

Assessing, Testing and Estimating the Amount of Fine-Tuning by Means of Active Information


{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Fine-Tuning
- (i)
- Establishing the life-permitting interval (LPI) A that allows the existence of life for the constant, with or denoting the range of values that this constant could possibly take, including those that do not permit life.
- (ii)
- Determining the probability of such a LPI. If contains unknown parameters , find an upper boundof .
- (iii)
- Suppose that corresponds to an agent who uses background knowledge of what is required for life to exist in order to bring about a constant of nature X that definitely permits life (). The active information is then a measure of how much background knowledge this agent has infused. Following [26,27], we conclude that X is finely tuned when the lower bound of is large enough. That is, FT corresponds to infusing a high degree of background knowledge into a problem.
- (a)
- It has an independent specification;
- (b)
- It is very unlikely to occur by chance.
1.2. The Present Article
2. Specificity and Target
Interpretation of Target
3. Active Information for Exponentially Tilted Systems
3.1. Exponential Tilting
3.2. Metropolis–Hastings Systems with Exponential Tilting Equilibrium
3.3. Active Information for Metropolis–Hastings Systems in Non-Equilibrium
3.4. Active Information for Metropolis–Hastings Systems with Stopping
4. Estimating Active Information and Testing Fine-Tuning
4.1. Null Distribution Known
4.1.1. Nonparametric Estimator and Test
4.1.2. Parametric Estimator and Test
4.1.3. Comparison between Nonparametric and Parametric Estimates of Actinfo
4.2. Null Distribution Unknown
4.2.1. One Sample Available
4.2.2. Two Samples Available
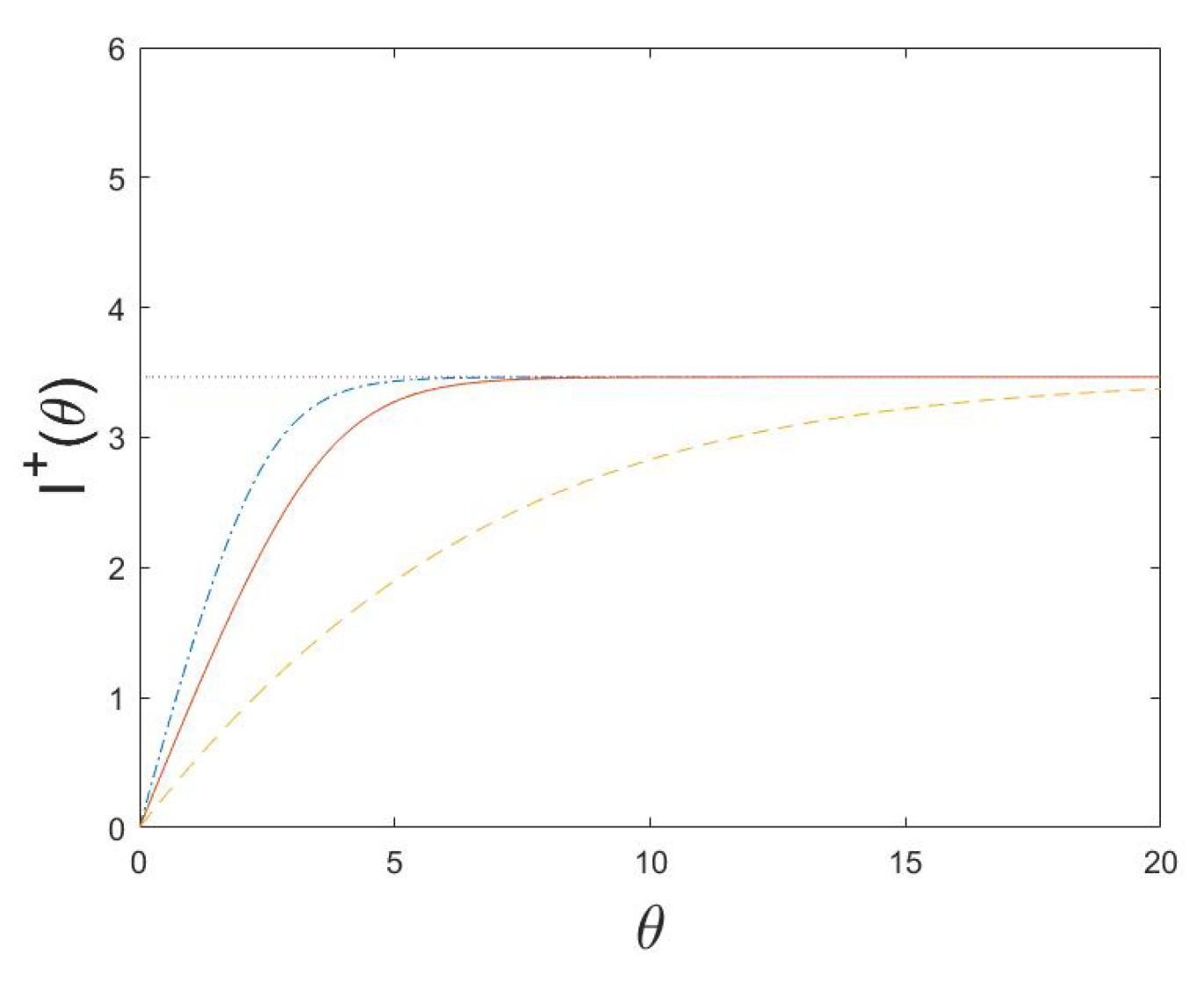
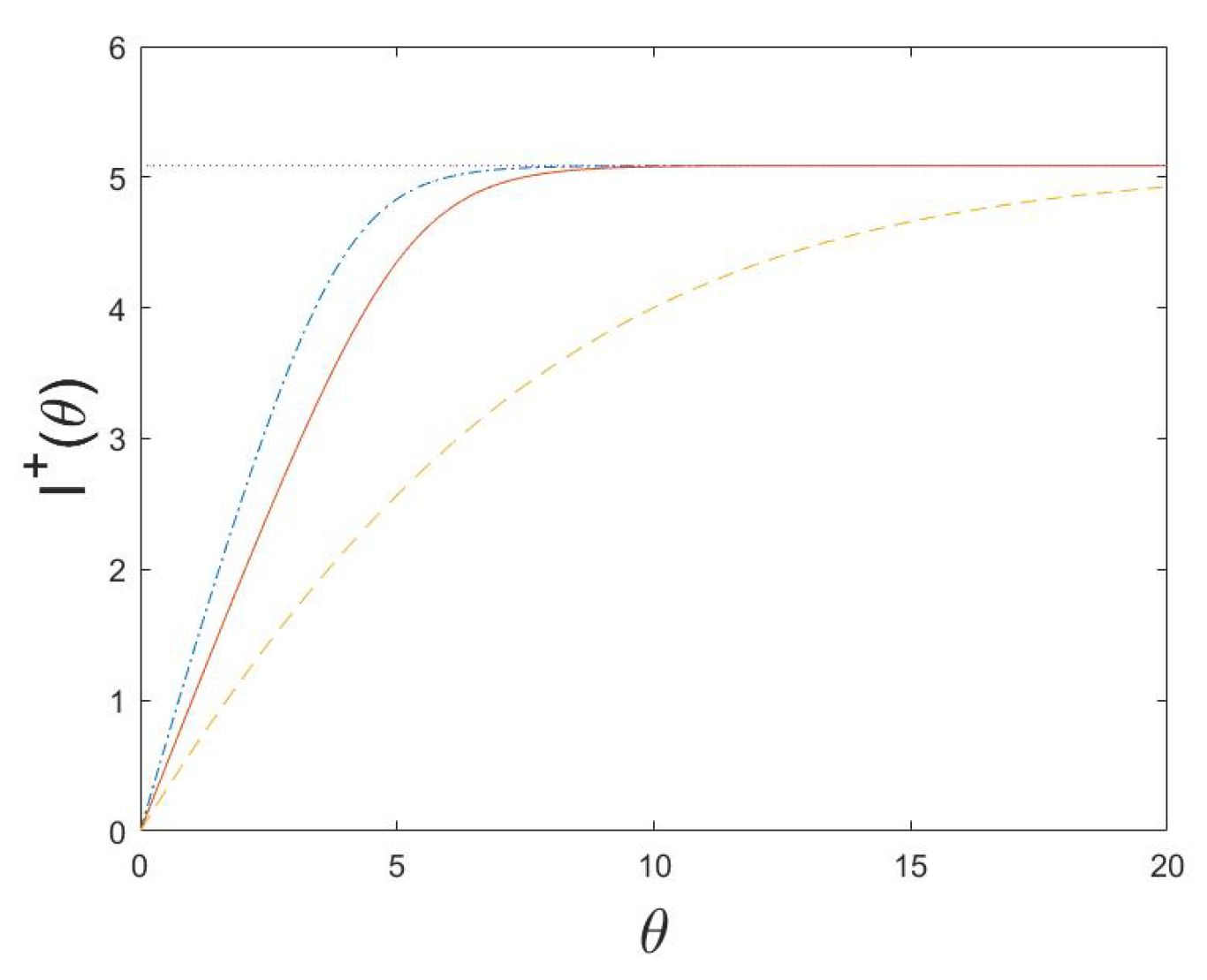
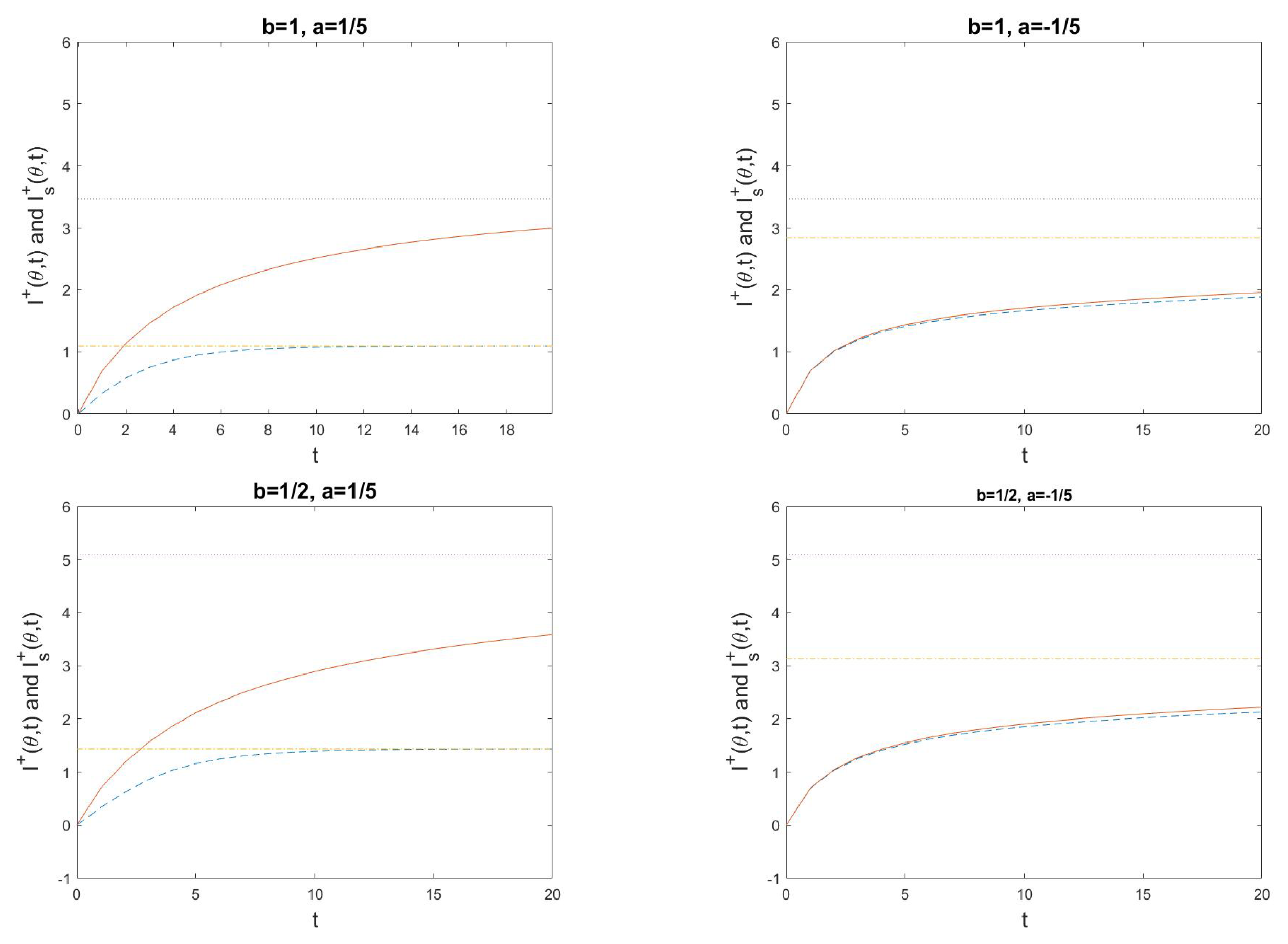
5. Examples
6. Discussion
7. Proofs
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gödel, K. Über Formal Unentscheidbare Sätze der Principia Mathematica und Verwandter Systeme, I. Monatshefte Math. Phys. 1931, 38, 173–198. [Google Scholar] [CrossRef]
- Hofstadter, D.R. Gödel, Escher, Bach: An Ethernal Golden Braid; Basic Books: New York, NY, USA, 1999. [Google Scholar]
- Whitehad, A.N.; Russell, B. Principia Mathematica; Cambridge University Press: Cambridge, UK, 1927. [Google Scholar]
- Wolpert, D.H.; MacReady, W.G. No Free Lunch Theorems for Search; Technical Report SFI-TR-95-02-010; Santa Fe Institute: Santa Fe, NM, USA, 1995. [Google Scholar]
- Wolpert, D.H.; MacReady, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Wolpert, D.H. What is important about the No Free Lunch theorems? In Black Box Optimization, Machine Learning and No-Free Lunch Theorems; Pardalos, P.M., Rasskazova, V., Vrahatis, M.N., Eds.; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Dembski, W.A.; Marks, R.J., II. Bernoulli’s Principle of Insufficient Reason and Conservation of Information in Computer Search. In Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 2647–2652. [Google Scholar] [CrossRef]
- Dembski, W.A.; Marks, R.J., II. Conservation of Information in Search: Measuring the Cost of Success. IEEE Trans. Syst. Man, Cybern. Part Syst. Hum. 2009, 5, 1051–1061. [Google Scholar] [CrossRef]
- Hazen, R.M.; Griffin, P.L.; Carothers, J.M.; Szostak, J.W. Functional information and the emergence of biocomplexity. Proc. Natl. Acad. Sci. USA 2007, 104, 8574–8581. [Google Scholar] [CrossRef] [PubMed]
- Szostak, J.W. Functional information: Molecular messages. Nature 2003, 423, 689. [Google Scholar] [CrossRef] [PubMed]
- Díaz-Pachón, D.A.; Marks, R.J., II. Generalized active information: Extensions to unbounded domains. BIO-Complexity 2020, 2020, 1–6. [Google Scholar] [CrossRef]
- Díaz-Pachón, D.A.; Sáenz, J.P.; Rao, J.S.; Dazard, J.E. Mode hunting through active information. Appl. Stoch. Model. Bus. Ind. 2019, 35, 376–393. [Google Scholar] [CrossRef]
- Liu, T.; Díaz-Pachón, D.A.; Rao, J.S.; Dazard, J.E. High Dimensional Mode Hunting Using Pettiest Component Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2022, accepted. [Google Scholar] [CrossRef]
- Montañez, G.D. The famine of forte: Few search problems greatly favor your algorithm. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 477–482. [Google Scholar] [CrossRef]
- Montañez, G.D. A Unified Model of Complex Specified Information. BIO-Complexity 2018, 2018, 1–26. [Google Scholar] [CrossRef]
- Díaz-Pachón, D.A.; Sáenz, J.P.; Rao, J.S. Hypothesis testing with active information. Stati. Probab. Lett. 2020, 161, 108742. [Google Scholar] [CrossRef]
- Carter, B. Large Number Coincidences and the Anthropic Principle in Cosmology. In Confrontation of Cosmological Theories with Observational Data; Longhair, M.S., Ed.; D. Reidel: Dordrecht, The Netherlands, 1974; pp. 291–298. [Google Scholar]
- Barrow, J.D.; Tipler, F.J. The Anthropic Cosmological Principle; Oxford University Press: Oxford, UK, 1988. [Google Scholar]
- Davies, P. The Accidental Universe; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- Lewis, G.F.; Barnes, L.A. A Fortunate Universe: Life In a Finely Tuned Cosmos; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar] [CrossRef]
- Rees, M.J. Just Six Numbers: The Deep Forces That Shape The Universe; Basic Books: New York, NY, USA, 2000. [Google Scholar]
- Adams, F.C. The degree of fine-tuning in our universe—Furthermore, others. Phys. Rep. 2019, 807, 1–111. [Google Scholar] [CrossRef]
- Barnes, L.A. The Fine Tuning of the Universe for Intelligent Life. Publ. Astron. Soc. Aust. 2012, 29, 529–564. [Google Scholar] [CrossRef]
- Tegmark, M.; Rees, M.J. Why is the cosmic microwave background fluctuation level 10−5. Astrophys. J. 1998, 499, 526–532. [Google Scholar] [CrossRef][Green Version]
- Tegmark, M.; Aguirre, A.; Rees, M.; Wilczek, F. Dimensionless constants, cosmology, and other dark matters. Phys. Rev. D 2006, 73, 023505. [Google Scholar] [CrossRef]
- Díaz-Pachón, D.A.; Hössjer, O.; Marks, R.J., II. Is Cosmological Tuning Fine or Coarse? J. Cosmol. Astropart. Phys. 2021, 2021, 020. [Google Scholar] [CrossRef]
- Díaz-Pachón, D.A.; Hössjer, O.; Marks, R.J., II. Sometimes size does not matter. Found. Phys. 2022. under revision. [Google Scholar]
- Dingjan, T.; Futerman, A.H. The fine-tuning of cell membrane lipid bilayers accentuates their compositional complexity. BioEssays 2021, 43, e2100021. [Google Scholar] [CrossRef]
- Dingjan, T.; Futerman, A.H. The role of the `sphingoid motif’ in shaping the molecular interactions of sphingolipids in biomembranes. Biochim. Biophys. Acta BBA Biomembr. 2021, 1863, 183701. [Google Scholar] [CrossRef]
- Thorvaldsen, S.; Hössjer, O. Using statistical methods to model the fine-tuning of molecular machines and systems. J. Theor. Biol. 2020, 501, 110352. [Google Scholar] [CrossRef]
- Asmussen, S.; Glynn, P.W. Stochastic Simulation: Algorithms and Analysis; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Siegmund, D. Importance Sampling in the Monte Carlo Study of Sequential Tests. Ann. Stat. 1976, 4, 673–684. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Robert, C.P.; Casella, G. Monte Carlo Statistical Methods; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H. Equation of State Calculations by Fast Computing Machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D., Jr.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Ross, S. Introduction to Probability Models, 8th ed.; Academic Press: Cambridge, MA, USA, 2003. [Google Scholar]
- Asmussen, R.; Nerman, O.; Olsson, M. Fitting Phase-type Distributions via the EM Algorithm. Scand. J. Stat. 1996, 23, 419–441. [Google Scholar]
- Neuts, M.F. Matrix-Geometric Solutions in Stochastic Models: An Algorithmic Approach; Johns Hopkins University Press: Hoboken, NJ, USA, 1981. [Google Scholar]
- Hössjer, O.; Bechly, G.; Gauger, A. On the waiting time until coordinated mutations get fixed in regulatory sequences. J. Theor. Biol. 2021, 524, 110657. [Google Scholar] [CrossRef] [PubMed]
- Varadhan, S.R.S. Large Deviations and Applications; SIAM: Philadelphia, PA, USA, 1984. [Google Scholar]
- Hössjer, O.; Díaz-Pachón, D.A.; Chen, Z.; Rao, J.S. Active information, missing data, and prevalence estimation. arXiv 2022, arXiv:2206.05120. [Google Scholar] [CrossRef]
- Hössjer, O.; Díaz-Pachón, D.A.; Rao, J.S. Active Information, Learning, and Knowledge Acquisition. PsyArXiv 2022. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Durrett, R. Probability Models for DNA Sequence Evolution. Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Moran, P.A.P. Random processes in genetics. Math. Proc. Camb. Philos. Soc. 1958, 54, 60–71. [Google Scholar] [CrossRef]
- Moran, P.A.P. A general theory of the distribution of gene frequencies—I. Overlapping generations. Proc. Roy. Soc. Lond. B 1958, 149, 102–112. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Vikhar, P.A. Evolutionary algorithms: A critical review and its future prospects. In Proceedings of the 2016 International Conference on Global Trends in Signal Processing, Information Computing and Communication (ICGTSPICC), Jalgaon, India, 22–24 December 2016; pp. 261–265. [Google Scholar]
- Abel, D.L.; Trevors, J.T. Three subsets of sequence complexity and their relevance to biopolymeric information. Theor. Biol. Med. Model 2005, 2, 29. [Google Scholar] [CrossRef] [PubMed]
- Durston, K.K.; Chiu, D.K.Y. A functional entropy model for biological sequences. Dynamics of Continuous, Discrete & Impulsive Systems, Series B: Applications & Algorithms, Supplement. In Proceedings of the International Conference on Engineering Applications and Compuational Algorithms, Guelph, ON, Canada, 27–29 July 2005; Liu, X., Ed.; pp. 722–725. [Google Scholar]
- Durston, K.K.; Chiu, D.K.Y. Functional Sequence Complexity in Biopolymers. In The First Gene: The Birth of Programming, Messaging and Formal Control; Abel, D.L., Ed.; LongView Press: New York, NY, USA, 2011; pp. 147–169. [Google Scholar]
- Durston, K.K.; Chiu, D.K.Y.; Abel, D.L.; Trevors, J.T. Measuring the functional sequence complexity of proteins. Theor. Biol. Med. Model 2007, 4, 47. [Google Scholar] [CrossRef] [PubMed]
- Díaz-Pachón, D.A.; Marks, R.J., II. Active Information Requirements for Fixation on the Wright-Fisher Model of Population Genetics. BIO-Complexity 2020, 2020, 1–6. [Google Scholar] [CrossRef]
- Kallenberg, O. Foundations of Modern Probability, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2021; Volume 2. [Google Scholar]
- Popov, S. Two-Dimensional Random Walk: From Path Counting to Random Interlacements; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar] [CrossRef]
- Grimmett, G.; Stirzaker, D. Probability and Random Processes, 3rd ed.; Oxford Univeristy Press: Oxford, UK, 2001. [Google Scholar]
- Komarova, N.L.; Sengupta, A.; Nowak, M.A. Mutation-selection networks of cancer initiation: Tumor suppressor genes and chromosomal instability. J. Theor. Biol. 2003, 223, 433–450. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Díaz-Pachón, D.A.; Hössjer, O. Assessing, Testing and Estimating the Amount of Fine-Tuning by Means of Active Information. Entropy 2022, 24, 1323. https://doi.org/10.3390/e24101323
Díaz-Pachón DA, Hössjer O. Assessing, Testing and Estimating the Amount of Fine-Tuning by Means of Active Information. Entropy. 2022; 24(10):1323. https://doi.org/10.3390/e24101323
Chicago/Turabian StyleDíaz-Pachón, Daniel Andrés, and Ola Hössjer. 2022. "Assessing, Testing and Estimating the Amount of Fine-Tuning by Means of Active Information" Entropy 24, no. 10: 1323. https://doi.org/10.3390/e24101323
APA StyleDíaz-Pachón, D. A., & Hössjer, O. (2022). Assessing, Testing and Estimating the Amount of Fine-Tuning by Means of Active Information. Entropy, 24(10), 1323. https://doi.org/10.3390/e24101323