
Structural Entropy of the Stochastic Block Models



{kind=link}
Abstract
:1. Introduction
1.1. Compression of Graphs
- We introduce the partitioned structural entropy which generalizes the structural entropy for unlabeled graphs and we show that it reflects the partition information of the SBM.
- We provide an explicit formula for the partitioned structural entropy of the SBM.
- We also propose a compression scheme that asymptotically achieves this entropy limit.
1.2. Related Works
2. Preliminaries
2.1. Structural Entropy of Unlabeled Graphs
- 1.
- The structural entropy of is:for some.
- 2.
- For a structure S of n vertices andwhereis the entropy rate of a binary memoryless source.
2.2. Stochastic Block Model–Our Result
- (i)
- The partitioned structural entropy of is:for some.
- (ii)
- For a balanced bipartitioned structure S andwhereis the entropy rate of a binary memoryless source.
3. Proof of Theorem 2
- (a)
- S is asymmetric on and , respectively;
- (b)
- , for .
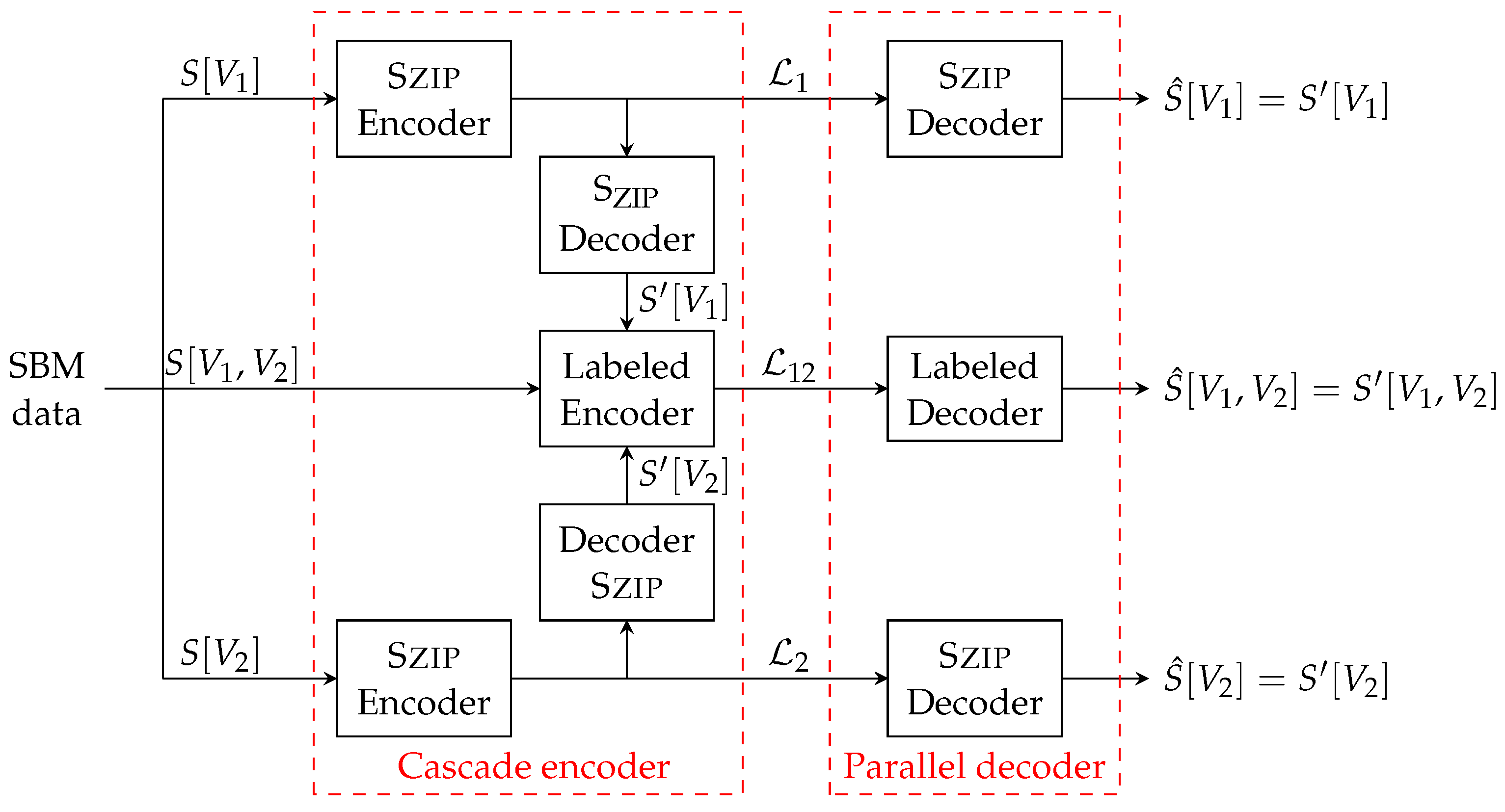
4. SBM Compression Algorithm
- (i)
- The expected codeword length asymptotically achieves the entropy of the message, i.e.,
- (ii)
- For any ,
- (iii)
- The arithmetic algorithm runs in time .
- (i)
- The algorithm asymptotically achieves the structural entropy in (1) (Note that .), i.e.,
- (ii)
- For any ,
5. General SBM with Blocks
5.1. Structural Entropy
- (i)
- The r-partitioned structural entropy for isfor some .
- (ii)
- For ,
5.2. Compression Algorithm
- (i)
- The algorithm asymptotically achieves the structural entropy in (6), i.e.,
- (ii)
- For any ,
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| SBM | Stochastic Block Models |
| Szip | Compression algorithm in [25] |
| AEP | Asymptotic Equipartition |
References
- Yeung, R.W. Information Theory and Network Coding; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. The lattice theory of information. Trans. Ire Prof. Group Inf. Theory 1953, 1, 105–107. [Google Scholar] [CrossRef]
- Palla, G.; Derényi, I.; Farkas, I.; Vicsek, T. Uncovering the overlapping community structure of complex networks in nature and society. Nature 2005, 435, 814–818. [Google Scholar] [CrossRef] [Green Version]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Social Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Abbe, E.; Bandeira, A.S.; Hall, G. Exact recovery in the stochastic block model. IEEE Trans. Inf. Theory 2015, 62, 471–487. [Google Scholar] [CrossRef] [Green Version]
- Mossel, E.; Neeman, J.; Sly, A. Consistency thresholds for the planted bisection model. In Proceedings of the Forty-Seventh Annual ACM Symposium on Theory of Computing, Portland, OR, USA, 14–17 June 2015; pp. 69–75. [Google Scholar]
- Abbe, E.; Sandon, C. Community detection in general stochastic block models: Fundamental limits and efficient algorithms for recovery. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 17–20 October 2015; pp. 670–688. [Google Scholar]
- Hajek, B.; Wu, Y.; Xu, J. Information limits for recovering a hidden community. IEEE Trans. Inf. Theory 2017, 63, 4729–4745. [Google Scholar] [CrossRef]
- Bianconi, G. Entropy of network ensembles. Phys. Rev. E 2009, 79, 036114. [Google Scholar] [CrossRef] [Green Version]
- Peixoto, T.P. Entropy of stochastic blockmodel ensembles. Phys. Rev. E 2012, 85, 056122. [Google Scholar] [CrossRef] [Green Version]
- Abbe, E. Community detection and stochastic block models: Recent developments. J. Mach. Learn. Res. 2017, 18, 6446–6531. [Google Scholar]
- Asadi, A.R.; Abbe, E.; Verdú, S. Compressing data on graphs with clusters. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1583–1587. [Google Scholar] [CrossRef]
- Zenil, H.; Kiani, N.A.; Tegnér, J. A Review of Graph and Network Complexity from an Algorithmic Information Perspective. Entropy 2018, 20, 551. [Google Scholar] [CrossRef] [Green Version]
- Turán, G. On the succinct representation of graphs. Discr. Appl. Math. 1984, 8, 289–294. [Google Scholar] [CrossRef] [Green Version]
- Harary, F.; Palmer, E.M. Graphical Enumeration; Academic Press: Cambridge, MA, USA, 1973. [Google Scholar]
- Naor, M. Succinct representation of general unlabeled graphs. Discr. Appl. Math. 1990, 28, 303–307. [Google Scholar] [CrossRef] [Green Version]
- Kieffer, J.C.; Yang, E.H.; Szpankowski, W. Structural complexity of random binary trees. In Proceedings of the 2009 IEEE International Symposium on Information Theory (ISIT), Seoul, Korea, 28 June–3 July 2009; pp. 635–639. [Google Scholar]
- Adler, M.; Mitzenmacher, M. Towards compressing Web graphs. In Proceedings of the DCC 2001. Data Compression Conference, Snowbird, Utah, 27–29 March 2001; pp. 203–212. [Google Scholar]
- Chierichetti, F.; Kumar, R.; Lattanzi, S.; Mitzenmacher, M.; Panconesi, A.; Raghavan, P. On Compressing Social Networks. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 28 June–1 July 2009; pp. 219–228. [Google Scholar]
- Peshkin, L. Structure induction by lossless graph compression. In Proceedings of the 2007 Data Compression Conference (DCC’07), Snowbird, Utah, 27–29 March 2007; pp. 53–62. [Google Scholar]
- Savari, S.A. Compression of words over a partially commutative alphabet. IEEE Trans. Inf. Theory 2004, 50, 1425–1441. [Google Scholar] [CrossRef]
- Sun, J.; Bollt, E.; Ben-Avraham, D. Graph Compression-Save Information by Exploiting Redundancy. J. Statist. Mechan. Theory Exper. 2008, 2008, 06001. [Google Scholar] [CrossRef]
- Choi, Y.; Szpankowski, W. Compression of Graphical Structures: Fundamental Limits, Algorithms, and Experiments. IEEE Trans. Inf. Theory 2012, 58, 620–638. [Google Scholar] [CrossRef] [Green Version]
- Łuczak, T.; Magner, A.; Szpankowski, W. Compression of Preferential Attachment Graphs. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1697–1701. [Google Scholar]
- Łuczak, T.; Magner, A.; Szpankowski, W. Asymmetry and structural information in preferential attachment graphs. Random Struct. Algorithms 2019, 55, 696–718. [Google Scholar] [CrossRef] [Green Version]
- Sauerhoff, M. On the Entropy of Models for the Web Graph. 2016. Available online: https://www.researchgate.net/publication/255589046OntheEntropyofModelsfortheWebGraph (accessed on 1 November 2021).
- Kontoyiannis, I.; Lim, Y.H.; Papakonstantinopoulou, K.; Szpankowski, W. Symmetry and the Entropy of Small-World Structures and Graphs. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Victoria, Australia, 11–16 July 2021; pp. 3026–3031. [Google Scholar]
- Körner, J. Coding of an information source having ambiguous alphabet and the entropy of graphs. In 6th Prague Conference on Information Theory; Walter de Gruyter: Berlin, Germany, 1973; pp. 411–425. [Google Scholar]
- Alon, N.; Orlitsky, A. Source coding and graph entropies. IEEE Trans. Inf. Theory 1996, 42, 1329–1339. [Google Scholar] [CrossRef] [Green Version]
- Rashevsky, N. Life information theory and topology. Bull. Math. Biophys. 1955, 17, 229–235. [Google Scholar] [CrossRef]
- Trucco, E. A note on the information content of graphs. Bull. Math. Biophys. 1956, 18, 129–135. [Google Scholar] [CrossRef]
- Mowshowitz, A. Entropy and the complexity of the graphs I: An index of the relative complexity of a graph. Bull. Math. Biophys. 1968, 30, 175–204. [Google Scholar] [CrossRef] [PubMed]
- Mowshowitz, A. Entropy and the complexity of graphs II: The information content of digraphs and infinite graphs. Bull. Math. Biophys. 1968, 30, 225–240. [Google Scholar] [CrossRef]
- Mowshowitz, A. Entropy and the complexity of graphs III: Graphs with prescribed information content. Bull. Math. Biophys. 1968, 30, 387–414. [Google Scholar] [CrossRef]
- Mowshowitz, A. Entropy and the complexity of graphs IV: Entropy measures and graphical structure. Bull. Math. Biophys. 1968, 30, 533–546. [Google Scholar] [CrossRef]
- Mowshowitz, A.; Dehmer, M. Entropy and the Complexity of Graphs Revisited. Entropy 2012, 14, 559–570. [Google Scholar] [CrossRef]
- Dehmer, M.; Mowshowitz, A. A History of Graph Entropy Measures. Inf. Sci. 2011, 181, 57–78. [Google Scholar] [CrossRef]
- Pasco, R.C. Source Coding Algorithms for Fast Data Compression. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 1976. [Google Scholar]
- Rissanen, J.J. Generalized Kraft Inequality and Arithmetic Coding. IBM J. Res. Dev. 1976, 20, 198–203. [Google Scholar] [CrossRef]
- Willems, F.; Shtarkov, Y.; Tjalkens, T. The context-tree weighting method: Basic properties. IEEE Trans. Inf. Theory 1995, 41, 653–664. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Guo, T.; Zhou, Q.; Han, W.; Bai, B.; Zhang, G. Structural Entropy of the Stochastic Block Models. Entropy 2022, 24, 81. https://doi.org/10.3390/e24010081
Han J, Guo T, Zhou Q, Han W, Bai B, Zhang G. Structural Entropy of the Stochastic Block Models. Entropy. 2022; 24(1):81. https://doi.org/10.3390/e24010081
Chicago/Turabian StyleHan, Jie, Tao Guo, Qiaoqiao Zhou, Wei Han, Bo Bai, and Gong Zhang. 2022. "Structural Entropy of the Stochastic Block Models" Entropy 24, no. 1: 81. https://doi.org/10.3390/e24010081
APA StyleHan, J., Guo, T., Zhou, Q., Han, W., Bai, B., & Zhang, G. (2022). Structural Entropy of the Stochastic Block Models. Entropy, 24(1), 81. https://doi.org/10.3390/e24010081