
Node Importance Identification for Temporal Networks Based on Optimized Supra-Adjacency Matrix

Abstract
1. Introduction
2. Preliminaries
3. Description of the OSAM Temporal Network Modeling Method
3.1. Expression of Intra-Layer Relationships
3.2. Expression of Inter-Layer Relationships
3.3. Modeling the Optimized Supra-Adjacency Matrix
3.4. Calculation of the Eigenvector Centrality
4. Experimental Analysis
4.1. Data Sets
4.2. Evaluation Method
4.2.1. Evaluation Based on the Spreading Model
4.2.2. Evaluation based on Correlation
4.3. Experimental Results
4.3.1. Message Transmission Capability of Nodes in a Temporal Network
4.3.2. Quality of the Node Importance Sorted List
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Huang, Q.J.; Zhao, C.L.; Zhang, X.; Wang, X.J.; Yi, D.Y. Centrality measures in temporal networks with time series analysis. EPL Europhys. Lett. 2017, 118, 36001. [Google Scholar] [CrossRef]
- Ai, X. Node importance ranking of complex networks with entropy variation. Entropy 2017, 19, 303. [Google Scholar] [CrossRef]
- Fu, Y.J.; Yang, Y.Y.; Zhao, M.M.; Zhang, J.L.; Xie, G. Node importance evaluation for multilayer temporal network based on node similarity biased walk. Sci. Technol. Eng. 2020, 20, 10301–10307. [Google Scholar]
- Bonacich, P. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 35–41. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888–893. [Google Scholar] [CrossRef]
- Ren, X.L.; Lü, L.Y. Review of ranking nodes in complex networks (in Chinese). Chin. Sci. Bull. (Chin. Ver.) 2014, 59, 1175–1197. [Google Scholar] [CrossRef]
- Hu, G.; Xu, L.P.; Xu, X. Identification of important nodes based on dynamic evolution of inter-layer isomorphism rate in temporal networks. Acta Phys. Sin. 2021, 70, 108901. [Google Scholar] [CrossRef]
- Yang, J.N.; Liu, J.G.; Guo, Q. Node importance idenfication for temporal network based on inter-layer similarity. Acta Phys. Sin. 2018, 67, 048901. [Google Scholar] [CrossRef]
- Chen, S.; Ren, Z.M.; Liu, C.; Zhang, Z.K. Identification Methods of Vital Nodes on Temporal Networks. J. Univ. Electron. Sci. Technol. China 2020, 49, 291–314. [Google Scholar]
- Kim, H.; Anderson, R. Temporal node centrality in complex networks. Phys. Rev. E 2012, 85, 026107. [Google Scholar] [CrossRef] [PubMed]
- Yu, E.Y.; Fu, Y.; Chen, X.; Xie, M.; Chen, D.B. Identifying critical nodes in temporal networks by network embedding. Sci. Rep. 2020, 10, 12494. [Google Scholar] [CrossRef] [PubMed]
- Takaguchi, T.; Yano, Y.; Yoshida, Y. Coverage centralities for temporal networks. Eur. Phys. J. B 2016, 89, 35. [Google Scholar] [CrossRef]
- Ye, Z.H.; Zhan, X.X.; Zhou, Y.Z.; Liu, C.; Zhang, Z.K. Identifying Vital Nodes on Temporal Networks: An Edge-Based K-Shell Decomposition. In Proceedings of the 36th Chinese Control Conference, Dalian, China, 26–28 July 2017. [Google Scholar]
- Qu, C.; Zhan, X.; Wang, G.; Wu, J.; Zhang, Z.K. Temporal information gathering process for node ranking in time-varying networks. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 033116. [Google Scholar] [CrossRef]
- Ogura, M.; Preciado, V.M. Katz centrality of Markovian temporal networks: Analysis and optimization. In Proceedings of the 2017 American Control Conference, Seattle, DC, USA, 24–26 May 2017. [Google Scholar]
- Luo, L.; Tao, L.; Yuan, Z.Y.; Lai, H.; Zhang, Z.L. An Information Theory Based Approach for Identifying Influential Spreaders in Temporal Networks. In Proceedings of the International Symposium on Cyberspace Safety and Security, Xi’an, China, 23–25 October 2017. [Google Scholar]
- Guo, Q.; Yin, R.R.; Liu, J.G. Node importance identification for temporal networks via the TOPSIS method. J. Univ. Electron. Sci. Technol. China 2019, 48, 296–300. [Google Scholar]
- Assari, A.; Mahesh, T.; Assari, E. Role of public participation in sustainability of historical city: Usage of TOPSIS method. Indian J. Sci. Technol. 2012, 5, 2289–2294. [Google Scholar] [CrossRef]
- Taylor, D.; Myers, S.A.; Clauset, A.; Porter, M.A.; Mucha, P.J. Eigenvector-based centrality measures for temporal networks. Multiscale Model. Simul. 2017, 15, 537–574. [Google Scholar] [CrossRef]
- Jiang, J.L.; Fang, H.; Li, S.Q.; Li, W.M. Identifying important nodes for temporal networks based on the ASAM model. Phys. A Stat. Mech. Its Appl. 2022, 586, 126455. [Google Scholar] [CrossRef]
- Ferreira, A. Building a reference combinatorial model for MANETs. IEEE Netw. 2004, 18, 24–29. [Google Scholar] [CrossRef]
- Michail, O. An introduction to temporal graphs: An algorithmic perspective. Internet Math. 2016, 12, 239–280. [Google Scholar] [CrossRef]
- Liu, J.G.; Ren, Z.M.; Guo, Q.; Wang, B.H. Node importance ranking of complex networks. Acta Phys. Sin. 2013, 62, 178901. [Google Scholar]
- Boulicaut, J.F.; Esposito, F.; Giannotti, F.; Pedreschi, D. Machine Learning: ECML. In Proceedings of the 2004 15th European Conference on Machine Learning, Pisa, Italy, 20–24 September 2004. [Google Scholar]
- Paranjape, A.; Benson, A.R.; Leskovec, J. Motifs in temporal networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017. [Google Scholar]
- Génois, M.; Vestergaard, C.L.; Fournet, J.; Panisson, A.; Bonmarin, I.; Barrat, A. Data on face-to-face contacts in an office building suggest a low-cost vaccination strategy based on community linkers. Netw. Sci. 2015, 3, 326–347. [Google Scholar] [CrossRef]
- Liu, L.L.; Tan, Z.Y.; Shu, J. Node Importance Estimation Method for Opportunistic Network Based on Graph Neural Networks. J. Comput. Res. Dev. 2022, 59, 834–851. [Google Scholar]
- López, M.; Peinado, A.; Ortiz, A. An extensive validation of a SIR epidemic model to study the propagation of jamming attacks against IoT wireless networks. Comput. Netw. 2019, 165, 106945. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
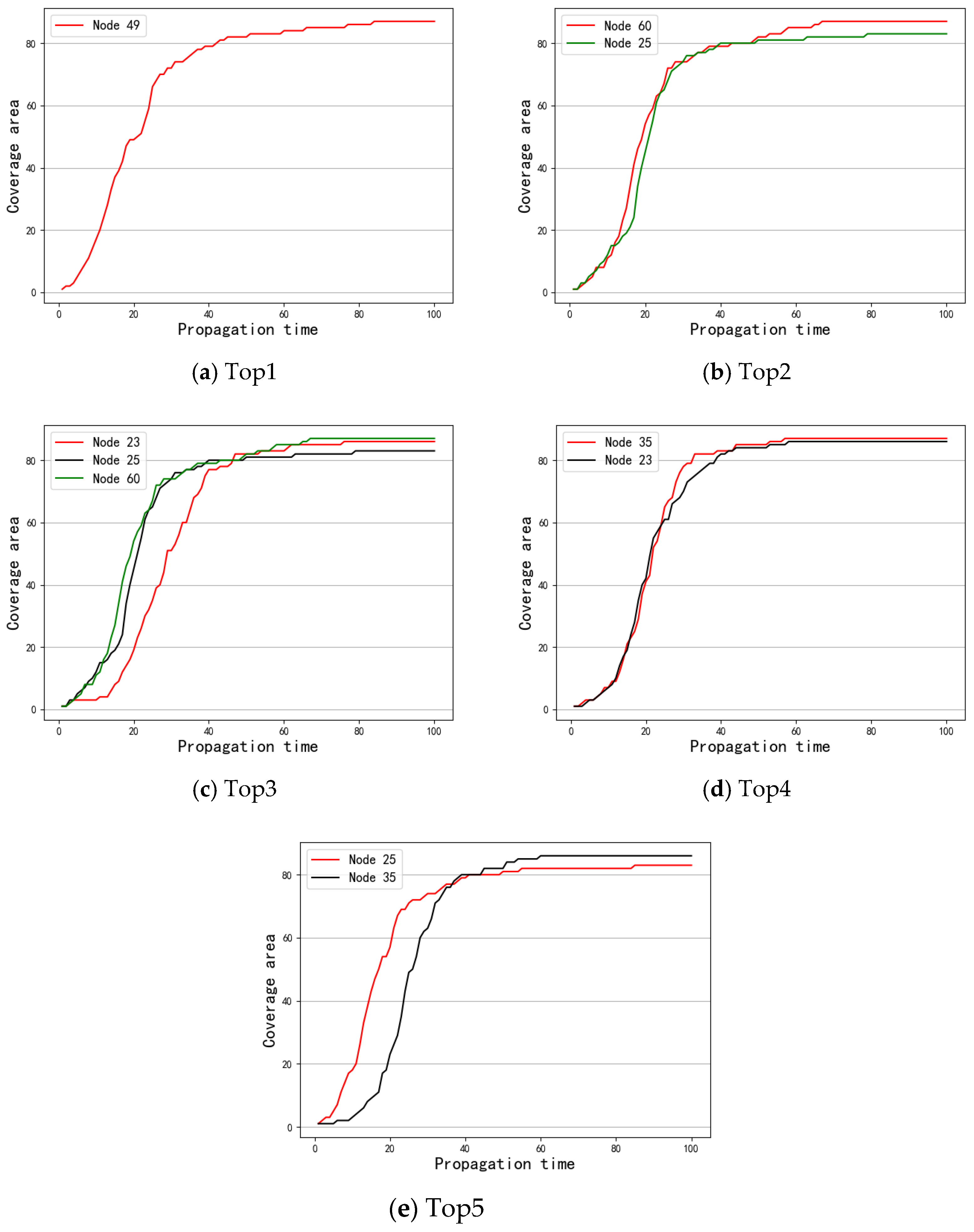{kind=link}
{kind=link}
| Data Set | N | C | Time Span | T |
|---|---|---|---|---|
| Enron | 151 | 33,124 | 1 year | 12 |
| Emaildept3 | 89 | 12,216 | 802 days | 9 |
| Workspace | 92 | 9287 | 6/24/–7/3, 2013 | 10 |
| Method | Top1 | Top2 | Top3 | Top4 | Top5 | S |
|---|---|---|---|---|---|---|
| SAM | 107 | 127 | 129 | 51 | 92 | |
| SSAM | 107 | 127 | 51 | 19 | 91 | |
| OSAM | 127 | 107 | 129 | 51 | 65 |
| Method | Top1 | Top2 | Top3 | Top4 | Top5 | S |
|---|---|---|---|---|---|---|
| SAM | 49 | 60 | 25 | 23 | 35 | |
| SSAM | 49 | 25 | 60 | 23 | 35 | |
| OSAM | 49 | 60 | 23 | 35 | 25 |
| Method | Top1 | Top2 | Top3 | Top4 | Top5 | S |
|---|---|---|---|---|---|---|
| SAM | 73 | 15 | 59 | 38 | 28 | |
| SSAM | 73 | 15 | 59 | 38 | 52 | |
| OSAM | 28 | 15 | 73 | 52 | 38 |
| Enron | Emaildept3 | Workspace | |||
|---|---|---|---|---|---|
| Method | NCDG@10 | Method | NCDG@10 | Method | NCDG@10 |
| SAM | 0.5556 | SAM | 0.3433 | SAM | 0.3677 |
| SSAM | 0.6074 | SSAM | 0.4881 | SSAM | 0.4383 |
| OSAM | 0.6481 | OSAM | 0.6622 | OSAM | 0.5376 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, R.; Zhang, S.; Zhang, D.; Zhang, X.; Bao, X. Node Importance Identification for Temporal Networks Based on Optimized Supra-Adjacency Matrix. Entropy 2022, 24, 1391. https://doi.org/10.3390/e24101391
Liu R, Zhang S, Zhang D, Zhang X, Bao X. Node Importance Identification for Temporal Networks Based on Optimized Supra-Adjacency Matrix. Entropy. 2022; 24(10):1391. https://doi.org/10.3390/e24101391
Chicago/Turabian StyleLiu, Rui, Sheng Zhang, Donghui Zhang, Xuefeng Zhang, and Xiaoling Bao. 2022. "Node Importance Identification for Temporal Networks Based on Optimized Supra-Adjacency Matrix" Entropy 24, no. 10: 1391. https://doi.org/10.3390/e24101391
APA StyleLiu, R., Zhang, S., Zhang, D., Zhang, X., & Bao, X. (2022). Node Importance Identification for Temporal Networks Based on Optimized Supra-Adjacency Matrix. Entropy, 24(10), 1391. https://doi.org/10.3390/e24101391