1. Introduction
Since a great diversity of real-world dynamical systems exhibit observable time series outputs characterized by scaling properties and complex correlations structure, many techniques have been developed in the last two decades to analyze this kind of time series and quantify adequately their properties, with Detrended Fluctuation Analysis (DFA) [
1] being one of the most widely used, although other methods derived from fractal properties, complexity, and information theory are also common, such as Poincaré plots, fractal dimension, Hurst exponent (very related to DFA), different entropic techniques (Shannon, conditional, approximate, sample and multiscale entropies), and symbolic dynamics (see [
2] for a recent review).
For a given scale ℓ of observation of the analyzed time series, DFA partitions the time series into windows of size ℓ, and quantifies the fluctuations of the time series within each window around the local trend. After averaging in all the windows of size ℓ, DFA provides the fluctuation function which measures the average local fluctuations as a function of the observation scale (ℓ). In time series with perfect scaling and fractal power-law correlations, one finds asymptotically . The scaling exponent is typically obtained as the slope of a linear fit of vs. . The exponent quantifies the strength of the power-law correlations and characterizes the underlying dynamical system.
However, in many cases and especially when analyzing physiological time series associated with cardiac dynamics, the
vs.
curve exhibits two different slopes (correlation behaviors) at short and large scales of observation. In this case, very often,
two scaling exponents are obtained by fitting the
vs.
at short (
) and large (
) scales [
3,
4,
5], which quantify the short-term and long-term correlations, respectively. These two different scaling exponents are usually associated with the existence of different control mechanisms in the dynamical system which act at distinct time scales, so that
characterizes the control mechanism responsible for the short-time scales behavior, and, similarly,
is linked to the mechanism acting at long-time scales. The calculation of these two exponents has become a standard technique, when studying heart-rate variability [
2,
6], although it is also very common to distinguish between short-term and long-term scaling exponents in many other scientific fields. Some examples can be: the analysis of electroencephalograms for patients with Alzheimer’s disease [
7], the behavior of glucose levels for patients with diabetes mellitus [
8], the radon levels in soil associated with earthquakes [
9], the stock market activity [
10], the behavior of seismic signals [
11]. or the properties of the trajectory of the center of pressure in the human postural control system [
12].
In this work, we show that the use of
to characterize the correlations and scaling properties of dynamical systems at short time scales may lead to incorrect results. In particular, we show that, when analyzing artificial time series with
perfect scaling,
systematically fails to detect the correct scaling at short scales. By using the Fourier Filtering Method algorithm (FFM), we are able to create synthetic time series with perfect scaling, i.e., characterized by a single scaling exponent
at
all scales of observation. For these time series,
should behave as a perfect power-law at all scales (including short scales),
. In this case, the
vs.
plot should be a straight line with slope
, and therefore we should also obtain for short scales that
. However, we observe that, independently of the
value used to generate the FFM time series, the
vs.
plot always exhibits a downwards curvature at short scales that has been reported previously [
13] in time series with perfect scaling and some ad-hoc corrections to DFA were proposed, which has been attributed to overfitting in the detrended procedure [
14]. The same effect is known to happen in the multifractal generalization of DFA [
15]. However, we want to analyze systematically here how this phenomenon affects the determination of
, since the curvature appears precisely in the range of scales where
is typically obtained, and the majority of authors do not consider the ad-hoc corrections proposed in [
13]. The curvature produces a systematic overestimation of
, which is in all cases larger than the correct exponent
,
.
We show that this overestimation is not due to effects produced by the finite time series length, but an intrinsic limitation of DFA, which only recovers the true scaling exponent at larger scales of observation. In addition, the overestimation depends on the range of scales used to obtain , which varies considerably for different authors. The overestimation also depends on the value of the true scaling exponent of the time series.
In addition, we also analyze the behavior of when studying time series with a scaling crossover separating two regions of true perfect scaling at both sides of the crossover, i.e., at short and large scales of observation. We create such time series by using a modified version of the Fourier Filtering Method, in which we can use as input the true values of and as well as the scale at which the crossover is located. In this case, should exhibit two perfect linear behaviors in a log-log plot, with two different slopes for short and large scales and a transition between the two regimes around the scale of the crossover. As before, is estimated as the slope of the linear fit of vs. for short scales, and should coincide with the corresponding short-scale exponent used in the generation of the time series. However, we find that the estimated value does not coincide with the true scaling exponent used to model the short scale behavior, which can be severely underestimated or overestimated. In this case, the estimated value depends not only on the fitting range used to obtain it and of the real value but, even worse, on the value, i.e., time series generated with the same true value and different true values, provides different estimations of , although the short-term scaling properties are identical in all cases.
Therefore, the results we present here, obtained both for time series with perfect scaling and with scaling crossovers, suggest that, when analyzing real-world complex time series, the spurious value of the estimated result could lead to incorrect interpretations of the short time behavior of the underlying dynamical system.
This paper is organized as follows: In
Section 2, we introduce the connection of the autocorrelation function and Detrended Fluctuation Analysis, as well as how these two techniques should behave when applied to power-law correlated time series with perfect scaling. In addition, we also introduce how these time series can be generated by the Fourier Filtering Method. In
Section 3, we introduce the question of the behavior of DFA at short scales, and how the short-term scaling exponent is usually determined. In
Section 4, we present a systematic analysis of the behavior of DFA at short scales, and of the corresponding
exponent, when applied to time series with perfect scaling characterized by a single exponent. In this case, we show the overestimation effect described above, and systematically quantify it as a function of the true scaling exponent, and of the fitting range considered to estimate it. In
Section 5, we introduce the generation of time series with two different perfect scaling behaviors for short and large scales, i.e., with known true values of
and
, and study systematically the behavior of the estimated
as a function of the fitting range used to obtain it, and also as a function of the true
value and of the true
value. Finally, in
Section 6, we present our conclusions.
2. Detrended Fluctuation Analysis and Autocorrelation Function in Time Series with Power–Law Correlations
In principle, the natural way of studying the correlations present in a time series for a given lag (
r) is the determination of the autocorrelation function,
. For a stationary time series
(
, the corresponding autocorrelation function can be calculated as
where
denotes average over the whole time series. Without loss of generality, in the following, we assume that
. When the time series
is long-range power-law correlated, such as, for example, in fractional Gaussian noise (fGn), then its autocorrelation function
behaves as a power law of the lag
r [
16]:
where
H is the well-known Hurst exponent [
17] with values in the range
, and then the autocorrelation exponent
given by
, must be in the range
. For
(
), the correlations are positive, while, for
, the time series is anticorrelated. Note that, for the special case
, the autocorrelation function vanishes, and the time series is uncorrelated (white noise behavior).
Similar power-law behavior for
as that in (
2) is obtained for time series generated using the
Fourier Filtering Method (FFM) algorithm [
18,
19]. In this technique, a power spectrum of the type
is imposed by creating a signal
in the frequency
f domain such that
and
, where
is a random phase in the interval
. The time series
obtained by Fourier transforming back
presents by construction a power spectrum
. According to the Wiener–Khinchin theorem, the autocorrelation function of the final time series
is
, and therefore the relation between the three exponents
H,
and
is [
20]:
FFM has become the standard method to create a controlled power-law correlated time series, and it is used in many contexts for that purpose [
21,
22,
23,
24,
25,
26]
However, in many real-world time series, the autocorrelation function is not convenient to determine the exponent
(or
H), since
is noisy and very sensitive to the time series size
N [
16,
27], and it is only properly estimated for large
N, very often not available in real experiments. This is the reason motivating the use of indirect methods to quantify correlations and scaling, such as Detrended Fluctuation Analysis (DFA), which is one of the most widely used.
Detrended Fluctuation Analysis was designed [
1] to estimate the scaling properties of a given time series even in the presence of non-stationarities. DFA has been intensively tested and characterized by applying it to signals with different properties (trends, nonlinear filters, etc.) [
28,
29] and, since then, DFA has become one of the most standard methods used to analyze complex time series in many scientific fields. DFA works as follows: (i) Calculate the ’accumulated walk’
of the analyzed time series
of length
N, such that
(ii) Divide the walk
into boxes of equal length
ℓ (the scale of observation). (iii) Within each box of length
ℓ, calculate a linear fit of
to determine the
linear trend within that box. The
Y coordinate of the fitted line in each box is denoted by
. (iv) The walk
is detrended by subtracting the local trend
in each box of length
ℓ. (v) For a given box size
ℓ, the root mean-square (r.m.s.) fluctuation function
for the detrended walk is calculated as:
where, as usual,
means averaging over the whole time series. (vi) The above computation is repeated for a broad range of scales (box sizes
ℓ) in order to provide a relationship between
and the scale
ℓ. Scaling is present when
According to this last equation, when applying DFA to analyze real-world experimental data, the scaling exponent is typically determined as the slope of a linear fit of vs. .
For stationary power-law correlated signals, . The case corresponds to the absence of correlations (white noise), while indicates positive power-law correlations and corresponds to power-law anticorrelated time series. In this context, the DFA exponent and the Hurst exponent H have the same value, . In addition, DFA can be also applied to non-stationary long-range correlated signals of fractional Brownian motion type, and, in this case, . For example, for the standard Brownian motion, .
In this work, we focus on stationary power-law correlated signals (
), where both the autocorrelation function and DFA can be applied. Note that, when the analyzed time series
is stationary, an analytical relation between the autocorrelation function
and the DFA fluctuation function
can be established. According to the derivation by Höll and Kantz [
30], also obtained in a different manner by Talkner and Weber [
31], for a time series with variance
, we can write:
with
and
We want to remark that Equation (
6) is an exact result, independently of the specific behavior of
(positive, negative, power-law behaved or not, etc.). Therefore, Equation (
6), which uses as input the values of
, provides an alternative way to the use of the standard DFA algorithm (
4) to calculate the fluctuation function
for stationary time series. In the results presented in the next sections, when considering stationary time series, we have applied both techniques and have obtained identical results. In the case of non-stationary time series, we have used the standard DFA algorithm (
4).
4. Behavior of in Time Series with Perfect Scaling
In this section, we show that, even for time series with perfect scaling behavior (i.e., with pure power-law fractal correlations), does not provide an appropriate value characterizing such correlations. Here, we use the fitting range for obtaining the results presented in this section, as a kind of consensus among the different ranges used in the bibliography described above. For completeness, some other values for the fitting range that are used in the bibliography will be also considered later.
We consider artificial time series generated using the Fourier Filtering Method described in
Section 2. Due to the relation between the different scaling exponents (
3) and as
for stationary power-law correlated time series, when we choose an input value
and we create a time series with a perfect power-law behavior for the power spectrum,
(perfect scaling), we should obtain a perfect power-law behavior for the DFA fluctuation function
at all scales,
. However, we see below that this is not the case. In order to introduce the systematic errors when obtaining
, in
Figure 1,
Figure 2 and
Figure 3, we only present the results obtained for stationary time series of fractional Gaussian noise type, i.e., with a true scaling exponent in the range
. The behavior of
for time series of fractional Brownian motion type with
exhibit similar properties, and it is not shown in
Figure 1,
Figure 2 and
Figure 3 but will be included in
Figure 4, where we show the final results for the systematic overestimation of
.
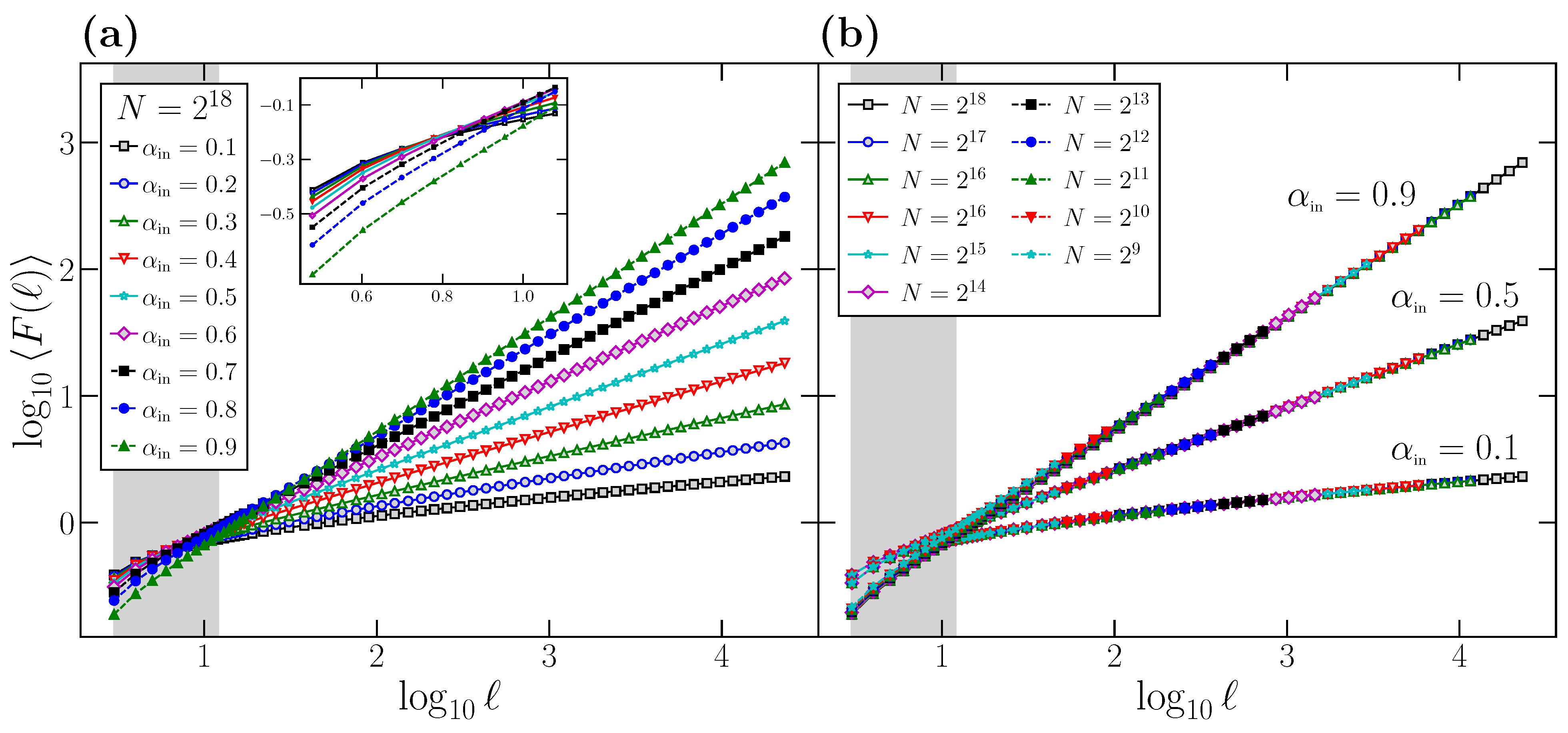
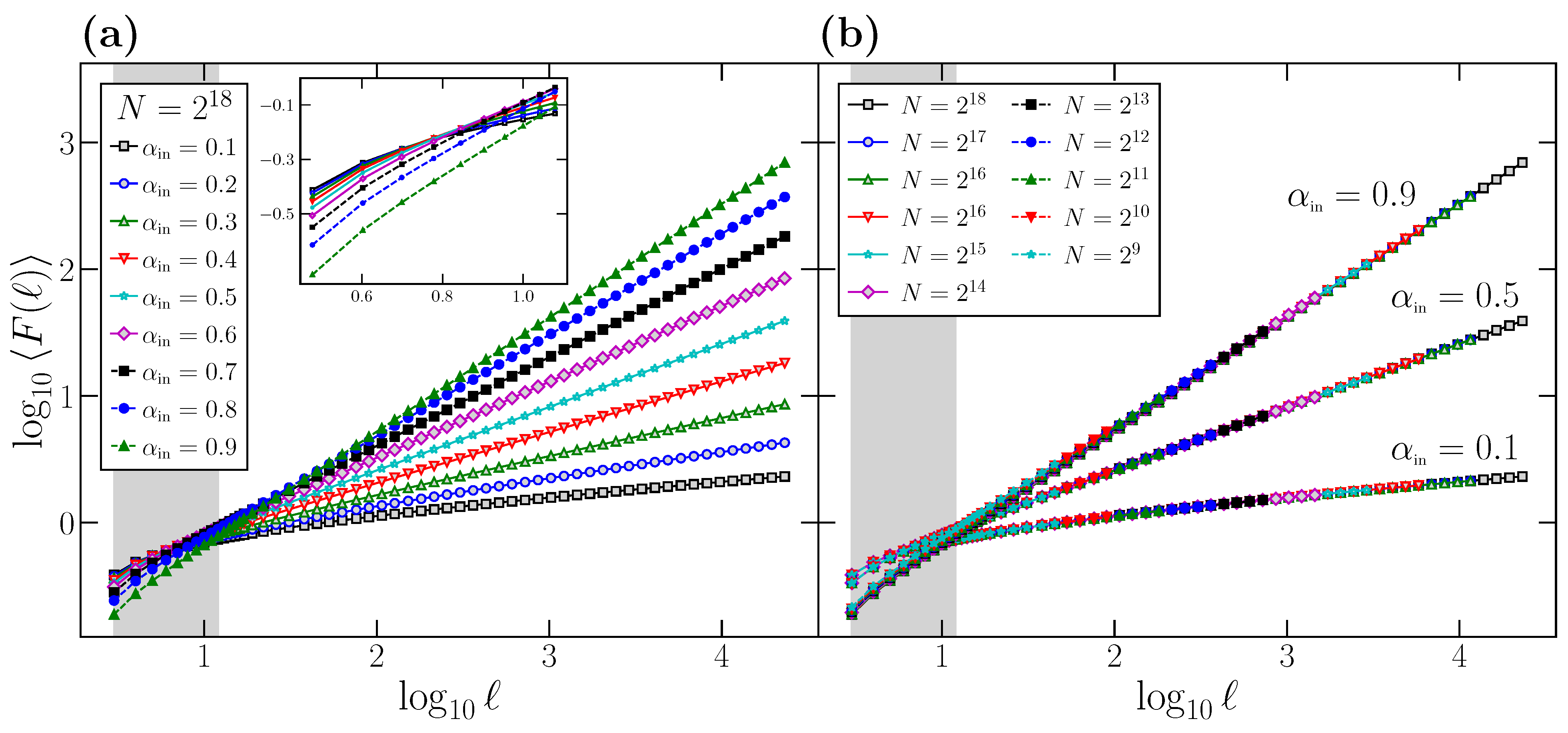
In
Figure 1a, we represent [
42] the average behavior of the
function (
) for time series generated using the FFM algorithm with different
values. For each
value, we generate
time series of length
data points, calculate the
function for each one for scales
ℓ in the range
, and average the
functions to obtain
. We first observe how the behavior of
is correct for large scales, where all the curves in
Figure 1a exhibit a slope in the log-log plot identical to the corresponding
value.
However, if we observe the curves in
Figure 1a, all of them present some degree of curvature at small scales, where the local slope deviates clearly from the correct
value, which is only observed when the scale
ℓ of observation increases. We remark that this curvature observed in the small
ℓ region is not caused by a different behavior of the correlations at this scale, since all the time series considered have been generated to have a perfect power-law power spectrum, and therefore with the same scaling exponent at all scales. Indeed, the shaded area in
Figure 1a corresponds to the range
. i.e., the usual range where the scaling exponent
is obtained, and covers precisely the region where the curvature of the
vs.
plots is more evident.
We also note that this curvature effect is not due to finite size effects. To show that this is the case, in
Figure 1b, we choose as examples three different values of
(although the results are general), and consider different time series length
N. For each
N, we generate
FFM time series to obtain the corresponding
functions. We observe that, for the three
values, the curves corresponding to different
N overlap perfectly in the range
, where DFA is calculated, and therefore the curvature observed at small scales is independent of the time series length
N. This leads us to conclude that the curvature is a side effect of the DFA technique itself, which presents such curvature at small scales and only recovers the correct
value in the large scale region.
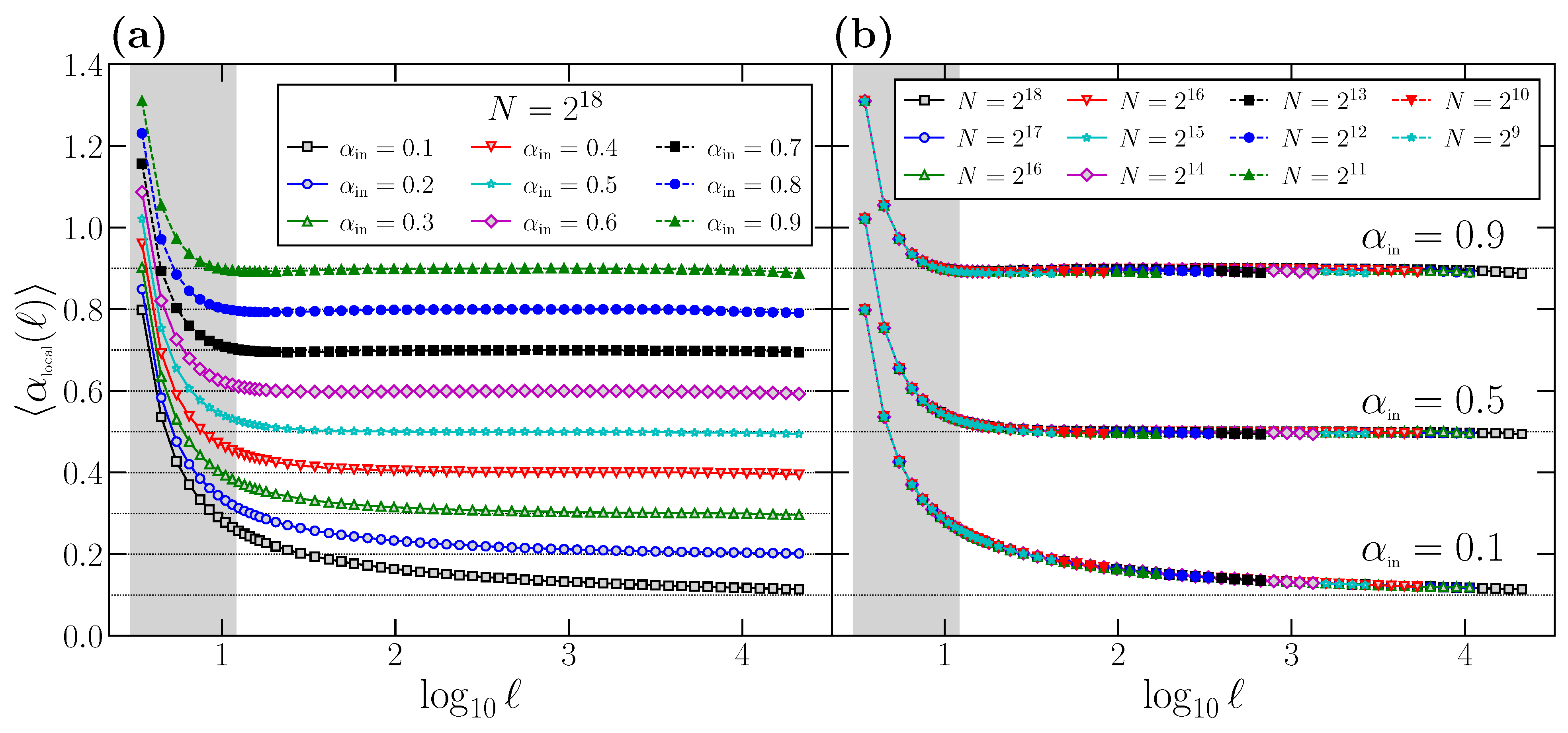
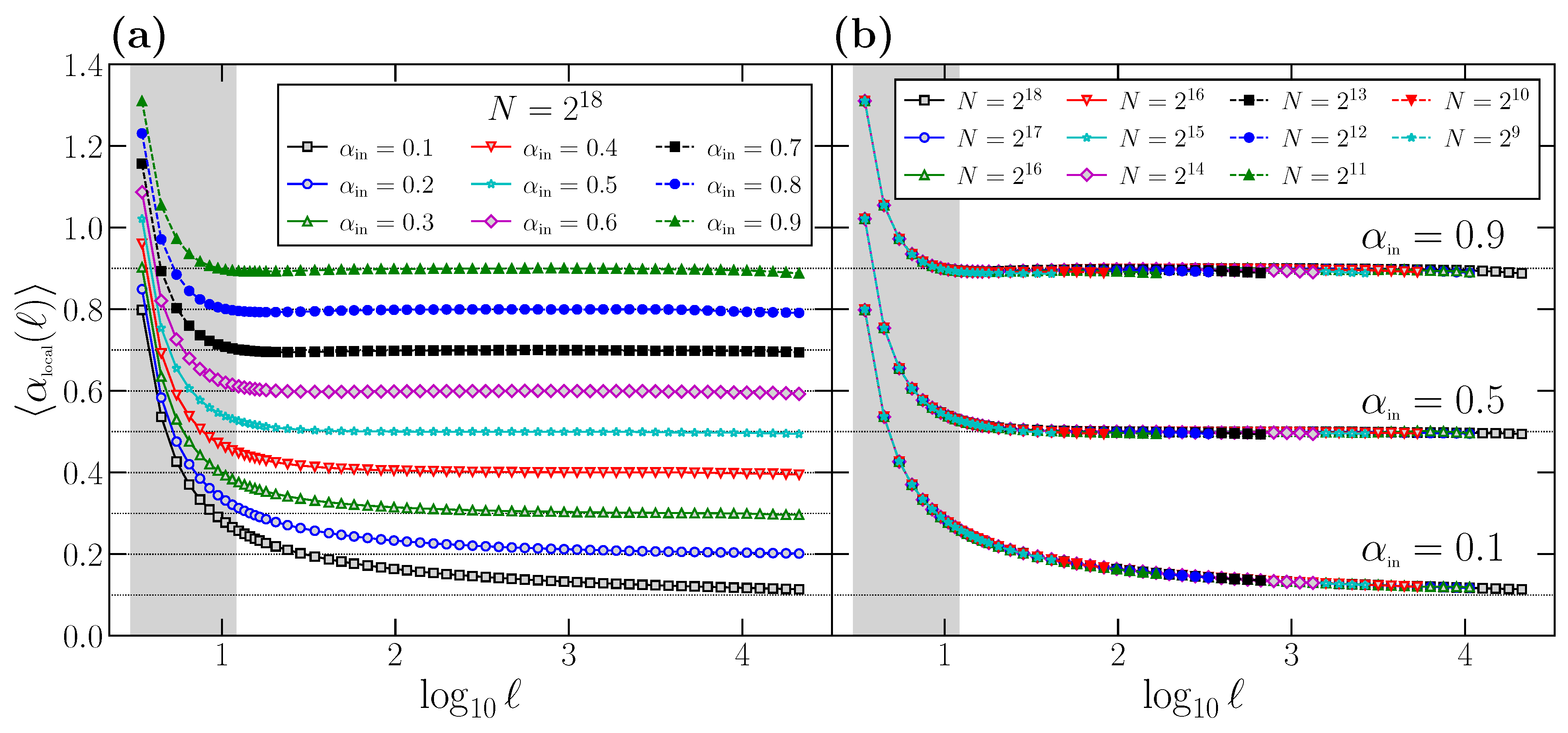
This curvature effect can be better appreciated if we define the
local scaling exponent
as the local slope of the
vs.
curve:
For time series with perfect scaling, such as the ones generated with the FFM algorithm, we should obtain
. However, due to the curvature of the
function, there is a clear deviation of
with respect to the correct value
at short scales. This effect is shown in
Figure 2a, where we plot the behavior of
for different
values. All the curves have been obtained by generating
time series of length
for any value of
, obtaining for each one the corresponding function
using Equation (
9), and averaging the results to get
. Again, the range of scales usually considered to determine
is shown as a shaded rectangle.
According to the results shown in
Figure 2a, we can conclude that DFA provides the correct scaling exponent
asymptotically: only for large or moderately large scales does the local slope
reach the true
value, which is shown in all cases with a horizontal dashed line. However, at short scales, the local exponent
presents a large deviation with respect to the asymptotic value, specifically a clear overestimation since always
. This deviation is larger for smaller
values, especially for the anticorrelated cases
, but it is notorious in all cases. We remark that the scales where the deviation of
with respect to the correct scaling exponent
is larger coincides with the shaded area, i.e., the range of scales used to determine
.
Similarly to what we did in
Figure 1, we proceed to show that the overestimation observed in
at short scales with respect to
is not due to size effects: in
Figure 2b, we show similar curves to the ones shown in
Figure 2a, but obtained for a wide range of time series length
N. We choose as examples the same three
values considered in
Figure 1b. For each combination of
and
N, we generate
time series, determine for each one the corresponding
function in the range
, and obtain the average of the
curves. We observe that all the curves corresponding to the same
value overlap perfectly on top of each other independently of
N. Although shown only for three
values, the behavior is completely general. Therefore, we can conclude that the deviation is not due to effects produced by the time series length
N, but an intrinsic property of DFA, which systematically leads to a clear overestimation of
at short scales.
Since the short-term scaling exponent
is commonly estimated by the slope of a linear fitting of
vs.
in the range
, we observe from the results of
Figure 1 and
Figure 2 that, even for time series with perfect scaling,
will provide a spurious result not characterizing the correlations at those scales. Note that
for
, and therefore
, which is a kind of average of
in the fitting interval, will be also overestimated and will not properly represent the correlation properties at these scales.
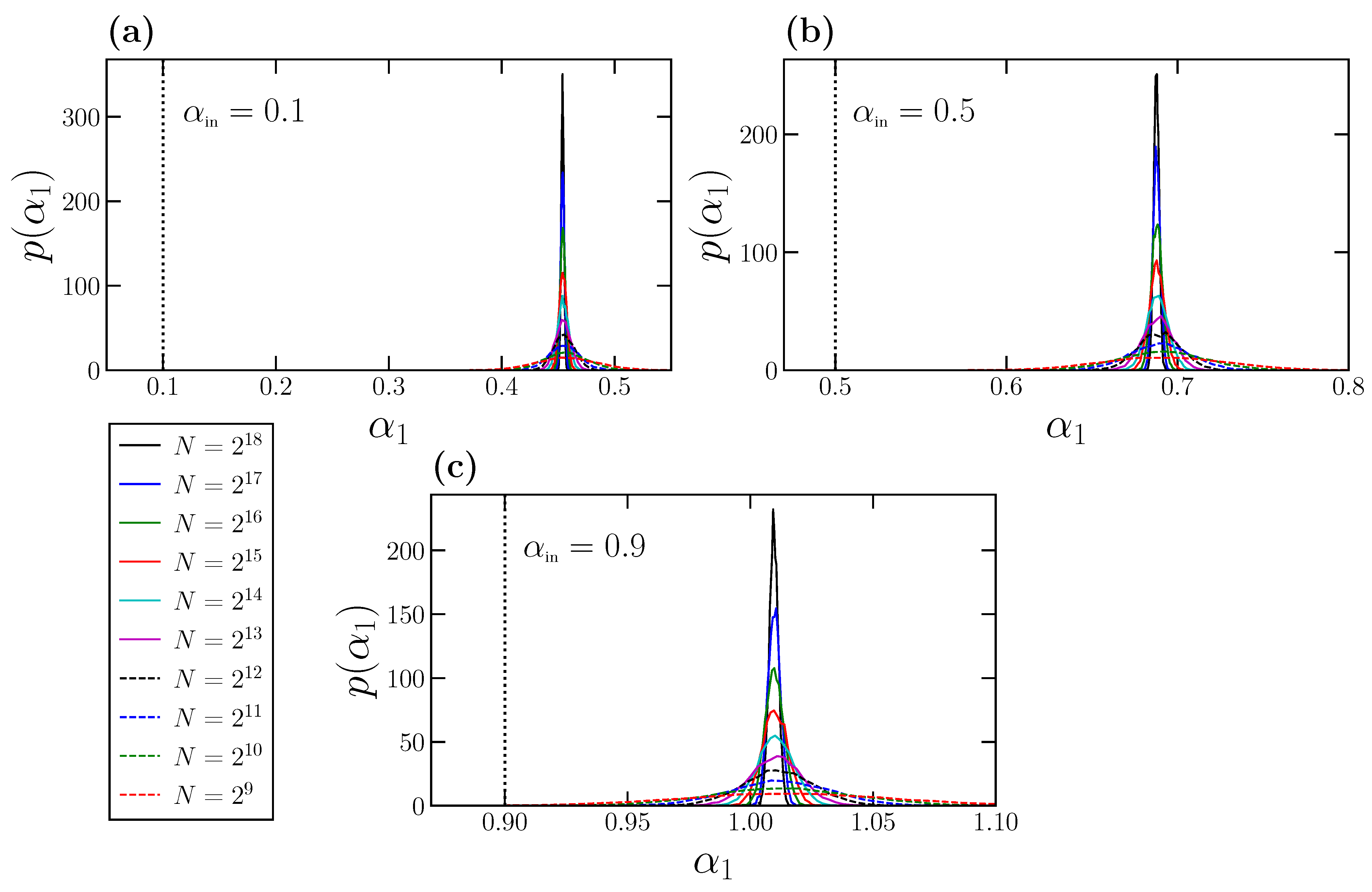
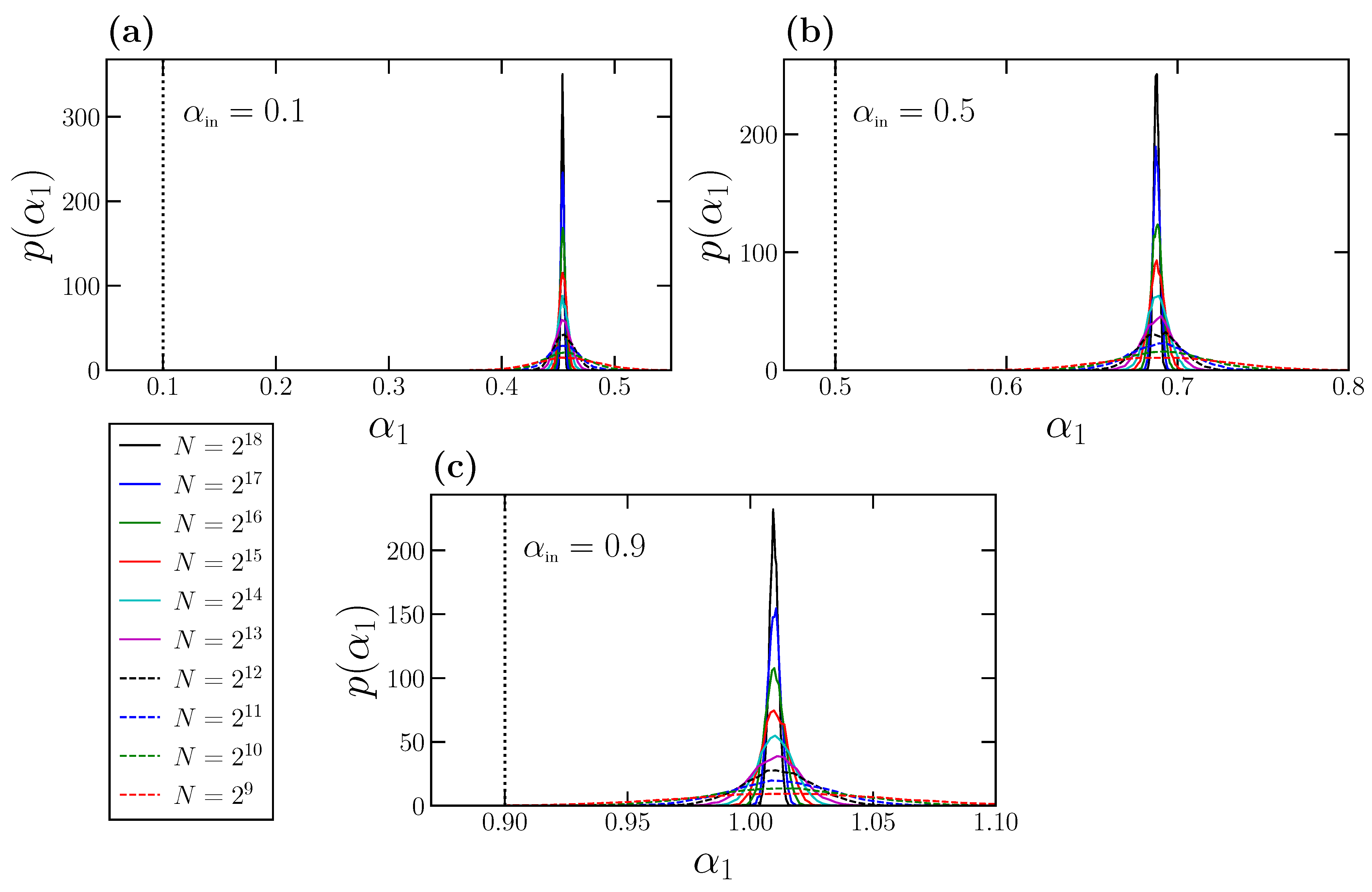
Indeed, we can determine statistically the behavior of
for time series with perfect scaling. For that purpose, we choose different values of
, and for each one we consider a wide range of time series length
N. For each combination of
and
N, we generate a
time series with perfect scaling characterized by
using the FFM algorithm. For each individual time series, we calculate the DFA fluctuation function
and obtain the corresponding
value by fitting
vs.
for
. Therefore, we finally have
individual
values for each pair
and
N, from where we can obtain numerically the corresponding probability density
. In
Figure 3, we show the results for the probability densities obtained for
(panel a),
(panel b), and
(panel c). In each panel, we show the normalized probability densities for a wide range of time series length
N values. In addition, we also show in each panel with a vertical dashed line the corresponding
value, which truly characterizes the scaling and the correlations of the time series at
all scales.
The behavior of
is quite similar in the three panels shown in
Figure 3. Each individual density
exhibits a Gaussian-like shape with the peak centered at the corresponding mean value
. Interestingly, and since for a given
all the
densities are centered in the same value independently of the time series length
N, the expected
value depends only on the corresponding
, but not on
N. This property could have been anticipated by observing the overlapping of the curves shown in
Figure 1b and
Figure 2b for different
N values. The effect of the time series length
N is only reflected in the width of
, which is larger for small
N values, and decreases noticeably as
N increases.
We observe in
Figure 3 that the exponent
is systematically overestimated, and this effect can lead to spurious misinterpretations of the behavior of the analyzed time series, and therefore of the underlying dynamical system. For example, in
Figure 3a, we analyze FFM time series fully characterized by
. This value indicates very strong power-law anticorrelations. However, the expected value
is close to 0.5, corresponding to the absence of correlations (white noise behavior). In
Figure 3b, we consider precisely
, and therefore the corresponding FFM time series are completely uncorrelated (white noises). However, we obtain in this case
that would be interpreted as corresponding to positive and quite strong power-law correlations at short scales. In
Figure 3c, we use
, so that the corresponding FFM time series are very strongly positively correlated. In this case, we obtain
slightly larger than 1 that would be interpreted as corresponding to a non-stationary time series, for which
, although the FFM time series are stationary.
These overestimations of
could strongly affect the interpretation and implications of the results obtained with physiological time series. For example, Rogers et al. [
41] show that the
value obtained from heart rate time series drops to 0.5 when runner’s fatigue increases. If we do not take into account these overestimations, we can conclude that fatigue makes the heart rate be random at short scales, whereas, in reality, the heart rate becomes highly anticorrelated at short scales.
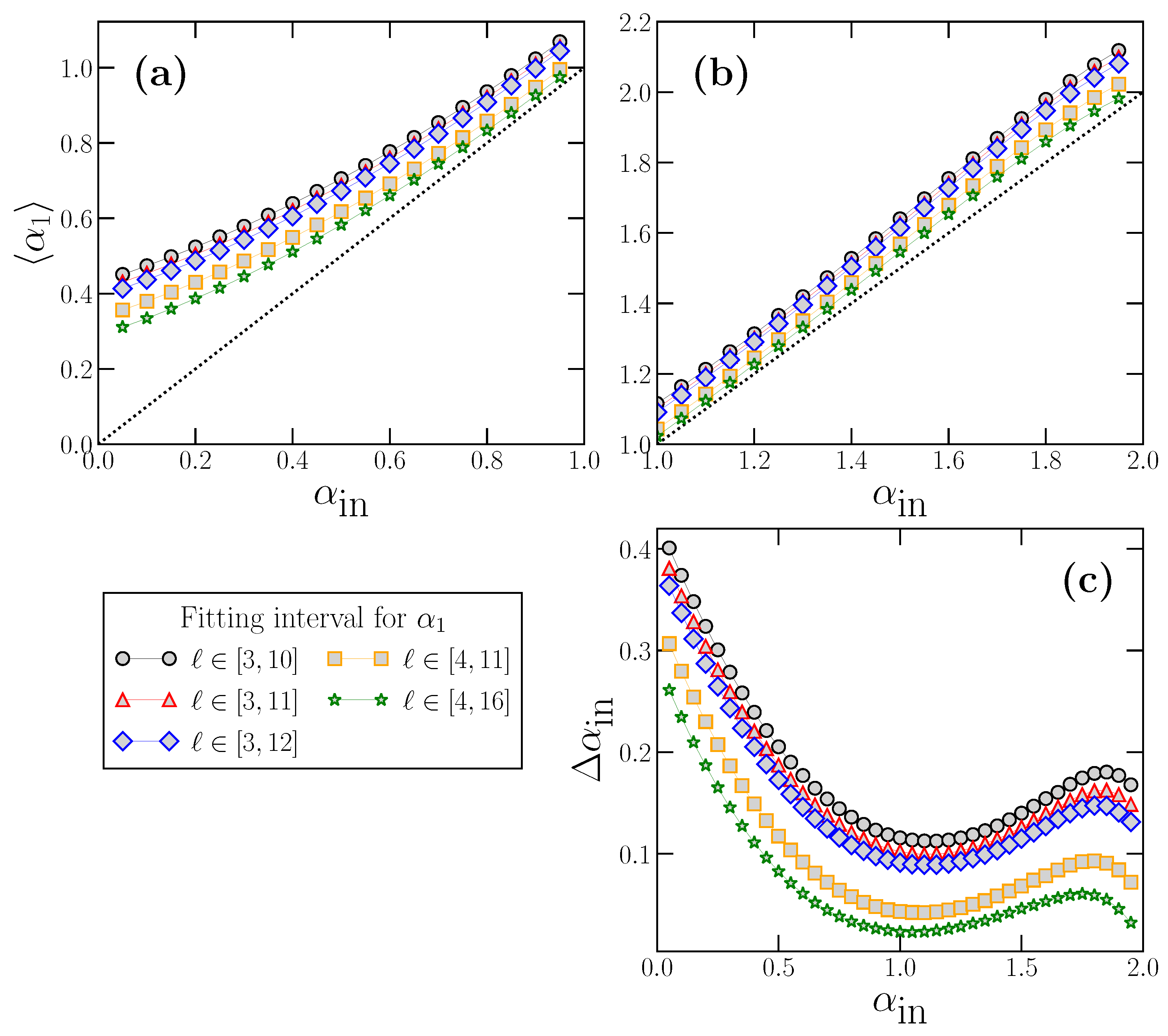
These examples are useful to illustrate how
systematically overestimates the true scaling exponent
, and also that the overestimation depends on
value. By repeating the same calculations presented in
Figure 3 but for many
values in the interval
(i.e., for stationary and non-stationary cases), we can obtain the dependence of the expected value
on
, and quantify the overestimation
defined as:
The results for
as a function of
are shown in
Figure 4, where for clarity we have separated the results corresponding to stationary time series with
(panel a), and to non-stationary time series with
(panel b). In addition, we also include the dependence of
on
in panel c.
We observe how
is larger for a stationary power-law strongly anticorrelated time series
close to 0) and decreases as the true scaling exponent
increases, reaching a minimum value around
. After the minimum value,
increases again in the non-stationary region and reaches a maximum at around
Although of variable extent, the overestimation always exists, and, as we have seen with the examples of
Figure 3, this can lead to misinterpretations if the exponent
is considered to truly represent the short-term correlations of the analyzed time series.
We also include in
Figure 4 the behavior of
and
as a function of
for other values of the range of scales used to obtain
(typically used in the bibliography), in addition to the case
, we have used in previous figures. We see that
and
depend also on the fitting interval considered, which is different for different authors, adding another degree of arbitrariness to the already difficult interpretation of the
value.
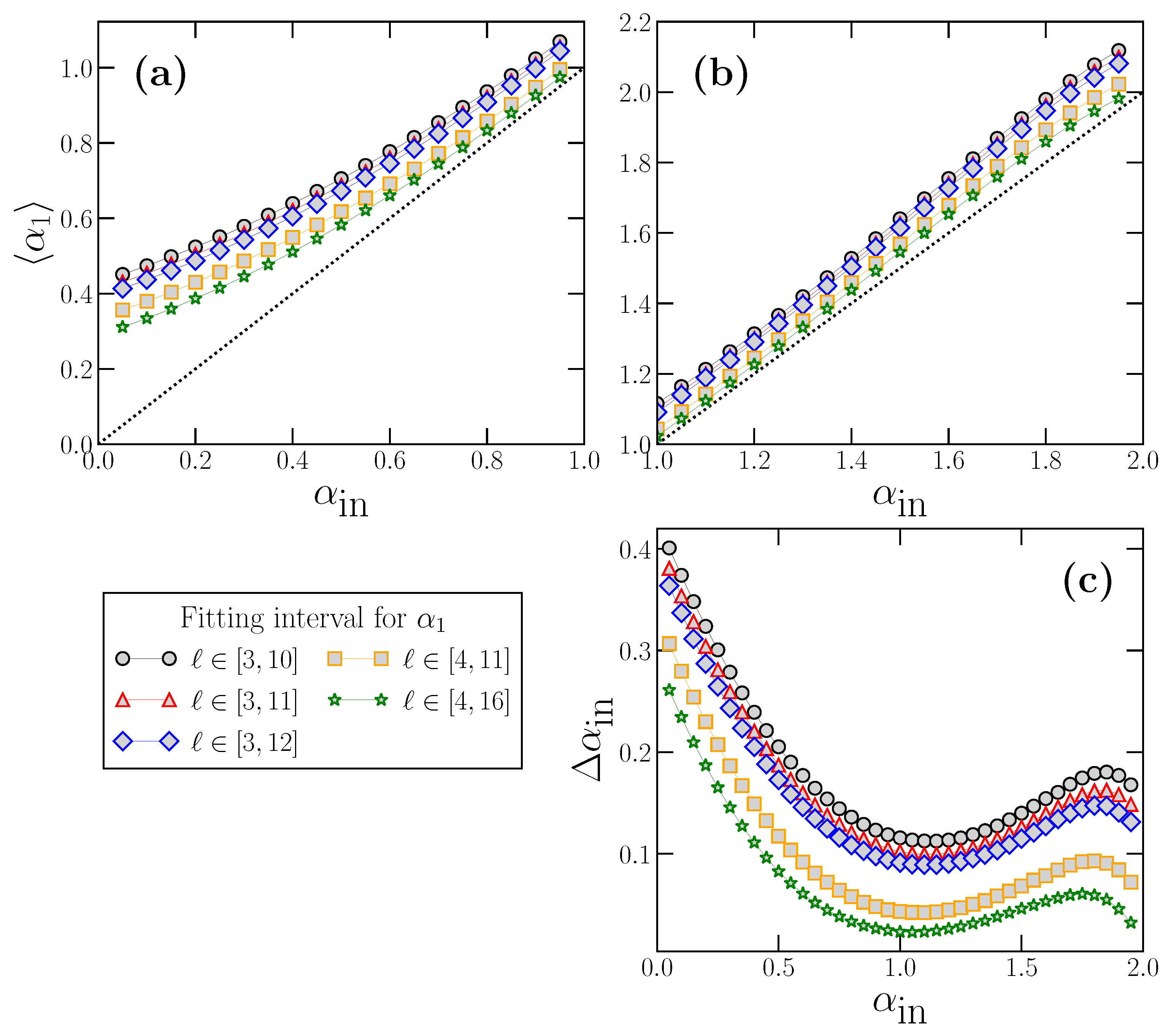
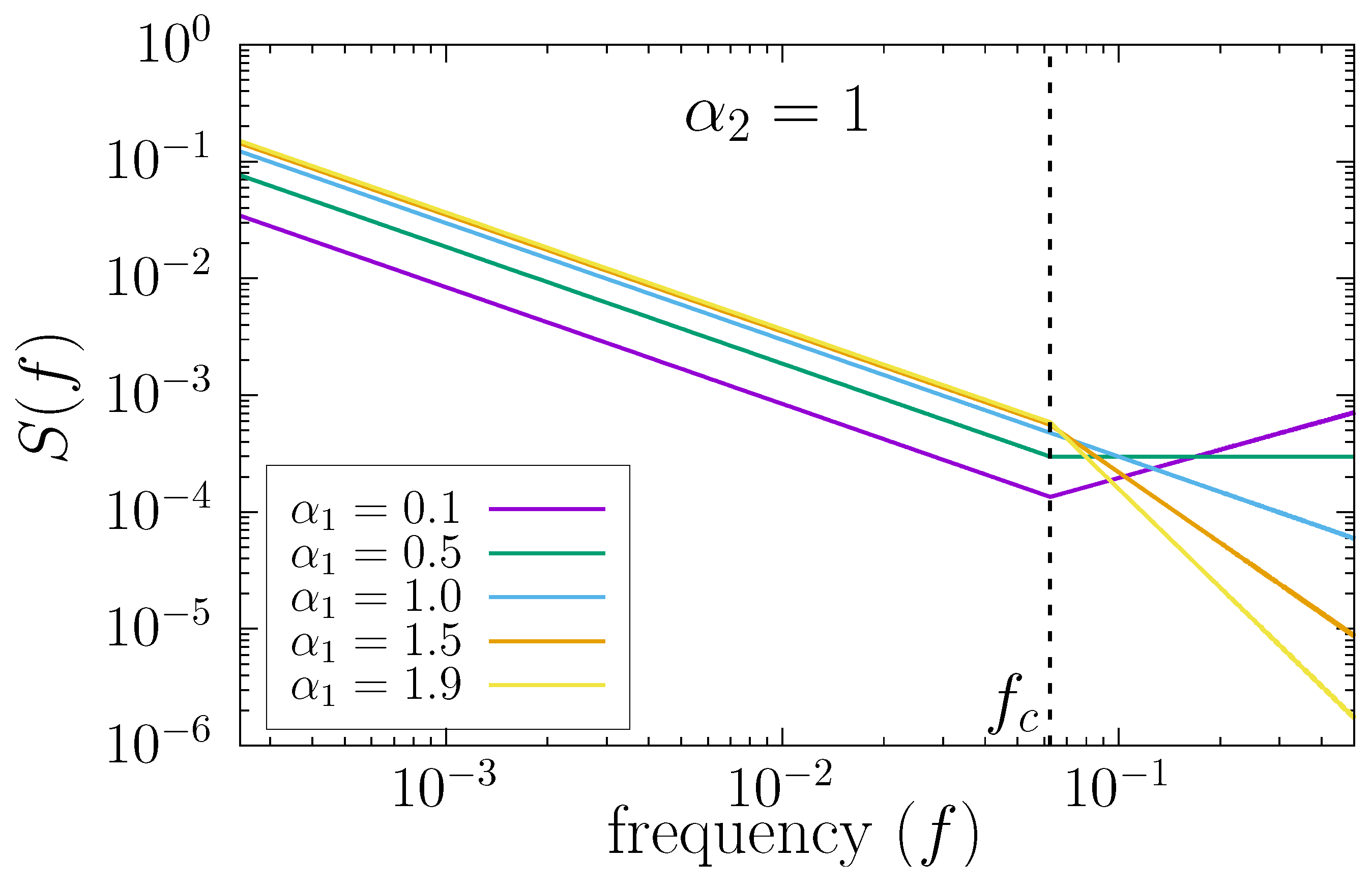
5. Behavior of for Time Series with Scaling Crossovers
We consider in this section time series truly characterized by different short and long-term scaling exponents
and
, and therefore with a scaling crossover at intermediate scales. These time series can be generated by using a modified version [
43] of the Fourier Filtering Method described in
Section 2. Essentially, the numerical procedure is identical to the standard FFM algorithm, but the power spectrum
, instead of as a single power-law, is modeled as:
This equation corresponds to two different power-law behaviors of
controlled by the exponents
(high frequencies) and
(low frequencies), with a crossover at frequency
. As an example, in
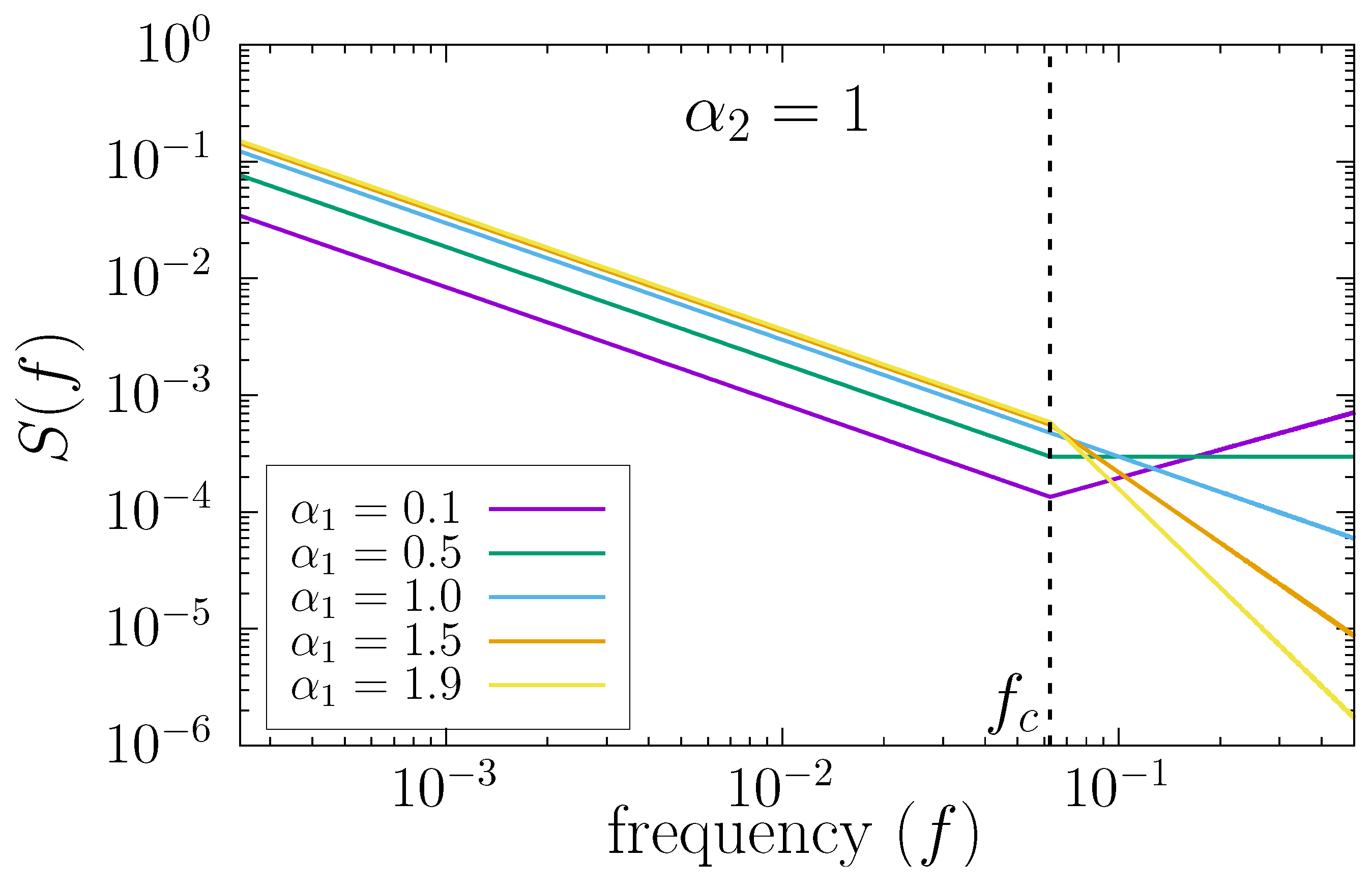
Figure 5, we show the power spectrum of time series generated with this technique by using the numerical value
and different values of
. The crossover frequency
is indicated with a vertical dashed line, and we have used
in the figure.
According to the definition of
in Equation (
11) and of the relation between the exponents of
and DFA, when the corresponding signal in the frequency domain is Fourier-transformed back into time domain to obtain the time series
, the short scale behavior is truly characterized by a DFA exponent
and the large scale behavior, by a DFA exponent
. The scale of the crossover,
, is given by
.
We note that this modified version of FFM has three input parameters, the scale of the crossover and the scaling exponents and that truly characterize the behavior of the final time series by construction. Since these exponents are inputs of the algorithm, from now on, we term them and , respectively.
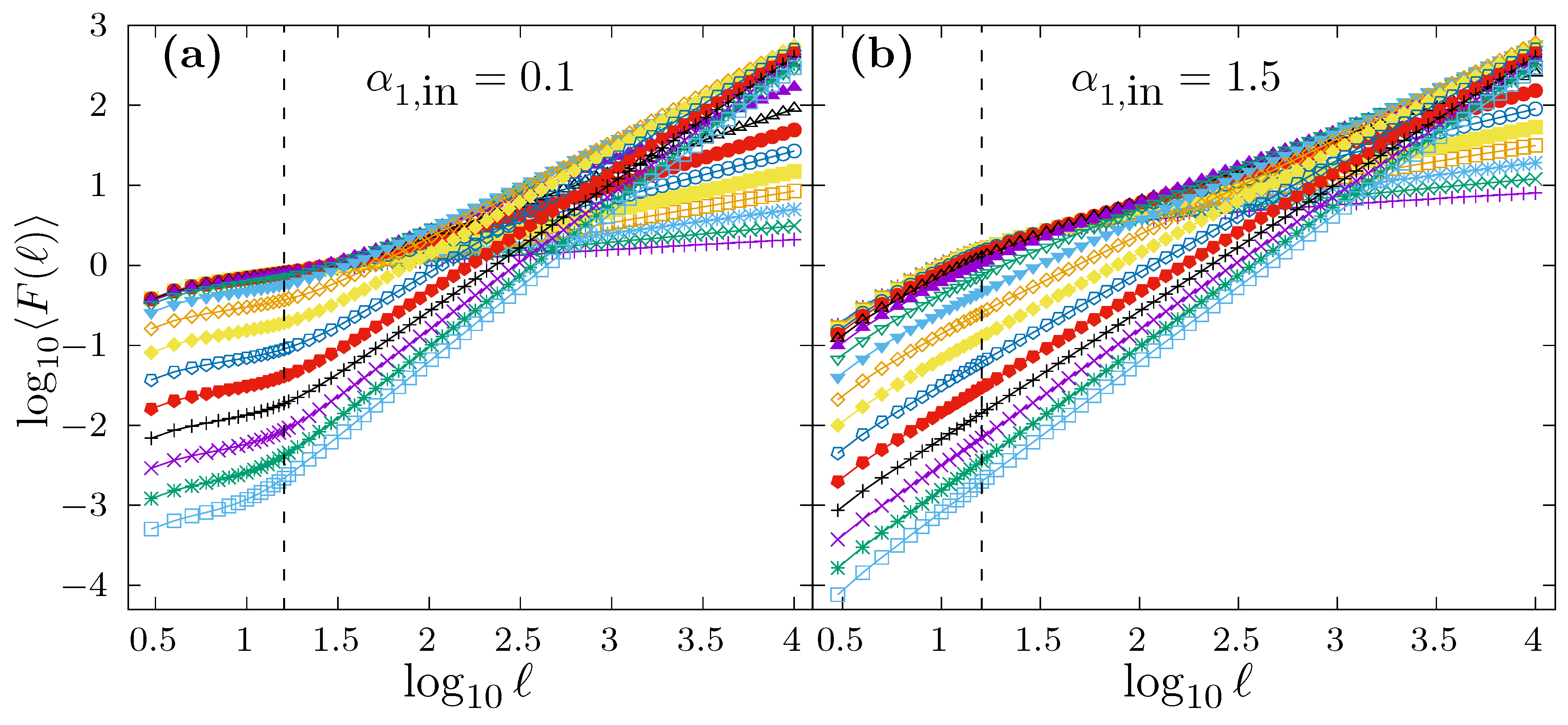
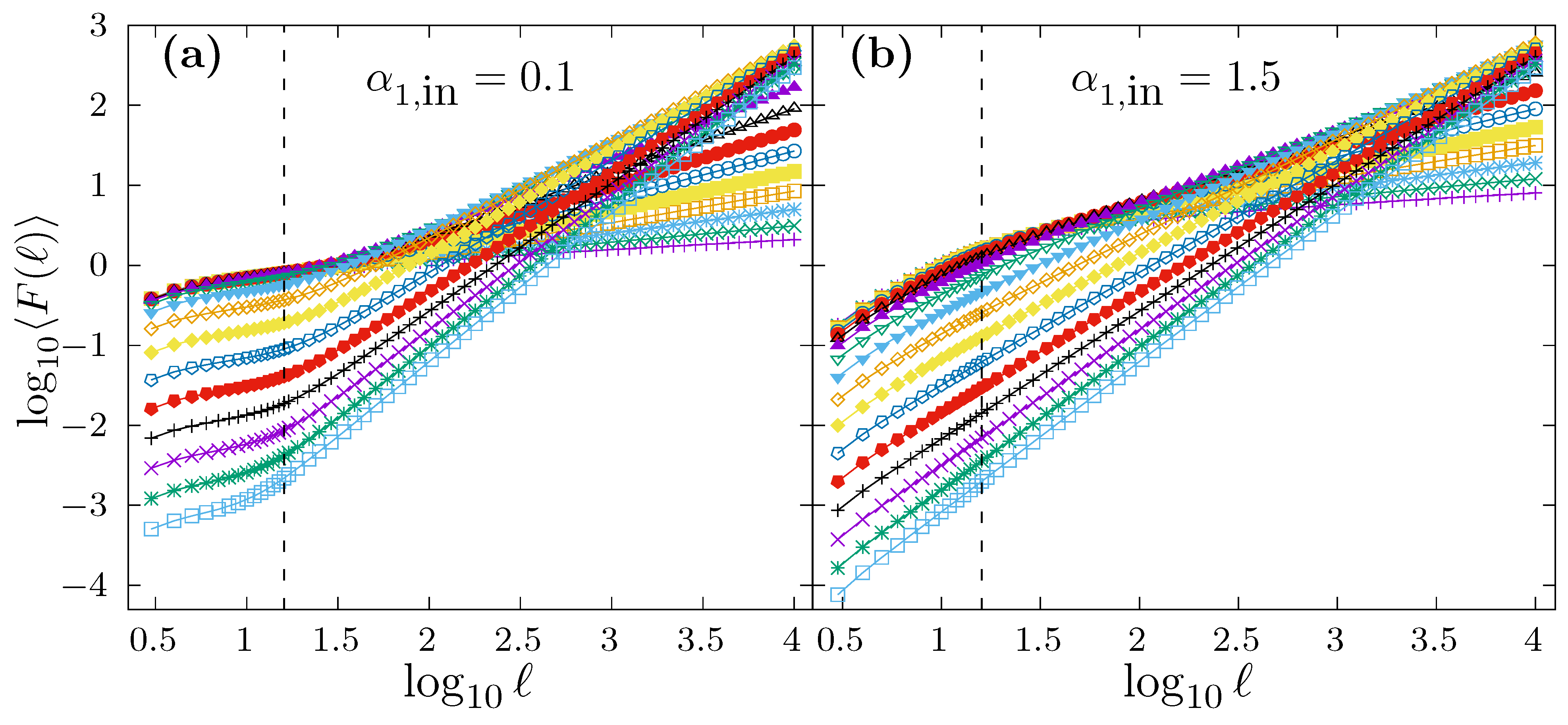
In order to illustrate how DFA behaves when applied to time series with scaling crossovers generated by the modified FFM algorithm proposed in (
11), in
Figure 6, we show the average DFA fluctuation function
obtained for such kind of time series. In particular, we have considered in
Figure 6 a scaling crossover at
shown as a vertical dashed line in both panels. In panel a, we fix
, and each curve corresponds to
values in the range
.
Figure 6b shows a similar case as in
Figure 6a, but using a fixed value of
. In both panels, for each different
, we have generated
time series of length
to obtain the corresponding average curve
. In all cases, we observe a change of slope in the
vs.
plot between short and large scales (as it should be).
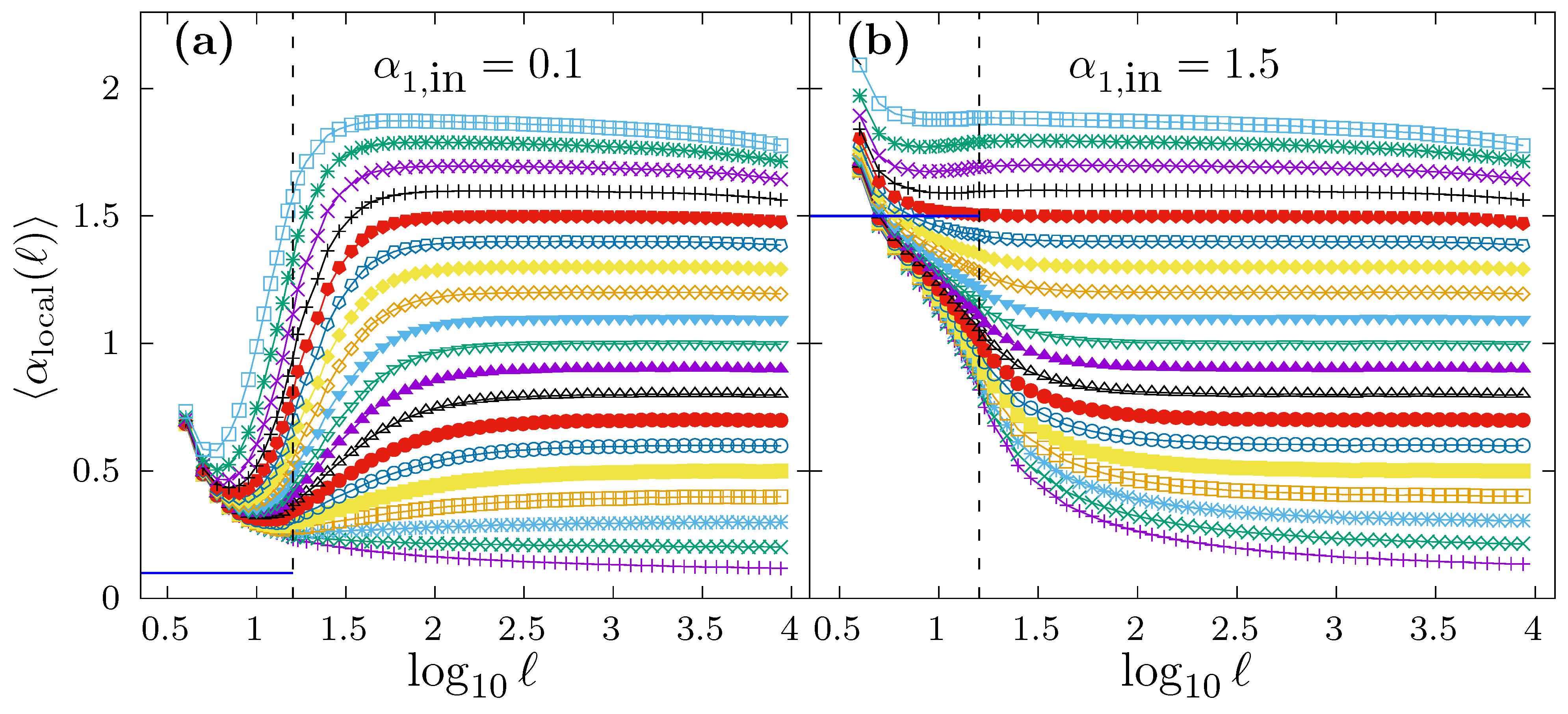
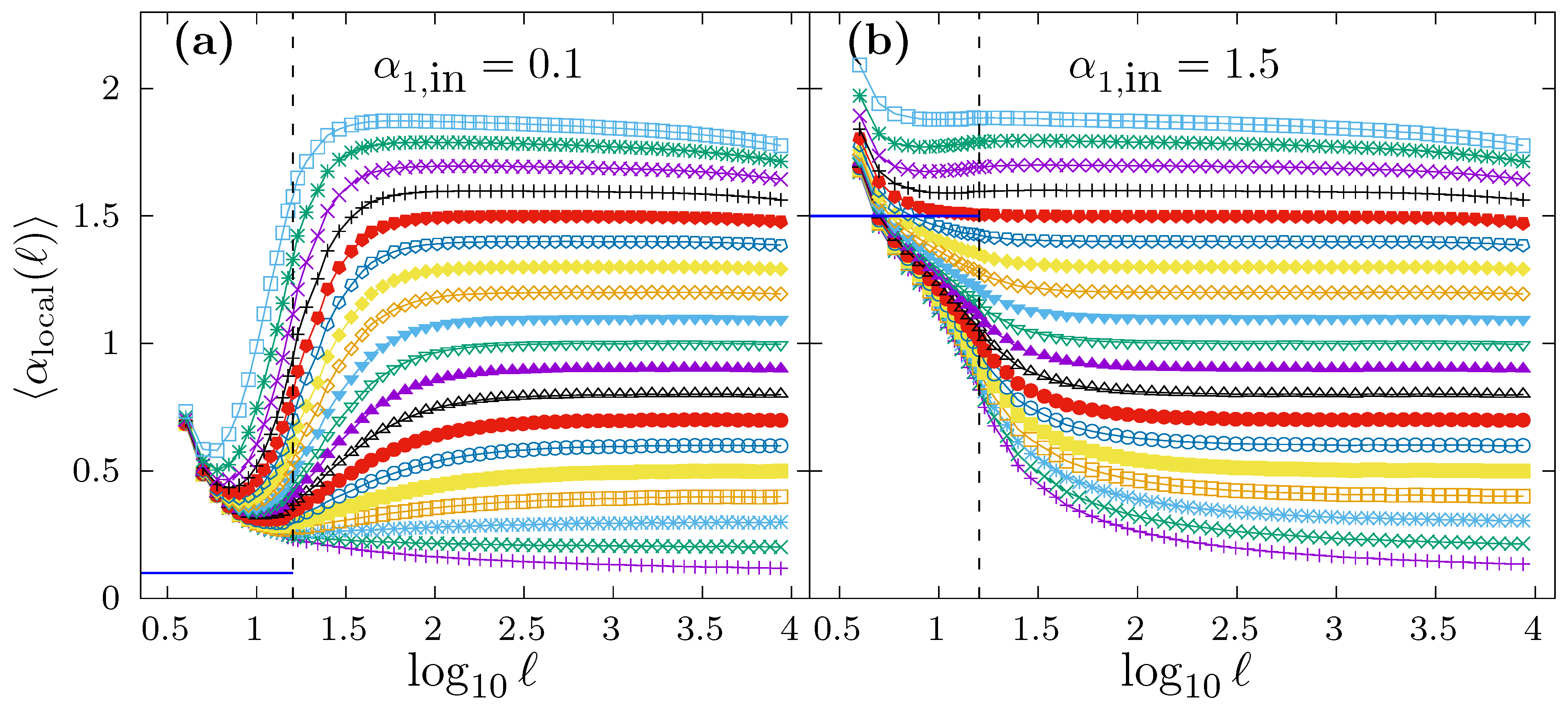
However, we want to investigate if the local scaling exponent in the short scale region for this kind of time series is able to recover the correct
value. For that purpose, and for the same time series used to produce
Figure 6, we show in
Figure 7 the average local scaling exponent
as a function of
. The scaling crossover at
is shown in both panels as a vertical dashed line. In panel a, we consider the case
, while in panel b
. The different curves in both panels correspond to
, and the average
is obtained by generating
time series with
for each
value. In both panels, we indicate with a horizontal segment in the short scale region the true
value used to generate the time series. In panel a, we observe how all the
curves all well above the correct
value. In this case, any fitting interval chosen in the short scale range will provide a drastic overestimation of
, although the specific estimation
value depends also on
. In panel b, we observe that some curves lie above the true
value (approximately for
) while other curves lie below the true
value (approximately for
). In the former case, the estimation
will overestimate the correct
value, while, in the latter,
will be underestimated. Either way,
would not be properly determined in any case, and the particular estimated
value would depend on the true
, despite the fact that
is identical in all cases.
The examples shown in
Figure 6 and
Figure 7 indicate the practical impossibility of properly estimating the true
for time series with scaling crossovers. Similarly to what we did in
Section 3, we now proceed to analyze the behavior of the estimated short scale exponent
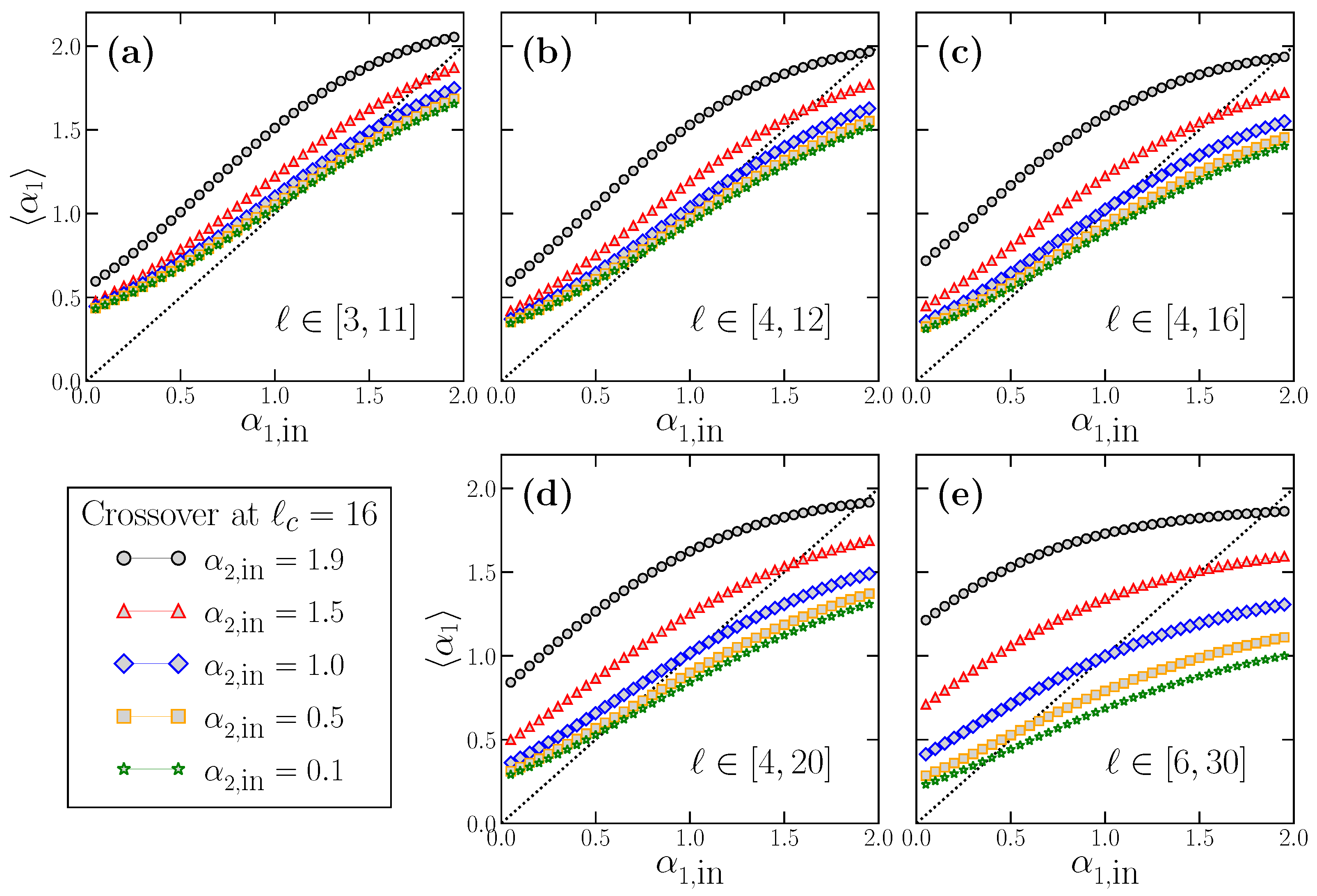
for these time series. The results for
as a function of the true
are shown in
Figure 8. We consider
values in the range
to include stationary and non-stationary time series. Each panel corresponds to the use of a different fitting range to obtain
, typically used in the bibliography. Within each panel, we present five different curves since we have considered five distinct values of
to check its possible influence on
, which we know to exist according to
Figure 7. For each combination of
and
, we use the modified FFM algorithm in Equation (
11) to generate
time series with
with the crossover scale at
. The
value for each individual time series is obtained by a fitting in the corresponding fitting range, and the resulting
values of
are averaged to get
. In panels a–c, we consider fitting ranges for obtaining
below the crossover scale
, while in panels d and e, the upper limit of the fitting interval is above
. Note that, in a real-world time series with two different scaling behaviors at short and large scales, the true scale of the crossover is not exactly known a priori, so that situations such as the ones shown in panels d and e are realistic. In all cases, the dashed line in the diagonal of all panels corresponds to the line
, i.e., the expected behavior of
in case of being correctly estimated.
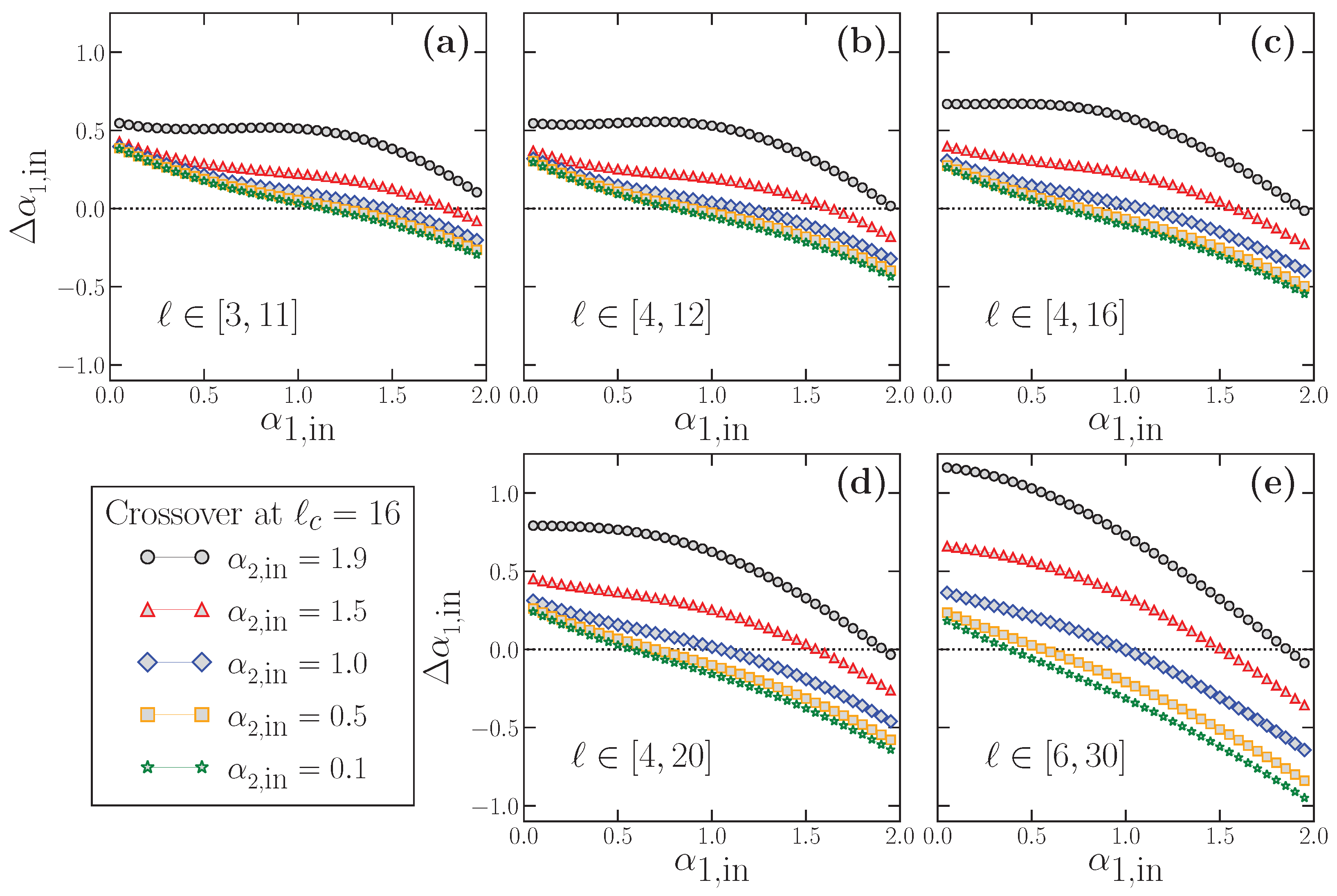
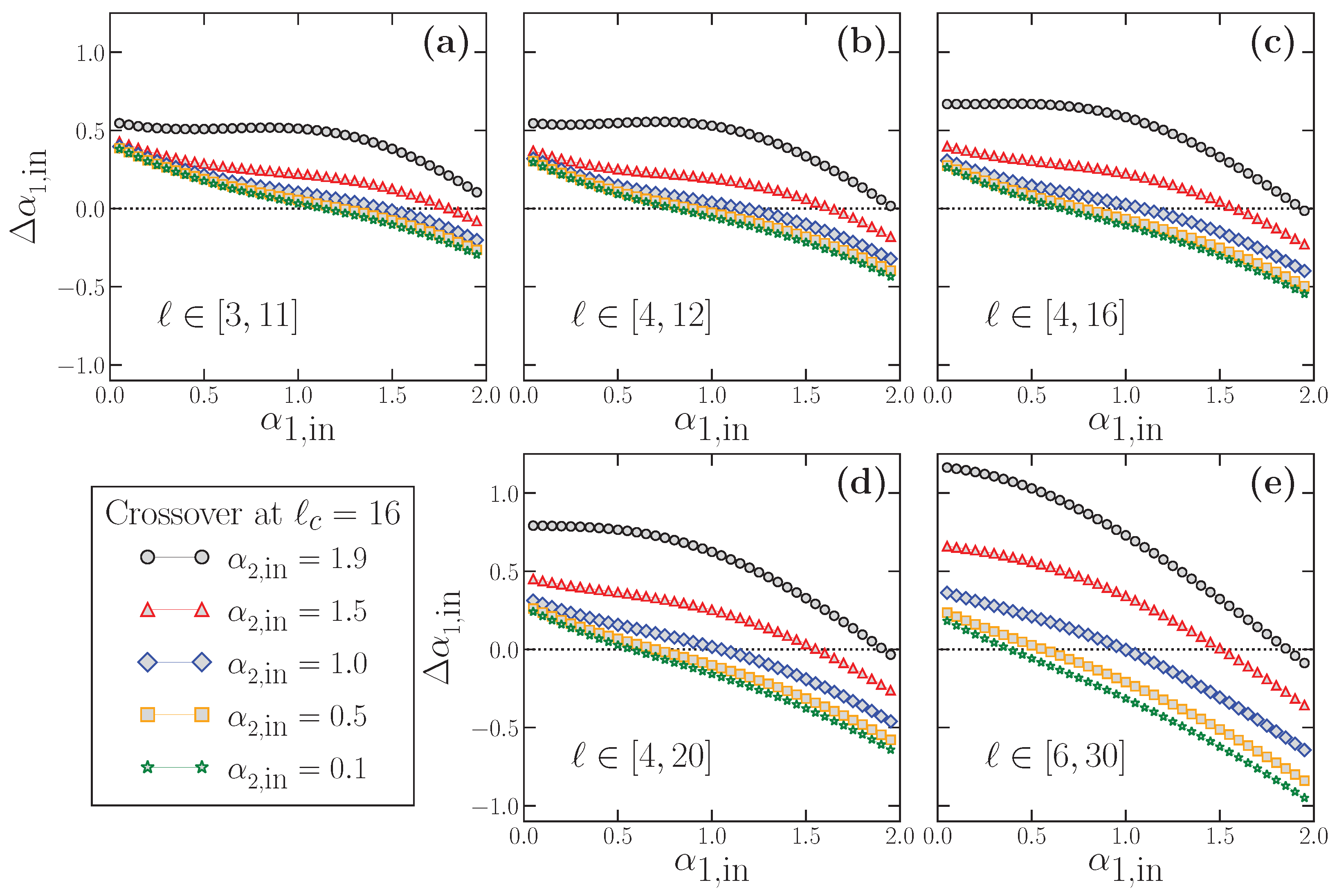
Similarly, in
Figure 9, we show the results for
obtained from the data presented in
Figure 8. In this case, the deviation of
with respect to the true short-scale value is defined as:
We apply directly this last expression to the results shown in
Figure 8 to obtain
Figure 9. In all panels of this latter figure, the horizontal dotted line at
corresponds to the perfect estimation of the true
.
The results shown in
Figure 8 and
Figure 9 have profound implications: First,
practically never estimates properly the true
value, as we suspected from the results of
Figure 7. In this case,
may overestimate (
) or underestimate (
), very often severely, the correct
. In general, for any fitting interval, we find that the overestimation happens for small
, and the underestimation for large
values. In between these two extrema, and since
and
are smooth functions of
, there is an accidental single value of
correctly estimated where the curves change from the over- to the underestimation region. However, this value is not robust since it depends on the fitting interval and the
value considered.
The deviation
depends obviously on the true
value, but also on the fitting interval considered (see
Figure 9), which is always quite arbitrary since the scaling of the crossover is not exactly known in real-world time series. We note that
can have large values (i.e., strong under or overestimation of the true
) even when the fitting interval lies completely below the true crossover scale (
Figure 8a–c and
Figure 9a–c), and may worsen if the upper limit of the fitting interval is larger than the crossover scale (
Figure 8d,e and
Figure 9d,e).
However, in addition to these effects that preclude a correct estimation of the true
, there is another factor shown in
Figure 8 and
Figure 9 which questions severely the use of DFA at short scales, and that we already discussed partially when presenting
Figure 7. We note that, for a fixed value of
, the corresponding estimated value
(and therefore the deviation
)
depends also on the value of the true large-scale exponent . This effect implies a serious methodological problem: let us imagine two time series with exactly the same
value (the same scaling behavior at short scales), but very different
values. According to our results in
Figure 8, if DFA is applied as usual at short scales to estimate the corresponding
value in these time series, the two estimated
values would be very different too, although the short-term scaling properties are identical in both time series, since they have the same true
. This case corresponds to imagining a vertical line for a fixed
value at any of the panels of
Figure 8. The line will cross the different curves at different
values, which would be the estimated values provided by DFA, although, in all cases, the short-term scaling is the same. This effect corresponds exactly to the examples shown in
Figure 7: while in all cases
(panel a) or
(panel b), a fitting in the short scale region (a kind of average of the corresponding
) would provide different estimated
values depending on
.
Similarly, the opposite situation is also possible: for two time series with different
values, one can estimate the same
value applying DFA at short scales if the two time series have a different large-scale exponent
. This case corresponds to imagining a horizontal line at any fixed
value in any of the panels of
Figure 8. The line will cross the curves at very different true
values, so that the time series truly have very different scaling properties at short scales but will be considered to have the same
value if DFA is used.
6. Discussion and Conclusions
In the last two decades, Detrended Fluctuation analysis has become a widely-used standard method to characterize the correlations and scaling properties of real-world complex time series. Within this context, many authors, especially in the field of physiology in the analysis of cardiac signals, study the scaling properties of the experimental time series by applying separately DFA at short and large scales of observation, therefore characterizing the time series by two exponents, and , corresponding to short and large scales, respectively. If both exponents are different, and this happens very often, the difference is attributed to the existence of different mechanisms controlling the underlying dynamical system which act at different time scales, short and long range.
Here, we have shown that, when considering time series with perfect scaling, and therefore with a single exponent for all the scales of observation, DFA estimates correctly the real scaling exponent for large or moderately large scales of observation. However, if we calculate for these time series the exponent in the range of short scales, we have observed a systematic deviation of with respect to the correct and unique scaling exponent, which is in many cases largely overestimated by . This deviation depends not only on the value of the real scaling exponent, but also on the range of scales used to obtain . We have shown that this overestimation is not due to size effects of the time series, and therefore that it is an intrinsic property of DFA (artifact) at short scales.
In addition, when time series with a scaling crossover and two different scaling exponents at short and large scales are considered, the value estimated by DFA can overestimate or underestimate (in many cases for a great amount) the correct short-scale exponent. The deviation of the estimated with respect to the true exponent depends on the value of the true exponent itself, and of the fitting range considered (which varies among different authors) even if fitting ranges well below the scale of the crossover are considered. Even more importantly, the estimated value of also depends on the value of the long-term scaling exponent, so that time series with identical short scale properties and different long scale properties will have different estimations of . This effect can also appear in the reverse way: we can find time series with the same estimated values but with very different real short-term scaling properties if the long-term exponent is different.
We note that the results found in this work are of general applicability: note that the behavior of DFA at short scales we observe is due to the intrinsic mathematical properties of DFA, which only works properly asymptotically. i.e., for large scales. In the short scale region, the function never behaves as a power-law, neither for signals with perfect scaling at all scales nor for signals with scaling crossovers, and this result is independent of the type of time series considered. Therefore, trying to fit to a power-law in the short scale region always produces spurious results.
For all these reasons, the estimated value of does not characterize properly the scaling properties and correlations at short scales, so that one has to be very careful when interpreting the meaning of obtained for real-world experimental time series. On the one hand, if the experimental data truly exhibit perfect scaling with a single exponent, will have a different value and could wrongly lead to the conclusion that there exists some specific mechanism acting on the dynamical system at short scales. On the other hand, for time series with two truly different scaling exponents produced by the characteristics of the dynamical system, the obtained value will be also affected by the systematic deviation at short scales and will not coincide with the true short-scale exponent. In this latter case, the obtained value will not characterize properly the real control mechanism acting at short scales on the dynamical system.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}