [Google Scholar] [CrossRef]
- Xie, X.; Liu, H.; Zeng, S.; Lin, L.; Li, W. A novel progressively undersampling method based on the density peaks sequence for imbalanced data. Knowl.-Based Syst. 2021, 213, 106689. [Google Scholar] [CrossRef]
- Gomes, H.M.; Bifet, A.; Read, J.; Barddal, J.P.; Enembreck, F.; Pfharinger, B.; Holmes, G.; Abdessalem, T. Adaptive random forests for evolving data stream classification. Mach. Learn. 2017, 106, 1469–1495. [Google Scholar] [CrossRef]
- Detti, P. Siena Scalp EEG Database (Version 1.0.0). PhysioNet. 2020. Available online: https://physionet.org/content/siena-scalp-eeg/1.0.0/ (accessed on 18 May 2022).
- Detti, P.; Vatti, G.; Zabalo Manrique de Lara, G. EEG Synchronization Analysis for Seizure Prediction: A Study on Data of Noninvasive Recordings. Processes 2020, 8, 846. [Google Scholar] [CrossRef]
- LightWAVE Viewer (Version 0.71). PhysioNet. Available online: https://physionet.org/lightwave/ (accessed on 30 October 2022).
- Last, M.; Bunke, H.; Kandel, A. Data Mining in Time Series and Streaming Databases. World Scientific: Singapore, 2018; Volume 83. [Google Scholar]
- Sánchez-Hernández, S.E.; Salido-Ruiz, R.A.; Torres-Ramos, S.; Román-Godínez, I. Evaluation of Feature Selection Methods for Classification of Epileptic Seizure EEG Signals. Sensors 2022, 22, 3066. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patient ID | File Name | Normal Signals Duration | Seizures Signals Duration | Seizures Signals Ratio |
|---|---|---|---|---|
| 1 | PN00-1, PN00-2, PN00-3, PN00-4, PN00-5 | 11581 | 315 | 0.0264 |
| 2 | PN01-1 | 12,000 | 55 | 0.0045 |
| 3 | PN03-2 | 11,581 | 74 | 0.0063 |
| 4 | PN05-2, PN05-3, PN05-4 | 21727 | 107 | 0.0049 |
| 5 | PN06-1, PN06-4, PN06-5 | 22662 | 147 | 0.0064 |
| 6 | PN07-1 | 12,000 | 63 | 0.0052 |
| 7 | PN09-1 | 8233 | 81 | 0.0097 |
| 8 | PN10-1 | 9982 | 70 | 0.0069 |
| 9 | PN11-1 | 8677 | 56 | 0.0064 |
| 10 | PN12-1 | 9774 | 64 | 0.0065 |
| 11 | PN13-1 | 9355 | 49 | 0.0052 |
| 12 | PN14-1 | 7868 | 28 | 0.0035 |
| 13 | PN16-1 | 8270 | 124 | 0.0147 |
| 14 | PN17-1 | 9277 | 71 | 0.0075 |
| Average | - | 11,641.93 | 93.14 | 0.0081 |
| Technique \Confusion Matrix | ARF | ARF + Skew | ARF+SAW | ||||
|---|---|---|---|---|---|---|---|
| Predicted Values | Predicted Values | Predicted Values | |||||
| Seizure | Normal | Seizure | Normal | Seizure | Normal | ||
| Actual values | Seizure | 0 | 14 | 668 | 7 | 95 | 7 |
| Normal | 0 | 1586 | 750 | 175 | 53 | 1534 | |
| Technique \Measure | TPR | TNR | FPR | FNR | Accuracy | Precision | F1-Score |
|---|---|---|---|---|---|---|---|
| ARF | 0.0067 | 0.9998 | 0.0001 | 0.9932 | 0.9912 | 0.0700 | 0.0122 |
| ARF + Skew | 0.9896 | 0.1891 | 0.8108 | 0.0103 | 0.5268 | 0.4710 | 0.6562 |
| ARF + SAW | 0.9313 | 0.9666 | 0.0333 | 0.0686 | 0.9644 | 0.6418 | 0.7600 |
| Technique \Measure | TPR | TNR | FPR | FNR | Accuracy | Precision | F1-Score |
|---|---|---|---|---|---|---|---|
| VFDT | 0.3981 | 0.9622 | 0.0378 | 0.6019 | 0.9276 | 0.5543 | 0.4633 |
| EFDT | 0.3522 | 0.7751 | 0.2249 | 0.6478 | 0.7487 | 0.3637 | 0.3578 |
| KNN | 0.7259 | 0.9515 | 0.0485 | 0.2741 | 0.9379 | 0.5001 | 0.5922 |
| ARF | 0.9313 | 0.9666 | 0.0333 | 0.0686 | 0.9644 | 0.6418 | 0.7600 |
| Research Work\Evaluation Metric | Accuracy | TPR (Sensitivity) | TNR (Specificity) |
|---|---|---|---|
| Dissanayake et al. [44] (2021) | 95.88 | 95.88 | 96.41 |
| Sánchez et al. [55] (2022) | 96 | 76 | - |
| SAW (the proposed method) | 96.44 | 93.13 | 96.66 |
| Technique/Time | Window Training | Instance Training | Window Inference | Instance Inference |
|---|---|---|---|---|
| ARF | 7.45588 | 0.00466 | 1.06275 | 0.00066 |
| ARF + Skew | 9.61430 | 0.00601 | 0.99271 | 0.00062 |
| ARF + SAW | 10.75906 | 0.00633 | 1.25258 | 0.00074 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fatlawi, H.K.; Kiss, A. Similarity-Based Adaptive Window for Improving Classification of Epileptic Seizures with Imbalance EEG Data Stream. Entropy 2022, 24, 1641. https://doi.org/10.3390/e24111641
Fatlawi HK, Kiss A. Similarity-Based Adaptive Window for Improving Classification of Epileptic Seizures with Imbalance EEG Data Stream. Entropy. 2022; 24(11):1641. https://doi.org/10.3390/e24111641
Chicago/Turabian StyleFatlawi, Hayder K., and Attila Kiss. 2022. "Similarity-Based Adaptive Window for Improving Classification of Epileptic Seizures with Imbalance EEG Data Stream" Entropy 24, no. 11: 1641. https://doi.org/10.3390/e24111641
APA StyleFatlawi, H. K., & Kiss, A. (2022). Similarity-Based Adaptive Window for Improving Classification of Epileptic Seizures with Imbalance EEG Data Stream. Entropy, 24(11), 1641. https://doi.org/10.3390/e24111641