1. Introduction
Rosenblatt [
1] studied elementary perceptrons (
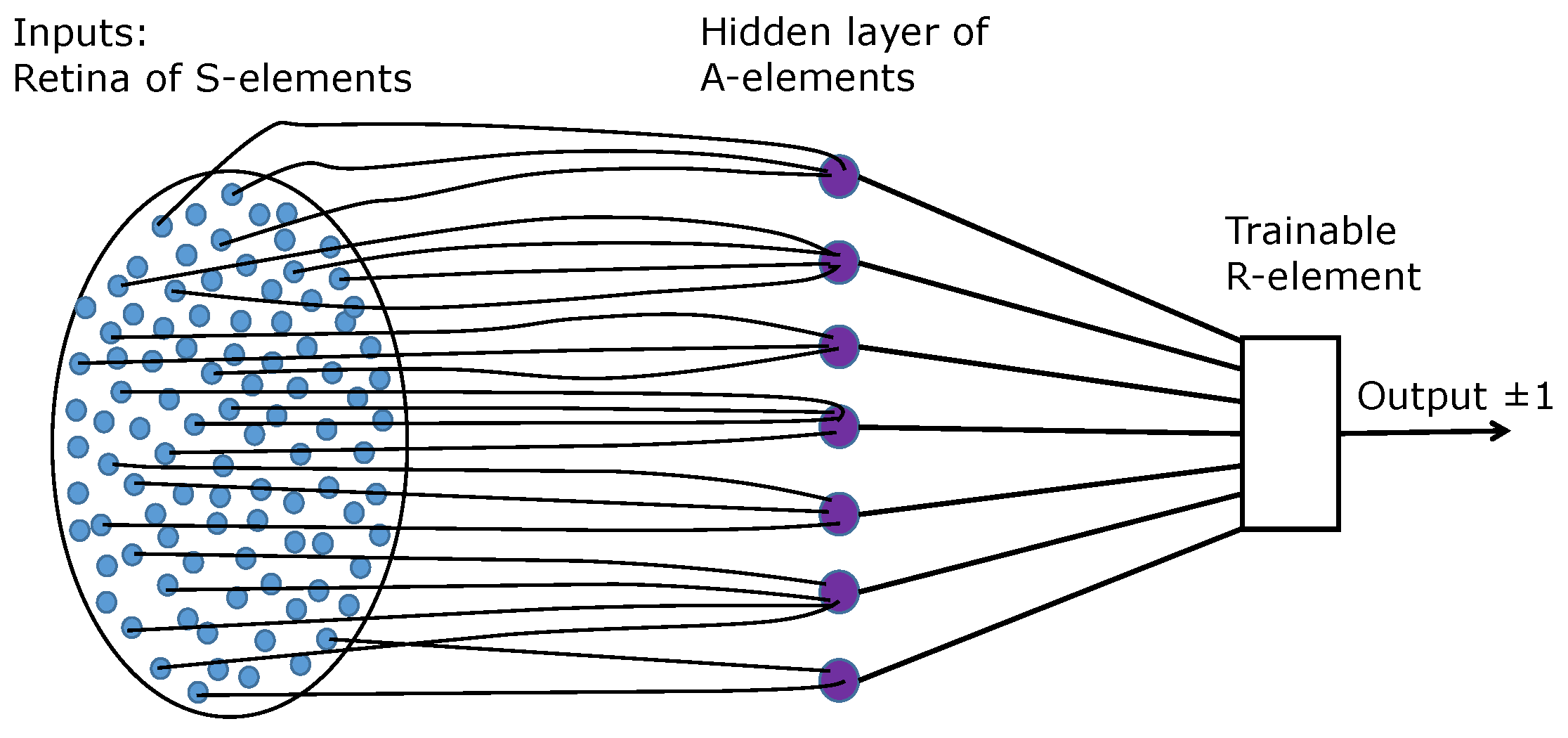
Figure 1).
A- and
R-elements are the classical linear threshold neurons. The
R-element is trainable by the Rosenblatt algorithm, while the
A-elements should represent a sufficient collection of features.
Rosenblatt assumed no restrictions on the choice of the
A-elements. He proved that the elementary perceptrons can separate any two non-intersecting sets of binary images (Rosenblatt’s first theorem in [
1]). The proof was very simple. For each binary image
x, we can create an
A-element
that produces output 1 for this image and 0 for all others. Indeed, let the input retina have
n elements and
be a binary vector (
or 1) with
k non-zero elements. The corresponding
A-element
has input synapses with weights
if
and
if
. For an arbitrary binary image
y,
and this sum is equal to 1 if and only if
. The threshold for the
output can be selected as
. Thus,
The set of neurons
created for all binary vectors
x transforms binary images into the vertexes of the standard simplex in
with coordinates
(
1). Any two non-intersecting subsets of the standard simplex can be separated by a hyperplane. Therefore, there exists an
R-element that separates them. According to the convergence theorem (Rosenblatt’s fourth theorem in [
1]), this
R-element can be found by the perceptron learning algorithm (a simple relaxation method for solving of systems of linear inequalities).
Thus, Rosenblatt’s first theorem is proven:
Theorem 1. An elementary perceptron can separate any two non-intersecting sets of binary images.
Of course, selection of the
A-elements in the proposed form
for all binary images is not necessary in the realistic applied classification problems. Sometimes, even an empty hidden layer can be used (the so-called linearly separable problems). Therefore, together with Rosenblatt’s first theorem, we obtain a problem about the reasonable (if not optimal) selection of
A-element. There are many frameworks for approaching this question, for example, the general feature selection algorithms: we generate (for example, randomly, or with some additional heuristics) a large set of
A-elements that is sufficient for solving the classification problem, and then select the appropriate set of features using different methods. For the bibliography about feature selection, we refer to recent reviews [
2,
3,
4].
The Minsky and Papert book
Perceptron [
5] was published seven years later than Rosenblatt’s book. They started from the restricted percetrons and assumed that each
A-element has a bounded receptive field (either by a pre-selected diameter or by the bounded number of inputs). Immediately, instead of Rosenblatt’s omnipotence of unrestricted perceptrons, they found that the elementary perceptron with such restrictions cannot solve some problems, such as the connectivity of the image or the parity of the number of pixels in it.
Minsky and Papert proposed various definitions of restrictions. The first was the definition of the local order of a predicate. A predicate
computed by an elementary perceptron is
conjunctively local of order k if each
A-element has only
k inputs (depends only on
k points) and
Minsky and Papert studied flat binary image predicates. The first theorem about a limited perceptron stated that if S is a square lattice, then the connectivity of an image is not a conjuctively local predicate of any order. Then they published a much deeper theorem without the condition of conjunctive form but for the bounded number of inputs of A-elements: the only topologically invariant predicates of finite order are functions of the Euler characteristic of the image (Michael Paterson Theorem). Then they mentioned: “It seems intuitively clear that the abstract quality of connectedness cannot be captured by a perceptron of finite order because of its inherently serial character: one cannot conclude that a figure is connected by any simple order-independent combination of simple tests.” The serial Turing machine serial algorithm for the connectivity test was presented with the evaluation of the necessary memory (the number of squares of the Turing tape): “For any there is a 2-symbol Turing machine that can verify the connectedness of a figure X on any rectangular array S, using less than squares of tape”. That is not very far from the deep multilayer perceptons with depth , but this step was not executed.
Minsky and Papert’s results were generalized to more general metric spaces and graphs [
6]. The heuristic behind these results is quite simple: if a human cannot solve the problem immediately at a glance and needs to apply some sequential operations such as counting pixels or following a tangled path, then this problem is not solvable by a restricted elementary perceptron.
At the same time, we can expect that the unrestricted elementary perceptron can solve this problem but at the cost of great (exponential?) complexity. Multilayer (“deep”) networks are expected to solve these problems without an explosion of complexity. In that sense, deep networks should be simpler than shallow networks for the problems that cannot be solved by restricted elementary perceptrons and require (from humans) a combination of parallel and sequential actions.
As we can see, there is no contradiction between the omnipotence of unrestricted perceptrons and the limited abilities of perceptrons with limitation. Moreover, there is a clear heuristic that allows us to find the problems of “inherently serial character” (following the Minsky and Papert comment). A human cannot solve such problems with one glance and needs some serial actions, such as following tangled paths.
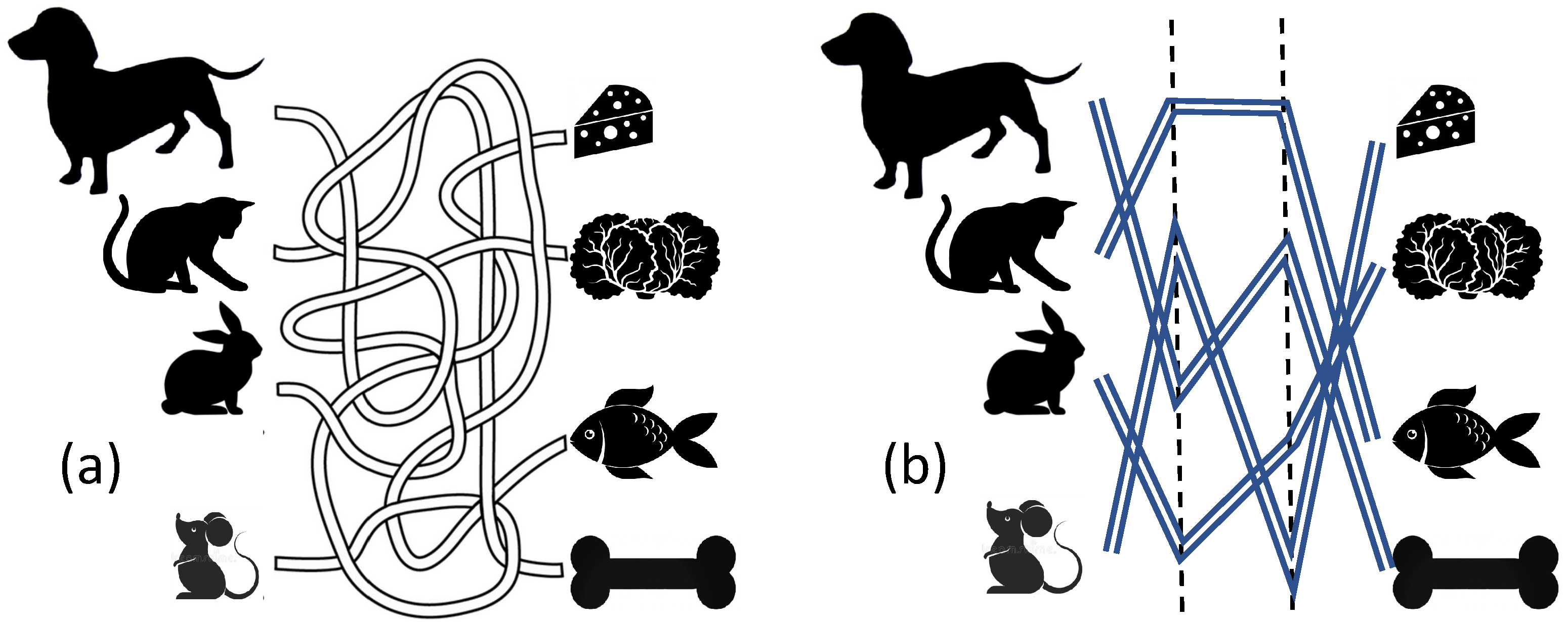
In this note, we demonstrate the relative simplicity of deep solvers on a version of the well-known travel maze problem (
Figure 2). This geometric problem is closely related to the connectivity problem and has been used for benchmarking in various areas of machine learning (see, for example, [
7]). The simplicity of the deep solution for this problem is not a miracle “because of its inherently serial character”. A human solves it following the paths along their length
L.
For formal analysis of the travel maze problem, we need to represent the paths on a discrete retina of
S-elements (
Figure 1). Then, to implement the logic of the proof of Rosenblatt’s first theorem, each
A-element should be an indicator element for a possible path. For each guest-delicacy pair in
Figure 2a or
Figure 2b, an elementary perceptron must be created that returns 1 if there is a path from this guest to this delicacy, and 0 if there are no such paths. Thus,
elementary perceptrons should be created. We can easily combine them in a shallow network with
outputs. To finalize the formal statement, we should specify the set of the possible paths. In our work, we select a very simple specification without loops, steps back or non-transversal intersections of paths (
Figure 2b).
2. Formal Problem Statement
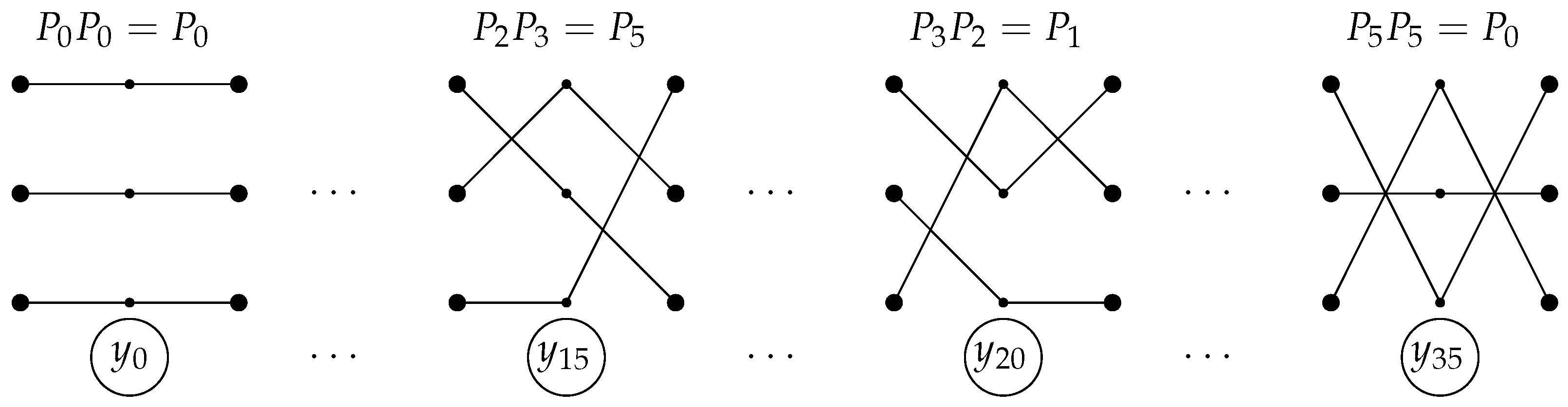
Consider the following problem. There are
n people, each of whom owns a single object from the set
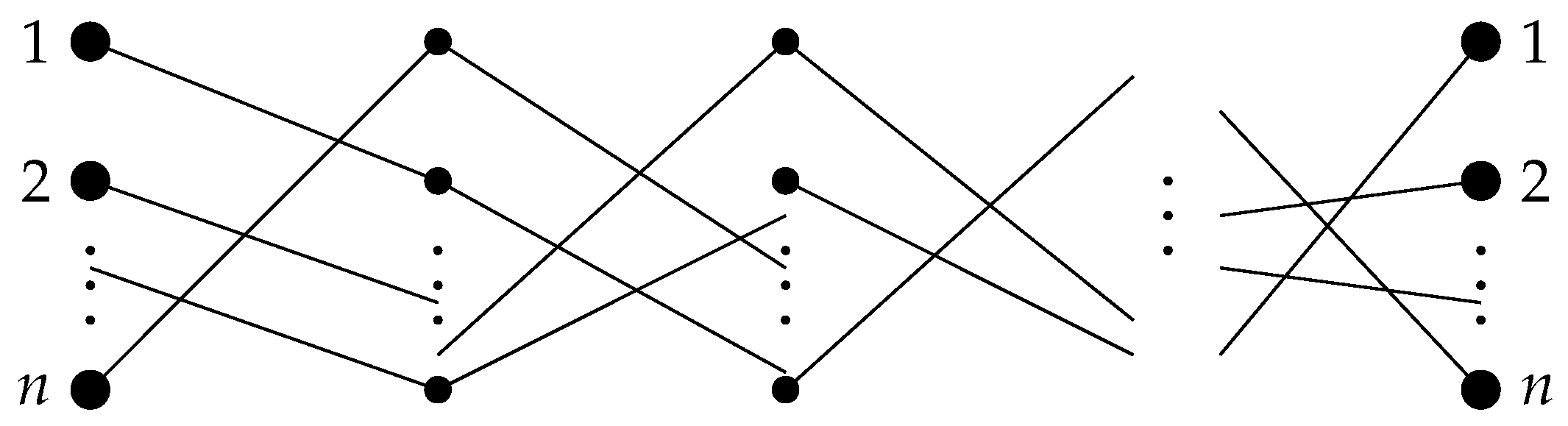
and different people that own different objects. This correspondence between people and objects can be drawn as a diagram consisting of
n broken lines, each of which contains
L links (
Figure 3). Each stage of the diagram consists of
n links and can be encoded by a permutation or, equivalently, by a permutation matrix in a natural way. Namely, if an edge is drawn from node
i to node
then the permutation can be represented in the form
or by the permutation matrix
where
If the permutation matrix
corresponds to the
i-th stage, then the product
is the permutation matrix again, and it defines the correspondence “person–object”. It is required to construct a shallow (fully connected) neural network that determines the correspondence “person–object” from the diagram.
We formally model a simplified version of the travel maze problem as follows. Each travel maze problem is an L-tuple of bijective functions (permutations) from to Denote by the set of such L-tuples. The composition of these functions from an L-tuple is also a bijective function to that one-to-one associates objects with persons. Thus, the set of all simplified versions of the travel maze problem is the set In addition, the set is a union of classes of L-tuples, each of which corresponds to the same product
When building the neural network for a travel maze problem, we want each neuron of the neural network to have Boolean values. In particular, each neuron of the next layer is a Boolean function of the neurons of the previous layer.
3. Shallow Neural Network Solution
Arrange all the permutations Then, is the set of the corresponding permutation matrices.
We denote the entries of the matrix
by
where
and the other entries are equal to
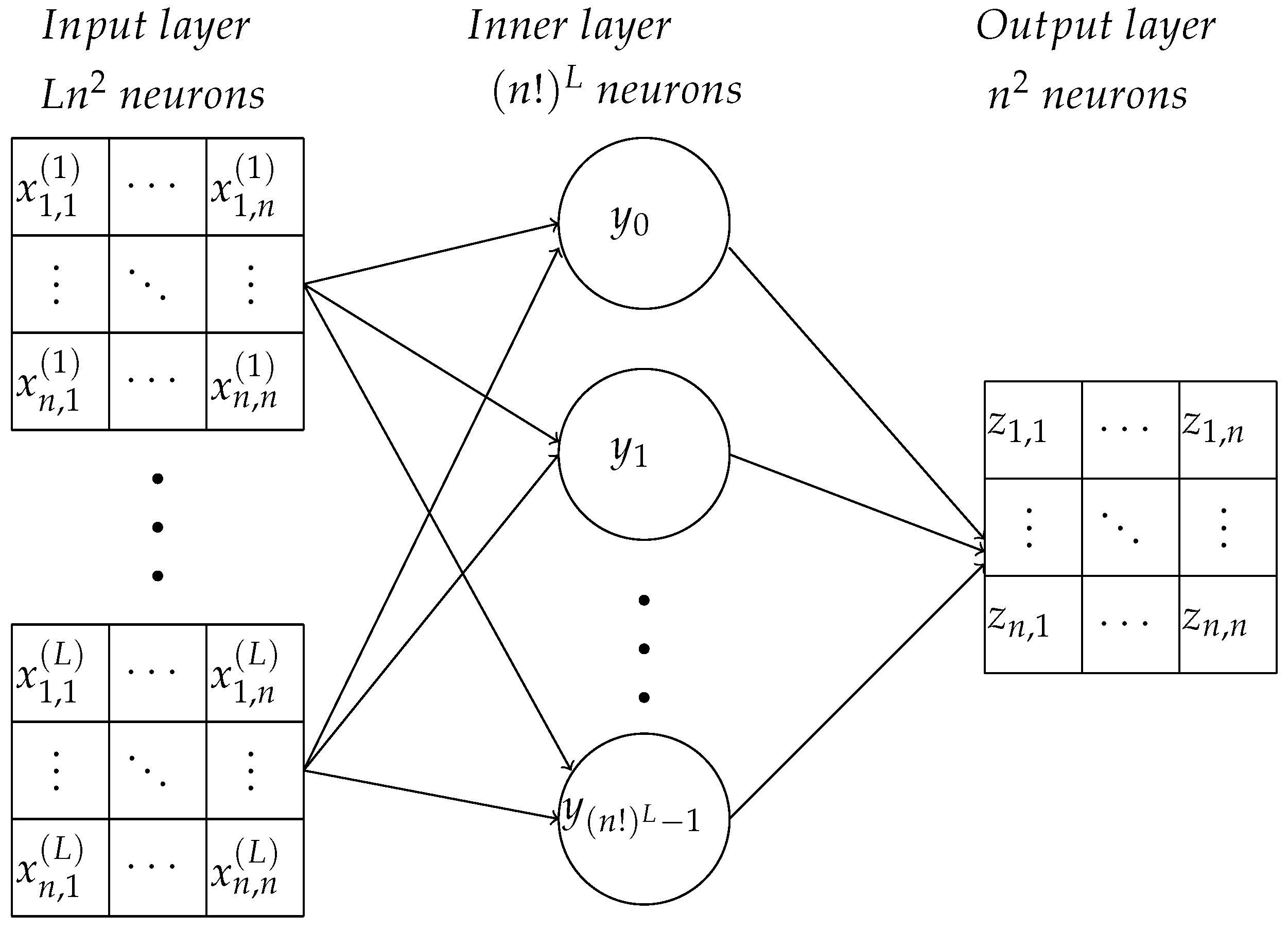
Let an L-tuple ( for all ) be an L-tuple (a word of length L) over the set of permutation matrices M. The number of such permutation matrices is , and the number of L-tuples with elements from M is . Consider all such words arranged by the lexicographical order. For each word with the number j, we assign the same number to the product . The matrix is also an permutation matrix.
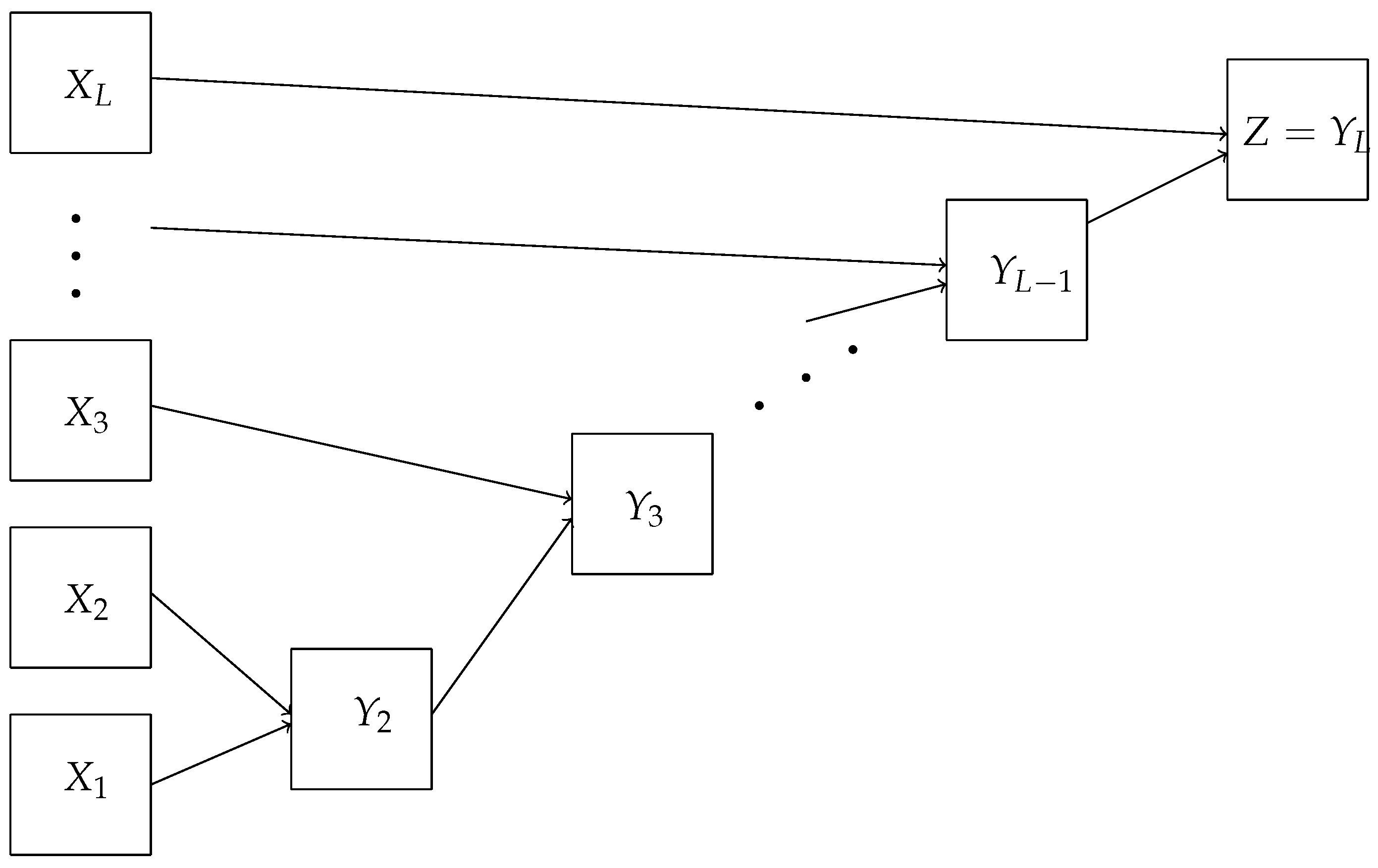
Entries of matrices
are inputs of the neural network (see
Figure 4). Each input corresponds to an input neuron (
S-element,
Figure 1). An inner layer
A-neuron
corresponds to the
L-tuple
having the same number
j. The neuron
should give the output signal 1 if the input vector is
and output 0 for all other
possible input vectors. Other input vectors are impossible in our settings (
Figure 4). Each matrix element of every permutation matrix
is either 0 or 1; therefore, the
L-tuples star of output connections of the inner neuron can be coded as a 0–1 sequence, that is a vertex of the
-dimensional unit cube. (Apparently, there are more vertices than
L-tuples of permutation matrices). This cube is a convex body, and each vertex can be separated from all other vertices by a linear functional. In particular, for each
j, we can find a linear functional
such that
and
(
,
). Here we, with some abuse of language, use the same notation for the tuple
and the correspondent vertex of the cube (a 0–1 sequence of the length
). Thus, each inner neuron
can be chosen in the form of the linear threshold element with the output signal (compare to (
1) and Theorem 1):
where
h is the Heaviside step function. We use for the output of the neuron
the same notation
.
The structural difference of the shallow network (
Figure 4) for the travel maze problem from the elementary perceptron (
Figure 1) is the number of neurons in the output layer. For the travel maze problem, the answer is the permutation matrix with
0–1 elements. The inner layer neuron
detects the
L-tuple of one-step permutation matrices
. When this input vector is detected,
sends the output signal 1 to the output neurons connected with it. For all other input vectors, it keeps silent. The output neurons are simple linear adders. The output neurons
are labelled by pairs of indexes,
. The matrix of outputs is the permutation matrix from the start to the end of the travel. The structure of the output connections of
is determined by the input
L-tuple
: the connection from
to
has weight 1 if the corresponding entry
and is 0 if
. (Recall that
).
Thus, the neuron
corresponds to our problem answer. Let us represent the network functioning in more detail with explicit algebraic presentations. All the inputs and outputs are Boolean (0–1) variables. We use the standard Boolean algebra notations. In particular,
Thus, if
is a neuron of the inner layer, then it corresponds to the product
where
is the expansion of
j in the base
Denote
Note that
.
Each neuron
of the inner layer for
corresponds to the same product
:
The third level neurons
form the matrix
that is the answer to this problem:
Since
then the right-hand side in the equality (
2) contains exactly
terms
Theorem 2. For travel maze problems there is a shallow neural network that has a depth of neurons andconnections between them. The constructed network memorizes products in all L-tuples of permutation matrices, recognizes the input L-tuple of permutations, and sends the product to the output.
Example 1. Consider (Figure 5). ThenFor example, we have for ; therefore,We can write similar expressions for all other In this case, we have and so Example 2. Let (Figure 6). Then| · | | | | | | | |
| | | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
For example, we have for , so We can write similar expressions for the other
6. Conclusions and Outlook
A shallow neural network combined from elementary Rosenblatt’s perceptrons can solve the travel maze problem in accordance with Rosenblatt’s first theorem.
The complexity of the constructed solution of the travel maze problem for a deep network is much smaller than for the solution provided by the shallow network (the main terms are versus for the numbers of neurons and versus for the numbers of connections).
The first result is important in the context of the widespread myth that elementary Rosenblatt’s perceptrons have limited abilities and that Minsky and Papert revealed these limitations. This mythology has penetrated even into the encyclopedic literature [
8].
Original Rosenblatt’s perceptrons [
1] (
Figure 1) can solve any problem regarding the classification of binary images and, after minor modification, even wider. This simple fact was proven in Rosenblatt’s first theorem, and nobody criticised this theorem and proof. The universal representation property of shallow neural networks were studied in the 1990s from different points of view, including the approximation of real-valued functions [
9] and the evaluation of upper bounds on rates of approximation [
10]. Elegant analysis of shallow neural networks involved infinite-dimensional hidden layers [
11], and upper bounds were derived on the speed of decrease of approximation error as the number of network units increases. Abilities and limitations of shallow networks were reviewed recently in detail [
12].
Of course, a single
R-element can solve only linearly separable problems, and, obviously, not all problems are linearly separable. Stating this trivial statement does not require any intellectual effort. Minsky and Papert [
5] considered much more complex systems then a single linear threshold
R-element. They studied the same elementary perceptrons that Rosenblatt did (
Figure 1) with one restriction:
receptive fields of A-elements are bounded. These limitations may assume a sufficiently small diameter of the receptive field (the most common condition) or a limited number of input connections of each
A-neuron. Elementary perceptrons with such restrictions have limited abilities: if we have only local information, then we cannot solve such a global problem as checking the connectivity of a set or the travel maze problem with one glance. We should integrate the local knowledge into global criterion using a sequence of steps. This intuitively clear statement was accurately formalised and proved for the parity problem by Minsky and Papert [
5].
Without restrictions, elementary perceptrons are omnipotent. In particular, they can solve the travel maze problem in the proposed form, but the complexity of solutions can be huge (Theorem 2). On the contrary, the deep network solution (Theorem 3) is much simpler and seems to be much more natural. It combines solutions from the one-step permutations locally, step by step, whereas the shallow network operates by all possible global paths. Restriction of the possible paths of travel by a bounded radius of a single step (
Section 5) does not change the situation qualitatively. (The restricted problem is simpler than the original one. This should not be confused with the
A-elements’ receptive field limitations proposed by Minsky and Papert [
5] that complicate all problems.)
The second observation seems to be more important than the first one: the properly selected deep solutions can be much simpler than the shallow solutions. In contrast to the widely discussed huge deep structures and their surprising efficiency (see the detailed exposition of the mathematics of deep learning in [
13]) the relatively small but deep neural networks are non-surprisingly effective for the solution of problems where local information should be integrated into global decisions, such as in the discussed version of the travel maze problem. These networks combine the benefits of the fine-grained parallel procession and the solutions of problems at a glance with the possibility of emulating logic of sequential data analysis when it is necessary. The important question in this context is: “How deep should be the depth?” [
14]. The answer depends on the problem.
Comparing a
lower bound on the complexity of shallow networks with an
upper bound on the complexity of deep networks for travel maze problem will provide a much deeper result than our theorems. We have not yet been able to obtain the lower complexity bound of shallow networks for travel maze problems. In this paper, our goal was more modest: we compared the Rosenblatt’s first theorem “at work” with the obvious sequential deep algorithm of depth of order
L. The solution of the simplified travel maze problem is equivalent to the computation of the product of
L permutation matrices
. The algorithm of depth
L is equivalent to the parenthesization
. Other parenthesizations can easily produce algorithms of lower depth of order
. For example, for eight matrices, we can group multiplications as follows:
. It is obvious that the minimal depth achievable by parenthesization for products of
L square matrices growths with
L as
. (The theory of optimal parenthesization of rectangular matrix chain products is well-developed; see, for example, [
15] and references there.) The
problem is in the optimal computation of permutation matrix chain products with the depth independent of
L. Is there any algorithm better than memorising the answers and the recognition of the input chains without any real computation of products? In other words, is there an algorithm that provides significantly more efficient solutions to the travel maze problem than the proof of Rosenblatt’s first theorem does?
Thus, the open question remains: are the complexity estimates sharp? How far are our solutions from the best ones? We do not expect that this problem has a simple solution because even for multiplication of
matrices, no final solution has yet been found, despite great efforts and significant progress (to the best of our knowledge, the latest improvement from
to
was achieved recently [
16]).
Another open question might attract attention: analysing the original geometric travel maze problem (see
Figure 2 instead of its more algebraic simplification presented in
Figure 3). It includes many non-trivial tasks, for example, convenient discrete representation of the possible paths with bounded curvature, lengths and ends, and the constructive selection of
-networks in the space of such paths for preparing the input weights of
A-elements.
Analysis of more realistic cases with differential paths and a possibility of stepping back requires geometric and topological methods. Differential paths with bounded curvature
k and lengths
l form a compact set
in the space of continuous paths equipped by the standard
metrics
. A paths with its
-vicinity form a strip that we see in
Figure 2a. Each strip has its smooth mean path. We assume that the strips do not intersect beyond small neighborhoods of several isolated points of mean paths intersections. The
-network in the set
and metrics
is finite. For an empirically given path, we have to find the closest paths from this
-network. The additional challenge is in the discretization of the input information. We should present the paths as the broken lines on a grid. The selection of the grid should allow us to resolve the intersections. For reliable recognition, an assumption of the minimal possible angle
of mean path intersections or self-intersections is needed. After that, one can use the logic of Rosenblatt’s first theorem and produce an elementary perceptron for solving the travel maze problem in this continuous setting. The perceptron construction and weights will depend on
k,
l,
, and
. The detailed solution is beyond the scope of our paper.
The travel maze problem is discussed as a prototype problem for mobile robot navigation [
17,
18]. There exist universal “Elastic Principal Graph” (ElPiGraph) algorithms and open access software for the analysis of the raw image [
7]. These algorithms were applied to the very new areas of data mining: they were used for revealing disease trajectories and dynamic phenotyping [
19] and for the analysis of single-cell data for outlining the cell development trajectories [
20] The travel maze problem in its differential settings (
Figure 2a) was used as a benchmark for the ElPiGraph algorithm that untangles the complex paths of the maze [
7].
The complexities of functions computable by deep and shallow networks used for the solution of the classification problem were compared for the same complexity of networks [
21]. The complexities of the functions were measured using topological invariants of the superlevel sets. The results seem to support the idea that deep networks can address more difficult problems with the same number of resources.
The problem of effective parallelism pretends to be the central problem that is being solved by the whole of neuroinformatics [
22]. It has long been known that the efficiency of parallel computations increases slower than the number of processors. There is a well known “Minsky hypothesis”: the efficiency of a parallel system increases (approximately) proportionally to the logarithm of the number of processors; at the least, it is a concave function. Shallow neural networks pretend to solve all problems in one step, but the cost for that may be an enormous number of resources. Deep networks make possible a trade-off between resources (number of elements) and the time needed to solve a problem since they can combine the efficient parallelism of neural networks with elements of sequential reasoning. Therefore, neural networks can be a useful tool for solving the problem of efficient fine-grained parallel computing if we can answer the question: how deep should the depths be for different classes of problems? The case study presented in our note gives an example of a significant increase in efficiency for a reasonable choice of depth.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
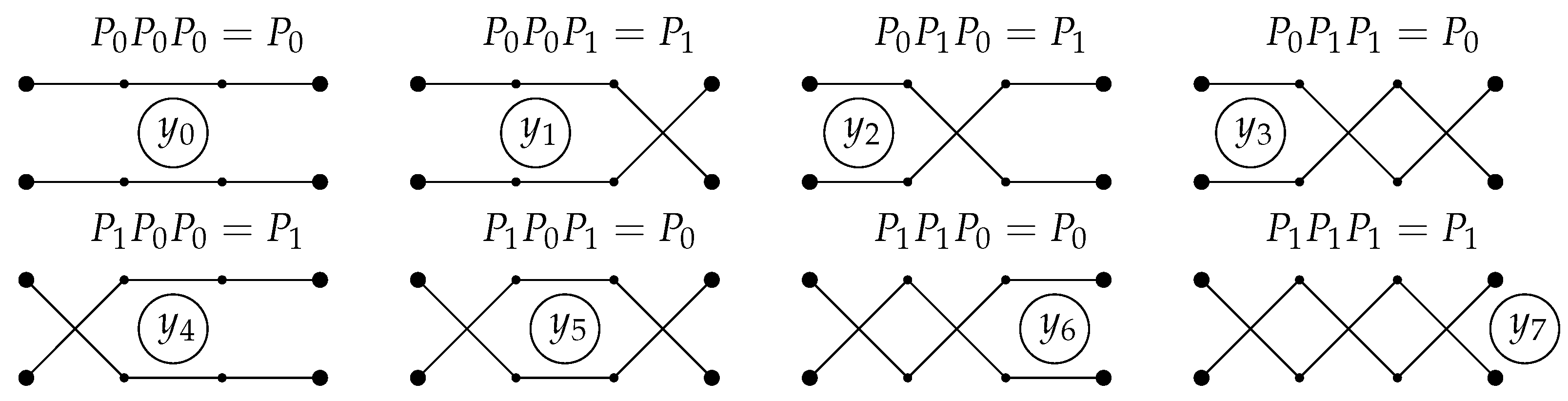{kind=link}
{kind=link}
{kind=link}






